π0——用于通用机器人控制的VLA模型:一套框架控制7种机械臂(基于PaliGemma和流匹配的3B模型)
在此文之前,我花了一天半,详细解读了清华这个机器人扩散大模型RDT,包括其每一个附录,并在上文中预告说:下一篇是一个3B的机器人大模型打通7种不同品牌的机械臂,这几个工作宣告机器人真正进入大模型时代故,本文来了。
前言
在此文之前,我花了一天半,详细解读了清华一研究团队发布的机器人扩散大模型RDT,包括其每一个附录
当时在该文中预告说:下一篇是一个3B的机器人大模型打通7种不同品牌的机械臂,这几个工作宣告机器人真正进入大模型时代
故,本文来了
- 一方面,不断努力,让我的博客成为「大模型开发者和具身智能从业者」的必看,以结交广大同行,以有高频次 高层次 高水平的交流/合作,共同推动行业进步
- 二方面,本文最大的价值和意义在于:一套框架控制7种机械臂,实现各种机械臂的丝滑迁移与平替
且除了我司「七月在线」已经完成的umi/dexcap复现与优化、正在复现/优化的idp3外,如果能把这个π0 在国内商业化、落地,感觉价值也非常大,如有兴趣一块搞的,欢迎私我
update:后在25年2.4日,π0开源了,详见《自回归版π0-FAST——打造高效Tokenizer:比扩散π0的训练速度快5倍但效果相当(含π0-FAST源码剖析)》
此外,考虑到π0算是把基于机器人大模型的「预训练-微调」模式彻底带火了,且这种模式很快会越来越多『犹如此前大模型革命NLP 其次CV等各模态,目前到了robot领域』,算是代表了通用机器人的核心发展方向,故值得把π0写的相对透彻、细致,故我后来在π0的基础上,又详细介绍了:
- 多模态PaliGemma (独立成文)
- Transfusion、Playground v3 (见本文第三部分)
- 流匹配Flow Matching与修正流Rectified Flow (它两的介绍详见此文第五部分)
至于这两在机器人领域的更多应用,则见本文第四部分 - π0的几个参考基线与相似工作
1 一文通透OpenVLA及其源码剖析——基于Prismatic VLM(SigLIP、DinoV2、Llama 2)及离散化动作预测
2 一文速览CogACT及其源码剖析:把OpenVLA的离散化动作预测换成DiT,逼近π0(含DiT的实现)
3 机器人大脑VLA的发展史——从微调VLM起步:详解RoboFlamingo、Octo、TinyVLA
且再后来
- 我又把π0的源码又逐行剖析了下,详见
π0源码(openpi)剖析——从π0模型架构的实现:如何基于PaLI-Gemma和扩散策略去噪生成动作,到基于C/S架构下的模型训练与部署
抠代码好处多多,比如π0论文中并没有明确指出paligemma后接的动作专家 用的什么结构实现,这几天反复抠了下其官方实现代码后,原来用的gemma_300m,已于25年3.16日 补充到下文中- 然后我司还在不断加大对具身的落地,比如微调π0,详见
π0的微调——如何基于各种开源数据集、以及私有数据集微调openpi(含我司七月的微调实践及在机械臂上的部署)- 最后,25年3月下旬,我司在落地π0的过程中,再次回顾本文,给本文增加了新的一节:1.4.2 对语言指令的遵循
且更新了一下此节的内容:1.3.2 SayCan把总目标分解成一个个子目标:为VLM提供更新的语言指令
当然,LeRobot对π0的封装,也值得一看,详见此文《LeRobot pi0——LeRobot对VLA策略π0的封装:含其源码剖析与真机部署(智能化程度高于ACT)》
第一部分 整体理解π0
1.1 π0——用于通用机器人控制的流匹配VLA模型
1.1.1 背景:机器人基础模型的三大挑战——大规模预训练、架构、训练策略
在自然语言[1]和计算机视觉[39]领域,基于多样化多任务数据进行预训练的通用基础模型往往优于那些针对单一任务精细定制和专门化模型的解决方案
例如,如果目标是在照片中识别鸟类,更高效的方法可能是先在大量不同的图像-语言关联数据上进行预训练,然后再针对鸟类识别任务进行微调或提示,而不是仅仅在鸟类识别数据上训练
同样地,作者会发现
- 为了实现高效的专用机器人系统,首先在高度多样化的机器人数据上进行预训练,然后再针对所需任务进行微调或提示会更加有效
这可以解决数据稀缺的问题,因为通用模型可以利用更多的数据来源——包括其他任务、其他机器人,甚至非机器人领域的数据 - 同时也可能解决鲁棒性和泛化性挑战,因为多样化的数据覆盖了更广泛的观测和动作,提供了各种场景、纠正和恢复行为,这些在更狭窄的专用数据中可能不存在
然而,开发此类通用型机器人策略——即机器人基础模型——涉及许多三大挑战
- 首先,任何此类研究都必须在非常大规模上进行,因为大规模预训练的全部优势通常在较小规模上无法体现[54]
- 其次,需要开发能够有效利用多样化数据源的合适模型架构,同时还要能够表达与复杂物理场景交互所需的复杂和微妙行为
- 第三,需要合适的训练方案。这可能是最重要的要素,因为NLP和计算机视觉中大模型的最新进展很大程度上依赖于对预训练和后训练数据进行精细策划的策略[35-即instructGPT原始论文,Training language models to follow instructions with human feedback,详见此文]
1.1.2 预训练的视觉-语言模型VLM主干 + 动作专家通过「流匹配」输出动作
24年10月底,来自Physical Intelligence公司的研究者们提出了一个原型模型和学习框架,称之为π0
- 作者包括Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi,Chelsea Finn, Niccolo Fusai, Lachy Groom,
Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell,Mohith Mothukuri,
Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, Ury Zhilinsky等20多人
其中的Kevin Black是伯克利AI的博士生,也是该公司的研究员
Noah Brown是Google RT1和RT2的二作
Danny Driess也是 RT2的作者之一
联创Chelsea Finn是斯坦福ALOHA团队的指导老师,也是RT2的作者之一
CEO Karol Hausman,曾是谷歌大脑机器人操作研究主管,2021年至今兼任斯坦福客座教授
联创Sergey Levine则是UC伯克利电气工程和计算机科学系副教授,谷歌学术被引用量为超过12.7万 - 其对应的论文为《π0: A Vision-Language-Action Flow Model for General Robot Control》
- 其对应的技术blog为:physicalintelligence.company/blog/pi0
但截止到24年11月中旬,π0没开源、没开放代码,且难度相对较高
下图图1中展示了该模型和系统:先在高度多样化的机器人数据上进行预训练——变成了相比不二次预训练情况下更强大的VLA(类似7-RT-2、24-OpenVLA、55-Tinyvla),然后针对具体任务进行微调

而想达到这个目标,需要解决上面所说的三大挑战:大规模数据、架构、训练策略/方法,π0是如何逐一解决的呢
- 为了整合多样的数据源,作者
首先利用一个预训练的视觉-语言模型(VLM)来导入互联网规模的经验。基于VLM构建他们的模型,使其继承了语言模型和视觉-语言模型的通用知识、语义推理和问题解决能力
其次,进一步训练模型以整合机器人动作,使其成为一个视觉-语言-动作(VLA)模型
为了能够利用多种不同的机器人数据源,作者采用跨体态训练[10],即将多种类型机器人的数据合并到同一个模型中
这些不同类型的机器人具有不同的构型空间和动作表示,包括单臂和双臂系统,以及移动操作机器人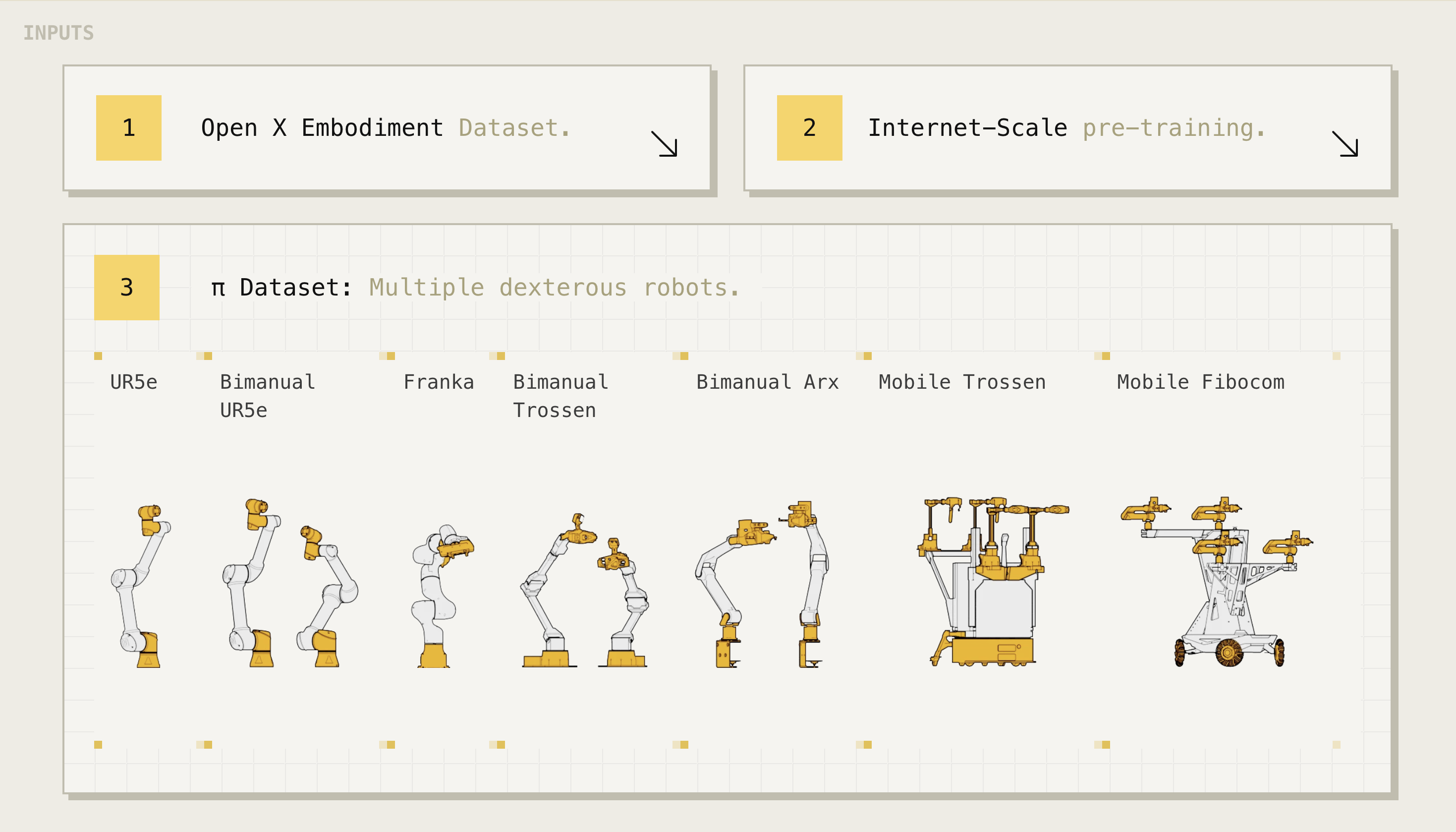
其实这点和上一篇文章介绍的RDT是同样的问题,详见此文《RDT——清华开源的双臂机器人扩散大模型(基于DiT改造而成):先预训练后微调,支持语言、图像、动作多种输入》的「1.2.1节解决数据异构性问题,且兼容多个模态的输入」 - 在模型的架构上,为了能够执行高度灵巧和复杂的物理任务,作者使用
带有流匹配「[或叫修正流Rectified Flow,而修正流则是流匹配的一种改进,详见32-Rectified flow: A marginal preserving approach to optimal transport,至于流匹配是扩散模型[20-DDPM,46]的变体,详见28- Flow matching for generative modeling,以及此文《文生图中从扩散模型到流匹配的演变:从SDXL到Stable Diffusion3(含Flow Matching和Rectified Flow的详解)》的第五部分]」
的动作分块架构[57-Learning fine-grained bimanual manipulation with low-cost hardware,即动作分块算法ACT,详见此文:一文通透动作分块算法ACT:斯坦福Moblie Aloha所用的动作序列预测算法(Action Chunking with Transformers)]
来表示复杂的连续动作分布[28,32]
we use an action chunking architecture [57] with flow matching (a variant of diffusion) to represent complex continuous action distributions [28, 32].
