【AI大模型】一文彻底搞懂Transformer - 多头注意力(Multi-Head Attention)
在深度学习中,多头注意力(Multi-Head Attention)是一种注意力机制。它是对传统注意力机制的一种改进,旨在通过分割输入特征为多个“头部”(head)并独立处理每个头部来提高模型的表达能力和学习能力。
在深度学习中,多头注意力(Multi-Head Attention)是一种注意力机制。它是对传统注意力机制的一种改进,旨在通过分割输入特征为多个“头部”(head)并独立处理每个头部来提高模型的表达能力和学习能力。
多头注意力机制已被广泛应用于各种深度学习任务中,包括但不限于机器翻译、文本摘要、语音识别、图像描述生成等。它在Transformer架构中扮演着至关重要的角色,而Transformer架构也已成为许多自然语言处理(NLP)任务的首选模型。
Multi-Head Attention
一、多头注意力机制
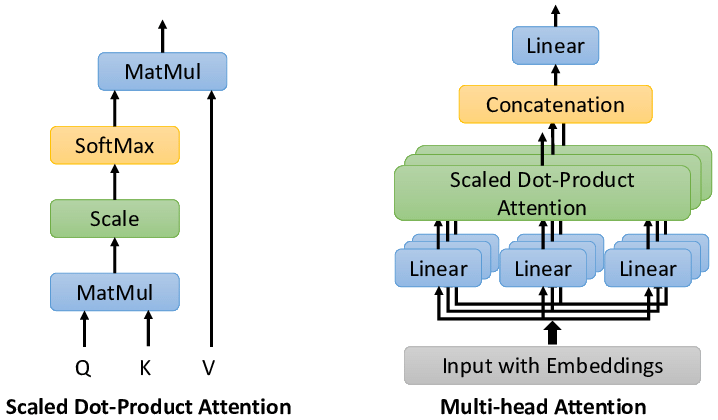
多头注意力机制(Multi-Head Attention)是什么?多头注意力机制将输入的特征(通常是查询、键和值)通过多个独立的、并行运行的注意力模块(或称为“头”)进行处理。
每个头都会独立地计算注意力得分,并生成一个注意力加权后的输出。这些输出随后被合并(通常是通过拼接或平均)以形成一个最终的、更复杂的表示。
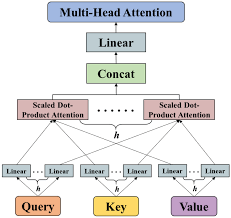
