
我的AI知识库内容制作血泪史!Coze×Trace玩转爬虫数据,IP代理池爬虫高效爬取!
例如,市场求职经验分享、销售经验分享、国家文件分析、国际局势分析等,利用语言表达收集干货内容,上述项目是一个非常不错的选择。当前AI视频领域内容还不够完善,文本生成AI视频的幻灯片垃圾、毫无价值的抽象图生视频,都在冲击我们的信息获取渠道。所以在如今的AI时代,AI工具泛滥的前提下,获取到真实干货信息尤为重要,爬虫成为我们不可或缺的突破手段,好的代理平台也就成为了重中之重
我花了3周搭建的AI知识库里面竟是垃圾?看Coze×Trace救场实录!🔥🔥🔥
引言
"当98%的视频知识正在经历’数字蒸发’—— 我们监测到一场静默的信息屠杀:
职场前辈的升迁秘籍在收藏夹存活不超过72小时;
行业大牛的深度洞察有87%随视频下架永久消失;
创业者的踩坑实录,93%被算法埋进娱乐至死的流量坟场…
"我们正在经历知识载体的权力更迭——当文本世界仍在贩卖过期的认知货币,
光看文本很难区分是否存在大量的AI内容,但视频可以辨别
如今知识分享文章,充斥着大量AI废话垃圾
职场中的弯弯绕绕,在文章中无法道清

在我看来,视频是信息整合的产物,文章则是碎片化知识的补充。所以,我认为那些自己珍藏的宝藏up主,他们口头总结的实践经验分享,更能打破我们的信息茧房。而其中的口头表达内容,才更值得我们吸收与利用。相比之下,你用半小时读完的所谓“深度长文”,不过是AI把6个月前以及其他AI信息翻炒出的新型垃圾。想要了解真正的经验内幕,是相当困难的!