说白了,相当于通过流匹配微调VLM以生成动作(且是多时间步的动作块)
our model em-ploys a novel design that fine-tunes a VLM to produce actions via flow matching [32, 28], a variant of diffusion [20, 46]
那为何要这么做呢?原因也很简单,VLM 可以有效地从网络上传输语义知识,但它们经过训练只能输出离散语言token。灵巧的机器人操作需要π0以高频率(比如高达每秒 50 次)输出运动命令。为了提供这种级别的灵活性,他们通过流匹配为预训练的 VLM 提供连续动作输出
总之,这使得他们的模型能够以高达50Hz的频率控制机器人进行诸如叠衣服(见上图图1,另,下文的1.2.3节中会介绍50Hz 是怎样的一个概念)这样的灵巧任务——每个新输出大约每半秒重新计算一次,最终一次性输出 50 个未来时间步的动作
且为了将流匹配与VLM结合,他们使用了一种新颖的动作专家,它通过流式输出(flow-based outputs)增强了标准VLM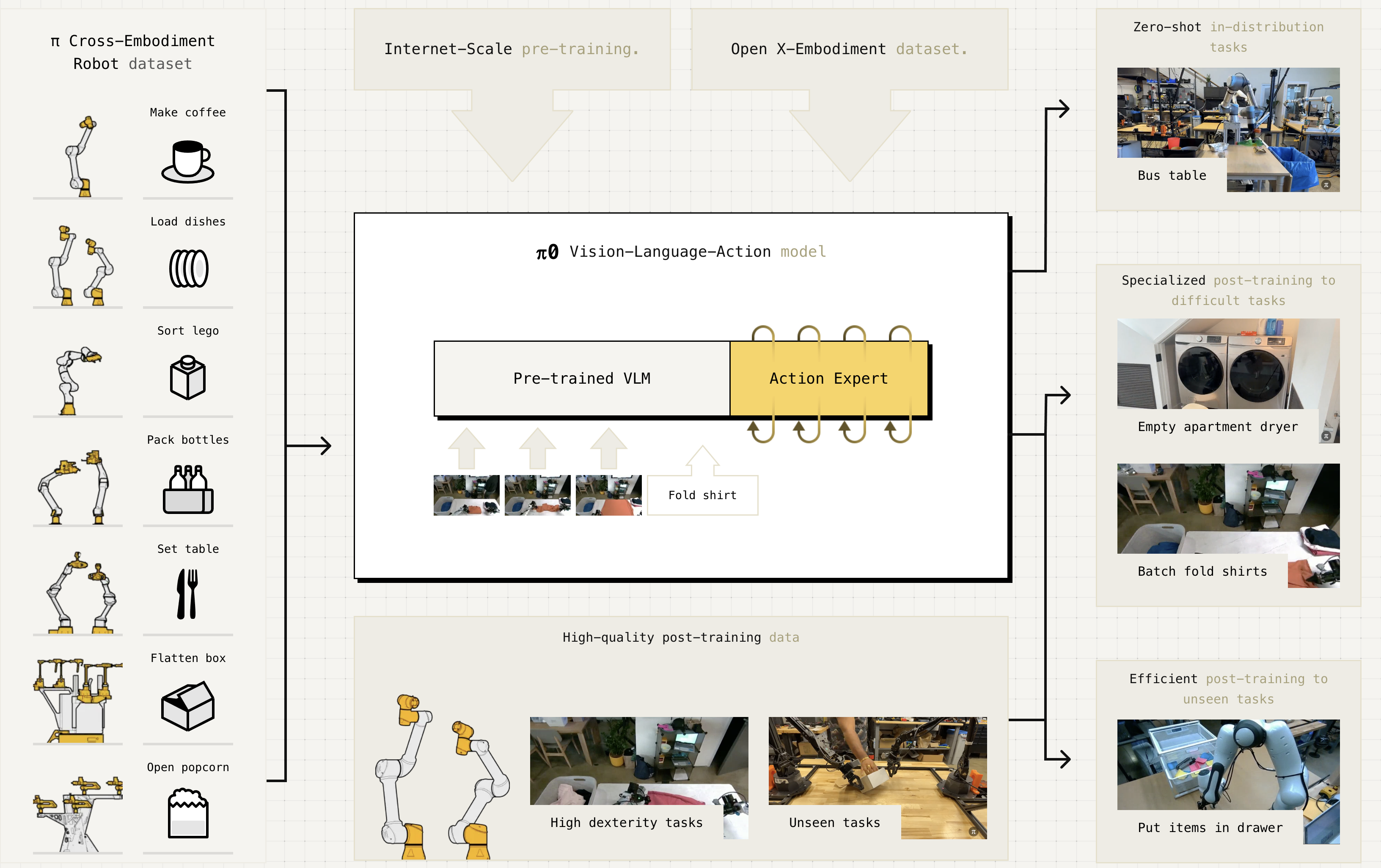
其实,已有许多将预训练语言模型与扩散模型结合的方法被提出[40,41,14],包括专门将扩散与自回归大型语言模型混合的模型[19,29,59]
这些模型通常关注图像生成,但作者的动作生成模型与Zhou等类似
[ 59-Transfusion: Predict the next token and diffuse images with one multi-modal model,一个既可以预测下一个token又可以生成图像的多模态模型(相当于训练单个模型来同时预测离散文本token和扩散连续图像),总之,其通过在50%文本和50%图像数据上预训练一个Transformer模型来展示Transfusion,详见下文的2.1节 ]
其通过在单个序列元素上应用扩散风格(流匹配)损失训练他们的模型,而不是仅解码器的transformers的标准交叉熵损失
Like Zhou et al. [59], we train our model via a diffusion-style (flow matching) loss applied on individual sequence elements, in lieu of the standard cross-entropy lossfor decoder-only transformers
与Liu等[29-Playground v3: Improving text-to-image alignment with deep-fusion large language models.]类似,为对应于扩散的token使用了一套独立的权重(该扩散的token即是机器人的动作),将这些概念融入VLA模型中,提出了据他们所知的首个能够为灵巧控制生成高频动作片段的流匹配 VLA
Like Liu et al. [29], we use a separate set of weights for the tokens corresponding todiffusion. Incorporating these concepts into a VLA model, we introduce what to our knowledge is the first flow matchingVLA that produces high-frequency action chunks for dexterouscontrol. - 在训练策略/方法上,为了灵活且稳健地执行复杂任务
模型首先在极大且多样化的语料库上进行预训练,然后在更狭窄且经过精心筛选的数据上进行微调,以引导出所需的行为模式
总之,流匹配的工作方式和扩散模型有些类似,核心思想都是通过逐步添加噪声来简化数据分布,然后逐步去噪得到隐私数据「Google deepmind团队甚至专门有一篇文章阐述流匹配其实与扩散模型是等价的,详见:diffusionflow.github.io/」
具体而言
- 训练时,随机对动作施加高斯噪声,并训练模型输出去噪向量场
推理时,从高斯噪声开始,通过数值积分向量场生成动作序列- 不同之处在于
流匹配直接对数据和噪声分布之间的映射场(vector field)进行建模,训练目标是匹配这一映射场
而扩散模型通常学习的是每个去噪步骤的条件分布「如还不熟悉扩散模型的,请参见此文《图像生成发展起源:从VAE、VQ-VAE、扩散模型DDPM、DETR到ViT、Swin transformer》的第二部分」so,流匹配方法能够高精度地建模复杂多峰分布,非常适合高频灵巧操作任务
1.2 模型架构与模型推理
1.2.1 整体理解:PaliGemma + 动作专家 + 流匹配Flow matching
作者首先组建了一个预训练混合数据集,该数据集由他们自有的灵巧操作数据集(第V-C节)与OXE数据集[10-即 Open X-Embodiment,关于OXE的介绍详见此文《Google视觉机器人超级汇总:从RT、RT-2到RT-X、RT-H(含Open X-Embodiment数据集详解)》的第三部分]的加权组合组成,该数据集涵盖7种不同的机器人配置,涉及68项不同任务,而OXE数据集包含包含22种机器人的数据
- 预训练阶段还使用了多样化的语言标签,结合了任务名称和片段标注(对子轨迹的细粒度标签,通常长度约为2秒)
预训练阶段的目的是训练一个基础模型,使其具备广泛的能力和泛化能力,但不必针对任何单一任务达到高性能。该基础模型能够根据语言指令执行多种任务,具备初步的熟练度 - 对于复杂且需要灵巧操作的任务,随后采用后训练流程,利用高质量的精心策划数据将模型适配到特定的下游任务
他们研究了数据量较小至中等的高效后训练,以及针对如折叠衣物和移动操作等复杂任务,采用较大规模数据集的高质量后训练——即微调
如下图图3所示

- π0模型主要由一个语言模型transformer骨干组成。遵循标准的后期融合视觉语言模型(VLM)方法[3,11,30],图像编码器将机器人获取的图像观测嵌入到与语言token相同的嵌入空间中
且进一步通过机器人相关的特定输入和输出——即本体感觉状态和机器人动作 来进行增强「We further augment this backbone with robotics-specific inputs and outputs — namely,proprioceptive state and robot actions.」 - π0使用条件流匹配[28,32]来建模动作的连续分布。流匹配为他们的模型提供了高精度和多模态建模能力,使其特别适合高频率的灵巧操作任务
该架构灵感来自Transfusion [59],该方法通过多个目标训练单一Transformer,token对应的连续输出(比如机器人的动作)通过流匹配损失进行监督,而与离散输出对应的token则通过交叉熵损失进行监督
Our architecture is inspired by Transfusion [59], which trains a single transformer using multiple objectives, with tokens1 corresponding to continuous outputs supervised via a flow matching loss and tokens corresponding to discrete outputs supervised via a cross-entropy loss.
