【NLP 28、一文速通NLP文本分类任务 —— 深度学习】
九万字长文,一文讲清NLP自然语言处理中的文本分类任务附有NLP文本分类任务基础模板代码
目录
Ⅴ、手动实现堆叠带有门控机制的卷积神经网络(StackGatedCNN)
Ⅶ、手动实现结合BERT和LSTM的模型(BertLSTM)
Ⅸ、手动实现提取BERT模型中间层的输出(BertMidLayer)
Ⅶ、对比 Transformer 和 LSTM 模型结构的优缺点 🧠
总有一朵花,属于你的春天
—— 25.1.24
一、深度学习 — pipeline 流水线
将深度学习的整个流程拆分成几个基本模块,每个模块负责一件专门的事情,这样有利于复用
将整个训练拆分成五个Python文件:
config.py:输入模型配置参数,如学习率等
loader.py:加载数据集,做预处理,为训练做准备(取决于数据格式,主要做预处理)
model.py:定义神经网络模型结构(主要内容,定义哪些神经网络模型结构可用)
evaluate.py:定义评价指标,每轮训练后做评测(固定任务中,评价指标基本固定)
main.py:模型训练主流程(神经网络任务中,改动倾向于最小,几乎不需要动)
1.配置文件 config.py
配置参数信息,输入模型配置参数,如学习率等
Ⅰ、路径相关
model_path:保存训练好的模型,这里要指定一个存在的文件夹路径。如果是加载已有的模型,要给出模型的准确存储路径。
train_data_path:指向训练数据所在的文件夹或者文件。如果是文件夹,里面应该包含训练数据文件(如多个文本文件或者一个大的数据集文件)。
valid_data_path:指向验证数据所在的文件夹或者文件。
vocab_path:指定词表的存储路径。例如在自然语言处理中,词汇表可能是一个文本文件,路径可以是./data/vocab.txt。
Ⅱ、模型相关
model_type:根据任务选择合适的模型类型,如Transformer(常用于机器翻译等序列到序列任务)、LSTM(长短时记忆网络,适合处理序列数据)、CNN(卷积神经网络,可用于图像或者文本分类等任务)等。
max_length:在处理序列数据(如文本)时,定义序列的最大长度。例如在文本分类任务中,如果大多数文本的长度不超过512个单词,可设置max_length = 512
hidden_size:对于神经网络模型(如RNN、LSTM、Transformer等),这是隐藏层的大小。常见的值根据任务和模型复杂度有所不同,比如在简单的文本分类任务中可以是128或者256。
kernel_size:主要用于卷积神经网络(CNN),表示卷积核的大小。例如在处理图像时,kernel_size = 3表示3x3的卷积核;在处理文本时(将文本看作序列,类似一维卷积),可能是kernel_size = 2或者3等。
num_layers:对于多层神经网络(如多层LSTM、Transformer的多层结构等),指定网络的层数。比如在构建一个较深的LSTM网络时,num_layers = 3。
Ⅲ、训练相关
epoch:表示整个训练数据集被遍历的次数。例如epoch = 10意味着模型会对训练数据完整地训练10次。
batch_size:每次训练时输入模型的样本数量。常见的值有32、64、128等,根据硬件资源(如GPU内存)和数据集大小调整。
pooling_style:在使用池化层(如在CNN中)时指定池化方式,如max_pooling(最大池化)或者average_pooling(平均池化)。
optimizer:选择优化算法,如Adam、SGD(随机梯度下降)、Adagrad等
learning_rate:学习率决定了模型参数更新的步长。常见的值如0.001、0.01等,需要根据任务和模型进行调整。
pretrain_model_path:如果要使用预训练模型,这里指定预训练模型的路径。例如在使用BERT进行微调时,给出BERT预训练模型的存储路径。
seed:随机数种子,用于确保实验的可重复性。例如设置seed = 42。
# -*- coding: utf-8 -*-
"""
配置参数信息
"""
Config = {
"model_path": "output",
"train_data_path": "F:\人工智能NLP\\NLP\Day7_文本分类问题\data\\train_tag_news.json",
"valid_data_path": "F:\人工智能NLP\\NLP\Day7_文本分类问题\data\\valid_tag_news.json",
"vocab_path":"chars.txt",
"model_type":"bert",
"max_length": 30,
"hidden_size": 256,
"kernel_size": 3,
"num_layers": 2,
"epoch": 15,
"batch_size": 128,
"pooling_style":"max",
"optimizer": "adam",
"learning_rate": 1e-3,
"pretrain_model_path":"F:\人工智能NLP/NLP资料\week6 语言模型/bert-base-chinese",
"seed": 987
}2.数据加载 loader.py
加载数据集,做预处理,为训练做准备(取决于数据格式,主要做预处理)
Ⅰ、类初始化
dict():Python 的内置函数,用于创建一个新的字典对象。字典是一种可变的、无序的键值对集合。
| 参数名称 | 类型 | 描述 |
|---|---|---|
arg |
可选 | 任何可迭代的键值对集合,如列表的元组、另一个字典等。 |
**kwargs |
可选 | 关键字参数,用于直接在字典中设置键值对。 |
items(): 是字典对象的方法,用于返回字典中所有键值对的视图对象。每个键值对以元组的形式表示。
len():是 Python 的内置函数,用于返回对象的长度或项目数。对于字典,它返回字典中键值对的数量。
| 参数名称 | 类型 | 描述 |
|---|---|---|
object |
可迭代对象 | 需要计算长度的对象,如列表、字典、字符串等。 |
BertTokenizer.from_pretrained():Hugging Face 的 transformers 库中 BertTokenizer 类的一个类方法,用于加载预训练的 BERT 分词器。预训练的分词器包含词汇表和相关的配置,适用于特定的预训练模型。
| 参数名称 | 类型 | 描述 |
|---|---|---|
pretrained_model_name_or_path |
str 或 os.PathLike |
预训练模型的名称或路径。可以是 Hugging Face 模型库中的名称(如 'bert-base-uncased'),也可以是本地文件系统的路径。 |
cache_dir |
Optional[str] |
用于缓存下载模型的目录。如果未指定,默认使用 ~/.cache/huggingface/transformers。 |
force_download |
bool |
是否强制重新下载模型和分词器,即使已经存在于缓存中。默认为 False。 |
resume_download |
bool |
是否在下载过程中断后继续下载。默认为 False。 |
local_files_only |
bool |
是否仅使用本地文件,不尝试从网络上下载。默认为 False。 |
use_fast |
bool |
是否使用基于 Rust 的快速分词器。默认为 True。如果设置为 False,将使用 Python 实现的分词器。 |
**kwargs |
其他关键字参数 | 其他与分词器相关的配置参数,如 do_lower_case、version 等,具体取决于所使用的预训练模型。 |
class DataGenerator:
def __init__(self, data_path, config):
self.config = config
self.path = data_path
# 每一个标签对应一个实际的类别
self.index_to_label = {0: '家居', 1: '房产', 2: '股票', 3: '社会', 4: '文化',
5: '国际', 6: '教育', 7: '军事', 8: '彩票', 9: '旅游',
10: '体育', 11: '科技', 12: '汽车', 13: '健康',
14: '娱乐', 15: '财经', 16: '时尚', 17: '游戏'}
self.label_to_index = dict((y, x) for x, y in self.index_to_label.items())
self.config["class_num"] = len(self.index_to_label)
if self.config["model_type"] == "bert":
self.tokenizer = BertTokenizer.from_pretrained(config["pretrain_model_path"])
self.vocab = load_vocab(config["vocab_path"])
self.config["vocab_size"] = len(self.vocab)
self.load()Ⅱ、加载数据并预处理
open():Python 的内置函数,用于打开一个文件,并返回一个文件对象。该文件对象可以用于读取、写入或追加文件内容。
| 参数名称 | 类型 | 描述 |
|---|---|---|
file |
str 或 pathlib.Path |
要打开的文件的路径。可以是相对路径或绝对路径。 |
mode |
str |
指定文件的打开模式。常见的模式包括:
|
json.loads():是 Python 的 json 模块中的函数,用于将 JSON 格式的字符串解析为 Python 对象(如字典、列表等)。
| 参数名称 | 类型 | 描述 |
|---|---|---|
s |
str |
要解析的 JSON 格式的字符串。 |
cls |
object |
可选参数,用于指定自定义的 JSON 解码器类,默认为 json.JSONDecoder。 |
object_hook |
callable |
可选参数,用于自定义反序列化后的对象。接受一个字典并返回一个对象。 |
parse_float |
callable |
可选参数,用于自定义浮点数的解析。接受一个字符串并返回一个浮点数。 |
parse_int |
callable |
可选参数,用于自定义整数的解析。接受一个字符串并返回一个整数。 |
parse_constant |
callable |
可选参数,用于自定义解析 JSON 中的特殊常量(如 null、true、false)。 |
object_pairs_hook |
callable |
可选参数,类似于 object_hook,但接收的是键值对的列表。 |
strict |
bool |
可选参数,指定是否在遇到非法字符时抛出异常。默认为 True。 |
buffer_size |
int |
可选参数,指定读取缓冲区的大小。默认为 None。 |
tokenizer.encode():Hugging Face 的 transformers 库中分词器(Tokenizer)的方法,用于将文本转换为模型可接受的输入格式(通常是 token IDs)。这在自然语言处理任务中非常常见,尤其是在使用预训练模型时。
| 参数名称 | 类型 | 描述 |
|---|---|---|
text |
str 或 List[str] |
要编码的文本。可以是单个字符串或字符串列表。 |
text_pair |
str 或 List[str] |
可选参数,与 text 配对的第二个文本,通常用于编码句子对(如问答任务中的问题和答案)。 |
add_special_tokens |
bool |
是否添加特殊的分词标记(如 [CLS] 和 [SEP])。默认为 True。 |
truncation |
bool 或 str |
是否截断输入文本以适应模型的最大长度。如果为 True,则根据 max_length 截断;如果为 False,则不截断。也可以传入 'longest_first' 或 'only_second' 等策略。默认为 False。 |
padding |
bool、str 或 int |
是否填充输入文本以达到模型的最大长度。如果为 True,则填充到 max_length;如果为 'longest',则填充到最长序列的长度;如果为整数,则填充到指定的长度。默认为 False。 |
max_length |
int |
编码后序列的最大长度。如果 truncation 或 padding 被启用,将以此值作为基准。默认为 None,表示不限制长度。 |
stride |
int |
在截断时,重叠部分的步幅。例如,stride=128 表示在截断时,每 128 个 token 保留一部分。默认为 0。 |
return_tensors |
str |
指定返回张量的类型。常见的值包括 'pt'(PyTorch)、'tf'(TensorFlow)、'np'(NumPy)等。默认为 None,返回 Python 列表。 |
return_attention_mask |
bool |
是否返回注意力掩码(attention mask),用于标识哪些 token 是填充的。默认为 False。 |
return_token_type_ids |
bool |
是否返回 token 类型 ID(token type IDs),用于区分句子对中的两个句子。默认为 False。 |
| 其他参数 | - | 根据具体分词器和任务需求,可能还有其他参数,如 position_ids、word_ids 等。 |
torch.LongTensor(): PyTorch 库中的函数,用于创建一个包含长整型(int64)数据的新张量。这在处理需要整数索引的数据(如标签、ID 等)时非常有用。
| 参数名称 | 类型 | 描述 |
|---|---|---|
data |
可迭代的数值类型 | 用于初始化张量的数据,可以是列表、元组、NumPy 数组等。例如,[1, 2, 3]。 |
dtype |
torch.dtype |
可选参数,指定张量的数据类型。默认为 torch.int64(即 LongTensor)。 |
device |
str 或 torch.device |
可选参数,指定张量存放的设备,如 'cpu' 或 'cuda:0'。默认为当前默认设备。 |
requires_grad |
bool |
可选参数,指定是否需要计算梯度。默认为 False。 |
| 其他参数 | - | 根据具体需求,可能还有其他参数,如 size、layout 等。 |
append():Python 中常用的方法,主要用于在列表(list)的末尾添加一个元素。除此之外,在其他数据结构如字符串(string)和字典(dictionary)中也有类似的方法,但功能和使用方式有所不同。
| 参数名称 | 类型 | 描述 |
|---|---|---|
item |
任意类型 | 要添加到列表末尾的元素。可以是任何数据类型,如整数、字符串、列表等。 |
def load(self):
self.data = []
with open(self.path, encoding="utf8") as f:
for line in f:
line = json.loads(line)
tag = line["tag"]
label = self.label_to_index[tag]
title = line["title"]
if self.config["model_type"] == "bert":
input_id = self.tokenizer.encode(title, max_length=self.config["max_length"], pad_to_max_length=True)
else:
input_id = self.encode_sentence(title)
input_id = torch.LongTensor(input_id)
label_index = torch.LongTensor([label])
self.data.append([input_id, label_index])
returnⅢ、文本编码
.get():用于获取字典中指定键对应的值。如果键不存在于字典中,可以返回一个默认值,而不会引发 KeyError 异常。
| 参数名称 | 类型 | 描述 |
|---|---|---|
key |
任意可哈希类型 | 要查找的键。 |
default |
任意类型 | 可选参数。如果键不存在时返回的默认值。如果未提供,默认为 None。 |
append():用于在列表的末尾添加一个新的元素。
| 参数名称 | 类型 | 描述 |
|---|---|---|
item |
任意类型 | 要添加到列表末尾的元素。 |
def encode_sentence(self, text):
input_id = []
for char in text:
input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
input_id = self.padding(input_id)
return input_idⅣ、对输入序列截断或填充
len():是 Python 的内置函数,用于返回对象的长度或项目数。对于字典,它返回字典中键值对的数量。
| 参数名称 | 类型 | 描述 |
|---|---|---|
object |
可迭代对象 | 需要计算长度的对象,如列表、字典、字符串等。 |
#补齐或截断输入的序列,使其可以在一个batch内运算
def padding(self, input_id):
input_id = input_id[:self.config["max_length"]]
input_id += [0] * (self.config["max_length"] - len(input_id))
return input_idⅤ、返回数据长度
len():是 Python 的内置函数,用于返回对象的长度或项目数。对于字典,它返回字典中键值对的数量。
| 参数名称 | 类型 | 描述 |
|---|---|---|
object |
可迭代对象 | 需要计算长度的对象,如列表、字典、字符串等。 |
def __len__(self):
return len(self.data)Ⅵ、返回对应索引位置元素
def __getitem__(self, index):
return self.data[index]Ⅶ、加载词表
open():函数用于打开一个文件,并返回一个文件对象。你可以使用这个文件对象来读取、写入或追加文件内容。
| 参数名称 | 类型 | 描述 |
|---|---|---|
file |
str 或 pathlib.Path |
要打开的文件的路径。可以是相对路径或绝对路径。 |
mode |
str |
指定文件的打开模式。常见的模式包括: - 'r':读取模式(默认)- 'w':写入模式,会覆盖原有内容- 'a':追加模式,在文件末尾添加内容- 'x':独占创建模式,如果文件已存在则报错- 'b':二进制模式- 't':文本模式(默认)- '+':读写模式- 组合使用,如 'rb'、'w+' 等。 |
buffering |
int |
设置缓冲策略。常见值: - 0:无缓冲(仅适用于二进制模式)- 1:行缓冲(仅适用于文本模式)- >1:指定缓冲区大小- 默认为系统默认缓冲策略。 |
encoding |
str |
指定文件的编码方式,如 'utf-8'、'gbk' 等。仅在文本模式下有效。 |
errors |
str |
指定如何处理编码和解码错误。常见值包括 'strict'(默认)、'ignore'、'replace' 等。仅适用于文本模式。 |
newline |
str |
控制换行符的处理方式。主要用于跨平台文本文件的处理。 |
closefd |
bool |
如果为 False,文件关闭时文件描述符不会关闭。默认为 True。 |
opener |
callable |
自定义打开器。用于替代内置的打开机制。 |
enumerate():函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
| 参数名称 | 类型 | 描述 |
|---|---|---|
iterable |
可迭代对象 | 需要被枚举的对象,如列表、元组、字符串等。 |
start |
int,可选 |
索引起始值,默认为 0。可以指定其他整数作为起始索引。 |
strip():用于移除字符串头尾指定的字符(默认为空格或换行符)。它不会修改原字符串,而是返回一个新的字符串。
| 参数名称 | 类型 | 描述 |
|---|---|---|
chars |
str,可选 |
指定要移除的字符集合。如果未指定,默认移除空白字符(包括空格、制表符 \t、换行符 \n 等)。如果指定了字符集,strip() 将移除字符串开头和结尾出现的这些字符。 |
def load_vocab(vocab_path):
token_dict = {}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
token = line.strip()
token_dict[token] = index + 1 #0留给padding位置,所以从1开始
return token_dictⅧ、封装数据
DataLoader():PyTorch 中一个非常重要的类,用于批量加载和处理数据,以便高效地进行模型训练和评估。DataLoader 与 Dataset 配合使用,提供了诸如数据打乱(shuffle)、批量处理(batching)、并行加载(num_workers)等功能,极大地简化了数据处理的流程。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
dataset |
Dataset |
- | 要加载的数据集对象,必须是继承自 torch.utils.data.Dataset 的实例。 |
batch_size |
int |
1 | 每个批次包含的样本数量。较大的批次可以加快训练速度,但可能需要更多的内存。 |
shuffle |
bool |
False |
如果设置为 True,则在每个 epoch 开始时打乱数据顺序。通常在训练时设置为 True,在验证或测试时设置为 False。 |
sampler |
Sampler 或 None |
None |
用于采样的策略。如果指定了 sampler,则忽略 shuffle 参数。通常用于特定需求的采样,如不均衡数据集的处理。 |
batch_sampler |
BatchSampler 或 None |
None |
用于生成批次的采样器。如果指定了 batch_sampler,则忽略 batch_size、shuffle、sampler 和 drop_last 参数。通常用于更复杂的批次生成策略。 |
num_workers |
int |
0 | 用于数据加载的子进程数量。设置为 0 表示在主进程中加载数据。增加 num_workers 可以加快数据加载速度,但需要更多的系统资源。 |
collate_fn |
callable 或 None |
None |
用于将采样得到的样本列表合并成一个批次。默认情况下,PyTorch 会将样本堆叠(stack)成一个张量。可以通过自定义 collate_fn 来处理不规则的数据。 |
pin_memory |
bool |
False |
如果设置为 True,则将数据加载到 GPU 内存中,可以加快数据传输速度。仅在数据加载到 GPU 时使用。 |
drop_last |
bool |
False |
如果设置为 True,则在最后一个批次样本不足 batch_size 时丢弃该批次。通常在数据集大小不能被 batch_size 整除时使用,以避免影响训练。 |
timeout |
float |
0 | 数据加载的超时时间(秒)。如果在指定时间内数据未加载完成,将引发超时错误。 |
worker_init_fn |
callable 或 None |
None |
每个子进程在开始工作前调用的函数,可以用于初始化每个子进程的环境,如设置随机种子等。 |
# 用torch自带的DataLoader类封装数据
def load_data(data_path, config, shuffle=True):
dg = DataGenerator(data_path, config)
dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
return dlⅨ、数据加载
# -*- coding: utf-8 -*-
import json
import re
import os
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer
"""
数据加载
"""
class DataGenerator:
def __init__(self, data_path, config):
self.config = config
self.path = data_path
# 每一个标签对应一个实际的类别
self.index_to_label = {0: '家居', 1: '房产', 2: '股票', 3: '社会', 4: '文化',
5: '国际', 6: '教育', 7: '军事', 8: '彩票', 9: '旅游',
10: '体育', 11: '科技', 12: '汽车', 13: '健康',
14: '娱乐', 15: '财经', 16: '时尚', 17: '游戏'}
self.label_to_index = dict((y, x) for x, y in self.index_to_label.items())
self.config["class_num"] = len(self.index_to_label)
