经典文献阅读之--GSPR(基于3D高斯点云的多模态地点识别在自动驾驶中的应用)
地点识别的任务是通过。在自动驾驶系统中,。然而,由于光照、季节和天气的变化,特别是在大规模的室外环境中,。相比之下,。然而,LPR的识别性能仍然受到激光雷达点云自然稀疏性以及缺乏纹理和语义信息的限制。大多数,导致未能充分利用。因此,如何有效地将多模态传感器数据融合为统一的场景表示,并充分提取多模态的时空相关性,仍是一个值得进一步研究的话题。3D-GS方法通过3D高斯建模构建了显式的场景表示,能够快
0. 简介
地点识别的任务是通过修正SLAM算法中的累计漂移来提供全球定位信息。在自动驾驶系统中,摄像头常用于基于视觉的地点识别(VPR),提供丰富的语义和纹理信息。然而,由于光照、季节和天气的变化,特别是在大规模的室外环境中,从摄像头图像中提取的视觉特征往往不够稳定,导致识别精度较低。相比之下,激光雷达传感器在这些因素下表现出更高的稳定性,因此在大规模室外场景中,基于激光雷达的地点识别(LPR)更为稳健。然而,LPR的识别性能仍然受到激光雷达点云自然稀疏性以及缺乏纹理和语义信息的限制。
大多数多模态地点识别(MPR)方法从场景的原始表示(例如原始图像和点云)中独立提取特征,并执行不可解释的特征级融合,导致未能充分利用不同模态之间的时空相关性。因此,如何有效地将多模态传感器数据融合为统一的场景表示,并充分提取多模态的时空相关性,仍是一个值得进一步研究的话题。3D-GS方法通过3D高斯建模构建了显式的场景表示,能够快速渲染新视角,同时有效捕捉精确的几何信息。通过聚合多个视角的连续观测,3D-GS全面构建了空间结构表示,为多模态地点识别的时空融合提供了可能。本文《GSPR: Multimodal Place Recognition Using 3D Gaussian Splatting for Autonomous Driving》目前相关的项目已经在Github上发布了。