在Transfusion的基础上,他们还发现,为机器人特定的(动作和状态)token使用一套单独的权重能够提升性能「Building on Transfusion, we additionally found that using a separate set of weights for the robotics-specific (action and state) tokens led to an improvement in performance. 」
这种设计类似于专家混合模型[45-Outrageously large neural networks:The sparsely-gated mixture-of-experts laye,25-Gshard,12-Glam: Efficientscaling of language models with mixture-of-expert,16-Switch transformer],其中有两大模块
- 第一大模块用于图像和文本(比如人类指令)输入
- 第二大模块用于机器人特定的输入(比如机器人的状态),和输出(比如预测的机器人动作),该第二组权重称为动作专家
相当于这两大模块各司其职,各自处理各自接收到的输入
正式地,他们希望对数据分布建模,其中
- 首先,
对应于未来动作序列(作者在任务中使用H=50,即一次性预测未来的50个连续动作块)
顺带强调下
当我们看到这个符号时,它表示的是输出的预测动作——相当于是不带有噪声的动作
当看到这个符号时,它表示的是输入噪声动作——相当于是带有噪声的动作
PS,此点记住了,可以避免概念上的混淆(且如果你细心的话,你会发现本文全文中,我特意为了区别,皆是:动作输入用的绿色字体,动作输出用的红色字体) - 其次,
是一个观察,观察由多张RGB图像、一个语言指令和机器人的本体状态组成,即
其中是第
张图像(每个机器人有2或3张图像)
是一系列语言token
是关节角度的向量
图像
对于动作块中的每个动作
,都有一个相应的动作token,将其输入动作专家action expert
相当于,对于π的基础模型 VLM,它本身并不直接输出动作。那怎么让它生成动作呢?具体而言,作者团队在VLM后面接一个专门的动作模块
- 这个 action expert 是怎么工作的呢?
它不是直接把自己的参数塞进VLM模型中,变成一个整体大模型来输出动作
而是通过"交叉注意力cross-attention"去关注VLM的参数——从而基于文本指令指导去噪,下文会详解
至于代码剖析则请看此文《π0源码剖析——从π0模型架构的实现(如何基于PaLI-Gemma和扩散策略去噪生成动作),到基于C/S架构下的模型训练与部署》中的「1.2.4 class Pi0:含损失函数(训练去噪的准确性)、推理(去噪生成动作)」- 故,action expert 就是“看着” VLM的参数,根据这些信息生成具体的连续的动作——而无需像RT-2那样对其进行离散化或token化(discretize or tokenize)
在训练过程中,使用条件流匹配损失Conditional Flow Matching[28,32]对这些动作token进行监督「前者为学习网络 相当于预测的噪声,后者
为学习目标 相当于添加的真实噪声,即训练前者去逼近后者」
其中下标 表示机器人时间步,上标
表示流匹配时间步
- 最近在高分辨率图像[14]和视频[38]合成方面的研究表明,当流匹配与简单的线性高斯(或最优传输)概率路径[28]结合时,可以实现强大的经验性能
具体由下述表达式给出 - 在实践中
第一步,一般都是网络先通过随机采样符合正太分布的噪声进行训练,计算“带噪声的动作”
In practice, the networkis trained by sampling random noise ϵ ∼N(0, I), computingthe “noisy actions” Aτt = τAt + (1 −τ)ϵ
相当于先加噪,类似此文中「5.2.1 通过示意图对比:ϵ-prediction、v-prediciton与rectified flow」最后对rectified flow的阐述: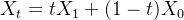 或
或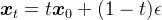
相当于从动作分布
之后,再去噪
故,便有第二步:然后训练网络输出「此为动作块的向量场表示,
代表预测的噪声」,以匹配去噪向量场
(
代表添加的真实噪声)「即training the network outputs vθ (Aτt , ot) to match the denoising vector field u(Aτt |At) = ϵ −At.」
所以才有上面提到的损失函数
啥意思呢?
相当于得到了所添加的真实噪声之后,便可以通过该公式,计算得到
- 动作专家使用全双向注意力掩码,以便所有动作token彼此关注「The action expert uses a full bidirectional attention mask, so that all action tokens attendto each other」
在训练过程中,从一个强调较低(更嘈杂)时间步的 beta分布 中采样流匹配时间步
更多细节请参见附录B「During training, we sample the flow matching time step τ from a beta distribution that emphasizes lower(noisier) timesteps. See Appendix B for more details.」到
积分学习到的向量场来生成动作,从随机噪声
开始,且作者使用前向欧拉积分规则「At inference time, we generate actions by integrating thelearned vector field from τ = 0 to τ = 1, starting with randomnoise A0t ∼N(0, I). We use the forward Euler integrationrule:」
其中是积分步长
在他们的实验中,使用了10个积分步骤(对应于)。注意,推理过程可以通过缓存前缀
他们在附录D中提供了有关推理过程的更多细节,包括模型各个部分的推理时间
此外
虽然原则上他们的模型可以从头初始化,或在任何VLM骨干上进行微调,但实际操作中他们采用PaliGemma [5-PaliGemma: A versatile 3B VLM for transfer]作为他们的基础模型
为了方便大家更好的理解,我特地再补充三点
- 其中的PaliGemma是一个开源的30亿参数VLM 「关于PaliGemma的详细介绍,请参见此文:多模态PaliGemma(含1代和2代):Google推出的基于SigLIP和Gemma的视觉语言模型(含SigLIP详解)」,在模型规模和性能之间提供了便利的权衡
可能有的读者有疑问,VLM那么多,为何独独选择的PaliGemma呢?其实原因很直接,因为其效果还可以,详见此文《RoboVLM——通用机器人策略的VLA设计哲学:如何选择骨干网络、如何构建VLA架构、何时添加跨本体数据》的「1.2.3 哪种VLM骨干网络更适合VLA?KosMos和Paligemma表现更好」- 然后,作者为动作专家添加了3亿参数(从头初始化):基于gemma_300m
如此文《π0源码剖析——从π0模型架构的实现(如何基于PaLI-Gemma和扩散策略去噪生成动作),到基于C/S架构下的模型训练与部署》的一节「1.2.3 class Pi0Config:定义动作专家底层结构gemma_300m,且含inputs_spec、get_freeze_filter」所说,π0在实际实现时,用的gemma_300m定义的动作专家从而使得整个π0的参数总计达到33亿class Pi0Config(_model.BaseModelConfig): dtype: str = "bfloat16" paligemma_variant: _gemma.Variant = "gemma_2b" action_expert_variant: _gemma.Variant = "gemma_300m"- 除了他们的主要VLA模型外,他们还训练了一个类似的基线模型——π0-small,该模型在消融实验中没有使用VLM初始化
作者称之为π0-small的这个模型拥有470M参数,没有使用VLM初始化,并且在没有使用VLM初始化的数据训练中,作者发现了一些有助于训练的小差异,这些差异在原论文的附录C中进行了总结
1.2.2 深入细节:改造VLM PaliGemma:后接action expert,使其成为VLA模型
作者遵循PaliGemma VLM [5]的设计

但有以下不同:
- 为机器人特定的token增加了额外的输入和输出投影,包括状态向量
- 增加了一个用于结合流匹配时间步的MLP信息
- 以及动作专家(比如gemma_300m)的一组较小的权重
具体的改动,分别涉及到以下几点
- 附加输入和输出
标准的PaliGemma架构接收一系列图像,随后是语言指令
但作者附加了输入和输出,即,token数量等于动作视界(在作者的任务中H= 50),作者仅使用transformer输出中对应于