if self.config["model_type"] == "bert":
self.tokenizer = BertTokenizer.from_pretrained(config["pretrain_model_path"])
self.vocab = load_vocab(config["vocab_path"])
self.config["vocab_size"] = len(self.vocab)
self.load()
def load(self):
self.data = []
with open(self.path, encoding="utf8") as f:
for line in f:
line = json.loads(line)
tag = line["tag"]
label = self.label_to_index[tag]
title = line["title"]
if self.config["model_type"] == "bert":
input_id = self.tokenizer.encode(title, max_length=self.config["max_length"], pad_to_max_length=True)
else:
input_id = self.encode_sentence(title)
input_id = torch.LongTensor(input_id)
label_index = torch.LongTensor([label])
self.data.append([input_id, label_index])
return
def encode_sentence(self, text):
input_id = []
for char in text:
input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
input_id = self.padding(input_id)
return input_id
#补齐或截断输入的序列,使其可以在一个batch内运算
def padding(self, input_id):
input_id = input_id[:self.config["max_length"]]
input_id += [0] * (self.config["max_length"] - len(input_id))
return input_id
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
def load_vocab(vocab_path):
token_dict = {}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
token = line.strip()
token_dict[token] = index + 1 #0留给padding位置,所以从1开始
return token_dict
#用torch自带的DataLoader类封装数据
def load_data(data_path, config, shuffle=True):
dg = DataGenerator(data_path, config)
dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
return dl
if __name__ == "__main__":
from config import Config
dg = DataGenerator("F:\人工智能NLP\\NLP\Day7_文本分类问题\data\\valid_tag_news.json", Config)
print(dg[1])
3.模型建立 model.py
定义神经网络模型结构(主要内容,定义哪些模型结构可用),如果增添网络结构,只需要在这个文件更改
Ⅰ、模型初始化
hidden_size:对于神经网络模型(如RNN、LSTM、Transformer等),这是隐藏层的大小。常见的值根据任务和模型复杂度有所不同,比如在简单的文本分类任务中可以是128或者256。
vocab_size:指定词表的存储路径。例如在自然语言处理中,词汇表可能是一个文本文件,路径可以是./data/vocab.txt。
class_num:指定分类数目
model_type:根据任务选择合适的模型类型,如Transformer(常用于机器翻译等序列到序列任务)、LSTM(长短时记忆网络,适合处理序列数据)、CNN(卷积神经网络,可用于图像或者文本分类等任务)等。
num_layers:对于多层神经网络(如多层LSTM、Transformer的多层结构等),指定网络的层数。比如在构建一个较深的LSTM网络时,num_layers = 3。
use_bert:是否使用bert模型
nn.Embedding():是一个嵌入层,用于将离散的输入(如单词索引)映射到固定大小的向量空间中。这在自然语言处理(NLP)中非常常见,用于将词汇表中的每个词转换为一个向量表示(词嵌入)。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
num_embeddings |
int | - | 词汇表中词的总数 |
embedding_dim |
int | - | 每个词的嵌入维度 |
padding_idx |
int, 可选 | None | 如果提供,将此索引对应的嵌入向量初始化为零 |
max_norm |
float, 可选 | None | 嵌入向量的最大范数,超过则会被归一化 |
norm_type |
float, 可选 | 2.0 | 计算范数的类型(如L2范数) |
scale_grad_by_freq |
bool, 可选 | False | 是否根据词频缩放梯度 |
sparse |
bool, 可选 | False | 是否使用稀疏梯度 |
_weight |
Tensor, 可选 | None | 预定义的权重张量 |
model_type:一个变量或参数,用于指定模型的类型。
lambda:Python中的一个关键字,用于创建匿名函数(即没有名称的函数)。在深度学习中,常用于定义简单的函数,如损失函数、激活函数或自定义层。
nn.LSTM():实现了长短期记忆网络(Long Short-Term Memory),一种特殊的循环神经网络(RNN),能够有效捕捉长距离依赖关系。LSTM通过引入门控机制(输入门、遗忘门、输出门)来解决传统RNN中的梯度消失问题。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input_size |
int | - | 输入特征的维度 |
hidden_size |
int | - | 隐藏层的大小 |
num_layers |
int, 可选 | 1 | LSTM层的堆叠层数 |
bias |
bool, 可选 | True | 是否使用偏置项 |
batch_first |
bool, 可选 | False | 如果为True,输入和输出张量的形状为 (batch, seq, feature) |
dropout |
float, 可选 | 0 | 如果 num_layers > 1,层之间的dropout概率 |
bidirectional |
bool, 可选 | False | 是否使用双向LSTM |
proj_size |
int, 可选 | 0 | 输出投影的大小(仅适用于某些实现) |
nn.GRU():实现了门控循环单元(Gated Recurrent Unit),一种简化版的LSTM。GRU通过引入更新门和重置门来控制信息的流动,通常比LSTM具有更少的参数和更高的计算效率。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input_size |
int | - | 输入特征的维度 |
hidden_size |
int | - | 隐藏层的大小 |
num_layers |
int, 可选 | 1 | GRU层的堆叠层数 |
bias |
bool, 可选 | True | 是否使用偏置项 |
batch_first |
bool, 可选 | False | 如果为True,输入和输出张量的形状为 (batch, seq, feature) |
dropout |
float, 可选 | 0 | 如果 num_layers > 1,层之间的dropout概率 |
bidirectional |
bool, 可选 | False | 是否使用双向GRU |
nn.RNN():实现了基本的循环神经网络(Recurrent Neural Network)。RNN能够处理序列数据,但存在梯度消失问题,通常不如LSTM和GRU适用于长序列。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input_size |
int | - | 输入特征的维度 |
hidden_size |
int | - | 隐藏层的大小 |
num_layers |
int, 可选 | 1 | RNN层的堆叠层数 |
nonlinearity |
str, 可选 | 'tanh' | 激活函数类型,可选 'tanh' 或 'relu' |
bias |
bool, 可选 | True | 是否使用偏置项 |
batch_first |
bool, 可选 | False | 如果为True,输入和输出张量的形状为 (batch, seq, feature) |
dropout |
float, 可选 | 0 | 如果 num_layers > 1,层之间的dropout概率 |
bidirectional |
bool, 可选 | False | 是否使用双向RNN |
CNN():指卷积神经网络(Convolutional Neural Network),用于处理具有网格结构的数据,如图像。CNN通过卷积层、池化层和全连接层提取特征,广泛应用于图像分类、目标检测等任务。
注意:PyTorch中没有直接的CNN类,通常需要自定义或使用组合层(如nn.Conv2d、nn.MaxPool2d等)构建CNN模型。
GatedCNN():GatedCNN 是一种带有门控机制的卷积神经网络。它结合了卷积操作和门控机制(类似于GRU或LSTM中的门控),用于更有效地捕捉和利用序列数据中的特征。
注意:PyTorch中没有内置的GatedCNN类,通常需要自定义实现。
StackGatedCNN():StackGatedCNN 是堆叠带有门控机制的卷积神经网络。通过堆叠多个带有门控的卷积层,可以增强模型的特征提取能力,适用于复杂的序列数据处理任务。
注意:PyTorch中没有内置的StackGatedCNN类,通常需要自定义实现。
RCNN():指区域卷积神经网络(Region-based Convolutional Neural Network),常用于目标检测任务。RCNN通过提取候选区域并对其进行卷积操作,实现对图像中多个目标的检测和分类。
注意:PyTorch中没有内置的RCNN类,通常使用如torchvision.models.detection中的模型(如Faster R-CNN)。
BertModel.from_pretrained():Hugging Face Transformers库中的方法,用于从预训练的权重加载BERT模型。这使得用户可以快速使用预训练的BERT模型进行微调或直接应用。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
pretrained_model_name_or_path |
str | "bert-base-uncased" | 预训练模型的名称或路径 |
config |
Config, 可选 | None | 模型的配置对象 |
cache_dir |
str, 可选 | None | 缓存预训练模型的目录 |
force_download |
bool, 可选 | False | 是否强制重新下载模型 |
resume_download |
bool, 可选 | False | 是否在下载中断后继续下载 |
local_files_only |
bool, 可选 | False | 是否仅使用本地文件 |
mirror_url |
str, 可选 | None | 镜像URL地址 |
progress |
bool, 可选 | True | 是否显示下载进度 |
BertLSTM():是结合BERT和LSTM的模型架构。通常,BERT用于提取上下文特征,然后将这些特征输入到LSTM层中,以捕捉序列中的时间依赖关系。这种组合常用于文本分类、序列标注等任务。
注意:PyTorch中没有内置的BertLSTM类,通常需要自定义实现。
BertCNN():是结合BERT和卷积神经网络(CNN)的模型架构。BERT用于提取上下文特征,然后通过CNN层提取局部特征,适用于文本分类、情感分析等任务。
注意:PyTorch中没有内置的BertCNN类,通常需要自定义实现。
BertMidLayer():用于提取BERT模型中间层的输出。这允许用户获取BERT在特定层次的特征表示,以便进行更细粒度的分析或应用。
注意:PyTorch中没有内置的BertMidLayer类,通常需要自定义实现或使用Hugging Face Transformers库中的相关功能。
nn.Linear():实现了一个全连接层(线性层),用于将输入特征映射到指定维度的输出。它通过矩阵乘法和可选的偏置项进行线性变换。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
in_features |
int | - | 输入特征的数量 |
out_features |
int | - | 输出特征的数量 |
bias |
bool, 可选 | True | 是否使用偏置项 |
device |
device, 可选 | None | 指定张量所在的设备(如CPU或GPU) |
dtype |
dtype, 可选 | None | 张量的数据类型 |
nn.functional.cross_entropy(): 计算交叉熵损失,常用于多分类任务。它结合了log_softmax和NLLLoss(负对数似然损失),简化了多分类损失函数的计算。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input |
Tensor | - | 模型的未归一化得分(通常经过log_softmax) |
target |
Tensor | - | 真实标签,类别索引 |
weight |
Tensor, 可选 | None | 每个类别的权重,用于处理类别不平衡 |
reduction |
str, 可选 | 'mean' | 损失的缩减方式,可选 'none', 'mean', 'sum' |
ignore_index |
int, 可选 | -1 | 忽略指定索引的损失 |
label_smoothing |
float, 可选 | 0 | 标签平滑系数 |
def __init__(self, config):
super(TorchModel, self).__init__()
hidden_size = config["hidden_size"]
vocab_size = config["vocab_size"] + 1
class_num = config["class_num"]
model_type = config["model_type"]
num_layers = config["num_layers"]
self.use_bert = False
self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)
if model_type == "fast_text":
self.encoder = lambda x: x
elif model_type == "lstm":
self.encoder = nn.LSTM(hidden_size, hidden_size, num_layers=num_layers, batch_first=True)
elif model_type == "gru":
self.encoder = nn.GRU(hidden_size, hidden_size, num_layers=num_layers, batch_first=True)
elif model_type == "rnn":
self.encoder = nn.RNN(hidden_size, hidden_size, num_layers=num_layers, batch_first=True)
elif model_type == "cnn":
self.encoder = CNN(config)
elif model_type == "gated_cnn":
self.encoder = GatedCNN(config)
elif model_type == "stack_gated_cnn":
self.encoder = StackGatedCNN(config)
elif model_type == "rcnn":
self.encoder = RCNN(config)
elif model_type == "bert":
self.use_bert = True
self.encoder = BertModel.from_pretrained(config["pretrain_model_path"], return_dict=False)
hidden_size = self.encoder.config.hidden_size
elif model_type == "bert_lstm":
self.use_bert = True
self.encoder = BertLSTM(config)
hidden_size = self.encoder.bert.config.hidden_size
elif model_type == "bert_cnn":
self.use_bert = True
self.encoder = BertCNN(config)
hidden_size = self.encoder.bert.config.hidden_size
elif model_type == "bert_mid_layer":
self.use_bert = True
self.encoder = BertMidLayer(config)
hidden_size = self.encoder.bert.config.hidden_size
self.classify = nn.Linear(hidden_size, class_num)
self.pooling_style = config["pooling_style"]
self.loss = nn.functional.cross_entropy #loss采用交叉熵损失
Ⅱ、前向计算
range():Python内置函数,用于生成一个整数序列。它常用于 for 循环中,以迭代指定范围内的数值。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
start |
int | 0 | 序列的起始值(包含)。默认为0。 |
stop |
int | - | 序列的结束值(不包含)。必须指定。 |
step |
int | 1 | 序列中相邻两个数之间的差值。默认为1。 |
isinstance():Python内置函数,用于检查一个对象是否是指定类型或其子类的实例。它常用于类型检查和条件判断。
| 参数名称 | 类型 | 描述 |
|---|---|---|
object |
任意 | 要检查的对象。 |
classinfo |
type 或 tuple of types | 要比较的类型或类型的元组。可以是单个类型或多个类型的组合。 |
tuple: Python的内置数据类型,用于存储有序且不可变的元素集合。与列表(list)类似,元组可以包含任意类型的元素,但其内容在创建后无法修改。元组通常用于存储不需要更改的数据,如函数返回多个值、字典的键等。
| 常用方法名称 | 描述 |
|---|---|
count(x) |
返回元素 x 在元组中出现的次数。 |
index(x[, start[, end]]) |
返回元素 x 在元组中首次出现的索引。可选参数 start 和 end 用于指定搜索范围。 |
nn.MaxPool1d():实现了一维最大池化操作,常用于卷积神经网络(CNN)中对序列数据进行下采样,减少参数数量并提取主要特征。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
kernel_size |
int 或 tuple | - | 池化窗口的大小。可以是单个整数或一个包含单个整数的元组。 |
stride |
int 或 tuple | kernel_size |
池化操作的步幅。可以是单个整数或一个包含单个整数的元组。 |
padding |
int 或 tuple | 0 | 输入的每一侧填充的大小。可以是单个整数或一个包含单个整数的元组。 |
dilation |
int 或 tuple | 1 | 控制窗口中元素步幅的参数。可以是单个整数或一个包含单个整数的元组。 |
ceil_mode |
bool, 可选 | False | 如果为True,使用ceil而不是floor计算输出大小。 |
return_indices |
bool, 可选 | False | 如果为True,返回最大值的索引。 |
nn.AvgPool1d():实现了一维平均池化操作,用于卷积神经网络(CNN)中对序列数据进行下采样,通过计算窗口内元素的平均值来提取特征。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
kernel_size |
int 或 tuple | - | 池化窗口的大小。可以是单个整数或一个包含单个整数的元组。 |
stride |
int 或 tuple | kernel_size |
池化操作的步幅。可以是单个整数或一个包含单个整数的元组。 |
padding |
int 或 tuple | 0 | 输入的每一侧填充的大小。可以是单个整数或一个包含单个整数的元组。 |
ceil_mode |
bool, 可选 | False | 如果为True,使用ceil而不是floor计算输出大小。 |
count_include_pad |
bool, 可选 | True | 是否将填充的元素包含在平均值计算中。 |
.transpose():PyTorch张量的方法,用于交换张量的两个维度。它返回一个新的张量,其指定维度的顺序被交换。
| 参数名称 | 类型 | 描述 |
|---|---|---|
dim0 |
int | 第一个要交换的维度索引。 |
dim1 |
int | 第二个要交换的维度索引。 |
.squeeze():PyTorch张量的方法,用于移除张量中大小为1的维度。如果未指定维度,则移除所有大小为1的维度。
| 参数名称 | 类型 | 描述 |
|---|---|---|
dim |
int, 可选 | 要移除的维度索引。如果指定,仅移除该维度如果其大小为1。默认为None,移除所有大小为1的维度。 |
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, target=None):
if self.use_bert: # bert返回的结果是 (sequence_output, pooler_output)
#sequence_output:batch_size, max_len, hidden_size
#pooler_output:batch_size, hidden_size
x = self.encoder(x)
else:
x = self.embedding(x) # input shape:(batch_size, sen_len)
x = self.encoder(x) # input shape:(batch_size, sen_len, input_dim)
if isinstance(x, tuple): #RNN类的模型会同时返回隐单元向量,我们只取序列结果
x = x[0]
#可以采用pooling的方式得到句向量
if self.pooling_style == "max":
self.pooling_layer = nn.MaxPool1d(x.shape[1])
else:
self.pooling_layer = nn.AvgPool1d(x.shape[1])
x = self.pooling_layer(x.transpose(1, 2)).squeeze() #input shape:(batch_size, sen_len, input_dim)
#也可以直接使用序列最后一个位置的向量
# x = x[:, -1, :]
predict = self.classify(x) #input shape:(batch_size, input_dim)
if target is not None:
return self.loss(predict, target.squeeze())
else:
return predictⅢ、手动实现卷积神经网络(CNN)
int():Python的内置函数,用于将一个数值或字符串转换为整数类型。如果传入的参数无法转换为整数,会引发 ValueError。
| 参数名称 | 类型 | 描述 |
|---|---|---|
x |
int, float, str | 要转换的值。可以是整数、浮点数或表示整数的字符串。 |
base |
int, 可选 | 用于解析字符串的进制(2到36之间)。默认为10。 |
nn.Conv1d():是PyTorch中的一个模块,用于实现一维卷积操作。它通常用于处理序列数据,如时间序列或单通道的图像数据(例如,灰度图像沿宽度方向的卷积)。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