以上就是我此次项目的出发背景,不知大家是否能够产生共鸣?
项目开始
所以我们既需要将选择视频出来的分享内容得到转换,又需要将转换的内容很好的利用整合
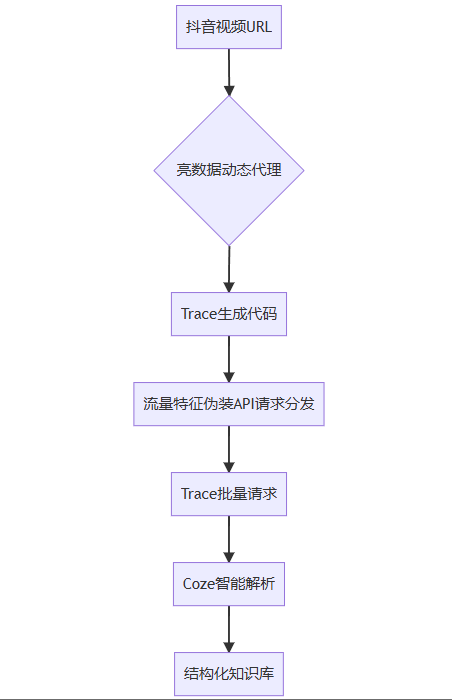
痛点-方案映射表——项目亮点
| 用户认知困境 | 技术解决方案 | 认知收益 |
|---|---|---|
| 关注即遗忘 | IP池爬虫自动化存档 | 将自己经常看到的宝藏博主视频爬取下来 |
| 信息转换 | Coze将视频url转文本 | 提取视频中的口语化内容 |
| 编程无经验 | Trace完成开发所需 | 可批量转换干货口语化内容 |
| 碎片化知识利用 | 构建自己的AI知识库 | 突破认知盲区,补充垂直有效的知识库干货内容 |
其实我们首先要做的,就是要获取到内容的来源,首先当然要选择博主,进行批量爬取

项目实现
爬取视频博主主页链接
我们打开Trace工具输入指令生成代码:
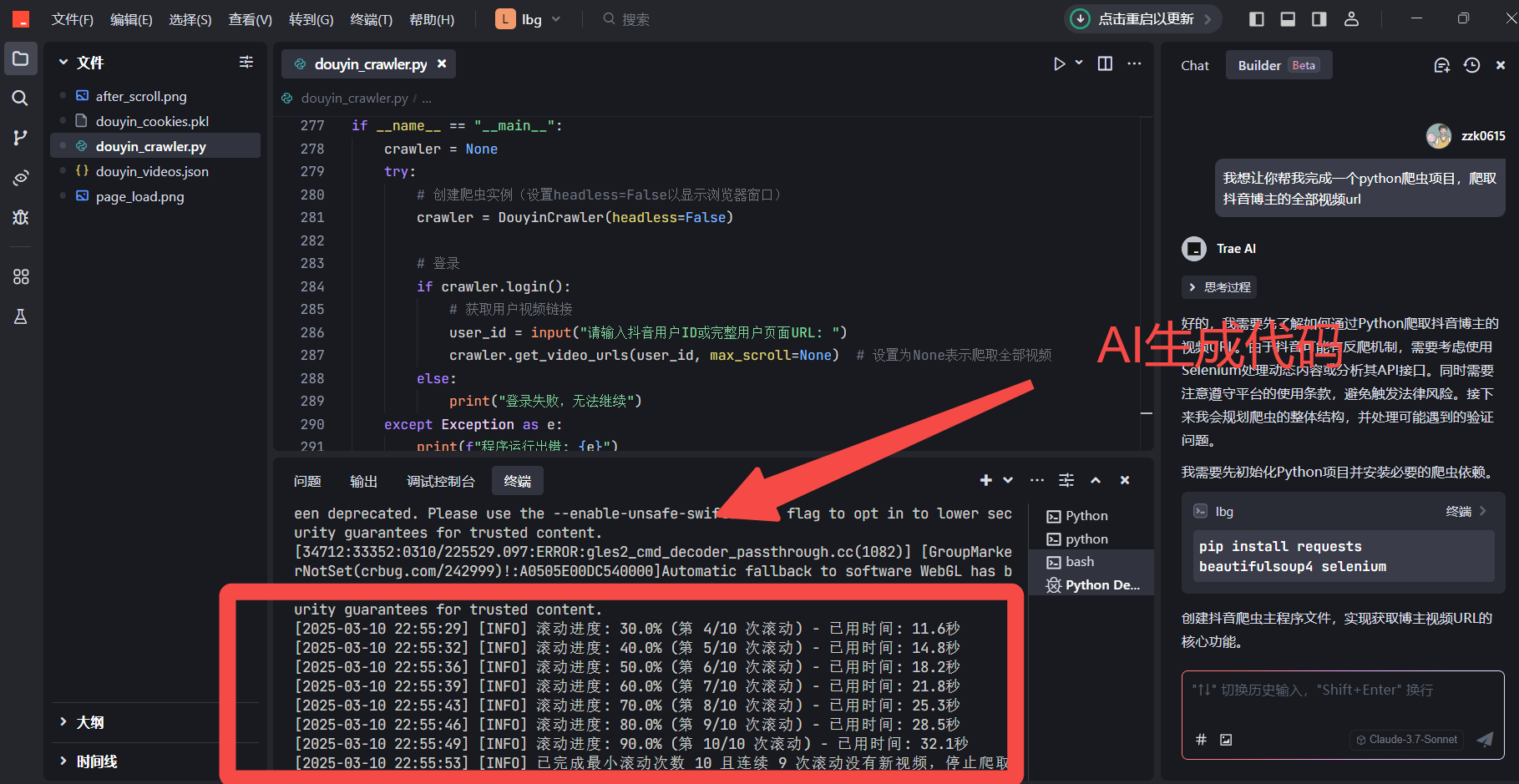
