【大模型】Xinference的安装和部署
Xinference通过提供简单API和强大的功能,使得私有化模型的大规模部署成为可能,无论是在个人电脑还是分布式集群中,都能够发挥异构硬件的全部潜力,达到最极致的吞吐量与最低的推理延迟。:Xinference简化了包括大语言模型、多模态模型、语音识别模型等模型部署的过程,允许用户轻松一键部署自己的模型或内置的前沿开源模型。:Xinference专注于优化模型的推理性能,并支持多种类型的模型,包括
1 Xinference的简介
【xinference的官网链接】https://inference.readthedocs.io/zh-cn/latest/getting_started/index.html
【github链接】https://github.com/xorbitsai/inference
Xinference是一个性能强大且功能全面的分布式推理框架,它能够用于大语言模型(LLM)、语音识别模型、多模态模型等各种模型的推理。以下是Xinference的一些关键特性和信息:
- 一键部署模型:Xinference简化了包括大语言模型、多模态模型、语音识别模型等模型部署的过程,允许用户轻松一键部署自己的模型或内置的前沿开源模型。
- 内置前沿模型:Xinference允许用户一键下载并部署内置的大量前沿模型,如
chatglm2、vicuna、wizardlm等,且持续更新支持的模型列表。- 异构硬件使用:Xinference可以在CPU上完成推理,也可以在显卡忙时将部分计算工作交给CPU完成,以增大集群的吞吐率。
- 灵活的API:Xinference提供包括RPC和RESTful API(兼容OpenAI协议)在内的多种接口,方便与现有系统集成。此外,还提供命令行与Web UI方便用户管理和监控系统。
- 分布式架构:Xinference采用分布式架构,支持跨设备与跨服务器的模型部署,允许高并发推理,并简化扩容和缩容。
- 第三方集成:Xinference可以与包括LangChain在内的第三方库无缝集成,协助快速构建基于AI的应用程序。
- 支持多种推理引擎:Xinference支持多种推理引擎,包括
vllm、sglang、llama.cpp、transformers等,以适应不同模型的需求。- 跨平台支持:Xinference可以在Linux、Windows、MacOS上通过pip安装,方便在不同操作系统上使用。
- 开源社区支持:Xinference是开源的,这意味着它可以从社区中获得持续的更新和支持,同时也允许用户根据需要进行定制和扩展。
- 模型推理性能优化:Xinference专注于优化模型的推理性能,并支持多种类型的模型,包括深度学习模型。
Xinference通过提供简单API和强大的功能,致力于私有化模型的大规模部署,无论是在个人电脑还是分布式集群中,都能够发挥异构硬件的全部潜力,达到最极致的吞吐量与最低的推理延迟。
2 Xinference的环境配置与本地运行
2.1 环境配置
1【本机环境】
- Ubuntu:22.04.5
- CUDA Version:12.2
2【创建虚拟环境】
conda create --name xinference python=3.11 -c conda-forge conda activate xinference3【安装大模型使用到的所有的依赖】
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simple【出现的bug】
【解决办法】
- 直接到官网下载whl文件,然后通过本地安装的方式就可以。
https://github.com/abetlen/llama-cpp-python/releases下载合适的平台、python版本、cuda版本的whl文件。
pip 进行安装pip install llama_cpp_python-*
- 待安装结束后重新运行
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simple
2.2 本地运行 Xinference
【正常的启动Xinference】
## 国内访问不了 huggingface, # xinference-local --host 0.0.0.0 --port 9997 ## 使用 modelscope # XINFERENCE_MODEL_SRC=modelscope xinference-local --host 0.0.0.0 --port 9997 ## 设置好modelscope下载模型时的默认路径 XINFERENCE_HOME=/opt/ai-platform/lldataset/240/modelscope XINFERENCE_MODEL_SRC=modelscope xinference-local --host 0.0.0.0 --port 9997