1. 主要贡献
在本文中,我们提出了一种基于3D高斯点云的多模态地点识别方法,称为GSPR,如图1所示。我们首先设计了一种多模态高斯点云(MGS)方法,以表示自动驾驶场景。我们利用激光雷达点云作为高斯初始化的先验,这有助于解决在此类环境中结构光束(SfM)失败的问题。此外,我们采用了一种混合掩蔽机制,以去除对地点识别价值较低的不稳定特征。通过这种方式,我们将多模态数据融合为一个时空统一的高斯场景表示。接着,我们通过体素划分将每个场景中的无序高斯点下采样为一组体素,并开发了一个基于3D图卷积和变换器的网络,以提取高层次的时空特征,从而生成用于地点识别的区分性描述符。通过所提出的多模态高斯点云方法,我们将多模态数据融合为一个统一的显式场景表示,为多模态地点识别的时空融合奠定了基础。总之,我们的主要贡献如下:
• 我们提出了多模态高斯点云方法,将多视角相机和激光雷达数据协调为一个时空统一的显式场景表示。
• 我们提出了GSPR,这是一种新颖的多模态地点识别网络,配备了3D图卷积和变换器,以聚合MGS场景表示中固有的高层次局部和全局时空信息。
• 大量实验结果表明,我们的方法在地点识别性能上优于最先进的单模态和多模态方法,同时在未见过的驾驶场景中展现出良好的泛化能力。
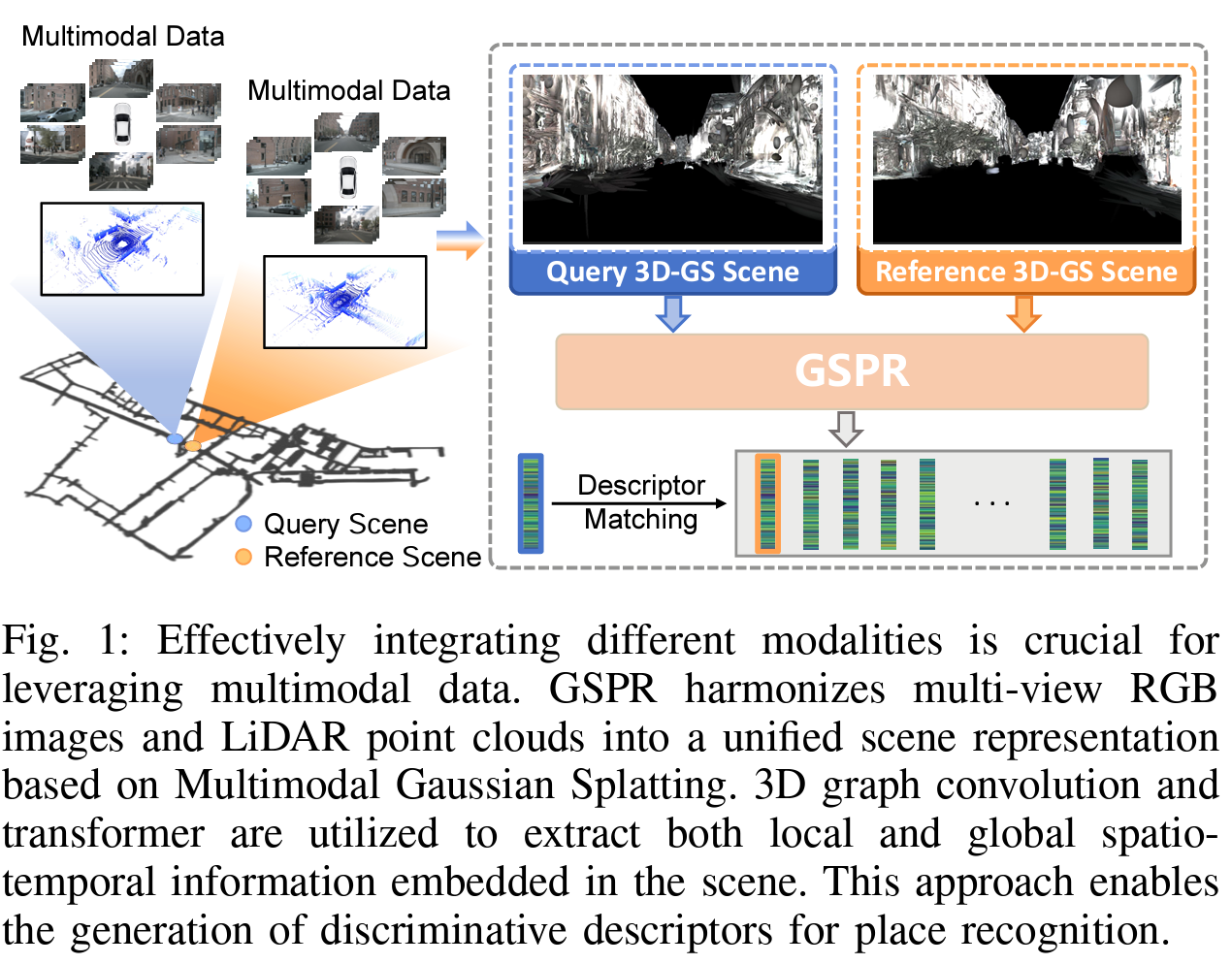
图1:有效整合不同模态对于充分利用多模态数据至关重要。GSPR基于多模态高斯点云,将多视角RGB图像和激光雷达点云协调为一个统一的场景表示。我们利用3D图卷积和变换器提取嵌入场景中的局部和全局时空信息。这种方法使得生成用于地点识别的区分性描述符成为可能。
2. 主要方法
