
DeepSeek在Windows系统一键包本地部署与科普
DeepSeek在Windows系统一键包本地部署,R1介绍,模型对比
一、前言
新年第一炮由DeepSeek打响,这一炮干翻美股,开启了人工智能和全球经济的又一个春天。回想起几年前ChatGPT横空出世取得了划时代的关注与影响,滋润着人工智能的话题经久不衰,但是似乎人们逐渐适应了这个温床。DeepSeek无疑是一个天外来物,在已经近乎平静的井底砸出了新的波澜。相信使用过ChatGPT的用户心底都有一个疑问,这二者到底哪个更吊?笔者亦非常好奇。本着拥抱新技术的态度,好不好用实践出真知嘛,咱也来体验一把。
二、Windows系统下直接安装包本地部署
网上也出了不少的教程,基本都是最正儿八经安装ollama,然后命令行一顿鼓捣,笔者偶然间看到了一个博主分享的Windows版本的安装包,可以直接通过LM Studio 平台(本地大语言模型 (LLM) 应用平台)本地部署大模型。
deepseek本地部署教程一键安装包-windows电脑deepseek本地运行-CSDN博客
(1)网盘下载

(2)管理者身份运行exe文件
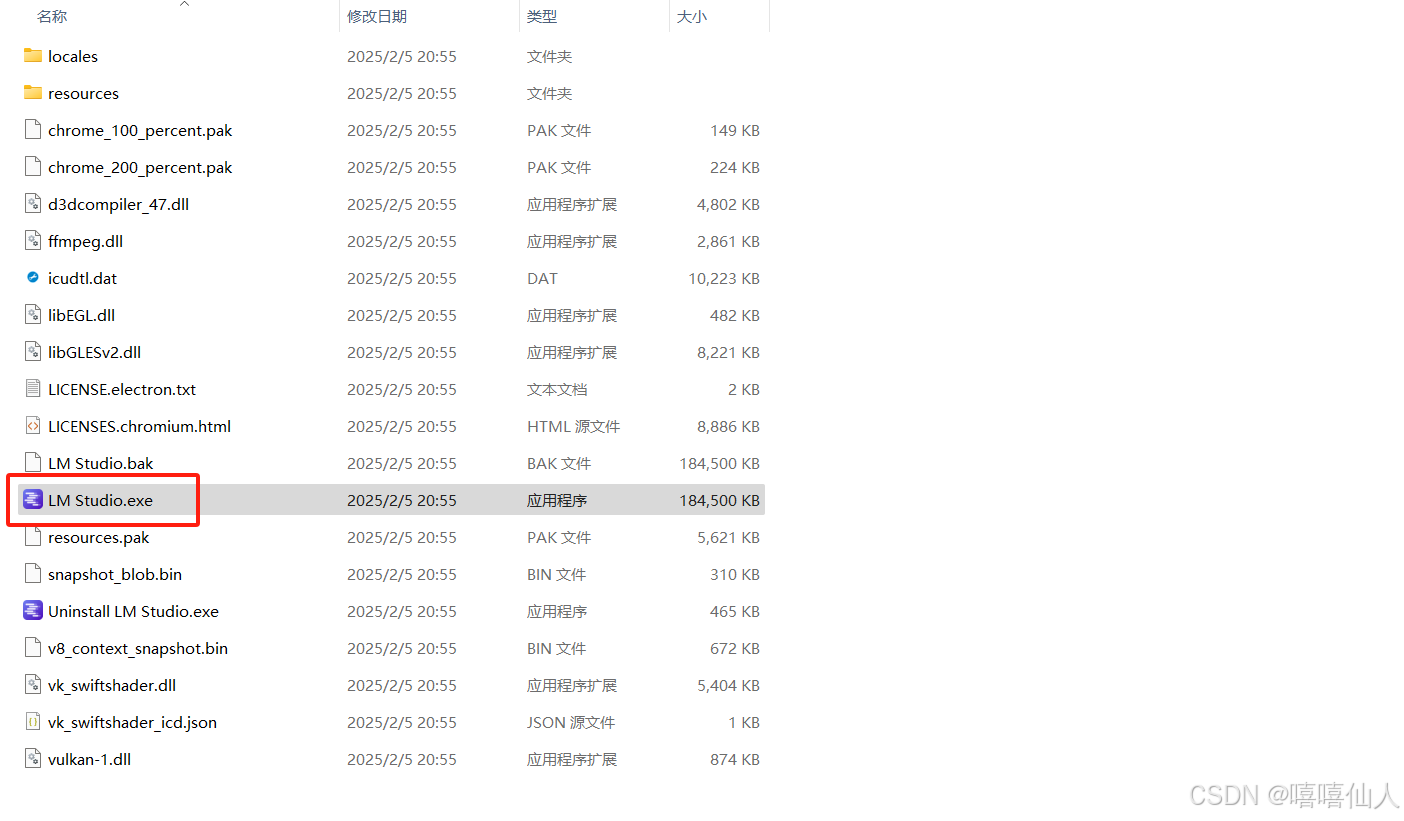
(3)等待程序加载之后 ,即可选择模型
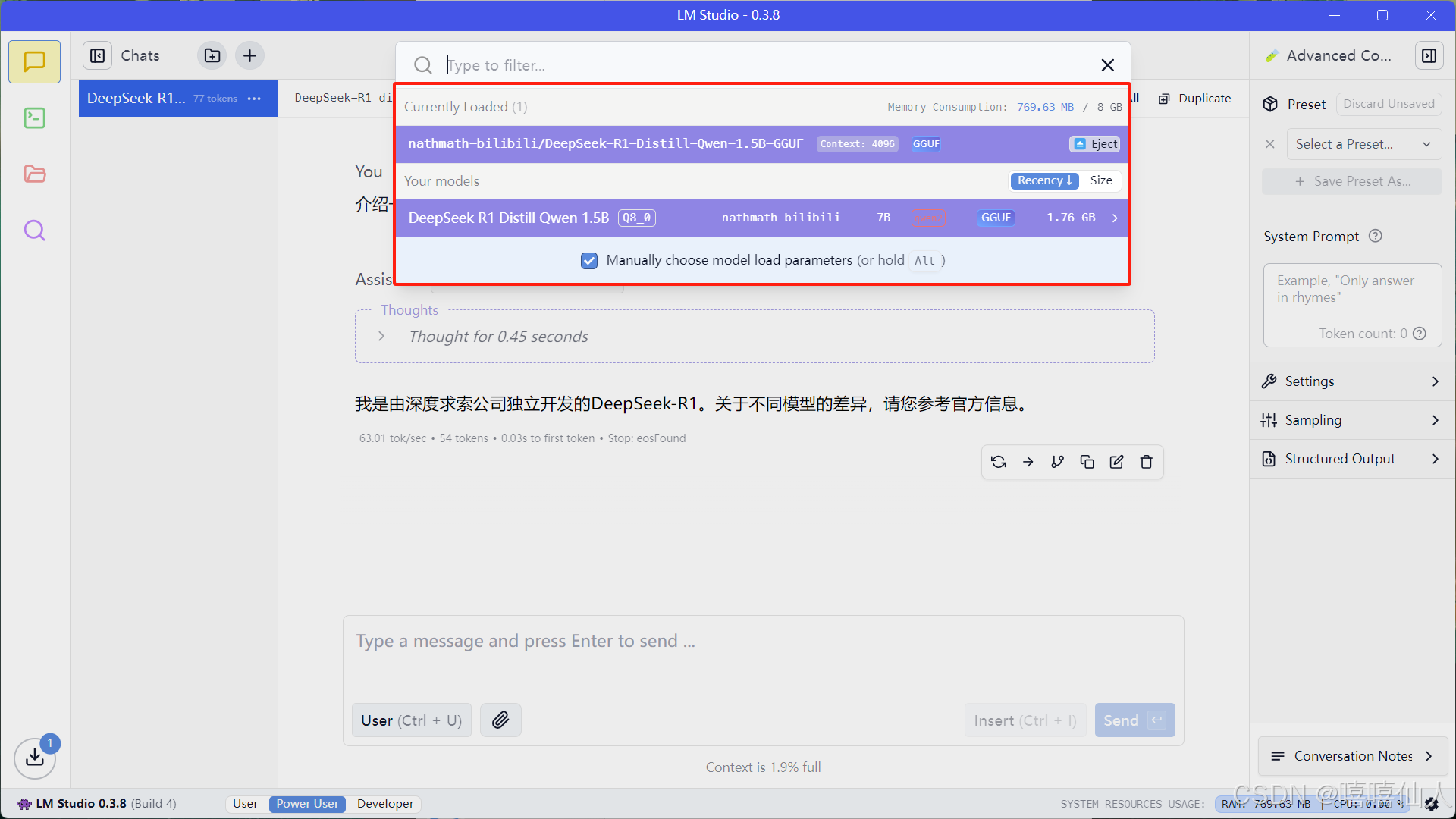
(4)自定义添加其他模型
只需要将对应的压缩包解压到.lmstudio\models\nathmath-bilibili路径即可

三、本地部署与网页版本的区别
之前没有尝试过大模型的本地部署,最开始先入为主的思想就是没必要,明明网页端可以实现的事儿干嘛要进行本地部署,但是借着这次本地部署DeepSeek的机会对于这个问题有了更多的理解。
