
【AI数字人教程】一幅图生成数字人,阿里EchoMimicV2两种部署方式教程
(全套教程文末领取哈)
阿里推出的开源数字人项目EchoMimicV2,相比之前版本,可以用一张图生成半身人像视频,适应更多的应用场景。

首先看效果,依旧请寡姐当模特:
生成结果(声音是AI生成):
EchoMimicV2可以直接部署,也可以通过ComfyUI部署,下面分别列出两种方法:
一、常规部署
请确保你已经安装了Python、Git等工具,并且网络畅通,在你想安装的文件夹处(此处为K盘)输入cmd,打开命令行窗口:
按照顺序,依次执行下列命令:
git clone https://github.com/antgroup/echomimic_v2
cd echomimic_v2
conda create -n echomimic python=3.10
conda activate echomimic
pip install pip -U
pip install torch2.5.1 torchvision0.20.1 torchaudio2.5.1 xformers0.0.28.post3 --index-url https://download.pytorch.org/whl/cu124
pip install torchao --index-url https://download.pytorch.org/whl/nightly/cu124
pip install -r requirements.txt
pip install --no-deps facenet_pytorch==2.6.0
EchoMimicV2需要用到ffmpeg-static,在这里下载:
https://www.johnvansickle.com/ffmpeg/old-releases/ffmpeg-4.4-amd64-static.tar.xz
把下载的文件解压,本教程中,我放在K:\echomimic_v2\ffmpeg-4.4-amd64-static
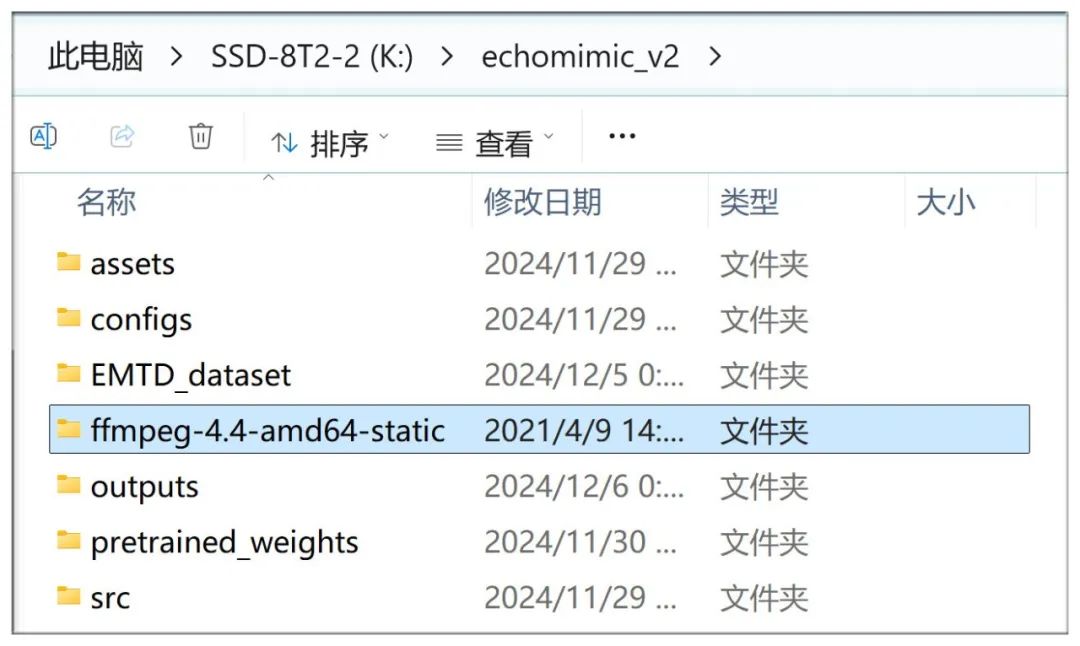
右键点击Windows的“此电脑”选择“属性”,来到这个界面,输入“高级系统设置”,点击:
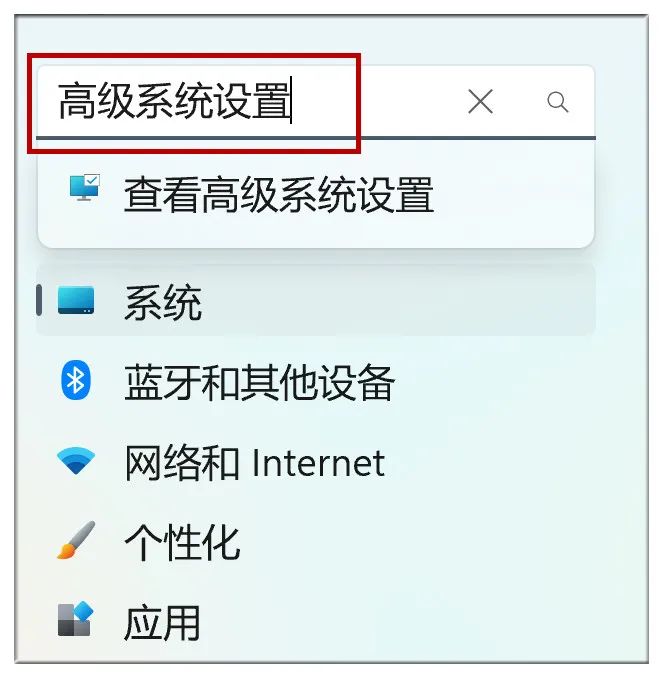
跳出这个窗口,点击“环境变量”:
在新跳出的窗口中,点击“新建”:
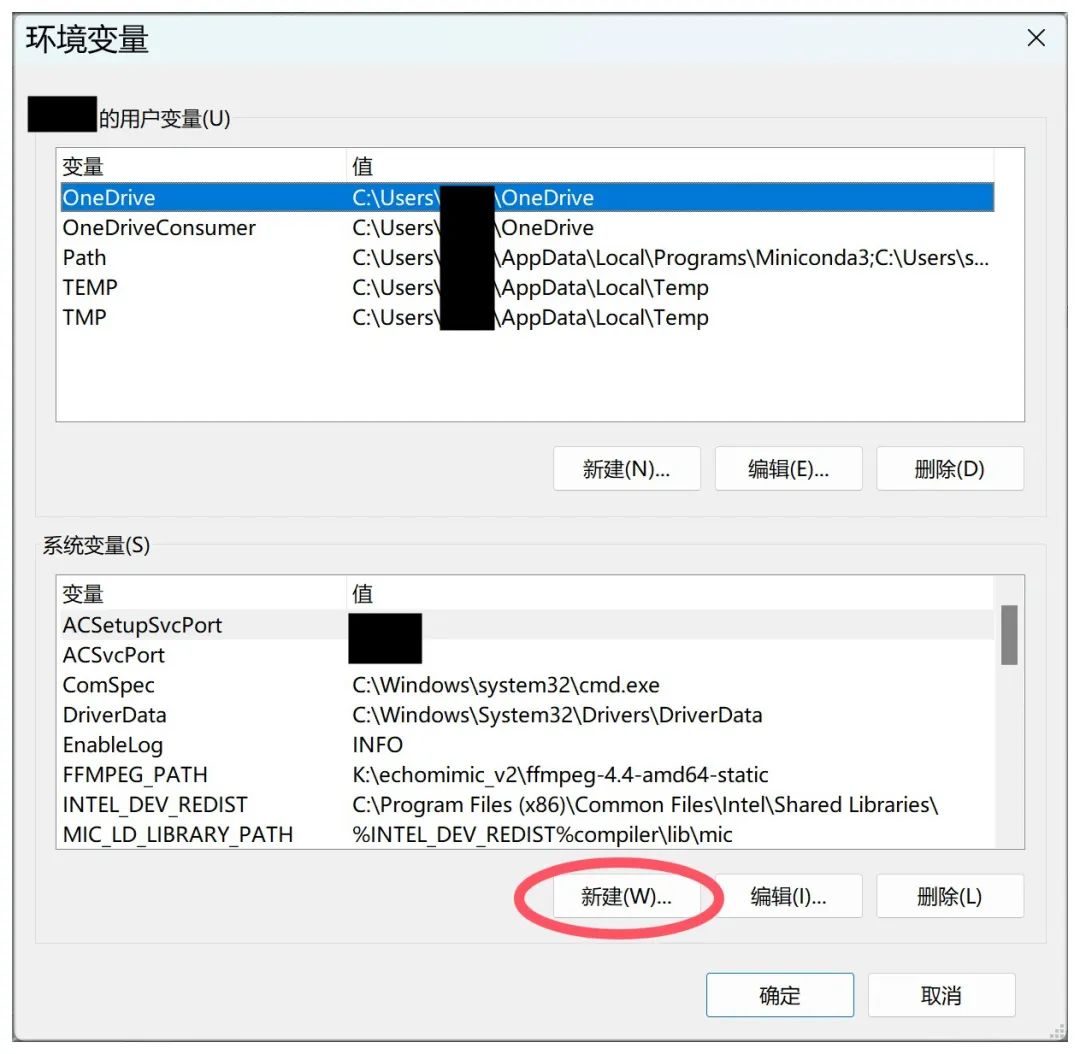
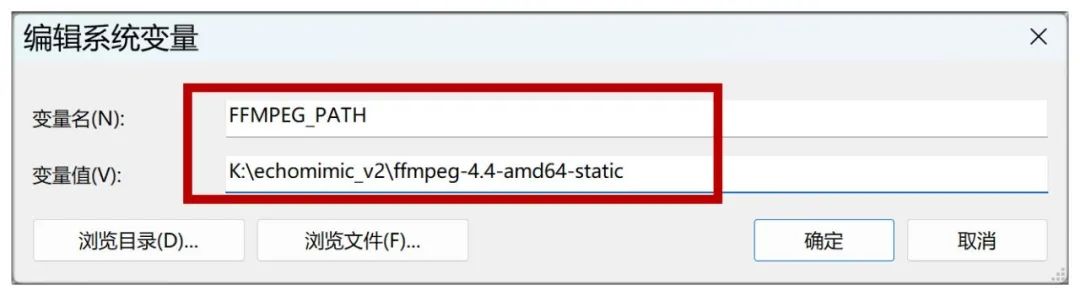