in_channels |
int | - | 输入张量的通道数。 |
out_channels |
int | - | 输出张量的通道数。 |
kernel_size |
int 或 tuple | - | 卷积核的大小。可以是单个整数或一个包含单个整数的元组。 |
stride |
int 或 tuple | 1 | 卷积操作的步幅。可以是单个整数或一个包含单个整数的元组。 |
padding |
int 或 tuple | 0 | 输入的每一侧填充的大小。可以是单个整数或一个包含单个整数的元组。 |
dilation |
int 或 tuple | 1 | 卷积核元素之间的间距。可以是单个整数或一个包含单个整数的元组。 |
groups |
int | 1 | 输入通道与输出通道之间的连接方式。默认为1,表示标准卷积。 |
bias |
bool, 可选 | True | 是否使用偏置项。如果为False,则不使用偏置。 |
padding_mode |
str, 可选 | 'zeros' | 填充模式,如 'zeros', 'reflect', 'replicate', 'circular' 等。 |
.transpose():是PyTorch张量的方法,用于交换张量的两个维度。它返回一个新的张量,其指定维度的顺序被交换。
| 参数名称 | 类型 | 描述 |
|---|---|---|
dim0 |
int | 第一个要交换的维度索引。 |
dim1 |
int | 第二个要交换的维度索引。 |
class CNN(nn.Module):
def __init__(self, config):
super(CNN, self).__init__()
hidden_size = config["hidden_size"]
kernel_size = config["kernel_size"]
pad = int((kernel_size - 1)/2)
self.cnn = nn.Conv1d(hidden_size, hidden_size, kernel_size, bias=False, padding=pad)
def forward(self, x): #x : (batch_size, max_len, embeding_size)
return self.cnn(x.transpose(1, 2)).transpose(1, 2)Ⅳ、手动实现带有门控机制的卷积神经网络(GatedCNN)
torch.sigmoid(): PyTorch 中的一个函数,用于计算输入张量中每个元素的 Sigmoid 激活函数值。Sigmoid 函数将输入值压缩到 0 和 1 之间,常用于二分类问题的输出层,将模型的输出转换为概率。
公式:![]()
| 参数名称 | 类型 | 描述 |
|---|---|---|
input |
Tensor | 输入的张量。可以是任意形状的张量。 |
out |
Tensor, 可选 | 输出张量,用于存储结果。如果未提供,将创建一个新的张量。 |
torch.mul(): PyTorch 中的一个函数,用于对输入张量进行逐元素相乘(element-wise multiplication)。它支持广播机制,可以用于不同形状的张量之间的乘法操作。
| 参数名称 | 类型 | 描述 |
|---|---|---|
input |
Tensor | 第一个输入张量。 |
other |
Tensor 或 float | 第二个输入张量或标量。可以是与 input 形状相同的张量,或者是一个标量。 |
out |
Tensor, 可选 | 输出张量,用于存储结果。如果未提供,将创建一个新的张量。 |
class GatedCNN(nn.Module):
def __init__(self, config):
super(GatedCNN, self).__init__()
self.cnn = CNN(config)
self.gate = CNN(config)
def forward(self, x):
a = self.cnn(x)
b = self.gate(x)
b = torch.sigmoid(b)
return torch.mul(a, b)Ⅴ、手动实现堆叠带有门控机制的卷积神经网络(StackGatedCNN)
range():Python 的内置函数,用于生成一个整数序列。它常用于 for 循环中,以迭代指定范围内的数值。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
start |
int | 0 | 序列的起始值(包含)。默认为0。 |
stop |
int | - | 序列的结束值(不包含)。必须指定。 |
step |
int | 1 | 序列中相邻两个数之间的差值。默认为1。 |
nn.ModuleList():PyTorch 中的一个容器类,用于将多个子模块(通常是神经网络层或其他模块)组织在一起。与普通的 Python 列表不同,nn.ModuleList 能够正确地注册和管理其中的子模块,使其在模型的参数列表中可见,并且能够在保存和加载模型时被正确处理。
| 参数名称 | 类型 | 描述 |
|---|---|---|
modules |
Iterable | 一个可迭代的子模块(如 nn.Linear、nn.ReLU 等)。 |
nn.Linear():实现了一个全连接层(线性层),用于将输入特征映射到指定维度的输出。它通过矩阵乘法和可选的偏置项进行线性变换。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
in_features |
int | - | 输入特征的数量 |
out_features |
int | - | 输出特征的数量 |
bias |
bool, 可选 | True | 是否使用偏置项 |
device |
device, 可选 | None | 指定张量所在的设备(如CPU或GPU) |
dtype |
dtype, 可选 | None | 张量的数据类型 |
nn.LayerNorm():PyTorch 中的一个模块,用于实现层归一化(Layer Normalization)。层归一化是一种在深度神经网络中常用的正则化技术,旨在加速训练过程并提高模型的泛化能力。与批归一化(Batch Normalization)不同,层归一化在每个样本的所有特征维度上进行归一化,而不是在批次维度上。这使得层归一化在处理变长序列数据(如自然语言处理中的句子)时尤为有效。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
normalized_shape |
int 或 tuple | - | 需要归一化的特征维度的大小。可以是单个整数或一个包含多个整数的元组。 |
eps |
float, 可选 | 1e-5 | 用于数值稳定性的小常数,防止除以零。 |
elementwise_affine |
bool, 可选 | True | 是否对每个归一化后的特征维度应用可学习的仿射变换(即缩放和偏移)。默认为True。 |
device |
device, 可选 | None | 指定张量所在的设备(如CPU或GPU)。默认为None,使用当前设备。 |
dtype |
dtype, 可选 | None | 指定张量的数据类型。默认为None,使用当前默认数据类型。 |
torch.relu(): PyTorch 中的一个函数,用于计算输入张量的修正线性单元(Rectified Linear Unit, ReLU)激活值。ReLU 是一种常用的非线性激活函数,广泛应用于各种神经网络架构中,特别是在深度学习中用于引入非线性特性。
公式:![]()
| 参数名称 | 类型 | 描述 |
|---|---|---|
input |
Tensor | 输入的张量。可以是任意形状的张量。 |
inplace |
bool, 可选 | 是否在输入张量上进行原地操作。默认为 False。如果设置为 True,则结果会覆盖输入张量,节省内存但会改变原始数据。 |
out |
Tensor, 可选 | 输出张量,用于存储结果。如果未提供,将创建一个新的张量。 |
class StackGatedCNN(nn.Module):
def __init__(self, config):
super(StackGatedCNN, self).__init__()
self.num_layers = config["num_layers"]
self.hidden_size = config["hidden_size"]
#ModuleList类内可以放置多个模型,取用时类似于一个列表
self.gcnn_layers = nn.ModuleList(
GatedCNN(config) for i in range(self.num_layers)
)
self.ff_liner_layers1 = nn.ModuleList(
nn.Linear(self.hidden_size, self.hidden_size) for i in range(self.num_layers)
)
self.ff_liner_layers2 = nn.ModuleList(
nn.Linear(self.hidden_size, self.hidden_size) for i in range(self.num_layers)
)
self.bn_after_gcnn = nn.ModuleList(
nn.LayerNorm(self.hidden_size) for i in range(self.num_layers)
)
self.bn_after_ff = nn.ModuleList(
nn.LayerNorm(self.hidden_size) for i in range(self.num_layers)
)
def forward(self, x):
#仿照bert的transformer模型结构,将self-attention替换为gcnn
for i in range(self.num_layers):
gcnn_x = self.gcnn_layers[i](x)
x = gcnn_x + x #通过gcnn+残差
x = self.bn_after_gcnn[i](x) #之后bn
# # 仿照feed-forward层,使用两个线性层
l1 = self.ff_liner_layers1[i](x) #一层线性
l1 = torch.relu(l1) #在bert中这里是gelu
l2 = self.ff_liner_layers2[i](l1) #二层线性
x = self.bn_after_ff[i](x + l2) #残差后过bn
return xⅥ、手动实现循环区域卷积神经网络(RCNN)
nn.RNN(): PyTorch 中的一个模块,用于实现基本的循环神经网络(Recurrent Neural Network)。RNN 特别适用于处理序列数据,如时间序列、自然语言文本等。它通过在时间步之间传递隐藏状态来捕捉序列中的依赖关系。
返回值:1.output:描述:包含每个时间步的隐藏状态。2. hn:描述:最后一个时间步的隐藏状态。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input_size |
int | - | 输入特征的维度。每个时间步的输入张量的最后一个维度应为 input_size。 |
hidden_size |
int | - | 隐藏层的大小。即每个时间步隐藏状态的维度。 |
num_layers |
int, 可选 | 1 | RNN 层的堆叠层数。默认为1。 |
bias |
bool, 可选 | True | 是否使用偏置项。如果为 False,则不使用偏置。 |
batch_first |
bool, 可选 | False | 如果为 True,输入和输出张量的形状为 (batch, seq, feature)。默认为 False(形状为 (seq, batch, feature))。 |
dropout |
float, 可选 | 0 | 如果 num_layers > 1,层之间的 dropout 概率。默认为0,表示不使用 dropout。 |
bidirectional |
bool, 可选 | False | 是否使用双向 RNN。如果为 True,则每个时间步会合并前向和后向的信息。默认为 False。 |
proj_size |
int, 可选 | 0 | 输出投影的大小。如果大于0,输出会被投影到 proj_size 维度。默认为0,表示不进行投影。 |
GatedCNN(): 手动实现带有门控机制的卷积神经网络
class RCNN(nn.Module):
def __init__(self, config):
super(RCNN, self).__init__()
hidden_size = config["hidden_size"]
self.rnn = nn.RNN(hidden_size, hidden_size)
self.cnn = GatedCNN(config)
def forward(self, x):
x, _ = self.rnn(x)
x = self.cnn(x)
return xⅦ、手动实现结合BERT和LSTM的模型(BertLSTM)
BertModel.from_pretrained():是 Hugging Face Transformers 库中的一个方法,用于从预训练的权重加载 BERT 模型。这使得用户可以快速使用预训练的 BERT 模型进行微调或直接应用,而无需从头开始训练。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
pretrained_model_name_or_path |
str | "bert-base-uncased" | 预训练模型的名称(如 "bert-base-uncased")或本地路径。 |
config |
Config | None | 模型的配置对象,可以自定义配置参数。 |
cache_dir |
str | None | 缓存预训练模型的目录。如果模型已经缓存,将从缓存中加载。 |
force_download |
bool | False | 是否强制重新下载模型,即使已经存在缓存。 |
resume_download |
bool | False | 下载中断后是否继续下载。 |
local_files_only |
bool | False | 是否仅使用本地文件,不尝试从远程服务器下载。 |
mirror_url |
str | None | 镜像 URL 地址,用于从镜像源下载模型。 |
progress |
bool | True | 是否显示下载进度条。 |
nn.LSTM():PyTorch 中实现长短期记忆网络(Long Short-Term Memory)的模块。LSTM 是一种特殊的循环神经网络(RNN),能够有效捕捉长距离依赖关系,广泛应用于序列建模任务,如自然语言处理、时间序列预测等。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input_size |
int | - | 输入特征的维度。 |
hidden_size |
int | - | 隐藏层的大小。 |
num_layers |
int | 1 | LSTM 层的堆叠层数。 |
bias |
bool | True | 是否使用偏置项。如果为 False,则不使用偏置。 |
batch_first |
bool | False | 如果为 True,输入和输出张量的形状为 (batch, seq, feature)。默认为 False(形状为 (seq, batch, feature))。 |
dropout |
float | 0 | 如果 num_layers > 1,层之间的 dropout 概率。 |
bidirectional |
bool | False | 是否使用双向 LSTM。 |
proj_size |
int | 0 | 输出投影的大小。如果大于0,输出会被投影到 proj_size 维度。默认为0,表示不进行投影。 |
class BertLSTM(nn.Module):
def __init__(self, config):
super(BertLSTM, self).__init__()
self.bert = BertModel.from_pretrained(config["pretrain_model_path"], return_dict=False)
self.rnn = nn.LSTM(self.bert.config.hidden_size, self.bert.config.hidden_size, batch_first=True)
def forward(self, x):
x = self.bert(x)[0]
x, _ = self.rnn(x)
return xⅧ、 手动实现集合Bert和CNN的模型(BertCNN)
BertModel.from_pretrained():是 Hugging Face Transformers 库中的一个方法,用于从预训练的权重加载 BERT 模型。这使得用户可以快速使用预训练的 BERT 模型进行微调或直接应用,而无需从头开始训练。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
pretrained_model_name_or_path |
str | "bert-base-uncased" | 预训练模型的名称(如 "bert-base-uncased")或本地路径。 |
config |
Config | None | 模型的配置对象,可以自定义配置参数。 |
cache_dir |
str | None | 缓存预训练模型的目录。如果模型已经缓存,将从缓存中加载。 |
force_download |
bool | False | 是否强制重新下载模型,即使已经存在缓存。 |
resume_download |
bool | False | 下载中断后是否继续下载。 |
local_files_only |
bool | False | 是否仅使用本地文件,不尝试从远程服务器下载。 |
mirror_url |
str | None | 镜像 URL 地址,用于从镜像源下载模型。 |
progress |
bool | True | 是否显示下载进度条。 |
class BertCNN(nn.Module):
def __init__(self, config):
super(BertCNN, self).__init__()
self.bert = BertModel.from_pretrained(config["pretrain_model_path"], return_dict=False)
config["hidden_size"] = self.bert.config.hidden_size
self.cnn = CNN(config)
def forward(self, x):
x = self.bert(x)[0]
x = self.cnn(x)
return xⅨ、手动实现提取BERT模型中间层的输出(BertMidLayer)
BertModel.from_pretrained():是 Hugging Face Transformers 库中的一个方法,用于从预训练的权重加载 BERT 模型。这使得用户可以快速使用预训练的 BERT 模型进行微调或直接应用,而无需从头开始训练。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
pretrained_model_name_or_path |
str | "bert-base-uncased" | 预训练模型的名称(如 "bert-base-uncased")或本地路径。 |
config |
Config | None | 模型的配置对象,可以自定义配置参数。 |
cache_dir |
str | None | 缓存预训练模型的目录。如果模型已经缓存,将从缓存中加载。 |
force_download |
bool | False | 是否强制重新下载模型,即使已经存在缓存。 |
resume_download |
bool | False | 下载中断后是否继续下载。 |
local_files_only |
bool | False | 是否仅使用本地文件,不尝试从远程服务器下载。 |
mirror_url |
str | None | 镜像 URL 地址,用于从镜像源下载模型。 |
progress |
bool | True | 是否显示下载进度条。 |
self.bert.config.output_hidden_states: 是否取出Bert中间层的输出
torch.add(): PyTorch 中的一个函数,用于对输入张量进行逐元素相加操作。它支持多种操作模式,包括将一个张量加到另一个张量上,或者将一个标量加到张量的每个元素上。
| 参数名称 | 类型 | 描述 |
|---|---|---|
input |
Tensor | 第一个输入张量。 |
other |
Tensor 或 float | 第二个输入张量或标量。可以是与 input 形状相同的张量,或者是一个标量。 |
out |
Tensor, 可选 | 输出张量,用于存储结果。如果未提供,将创建一个新的张量。 |
alpha |
float, 可选 | 标量乘数,用于缩放 other 张量后再进行相加。默认为1。 |
class BertMidLayer(nn.Module):
def __init__(self, config):
super(BertMidLayer, self).__init__()
self.bert = BertModel.from_pretrained(config["pretrain_model_path"], return_dict=False)
self.bert.config.output_hidden_states = True
def forward(self, x):
layer_states = self.bert(x)[2]#(13, batch, len, hidden)
layer_states = torch.add(layer_states[-2], layer_states[-1])
return layer_statesⅩ、选择优化器
Adam(): 是一种自适应学习率优化算法,结合了动量(Momentum)和均方根传播(RMSprop)的优点。它通过计算梯度的一阶矩估计和二阶矩估计来调整每个参数的学习率,从而在训练过程中自适应地调整学习步长。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
params |
Iterable | - | 需要优化的模型参数(通常是 model.parameters())。 |
lr |
float | 1e-3 | 学习率。 |
betas |
Tuple[float, float] | (0.9, 0.999) | 用于计算梯度及其平方的运行平均值的系数。 |
eps |
float | 1e-8 | 数值稳定性的小常数,防止除以零。 |
weight_decay |
float | 0 | 权重衰减(L2正则化)。 |
amsgrad |
bool | False | 是否使用 AMSGrad 变种。 |
SGD():随机梯度下降)是一种基本的优化算法,通过计算损失函数对模型参数的梯度,并按照一定的学习率更新参数。虽然简单,但在许多情况下仍然有效,尤其是在结合动量(momentum)时。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
params |
Iterable | - | 需要优化的模型参数(通常是 model.parameters())。 |
lr |
float | 0.01 | 学习率。 |
momentum |
float | 0 | 动量系数,用于加速SGD在相关方向上的收敛,并抑制震荡。 |
dampening |
float | 0 | 动量的阻尼系数。 |
weight_decay |
float | 0 | 权重衰减(L2正则化)。 |
nesterov |
bool | False | 是否使用Nesterov动量。 |
.parameters():是 PyTorch 中 nn.Module 类的一个方法,用于返回模型中所有需要优化的参数的迭代器。这些参数通常包括模型的权重和偏置项。通过调用此方法,可以将模型的参数传递给优化器进行更新。
| 参数名称 | 类型 | 描述 |
|---|---|---|
recurse |
bool | 如果为 True,则递归地遍历所有子模块,收集它们的参数。默认为 True。 |
def choose_optimizer(config, model):
optimizer = config["optimizer"]
learning_rate = config["learning_rate"]
if optimizer == "adam":
return Adam(model.parameters(), lr=learning_rate)
elif optimizer == "sgd":
return SGD(model.parameters(), lr=learning_rate)ⅩⅠ、建立网络模型结构
BertModel.from_pretrained():是 Hugging Face Transformers 库中的一个方法,用于从预训练的权重加载 BERT 模型。这使得用户可以快速使用预训练的 BERT 模型进行微调或直接应用,而无需从头开始训练。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
