遥感变化检测数据集标注讨论
关于遥感变化检测数据集的一些思考和疑问
前言
去年跟着导师做了一段时间的遥感变化检测研究,虽然最终也没有做出啥成果,但是还是累积了自己的一些思考和疑问。最近正好有些时间,想着整理整理,也算是去年的科研总结。(纯主观看法,错漏之处轻喷)
LEVIR-CD数据集
数据集介绍
原论文项目地址
LEVIR-CD原论文包含了一个新提出的变化检测网络以及数据集LEVIR-CD,这里我们就只针对数据集进行研究。
LEVIR-CD主要针对的是建筑物的变化,精度为0.5m/pixel,按照论文所说,其使用的图片源是Google Earth 提供的免费遥感图片,变化图的标注则是由Madacode完成。每个样本都经历了标注、检查两道工序,总计耗时120 人*天。
问题提出
为了寻找对模型进行改进的方法,我将不同时间的图片、GT变化图、模型输出变化图放到一个图片中进行比较,这让我有机会仔细观察数据集,从而发现了一些问题。
(下左图:变化前,下右图:变化后)(test_18.png)
(下左图:GT变化图,下右图:模型输出(绿色表示和GT重合,红色表示多余,黄色表示缺漏))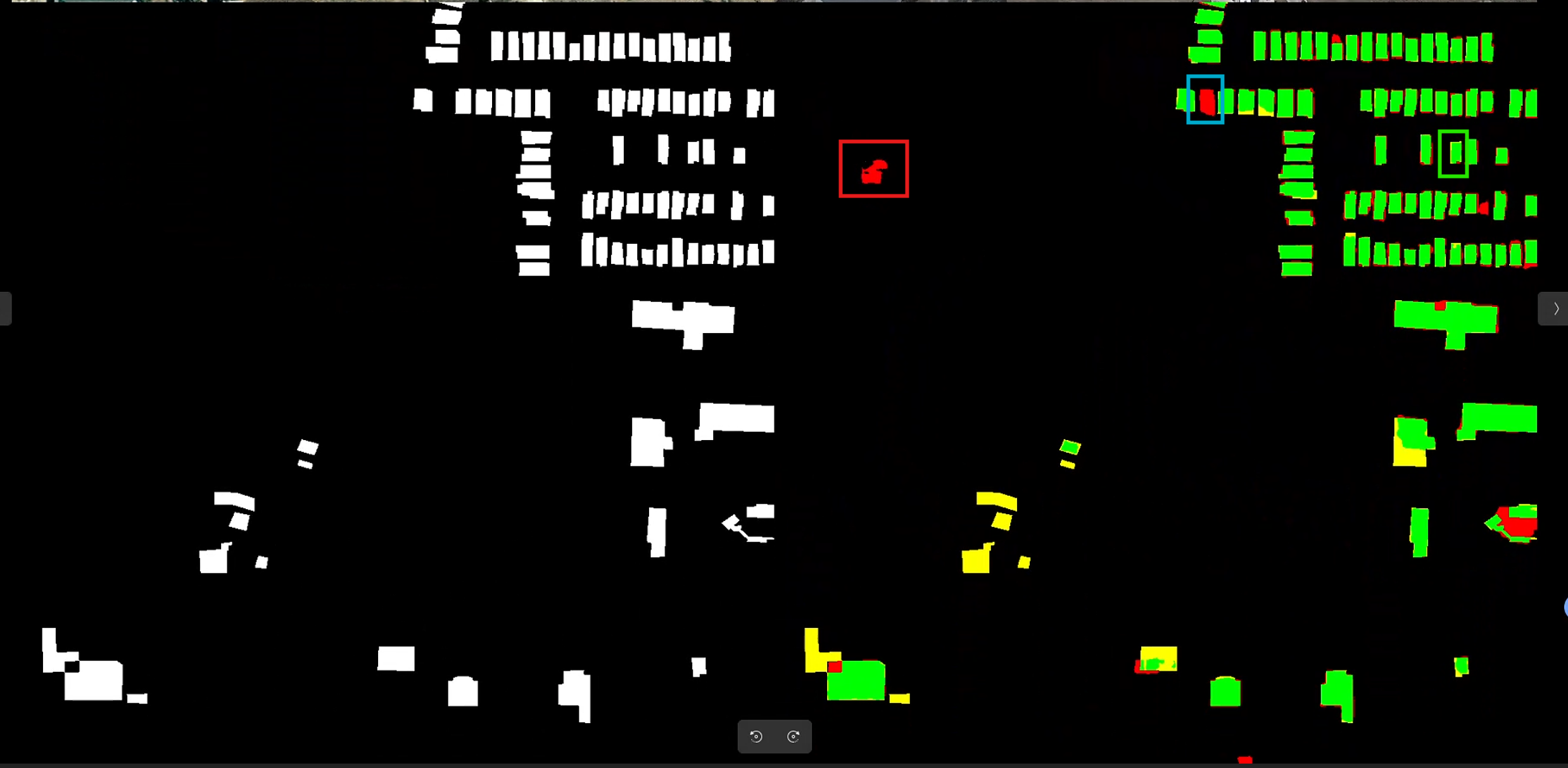
仔细观察图中的红框处,明显的建筑变化。但是在GT变化图中却没有标注。
蓝框处同样如此,但是这里是标注者刻意留空,仔细观察可以看出蓝框处建筑确实纹理不同。但是先不说建筑纹理为什么影响GT变化图标注,绿框处建筑纹理和蓝框处极其相似,却在GT变化图中体现了,这意味着哪怕是在同一个样本中,标注者的标准都不能统一。
类似的例子还有很多,例如:
(test_26.png)

LEVIR-CD总结
实事求是的讲,GT变化图将一些建筑物的变化忽略只导致了一部分的判断失误,还有很多的判断失误是模型未能识别出建筑物的变化导致的。那么我们可不可以先减少后一类的判断失误的发生,在数据集精度有限的情况下提升正确率呢?