但是我们可以很直观的看到,生成速度缓慢,并且常伴有视频转换不全并且有概率封号的情况,我们可以通过动态代理去避免这个事故,我们这里可以使用动态代理平台


接入方案——伪代码

# 动态代理配置
proxy_auth = "brd-customer-hl_c8247457-zone-residential_proxy1:c06sidmd55z5"
proxy_port = 33335
proxy_url = f"http://{proxy_auth}@brd.superproxy.io:{proxy_port}"
# 视频API特征参数
common_params = {
"device_platform": "webapp",
"aid": "6383",
"channel": "channel_pc_web",
"cookie_enabled": "true"
}
def get_douyin_url(video_id):
# 动态请求头构造
headers = {
"User-Agent": f"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/{random.randint(90,115)}.0.0.0 Safari/537.36",
"Referer": "https://www.douyin.com/",
"X-Requested-With": "XMLHttpRequest"
}
# 代理配置
proxy_handler = urllib.request.ProxyHandler({
'http': proxy_url,
'https': proxy_url
})
# 构造请求
opener = urllib.request.build_opener(proxy_handler)
urllib.request.install_opener(opener)
# 目标API地址
api_url = f"https://www.douyin.com/aweme/v1/web/aweme/detail/?aweme_id={video_id}&{urllib.parse.urlencode(common_params)}"
try:
req = urllib.request.Request(api_url, headers=headers)
with urllib.request.urlopen(req, timeout=10) as response:
if response.status == 200:
return response.read().decode('utf-8')
else:
print(f"请求失败,状态码:{response.status}")
return None