pretrained_model_name_or_path |
str | "bert-base-uncased" | 预训练模型的名称(如 "bert-base-uncased")或本地路径。 |
config |
Config | None | 模型的配置对象,可以自定义配置参数。 |
cache_dir |
str | None | 缓存预训练模型的目录。如果模型已经缓存,将从缓存中加载。 |
force_download |
bool | False | 是否强制重新下载模型,即使已经存在缓存。 |
resume_download |
bool | False | 下载中断后是否继续下载。 |
local_files_only |
bool | False | 是否仅使用本地文件,不尝试从远程服务器下载。 |
mirror_url |
str | None | 镜像 URL 地址,用于从镜像源下载模型。 |
progress |
bool | True | 是否显示下载进度条。 |
torch.LongTensor():PyTorch 中用于创建一个长整型(64位整数)张量的函数。长整型张量在需要存储整数索引、类别标签或其他需要较大整数范围的场景中非常有用。例如,在处理分类任务时,类别标签通常使用长整型表示。
| 参数名称 | 类型 | 描述 |
|---|---|---|
data |
可选 | 用于初始化张量的数据,可以是列表、元组、NumPy 数组等。 |
dtype |
可选 | 指定张量的数据类型,默认为 torch.int64(即 LongTensor)。 |
device |
可选 | 指定张量所在的设备(如 'cpu' 或 'cuda:0')。 |
requires_grad |
可选 | 是否需要计算梯度,默认为 False。 |
size |
可选 | 指定张量的形状,可以是一个整数或整数元组。 |
| 其他参数 | 可选 | 根据 data 的类型,可能需要提供其他参数,如 dtype 等。 |
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
from torch.optim import Adam, SGD
from transformers import BertModel
"""
建立网络模型结构
"""
class TorchModel(nn.Module):
def __init__(self, config):
super(TorchModel, self).__init__()
hidden_size = config["hidden_size"]
vocab_size = config["vocab_size"] + 1
class_num = config["class_num"]
model_type = config["model_type"]
num_layers = config["num_layers"]
self.use_bert = False
self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)
if model_type == "fast_text":
self.encoder = lambda x: x
elif model_type == "lstm":
self.encoder = nn.LSTM(hidden_size, hidden_size, num_layers=num_layers, batch_first=True)
elif model_type == "gru":
self.encoder = nn.GRU(hidden_size, hidden_size, num_layers=num_layers, batch_first=True)
elif model_type == "rnn":
self.encoder = nn.RNN(hidden_size, hidden_size, num_layers=num_layers, batch_first=True)
elif model_type == "cnn":
self.encoder = CNN(config)
elif model_type == "gated_cnn":
self.encoder = GatedCNN(config)
elif model_type == "stack_gated_cnn":
self.encoder = StackGatedCNN(config)
elif model_type == "rcnn":
self.encoder = RCNN(config)
elif model_type == "bert":
self.use_bert = True
self.encoder = BertModel.from_pretrained(config["pretrain_model_path"], return_dict=False)
hidden_size = self.encoder.config.hidden_size
elif model_type == "bert_lstm":
self.use_bert = True
self.encoder = BertLSTM(config)
hidden_size = self.encoder.bert.config.hidden_size
elif model_type == "bert_cnn":
self.use_bert = True
self.encoder = BertCNN(config)
hidden_size = self.encoder.bert.config.hidden_size
elif model_type == "bert_mid_layer":
self.use_bert = True
self.encoder = BertMidLayer(config)
hidden_size = self.encoder.bert.config.hidden_size
self.classify = nn.Linear(hidden_size, class_num)
self.pooling_style = config["pooling_style"]
self.loss = nn.functional.cross_entropy #loss采用交叉熵损失
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, target=None):
if self.use_bert: # bert返回的结果是 (sequence_output, pooler_output)
#sequence_output:batch_size, max_len, hidden_size
#pooler_output:batch_size, hidden_size
x = self.encoder(x)
else:
x = self.embedding(x) # input shape:(batch_size, sen_len)
x = self.encoder(x) # input shape:(batch_size, sen_len, input_dim)
if isinstance(x, tuple): #RNN类的模型会同时返回隐单元向量,我们只取序列结果
x = x[0]
#可以采用pooling的方式得到句向量
if self.pooling_style == "max":
self.pooling_layer = nn.MaxPool1d(x.shape[1])
else:
self.pooling_layer = nn.AvgPool1d(x.shape[1])
x = self.pooling_layer(x.transpose(1, 2)).squeeze() #input shape:(batch_size, sen_len, input_dim)
#也可以直接使用序列最后一个位置的向量
# x = x[:, -1, :]
predict = self.classify(x) #input shape:(batch_size, input_dim)
if target is not None:
return self.loss(predict, target.squeeze())
else:
return predict
class CNN(nn.Module):
def __init__(self, config):
super(CNN, self).__init__()
hidden_size = config["hidden_size"]
kernel_size = config["kernel_size"]
pad = int((kernel_size - 1)/2)
self.cnn = nn.Conv1d(hidden_size, hidden_size, kernel_size, bias=False, padding=pad)
def forward(self, x): #x : (batch_size, max_len, embeding_size)
return self.cnn(x.transpose(1, 2)).transpose(1, 2)
class GatedCNN(nn.Module):
def __init__(self, config):
super(GatedCNN, self).__init__()
self.cnn = CNN(config)
self.gate = CNN(config)
def forward(self, x):
a = self.cnn(x)
b = self.gate(x)
b = torch.sigmoid(b)
return torch.mul(a, b)
class StackGatedCNN(nn.Module):
def __init__(self, config):
super(StackGatedCNN, self).__init__()
self.num_layers = config["num_layers"]
self.hidden_size = config["hidden_size"]
#ModuleList类内可以放置多个模型,取用时类似于一个列表
self.gcnn_layers = nn.ModuleList(
GatedCNN(config) for i in range(self.num_layers)
)
self.ff_liner_layers1 = nn.ModuleList(
nn.Linear(self.hidden_size, self.hidden_size) for i in range(self.num_layers)
)
self.ff_liner_layers2 = nn.ModuleList(
nn.Linear(self.hidden_size, self.hidden_size) for i in range(self.num_layers)
)
self.bn_after_gcnn = nn.ModuleList(
nn.LayerNorm(self.hidden_size) for i in range(self.num_layers)
)
self.bn_after_ff = nn.ModuleList(
nn.LayerNorm(self.hidden_size) for i in range(self.num_layers)
)
def forward(self, x):
#仿照bert的transformer模型结构,将self-attention替换为gcnn
for i in range(self.num_layers):
gcnn_x = self.gcnn_layers[i](x)
x = gcnn_x + x #通过gcnn+残差
x = self.bn_after_gcnn[i](x) #之后bn
# # 仿照feed-forward层,使用两个线性层
l1 = self.ff_liner_layers1[i](x) #一层线性
l1 = torch.relu(l1) #在bert中这里是gelu
l2 = self.ff_liner_layers2[i](l1) #二层线性
x = self.bn_after_ff[i](x + l2) #残差后过bn
return x
class RCNN(nn.Module):
def __init__(self, config):
super(RCNN, self).__init__()
hidden_size = config["hidden_size"]
self.rnn = nn.RNN(hidden_size, hidden_size)
self.cnn = GatedCNN(config)
def forward(self, x):
x, _ = self.rnn(x)
x = self.cnn(x)
return x
class BertLSTM(nn.Module):
def __init__(self, config):
super(BertLSTM, self).__init__()
self.bert = BertModel.from_pretrained(config["pretrain_model_path"], return_dict=False)
self.rnn = nn.LSTM(self.bert.config.hidden_size, self.bert.config.hidden_size, batch_first=True)
def forward(self, x):
x = self.bert(x)[0]
x, _ = self.rnn(x)
return x
class BertCNN(nn.Module):
def __init__(self, config):
super(BertCNN, self).__init__()
self.bert = BertModel.from_pretrained(config["pretrain_model_path"], return_dict=False)
config["hidden_size"] = self.bert.config.hidden_size
self.cnn = CNN(config)
def forward(self, x):
x = self.bert(x)[0]
x = self.cnn(x)
return x
class BertMidLayer(nn.Module):
def __init__(self, config):
super(BertMidLayer, self).__init__()
self.bert = BertModel.from_pretrained(config["pretrain_model_path"], return_dict=False)
self.bert.config.output_hidden_states = True
def forward(self, x):
layer_states = self.bert(x)[2]#(13, batch, len, hidden)
layer_states = torch.add(layer_states[-2], layer_states[-1])
return layer_states
#优化器的选择
def choose_optimizer(config, model):
optimizer = config["optimizer"]
learning_rate = config["learning_rate"]
if optimizer == "adam":
return Adam(model.parameters(), lr=learning_rate)
elif optimizer == "sgd":
return SGD(model.parameters(), lr=learning_rate)
if __name__ == "__main__":
from config import Config
# Config["class_num"] = 3
# Config["vocab_size"] = 20
# Config["max_length"] = 5
Config["model_type"] = "bert"
model = BertModel.from_pretrained(Config["F:\人工智能NLP/NLP资料\week6 语言模型/bert-base-chinese"], return_dict=False)
x = torch.LongTensor([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]])
sequence_output, pooler_output = model(x)
print(x[2], type(x[2]), len(x[2]))
# model = TorchModel(Config)
# label = torch.LongTensor([1,2])
# print(model(x, label))4.模型效果测试 evaluate.py
定义评价指标,每轮训练后做评测(固定任务中,评价指标基本固定,不同任务,评价函数不同)
Ⅰ、初始化
config:存储模型的配置参数,如学习率、批次大小、路径等。这些参数通常从配置文件(如 JSON、YAML)中读取,并在初始化时传递给类
model:模型对象,存储要使用的机器学习或深度学习模型。这个模型将在训练、验证或测试过程中使用。
logger:日志记录器对象,用于记录训练过程中的信息、警告或错误。日志记录有助于调试和监控模型的训练状态。
valid_data:验证数据集路径
stats_dict:初始化一个字典,用于存储测试或验证过程中的统计结果。
load_data(): 是一个常用的函数,用于加载和预处理数据,以便在机器学习或深度学习模型中使用。具体的实现可能会根据数据的类型、来源以及预处理的需求而有所不同。
| 参数名称 | 类型 | 描述 |
|---|---|---|
data_path |
str |
数据文件的路径或数据源的标识符。 |
config |
dict 或 Config 对象 |
包含数据加载和预处理相关配置的字典或配置对象。 |
shuffle |
bool |
是否在加载数据后打乱数据顺序。默认为 True。 |
batch_size |
int |
每个批次的数据量。用于批量加载数据时使用。 |
num_workers |
int |
用于数据加载的子进程数量。提高数据加载速度。 |
transform |
callable |
数据预处理的转换函数或 torchvision 的 transforms.Compose 对象。 |
| 其他参数 | 根据具体需求 | 例如,标签文件路径、数据分割比例等。 |
def __init__(self, config, model, logger):
self.config = config
self.model = model
self.logger = logger
self.valid_data = load_data(config["valid_data_path"], config, shuffle=False)
self.stats_dict = {"correct":0, "wrong":0} #用于存储测试结果Ⅱ、模型评估,返回预测准确率
.info():对于 torch.Tensor:显示张量的详细信息,包括其大小、数据类型、设备(CPU/GPU)、是否需要梯度等。对于 nn.Module:显示模型的结构、参数数量、各层的详细信息等。
.eval():将模型设置为评估模式。在评估模式下,某些层(如 Dropout 和 BatchNorm)的行为会发生变化,以确保评估结果的准确性。
enumerate():函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
| 参数名称 | 类型 | 描述 |
|---|---|---|
iterable |
可迭代对象 | 需要被枚举的对象,如列表、元组、字符串等。 |
start |
int,可选 |
索引起始值,默认为 0。可以指定其他整数作为起始索引。 |
torch.cuda.is_available():用于检测当前系统中是否安装了支持 CUDA 的 NVIDIA GPU,并且 PyTorch 是否能够利用这些 GPU 资源。
.cuda():用于将张量或模型移动到指定的 CUDA 设备上,以便利用 GPU 进行加速计算。
| 参数名称 | 类型 | 描述 |
|---|---|---|
device |
int 或 str 或 torch.device |
可选参数,指定要移动到的 CUDA 设备。可以是设备的索引(如 0)、设备的名称(如 'cuda:0'),或 torch.device 对象。如果未指定,默认使用当前默认的 CUDA 设备。 |
torch.no_grad():用于临时禁用梯度计算。这在模型评估、推理或任何不需要计算梯度的操作中非常有用。使用该上下文管理器可以减少内存消耗并提高计算速度。
def eval(self, epoch):
self.logger.info("开始测试第%d轮模型效果:" % epoch)
self.model.eval()
self.stats_dict = {"correct": 0, "wrong": 0} # 清空上一轮结果
for index, batch_data in enumerate(self.valid_data):
if torch.cuda.is_available():
batch_data = [d.cuda() for d in batch_data]
input_ids, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
with torch.no_grad():
pred_results = self.model(input_ids) #不输入labels,使用模型当前参数进行预测
self.write_stats(labels, pred_results)
acc = self.show_stats()
return accⅢ、 统计预测结果正误数量
assert:Python 中的一个内置函数,用于在代码中设置断言,以验证某个条件是否为真。如果条件为假,assert 会引发一个 AssertionError 异常。这在调试和测试代码时非常有用,可以帮助开发者快速定位问题。
-
condition:一个布尔表达式,如果为False,则引发AssertionError。 -
message(可选):一个字符串,当断言失败时作为错误消息显示。
len():返回对象的长度或项目数。适用于列表、字典、字符串、集合、元组等可迭代对象。
| 参数名称 | 类型 | 描述 |
|---|---|---|
obj |
可迭代对象 | 需要计算长度的对象,如列表、字典、字符串等。 |
zip():用于将多个可迭代对象“压缩”在一起,生成一个由元组组成的迭代器。每个元组包含来自各个可迭代对象的元素。常用于并行迭代多个序列。
| 参数名称 | 类型 | 描述 |
|---|---|---|
iterable1, iterable2, ... |
可迭代对象 | 任意数量的可迭代对象,如列表、元组、字符串等。 |
torch.argmax():用于返回张量中指定维度上的最大值的索引。如果未指定维度,则返回整个张量中最大值的扁平化索引。常用于分类任务中获取预测类别。
| 参数名称 | 类型 | 描述 |
|---|---|---|
input |
Tensor |
输入的张量。 |
dim |
int |
(可选)要沿哪个维度查找最大值的索引。默认为 None,此时返回整个张量中最大值的扁平化索引。 |
keepdim |
bool |
(可选)是否保持输出张量的维度与输入相同。默认为 False。 |
int():用于将一个数字或字符串转换为整数。如果传入浮点数,会截断小数部分;如果传入字符串,必须是有效的整数表示。
| 参数名称 | 类型 | 描述 |
|---|---|---|
x |
int, float, str, bytes, bytearray, bool |
要转换的数字或字符串。 |
base |
int |
(可选)进制数,默认为 10。仅当 x 是字符串时使用。 |
def write_stats(self, labels, pred_results):
assert len(labels) == len(pred_results)
for true_label, pred_label in zip(labels, pred_results):
pred_label = torch.argmax(pred_label)
if int(true_label) == int(pred_label):
self.stats_dict["correct"] += 1
else:
self.stats_dict["wrong"] += 1
returnⅣ、显示预测结果的统计信息并返回准确率
.info():对于 torch.Tensor:显示张量的详细信息,包括其大小、数据类型、设备(CPU/GPU)、是否需要梯度等。对于 nn.Module:显示模型的结构、参数数量、各层的详细信息等。
def show_stats(self):
correct = self.stats_dict["correct"]
wrong = self.stats_dict["wrong"]
self.logger.info("预测集合条目总量:%d" % (correct +wrong))
self.logger.info("预测正确条目:%d,预测错误条目:%d" % (correct, wrong))
self.logger.info("预测准确率:%f" % (correct / (correct + wrong)))
self.logger.info("--------------------")
return correct / (correct + wrong)Ⅴ、模型效果测试