在“变量名”中填入FFMPEG_PATH,在“变量值”中填入刚才解压后的目录,这里是K:\echomimic_v2\ffmpeg-4.4-amd64-static
之后就是安装模型,依次执行下列命令:
git lfs install
git clone https://huggingface.co/BadToBest/EchoMimicV2 pretrained_weights
完成之后,EchoMimicV2目录下会建立一个pretrained_weights目录,里面已经有了基本的模型,但还需要下载其它几个相关模型:
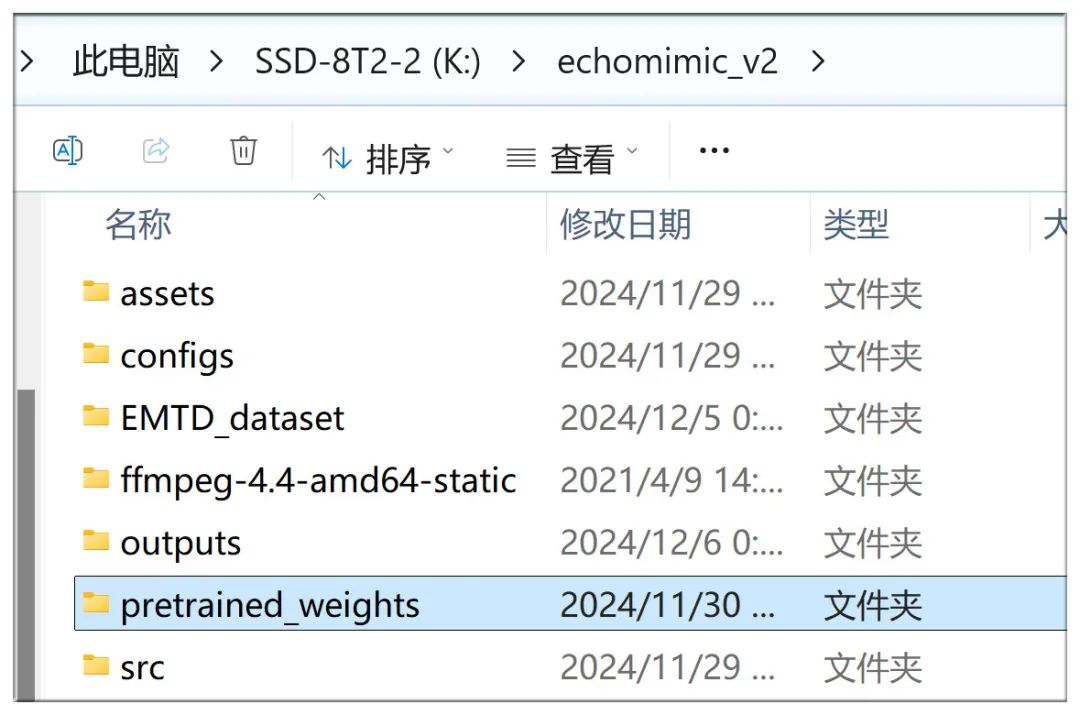
首先进入pretrained_weights目录,通过命令行输入:
git clone https://huggingface.co/stabilityai/sd-vae-ft-mse
git clone https://huggingface.co/lambdalabs/sd-image-variations-diffusers
直接下载tiny.pt文件,并放到audio_processor子目录里(没有就手动建一个),下载链接:https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt
完成之后,pretrained_weights目录结构是这样:

至此安装完毕,运行下面的命令,进入主界面:
python app.py
可以看到,工具主界面非常简洁,这里就不多解释。
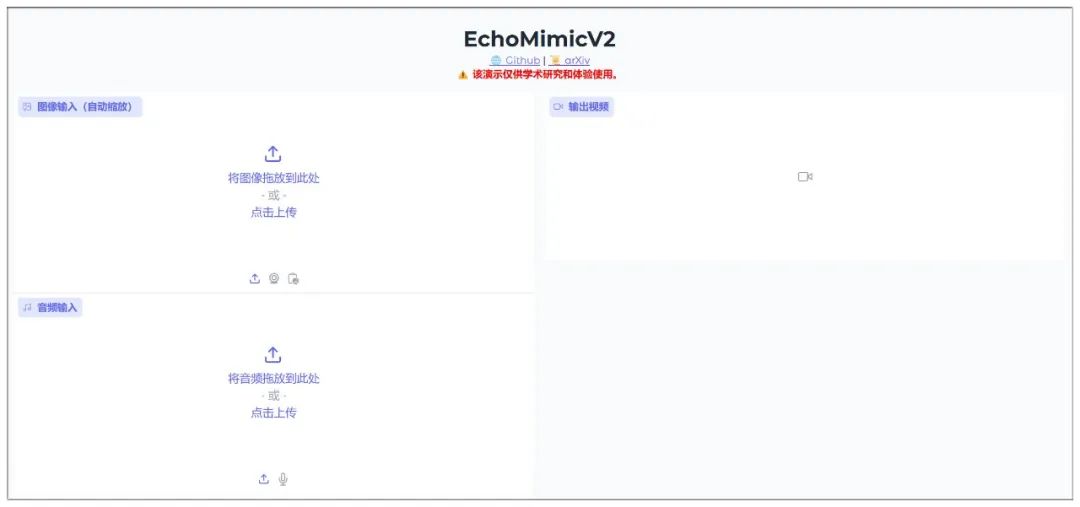
生成视频之后,主界面的样子:
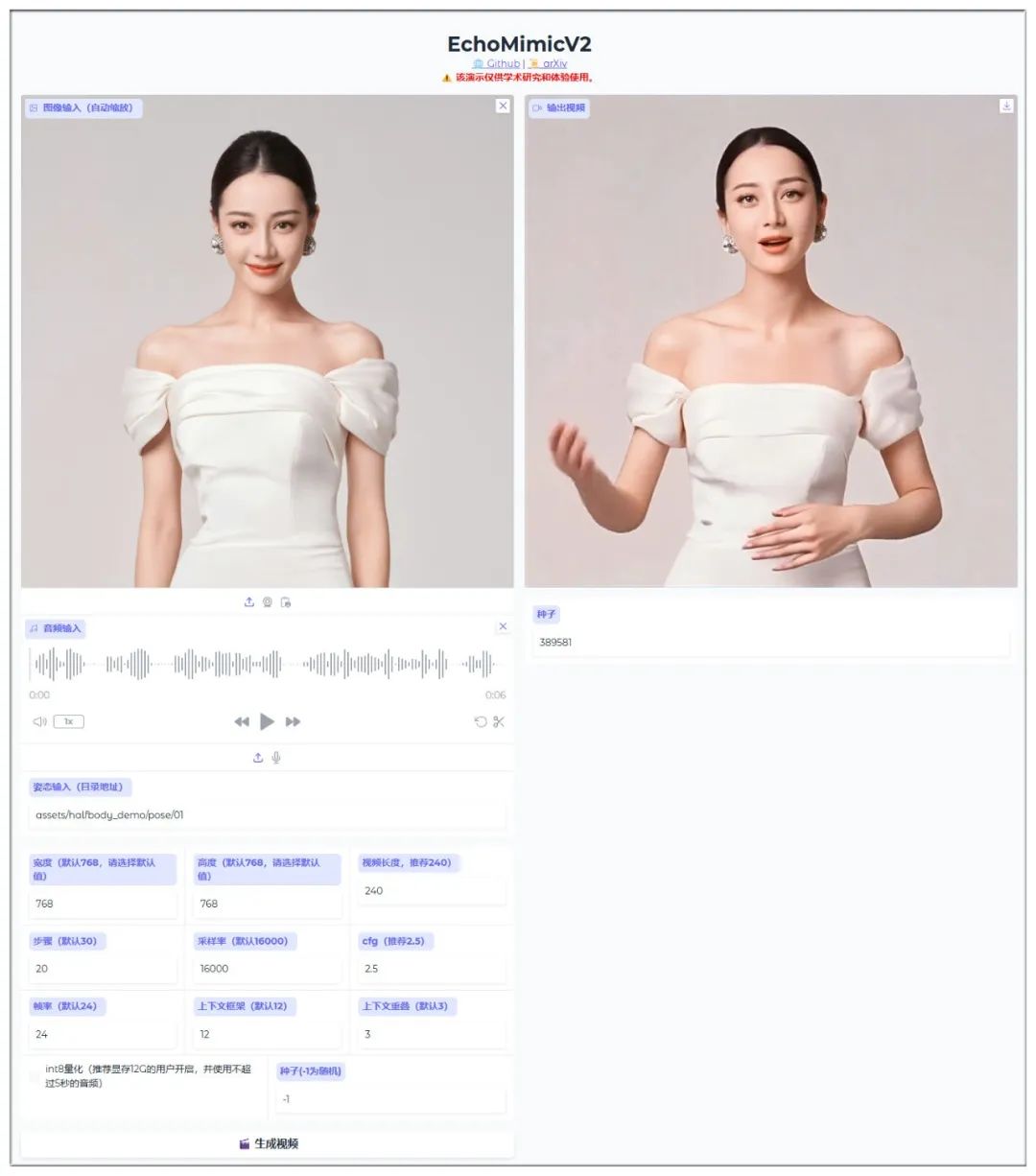
主界面列出了不少参数,按照官方说法,最好不要修改,否则容易崩坏。另外,如果有自己的姿态文件,可以通过“姿态输入”栏调用:

为方便使用,请建一个批处理文件,比如run.bat,内容如下:
@echo off
call conda activate echomimic
python app.py
pause
今后只要执行run.bat就可以了。
二、在ComfyUI当中部署
首先你应该已经安装了ComfyUI最新版,然后进入命令行模式,在/ComfyUI/custom_node目录下,依次运行:
git clone https://github.com/smthemex/ComfyUI_EchoMimic.git
cd ComfyUI_EchoMimic
pip install -r requirements.txt
pip install --no-deps facenet-pytorch
如果没安装过ffmpeg,则需要执行安装命令:
pip install ffmpeg-python
模型都需要手动下载并放置,具体如下:
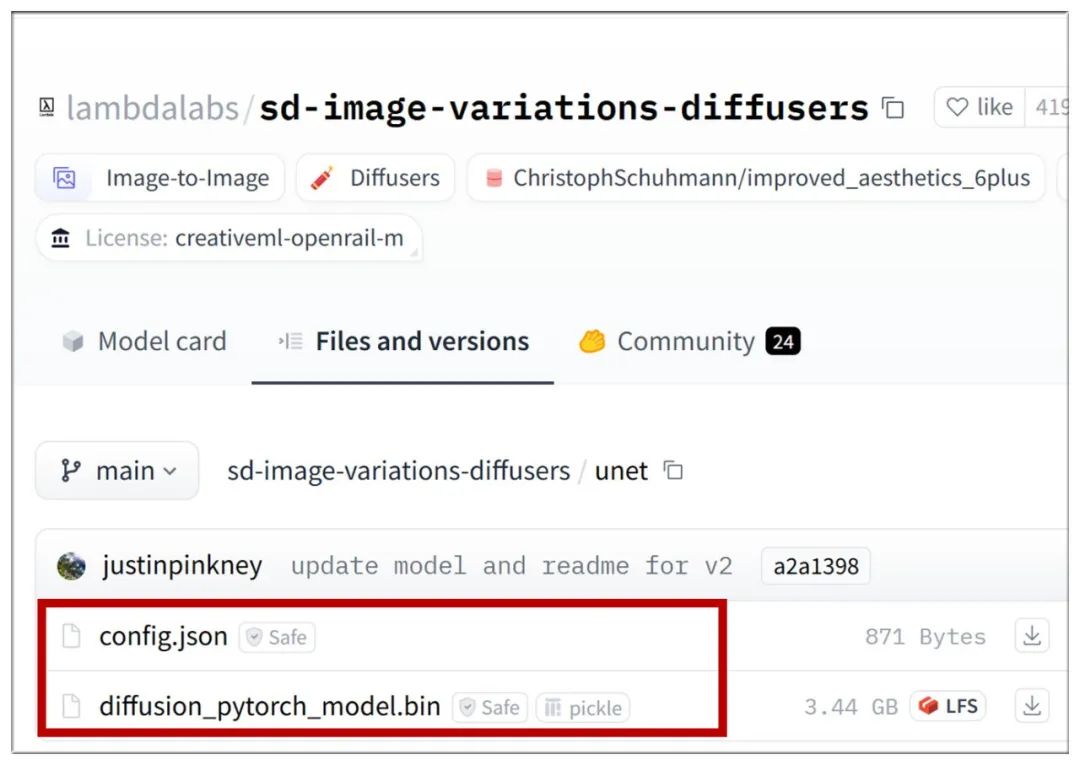
unet模型,放在/ComfyUI/models/echo_mimic/unet目录下:
https://huggingface.co/lambdalabs/sd-image-variations-diffusers/tree/main/unet
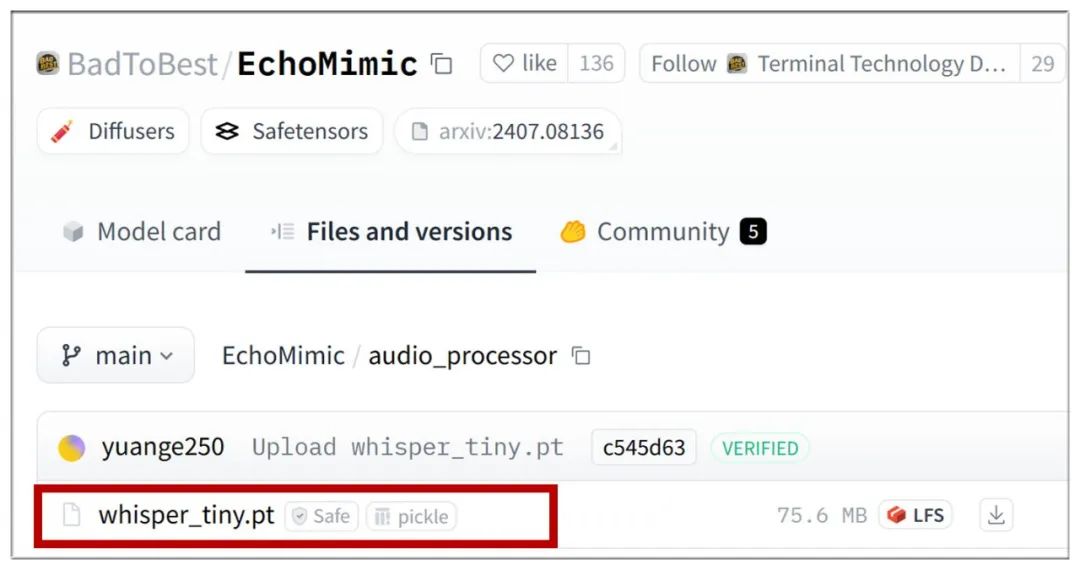
声音模型,放在/ComfyUI/models/echo_mimic/audio_processor目录下:
https://huggingface.co/BadToBest/EchoMimic/tree/main/audio_processor
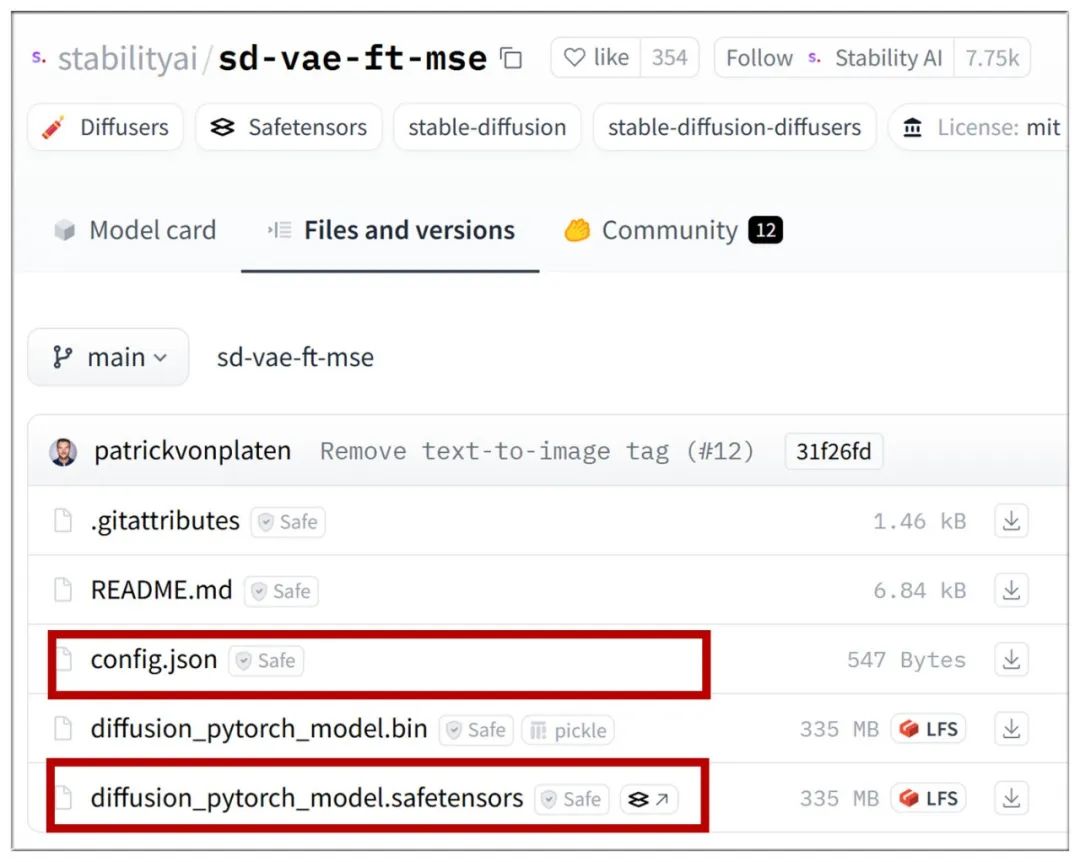
vae模型,放在/ComfyUI/models/echo_mimic/vae目录下:
https://huggingface.co/stabilityai/sd-vae-ft-mse/tree/main
至此,目录结构是这样:

接下来还有主模型需要下载。
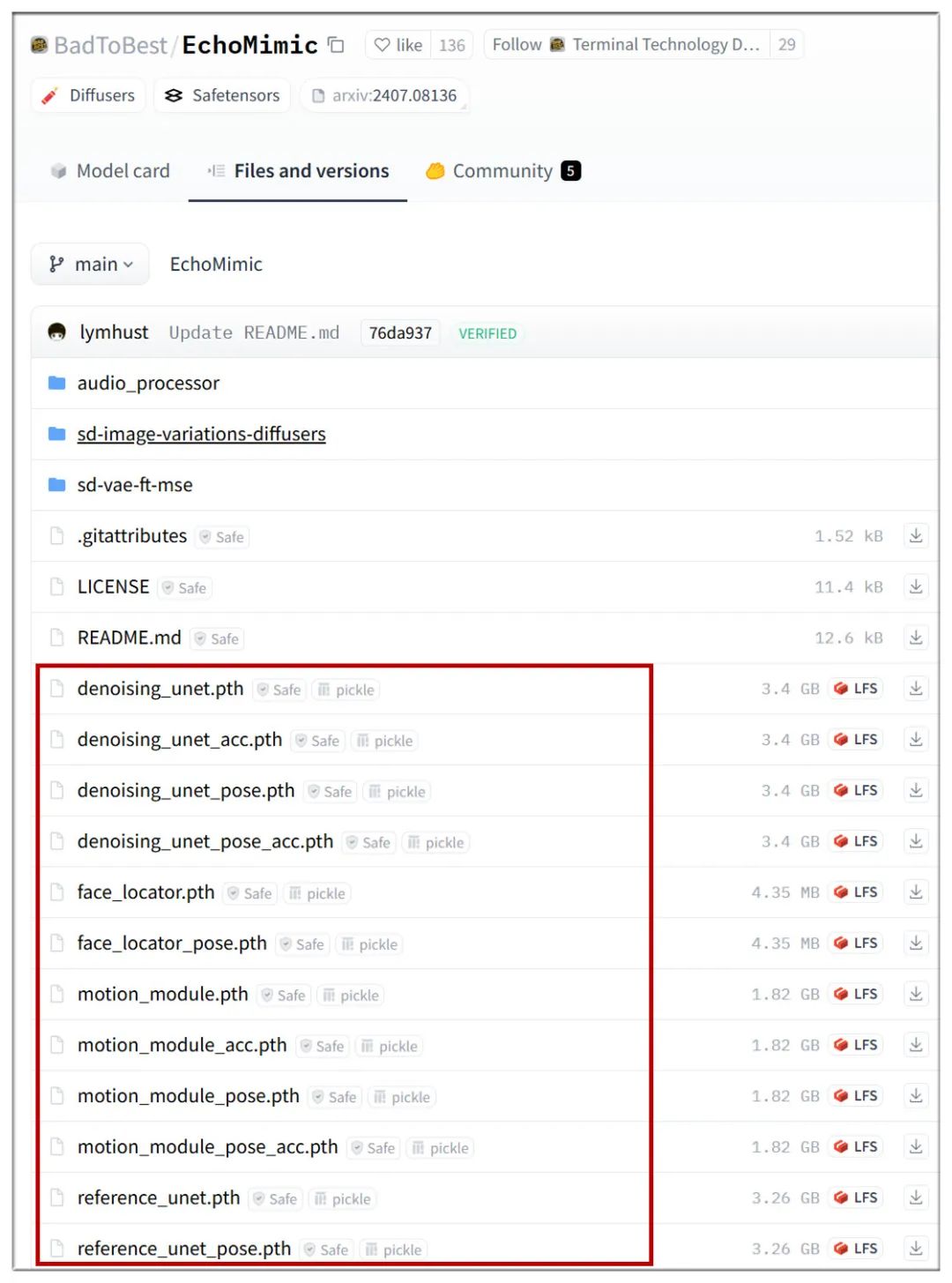