相信之前使用过网页版大模型(例如ChatGPT等)遇到过服务器繁忙无法响应的问题,这就是网页端大模型一个很明显的缺点,因为本质上都是在使用服务器的资源,而当多台主机同时占用服务器资源时,就会出现响应变慢等问题。与此同时,因为是你的网页客户端和大模型的服务器之间进行数据上下行,所以你的数据的隐私性会变差,这也是一个缺点。
相比之下,大模型的本地部署就可以弥补这些缺点,利用本机的硬件资源进行算法加速,不存在共享服务器的问题,除此之外因为数据都在本机上存储,隐私性较好。
但是本地部署要求也更高,例如对你电脑的软硬件配置要求较高,对于本地环境的配置还是有一些困难的,对于电脑小白可能不太友好。而且如果电脑性能一般的话谨慎安装,可能会导致电脑过载模型冻结。
四、DeepSeek各版本一览
目前DeepSeek主流的版本主要有DeepSeek R1和V3两个版本
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
相关技术已经开源,凭借这一点这值得一个star
DeepSeek R1和V3是两款针对不同应用场景设计的AI模型,它们在设计目标、技术实现和性能表现上有明显的区别:
(1)设计目标和应用场景
- DeepSeek R1:
- 目标用户:学术研究者、问题解决者和决策支持系统。
- 侧重点:深度推理和问题解决,适合需要逻辑分析和复杂推理的任务。
- 示例:在处理复杂的数据分析或科学问题时表现出色。
- DeepSeek V3:
- 目标用户:开发者和企业用户,侧重于大规模自然语言处理任务。
- 侧重点:可扩展性和高效处理,适合多语言翻译和内容生成等应用。
- 示例:在多语言任务和大规模数据处理中表现优异。
(2)技术实现和性能指标
- DeepSeek R1:
- 架构:采用稠密Transformer架构,适合处理长上下文,但计算资源消耗较高。
- 训练方法:结合监督微调和强化学习,强调思维链推理。
- 性能指标:在逻辑思维和数学推理方面表现较好。
