使用 dify + vllm 创建一个AI应用
本文基于 dify 和 vllm 部署的本地大模型,创建了一个修复python代码的 LLM 应用
·
本文基于 dify 和 vllm 部署的本地大模型,创建了一个修复python代码的 LLM 应用
1. 安装启动
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
sudo docker compose up -d
在浏览器中输入 http://localhost/install 就可以开始初始化了
2. 注册管理员
随便注册一个管理员账号,进行登陆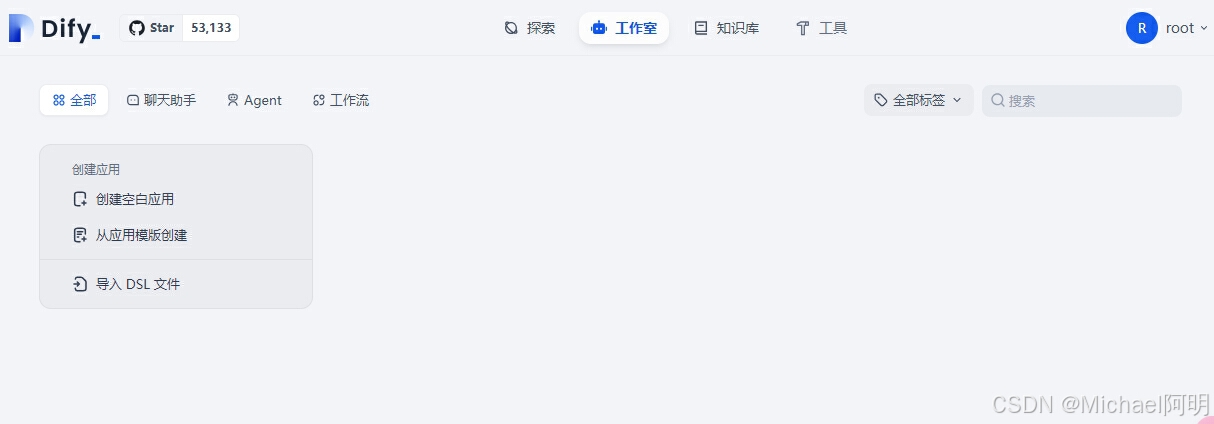
3. 创建应用
可以创建空白应用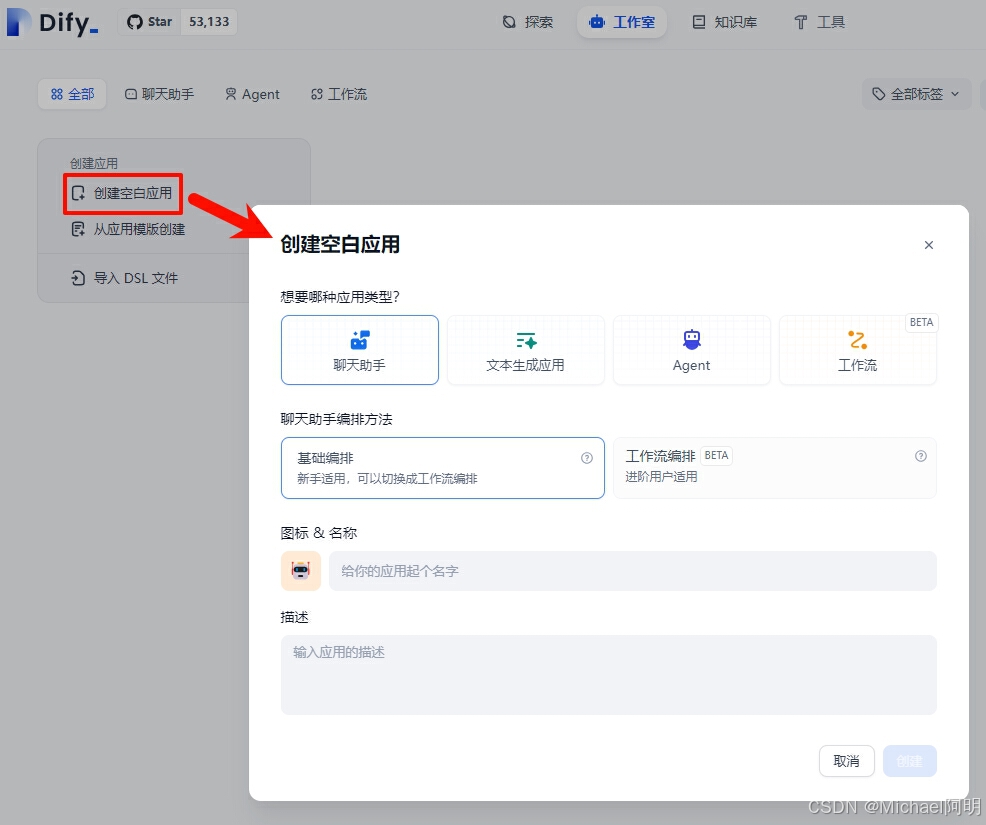
也可以从模板创建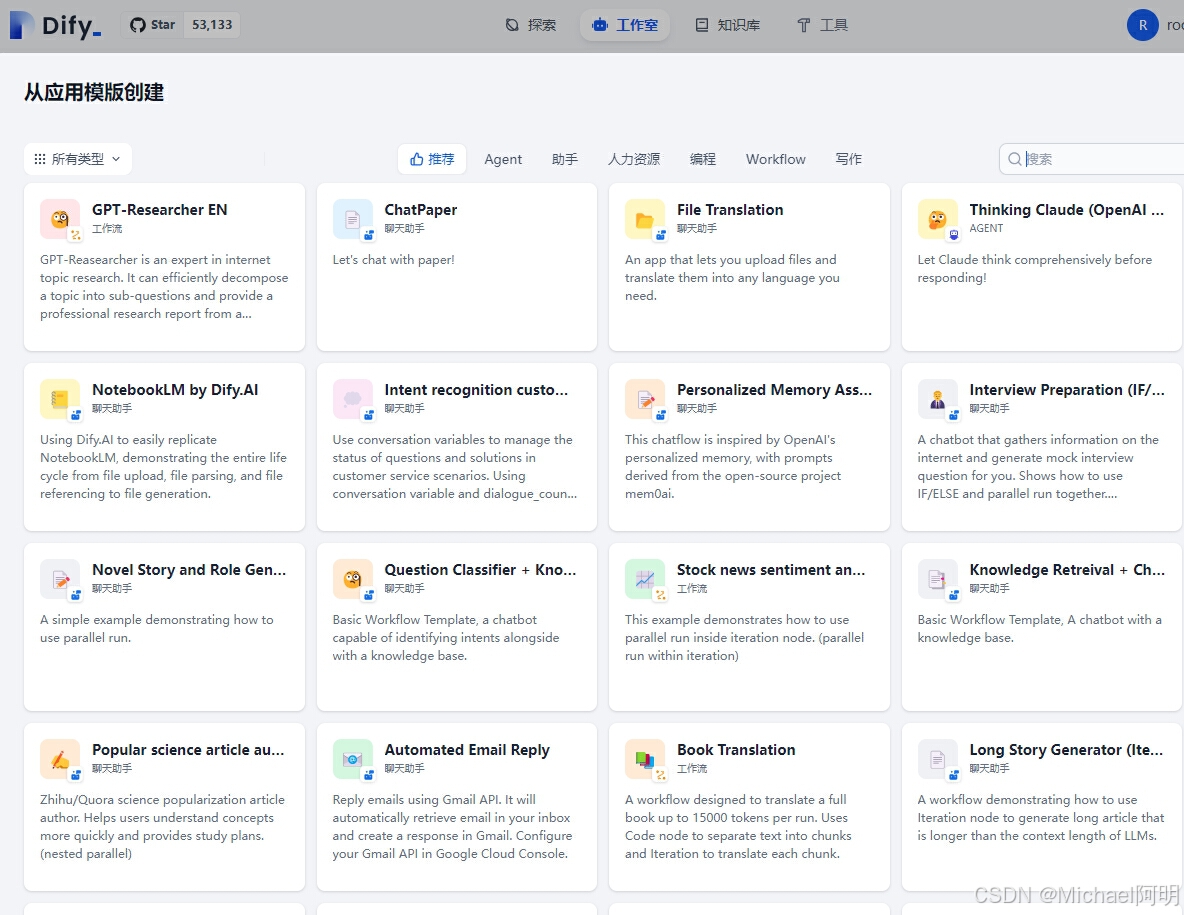
我们用模板创建一个 Python bug fixer 应用
4. 设置模型
- 可以设置商用的 api key
- 这里我们尝试使用 vllm 部署的本地大模型

5. 模型调试
选择模型进行测试
我把以下快速排序的代码(正确的),我给他改成错误的(见注释)
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2] # 改成 /
left = [x for x in arr if x < pivot] # 改成 <=
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot] # # 改成 >=
return quick_sort(left) + middle + quick_sort(right)
# 示例数组
example_array = [3, 6, 8, 10, 1, 2, 1]
# 对示例数组进行快速排序
sorted_array = quick_sort(example_array)
我的提示词:
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) / 2]
left = [x for x in arr if x <= pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x >= pivot]
return quick_sort(left) + middle + quick_sort(right)
示例数组
example_array = [3, 6, 8, 10, 1, 2, 1]
对示例数组进行快速排序
sorted_array = quick_sort(example_array)
Michael阿明写的代码有错误,请你修正代码,并用中文回答我错在哪里?