个噪声动作的部分,并通过线性投影解码为
The final set of input tokens correspond to the noisy action chunk Aτt = [aτt , ..., aτt+H−1], with the number of tokens equal to the action horizon (H = 50 for our tasks). We only use the transformer outputs corresponding to the H noisy actions,which are decoded into vθ (Aτ
t , ot) using a linear projection. - 整合了流匹配时间步
的多层感知机MLP
噪声动作块
The noisyaction chunk Aτt is mapped to the transformer’s embeddingdimension using an MLP that also incorporates the flowmatching timestep τ.
对于每个噪声动作,输入到transformer的对应嵌入表达式为
其中是一个正弦位置编码函数[51]
是动作维度,
是动作专家的嵌入维度(或宽度)
- 注意力掩码
π0使用具有3个块的分块因果注意力掩码:,
,和
在每个块内,存在全双向注意力,而每个块中的token不能关注未来块中的token - 动作专家「其训练目标用的flow matching」
π0实现为一个单一的transformer,其具有两组权重(也可称为专家[45])——即π0 is implemented as a single transformerwith two sets of weights (also known as experts [45]),每个token被路由到其中一个专家;权重仅通过transformer的自注意力层相互作用
那各个token到底是路由到具体哪个专家呢?很简单,则被路由到动作专家
对于PaliGemma,其基于Gemma 2B[49]语言模型,使用多查询注意力[44,关于多查询注意力的介绍详见此文:一文通透各种注意力:从多头注意力MHA到分组查询注意力GQA、多查询注意力MQA的第三部分],和配置{width=2048,depth=18,mlpdim=16,384,num heads=18, num kvheads=1,head dim=256}
而对于动作专家(比如π0官方实现中的gemma_300m),其仅在自注意力层中相互作用,width和mlp dim不必在专家之间匹配
另,为了加快推理速度(需要动作专家的多次前向传递),他们将动作专家缩小为{width=1024, mlp dim=4096},参数数量约为∼300M - 采样流匹配时间步
原始流匹配论文[28,32]从均匀分布中采样流匹配时间步:。Esser等人[14]则建议从对数正态分布中采样
作者认为,在高时间步(低噪声水平)时,模型只需学习恒等函数,而在低时间步(高噪声水平)时,模型只需学习数据分布的均值
然而,假设动作预测任务与高分辨率图像合成有细微的不同——虽然在文本标签的条件下预测均值图像可能相对容易,但在机器人观测条件下预测均值动作(即,学习)则是个更难的问题;这是因为观测
因此,作者设计了一个时间步采样分布,强调低时间步(高噪声水平);此外,超过给定阈值s的时间步根本不被采样,因为只要积分步长δ大于1−s,它们就不需要
分布由,且在实验中使用 s= 0.999,这允许δ > 11000 ,或最多 1,000 个积分步骤
1.2.3 模型推理
回想一下,模型接受一个观测和噪声动作
,并输出需要集成以获得下一个流匹配步骤的向量场
「Recall that our model takes an observation ot = [I1t , ..., Int , ℓt, qt] and the noisy actions Aτt and outputs the vector field that needs to be integrated to obtain the next flow matching step, vτt . 」
每次预测一个新的动作块时,必须对每个图像
进行编码,在与
对应的token上运行一次前向传递,然后运行10步流匹配,其中每一步都需要在与
对应的token上运行一次前向传递(与
对应的键和值是缓存的)「Each time we predict a new action chunk At, we must encode each of the images I1t , ..., Int , run a forward pass on the tokens corresponding to ot, and then run10 steps of flow matching, where each step requires running a forward pass on the tokens corresponding to Aτt (the keys and values corresponding to ot are cached).」
下表表I总结了使用3个摄像头图像进行此操作的计算时间

这些操作是在NVIDIA GeForce RTX 4090消费级GPU上计时的。对于移动机器人,推理是在Wi-Fi连接上进行的,增加了一小部分网络延迟。当然了,如果做进一步的优化、量化和其他改进可能会进一步减少推理时间
由于模型一次生成整个 H步动作块,作者可以在需要再次运行推理之前执行最多 H个动作。然而,实际可能会比这更频繁地进行推理,并且可以使用各种聚合策略结合来自不同推理调用的动作
作者在早期尝试了ACT算法中的时间集成[57- Learning fine-grained bimanual manipulation with
low-cost hardware,对于这点,我july的个人理解是时间集成是ACT策略中的其中一个选项,故用ACT的过程中,可以不用时间集成这个特征,是不影响对ACT的使用的],发现它对策略性能有害,因此作者选择不聚合动作,而是执行开放循环的动作块
- 对于20Hz的UR5e和Franka机器人,作者每0.8秒进行一次推理(在执行16个动作后)
- 而对于所有其他以50Hz运行的机器人,作者每0.5秒进行一次推理(在执行25个动作后)
这个50Hz是一个什么概念呢?简言之,不算慢了 但也不是很快,我给你对比一下,你就一目了然了,如此文《视觉语言机器人的大爆发:从RT2、VoxPoser、RoboFlamingo、OK-Robot到Figure 01、清华CoPa》对第五部分 Figure人形机器人的介绍——5.2.2 机器人操控小模型(类似Google的RT-1)中所述:输出action,一个基于neutral network的机器人操控小模型以 200hz 的频率(RT-2论文里提到的决策频率则只有1到5hz)生成的 24-DOF 动作(手腕姿势和手指关节角度)
1.3 数据收集及预训练-微调的训练方案(含让VLM充当机器人大脑)
就像大型语言模型LLM的训练通常分为预训练和后训练阶段一样,作者对他们的模型也采用多阶段训练程序
- 预训练阶段的目标是让模型接触到各种各样的任务,以便它能够获得广泛适用和一般的物理能力,而后训练阶段的目标是使模型能够熟练和流畅地执行所需的下游任务
- 因此,预训练和后训练数据集的要求是不同的:
预训练数据集应涵盖尽可能多的任务,并在每个任务中涵盖多样化的行为
后训练数据集则应涵盖有助于有效任务执行的行为,这些行为应表现出一致且流畅的策略。
直观地说,多样化(但质量较低)的预训练数据允许模型从错误中恢复并处理高度变化的情况,这些情况可能在高质量的后训练数据中不会出现,而后训练数据教会模型良好地执行任务
1.3.1 先基于机器人数据(开源 + 自采)预训练,之后实际任务中微调
在下图图4中提供了作者预训练混合的概述——其在超过10,000小时的机器人数据上进行预训练

- 该预训练混合物由
OXE的这个子集称之为OXE Magic Soup[24-Openvla:An open-source vision-language-action model,关于Openvla详见此文《一文通透OpenVLA及其源码剖析——基于Prismatic VLM(SigLIP、DinoV2、Llama 2)及离散化动作预测》的第二部分]
和
组成 - 上图右侧展示了预训练混合物中不同数据集的权重(the right figure illustrates the weight of the differentdatasets in the pre-training mixture.),上图左侧展示了通过步数衡量的相对大小
注意,由于每个训练样本对应一个时间步——即一个元组,——在本次讨论中,将以时间步来量化数据
- 训练混合数据集中有9.1%来自开源数据集,包括
这些数据集中的机器人和任务通常配备一到两个摄像头,并采用低频率控制,频率在 2 到 10 Hz 之间。然而,这些数据集涵盖了广泛的物体和环境 - 为了学习灵巧且更复杂的任务,作者还使用了来自他们自有的数据集,总计903M时间步长的数据,其中