- DeepSeek V3:
- 架构:采用混合专家(MoE)架构,通过动态路由机制优化计算成本。
- 训练方法:使用混合精度FP8训练,支持高质量训练和扩展序列长度。
- 性能指标:在数学、多语言任务和编码任务中表现优秀,响应速度更快
(3)DeepSeek R1
(i)DeepSeek R1的帝国组成
DeepSeek R1 的演变可以用下图简单表示:
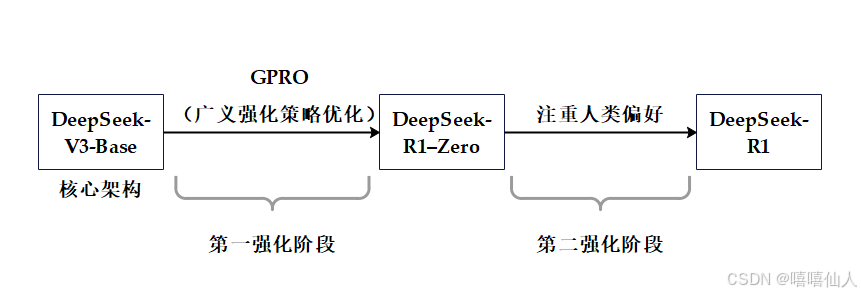
详细框图如下:
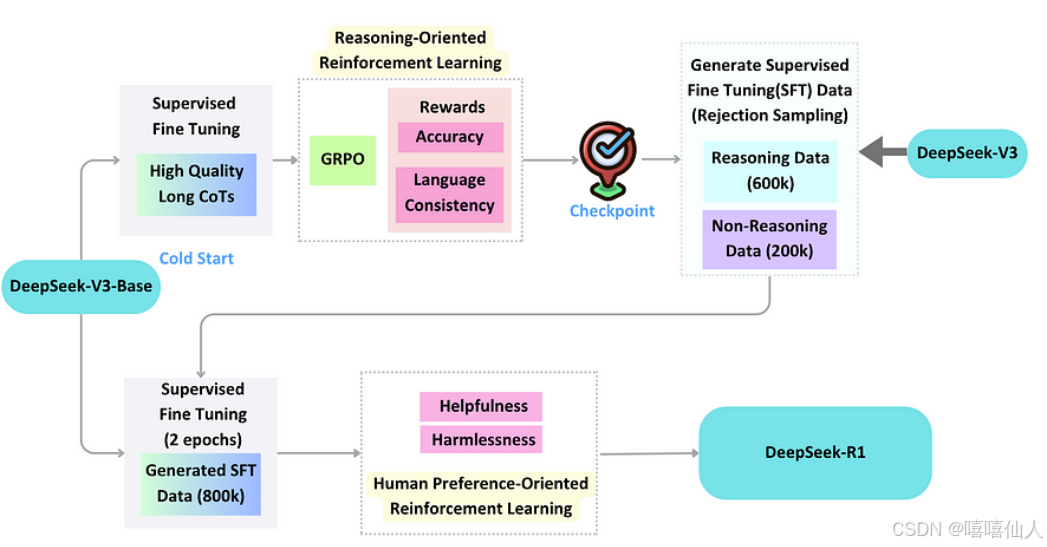
(ii)从DeepSeek-V3-Base到DeepSeek-R1–Zero
DeepSeek R1的核心架构是DeepSeek-V3-Base,这是一个庞大的混合专家 (MoE) 语言模型。

想象一下一个拥有数百万本书的图书馆。在像 ChatGPT 这样的传统密集模型中,每次提出问题时,模型都会“打开”图书馆中的每一本书来寻找答案。这种方法计算成本高昂且效率低下。
然而,DeepSeek-V3-Base 使用的是 MoE 架构。它不是访问所有书籍,而是依赖于针对不同主题定制的一组专门的“专家书籍”。这使得这个过程更快、更高效,更重要的是,更准确。
DeepSeek-V3-Base 拥有惊人的 6710 亿个参数,是现存最大的模型之一。对于处理的每个标记,都会激活 370 亿个参数,将焦点缩小到一小部分经过高度训练的专家,从而产生精确而快速的答案。该模型已在 14.8 万亿个高质量标记上进行了预训练,为深度推理和理解奠定了坚实的基础。
DeepSeek-R1–Zero 以 DeepSeek-V3-Base 为基础,使用 GRPO(广义强化策略优化)框架来改进推理。
(iii)从DeepSeek-V3-Base到DeepSeek-R1