我们提出的GSPR的概述如图2所示。GSPR由两个组成部分构成:多模态高斯点云(MGS)和全局描述符生成器(GDG)。多模态高斯点云将多视角相机和激光雷达数据融合为一个时空统一的高斯场景表示。全局描述符生成器通过3D图卷积和变换器模块从场景中提取高级时空特征,并将这些特征聚合为用于地点识别的区分性全局描述符。
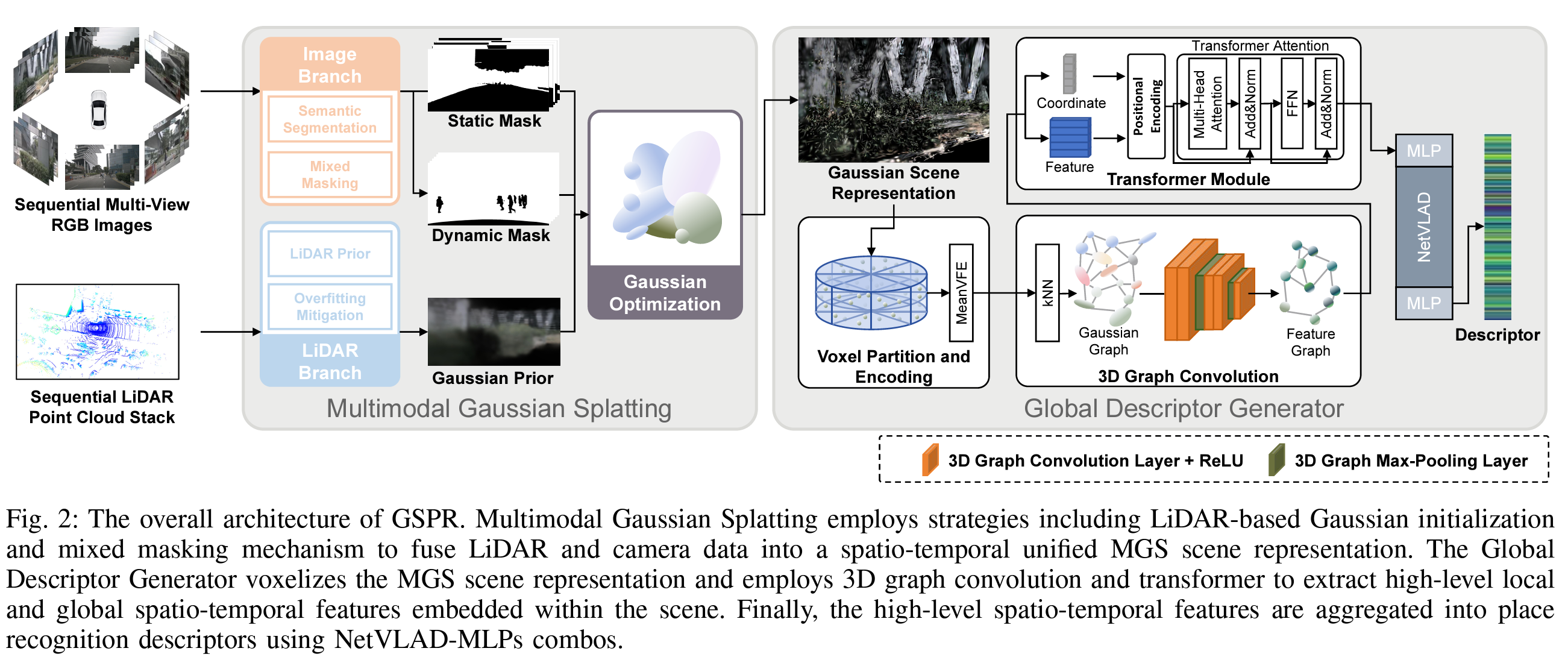
图2:GSPR的整体架构。多模态高斯点云采用包括基于激光雷达的高斯初始化和混合掩模机制在内的策略,将激光雷达和相机数据融合为一个时空统一的MGS场景表示。全局描述符生成器对MGS场景表示进行体素化,并利用3D图卷积和变换器提取嵌入在场景中的高级局部和全局时空特征。最后,这些高级时空特征通过NetVLAD-MLPs组合聚合为地点识别描述符。
3. 多模态高斯点云
如图3所示,我们引入多模态高斯点云用于自动驾驶场景重建。该方法通过图像分支和激光雷达分支处理多模态数据,然后通过高斯优化将不同模态整合为一个时空统一的显式场景表示。图像分支利用序列多视角RGB图像作为输入,通过混合掩模机制生成动态和静态掩模。激光雷达分支补充了远景的激光雷达覆盖,以减轻过拟合,并为高斯的初始化提供激光雷达先验。
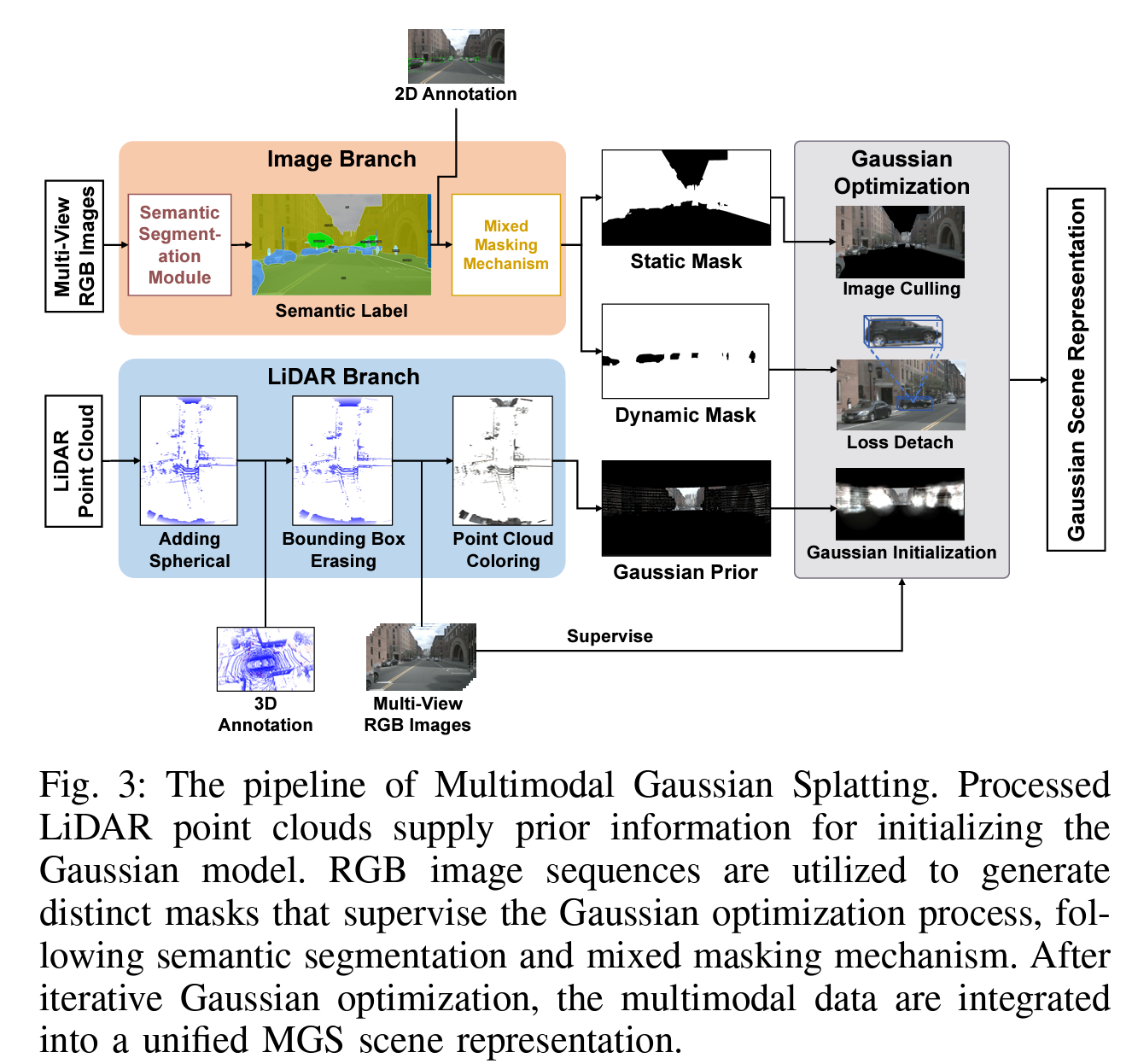
图3:多模态高斯点云渲染的流程。处理后的激光雷达点云为初始化高斯模型提供先验信息。RGB图像序列用于生成不同的掩膜,以监督高斯优化过程,遵循语义分割和混合掩膜机制。在经过迭代的高斯优化后,多模态数据被整合为统一的多模态高斯场景表示。
3.1 激光雷达先验
传统的3D-GS使用结构从运动(SfM)重建点云以初始化高斯模型。然而,在自动驾驶场景中,由于场景的复杂性、光照变化以及自车的高速运动,SfM可能会失败。为了解决这个问题,我们引入激光雷达点云来初始化高斯的位置,参考文献[23]和[24]。使用激光雷达点作为位置先验,3D高斯的分布可以表示为:
f ( x ∣ μ L , Σ ) = e − 1 2 ( x − μ L ) T Σ − 1 ( x − μ L ) ( 1 ) f(x|\mu^L,\Sigma) = e^{-\frac{1}{2}(x-\mu^L)^T\Sigma^{-1}(x-\mu^L)} \quad (1) f(x∣μL,Σ)=e−21(x−μL)TΣ−1(x−μL)(1)
其中, μ L ∈ R 3 \mu_L \in \mathbb{R}^3 μL∈R3是激光雷达点的位置, Σ ∈ R 3 × 3 \Sigma \in \mathbb{R}^{3 \times 3} Σ∈R3×3是3D高斯的协方差矩阵。为了充分利用不同模态之间的时空一致性进行高斯初始化,我们采用RGB图像对激光雷达点云进行着色。这种方法为初始化高斯的球面谐波系数提供了先验。为了获得激光雷达点 ( x L , y L , z L ) T ∈ R 3 (x^L,y^L,z^L)^T \in \mathbb{R}^3 (xL,yL,zL)T∈R3与像素 ( u , v ) T ∈ R 2 (u,v)^T \in \mathbb{R}^2 (u,v)T∈R2之间的准确对应关系,我们对落在每个训练视图的锥体内的激光雷达点进行分割,并随后将这些点投影到相应图像的像素坐标上以获得RGB值:
C r g b p i L = Interpolate ( I , K i n t r ( R p i L + t ) ) , p i L ∈ F C^{p^L_i}_{rgb} = \text{Interpolate}(I,K_{intr}(R{p^L_i} + t)), \quad p^L_i \in F CrgbpiL=Interpolate(I,Kintr(RpiL+t)),piL∈F