这些数据涵盖了68个任务,每个任务都由复杂的行为组成——例如,“清理餐具”任务包括将各种各样的盘子、杯子和餐具放入餐具回收箱,以及将各种垃圾物品扔进垃圾桶
请注意,这里的任务定义与以往工作有显著不同,之前的工作通常使用任何名词和动词的组合(例如,“捡起杯子”与“捡起盘子”)视为不同的任务
因此,作者数据集中实际的行为范围远比“任务”数量所暗示的要广泛得多
下文的“1.3.3 可操作的机器人系统:涉及7种机械臂和68个任务”更详细地讨论他们数据集中的具体机器人和任务(对应原论文V-C节)
此外,由于数据集在规模上存在一定的不平衡(例如,更难的叠衣任务样本数量较多),作者对每个任务-机器人组合按进行加权,其中
为该组合的样本数量,从而对样本数量过多的组合进行降权
- 配置向量
始终具有数据集中最大机器人的维度(在作者的案例中为18,以适应两个6-DoF机械臂、两个夹爪、一个移动底座和一个垂直驱动的躯干)
- 对于配置和动作空间维度较低的机器人,对配置和动作向量进行零填充。对于少于三张图像的机器人,还会屏蔽掉缺失的图像槽
- 在训练后阶段,使用一个较小的任务特定数据集对模型进行微调,以使其专门化用于特定的下游应用
如前所述,对“任务”的定义相当广泛——例如,“收拾”任务需要操作多种不同的物体。不同的任务需要非常不同的数据集,最简单的任务只需5小时,而最复杂的任务需要100小时或更多的数据
1.3.2 SayCan把总目标分解成一个个子目标:为VLM提供更新的语言指令
视觉语言大模型本身就可以充当机器人的大脑,给机器人做顶层任务规划,且由来已久,比如SayCan、清华的ViLa、CoPa等等
- 需要语义推理和高层策略的更复杂任务,例如清理桌子,也可以通过高层策略来受益,即将高层任务(如“清理桌子”)分解为更直接的子任务(如“拿起餐巾”或“将餐巾扔进垃圾桶”)
由于作者的模型经过训练可以处理语言输入,故可以使用高级视觉语言模型(VLM)来进行这些语义推理
这种方法类似于LLM/VLM的规划方法,例如上面让VLM充当机器人大脑一文中提到的SayCan:在多个实验任务中采用这样的高层策略来辅助模型进行高层策略规划
相当于VLM本身确实是可以做任务规划的,但要想规划的更具备可执行性时,更方便机器人实际操作时,可以用到SayCan这种能站在机器人角度、且具备一定的空间物理感的模型来打辅助——说白了,类似rekep,给GPT4的规划起到了一定的物理空间约束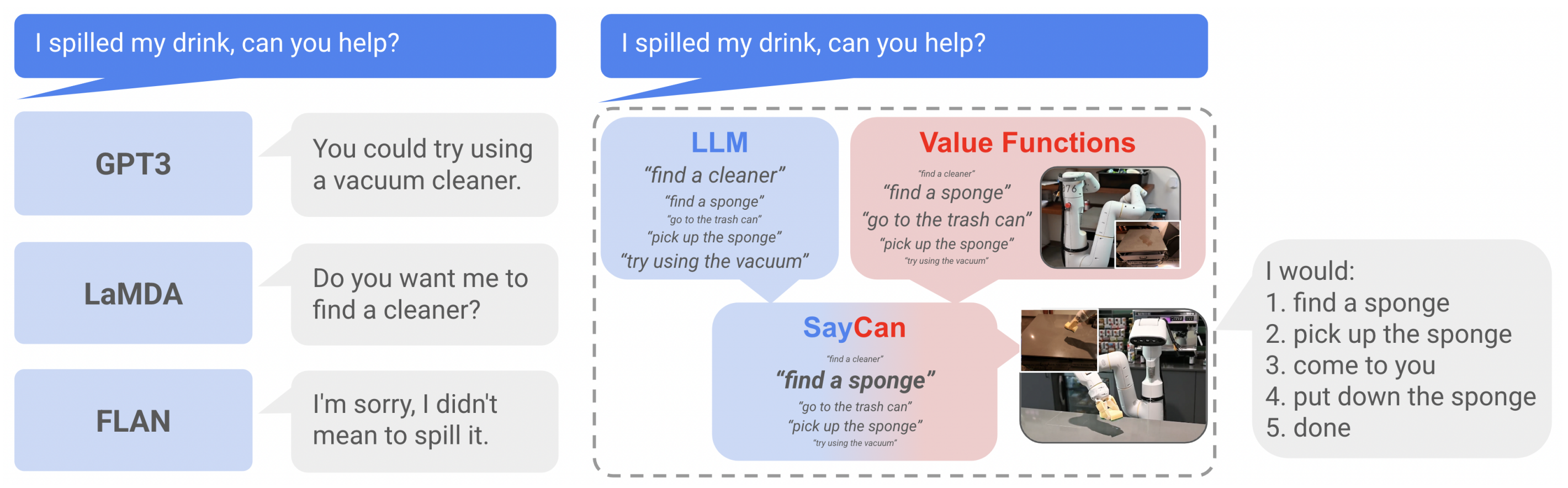
从而对于π0这样的VLA而言,可以让其下游的动作专家 执行效率更高、执行效果更好
「详见此文《让VLM充当机器人大脑——VLM规划下加约束:从SayCan、VoxPoser到ViLA、CoPa、ReKep》的第一部分」 - 进一步而言,如DexVLA「详见此文《机器人大小脑的融合——从微调VLM起步的VLA发展史:详解RoboFlamingo、Octo、TinyVLA、DexVLA》的第4部分」一文中结论部分所说的:“其中高级策略模型经常评估物体状态,并为低级视觉-语言-动作模型提供更新的语言指令”「Prior work, π0, addresses this by using SayCan, where a high-level policy model frequently assesses the object state and provides updated language instructions to the low-level vision-language-action model」
1.3.3 可操作的机器人系统:涉及7种机械臂和68个任务
作者灵巧操作数据集包含7种不同的机器人配置和68个任务,如下图图5所示

- UR5e
一款配有平行夹爪的机械臂,配备腕部安装和肩部上方摄像头,共有两路摄像头图像输入,以及7维配置和动作空间 - 双臂UR5e
两套 UR5e 系统,共有三路摄像头图像,以及一个 14 维的配置和动作空间 - Franka
Franka设置有两个摄像头和一个8维的配置和动作空间 - 双臂Trossen
该系统包含两个6自由度的Trossen ViperX机械臂——基于ALOHA设置[4,57],配备两个腕部摄像头和一个基座摄像头,总计拥有14维的配置和动作空间 - 双臂ARX(来自国内厂商方舟无限 ),和双臂AgileX(来自国内厂商松灵机器人)
其使用两个6自由度机械臂,支持ARX或AgileX机械臂,并配备三个摄像头(两个腕部和一个基座),具有总计14维的配置和动作空间
此类别涵盖两个不同的平台,但由于它们的运动学特性相似,故将它们归为一类 - 移动Trossen和移动ARX
此设置基于移动ALOHA[57]平台,具有两个安装在移动基座上的6自由度机械臂,这些机械臂可以是ARX机械臂或TrossenViperX机械臂
由于非全向基座增加了两个动作维度,因此具有14维的配置空间和16维的动作空间。系统配备两个腕部摄像头和一个底座摄像头
此类别涵盖两个不同的平台,但由于它们的运动学特性相似,故将它们归为一类 - 移动Fibocom
两个安装在全向底座上的6自由度ARX机械臂。底座增加了三个动作维度(两个用于平移,一个用于方向),因此具有14维的配置空间和17维的动作空间
在上文1.3.1节开头的图4中,作者总结了每个机器人在他们数据集中所占的比例
1.4 实验效果及验证:对基础模型的评估与灵巧任务
1.4.1 对基础模型的评估
为了做一系列验证对比,作者
- 与OpenVLA[24]进行比较,这是一个最初在OXE数据集[10]上训练的7B参数VLA模型。作者在完整混合数据集上训练OpenVLA
这对于OpenVLA来说是一个非常困难的混合物,因为它不支持动作分块或高频控制 - 此外,还与Octo [50-详见此文《大小脑的分层与融合——从微调VLM到VLA:详解RoboFlamingo、Octo、TinyVLA》]进行比较,这是一个较小的93M参数模型
虽然Octo不是VLA,但它确实使用扩散过程生成动作,为作者的流匹配VLA提供了一个有价值的比较点
作者还在与他们模型相同的混合数据集上对Octo进行了训练。但由于时间限制,作者无法为OpenVLA和Octo训练与他们完整模型相同的epochs数
因此,作者还与“计算等量”版本的模型进行比较,该版本仅训练160k步(而作者的主模型训练了700k步),这相当于或低于为基线提供的步骤数量(OpenVLA为160k,Octo为320k) - 还包括一个仅在UR5e数据上微调的OpenVLA模型版本,不进行跨体训练,旨在为UR5e任务提供一个更强的基线
- 最后,作者还包括与上文描述过的π0-small模型的比较,该模型可以视为作者模型的缩小版,没有进行VLM预训练
评估指标使用归一化分数,对每个任务和方法平均10 个回合的得分,其中每个回合在完全成功时获得1.0 分,部分成功时获得小数分
例如,收拾餐具任务的得分是正确放置在相应容器中的物体比例。他们在附录E 中描述了评分标准
结果如下图图7所示

- π0在所有零样本任务上取得了迄今为止最好的结果,在叠衬衫和较简单的收拾餐具任务上接近完美的成功率,并且在所有基线方法上都有大幅提升
π0 的”parity” 版本仅训练了160k 步,仍然优于所有基线方法,甚至π0-small 也优于OpenVLA 和Octo - OpenVLA在这些任务上表现不佳,因为其自回归离散化架构不支持动作块
仅使用UR5e 的OpenVLA 模型表现更好,但仍远低于π0 的表现 - Octo确实支持动作块,但其表示能力相对有限
上面的这些对比说明了将大规模、具有强表达能力的架构与通过流匹配或扩散建模复杂分布的能力相结合的重要性
此外,与π0-small的对比也说明了结合VLM预训练的重要性
不幸的是,最后的比较很难做到公平:π0-small使用的参数更少,但更大的模型在没有预训练的情况下难以使用
总体而言,这些实验表明π0提供了一个强大的预训练模型,能够有效地执行各种机器人任务,性能远优于先前的模型
1.4.2 对语言指令的遵循
VLM初始化既有助于在不发生过拟合的情况下实际训练更大的模型,也有助于提升模型对语言指令的理解能力。尽管如此,作者仍希望做实验以揭示π0的语言能力
每个任务的语言指令包括要拾取的物体和要放置这些物体的位置,带有语言标签的片段长度约为2秒。每个完整任务由多个此类片段组成
本次评估中的任务包括:
- 收拾餐桌:机器人必须清理桌面,将餐具和刀叉放入收纳箱,将垃圾放入垃圾桶
- 摆放餐具:机器人必须从收纳箱中取出物品来布置餐桌,包括餐垫、餐具、银器、餐巾和杯子,并根据语言指令进行调整
- 杂货打包:机器人必须将杂货物品,如咖啡豆、薏米、棉花糖、海苔、杏仁、意大利面和罐头等物品装入袋中
在下图图8中,展示了本次评估中的语言条件任务,并展示了评估结果

他们评估了五种不同的条件
- π0-flat(和π0-small-flat)对应于直接用任务描述(例如,“打包杂货”)命令模型,而不包含中间语言指令
- π0-human(和π0-small-human)提供中间步骤命令(例如,要拾取哪个物体以及将其放置在哪里)来自专家人类用户
这些条件评估每个模型遵循更详细语言指令的能力:虽然这些中间命令为如何执行任务提供了大量信息,但模型必须能够理解并遵循这些命令,才能从中受益 - 最后,π0-HL 评估了 π0 在由高级 VLM 提供高级命令的情况下的表现,如原论文第V-B节所述。这一条件同样是自主的,无需任何人类专家