# -*- coding: utf-8 -*-
import torch
from loader import load_data
"""
模型效果测试
"""
class Evaluator:
def __init__(self, config, model, logger):
self.config = config
self.model = model
self.logger = logger
self.valid_data = load_data(config["valid_data_path"], config, shuffle=False)
self.stats_dict = {"correct":0, "wrong":0} #用于存储测试结果
def eval(self, epoch):
self.logger.info("开始测试第%d轮模型效果:" % epoch)
self.model.eval()
self.stats_dict = {"correct": 0, "wrong": 0} # 清空上一轮结果
for index, batch_data in enumerate(self.valid_data):
if torch.cuda.is_available():
batch_data = [d.cuda() for d in batch_data]
input_ids, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
with torch.no_grad():
pred_results = self.model(input_ids) #不输入labels,使用模型当前参数进行预测
self.write_stats(labels, pred_results)
acc = self.show_stats()
return acc
def write_stats(self, labels, pred_results):
assert len(labels) == len(pred_results)
for true_label, pred_label in zip(labels, pred_results):
pred_label = torch.argmax(pred_label)
if int(true_label) == int(pred_label):
self.stats_dict["correct"] += 1
else:
self.stats_dict["wrong"] += 1
return
def show_stats(self):
correct = self.stats_dict["correct"]
wrong = self.stats_dict["wrong"]
self.logger.info("预测集合条目总量:%d" % (correct +wrong))
self.logger.info("预测正确条目:%d,预测错误条目:%d" % (correct, wrong))
self.logger.info("预测准确率:%f" % (correct / (correct + wrong)))
self.logger.info("--------------------")
return correct / (correct + wrong)
5.主函数文件 main.py
模型训练主流程(改动倾向于最小,几乎不需要动)
Ⅰ、导入参数
logging.basicConfig():Python logging 模块中的一个函数,用于配置日志系统的基本设置。通过调用此函数,可以设置日志记录的基本参数,如日志级别、日志格式、日志输出位置(控制台或文件)、日志文件的滚动策略等。如果日志系统已经配置过,再次调用 basicConfig() 通常不会有任何效果,除非设置了 force=True。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
level |
int | logging.WARNING |
设置日志记录的最低级别。常用级别包括 DEBUG (10)、INFO (20)、WARNING (30)、ERROR (40)、CRITICAL (50)。 |
filename |
str | None | 指定日志输出的文件名。如果未指定,日志将输出到标准错误流(stderr)。 |
filemode |
str | 'a' |
文件打开模式,如 'a'(追加)、'w'(写入)。 |
format |
str | '%(levelname)s:%(name)s:%(message)s' |
日志记录的格式字符串,可以使用各种格式化选项。 |
datefmt |
str | None | 日期时间的格式字符串,用于格式化日志记录中的时间戳。 |
style |
str | '%' |
格式字符串的风格,支持 '%'、'{' 和 '$'。 |
handlers |
list | None | 指定要添加的日志处理器列表。如果未指定,将使用默认的处理器。 |
force |
bool | False | 如果为 True,则强制重新配置日志系统,即使已经配置过。 |
encoding |
str | None | 文件编码,用于写入日志文件时指定编码格式。 |
delay |
bool | False | 如果为 True,则在第一次记录日志时才打开日志文件。 |
handlers |
list | None | 指定要添加的日志处理器列表。如果未指定,将使用默认的处理器。 |
logging.getLogger():logging 模块中的一个函数,用于获取一个日志记录器(Logger)对象。日志记录器用于记录应用程序中的日志信息。通过调用 getLogger() 并传入一个名称,可以获取指定名称的日志记录器。如果传入的名称相同,将返回同一个日志记录器实例,从而实现日志记录器的复用。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
name |
str | 'root' |
日志记录器的名称。使用点分隔的层级名称可以创建日志记录器的层次结构。如果未指定,默认为 'root'。 |
version |
int | None | 日志记录器的版本号,通常用于配置日志记录器的层次结构。 |
# [DEBUG, INFO, WARNING, ERROR, CRITICAL]
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
Ⅱ、定义一个随机数种子
定义一个随机数种子,有助于复现实验结果
random.seed():Python 内置 random 模块中的函数,用于初始化随机数生成器的种子。设置相同的种子可以确保每次运行程序时生成的随机数序列相同,这对于结果的可重复性非常重要。
| 参数名称 | 类型 | 描述 |
|---|---|---|
a |
int 或 None | 种子值。如果未提供,默认为当前时间或操作系统特定的随机源。如果设置为 None,则使用系统时间或操作系统特定的随机源。 |
np.random.seed():NumPy 库中的函数,用于设置全局随机种子。这确保了使用 NumPy 生成的随机数序列在每次运行时保持一致,从而实现结果的可重复性。
| 参数名称 | 类型 | 描述 |
|---|---|---|
seed |
int 或 None | 种子值。如果未提供,默认为当前时间或操作系统特定的随机源。如果设置为 None,则使用系统时间或操作系统特定的随机源。 |
torch.manual_seed():PyTorch 库中的函数,用于设置 CPU 的随机种子。这确保了使用 PyTorch 在 CPU 上生成的随机数序列在每次运行时保持一致,从而实现结果的可重复性
| 参数名称 | 类型 | 描述 |
|---|---|---|
seed |
int | 种子值。必须是一个非负整数。 |
torch.cuda.manual_seed_all():PyTorch 库中的函数,用于设置所有可用 CUDA 设备的随机种子。这确保了在使用 PyTorch 进行 GPU 计算时,生成的随机数序列在每次运行时保持一致,从而实现结果的可重复性。
| 参数名称 | 类型 | 描述 |
|---|---|---|
seed |
int | 种子值。必须是一个非负整数。 |
# 定义随机数种子
seed = Config["seed"]
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)Ⅲ、模型训练
1.配置参数
os.path.isdir(): Python os 模块中的一个函数,用于判断指定的路径是否是一个目录(文件夹)。它返回一个布尔值,如果路径存在且是一个目录,则返回 True,否则返回 False。
| 参数名称 | 类型 | 描述 |
|---|---|---|
path |
str | 要检查的路径字符串。可以是绝对路径或相对路径。 |
os.mkdir():是 Python os 模块中的一个函数,用于创建一个新的目录。如果目录已经存在,会引发 FileExistsError 异常。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
path |
str 或 bytes | - | 要创建的目录路径。 |
mode |
int | 0o777 |
目录的权限模式(如 0o755)。在大多数平台上会被 umask 修改。 |
dir_fd |
int, 可选 | None |
文件描述符,用于相对于某个目录创建新目录(高级用法)。 |
torch.cuda.is_available():PyTorch 库中的一个函数,用于检查当前环境中是否可用 CUDA(即 NVIDIA GPU 支持)。如果 CUDA 可用且 PyTorch 已正确配置,函数返回 True,否则返回 False。
logger.info():Python logging 模块中的一个方法,用于记录信息级别的日志消息。通常用于记录程序的正常运行状态或重要事件。
| 参数名称 | 类型 | 描述 |
|---|---|---|
message |
str | 要记录的信息消息。 |
.cuda():PyTorch 中张量(Tensor)和模型(Module)的一个方法,用于将张量或模型移动到 CUDA 设备(即 GPU)上进行计算。如果系统中有多个 GPU,可以通过指定设备索引来选择特定的 GPU。
| 参数名称 | 类型 | 描述 |
|---|---|---|
device |
int 或 str, 可选 | 指定要移动到的 CUDA 设备。可以是设备索引(如 0)或设备名称(如 'cuda:0')。默认为 'cuda',即默认 GPU。 |
2.训练主流程
标准梯度下降法训练四步:
① 梯度归零:optimizer.zero_grad():优化器(如
torch.optim.Adam、torch.optim.SGD等)的方法,用于将优化器中所有参数的梯度清零。在使用梯度下降等优化算法时,每次反向传播前需要清零梯度,以避免梯度累积导致训练不稳定。② 前向计算,计算loss损失
③ 反向传播,计算梯度:loss.backward():是 PyTorch 中张量(Tensor)的方法,用于计算损失函数相对于模型参数的梯度。调用此方法会执行反向传播算法,自动计算所有需要梯度的张量的梯度。
参数名称 类型 描述 retain_graphbool, 可选 是否保留计算图,默认为 False。如果需要在多次反向传播中复用计算图,可以设置为True。create_graphbool, 可选 是否创建计算图的导数,默认为 False。用于高阶导数计算。④ 根据梯度优化模型权重:optimizer.step():优化器的方法,用于根据计算得到的梯度更新模型的参数。调用此方法会根据优化算法(如 SGD、Adam 等)更新模型的权重和偏置。
range():是 Python 的内置函数,用于生成一个整数序列。range 返回一个 range 对象,该对象可以用于 for 循环或其他需要序列的场景。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
start |
int | 0 | 序列的起始值(包含)。默认为0。 |
stop |
int | - | 序列的结束值(不包含)。必须指定。 |
step |
int | 1 | 序列中相邻两个数之间的差值。默认为1。 |
model.train():PyTorch 模型的方法,用于将模型设置为训练模式。在训练模式下,某些层(如 Dropout、BatchNorm)会表现出不同的行为,以确保训练过程的正确性。
logger.info(): Python logging 模块中的方法,用于记录信息级别的日志消息。通常用于记录程序的正常运行状态或重要事件。
| 参数名称 | 类型 | 描述 |
|---|---|---|
message |
str | 要记录的信息消息。 |
enumerate():Python 的内置函数,用于将可迭代对象(如列表、元组、字符串等)组合为一个索引序列,同时获取每个元素的索引和值。常用于遍历列表时同时获取元素的索引和值。
| 参数名称 | 类型 | 描述 |
|---|---|---|
iterable |
可迭代对象 | 需要遍历的可迭代对象。 |
start |
int, 可选 | 索引起始值,默认为 0。 |
append():Python 列表(list)的方法,用于在列表末尾添加一个元素。常用于动态扩展列表内容。
| 参数名称 | 类型 | 描述 |
|---|---|---|
item |
任意 | 要添加到列表末尾的元素。 |
.item():PyTorch 中张量(Tensor)的一个方法,用于将单个元素的张量转换为对应的 Python 数值。它主要用于从标量张量中提取数值,以便在需要时进行进一步的处理或显示。
适用场景:① 当张量只包含一个元素时,可以使用 item() 方法将其转换为 Python 的基本数据类型(如 int、float 等)。② 常用于获取损失函数的值、评估指标或其他需要将张量结果转化为可读格式的场景。
np.mean():NumPy 库中的函数,用于计算数组中元素的平均值。可以沿着指定的轴计算平均值,或者对整个数组计算全局平均值。
| 参数名称 | 类型 | 描述 |
|---|---|---|
a |
array_like | 输入数组。 |
axis |
int 或 tuple, 可选 | 沿着哪个轴计算平均值。默认为 None,表示计算整个数组的平均值。 |
dtype |
data-type, 可选 | 计算平均值时使用的数据类型。 |
out |
ndarray, 可选 | 用于存放结果的替代输出数组。 |
keepdims |
bool, 可选 | 如果为 True,则保持被缩减轴的维度。默认为 False。 |
where |
array_like, 可选 | 用于选择哪些元素参与平均值计算,默认为所有元素。 |
model.eval():PyTorch 中模型(通常是继承自 nn.Module 的类的实例)的一个方法,用于将模型设置为评估模式(evaluation mode)。在评估模式下,某些层(如 Dropout 和 Batch Normalization)会改变其行为,以确保模型在测试或验证数据上的表现与实际应用中一致。
主要作用:① 禁用 Dropout:在评估模式下,Dropout 层不会随机丢弃神经元,而是按训练时学习到的权重进行前向传播。② 使用固定统计量:Batch Normalization 层在评估模式下会使用训练过程中累积的全局均值和方差,而不是当前批次的统计数据。
os.path.join():Python os 模块中的一个函数,用于将多个路径部分组合成一个完整的路径字符串。它会根据操作系统的不同自动选择合适的路径分隔符(如 Windows 使用 \,Unix/Linux/Mac 使用 /)。
| 参数名称 | 类型 | 描述 |
|---|---|---|
*paths |
str | 一个或多个路径部分,可以是字符串或字节。这些部分将被连接成一个完整的路径。 |
state_dict(): PyTorch 中 nn.Module 类的一个方法,用于返回一个包含模型所有可学习参数和缓冲区的字典。state_dict 是一种方便的方式来保存和加载模型的状态,常用于模型的保存、加载和迁移学习。
torch.save(): PyTorch 中用于序列化并保存对象到磁盘的函数。它可以保存各种 PyTorch 对象,如模型、张量、字典等。常用于保存训练好的模型、优化器状态或其他需要持久化的数据。
| 参数名称 | 类型 | 描述 |
|---|---|---|
obj |
任意 | 要保存的对象,如模型、张量、字典等。 |
f |
str 或 pathlib.Path 或 file-like object |
保存对象的路径或文件对象。可以是字符串路径、pathlib.Path 对象,或任何支持 write() 方法的文件对象。 |
pickle_module |
可选,module |
用于序列化和反序列化的 pickle 模块,默认为 torch._C.PickleModule。 |
pickle_protocol |
可选,int |
使用的 pickle 协议版本,默认为 pickle.HIGHEST_PROTOCOL。 |
_use_new_zipfile_serialization |
可选,bool |
是否使用新的 zipfile 序列化方式,默认为 False。 |
def main(config):
# 创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])
# 加载训练数据
train_data = load_data(config["train_data_path"], config)
# 加载模型
model = TorchModel(config)
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
model = model.cuda()
# 加载优化器
optimizer = choose_optimizer(config, model)
# 加载效果测试类
evaluator = Evaluator(config, model, logger)
# 训练
for epoch in range(config["epoch"]):
epoch += 1
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
optimizer.zero_grad()
input_ids, labels = batch_data # 输入变化时这里需要修改,比如多输入,多输出的情况
loss = model(input_ids, labels)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)
logger.info("epoch average loss: %f" % np.mean(train_loss))
acc = evaluator.eval(epoch)
# model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)
# torch.save(model.state_dict(), model_path) #保存模型权重
return accⅣ、配置参数,训练模型
# -*- coding: utf-8 -*-
import torch
import os
import random
import os
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
# [DEBUG, INFO, WARNING, ERROR, CRITICAL]
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
"""
模型训练主程序
"""
# 定义随机数种子
seed = Config["seed"]
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def main(config):
# 创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])
# 加载训练数据
train_data = load_data(config["train_data_path"], config)
# 加载模型
model = TorchModel(config)
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
model = model.cuda()
# 加载优化器
optimizer = choose_optimizer(config, model)
# 加载效果测试类
evaluator = Evaluator(config, model, logger)
# 训练
for epoch in range(config["epoch"]):
epoch += 1
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
optimizer.zero_grad()
input_ids, labels = batch_data # 输入变化时这里需要修改,比如多输入,多输出的情况
loss = model(input_ids, labels)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)
logger.info("epoch average loss: %f" % np.mean(train_loss))
acc = evaluator.eval(epoch)
# model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)
# torch.save(model.state_dict(), model_path) #保存模型权重
return acc
if __name__ == "__main__":
for model in ["cnn"]:
Config["model_type"] = model
print("最后一轮准确率:", main(Config), "当前配置:", Config["model_type"])CNN卷积神经网络作文本分类任务: ![]()
Ⅴ、对比其他模型 🔍
# -*- coding: utf-8 -*-
import torch
import os
import random
import os
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
# [DEBUG, INFO, WARNING, ERROR, CRITICAL]
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
"""
模型训练主程序
"""
seed = Config["seed"]
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def main(config):
# 创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])
# 加载训练数据
train_data = load_data(config["train_data_path"], config)
# 加载模型
model = TorchModel(config)
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
model = model.cuda()
# 加载优化器
optimizer = choose_optimizer(config, model)
# 加载效果测试类
evaluator = Evaluator(config, model, logger)
# 训练
for epoch in range(config["epoch"]):
epoch += 1
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
optimizer.zero_grad()
input_ids, labels = batch_data # 输入变化时这里需要修改,比如多输入,多输出的情况
loss = model(input_ids, labels)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)
logger.info("epoch average loss: %f" % np.mean(train_loss))
acc = evaluator.eval(epoch)
# model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)
# torch.save(model.state_dict(), model_path) #保存模型权重
return acc
if __name__ == "__main__":
# 对比所有模型
# 中间日志可以关掉,避免输出过多信息
# 超参数的网格搜索
for model in ["gated_cnn", 'bert', 'lstm']:
Config["model_type"] = model
for lr in [1e-3, 1e-4]:
Config["learning_rate"] = lr
for hidden_size in [128]:
Config["hidden_size"] = hidden_size
for batch_size in [64, 128]:
Config["batch_size"] = batch_size
for pooling_style in ["avg", 'max']:
Config["pooling_style"] = pooling_style
print("最后一轮准确率:", main(Config), "当前配置:", Config)组1:model_type = gated_cnn、learning_rate = 1e-3、hidden_size = 128、batch_size = 64、pooling_style = avg
![]()
组2:model_type = gated_cnn、learning_rate = 1e-3、hidden_size = 128、batch_size = 64、pooling_style = max
![]()
组3:model_type = gated_cnn、learning_rate = 1e-3、hidden_size = 128、batch_size = 128、pooling_style = avg
![]()
组4:model_type = gated_cnn、learning_rate = 1e-3、hidden_size = 128、batch_size = 128、pooling_style = max
![]()
组5:model_type = gated_cnn、learning_rate = 1e-4、hidden_size = 128、batch_size = 64、pooling_style = avg
![]()
组6:model_type = gated_cnn、learning_rate = 1e-4、hidden_size = 128、batch_size = 64、pooling_style = max
![]()
组7:model_type = gated_cnn、learning_rate = 1e-4、hidden_size = 128、batch_size = 128、pooling_style = avg
![]()
组8:model_type = gated_cnn、learning_rate = 1e-4、hidden_size = 128、batch_size = 128、pooling_style = max
![]()
组9:model_type = bert、learning_rate = 1e-3、hidden_size = 128、batch_size = 64、pooling_style = avg
![]()
组9:model_type = bert、learning_rate = 1e-3、hidden_size = 128、batch_size = 64、pooling_style = max
![]()
组10:model_type = bert、learning_rate = 1e-3、hidden_size = 128、batch_size = 128、pooling_style = avg
![]()
组11:model_type = bert、learning_rate = 1e-3、hidden_size = 128、batch_size = 128、pooling_style = max
![]()
组12:model_type = bert、learning_rate = 1e-4、hidden_size = 128、batch_size = 64、pooling_style = avg
![]()
组14:model_type = bert、learning_rate = 1e-4、hidden_size = 128、batch_size = 64、pooling_style = max
![]()
组15:model_type = bert、learning_rate = 1e-4、hidden_size = 128、batch_size = 128、pooling_style = avg
![]()
组16:model_type = bert、learning_rate = 1e-4、hidden_size = 128、batch_size = 128、pooling_style = max
![]()
组17:model_type = lstm、learning_rate = 1e-3、hidden_size = 128、batch_size = 64、pooling_style = avg
![]()
组18:model_type = lstm、learning_rate = 1e-3、hidden_size = 128、batch_size = 64、pooling_style = max
![]()
组19:model_type = lstm、learning_rate = 1e-3、hidden_size = 128、batch_size = 128、pooling_style = avg
![]()
组20:model_type = lstm、learning_rate = 1e-3、hidden_size = 128、batch_size = 128、pooling_style = max
![]()
组21:model_type = lstm、learning_rate = 1e-4、hidden_size = 128、batch_size = 64、pooling_style = avg
![]()
组22:model_type = lstm、learning_rate = 1e-4、hidden_size = 128、batch_size = 64、pooling_style = max
![]()
组23:model_type = lstm、learning_rate = 1e-4、hidden_size = 128、batch_size = 128、pooling_style = avg
![]()
组24:model_type = lstm、learning_rate = 1e-4、hidden_size = 128、batch_size = 128、pooling_style = max
![]()
模块化的意义:可读性、复用性、未来工作中少做重复工作
Ps:主流程main.py一般基本不需要改变;对于每一类任务,评测函数evaluate.py也不需要改动;loader.py取决于数据的格式,主要任务是数据预处理;config.py是配置文件,最关键的是model.py,声明做某一类任务有哪些模型结构可用
二、🚀 常见的模型结构
1.文本分类 — fastText
fastText 是 Facebook AI Research(FAIR)于 2016 年开源的一款用于高效文本分类和词向量学习的工具包。它结合了自然语言处理和机器学习中最先进的技术,具有速度快、性能好、易于使用等特点。

Ⅰ、模型结构:
x ——> Embedding ——> Mean Pooling ——> 预测Label
① 文本数据过嵌入层,对每个字做词嵌入,得到词向量
② 过平均池化层做池化
③ 最终得到 预测的Lable标签
词向量的分类层预测得到的向量的维度是:嵌入维度 × 词表大小(Embedding × Vocab_size),在词表上做分类(类别数 / 词向量维度等于词表长度)
在文本分类任务中,最终分类层预测得到的向量的维度是:嵌入维度 × 分类类别数(Embedding × 指定分类数目)
Ⅱ、核心特点
高效性:fastText 在训练和预测时速度极快。它采用了基于哈希技巧的 n - gram 特征和分层 Softmax 等优化技术,能够在处理大规模数据时显著减少计算量和内存消耗。例如,在处理包含数百万条文本的数据集时,fastText 可以在几分钟内完成训练。
多语言支持:支持多种语言的文本分类和词向量学习。它不依赖于特定语言的语法规则,能够处理不同语言的字符编码和词汇特点,具有较好的通用性。
简单易用:提供了简单的命令行接口和 Python 等编程语言的 API,用户可以轻松地进行模型的训练、评估和预测。即使没有深厚的机器学习背景,也能快速上手使用。
Ⅲ、主要功能
① 词向量学习
fastText 可以学习词的向量表示(词嵌入),其原理基于连续词袋模型(CBOW)和 Skip - gram 模型,并进行了改进。它不仅考虑了单个词的信息,还引入了字符级别的 n - gram 特征,能够更好地处理未登录词(在训练数据中未出现的词)
FastText():由 Facebook 开发的一个开源库,主要用于高效的文本表示学习和自然语言处理任务。FastText 提供了简单而强大的接口,用于训练词向量(word embeddings)和进行文本分类。与传统的 Word2Vec 模型相比,FastText 能够更好地处理罕见词和形态丰富的语言,因为它不仅考虑单词本身,还考虑了单词的子词(n-grams)信息。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
lr |
float | 0.05 | 学习率。 |
epoch |
int | 5 | 训练的轮数。 |
wordNgrams |
int | 1 | 使用的 n-gram 大小(1 表示仅使用单词,2 表示使用 bi-grams,依此类推)。 |
bucket |
int | 2000000 | 用于哈希的桶的数量,影响内存使用和计算速度。 |
dim |
int | 100 | 词向量的维度。 |
loss |
str | "hs" | 损失函数类型,可选 "hs"(分层 softmax)、"ns"(负采样)、"softmax"。 |
minn |
int | 3 | 子词的最小长度。 |
maxn |
int | 6 | 子词的最大长度。 |
t |
float | 1e-4 | 负采样的阈值。 |
verbose |
int | 2 | 日志详细程度(0、1、2)。 |
model |
str | "skipgram" | 训练模型类型,可选 "skipgram" 或 "cbow"。 |
ws |
int | 5 | 上下文窗口大小。 |
minCount |
int | 5 | 最小词频,低于此频率的词将被忽略。 |
neg |
int | 5 | 负采样的样本数量(仅适用于 "ns" 损失)。 |
thread |
int | 12 | 训练时使用的线程数。 |
lrUpdateRate |
int | 100 | 学习率更新的频率。 |
tuneGradSq |
bool | False | 是否调整梯度平方。 |
pretrainedVectors |
str | None | 预训练的词向量文件路径。 |
saveOutput |
bool | False | 是否保存输出权重。 |
model.wv[]:FastText 模型中的一个属性,用于访问训练好的词向量。通过 model.wv[word] 可以获取指定单词的向量表示。如果单词存在于词汇表中,将返回对应的向量;否则,可能返回一个全零向量或特定的错误提示。
| 参数名称 | 类型 | 描述 |
|---|---|---|
word |
str | 要查询的单词。 |
from gensim.models import FastText
import numpy as np
# 示例文本数据
sentences = [["你", "好", "啊"], ["今", "天", "天", "气", "不", "错"]]
# 训练 fastText 模型
model = FastText(sentences, vector_size=100, window=5, min_count=1, epochs=10)
# 获取某个词的词向量
word_vector = model.wv['你']
print(word_vector)② 文本分类
fastText 可以用于文本分类任务,如新闻分类、情感分析等。在训练过程中,它将文本表示为词和字符 n - gram 的特征向量,然后使用线性分类器进行分类。
fasttext.train_supervised():FastText 库中的一个函数,用于训练一个有监督的文本分类模型。与传统的无监督学习方法(如 FastText 的 train() 方法用于词向量训练)不同,train_supervised() 专门用于监督学习任务,如文本分类、情感分析等。该函数允许用户指定训练数据、模型参数以及保存模型的路径,从而灵活地训练和部署监督模型。
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input |
str | - | 训练数据的文件路径。数据格式通常为每行一个样本,格式为 __label__<类别> <文本>。 |
output |
str | - | 训练后模型的保存路径。 |
lr |
float | 0.1 | 学习率。 |
lr_update_rate |
int | 100 | 学习率更新的频率(每处理多少个样本更新一次学习率)。 |
dim |
int | 100 | 词向量的维度。 |
ws |
int | 5 | 上下文窗口大小。 |
epoch |
int | 5 | 训练的轮数。 |
minCount |
int | 5 | 最小词频,低于此频率的词将被忽略。 |
minCountLabels |
int | 0 | 标签的最小出现次数,低于此频率的标签将被忽略。 |
neg |
int | 5 | 负采样的样本数量(仅适用于某些损失函数)。 |
loss |
str | "hs" | 损失函数类型,可选 "hs"(分层 softmax)、"ns"(负采样)、"softmax"。 |
bucket |
int | 2000000 | 用于哈希的桶的数量,影响内存使用和计算速度。 |
thread |
int | 12 | 训练时使用的线程数。 |
t |
float | 1e-4 | 负采样的阈值。 |
verbose |
int | 2 | 日志详细程度(0、1、2)。 |
pretrainedVectors |
str | None | 预训练的词向量文件路径。 |
saveOutput |
bool | False | 是否保存输出权重。 |
import fasttext
# 训练数据文件路径
train_data = 'train.txt'
# 训练模型
model = fasttext.train_supervised(input=train_data, lr=1.0, epoch=25, wordNgrams=2, bucket=200000, dim=50, loss='hs')
# 预测文本的类别
text = "这是一个测试文本。"
predicted_label = model.predict(text)
print(predicted_label)Ⅳ、技术原理
① 字符级 n-gram 特征
对于英文来说,可以将每个词进行分割,最终再进行拼凑:<apple> —> [<ap, app, ppl, ple, le>]
fastText 在学习词向量和进行文本分类时,不仅考虑了整个词,还考虑了词的字符级 n - gram 信息。例如,对于单词 “apple”,其 3 - gram 特征包括 “<ap”、“app”、“ppl”、“ple”、“le>” 等(其中 “<” 和 “>” 分别表示单词的开始和结束)。这种方式能够捕捉到词的形态信息,提高模型对未登录词的处理能力。
② 分层Softmax
在文本分类任务中,当类别数量较多时,传统的 Softmax 函数计算复杂度较高。fastText 采用了分层 Softmax 技术,将类别组织成一棵二叉树,通过在树上进行路径搜索来计算概率,从而大大减少了计算量。
Ⅴ、应用场景
① 文本分类:如新闻分类、垃圾邮件过滤、情感分析等。fastText 能够快速训练分类模型,并在大规模数据集上取得较好的分类效果。
② 信息检索:通过学习词向量,fastText 可以用于计算文本之间的相似度,从而实现信息检索和推荐系统。
③ 语言模型:其词向量可以作为语言模型的输入,帮助模型更好地理解文本的语义信息。
2.文本分类 — TextRNN
使用RNN(RNN的变种:LSTM、GRU)对文本进行编码,使用最后一个位置的输出向量进行分类
Ⅰ、模型结构
x —> embedding —> BiLSTM —> Dropout —> LSTM —> Linear —> softmax —> y
Ⅱ、RNN 循环神经网络
循环神经网络(Recurrent Neural Network,RNN)是一类专门用于处理序列数据的神经网络,在自然语言处理、语音识别、时间序列分析等领域有着广泛的应用。RNN 的核心思想是引入循环结构,使得网络能够利用之前的信息来处理当前的输入,从而捕捉序列中的上下文信息。
隐向量按时间步向后传递,起到记忆的作用
最后一个字代表的向量包含之前所有的向量的信息,也就是整句话的信息
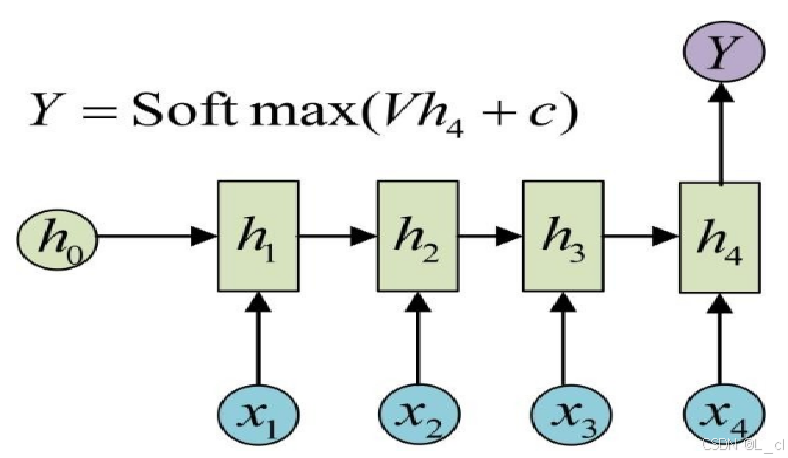
① 结构特点
RNN 由多个相同的单元组成,每个单元会接收当前时刻的输入和上一时刻的隐藏状态,并输出当前时刻的隐藏状态。隐藏状态可以看作是网络对之前输入信息的记忆。
② 公式
xt 是时刻 t 的输入向量,ht 是时刻 t 的隐藏状态向量,U、W、V分别是:输入到隐藏层、隐藏层到隐藏层 以及 隐藏层到输出层的权重矩阵,b 和 c 分别是隐藏层和输出层的偏置向量。
隐藏状态更新:![]()
输出计算:![]()
③ 工作流程
前向传播:在处理一个序列时,RNN 从序列的第一个元素开始,依次计算每个时刻的隐藏状态和输出(输出对应的向量)。每个时刻的隐藏状态会作为下一个时刻的输入之一,从而将序列中的信息逐步传递下去。
反向传播:RNN 的训练通常使用反向传播通过时间(Backpropagation Through Time,BPTT)算法。该算法本质上是将 RNN 在时间上展开成一个深度神经网络,然后使用传统的反向传播算法进行参数更新。
④ 代码示例
1.模型构建:
nn.Embedding():是一个查找表,用于将离散的索引(通常是整数)映射到固定大小的向量(嵌入向量)。它常用于将单词索引转换为词嵌入向量,捕捉单词的语义信息。
| 参数名 | 类型 | 描述 |
|---|---|---|
num_embeddings |
int | 嵌入字典的大小,即不同类别的总数。 |
embedding_dim |
int | 每个嵌入向量的维度。 |
padding_idx |
int, 可选 | 指定一个索引,用于填充,该索引对应的嵌入向量在训练时不会被更新。 |
max_norm |
float, 可选 | 如果设置,嵌入向量的范数会被裁剪到不超过该值。 |
norm_type |
float, 可选 | 用于裁剪范数的类型,默认为2(L2范数)。 |
scale_grad_by_freq |
bool, 可选 | 如果为True,梯度会根据单词在mini-batch中的频率进行缩放。 |
sparse |
bool, 可选 | 如果为True,梯度会变为稀疏张量。 |
nn.RNN():循环神经网络的基本实现,用于处理序列数据。它通过隐藏状态在时间步之间传递信息,适用于自然语言处理、时间序列预测等任务。
| 参数名 | 类型 | 描述 |
|---|---|---|
input_size |
int | 输入特征的维度。 |
hidden_size |
int | 隐藏状态的维度。 |
num_layers |
int, 可选 | RNN的层数,默认为1。 |
nonlinearity |
str, 可选 | 激活函数,默认为'tanh',可选'relu'。 |
bias |
bool, 可选 | 是否使用偏置,默认为True。 |
batch_first |
bool, 可选 | 如果为True,输入和输出的形状为(batch_size, seq_len, input_size),默认为False。 |
dropout |
float, 可选 | 如果非零,在除最后一层外的每一层后添加Dropout层,默认为0。 |
bidirectional |
bool, 可选 | 如果为True,使用双向RNN,默认为False。 |
nn.Linear():是一个全连接层,用于将输入数据线性变换到输出空间。它常用于神经网络的最后一层或中间层。
| 参数名 | 类型 | 描述 |
|---|---|---|
in_features |
int | 输入特征的维度。 |
out_features |
int | 输出特征的维度。 |
bias |
bool, 可选 | 是否使用偏置,默认为True。 |
2.前向传播:
squeeze():用于移除张量中所有大小为1的维度,从而压缩张量的形状。它常用于处理神经网络输出中的多余维度。
| 参数名 | 类型 | 描述 |
|---|---|---|
input |
Tensor | 输入张量。 |
dim |
int, 可选 | 如果指定,只在该维度上移除大小为1的维度。 |
3.模型演示:
torch.randint():生成指定范围内的随机整数张量。它常用于生成随机索引或随机数据。
| 参数名 | 类型 | 描述 |
|---|---|---|
low |
int | 随机整数的最小值(包含)。 |
high |
int | 随机整数的最大值(不包含)。 |
size |
tuple | 输出张量的形状。 |
dtype |
torch.dtype, 可选 | 输出张量的数据类型,默认为torch.int64。 |
layout |
torch.layout, 可选 | 输出张量的内存布局,默认为torch.strided。 |
device |
torch.device, 可选 | 输出张量的设备,默认为CPU。 |
requires_grad |
bool, 可选 | 是否需要在反向传播中计算梯度,默认为False。 |
import torch
import torch.nn as nn
import torch.optim as optim
class RNNTextClassifier(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):
super(RNNTextClassifier, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
embedded = self.embedding(x)
output, hidden = self.rnn(embedded)
return self.fc(hidden.squeeze(0))
# 示例配置
vocab_size = 10000 # 词汇表大小
embedding_dim = 100 # 嵌入层维度
hidden_dim = 128 # RNN隐藏层维度
output_dim = 2 # 分类类别数
# 创建模型实例
model = RNNTextClassifier(vocab_size, embedding_dim, hidden_dim, output_dim)
# 示例输入
input_data = torch.randint(0, vocab_size, (32, 50)) # 批量大小为32,序列长度为50
# 前向传播
output = model(input_data)
print(output.shape) # 输出形状应为 [32, output_dim]⑤ 存在的问题
梯度消失或梯度爆炸:在 BPTT 过程中,由于梯度在时间上的反向传播涉及到多次矩阵乘法,当序列较长时,梯度可能会变得非常小(梯度消失)或非常大(梯度爆炸),导致模型难以学习到长距离的依赖关系。
长期依赖问题:由于梯度消失或梯度爆炸问题,RNN 在处理长序列时,很难捕捉到序列中相隔较远的元素之间的依赖关系。
Ⅲ、特殊的循环神经网络 — LSTM
长短期记忆网络(Long Short - Term Memory,LSTM)是一种特殊的循环神经网络(RNN)架构,由 Hochreiter 和 Schmidhuber 在 1997 年提出。它旨在解决 传统RNN在处理长序列数据时面临的梯度消失或梯度爆炸问题,从而能够更好地捕捉序列中的长距离依赖关系。
将RNN的隐单元复杂化,一定程度规避了梯度消失和信息遗忘的问题
① 结构和原理
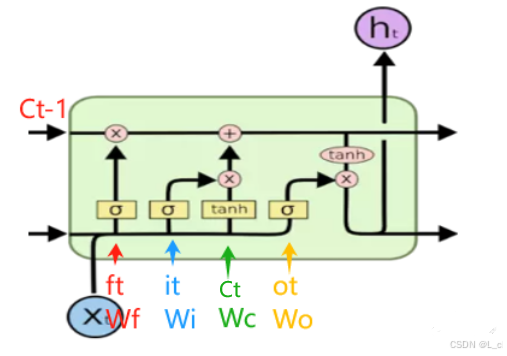
遗忘门 forget:RNN的基本公式操作![]()
将RNN中的激活函数tanh换成sigmoid,将结果映射到0/1,其余为RNN的基本公式
输入门 input:另一个类RNN层![]()
将RNN中的激活函数tanh换成sigmoid,将结果映射到0/1,W和b与第一层不同
标准的RNN层(主干部分):标准的RNN层![]()
记忆单元 cell:将过RNN层的输入和过遗忘门的记忆结合![]()
前三层RNN的复合运算,由 f_t 对记忆单元进行放缩,由 i_t 对输入进行控制,对输入信息做一定的放缩,控制重点部分内容,将二者相加,得到新的记忆单元,C_t-1 从前迭代到后面,f_t对过遗忘门的记忆做一定的放缩,i_t对过类RNN层的输入做一定的放缩
输出门 output:过一个类RNN层 ![]()
记忆单元过一个激活层,再与输出门相乘,得到当前这一步的输出![]()
以另外一份权重 W_o 作一个输出为RNN形式的参数,过sigmoid层,得到o_t,然后再将记忆单元输出的结果过一个 tanh 激活函数 再与这个输出门 o_t 相乘,得到每一个时间步的输出
② 应用场景
自然语言处理:如文本生成、机器翻译、情感分析、命名实体识别等。LSTM 能够处理变长的文本序列,捕捉文本中的语义信息和上下文关系。
时间序列预测:如股票价格预测、天气预报、能源消耗预测等。LSTM 可以学习时间序列数据中的模式和趋势,进行未来值的预测。
语音识别:在语音信号处理中,LSTM 可以处理语音序列,识别语音中的文字信息。
③ 与传统RNN的比较
梯度问题:传统 RNN 在处理长序列时,由于梯度在反向传播过程中会不断相乘,容易出现梯度消失或梯度爆炸问题,导致模型难以学习到长距离的依赖关系。而 LSTM 通过门控机制,能够更好地控制信息的流动,缓解了梯度问题,在处理长序列任务上表现更优。
记忆能力:LSTM 的细胞状态可以像传送带一样,让信息在序列处理过程中相对稳定地流动,从而能够更好地保存长距离的信息。相比之下,传统 RNN 的隐藏状态更新方式使得它在处理长序列时容易丢失早期的信息。