可以看到模型正在流式输出
6. 发布上线
在探索页面可以使用了
随着问答的进行,显存在逐步上升 11721MiB / 15360MiB
7. 创建API
创建 api key
使用代码进行调用
import requests
url = 'http://localhost/v1/chat-messages'
headers = {
'Authorization': 'Bearer app-dx09azp***',
'Content-Type': 'application/json',
}
query = f'''
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) / 2]
left = [x for x in arr if x <= pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x >= pivot]
return quick_sort(left) + middle + quick_sort(right)
示例数组
example_array = [3, 6, 8, 10, 1, 2, 1]
对示例数组进行快速排序
sorted_array = quick_sort(example_array)
Michael阿明写的代码有错误,请你修正代码,并用中文回答我错在哪里?
'''
data = {
"inputs": {},
"query": query,
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123"
}
response = requests.post(url, headers=headers, json=data)
# 打印返回结果
print(response.status_code) # 200
解析返回的响应
def parse_streaming_response(response):
"""
解析流式 response,提取输出文本块并拼接为完整字符串。
"""
complete_text = [] # 用于存储拼接的文本块
for line in response.iter_lines(decode_unicode=True):
# 跳过空行
if not line.strip():
continue
# 检查是否是一个有效的流式块
if line.startswith("data: "):
# 去掉前缀 "data: " 并尝试解析为 JSON
data = line[6:]
try:
event_data = json.loads(data) # 使用 json.loads 解析 JSON 数据
event = event_data.get("event", "")
if event == "message":
# 提取并累积文本块
complete_text.append(event_data.get("answer", ""))
elif event == "error":
# 如果有错误,打印错误信息
print(f"Error: {event_data.get('message', 'Unknown error')}")
break
elif event == "message_end":
# 在流结束时打印完整文本
print("Complete Text:", ''.join(complete_text))
break
except json.JSONDecodeError as e:
print(f"Failed to parse data: {data}, Error: {e}")
else:
print(f"Unrecognized line: {line}")
if response.status_code == 200:
parse_streaming_response(response)
else:
print(f"Request failed with status code: {response.status_code}, {response.text}")
输出:
>>> parse_streaming_response(response)
Complete Text: Michael阿明的代码存在几个问题。首先,`len(arr) / 2` 这一行会导致运行时错误,因为 Python 正整数除法会向零进行整数向下取整。其次,使用列表推导式时,`x <= pivot` 和 `x == pivot` 会被解释为 `x` 的与操作,而不是比较操作。最后,`+` 操作符用于拼接列表时,需要确保列表元素是可哈希的,以便进行自动索引。
以下是修正后的代码:
`` `python
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
example_array = [3, 6, 8, 10, 1, 2, 1]
sorted_array = quick_sort(example_array)
`` `
修正后的代码解决了这些问题:
1. 使用 `len(arr) // 2` 以避免整数向下取整的问题。
2. 修改列表推导式中的比较操作,使其正确地比较 `x` 的值而非与操作。
3. 保持 `+` 操作符用于拼接列表时的兼容性,确保列表元素是可哈希的。
使用这个修正后的代码,可以正确地对示例数组进行快速排序。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)