下图图9中的结果,平均每个任务进行10次试验,显示π0的语言跟随准确性明显优于π0-small
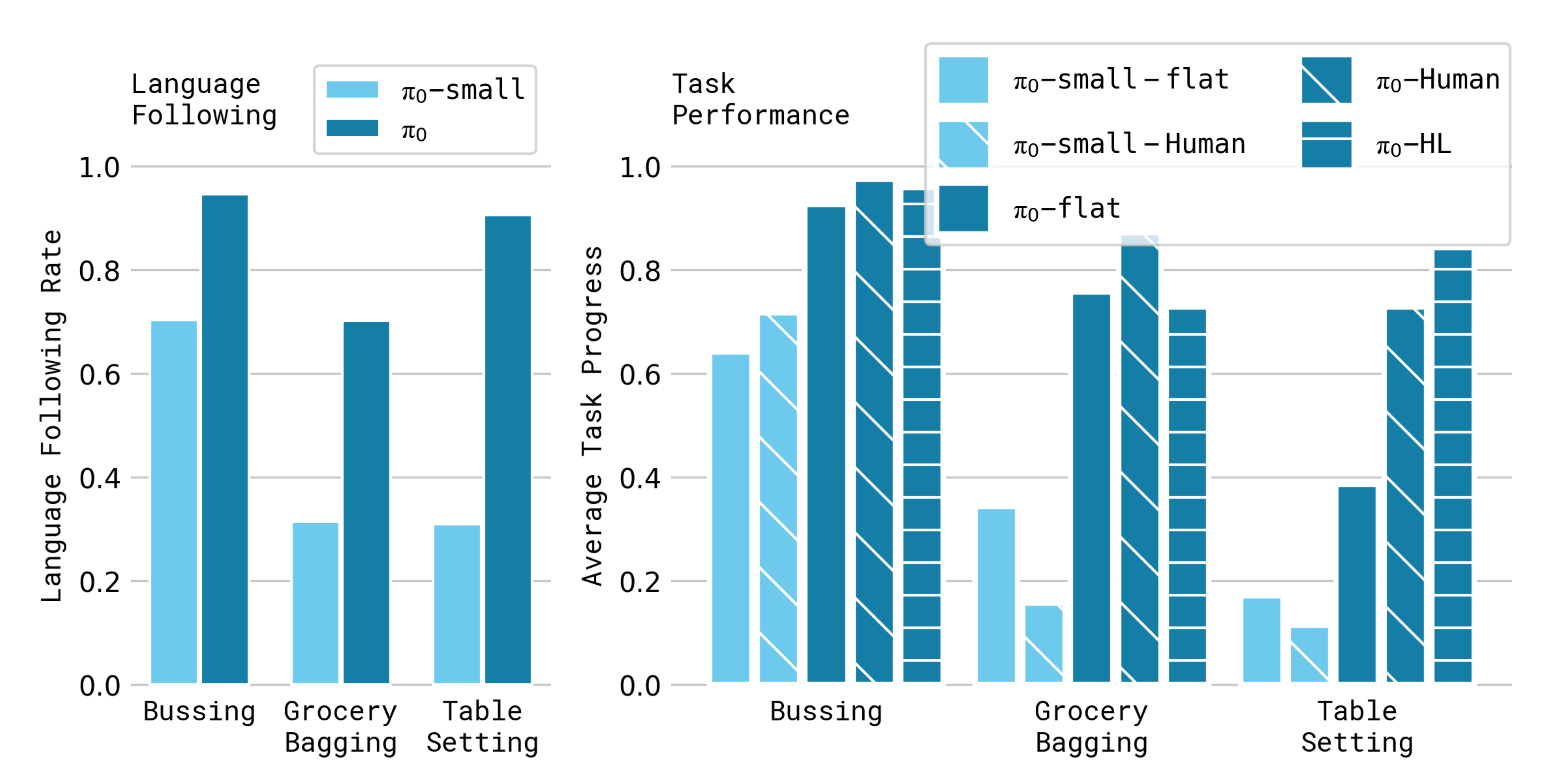
- 这表明,大型预训练 VLM 初始化带来了显著的提升。这一能力也转化为在专家人类指导(π0-human)和高级模型指导(π0-HL)下的性能提升
言外之意,就是,π0在从人类专家提供的中间语言命令中——即π0-human有显著改善,且自主高级策略π0-HL也有一定程度的改善 - 结果表明,π0 的语言跟随能力直接转化为在高级指导下的复杂任务中更出色的自主表现
The results indicate that π0’s language following ability directly translates into better autonomous performance on complex tasks with high-level guidance
1.4.3 学习新的灵巧任务
如下图图10所示,再看下面对一系列新任务的表现

- UR5e 堆叠碗
这个任务需要堆叠碗,使用四个不同尺寸的碗。由于这个任务需要像预训练数据中的收碗任务一样抓取和移动碗,因此将其归入“简单”层级
训练数据包含各种碗的使用,评估中混合使用已见和未见的碗 - 毛巾折叠
此任务需要折叠毛巾。由于这与衬衫折叠相似,而衬衫折叠在预训练中存在,因此将其归为“简单”级别 - 微波炉中的保鲜盒
该任务要求打开微波炉,将一个塑料容器放入其中,并关闭微波炉。容器有不同的形状和颜色,评估时会混合使用已见过和未见过的容器
容器的操作与预训练数据相似,但微波炉在预训练中未出现 - 纸巾更换
此任务需要从支架上取下旧的纸巾纸管,并用新的纸巾卷替换。由于在预训练中未找到此类物品,可以认为这属于“困难”级别 - Franka机器人在抽屉中的物品
此任务需要打开抽屉,将物品放入抽屉中并关闭。由于在预训练中没有类似的Franka机器人任务,故也认为这属于“困难”级别
作者在微调后将他们的模型与OpenVLA[24]和Octo [50]进行比较,它们也采用了预训练和微调的方法
由于作者的目标是评估特定模型(而非架构本身),因此使用这些模型在OXE [10]上公开可用的预训练检查点,然后针对每个任务进行微调
- 此外,作者还与纯粹的ACT[57]和Diffusion Policy [9,关于什么是扩散策略,详见此文:Diffusion Policy——斯坦福机器人UMI所用的扩散策略:从原理到其编码实现]进行比较,这些方法专门为从较小的数据集中学习灵活任务而设计
ACT和Diffusion Policy仅在微调数据集上进行训练,这些数据集的大小与ACT和Diffusion Policy实验中使用的各个数据集相似 - 作者通过从他们预训练的基础模型进行微调,以及从零开始训练来评估π0。这种比较旨在评估π0架构和我们的预训练过程各自带来的益处
- 作者假设具有VLM初始化的π0架构应该已经为各个任务提供了更强的起点,而预训练过程应该进一步提高其性能,尤其是在较小的微调数据集上
下图图11展示了各种方法在所有任务上的性能「其使用不同数量的数据进行微调。π0即使在数据量较少的情况下也能学习一些简单的任务,并且预训练模型通常比从头开始训练的模型获得更大的提升」,平均每个任务进行10次试验,每个任务使用不同数量的微调数据

作者在叠碗和微波炉中的塑料容器(Tupperware in microwave)任务上包含了所有基线
- 由于OpenVLA和Octo的性能显著较差,他们仅在其中一个数据集大小上运行这些模型,因为在现实世界中评估如此多模型的时间成本很高。结果显示,π0通常优于其他方法
- 有趣的是,最强的先前模型是那些完全从头开始在目标任务上训练的模型,这表明在这些领域利用预训练对先前方法来说是一个重大挑战
- 虽然π0在Tupperware任务上的5小时策略与基线表现相近,但1小时版本则明显更好。如预期,预训练对于与预训练数据更为相似的任务带来了更大的提升,尽管如此,预训练模型通常优于非预训练模型,有时甚至高出2倍
第二部分 π0的简单实现与正式开源
一开始有朋友给我发了个网友对π0的简单实现:github.com/allenzren/open-pi-zerogithub.com/allenzren/open-pi-zero
- 该模型采用类似 MoE 的架构(或近期的 MoT,每个专家都有自己的参数集,仅通过注意力机制进行交互)
并使用一个预训练的 30 亿参数的 PaliGemma 视觉语言模型(22.91 亿参数用于微调)和一组新的动作专家参数(3.15 亿参数) - 采用分块因果掩码,使得
- 该模型通过动作专家输出的动作块上的流匹配损失进行训练
// 后面会对这个π0的简单实现做下解读
update:还没来得及对其做解读,结果如本文开头所述,25年2.4日,π0开源了,详见
- 《π0开源了且推出自回归版π0-FAST——打造机器人动作专用的高效Tokenizer:比扩散π0的训练速度快5倍但效果相当》
-
《π0源码剖析——从π0模型架构的实现(如何基于PaLI-Gemma和扩散策略去噪生成动作),到基于C/S架构下的模型训练与部署》
第三部分(选读) 详解Transfusion和Playground v3
3.1 Transfusion:既可以预测下一个token,又可以扩散图像
3.1.1 Transfusion的提出
来自Meta、Waymo、南加州大学的研究者们推出了Transfusion:使用一个多模态模型预测下一个token并扩散图像,其参数大小为7B,其对应的论文为《Transfusion: Predict the Next Token andDiffuse Images with One Multi-Modal Model》
具体而言,作者通过在50%文本和50%图像数据上预训练一个Transformer模型来得到Transfusion,且对每种模态使用不同的目标:文本使用下一个token预测,图像部分采用扩散方法。模型在每一步训练中都接触到两种模态及其各自的损失函数
- 标准嵌入层将文本token转换为向量,而patch化层则表示将每张图像视为一系列patch向量序列。且作者对文本token应用因果注意力机制,对图像patch采用双向注意力机制
- 对于推理,作者引入了一种解码算法,将语言模型的文本生成标准实践与扩散模型的图像生成相结合
如下图所示「离散(文本)token以自回归方式处理,并在下一个token预测目标上进行训练。连续(图像)向量并行处理并在扩散目标上进行训练。其中,BOI和EOI标记用于分隔模态」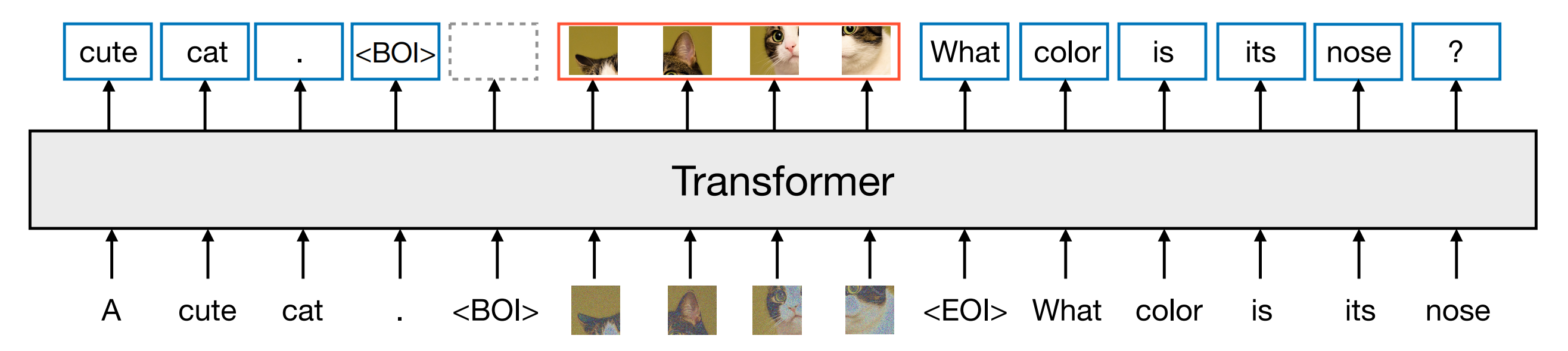
3.1.2 扩散与潜在图像表示
对于文本预测任务来说,比较简单,比如
- 给定一个从一个封闭词汇
中抽取的离散token序列
,语言模型预测该序列的概率
- 标准语言模型将
分解为条件概率的乘积——
这形成了一个自回归分类任务,其中每个token的概率分布是在序列前缀
的条件下,利用由
参数化的单一分布
进行预测
This creates an autoregressive classification task, where the probability distribution of each token yi is predicted conditioned on the prefix of asequence y<i using a single distribution Pθ parameterized by θ
且可以通过最小化在训练完成后,语言模型还可以通过从模型分布
接下来,我们重点看下扩散和潜在图像表示
去噪扩散概率模型(又称DDPM或扩散模型),其基于学习「逆转逐步加噪」过程的原理[即Denoising diffusion probabilistic models (a.k.a. DDPM or diffusion models) operate on the principle of learning to reverse a gradual noise-addition proces]
与通常处理离散token 的语言模型不同,扩散模型在连续向量
上运行,这使其尤其适用于处理图像等连续数据的任务
扩散框架包含两个过程:前向过程描述原始数据如何被转化为噪声,反向过程则是模型学习执行的去噪过程
- 前向过程
从数学角度来看,前向过程定义了带噪数据(作为模型输入)的生成方式
给定一个数据点,Ho等人[2020]定义了一个马尔可夫链,该链在T步内逐步加入高斯噪声,生成一系列噪声逐渐增加的版本
该过程的每一步由定义,其中
随着时间按照预设的噪声计划递增
且该过程可以重新参数化,使得能够通过一次高斯噪声采样直接从
:
这里,,为原始马尔可夫链提供了一个有用的抽象。实际上,训练目标和噪声调度器最终都是以这些术语来表达(和实现)的
如果对上面整个过程还不太理解的,或想深入了解更多细节的,均可以参看此文《图像生成发展起源:从VAE、VQ-VAE、扩散模型DDPM、DETR到ViT、Swin transformer》的第二部分——扩散模型DDPM:先前向加噪后反向去噪从而建立噪声估计模型 - 反向过程
扩散模型被训练来执行反向过程,学习逐步去噪数据