EchoMimicV1版本模型,放在/ComfyUI/models/echo_mimic目录下:
https://huggingface.co/BadToBest/EchoMimic/tree/main
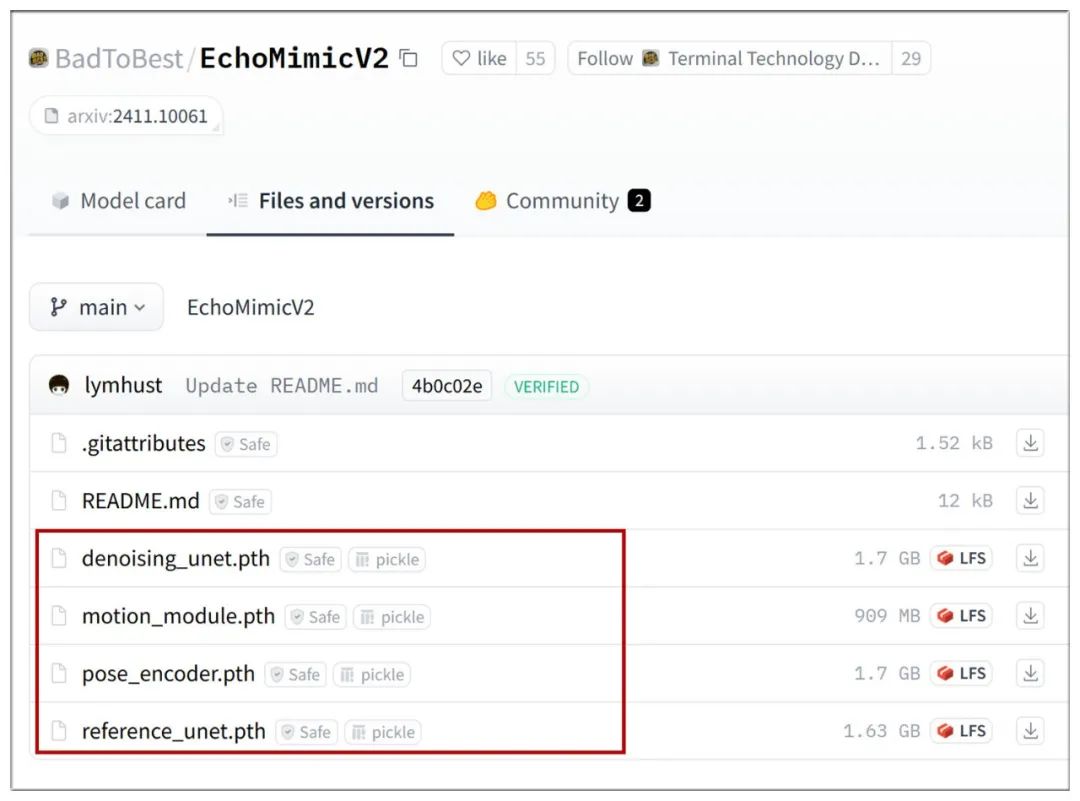
EchoMimicV2版本模型,放在/ComfyUI/models/echo_mimic/v2目录下:
https://huggingface.co/BadToBest/EchoMimicV2/tree/main
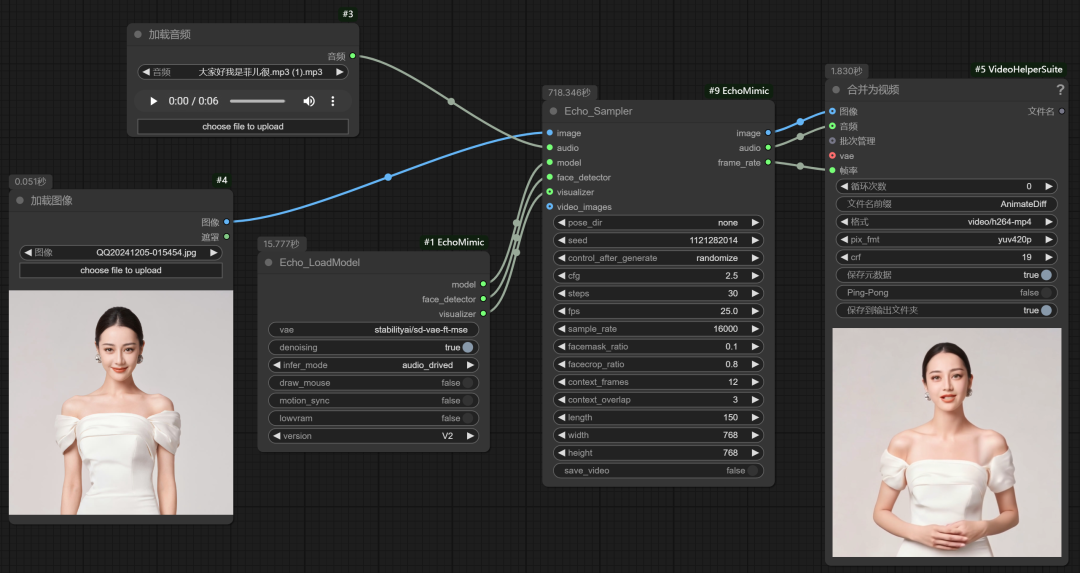
ok,安装基本完成,将工作流拖到ComfyUI界面,测试一下:
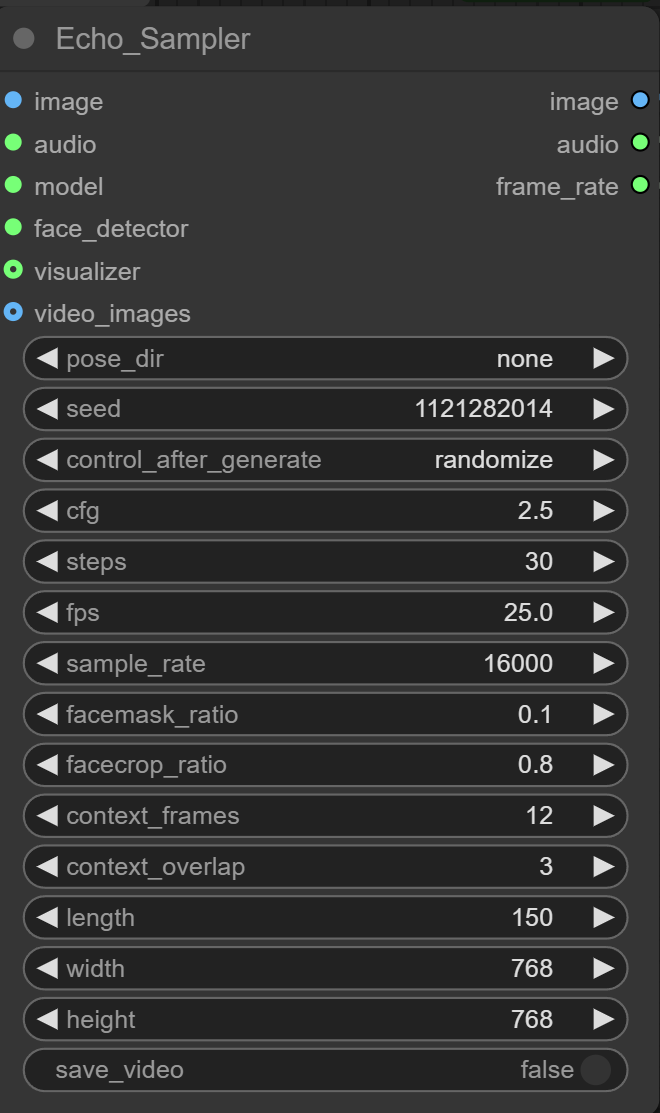
这个面板的参数设置如图,除length(视频长度外)基本不用改:
生成结果:
ComfyUI下不仅可以自定义手势,还可以用其它视频为参考,生成手势。这需要下载额外的模型:
yolov8m.pt,放在/ComfyUI/models/echo_mimic目录下:
https://huggingface.co/Ultralytics/YOLOv8/tree/main