DeepSeek – R1–Zero 的基础非常出色,但其性能并不完美。它难以清晰一致地呈现推理,尤其是在处理复杂的语言任务时。这促使 DeepSeek-R1–Zero 流水线进行了修订,从而催生了 DeepSeek-R1。
DeepSeek-R1 的开发始于使用高质量推理数据对 DeepSeek-V3-Base 进行冷启动。这些数据包括:
- 使用 CoT(思维链)示例的少量样本提示:这些示例指导模型逐步分解问题,鼓励结构化和逻辑推理。
- 使用明确指令的直接提示:该模型经过训练可以遵循任务的详细指令,确保一致性并符合用户期望。
- R1-Zero 的精炼输出:分析了 DeepSeek-R1-Zero 生成的预测,并且仅将最易读和最准确的示例包含在数据集中。
- 人工注释输出:专业的人工注释者审查并完善输出,以确保清晰度、连贯性并符合高质量标准。
通过利用这些精选的训练数据,DeepSeek-R1 能够解决 DeepSeek-R1–Zero 面临的可读性和语言一致性问题。
deepseek R1 是一种基于强化学习 (RL) 来处理复杂任务的推理优先模型。它有两个版本:
DeepSeek R1-Zero 和 DeepSeek R1。这些版本共享相同的架构,但训练方法不同。
(iv)DeepSeek R1推理能力
DeepSeek R1-零 完全使用 RL 进行训练,没有任何监督微调 (SFT)。这使得模型能够独立发展自我反思和验证等高阶推理功能。然而,R1-Zero 面临重复输出和可读性不一致等问题。
为了解决这些问题,DeepSeek R1 在 RL 之前加入了 SFT 阶段。这一步骤提高了模型的清晰度和准确性,使其成为推理任务的更可靠的选择。
(v)DeepSeek R1培训方法
R1 的训练过程着重于思想链 (CoT) 推理,这有助于模型将问题分解为更小、更易于管理的步骤。