Ⅳ、LSTM 手动实现
① Pytorch实现LSTM
np.random.random(): NumPy 中的一个函数,用于生成一个指定范围内的随机浮点数数组。默认情况下,它生成一个从 0 到 1 的随机浮点数数组。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
size |
int 或 tuple | 无 | 输出数组的形状。例如,size=5 返回一个长度为 5 的一维数组,size=(2, 3) 返回一个 2x3 的二维数组。 |
dtype |
dtype | float64 |
输出数组的数据类型,默认为 float64。 |
nn.LSTM():PyTorch 中的一个类,用于构建长短期记忆网络(LSTM)。LSTM 是一种特殊的循环神经网络(RNN),能够捕捉序列数据中的长期依赖关系。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input_size |
int | 无 | 输入特征的维度。 |
hidden_size |
int | 无 | 隐藏状态的维度。 |
num_layers |
int | 1 | LSTM 层的数量。 |
bias |
bool | True | 是否使用偏置权重。 |
batch_first |
bool | False | 如果为 True,输入和输出的形状为 (batch, seq, feature),否则为 (seq, batch, feature)。 |
dropout |
float | 0 | 如果 num_layers > 1,在第 2 层及之后的层之间应用 dropout 的概率。 |
bidirectional |
bool | False | 是否为双向 LSTM。如果是,则输出维度会翻倍。 |
state_dict():PyTorch 中模型和优化器的一个方法,用于获取模型的参数或优化器的状态。它返回一个字典,其中键是参数或状态的名称,值是对应的张量。
items():Python 字典的一个方法,用于返回字典中所有键值对的视图(dict_items 对象)。每个键值对以元组的形式表示。
#构造一个输入
length = 6
input_dim = 12
hidden_size = 7
x = np.random.random((length, input_dim))
# print(x)
#使用pytorch的lstm层
torch_lstm = nn.LSTM(input_dim, hidden_size, batch_first=True)
for key, weight in torch_lstm.state_dict().items():
print(key, weight.shape)② 手动实现sigmoid激活函数
np.exp():计算输入数组中每个元素的自然指数 ex,其中 x 是输入数组中的元素值。这个函数在数学、统计学、物理学、工程学等多个领域都有广泛的应用。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
x |
array_like | 无 | 输入值,可以是标量、向量、矩阵或任何 NumPy 兼容的数组类型。 |
out |
ndarray、None | None | 存储结果的位置。如果提供,它必须具有输入广播到的形状。 |
where |
array_like | True | 这种情况通过输入广播。在条件为真的位置,out 数组将被设置为 ufunc 结果。 |
casting |
str | 'same_kind' | 控制数据类型转换的方式。 |
order |
str | 'K' | 决定数组的内存布局。 |
dtype |
dtype | None | 指定输出数组的数据类型。 |
subok |
bool | True | 如果为 True,则允许输出为子类。 |
def sigmoid(x):
return 1/(1 + np.exp(-x))③ 用Pytorch的LSTM网络权重实现LSTM的运算
state_dict():PyTorch 中模型和优化器的一个方法,用于获取模型的参数或优化器的状态。它返回一个字典,其中键是参数或状态的名称,值是对应的张量。
.numpy():将TensorFlow张量或PyTorch张量转换为NumPy数组
w_i_x, w_f_x, w_c_x, w_o_x:存储长短期记忆网络(LSTM)中输入门的权重矩阵
w_i_x:输入门的权重矩阵,用于控制新信息的输入
w_f_x:遗忘门的权重矩阵,用于控制旧信息的遗忘
w_c_x:记忆单元cell更新的权重矩阵,用于计算新的候选细胞状态
w_o_x:输出门的权重矩阵,用于控制细胞状态的输出
w_i_h, w_f_h, w_c_h, w_o_h:存储 LSTM 中隐藏层到隐藏层的权重矩阵
w_i_h:输入门的权重矩阵,用于控制新信息的输入
w_f_h:遗忘门的权重矩阵,用于控制旧信息的遗忘
w_c_h:记忆单元cell更新的权重矩阵,用于计算新的候选细胞状态
w_o_h:输出门的权重矩阵,用于控制细胞状态的输出
b_i_x, b_f_x, b_c_x, b_o_x:存储 LSTM 中输入门的偏置向量
b_i_x:输入门的偏置向量
b_f_x:遗忘门的偏置向量
b_c_x:记忆单元cell更新的偏置向量
b_o_x:输出门的偏置向量
b_i_h, b_f_h, b_c_h, b_o_h:存储 LSTM 中隐藏层到隐藏层的偏置向量
b_i_h:输入门的偏置向量
b_f_h:遗忘门的偏置向量
b_c_h:记忆单元cell更新的偏置向量
b_o_h:输出门的偏置向量
w_i, w_f, w_c, w_o:存储 LSTM 中所有门的权重矩阵
w_i:输入门的权重矩阵
w_f:遗忘门的权重矩阵
w_c:记忆单元cell更新的权重矩阵
w_o:输出门的权重矩阵
b_f, b_i, b_c, b_o:存储 LSTM 中所有门的偏置向量
b_f:遗忘门的偏置向量
b_i:输入门的偏置向量
b_c:记忆单元cell更新的偏置向量
b_o:输出门的偏置向量
c_t, h_t:存储 LSTM 中的细胞状态和隐藏状态
c_t:当前时间步的记忆单元cell
h_t:当前时间步的隐藏状态
np.concatenate():沿指定轴连接数组序列
| 参数名 | 描述 |
|---|---|
| arrays | 需要连接的数组序列 |
| axis | 沿着哪个轴进行连接,默认为0 |
| out | 可选的输出数组 |
| dtype | 输出数组的数据类型 |
| casting | 数据类型转换的规则 |
np.zeros():创建一个指定形状和数据类型的全零数组
| 参数名 | 描述 |
|---|---|
| shape | 数组的形状 |
| dtype | 数组的数据类型,默认为float64 |
| order | 数组元素在内存中的排列顺序,默认为'C'(按行排列) |
np.newaxis:用于增加数组的维度
np.dot():计算两个数组的点积
| 参数名 | 描述 |
|---|---|
| a | 第一个输入数组 |
| b | 第二个输入数组 |
| out | 可选的输出数组 |
np.tanh():计算数组中每个元素的双曲正切值
.append():在数组末尾添加值
| 参数名 | 描述 |
|---|---|
| arr | 要被添加元素的原始数组 |
| values | 要添加到arr数组末尾的值 |
| axis | 指定在哪个轴上添加值,默认为None |
np.array():将输入数据(列表、元组等)转换为NumPy数组
| 参数名 | 描述 |
|---|---|
| object | 输入数据(列表、元组等) |
| dtype | 指定数据类型,默认为float64 |
| copy | 是否复制输入数据,默认为True |
| order | 数组元素在内存中的排列顺序,默认为'C'(行优先) |
#将pytorch的lstm网络权重拿出来,用numpy通过矩阵运算实现lstm的计算
def numpy_lstm(x, state_dict):
weight_ih = state_dict["weight_ih_l0"].numpy()
weight_hh = state_dict["weight_hh_l0"].numpy()
bias_ih = state_dict["bias_ih_l0"].numpy()
bias_hh = state_dict["bias_hh_l0"].numpy()
#pytorch将四个门的权重拼接存储,我们将它拆开
w_i_x, w_f_x, w_c_x, w_o_x = weight_ih[0:hidden_size, :], \
weight_ih[hidden_size:hidden_size*2, :],\
weight_ih[hidden_size*2:hidden_size*3, :],\
weight_ih[hidden_size*3:hidden_size*4, :]
w_i_h, w_f_h, w_c_h, w_o_h = weight_hh[0:hidden_size, :], \
weight_hh[hidden_size:hidden_size * 2, :], \
weight_hh[hidden_size * 2:hidden_size * 3, :], \
weight_hh[hidden_size * 3:hidden_size * 4, :]
b_i_x, b_f_x, b_c_x, b_o_x = bias_ih[0:hidden_size], \
bias_ih[hidden_size:hidden_size * 2], \
bias_ih[hidden_size * 2:hidden_size * 3], \
bias_ih[hidden_size * 3:hidden_size * 4]
b_i_h, b_f_h, b_c_h, b_o_h = bias_hh[0:hidden_size], \
bias_hh[hidden_size:hidden_size * 2], \
bias_hh[hidden_size * 2:hidden_size * 3], \
bias_hh[hidden_size * 3:hidden_size * 4]
w_i = np.concatenate([w_i_h, w_i_x], axis=1)
w_f = np.concatenate([w_f_h, w_f_x], axis=1)
w_c = np.concatenate([w_c_h, w_c_x], axis=1)
w_o = np.concatenate([w_o_h, w_o_x], axis=1)
b_f = b_f_h + b_f_x
b_i = b_i_h + b_i_x
b_c = b_c_h + b_c_x
b_o = b_o_h + b_o_x
c_t = np.zeros((1, hidden_size))
h_t = np.zeros((1, hidden_size))
sequence_output = []
for x_t in x:
x_t = x_t[np.newaxis, :]
hx = np.concatenate([h_t, x_t], axis=1)
# f_t = sigmoid(np.dot(x_t, w_f_x.T) + b_f_x + np.dot(h_t, w_f_h.T) + b_f_h)
f_t = sigmoid(np.dot(hx, w_f.T) + b_f)
# i_t = sigmoid(np.dot(x_t, w_i_x.T) + b_i_x + np.dot(h_t, w_i_h.T) + b_i_h)
i_t = sigmoid(np.dot(hx, w_i.T) + b_i)
# g = np.tanh(np.dot(x_t, w_c_x.T) + b_c_x + np.dot(h_t, w_c_h.T) + b_c_h)
g = np.tanh(np.dot(hx, w_c.T) + b_c)
c_t = f_t * c_t + i_t * g
# o_t = sigmoid(np.dot(x_t, w_o_x.T) + b_o_x + np.dot(h_t, w_o_h.T) + b_o_h)
o_t = sigmoid(np.dot(hx, w_o.T) + b_o)
h_t = o_t * np.tanh(c_t)
sequence_output.append(h_t)
return np.array(sequence_output), (h_t, c_t)④ 验证参数
torch.Tensor():PyTorch 中用于创建张量的基本函数。张量是 PyTorch 中的核心数据结构,用于表示多维数组,可以用于存储和操作训练数据、模型参数等
state_dict():PyTorch 中模型和优化器的一个方法,用于获取模型的参数或优化器的状态。它返回一个字典,其中键是参数或状态的名称,值是对应的张量。
state_dict() 只包含模型的可学习参数(如卷积层和全连接层的权重和偏置),不包括优化器的状态。
import torch
import torch.nn as nn
import numpy as np
'''
用矩阵运算的方式复现一些基础的模型结构
清楚模型的计算细节,有助于加深对于模型的理解,以及模型转换等工作
'''
#构造一个输入
length = 6
input_dim = 12
hidden_size = 7
x = np.random.random((length, input_dim))
# print(x)
#使用pytorch的lstm层
torch_lstm = nn.LSTM(input_dim, hidden_size, batch_first=True)
for key, weight in torch_lstm.state_dict().items():
print(key, weight.shape)
def sigmoid(x):
return 1/(1 + np.exp(-x))
#将pytorch的lstm网络权重拿出来,用numpy通过矩阵运算实现lstm的计算
def numpy_lstm(x, state_dict):
weight_ih = state_dict["weight_ih_l0"].numpy()
weight_hh = state_dict["weight_hh_l0"].numpy()
bias_ih = state_dict["bias_ih_l0"].numpy()
bias_hh = state_dict["bias_hh_l0"].numpy()
#pytorch将四个门的权重拼接存储,我们将它拆开
w_i_x, w_f_x, w_c_x, w_o_x = weight_ih[0:hidden_size, :], \
weight_ih[hidden_size:hidden_size*2, :],\
weight_ih[hidden_size*2:hidden_size*3, :],\
weight_ih[hidden_size*3:hidden_size*4, :]
w_i_h, w_f_h, w_c_h, w_o_h = weight_hh[0:hidden_size, :], \
weight_hh[hidden_size:hidden_size * 2, :], \
weight_hh[hidden_size * 2:hidden_size * 3, :], \
weight_hh[hidden_size * 3:hidden_size * 4, :]
b_i_x, b_f_x, b_c_x, b_o_x = bias_ih[0:hidden_size], \
bias_ih[hidden_size:hidden_size * 2], \
bias_ih[hidden_size * 2:hidden_size * 3], \
bias_ih[hidden_size * 3:hidden_size * 4]
b_i_h, b_f_h, b_c_h, b_o_h = bias_hh[0:hidden_size], \
bias_hh[hidden_size:hidden_size * 2], \
bias_hh[hidden_size * 2:hidden_size * 3], \
bias_hh[hidden_size * 3:hidden_size * 4]
w_i = np.concatenate([w_i_h, w_i_x], axis=1)
w_f = np.concatenate([w_f_h, w_f_x], axis=1)
w_c = np.concatenate([w_c_h, w_c_x], axis=1)
w_o = np.concatenate([w_o_h, w_o_x], axis=1)
b_f = b_f_h + b_f_x
b_i = b_i_h + b_i_x
b_c = b_c_h + b_c_x
b_o = b_o_h + b_o_x
c_t = np.zeros((1, hidden_size))
h_t = np.zeros((1, hidden_size))
sequence_output = []
for x_t in x:
x_t = x_t[np.newaxis, :]
hx = np.concatenate([h_t, x_t], axis=1)
# f_t = sigmoid(np.dot(x_t, w_f_x.T) + b_f_x + np.dot(h_t, w_f_h.T) + b_f_h)
f_t = sigmoid(np.dot(hx, w_f.T) + b_f)
# i_t = sigmoid(np.dot(x_t, w_i_x.T) + b_i_x + np.dot(h_t, w_i_h.T) + b_i_h)
i_t = sigmoid(np.dot(hx, w_i.T) + b_i)
# g = np.tanh(np.dot(x_t, w_c_x.T) + b_c_x + np.dot(h_t, w_c_h.T) + b_c_h)
g = np.tanh(np.dot(hx, w_c.T) + b_c)
c_t = f_t * c_t + i_t * g
# o_t = sigmoid(np.dot(x_t, w_o_x.T) + b_o_x + np.dot(h_t, w_o_h.T) + b_o_h)
o_t = sigmoid(np.dot(hx, w_o.T) + b_o)
h_t = o_t * np.tanh(c_t)
sequence_output.append(h_t)
return np.array(sequence_output), (h_t, c_t)
torch_sequence_output, (torch_h, torch_c) = torch_lstm(torch.Tensor([x]))
numpy_sequence_output, (numpy_h, numpy_c) = numpy_lstm(x, torch_lstm.state_dict())
print(torch_sequence_output)
print(numpy_sequence_output)
print("--------")
print(torch_h)
print(numpy_h)
print("--------")
print(torch_c)
print(numpy_c)
Ⅴ、双向LSTM

① 原理与结构
传统的 LSTM 在处理序列数据时,是按照序列的顺序依次处理每个元素,只能利用过去的信息来更新当前时刻的隐藏状态。而双向 LSTM 通过引入两个独立的 LSTM 层,一个按序列的正向顺序(从左到右)处理输入序列,另一个按序列的反向顺序(从右到左)处理输入序列。
双向长短期记忆网络(Bidirectional Long Short - Term Memory,BiLSTM)是对传统 LSTM 的扩展,它结合了正向和反向的 LSTM 结构,能够同时利用序列的过去和未来信息进行建模。正反双向LSTM计算时,都遵循LSTM的公式处理正序逆序信息
② 工作流程
输入一句话,将每个字过Embedding层,然后再过LSTM,同时过一个反向的LSTM,将过LSTM的向量与过反向LSTM的向量拼接起来,维度是单向LSTM的两倍,就是一个双向的LSTM,这种网络结构的效果一般比单向的LSTM好上不少,最终拿整句话的输出向量过一个线性层映射到分类的类别数量,再接一个softmax层,再取交叉熵,做多分类
③ 优势
捕捉更丰富的上下文信息:双向 LSTM 能够同时考虑序列元素的过去和未来信息,相比单向 LSTM,它可以捕捉到更全面的上下文依赖关系。例如在自然语言处理中,一个单词的含义不仅取决于它前面的单词,还可能受到后面单词的影响。双向 LSTM 可以更好地利用这种前后文信息,从而提高模型的性能。
提升序列建模能力:在许多序列相关的任务中,如词性标注、命名实体识别、机器翻译等,双向 LSTM 能够更准确地对序列进行建模,因为它可以从两个方向综合考虑信息,从而更好地理解序列的整体结构和语义。
④ 代码实现
1.模型定义:
nn.LSTM():PyTorch 中的一个模块,用于实现长短期记忆网络(LSTM)。LSTM 是一种特殊的循环神经网络(RNN),能够处理序列数据并捕捉长期依赖关系。
| 参数名 | 类型 | 描述 |
|---|---|---|
input_size |
int | 输入张量的特征维度大小。 |
hidden_size |
int | 隐藏层张量的特征维度大小。 |
num_layers |
int | LSTM 的层数,默认为 1。 |
bias |
bool | 是否使用偏置项,默认为 True。 |
batch_first |
bool | 如果为 True,输入和输出的张量形状为 (batch, seq, feature),默认为 False。 |
dropout |
float | 如果非零,则在除最后一层外的每个 LSTM 层输出上应用 dropout,默认为 0。 |
bidirectional |
bool | 如果为 True,则使用双向 LSTM,默认为 False。 |
nn.Linear():PyTorch 中的一个模块,用于实现全连接层(线性变换)。它对输入张量进行线性变换,公式为 y=x * A.T+b,其中 A 是权重矩阵,b 是偏置项
| 参数名 | 类型 | 描述 |
|---|---|---|
in_features |
int | 输入张量的特征维度大小。 |
out_features |
int | 输出张量的特征维度大小。 |
bias |
bool | 是否使用偏置项,默认为 True。 |
2.前向计算:
torch.zeros():创建一个指定形状的全零张量
| 参数名 | 类型 | 描述 |
|---|---|---|
size |
tuple | 定义输出张量形状的整数序列。 |
dtype |
torch.dtype | 指定返回张量的数据类型,默认为 torch.float32。 |
layout |
torch.layout | 指定返回张量的内存布局,默认为 torch.strided。 |
device |
torch.device | 指定返回张量所在的设备,默认为当前设备。 |
requires_grad |
bool | 指定返回张量是否需要梯度,默认为 False。 |
3.模型演示:
torch.randn():创建一个指定形状的张量,其中每个元素都是从标准正态分布(均值为 0,标准差为 1)中随机抽取的
| 参数名 | 类型 | 描述 |
|---|---|---|
size |
tuple | 定义输出张量形状的整数序列。 |
dtype |
torch.dtype | 指定返回张量的数据类型,默认为 torch.float32。 |
layout |
torch.layout | 指定返回张量的内存布局,默认为 torch.strided。 |
device |
torch.device | 指定返回张量所在的设备,默认为当前设备。 |
requires_grad |
bool | 指定返回张量是否需要梯度,默认为 False。 |
.shape():PyTorch 张量的一个属性,用于获取张量的形状。它返回一个元组,表示张量在各个维度上的大小。
import torch
import torch.nn as nn
# 定义双向LSTM模型
class BiLSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(BiLSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# 定义双向LSTM层
self.bilstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, bidirectional=True)
# 全连接层,由于是双向,输入维度要乘以2
self.fc = nn.Linear(hidden_size * 2, output_size)
def forward(self, x):
# 初始化隐藏状态和细胞状态
h0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size).to(x.device)
# 前向传播双向LSTM
out, _ = self.bilstm(x, (h0, c0))
# 取最后一个时间步的输出
out = out[:, -1, :]
# 全连接层
out = self.fc(out)
return out
# 示例使用
input_size = 10
hidden_size = 20
num_layers = 2
output_size = 1
model = BiLSTMModel(input_size, hidden_size, num_layers, output_size)
# 生成随机输入数据
batch_size = 32
seq_length = 5