3 使用 Docker 部署 Xinference(可选)
若本地安装不成功,可以选择使用docker部署。具体操作如下:
- docker 的安装
参考链接 【环境配置】ubuntu中 Docker的安装- 在有显卡的机器上运行
将 <your_version> 替换为 Xinference 的版本,比如 v0.10.3,可以用 latest 来用于最新版本。docker run -e XINFERENCE_MODEL_SRC=modelscope -p 9998:9997 \ --gpus all xprobe/xinference:<your_version> xinference-local -H 0.0.0.0 --log-level debug
4 Xinference的大模型下载与启动
4.1 大模型的终端命令启动
- 【具体操作】
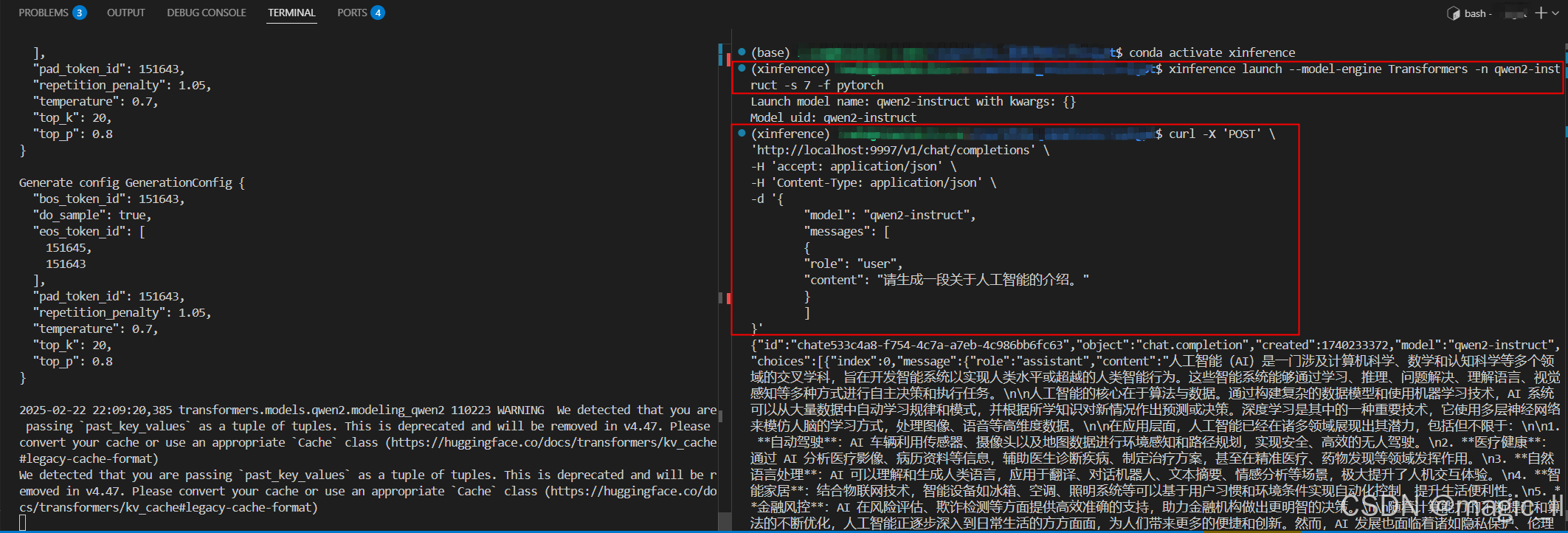
另外开启一个终端,运行如下命令。然后会进行模型下载和启动,结束后 该终端命令结束, 就代表xinference 将 qwen2-instruct 运行起来了。
这里以 qwen2-instruct 模型为例,使用的 模型引擎为 Transformers、模型格式使用 pytorch、模型大小为7B。关于这些参数如何得知,一个方法是可是浏览器界面进行模型加载页面可知,具体方法【Chat大模型界面启动】模型下载过程中,第一个终端界面如下图:xinference launch --model-engine Transformers -n qwen2-instruct -s 7 -f pytorch
- 【终端curl测试模型是否能够访问】
curl -X 'POST' \ 'http://localhost:9997/v1/chat/completions' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model": "qwen2-instruct", "messages": [ { "role": "user", "content": "请生成一段关于人工智能的介绍。" } ] }'
4.2 停止模型并释放资源
xinference terminate --model-uid "qwen2-instruct"加载模型与释放模型后,可以通过
nvidia-smi查看显卡使用的情况。
4.3 模型界面启动(可选)
在第一个步骤正常启动了xinference后,在浏览器界面访问 http://localhost:9997
4.3.1 Chat 大模型的启动
搜索和选择 【qwen2-instruct】
如下图,待参数设置OK后,点击小火箭,则下载模型和加载模型,模型下载到默认路径。
出现一些配置参数:
- Model Engine:部署使用的引擎
- Model Formate: 部署格式
- Model Size:模型的参数量大小,这里只有9b
- Quantization:量化精度
- N-GPU:选择使用第几个 GPU
点开Optional Configuations,还有一些参数
- Model UID:模型的名字,后续可能会用到,所以不能乱改
- GPU IDX:GPU的序号数,有几个GPU从0开始排序。比如两个GPU,则为0,1
- DownloadHub:以及提前下载好了模型,所以选择NONE
- ModelPath:模型地址。可选项,若针对已经下载的模型,填写模型的路径即可
小火箭之后,终端如下图
在xinference界面显示如下,则说明大模型成功运行了。4.3.2 向量模型的启动
- 搜索和选择 【bge-large-zh-v1.5】
- 成功部署
- 终端查看显存使用
4.3.3 Xinference查看运行的模型
xinference list









5 大模型的调用
Xinference提供了标准的OpenAI接口,在
http://127.0.0.1:9997/docs中可以查看。
使用库 langchain_openai 进行接口的调用如下:from langchain_openai import ChatOpenAI openai_api_base = 'http://127.0.0.1:9997/v1/' model = "qwen2-instruct" ## 部署模型的时候Model UID的值 temperature = 1 openai_api_key = "EMPTY" llm = ChatOpenAI(openai_api_base=openai_api_base, model=model, temperature=temperature, openai_api_key=openai_api_base) res = llm.invoke("""你是谁呀""") print(res.content)



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 35
35 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)