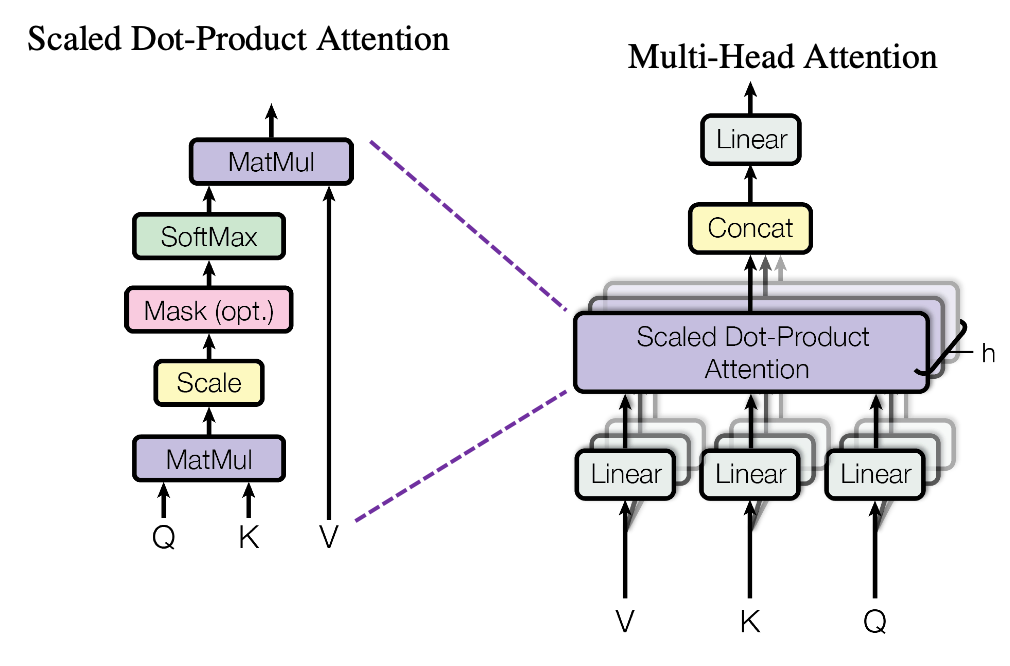
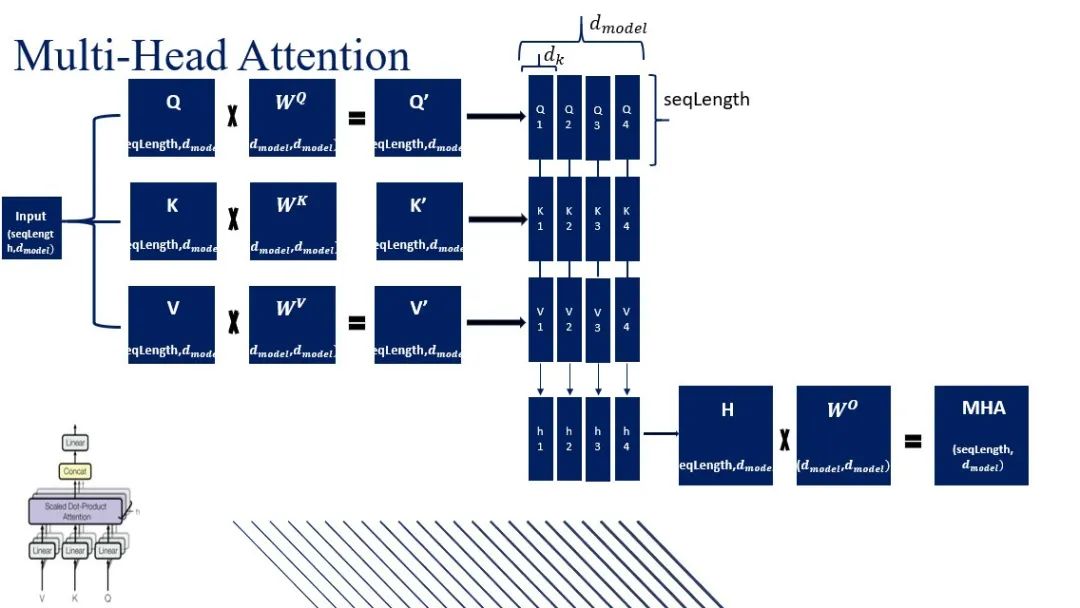
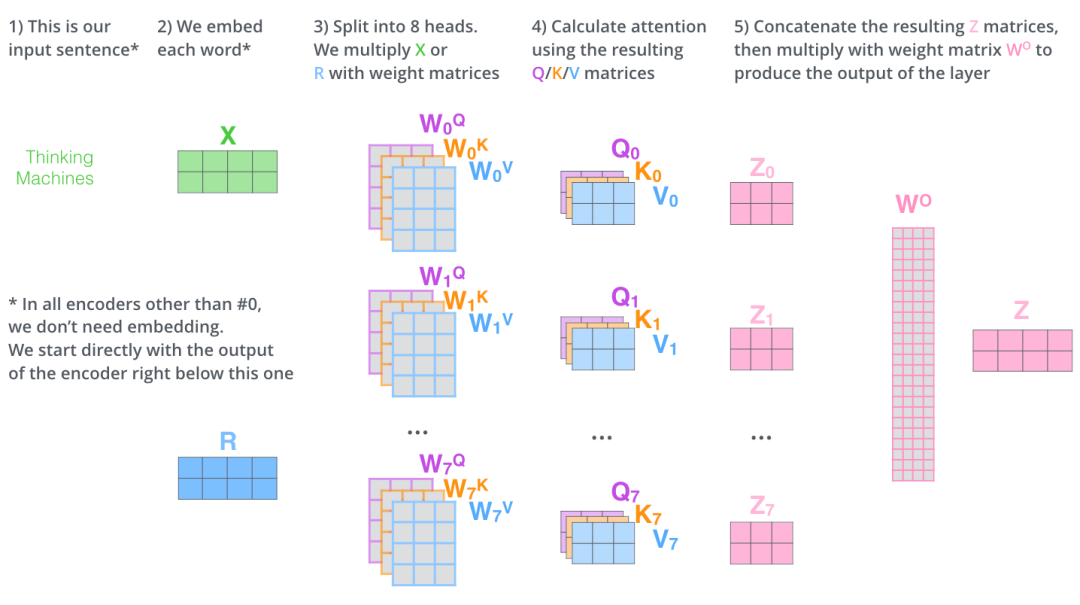
多头注意力计算过程是什么?多头注意力将输入序列通过线性变换得到查询、键和值矩阵,然后分头进行缩放点积注意力运算,最后将所有头的输出拼接并经过线性变换得到最终输出。
-
输入变换:输入序列首先通过三个不同的线性变换层,分别得到查询(Query)、键(Key)和值(Value)矩阵。这些变换通常是通过全连接层实现的。
-
分头:将查询、键和值矩阵分成多个头(即多个子空间),每个头具有不同的线性变换参数。
-
注意力计算:对于每个头,都执行一次缩放点积注意力(Scaled Dot-Product Attention)运算。具体来说,计算查询和键的点积,经过缩放、加上偏置后,使用softmax函数得到注意力权重。这些权重用于加权值矩阵,生成加权和作为每个头的输出。
-
拼接与融合:将所有头的输出拼接在一起,形成一个长向量。然后,对拼接后的向量进行一个最终的线性变换,以整合来自不同头的信息,得到最终的多头注意力输出。
多头注意力机制和注意力机制区别是什么?多头注意力机制通过引入多个并行的注意力头,提高了模型对输入数据的全面捕捉和处理能力,使其在处理大规模数据和复杂任务时更具优势。
-
注意力机制:通过聚焦于关键信息,提高了模型对输入数据的理解和处理能力。
-
多头注意力机制:通过并行处理和集成多个注意力头的结果,从不同角度捕捉数据的多样性,进一步增强了模型的学习能力和表达力。