对此,有多种方法可以做到这一点;在这项工作中,遵循Ho等人[2020]的方法,将方程中的高斯噪声ϵ 作为第
步累计噪声的代理「we follow the approach of Ho et al. [2020] and model the Gaussian noise ϵ in Equation 2 as a proxy for the cumulative noise at step t.」
具体来说,具有参数θ的模型被训练用于在给定加噪数据
进行条件建模,例如在生成图像时使用标题
因此,噪声预测模型的参数通过最小化均方误差损失来优化
在噪声设计上,在创建带噪示例时,
决定了时间步长
的噪声方差。在本研究中,一般采用常用的余弦调度器Nichol andDhariwal[2021],该调度器在很大程度上遵循
,并进行了一些调整
在推理上,解码是迭代完成的,在每一步中逐渐去除一部分噪声。从纯高斯噪声开始,模型
预测在时间步
累积的噪声
然后,按照噪声调度表示对预测噪声进行缩放,并从中移除相应比例的预测噪声,从而得到
实际上,推理过程中的时间步数通常少于训练时的时间步数。无分类器引导——CFG[Ho 和 Salimans, 2022] 常用于通过对比模型在有条件上下文 与无条件预测下的输出,从而提升生成效果,但其计算量会增加一倍
想深入了解更多细节的,可以参看此文《图像生成发展起源:从VAE、VQ-VAE、扩散模型DDPM、DETR到ViT、Swin transformer》
进一步,早期的扩散模型直接在像素空间中工作[Ho et al., 2020],但这在计算上非常昂贵。变分自编码器(VAEs)[Kingma and Welling, 2013]通过将图像编码到低维潜在空间中,能够节省计算资源
- 现代 VAE 以深度卷积神经网络(CNN)实现,并通过重构损失与正则化损失的结合进行训练[Esser 等, 2021],从而使下游模型如潜在扩散模型(LDM)[Rombach 等,2022a] 能够高效地在紧凑的图像块嵌入上运行
例如,将每个8×8像素块表示为一个8维向量。对于自回归语言建模方法[Ramesh et al., 2021, Yu et al., 2022],图像必须被离散化 - 离散自编码器,如矢量量化VAE(VQ-VAE)[Van Den Oord et al., 2017],通过引入量化层(及相关的正则化损失),将连续的潜在嵌入映射为离散的token,实现了这一目标
3.1.3 Transfusion的数据表示、模型架构、注意力、训练目标、推理
Transfusion主要创新在于可以针对不同模态采用不同的损失函数——对文本使用语言建模损失,对图像采用扩散损失——并在共享的数据和参数上进行训练
下图图1展示了Transfusion的过程
第一,在数据表示上
- 作者在实验中使用了两种模态的数据:离散文本和连续图像。每个文本字符串被分词为一个固定词汇表中的离散token组成的序列,每个token用一个整数表示
- 每幅图像则通过VAE编码为潜在patch块,每个patch用一个连续向量表示;这些patch按从左到右、从上到下的顺序排列,从每幅图像生成一组图像块向量序列
- 对于混合模态的样本,作者在每个图像序列前后分别添加特殊的图像开始(BOI)和图像结束(EOI)标记,然后将其插入到文本序列中
因此,最终最终得到一个可能同时包含离散元素(表示文本token的整数)和连续元素(表示图像块的向量)的单一序列
第二,在模型架构上
绝大多数模型的参数属于一个单一的transformer,无论模态如何,它都会处理每一个序列。transformer接收一个高维向量序列作为输入,并生成类似的向量作为输出
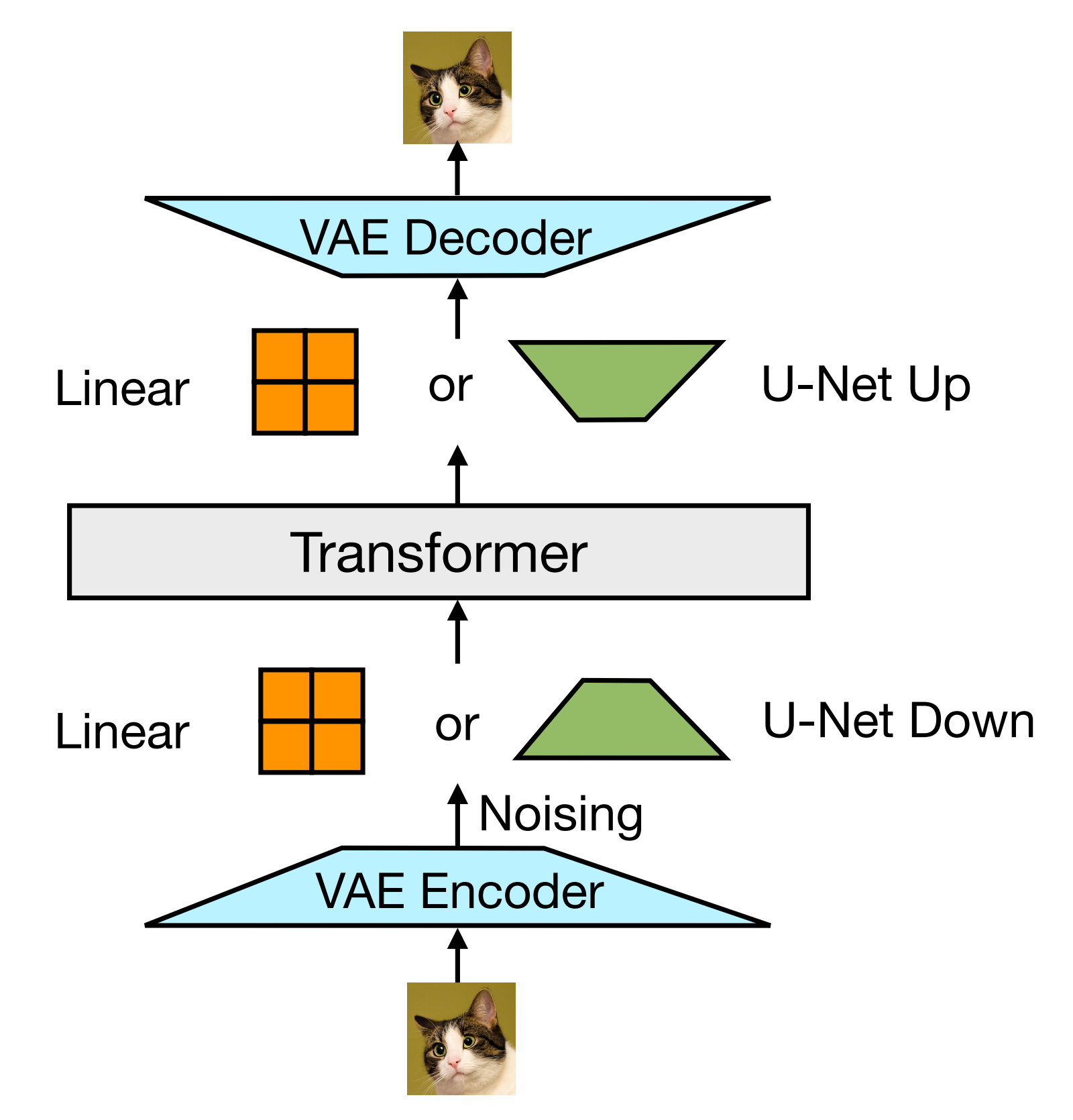
该transformer 以中的高维向量序列作为输入,并产生类似的向量作为输出,为了将作者的数据转换到这个空间中,作者使用轻量级、模态特定且参数不共享的组件
- 对于文本,这些是嵌入矩阵,将每个输入整数转换为向量空间,并将每个输出向量转换为词汇表上的离散分布
- 对于图像,作者尝试了两种不同的方法,将
的局部patch向量压缩为一个单一的transformer向量
1 一个简单的线性层
2 以及U-Net的上采样和下采样模块[Nichol和Dhariwal,2021,Saharia等,2022]
总体架构如下图图3所示
第三,在Transfusion 注意力上
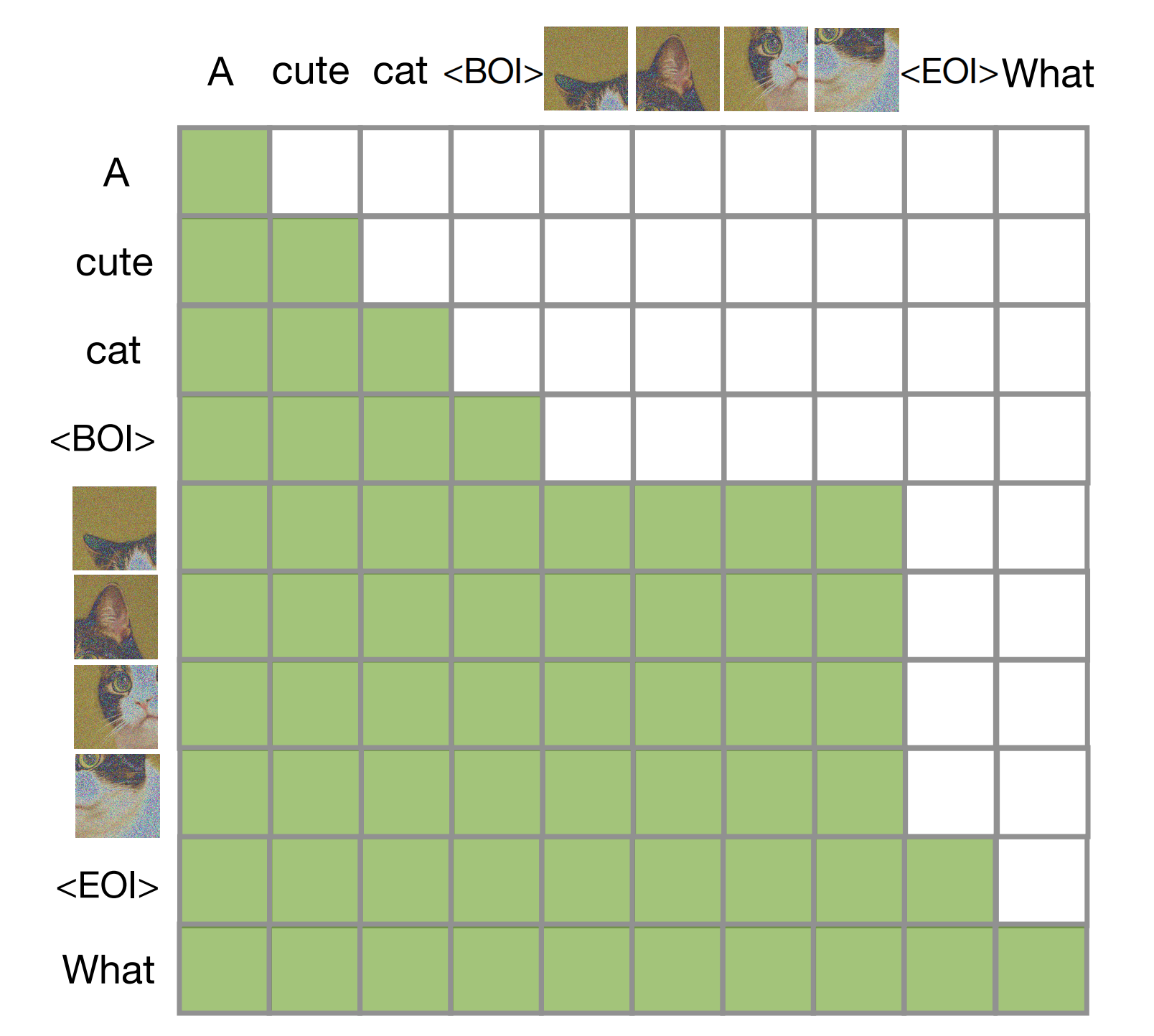
- 语言模型通常采用因果掩码,以便在一次前向-反向传播中高效地计算整个序列的损失和梯度,同时避免未来token的信息泄露。尽管文本本质上是序列化的,但图像并非如此,通常采用无约束(双向)注意力进行建模
- 故,Transfusion 结合了这两种注意力模式:对序列中的每个元素应用因果注意力,同时在每张图像的各元素之间应用双向注意力。这使得每个图像块能够关注同一图像中的其他所有块,但只能关注序列中先前出现的文本或其他图像的块「This allows every image patch to attend to every other patch with in the same image, but only attend to text or patches of other images that appeared previously in the sequence」。故作者发现,启用图像内部的注意力显著提升了模型性能
下图图4展示了一个Transfusion注意力掩码的例子
第四,在训练目标上
- 为了训练模型,作者对文本token的预测应用语言建模目标
,对图像块的预测应用扩散目标
- 具体来说,作者根据扩散过程向每个输入潜在图像
最终,通过简单地将每种模态计算的损失相加,并使用平衡系数λ,来结合这两种损失(离散分布损失与连续分布损失相结合以优化同一模型)
第五,在推理上
反映着训练目标,解码算法也在两种模式之间切换:LM 和扩散
- 在 LM模式下,遵循标准做法,从预测分布中逐个采样 token
- 当采样到BOI token时,解码算法切换到扩散模式,即按照扩散模型的标准解码流程进行
具体来说,将纯噪声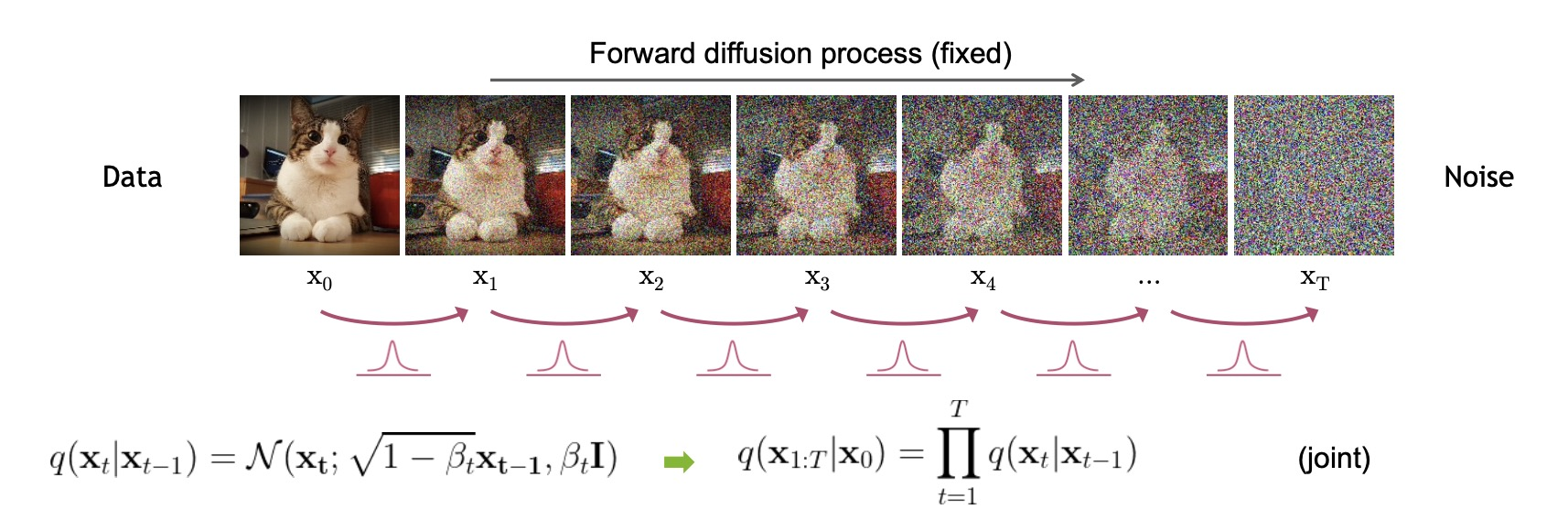
「以图像 patch 的形式,根据期望的图像大小」添加到输入序列中,并在 T 步内进行去噪
在每一步 t,根据噪声预测生成,并用其覆盖序列中的
也就是说,模型始终以噪声图像的最后一个时间步为条件,无法关注先前的时间步「the model always conditions on the last timestep of the noised image and cannot attend to previous timesteps」
如下图所示,便是一步步去噪的过程:基于
一旦扩散过程结束,则在预测的图像后添加 EOI token,并切换回 LM 模式。该算法能够生成任意混合的文本和图像模态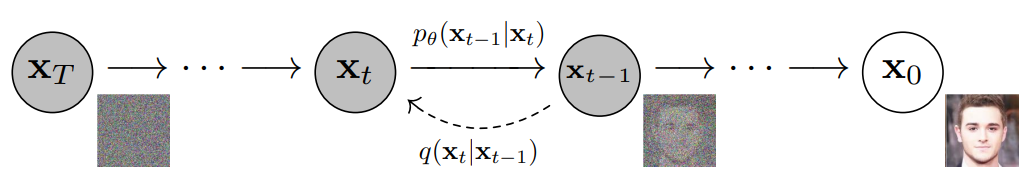
3.2 Playground v3
// 待更
第四部分(选读) π0之外,流匹配与修正流Rectified Flow在机器人领域的其他应用
关于什么是流匹配Flow Matching与修正流Rectified Flow,详见此文《文生图中从扩散模型到流匹配的演变:从SDXL到Stable Diffusion3(含Flow Matching和Rectified Flow的详解)》的第五部分
考虑到有朋友问:“感觉pi0特点是不是就是flow matching,有其他的论文也是这么做的吗”,SD3之类的我就不说了,我重点说下这两在机器人领域的其他应用
4.1 用于多支撑操控的流匹配模仿学习
4.1.1 Flow Matching Imitation Learningfor Multi-Support Manipulation
24年7月,来自法国国家信息与自动化研究所的研究者们提出了「用于多支撑操控的流匹配模仿学习」的方法,其对应的论文为《Flow Matching Imitation Learning for Multi-Support Manipulation》
4.1.2 相关工作与提出背景
传统的BC方法,如DMP[6]或ProMPs[7],在演示的状态空间分布内的简单任务中表现良好
- 但容易出现预测误差累积,进而导致状态发散和失败
为了解决这个问题,作者的策略预测动作轨迹,与以下最新的三个工作
9-即上文提到过的Diffusion Policy
24-即上面提到过的ACT
25-3D Diffusion Policy,详见此文《斯坦福iDP3——改进3D扩散策略以赋能人形机器人的训练:不再依赖相机校准和点云分割(含3D扩散策略DP3的详解)》的第一部分
从而增强了时间上的连贯性,并缓解了误差累积的问题 - BC的另一个局限性在于处理人类演示中的多样性、无效动作以及解决同一任务时采用的不同策略。这些演示数据构成了一个多模态分布,并且可能是非凸的,因此对数据进行平均处理存在风险,可能导致任务失败
近期的方法通过将BC的策略重新表述为生成式过程,来应对这一问题
去噪扩散概率模型(DDPM)[10] 已成为一种新型的生成模型类别,其性能优于以往的生成模型
DDPM 通过逆转一个扩散过程,将噪声逐步添加到干净样本中,直到其变为高斯噪声