except Exception as e:
print(f"发生异常:{str(e)}")
return None
# 使用示例
if __name__ == "__main__":
video_id = "7341506063904820517" # 替换目标视频ID
result = get_douyin_url(video_id)
print(result)
time.sleep(random.uniform(2,5)) # 控制请求间隔
再接入动态代理之后,不断优化前端界面,我们可以看到抓取的数量,以及速度大大提高

并且我们还可以看到我们的使用情况

拿到之后,我们本地打开文件,可以看到拿到了主页的全部url

url转换接口
我们可以使用coze平台搭建出这样的工作流,并且进行发布
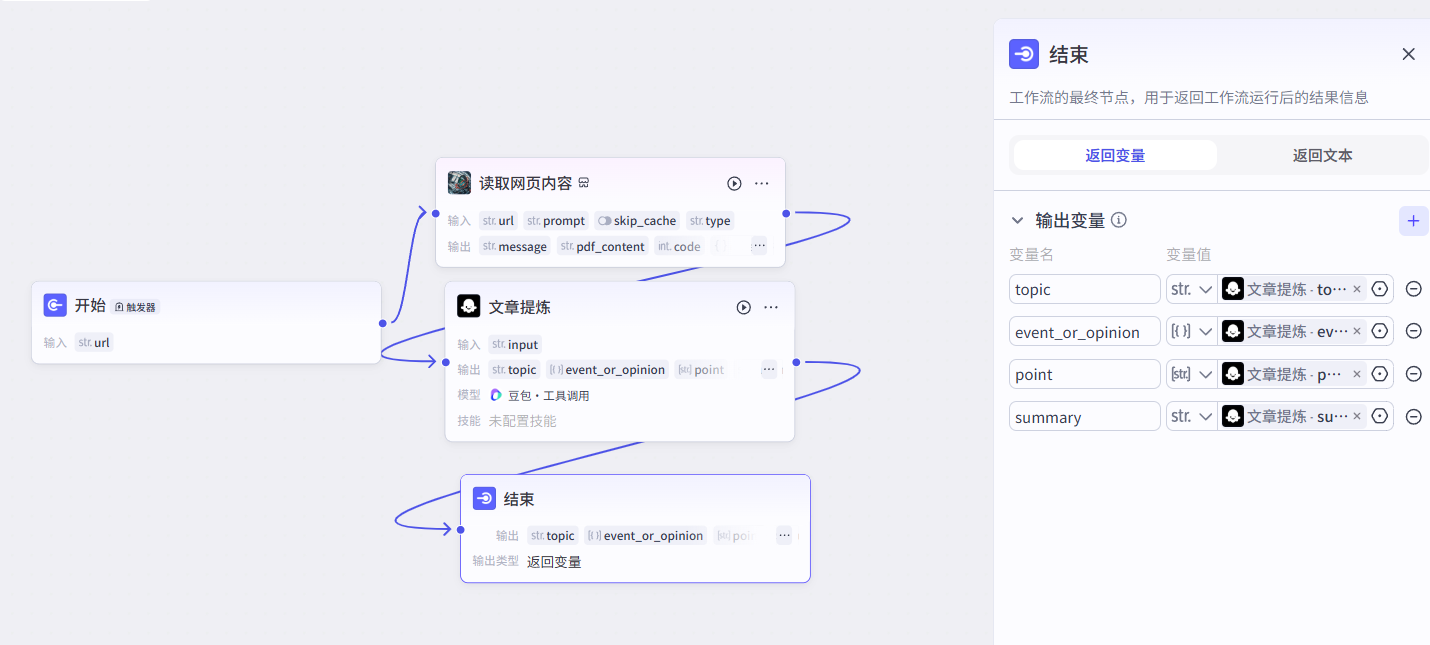
可以调试一下接口
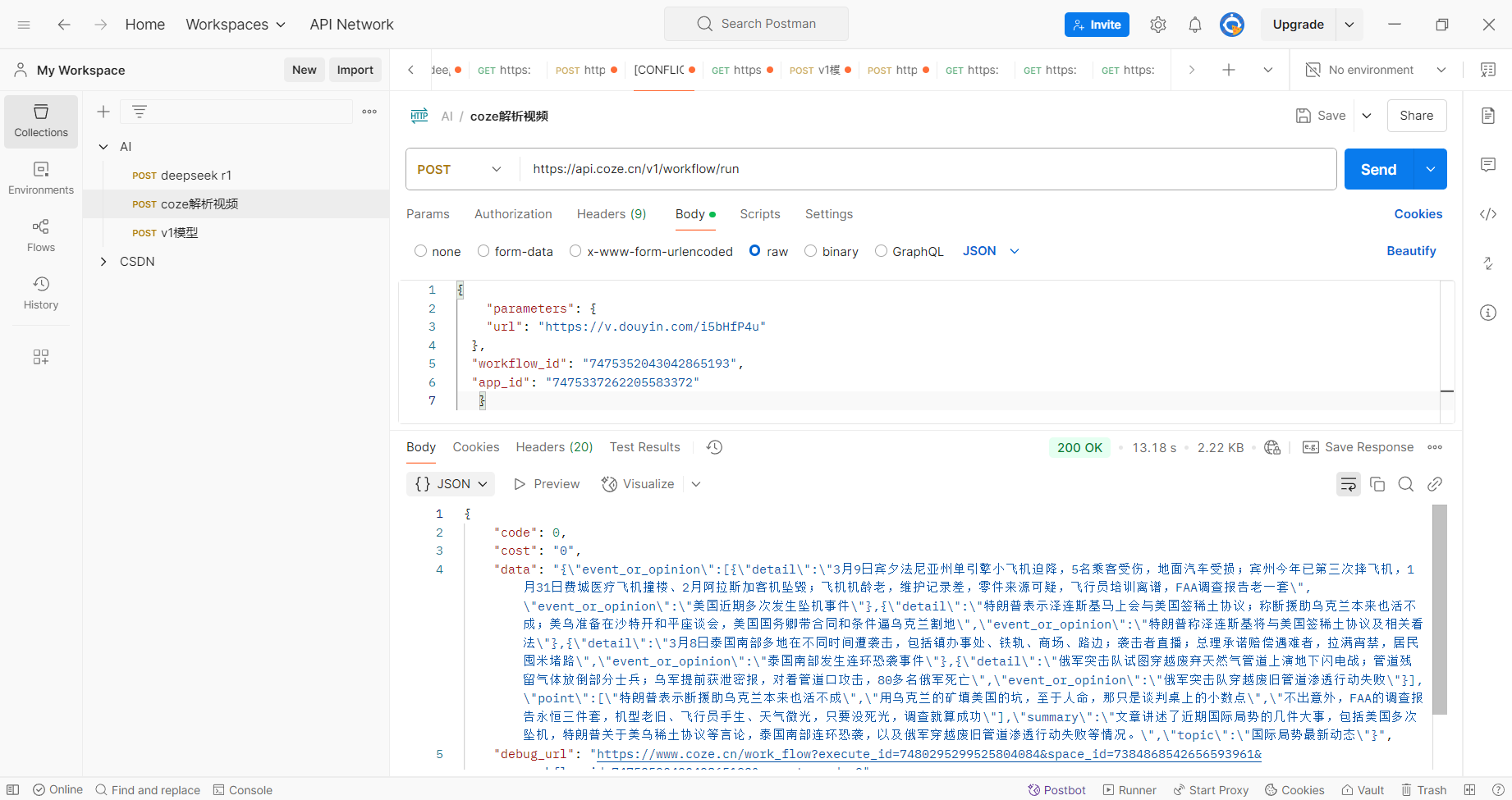
批量请求接口
我们把curl交给trace,让这个excel的链接批量请求这个接口,并把结果写入该目录下新建的excel中

最终成功写入文件中
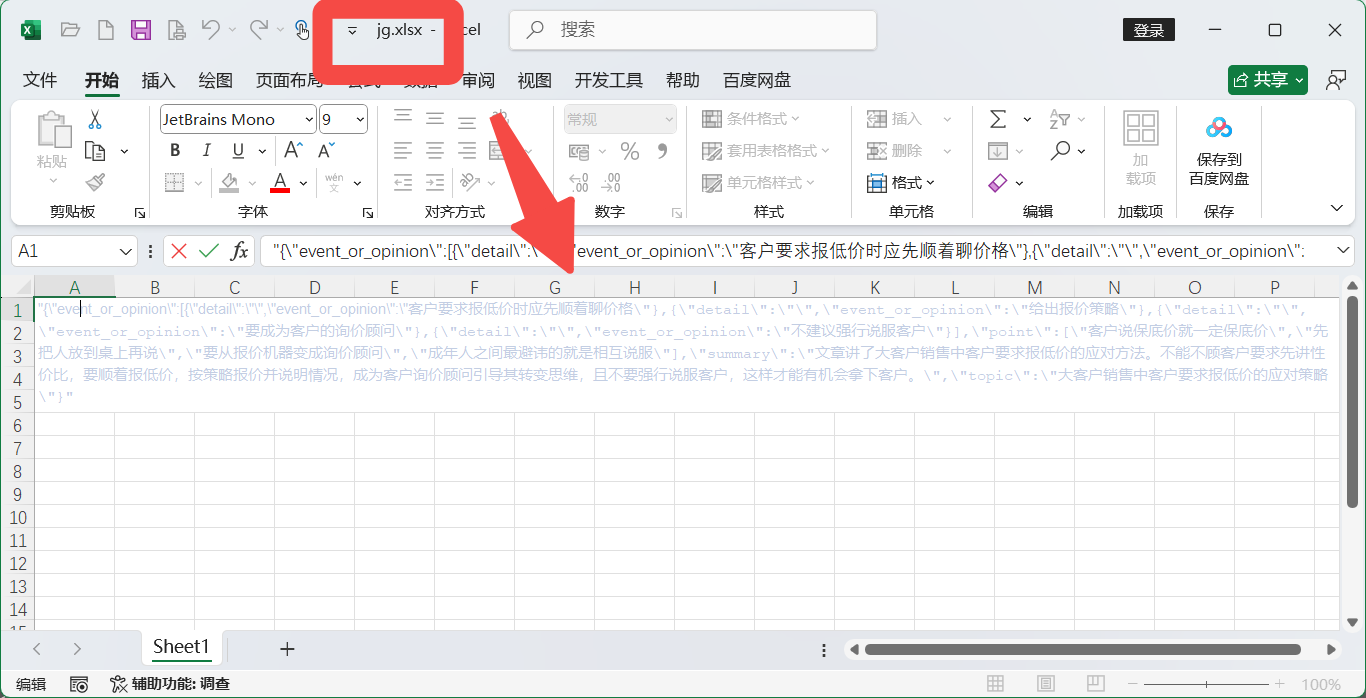