CoT 方法使 R1 在数学、编码和逻辑推理等领域非常有效。
(4)DeepSeek V3
DeepSeek V3 使用 MoE 架构,每个令牌啟动 671B 参数中的 37B 参数。
这种选择性活化可确保模型高效运行,在推理过程中需要更少的资源。
V3 的训练过程旨在具有成本效益。采用混合精准度FP8训练,减少大规模预训练所需的GPU小时数。
(5)DeepSeek R1 和 DeepSeek V3 对比
DeepSeek R1 专注于使用强化学习的推理任务,而 DeepSeek V3 则专注于透过其 Mixture-of-Experts 架构进行可扩展且高效的自然语言处理。DeepSeek R1和V3都支援本地部署,并提供硬体和软件配置的详细说明。
(6)1.5b、7b、8b、14b、32b、70b和671b
DeepSeek-R1 的一个令人兴奋的功能是它能够将知识提炼成更小、更高效的模型。在提炼过程中,DeepSeek-R1 充当老师,为 Qwen 和 Llama 等较小的学生模型提供精心挑选的训练数据。这些模型虽然规模较小,但经过训练后,可以在编码和数学等任务中表现出色。
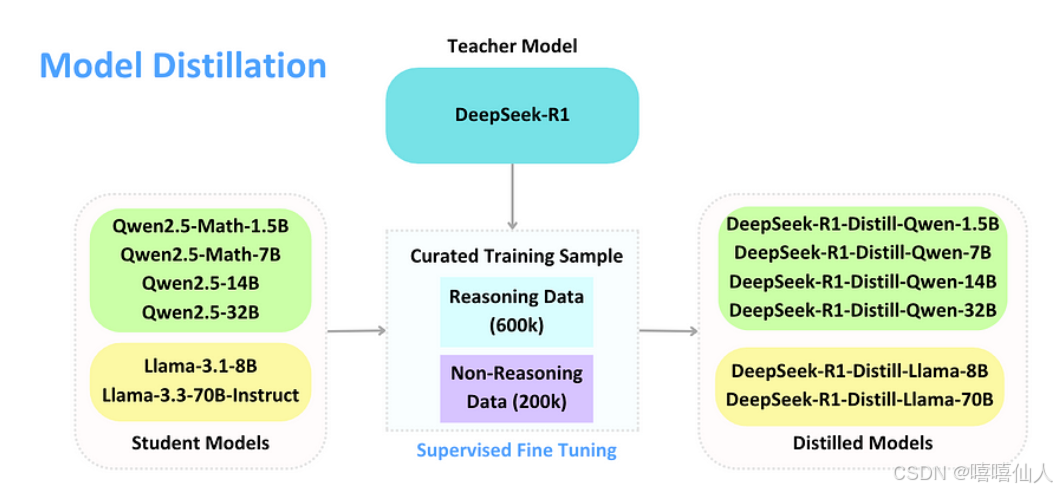
(i)参数规模与模型容量
-
1.5B-70B:这些版本是基于不同架构(如Qwen、Llama)的蒸馏模型。参数量从1.5B到70B不等,模型容量依次递增,能够学习和表示的知识也更丰富,适合处理复杂度不同的任务。
-
671B:这是DeepSeek-R1的基础大模型,参数量最大,模型容量极大,能够学习和记忆海量知识与信息,对复杂语言模式和语义关系的捕捉能力最强。
(ii)性能与准确性
-
1.5B-70B:随着参数量的增加,模型在各种任务中的准确性通常会有所提高。例如,70B模型在处理复杂逻辑推理问题和长文本上下文信息时,可能比1.5B模型表现得更出色。