二、Transformer & GPT
Transformer多头注意力有多少个Head?Transformer多头注意力中的“头”(Head)的数量是一个超参数,这意味着它可以根据具体任务和数据集的需求进行调整。在Transformer模型中,并没有固定数量的注意力头,而是可以根据实际情况进行配置。
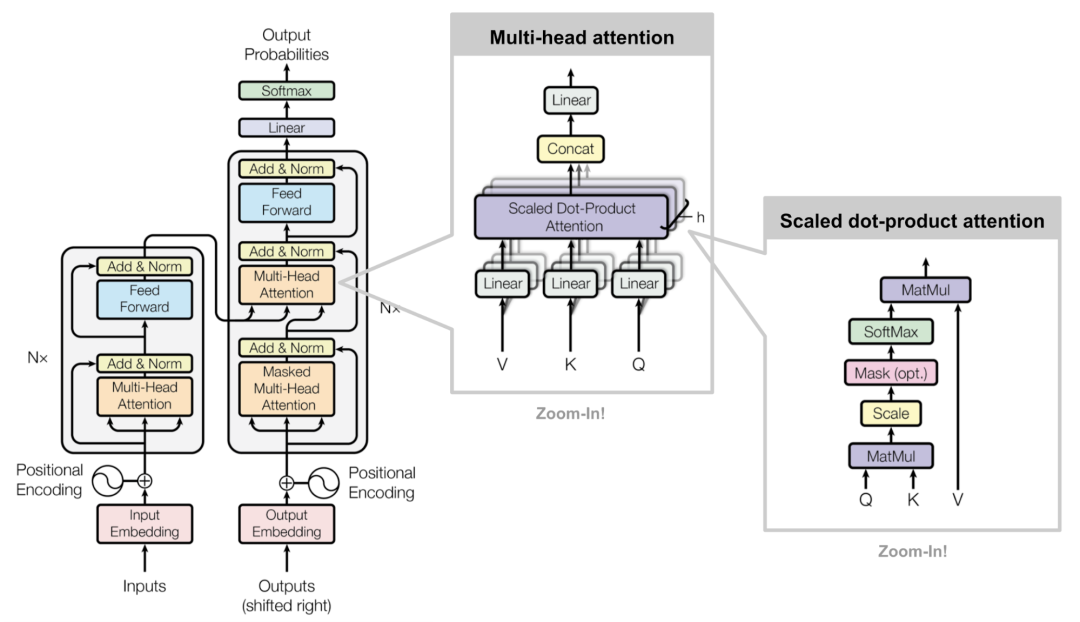
GPT多头注意力有多少个Head?GPT模型中的多头注意力机制的头数量同样是一个超参数,它根据GPT版本和模型配置的不同而有所变化。
-
GPT-1:GPT-1模型使用了12层的Transformer解码器结构,每层解码器中包含了多头自注意力机制。根据常见的配置,它可能采用了与Transformer模型相似的头数量设置,如8个、16个等。
-
GPT-2:GPT-2模型在结构上进行了扩展,例如GPT-2 Medium版本使用了24层的Transformer解码器,并且每层中的隐藏层维度为1024。在这个配置下,GPT-2 Medium有16个注意力头。
-
GPT-3:GPT-3模型在规模和复杂度上进一步增加,使用了更多的层和更大的隐藏层维度。然而,关于GPT-3具体使用了多少个注意力头的详细信息,并没有在公开文档中明确提及。与GPT-1和GPT-2类似,GPT-3的多头注意力头数量也是一个可以根据模型配置进行调整的超参数。

最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)