我觉得很难
因为后一类的判断失误即模型这种对于建筑物变化的忽略何尝不是因为训练集中出现了大量的对于建筑物变化的忽略,模型被这种时不时的对于建筑物变化的忽略搞糊涂了,为了提高训练集的正确率,它不得不学习一套别扭的规则来忽略一部分建筑物的变化(但是这种对建筑物的变化的忽略实质上是没有规则的,只是标注员的疏忽!!!)。
就如同大家高中都有的一种经历一样,当练习题的答案偶尔出错而我们不知道时,少部分人会耗费很多的无用功去试图探究原因,最后找出一套别扭的解释,顺带扭曲了之前建立的正确的知识架构。而大部分人都会觉得题目与我们构建的知识体系矛盾了,从而去询问老师得到答案有误的解答。
对于模型来说也是一样的,面对着错漏百出的数据集,怎么能够学习到一套自洽的知识体系呢?
CDD数据集
数据集介绍
原论文地址
同样只针对数据集进行介绍。
与LEVIR-CD相同,CDD数据集也是由Google Earth标注而来,精度为0.03-1m/pixel。
但与LEVIR-CD不同的是,CDD数据集中把车辆、植被、道路等都算入变化之内。并且如果我没理解错的话,CDD数据集还手动添加了部分实例物体(原文:and 4 seasonvarying image pairs with minimal changes and resolution of 1900x1000 pixels for adding additional objects manually.),大胆的决定!!!
问题提出
仍然是老生常谈的错漏问题,CDD数据集的错漏更为严重!
很明显这是因为CDD数据集将过多的实例的变化都考虑其中的缘故。
而除了变化的错漏,还有不应出现的变化出现在了变化图中。
(test_384.jpg)
蓝框中所标位置在时序图前后并未发生了什么变化。标注者却把这块区域记为变化。
而除此之外还有大范围的滥标,对于较大面积的变化出现时,标注者似乎主动选择了粗粒度的标注法。
注意看如下三幅图
(图一:test_1441.jpg)
(图二:test_827.jpg)

(图三:test_118.jpg)
图一中出现了大片的雪地覆盖的消失,没有被标注为变化,这是很符合常理的。图二中的房屋发生了扩建,要有相应的标记,但是大片雪地覆盖的消失却也标记为变化。这就是数据集内部标注规范都没有统一了。图三中也出现了大片雪地覆盖的情况,但是蓝框标出区域只是由草地变为雪地,却不应该标记为变化。
CDD总结
见识了CDD数据集的粗糙程度,LEVIR-CD感觉都成了细糠。
实在地说,将过多种类的事物都考虑在变化图中是一件很复杂的事情,这对于模型的语义理解能力要求更高。一旦通过这种高复杂度的数据集训练出来一个能力强大的模型,那么它的泛化性相比也会很高,这想必也是数据集作者想要做到的事,包括他人工添加额外的实例也是为了提高数据集复杂度。但是如果数据集本身的高复杂度再加上数据集标注人员的粗糙标注的话,模型的学习难度恐怕就难以估计了吧。
顺带一提,CDD数据集是18年的,LEVIR-CD数据集是20年的。LEVIR-CD数据集只选择了建筑物作为变化对象,主动降低了数据集复杂度,是不是也是对CDD这一类数据集进行思考之后的选择呢?
说开来去
在去年我曾做过利用深度图提高遥感变化检测准确度的尝试,当时所用产生深度图的模型是Depth Anything V2,其中相对于v1的变化主要是利用了合成数据,提高了数据集的精度,从而大大加强了深度图的表现。论文自己也说了,并没有使用多少fancy的技巧。
前两天偶然翻到卢策吾老师的访谈,他聊到了对具身智能训练所用的数据的看法: “我们在思考数据问题时,应先从‘具身智能究竟需要什么信息’这一问题出发,而不是先入为主地决定‘我想要哪种数据’。也就是说,要基于具身智能所需的信息量来配置数据,同时还要考虑数据的获取成本,以及它能否在规模化应用中被承担得起。”
具身智能一直在追求的是高质量、易获取的的训练数据。或者说所有主流领域的进步中高质量、易获取数据都功不可没。
在遥感变化检测这个领域中,我想这条规律应该也不会失效。但是一个相对狭窄的领域,能将数据集的质量推动到什么一个地步?
我不清楚,毕竟我只是一个刚刚在这个领域伸出一只脚又马上缩回去的门外汉罢了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 50
50 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)