其中, C r g b p i L C^{p^L_i}_{rgb} CrgbpiL是激光雷达点 p i L p^L_i piL的对应颜色, I I I表示图像, K i n t r K_{intr} Kintr和 R R R分别是与图像 I I I对应的相机的内参和外参,而 F F F表示落在相机锥体内的激光雷达点集合。
此外,我们从激光雷达点云中滤除地面点,并利用真实标注进行物体边界框的擦除,以确保静态背景的高质量重建。
3.2 过拟合缓解
与普通的3D-GS能够轻松渲染的有限场景不同,自动驾驶场景由于其无限性和训练视角的稀疏分布而面临挑战。这种监督信号的稀缺导致训练视角的过拟合,从而产生漂浮伪影和几何结构的错位。过拟合的一个重要原因是近景与远景之间的混淆。由于远景缺乏足够的几何信息,高斯分布在训练过程中容易将远景拟合为近景中的漂浮伪影,导致背景崩溃。参考文献[27]中用于天空重建的策略,我们通过添加球形点集来缓解这一影响,这些点均匀分布在激光雷达点云的周边。此操作旨在提高超出激光雷达覆盖范围的远景重建质量。球形点集还通过多视角RGB图像进行着色,以作为初始高斯先验。
3.3 混合掩膜机制
在自动驾驶场景中,存在一些环境特征随时间变化而不稳定,并且对地点识别的价值较低。因此,我们提出了混合掩膜机制,专注于在高斯优化过程中仅重建稳定部分。我们采用在Cityscapes数据集上预训练的Mask2Former [28]作为我们的语义分割模块,以生成训练图像的语义标签。通过将语义标签与二维真实标注相结合,我们可以获得实例级掩膜表示。鉴于不稳定环境特征的性质,我们将被掩膜区域分为静态掩膜(例如,天空和道路表面)和动态掩膜(例如,车辆和行人),它们在高斯优化过程中扮演着不同的角色。