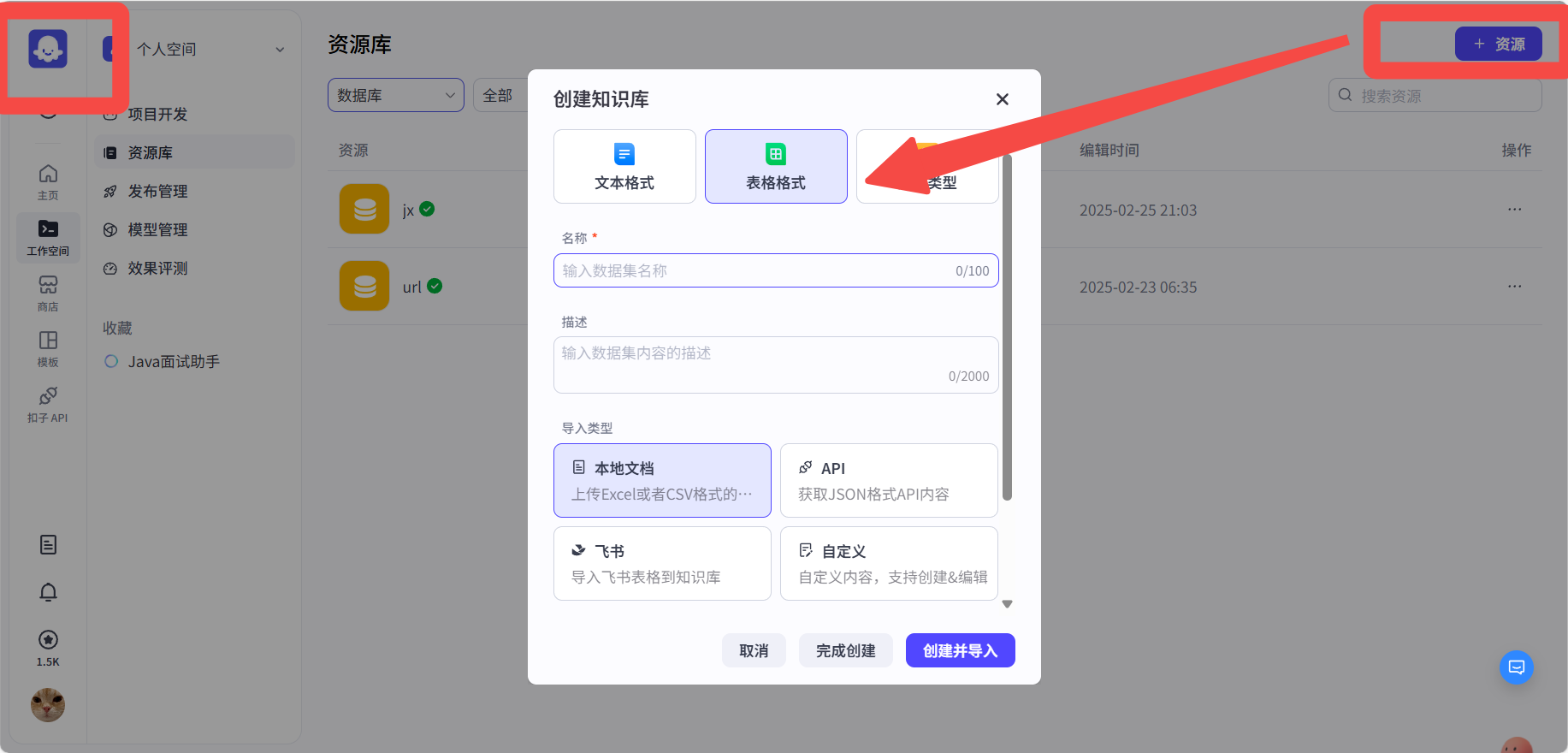
知识库构建
打开扣子的工作空间,新建知识库
导入我们的文档之后,我们可以来看一下效果
效果展示
我们可以看到当我们输入相同问题之后的不同回答对比。成功召回知识库,将视频中的干货内容,直接返回,成功将自身短视频的零碎的关键知识用AI进行整合,清洗了知识库的质量以及提升AI回答效果
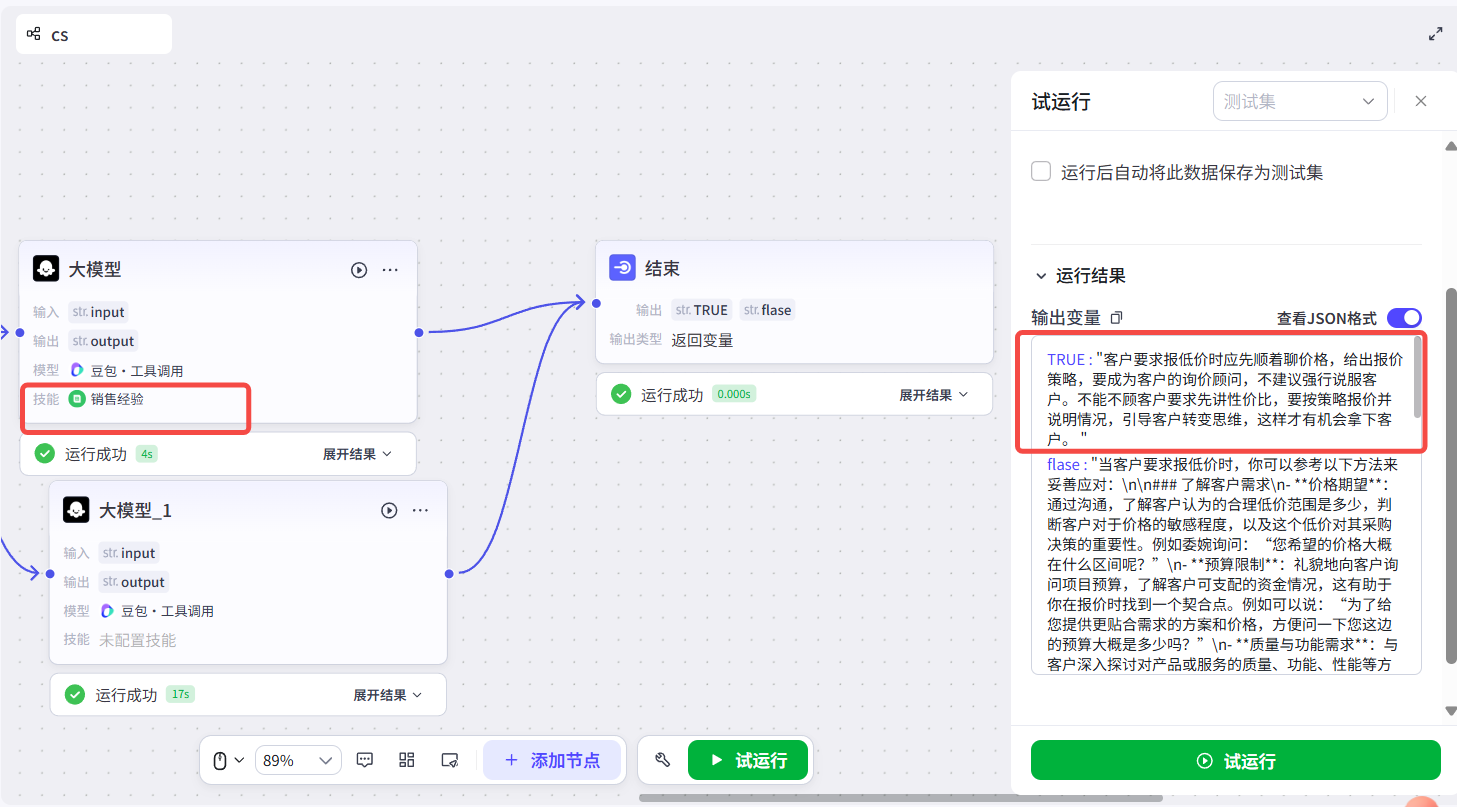
项目评估:
全链路解决方案
- 从动态代理爬虫→视频转文本→知识库构建→智能问答形成完整闭环,解决"信息蒸发"痛点
对抗AI文本内容泛滥
- 通过视频源筛选+口语特征提取,有效过滤AI生成文本的"伪干货"
在我看来,视频是信息整合的产物,文章则是碎片化知识的补充。所以,我认为那些自己珍藏的宝藏up主,他们口头总结的实践经验分享,更能打破我们的信息茧房。而其中的口头表达内容,才更值得我们吸收与利用。
例如,市场求职经验分享、销售经验分享、国家文件分析、国际局势分析等,利用语言表达收集干货内容,上述项目是一个非常不错的选择。当前AI视频领域内容还不够完善,文本生成AI视频的幻灯片垃圾、毫无价值的抽象图生视频,都在冲击我们的信息获取渠道。
所以在如今的AI时代,AI工具泛滥的前提下,获取到真实干货信息尤为重要,爬虫成为我们不可或缺的突破手段,好的代理平台也就成为了重中之重。