随后,通过求解随机微分方程,从噪声中生成干净样本
而去噪扩散隐式模型(DDIM)[26] 则将逆过程视为常微分方程进行求解,从而减少推理步骤,加快计算速度,但以牺牲部分生成质量为代价 - 最初,DDPM/DDIM这些方法 被用于图像生成,但近期的研究
[8-“Planning with diffusion for flexible behavior synthesis]
[9-Diffusion Policy]
[25-3D Diffusion Policy]
[27-Diffusion models for reinforcement learning: A survey]
已将这些最初用于图像生成的技术应用于强化和模仿学习
它们能够生成模仿人类演示的动作轨迹,条件依赖于任务的状态,有效捕捉高维概率分布,并能够处理具有多个模态的非凸、非连通分布
而流匹配[13]是一种基于最优传输理论
- [11-Stochastic interpolants: A unifying framework for flows and diffusions]
- [12-Building normalizing flows with stochastic interpolants]
的新型生成方法,在理论上与 DDPM 和 DDIM有相似之处
- 相比,Flow Matching 更为简单,超参数更少,数值上也更加稳定
Flow Matching 能够在传输流中产生更为笔直的路径,从而在给定积分步数的情况下提升生成质量,或者在相同质量下通过减少步数实现更快的推理速度,这对于实时机器人应用至关重要 - 与
[28-RF-POLICY: Rectified flows are computation-adaptive decision makers]
[29- “AdaFlow: Imitation learning with variance-adaptive flow-basedpolicies]
[30-Riemannian flow matching policy for robot motion learning]
一致
这些研究已在模拟机器人任务中展示了 flow 相较 diffusion的改进,且作者进一步研究了 Flow Matching 在机器人领域的应用,并将其部署在真实的人形机器人上
4.2 整体方法
作为一种基于示范学习的方法,使人形机器人能够执行多支撑操作任务,通过增加接触点和全身运动来增强操作能力
这些任务可以自主执行,也可以通过辅助共享自主方式完成,即人类操作员部分控制机器人,而学习得到的策略则提供辅助和接触点的选择
总之,作者强调了他们的方法如何处理接触切换过渡,并在实际硬件上控制由此产生的多接触运动
4.2.1 整体架构
作者设计了一个包含两个层级模块,以增强系统的鲁棒性「系统架构使用三种不同的操作模式(右)作为高层控制器输出执行器命令。这些命令通过SEIKO Retargeting [31], [32] 和 SEIKO Controller [22] 在机器人上实现(左)」
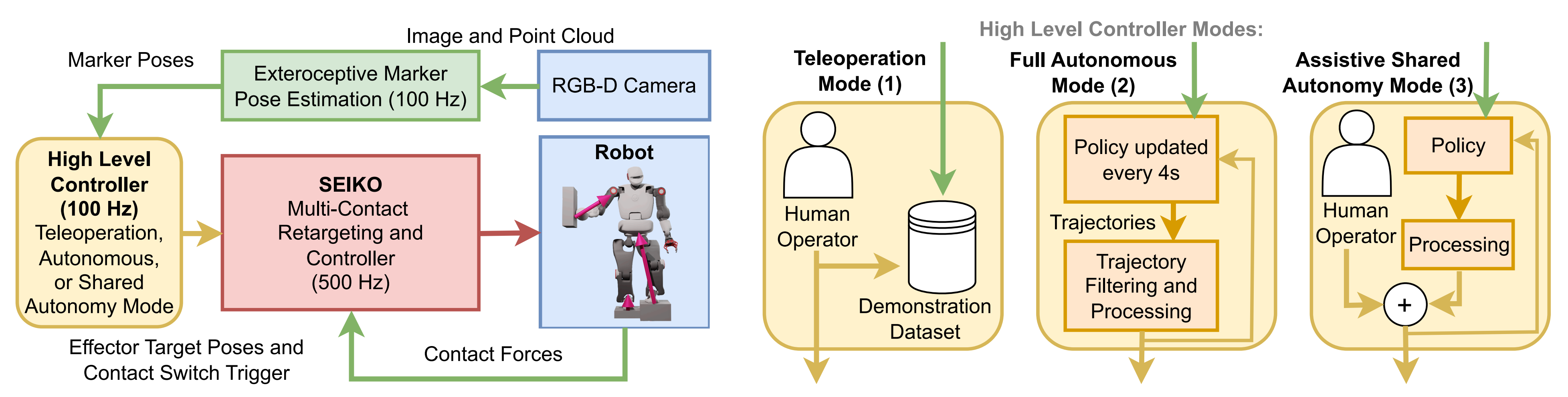
- 基于模型的低层控制器,负责全身优化、多接触力分配、接触切换与跟踪,并严格遵守可行性约束
A model-based low-levelcontroller addresses whole-body optimization, multi-contact force distribution, contact switching and tracking with strictfeasibility constraints. - 基于学习的高层控制器,则处理理笛卡尔末端执行器命令、接触位置和动作序列
高层控制器输出世界坐标系下的笛卡尔位姿目标,以及每个执行器的接触切换命令
A learning-based high-level controllerhandles Cartesian effector commands, contact locations, andsequencing.
It outputs a Cartesian pose target in world frameand a contact switch command for each effector.
执行器可以处于与环境固定接触的状态(启用状态),主动施加力以平衡机器人,或处于未接触、可自由移动(禁用状态)
接触切换命令是一个离散信号,用于触发低层控制器实现启用与禁用状态的切换
Effectors caneither be fixed in contact with the environment (enabled state),actively applying forces to balance the robot, or not in contactand free to move (disabled state).
The contact switch commandis a discrete signal that triggers the transition between enabledand disabled states implemented by the low-level controller.
下图图2中的高层控制器支持三种不同的工作模式,如下图右侧所示
- 远程操作模式用于创建数据集,记录发送给低层控制器的执行器命令,及机器人头部摄像头检测到的外部标记的位姿
The teleoperation mode is used to create a dataset recording effector commands sent to the low-level controller and poses of external markers detected by the robot’s head camera.
人类操作员直接指挥机器人采集演示数据,既可从随机初始状态完成任务,也可从手动选择的异常状态执行恢复操作
The human operator directly commands the robot to collect demonstrations, solving the task from randomizedinitial states or performing recovery actions from manuallyselected states outside nominal execution. - 自主模式则利用模仿收集到的演示数据训练出的策略独立完成任务
- 辅助共享自主模式结合了人类与策略的命令,以应对分布外任务
在该模式下,操作员控制一个执行器,其余由策略自主管理
策略在共享自主与完全自主模式下输入和后处理方式一致「The operator commands one effector while the policy autonomously manages the others. The policyuses identical inputs and post-processing in both shared andfull autonomous modes.」
但在共享自主模式下,操作员的命令会替代其所控制执行器的策略输出「However, in shared autonomy mode,the operator’s commands replace the policy’s output for the effector they control.」
尽管[9-DP],[25-DP3]表明基于扩散的模仿学习可以从原始图像或点云中学习,但作者选择在本研究中使用基准标记来监控任务的外部感知状态
这能够将注意力集中在与接触切换和多接触相关的挑战上。机器人头部的RGB-D相机通过AprilTags系统[33]在彩色图像中检测这些标记
从点云中提取标记在相机坐标系下的三维位置和姿态
随后,这些坐标通过正向运动学模型转换到机器人世界坐标系下
在人类专家演示过程中,标记的姿态会被记录到数据集中,并作为输入提供给自主策略
4.2.2 行为克隆策略与接触切换
// 待更
4.2.3 使用流匹配进行轨迹生成
行为克隆策略构建为一种生成式过程,该过程从数据中学习概率分布,并从中采样新的元素。由此产生的策略是随机的,能够采样出在相同状态下模仿人类操作员演示的轨迹
具体而言,作者采用流匹配方法[13-Flow straight and fast: Learning to generate and transfer data with rectified flow],该方法构建了一个流向量场,能够将源概率分布连续地变换为目标概率分布
下图图1展示了一个流将可以轻松采样的一维简单源分布,转化为更复杂的多峰分布的过程
- 流匹配方法基于最优传输理论,可被视为扩散方法[11]的确定性对应方案。在从源分布采样之后,流的积分过程会以确定性的方式生成目标分布的样本,这与扩散方法[10]在传输过程中引入噪声不同
流匹配通常产生更为直线的流,使得推理速度更快 - 流匹配的训练定义如下
// 待更

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 98
98 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)