sapiens_1b_goliath_best_goliath_AP_639_torchscript.pt2,放在ComfyUI/models/echo_mimic目录下:
https://huggingface.co/facebook/sapiens-pose-1b-torchscript/tree/main
可参考其它视频手势的工作流,是这个样子:
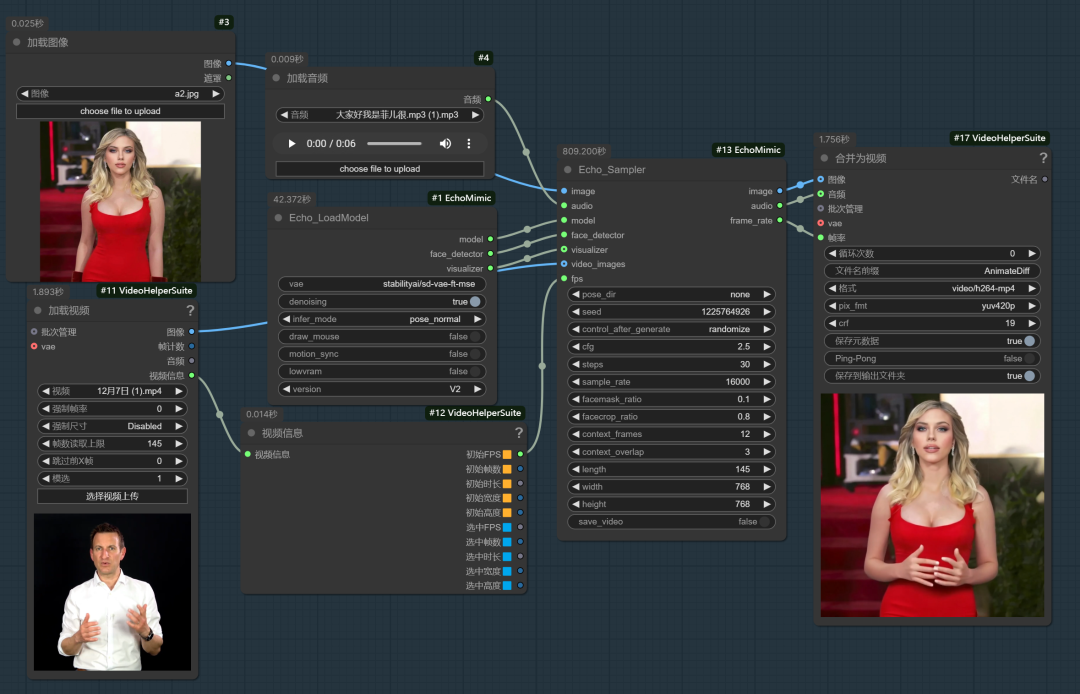
继续使用原来的声音,但改变手势,看看生成效果对比:
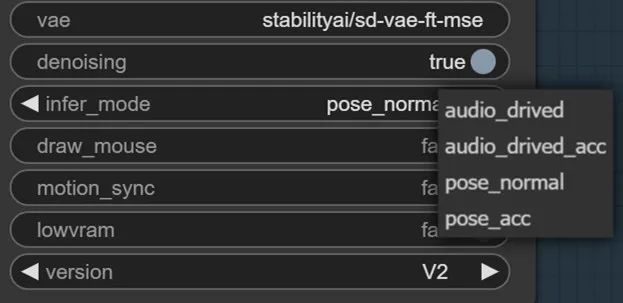
通过infer_mode选项,可以有几种控制人物手势的方式:
1、infer_mode选择audio_drive,pose_dir选择none,人物做出默认手势。
2、infer_mode选择audio_drive,pose_dir选择已有的手势npy文件夹(位于/ComfyUI/input/tensorrt_lite目录),人物做出指定手势。
3、infer_mode选择pose_normal,video_images加载视频,可参考已有视频生成手势。
以上两个工作流的下载链接:
三、几点注意事项
1、根据官方说明,只要显存足够,视频生成时长理论上不受限制。
2、实测目前生成效率不高,4090显卡生成10秒视频基本要十分钟以上。
3、安装时,如ComfyUI出现个别节点红色无法识别的情况,请用ComfyUI Manager(管理器)查找并安装。
文章涉及网址:
EchoMimicV2代码页:
https://github.com/antgroup/echomimic_v2
ComfyUI_EchoMimic代码页:
https://github.com/smthemex/ComfyUI_EchoMimic
ComfyUI代码页:
https://github.com/comfyanonymous/ComfyUI
ComfyUI-Manager代码页:
https://github.com/ltdrdata/ComfyUI-Manager
写在最后
SD全套资料,包括汉化安装包、常用模型、插件、关键词提示手册、视频教程等都已经打包好了,无偿分享,有需要的小伙伴可以自取。



感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
请添加图片描述
若有侵权,请联系删除

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 23
23 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)