本文案例中使用的动态住宅代理正在限时5折!
企业级用户特别推荐
文中演示的智能爬虫平台同步开启开发者狂欢季:
现成爬虫工具
除上述的代理使用方式之外,现成的爬虫工具,平台能抓取众多类型的热门网站,还可为企业客户需求定制开发。

例如,谷歌新闻,获取第一时间国际资讯,就是一个非常不错的选择
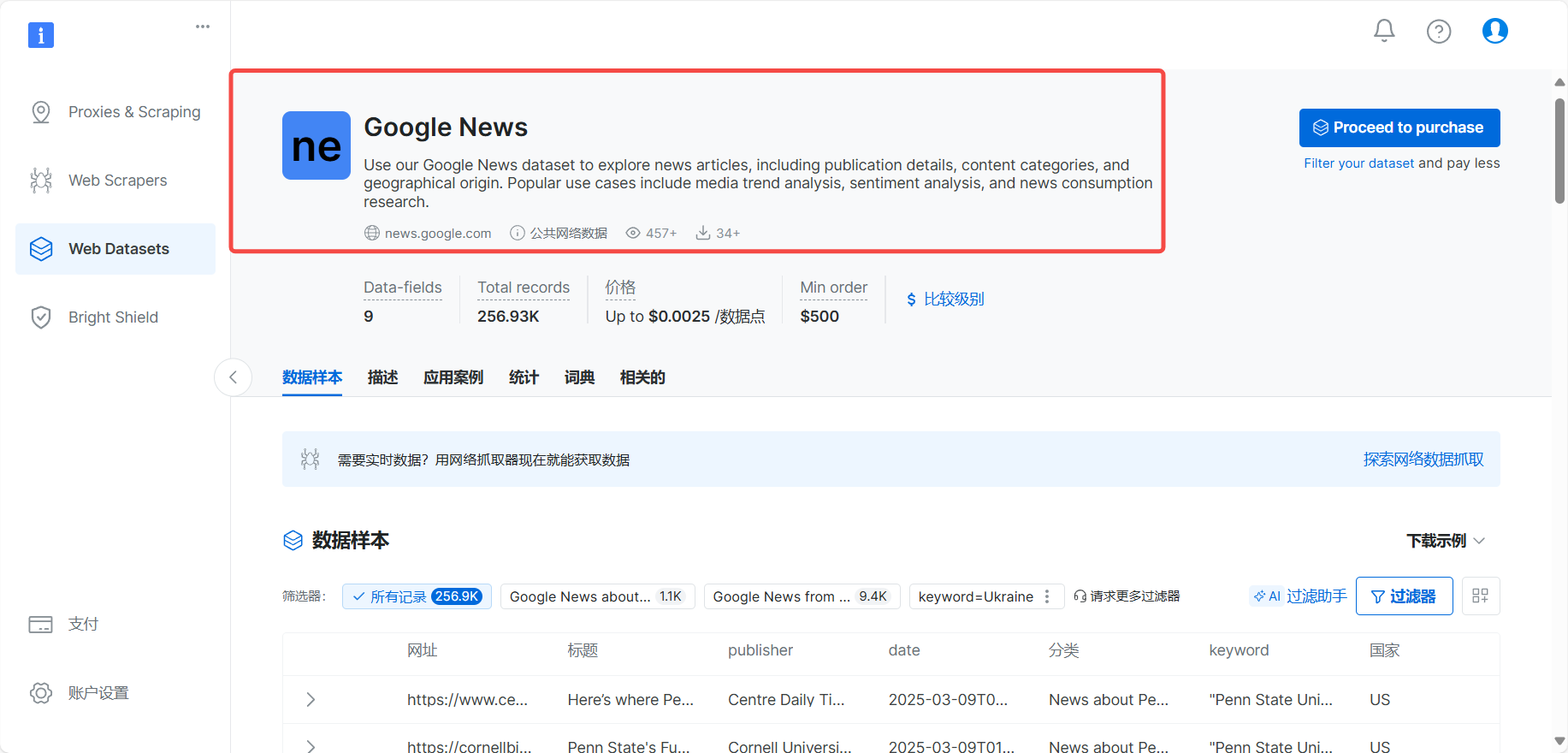
我们可以看到它下方提供了数据样本,以及字段的词典
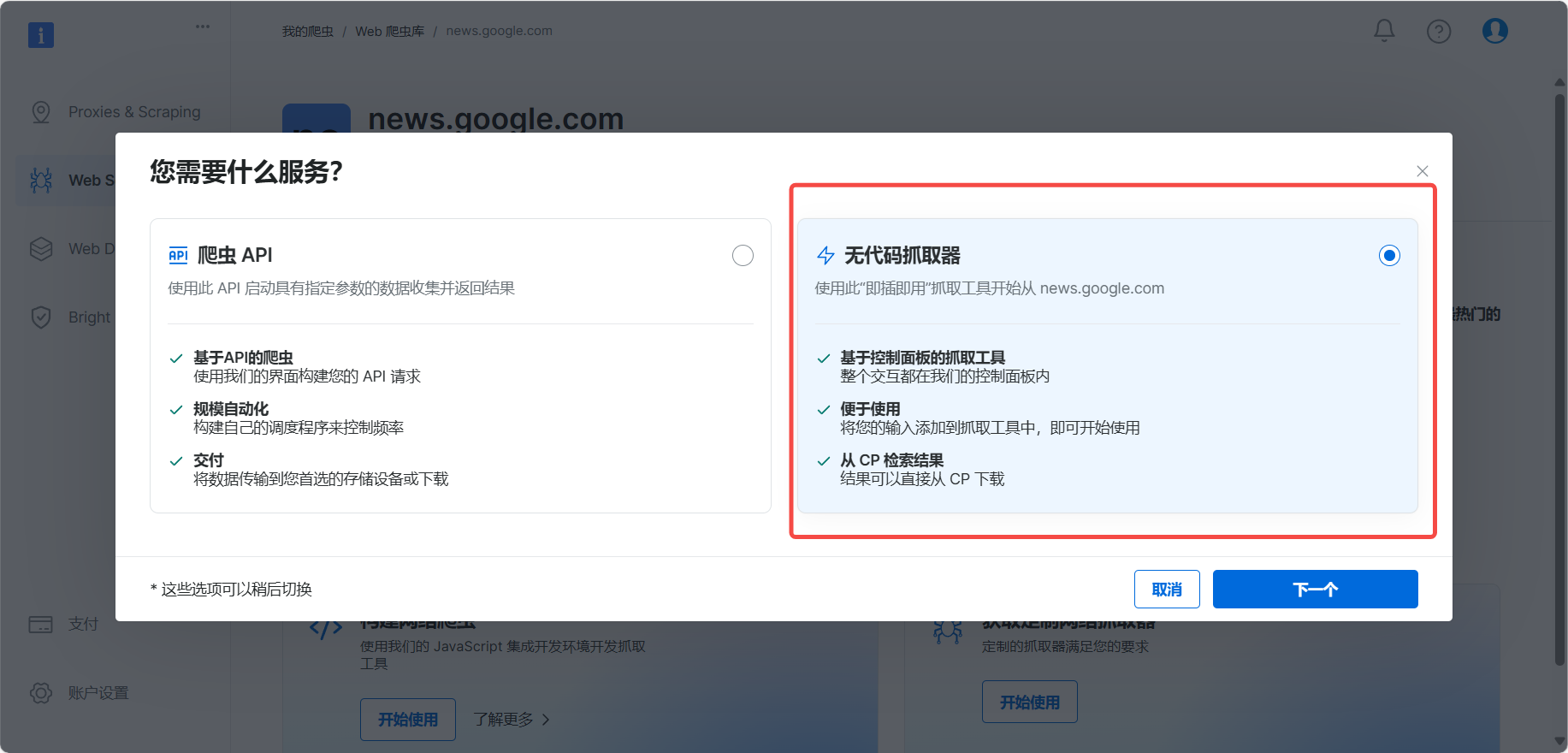
这里去设置关键字,定向地爬虫

不仅如此,它提供了API构建器让我们更方便的调用,不仅有网址和关键字,还有存储的位置返回效果等
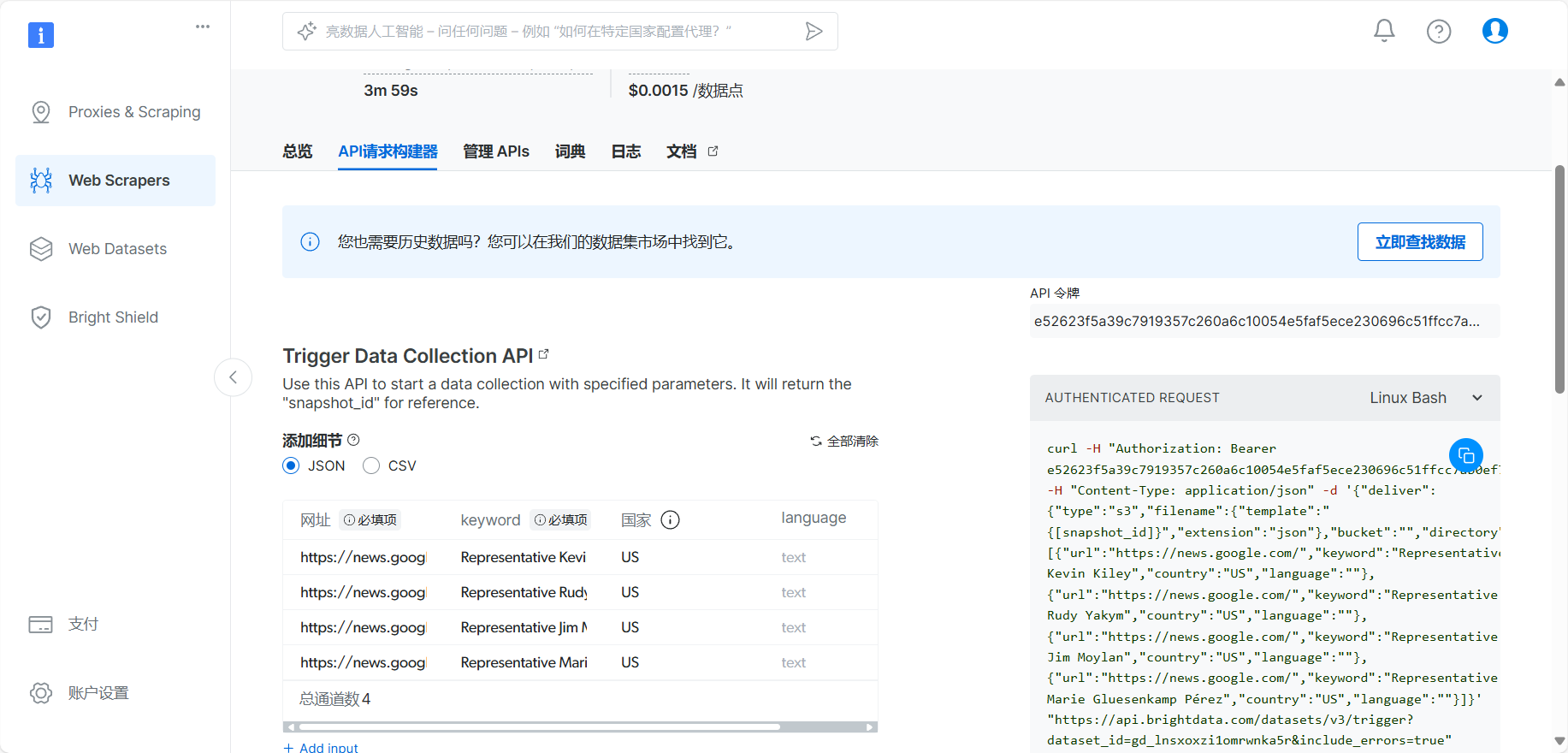
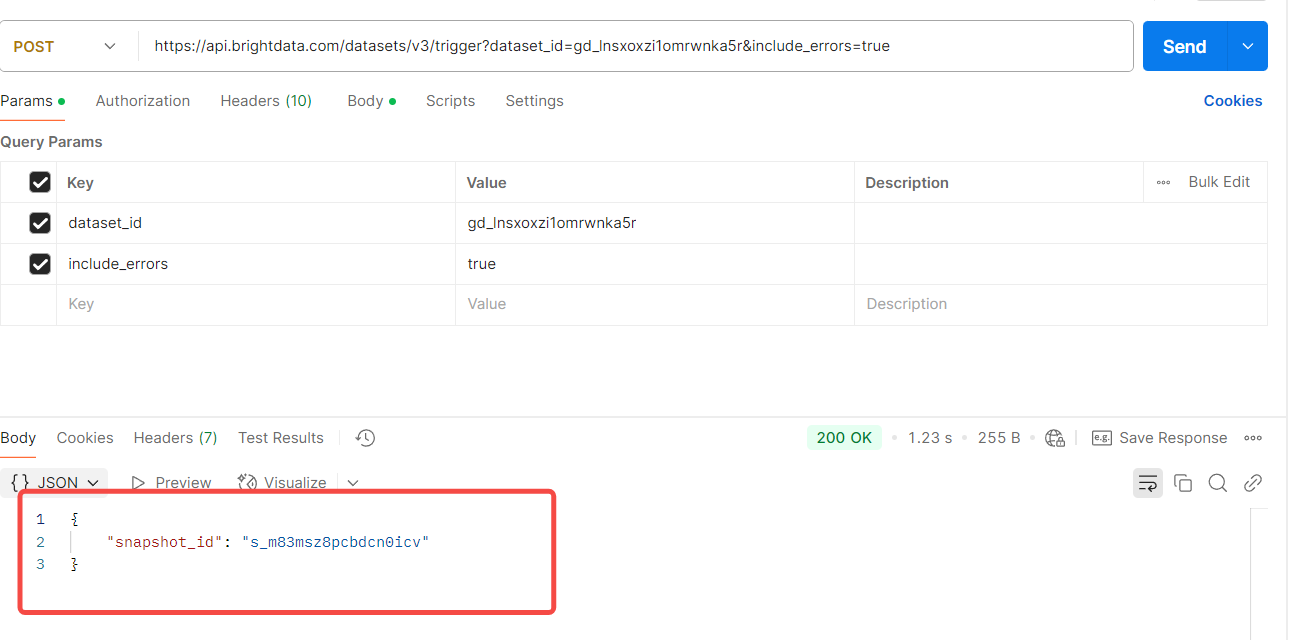
我们尝试请求它
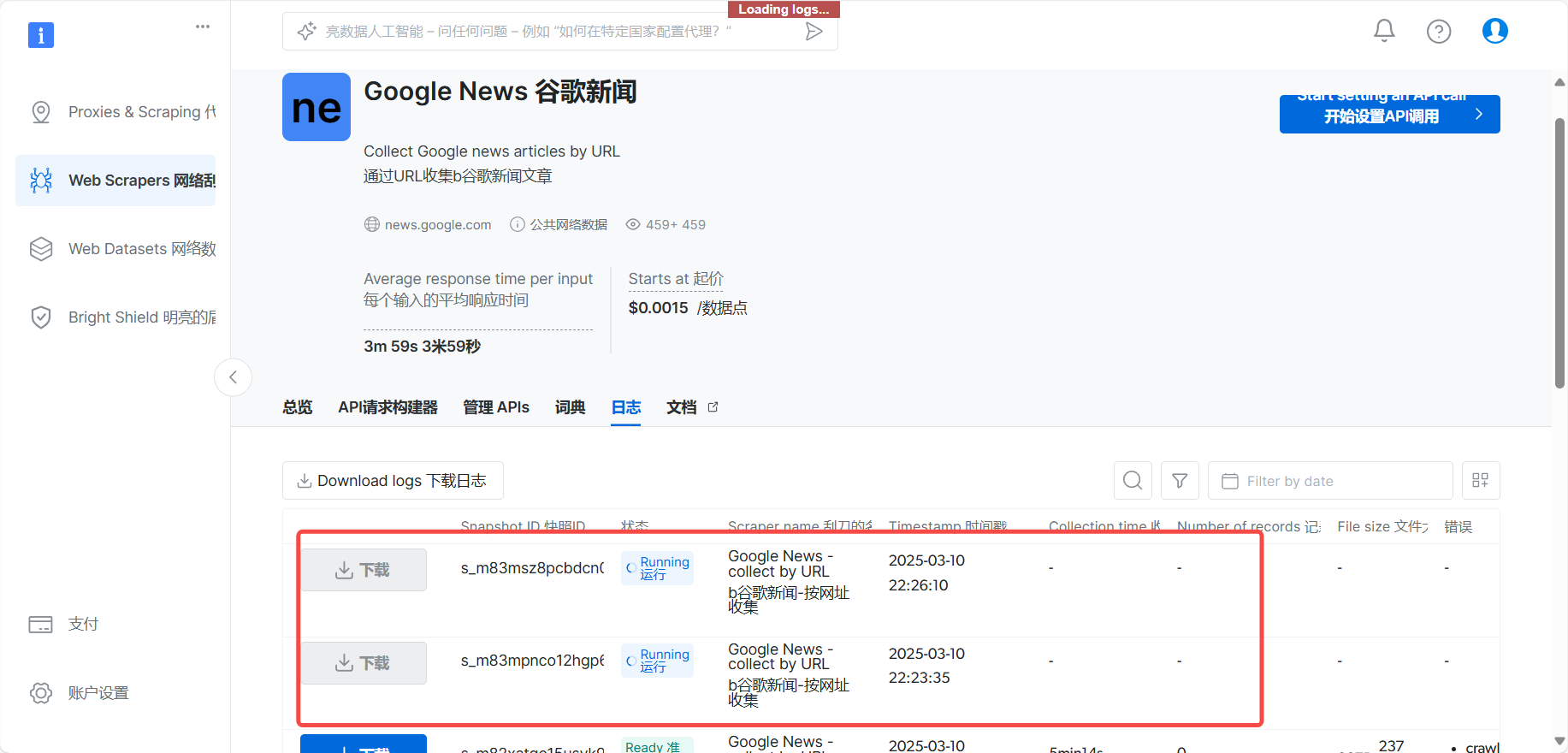
我们再看一下日志,看一下爬取状态
商业应用场景与价值
通过平台爬取谷歌新闻中关于拜登的新闻:
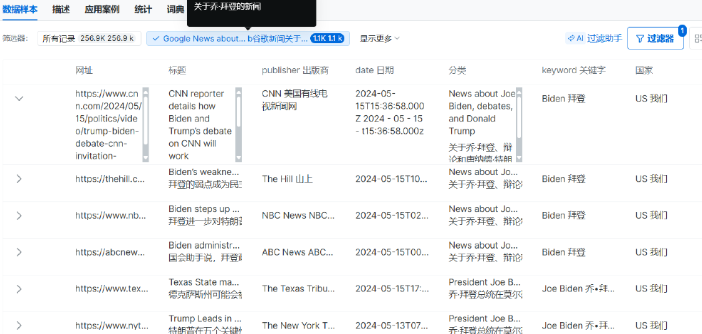
可以进行:
舆情监测与政策影响评估 分析拜登政策的媒体报道频率与情绪倾向,为政府机构或游说团体提供实时舆情报告。例如:
- 情绪分析:通过BERT等模型量化报道中的正面/中性/负面情感比例。
- 议题框架识别:聚类高频词汇(如“通胀”“外交政策”),追踪媒体对特定政策的聚焦程度。
媒体偏见研究 对比不同立场媒体的报道差异。例如:
- 保守派与自由派媒体:统计福克斯新闻与CNN对拜登经济政策的用词差异。
- 地域性偏差:分析美国本土媒体与国际媒体在乌克兰危机报道中对拜登角色的刻画差异。
政治竞选策略优化 为竞选团队提供数据支持,例如:
- 热点议题挖掘:识别媒体报道中未被充分回应的公众关切(如医疗改革或移民政策)。
- 竞争对手对比:通过对比特朗普与拜登的媒体曝光量,调整竞选广告投放策略
赋能计划
⚡️此刻启程,抢占数据主权⚡️
━━━━━━━━━━━━━━━━━━━━
立即访问官网,用专业工具开启您的数据资产沉淀之路。商业决策的底层逻辑正在改变——当别人还在垃圾信息中淘金时,您已手握真金白银的数据金矿。
当信息战进入算力时代,数据采集质量直接决定商业洞察的精准度

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 53
53 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)