-
671B:在各类任务上的准确性通常更高,尤其在数学推理、复杂逻辑问题解决、长文本理解与生成等方面,能更准确地给出答案和合理的解释。
(iii)训练与推理成本
-
1.5B-70B:训练成本相对较低,推理时对硬件要求也相对较低。例如,1.5B模型可以在较低配置的硬件上快速加载和运行。
-
671B:训练需要大量的计算资源和时间,推理时需要极高的硬件配置,显存需求超过336GB。
(iv)适用场景
-
1.5B-7B:适合对响应速度要求高、硬件资源有限的场景,如移动端的简单智能助手、轻量级的文本生成工具等。
-
8B-14B:可用于对模型性能有一定要求,但硬件条件有限的场景,如小型企业的日常文本处理、普通智能客服等。
-
32B-70B:适合对准确性有较高要求,硬件条件较好的场景,如专业领域的知识问答系统、中等规模的内容创作平台等。
-
671B:适用于对准确性和性能要求极高、对成本不敏感的场景,如大型科研机构进行前沿科学研究、大型企业进行复杂的商业决策分析等。
五、后言
经过提炼的模型 DeepSeek-Llama-70B 在各种基准测试中均胜过许多竞争对手,展示了较小模型实现高效率和顶级性能的强大能力。
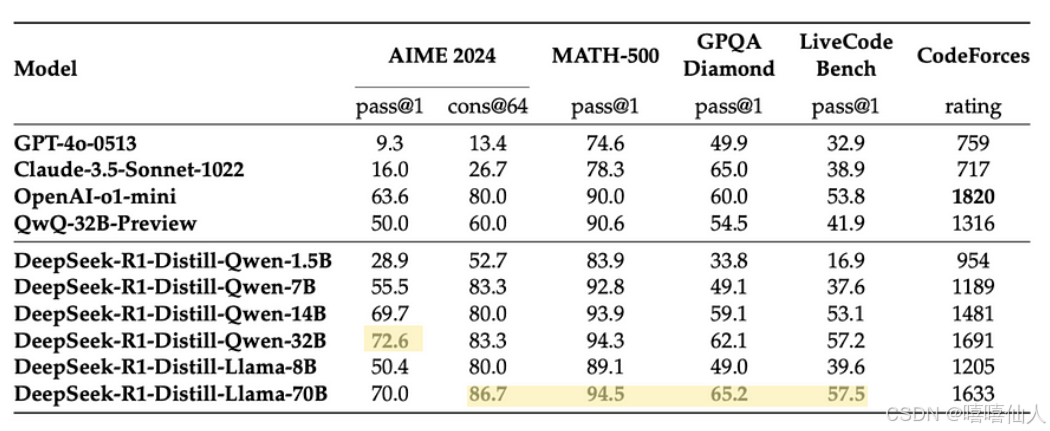
再回到最开始的问题,deepseek和ChatGPT到底哪个更屌,笔者认为这个问题有待商榷,因此可变性因素太多了,面对不同的任务不同的环境不同的场景,模型的表现均有差别,无法一概而论,但是不可否认的是deepseek此次横空出世代表着走向世界,取得了之前文心一言豆包等大模型没有取得的成就,这才是科技大爆炸百家争鸣应有的样子。
stay hungry,stay foolish才应该是我们的态度。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)