静态掩膜被用作训练图像筛选的标准。训练图像中被静态掩膜覆盖的区域将被叠加上3DGS渲染器的背景颜色,以限制高斯的生成。相反,动态掩膜则涵盖场景中的动态物体。值得注意的是,直接筛选这些动态物体的阴影区域可能会导致不必要的信息损失。因此,我们采用了一种损失分离策略,在高斯优化过程中对被掩膜区域省略LMGS损失 [9](见公式(10))。这一策略减轻了动态物体的负面影响,同时相比于直接过滤掉包含动态物体的帧,保持了足够的监督以进行大规模重建。如图4所示,我们提出的混合掩膜机制有效地掩盖了不稳定特征。此外,激光雷达先验的应用和过拟合缓解技术的调整有助于保持重建场景的一致尺度和准确几何结构。因此,我们提出的多模态高斯场景表示(MGS)在自动驾驶场景中展现出比传统3D-GS更强的全新视图合成能力,为描述地点提供了时空一致性的MGS场景表示。
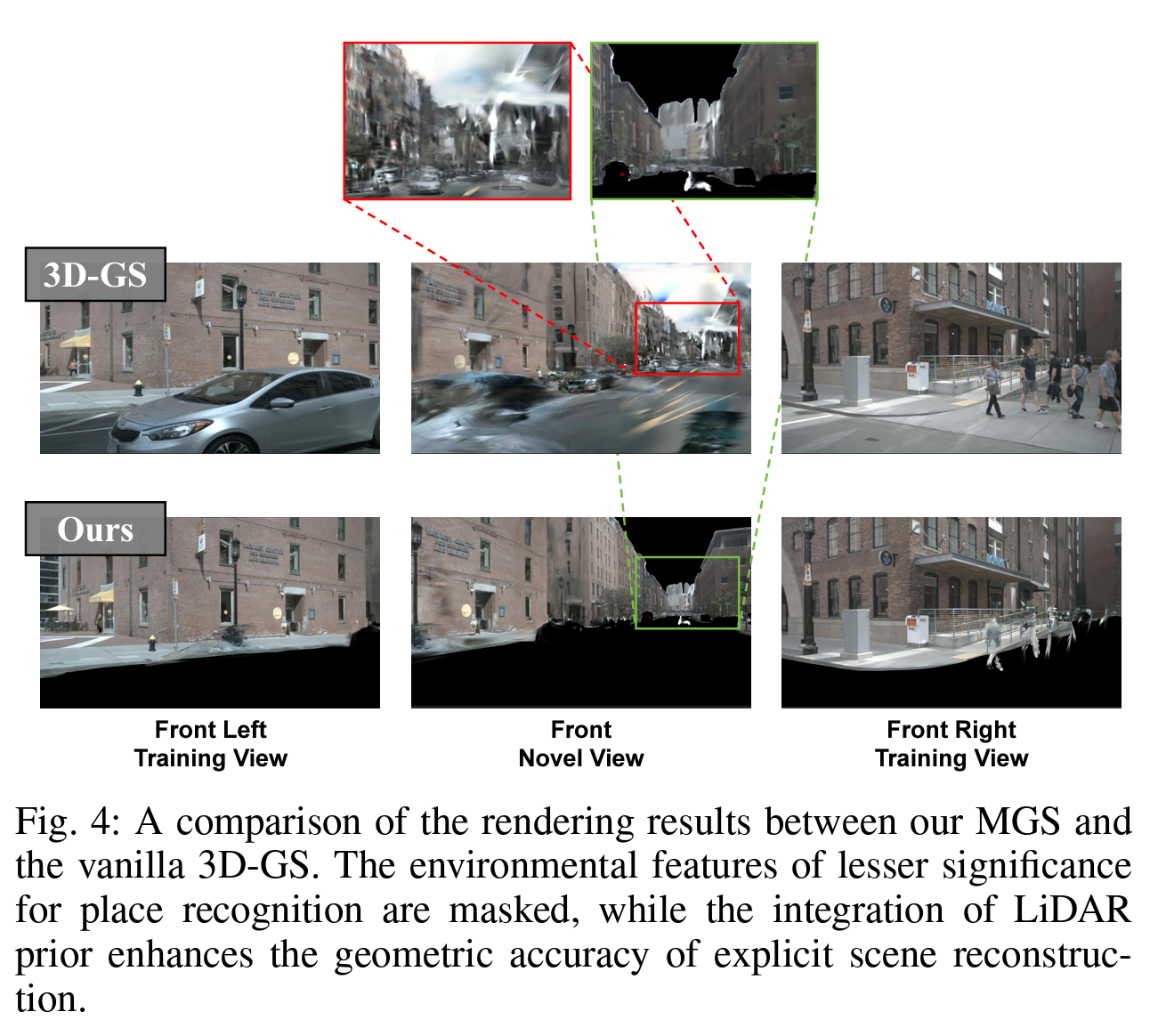
图4:我们提出的多模态高斯场景表示(MGS)与传统3D-GS的渲染结果比较。对地点识别价值较低的环境特征进行了掩膜处理,而激光雷达先验的整合则提升了显式场景重建的几何准确性。
4. 全局描述符生成器
全局描述符生成器用于从所提出的多模态高斯场景表示(MGS)中提取独特的地点识别描述符。为了提取高层次的时空特征,我们首先对MGS场景进行体素化,然后通过由3D图卷积[30]和变换器[31]模块组成的主干网络提取局部和全局特征。最后,将时空特征输入到NetVLAD-MLPs组合[4]中,并聚合成具有区分性的描述符。
…详情请参照古月居

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 22
22 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)