input_data = torch.randn(batch_size, seq_length, input_size)
# 前向传播
output = model(input_data)
print("输出形状:", output.shape)Ⅵ、 GRU
① 原理与结构
核心结构:
更新门(Update Gate):决定上一时刻的隐藏状态有多少信息被传递到当前时刻
重置门(Reset Gate):决定上一时刻的隐藏状态有多少信息被忽略
计算公式:
重置门:![]()
更新门:![]()
候选隐藏状态:![]()
当前隐藏状态:![]()
② 工作流程
输入处理:将输入序列分解为单独的时间步,并逐步传递给GRU。
门控计算:在每个时间步,计算重置门和更新门的值。
候选隐藏状态生成:结合当前输入和重置后的隐藏状态,生成候选隐藏状态。
隐藏状态更新:根据更新门的值,决定保留多少旧信息,更新当前隐藏状态。
输出生成:当前隐藏状态传递到输出层,生成最终输出。
③ 优势
结构简单:相比LSTM,GRU减少了门的数量,结构更为简洁,参数更少。
计算效率高:由于参数较少,GRU的训练速度通常比LSTM更快。
性能优异:在许多任务上,GRU的性能与LSTM相当,能够有效处理长序列数据。
解决梯度问题:通过引入门控机制,GRU有效地缓解了梯度消失和梯度爆炸问题
④ 代码实现
1.模型定义:
nn.GRU():实现门控循环单元(GRU),用于处理序列数据,能够捕捉长期依赖关系
| 参数 | 说明 |
|---|---|
input_size |
输入张量的特征维度大小 |
hidden_size |
隐层张量的特征维度大小 |
num_layers |
GRU层的数量 |
bias |
是否使用偏置项,默认为 True |
batch_first |
如果为 True,输入和输出的第一个维度是批大小,默认为 False |
dropout |
当 num_layers > 1 时,在每两个GRU层之间使用的 dropout 概率,默认为 0 |
bidirectional |
如果为 True,则使用双向 GRU,默认为 False |
nn.Linear():实现全连接层,对输入进行线性变换
| 参数 | 说明 |
|---|---|
in_features |
输入特征的数量 |
out_features |
输出特征的数量 |
bias |
是否使用偏置项,默认为 True |
2.前向计算:
torch.zeros():返回一个形状为 size,元素全为 0 的张量
| 参数 | 说明 |
|---|---|
size |
定义输出张量形状的整数序列 |
out |
指定输出的张量,默认为 None |
dtype |
返回张量的数据类型,默认为 None |
layout |
返回张量的布局,默认为 torch.strided |
device |
返回张量所在的设备,默认为 None |
requires_grad |
返回的张量是否需要梯度,默认为 False |
3.模型演示:
nn.MSELoss():计算均方误差损失,用于回归任务
| 参数 | 说明 |
|---|---|
reduction |
指定损失的计算方式,默认为 'mean',可选 'none'、'sum' |
torch.optim.Adam():实现 Adam 优化算法,用于更新模型参数
| 参数 | 说明 |
|---|---|
params |
需要优化的参数 |
lr |
学习率,默认为 0.001 |
betas |
用于计算梯度及其平方的运行平均值的系数,默认为 (0.9, 0.999) |
eps |
数值稳定性的术语,默认为 1e-8 |
weight_decay |
权重衰减(L2 惩罚),默认为 0 |
amsgrad |
是否使用 AMSGrad 变体,默认为 False |
range():生成一个不可变的整数序列
| 参数 | 说明 |
|---|---|
start |
序列的起始值,默认为 0 |
stop |
序列的结束值(不包含) |
step |
步长,默认为 1 |
torch.randn():生成服从标准正态分布的随机数张量
| 参数 | 说明 |
|---|---|
size |
定义输出张量形状的整数序列 |
out |
指定输出的张量,默认为 None |
dtype |
返回张量的数据类型,默认为 None |
layout |
返回张量的布局,默认为 torch.strided |
device |
返回张量所在的设备,默认为 None |
requires_grad |
返回的张量是否需要梯度,默认为 False |
optimizer.zero_grad():将模型参数的梯度清零,防止梯度累积
| 参数 | 说明 |
|---|---|
set_to_none |
是否将梯度设置为 None,默认为 False |
loss.backward():反向传播计算梯度
| 参数 | 说明 |
|---|---|
retain_graph |
是否保留计算图,默认为 False |
create_graph |
是否创建计算图,默认为 False |
optimizer.step():根据计算出的梯度更新模型参数
| 参数 | 说明 |
|---|---|
closure |
用于重新计算损失的可调用函数,默认为 None |
import torch
import torch.nn as nn
class GRUModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(GRUModel, self).__init__()
self.gru = nn.GRU(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h_0 = torch.zeros(1, x.size(0), hidden_size) # 初始化隐藏状态
out, _ = self.gru(x, h_0) # GRU前向传播
out = self.fc(out[:, -1, :]) # 取最后一个时间步的输出
return out
# 设定参数
input_size = 10
hidden_size = 20
output_size = 1
learning_rate = 0.01
num_epochs = 100
# 创建模型
model = GRUModel(input_size, hidden_size, output_size)
criterion = nn.MSELoss() # 损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # 优化器
# 假数据进行训练
for epoch in range(num_epochs):
x = torch.randn(5, 10, input_size) # batch_size=5, sequence_length=10
y = torch.randn(5, output_size)
outputs = model(x)
loss = criterion(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()Ⅶ、对比 Transformer 和 LSTM 模型结构的优缺点 🧠
① Transformer模型
优点
并行化:Transformer不依赖循环结构,可以并行处理整个序列,显著提高了训练效率
长距离依赖:自注意力机制能够直接捕捉序列中任意两个位置之间的关系,解决了长距离依赖问题
可扩展性:Transformer架构易于扩展,可以通过增加层数或注意力头数来提升模型性能
可解释性:自注意力机制使得Transformer具有较好的可解释性,可以通过观察注意力权重来分析模型在处理文本时关注的重点
广泛应用:Transformer在自然语言处理、计算机视觉等多个领域取得了巨大成功
缺点
计算和内存资源需求高:由于自注意力机制,Transformer的计算复杂度和内存需求较高,可能导致大型模型在资源有限的设备上难以运行
缺乏内在顺序感知:虽然自注意力机制有助于捕捉长距离依赖,但Transformer模型天然缺乏对顺序的感知,通常需要引入位置编码
训练数据需求大:为了训练一个表现良好的Transformer模型,通常需要大量的标注数据
容易产生不一致和无法解释的输出:尽管Transformer模型可以生成流畅且连贯的文本,但有时可能产生不一致或无法解释的输出
② LSTM模型
优点
捕捉长期依赖:通过门控机制,LSTM能够记住长期的依赖关系,解决了传统RNN无法记住长期信息的问题
避免梯度消失:LSTM的梯度主要通过细胞状态传播,而细胞状态的更新是线性的,缓解了梯度消失问题
灵活的记忆控制:LSTM通过遗忘门和输入门灵活地控制信息的传递,使得模型能够记住有用的信息,并丢弃不必要的信息
广泛应用:LSTM在时间序列预测、自然语言处理等领域有广泛的应用
缺点
计算开销较大:由于包含多个门的计算,LSTM的训练和推理时需要更多的计算资源
结构复杂:LSTM的结构比简单的RNN复杂,调参时需要更多的时间和精力
难以并行化:LSTM的循环结构使得其难以进行并行计算,限制了其在硬件上的加速能力
难以捕捉空间特征:LSTM主要侧重于时间维度的建模,对多变量时间序列中变量之间的空间关系缺乏有效的捕捉能力
| 特性 | Transformer | LSTM |
|---|---|---|
| 并行化能力 | 高度并行化,适合GPU加速,训练效率高 | 顺序计算,难以并行化,训练效率低 |
| 长距离依赖 | 自注意力机制,有效捕捉长距离依赖 | 门控机制,能够记住长期依赖,但处理长序列有限 |
| 可扩展性 | 易于扩展,通过增加层数或头数提升性能 | 结构相对固定,扩展性较差 |
| 可解释性 | 自注意力机制提供较好的可解释性 | 门控机制较难解释,内部状态复杂 |
| 计算资源需求 | 高,需要大量内存和计算资源 | 较高,但相对Transformer较低 |
| 训练数据需求 | 大,需要大量标注数据 | 较小,但性能可能受限于数据量 |
| 输出一致性 | 可能产生不一致或无法解释的输出 | 输出相对一致,但可能陷入局部最优 |
| 应用领域 | 自然语言处理、计算机视觉、语音识别等 | 时间序列预测、自然语言处理、语音识别等 |
| 结构复杂性 | 相对简单,易于理解和实现 | 较复杂,调参和维护难度较大 |
| 鲁棒性 | 对噪声数据有一定鲁棒性,但可能过拟合 | 对噪声数据有较强鲁棒性,但可能遗忘重要信息 |
面对较为简单的任务,需要一个快速分类器,双向LSTM模型 和 GatedCNN模型都是较为可靠的选择
3.文本分类 — TextCNN
TextCNN(Text Convolutional Neural Network)即文本卷积神经网络,是一种专门用于处理文本数据的卷积神经网络模型。其核心思想是将卷积神经网络(CNN)应用于自然语言处理(NLP)领域,通过卷积操作提取文本中的局部特征(类似于n-gram),从而实现高效的文本分类任务。
Ⅰ、原理与结构
TextCNN 的核心思想是将卷积神经网络(CNN)应用于文本处理。CNN 最初在图像领域取得了巨大成功,其卷积操作能够自动提取图像的局部特征。在文本处理中,TextCNN 把文本看作是一维的 “图像”,通过卷积操作提取文本中的局部特征模式,如短语、语义单元等。
嵌入层(Embedding Layer):将文本数据中的单词转换为稠密的向量表示(词向量)。可以使用预训练的词向量(如Word2Vec或GloVe)或随机初始化。
卷积层(Convolutional Layer):使用多个不同大小的卷积核对词向量进行卷积操作,提取文本中的局部特征。每个卷积核的大小对应不同的n-gram范围。
激活函数:通常使用ReLU(Rectified Linear Unit)作为激活函数,引入非线性。
池化层(Pooling Layer):采用最大池化或平均池化从卷积层的输出中提取最重要的特征,降低数据的维度。
全连接层(Fully Connected Layer):将池化层输出的特征向量映射到最终的类别预测上。
输出层:使用Softmax函数将全连接层的输出转换为各个类别的概率分布。
Ⅱ、工作流程
数据预处理:将文本数据进行分词、构建词表,并将单词转换为词向量。
输入层:将词向量输入到TextCNN模型中。
卷积层:使用不同大小的卷积核对词向量进行卷积操作,提取局部特征。
激活函数:对卷积层的输出应用ReLU激活函数。
池化层:采用最大池化操作,从卷积层的输出中提取最重要的特征。
全连接层:将池化层的输出特征向量映射到最终的类别预测上。
输出层:使用Softmax函数将全连接层的输出转换为各个类别的概率分布。
训练与预测:通过反向传播算法更新模型参数,并在测试集上进行预测。
利用一维卷积对文本进行编码
编码后的文本矩阵通过pooling转化为向量,用于分类
处理文本时的卷积应该整行进行卷积,不建议一次性卷积太多行,一次一般卷积二到五个字,需要局部一点一点进行卷积
每一次卷积得到当前这句话的向量,多次卷积得到一个矩阵,作为对于当前文本的表示,然后过一个归一化层pooling,得到当前文本的向量,将这个向量过一个线性层进行分类
Ⅲ、优势
网络结构简单:相较于深度学习方法,TextCNN的结构更为简单,易于理解和实现。
训练速度快:由于结构简单,TextCNN的训练速度较快,适合需要快速迭代的应用场景。
特征提取能力强:能够有效地捕捉文本中的上下文信息,适用于短文本分类任务。
灵活性:支持多种卷积核大小,可以灵活调整模型的参数以适应不同的任务。
Ⅳ、代码实现
nn.Embedding(): PyTorch 中用于将离散的整数(如词汇表中的单词)映射到低维向量空间的模块。它主要用于自然语言处理任务中,将单词转换为稠密的向量表示,以便模型能够捕捉词汇之间的语义关系。
| 参数名 | 描述 |
|---|---|
num_embeddings |
嵌入字典的大小,即词汇表的大小。 |
embedding_dim |
每个嵌入向量的维度。 |
padding_idx |
指定填充(PAD)对应的索引值。默认为 None。 |
max_norm |
如果设置,嵌入向量的范数超过此值时将被重新归一化。 |
norm_type |
用于计算范数的类型,默认为 2(L2 范数)。 |
scale_grad_by_freq |
如果为 True,梯度将根据单词在 mini-batch 中的频率进行缩放。默认为 False。 |
sparse |
如果为 True,权重矩阵的梯度将被视为稀疏张量。默认为 False。 |
nn.ModuleList():PyTorch 中用于存储和管理多个子模块的容器。它允许你将多个层或模块存储在一个列表中,并在需要时通过索引访问它们。
| 参数名 | 描述 |
|---|---|
modules |
子模块的列表。 |
nn.Conv1d():PyTorch 中用于一维卷积操作的类。它主要用于处理一维输入数据,如时间序列、音频信号等。
| 参数名 | 描述 |
|---|---|
in_channels |
输入信号的通道数。 |
out_channels |
输出信号的通道数,即卷积核的数量。 |
kernel_size |
卷积核的大小。 |
stride |
卷积核的步长。 |
padding |
在输入信号的边界周围填充0的层数。 |
dilation |
卷积核元素之间的间距,也称为扩张率。 |
groups |
从输入通道到输出通道的阻塞连接数。 |
bias |
布尔值,决定是否在输出中添加可学习的偏置项。 |
padding_mode |
填充模式,可以是 'zeros', 'reflect', 'replicate' 或 'circular'。 |
.transpose():PyTorch 中用于转置张量的方法。它可以将张量的维度进行交换,常用于调整数据的形状以适应不同的操作需求。
| 参数名 | 描述 |
|---|---|
dim0 |
要交换的第一个维度。 |
dim1 |
要交换的第二个维度。 |
nn.Linear():PyTorch 中用于执行线性变换的全连接层。它将输入张量通过权重矩阵和偏置向量进行线性变换,输出新的张量。
| 参数名 | 描述 |
|---|---|
in_features |
输入张量的特征数。 |
out_features |
输出张量的特征数。 |
bias |
布尔值,决定是否添加可学习的偏置项。默认为 True。 |
torch.cat():PyTorch 中用于沿指定维度拼接多个张量的函数。它可以将多个形状相同的张量在指定维度上连接起来。
| 参数名 | 描述 |
|---|---|
tensors |
要拼接的张量元组或列表。 |
dim |
沿哪个维度进行拼接。 |
import torch
import torch.nn as nn
import torch.nn.functional as F
class TextCNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, num_classes, kernel_sizes, num_filters):
super(TextCNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.convs = nn.ModuleList([
nn.Conv1d(embedding_dim, num_filters, kernel_size)
for kernel_size in kernel_sizes
])
self.fc = nn.Linear(num_filters * len(kernel_sizes), num_classes)
def forward(self, x):
x = self.embedding(x) # (batch_size, seq_len, embedding_dim)
x = x.transpose(1, 2) # (batch_size, embedding_dim, seq_len)
conv_outputs = []
for conv in self.convs:
conv_output = F.relu(conv(x)) # (batch_size, num_filters, seq_len - kernel_size + 1)
conv_output = F.max_pool1d(conv_output, conv_output.size(2)).squeeze(2) # (batch_size, num_filters)
conv_outputs.append(conv_output)
x = torch.cat(conv_outputs, dim=1) # (batch_size, num_filters * len(kernel_sizes))
x = self.fc(x)
return x
# 示例参数
vocab_size = 10000
embedding_dim = 100
num_classes = 10
kernel_sizes = [2, 3, 4]
num_filters = 100
# 创建模型实例
model = TextCNN(vocab_size, embedding_dim, num_classes, kernel_sizes, num_filters)
print(model)4.文本分类 — Gated CNN
对CNN的一种改进,采用了两个卷积,第二个卷积过一个sigmoid函数,张量映射到0,1之间,然后两个卷积权重不同,大小相同,做对位相乘,相当于对第一个卷积做一定的放缩
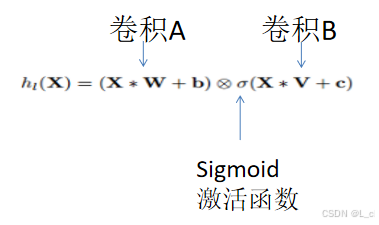

Ⅰ、原理与结构
GatedCNN的核心思想是通过引入门控机制来控制信息的流动,类似于LSTM中的门控机制。具体来说,GatedCNN使用两个独立的卷积层A和B,其中A经过sigmoid激活函数后作为门,控制B的输出信息传递到下一层。这种结构使得GatedCNN能够在保持计算效率的同时,有效地捕捉长距离依赖关系。
Ⅱ、工作流程
输入处理:将输入数据(如文本序列)通过Embedding层转换为查找表。
卷积操作:输入数据分别通过两个独立的卷积层A和B。
门控机制:卷积层A的输出经过sigmoid激活函数,生成门控信号。
信息传递:门控信号与卷积层B的输出逐元素相乘,控制信息的传递。
输出生成:经过门控操作后的结果通过softmax函数生成最终预测结果。
Ⅲ、优势
计算效率高:GatedCNN通过卷积操作替代了RNN的循环结构,能够并行处理数据,显著提高了计算效率。
长依赖处理:门控机制使得GatedCNN能够有效地捕捉长距离依赖关系,解决了传统CNN在处理长序列时的局限性。
简化模型:相比LSTM,GatedCNN的结构更为简单,参数更少,易于训练和部署。
Ⅳ、代码实现
nn.Conv1d():PyTorch 中用于一维卷积操作的类。它主要用于处理一维输入数据,如时间序列数据或文本数据。
| 参数名 | 描述 |
|---|---|
in_channels |
输入信号的通道数。 |
out_channels |
输出信号的通道数。 |
kernel_size |
卷积核的大小。 |
stride |
卷积核的步长。 |
padding |
在信号边界周围补充0的层数。 |
dilation |
卷积核元素之间的间距。 |
groups |
控制输入和输出之间的连接。 |
bias |
是否添加偏置项到输出中。 |
padding_mode |
指定填充模式。 |
nn.sigmoid():PyTorch 中的 Sigmoid 激活函数。它将输入值压缩到 (0, 1) 范围内,常用于二分类问题的输出层。
| 参数名 | 描述 |
|---|---|
x |
输入张量。 |
nn.Softmax():PyTorch 中的 Softmax 激活函数。它将输入值转换为概率分布,常用于多分类问题的输出层。
| 参数名 | 描述 |
|---|---|
input |
输入张量。 |
axis |
指定 Softmax 运算的轴。默认为 -1,表示最后一个维度。 |
torch.randn():PyTorch 中用于生成标准正态分布随机数的函数。它常用于初始化模型参数或生成随机输入数据。
| 参数名 | 描述 |
|---|---|
size |
输出张量的形状,可以是一个整数或一个元组。 |
out |
可选的输出张量。 |
dtype |
输出张量的数据类型。 |
layout |
输出张量的布局。 |
device |
输出张量的设备。 |
requires_grad |
是否需要记录梯度。 |
import torch
import torch.nn as nn
class GatedCNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(GatedCNN, self).__init__()
self.conv_A = nn.Conv1d(input_size, hidden_size, kernel_size=3, padding=1)
self.conv_B = nn.Conv1d(input_size, hidden_size, kernel_size=3, padding=1)
self.sigmoid = nn.Sigmoid()
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
A = self.conv_A(x)
B = self.conv_B(x)
gate = self.sigmoid(A)
gated_output = gate * B
output = self.softmax(gated_output.mean(dim=2))
return output
# 设定参数
input_size = 10
hidden_size = 20
output_size = 5
batch_size = 32
sequence_length = 10
# 创建模型
model = GatedCNN(input_size, hidden_size, output_size)
# 假数据进行训练
x = torch.randn(batch_size, input_size, sequence_length)
output = model(x)
print(output.shape) # 输出张量的形状5.文本分类 — TextRCNN
TextRCNN(Recurrent Convolutional Neural Network for Text Classification)是一种结合了循环神经网络(RNN)和卷积神经网络(CNN)的文本分类模型。它通过双向RNN捕捉文本的上下文信息,并使用CNN提取局部特征,从而有效地处理文本数据。
组合CNN和RNN,将输入的结果过一个Embedding层,然后过一个双向LSTM,然后将双向LSTM拼接起来的结果作为输入再输入一个CNN,进行文本分类

Ⅰ、模型结构
嵌入层(Embedding Layer):将文本数据中的单词转换为稠密的向量表示(词向量)。
双向RNN层(Bidirectional RNN Layer):使用双向LSTM或GRU来捕捉文本中的上下文信息。
卷积层(Convolutional Layer):使用一维卷积核对RNN的输出进行卷积操作,提取局部特征。
池化层(Pooling Layer):采用最大池化操作,从卷积层的输出中提取最重要的特征。
全连接层(Fully Connected Layer):将池化层的输出特征向量映射到最终的类别预测上。
输出层:使用Softmax函数将全连接层的输出转换为各个类别的概率分布。
Ⅱ、工作流程
数据预处理:将文本数据进行分词、构建词表,并将单词转换为词向量。
输入层:将词向量输入到TextRCNN模型中。
双向RNN层:使用双向RNN捕捉文本中的上下文信息。
卷积层:使用不同大小的卷积核对RNN的输出进行卷积操作,提取局部特征。
池化层:采用最大池化操作,从卷积层的输出中提取最重要的特征。
全连接层:将池化层的输出特征向量映射到最终的类别预测上。
输出层:使用Softmax函数将全连接层的输出转换为各个类别的概率分布。
训练与预测:通过反向传播算法更新模型参数,并在测试集上进行预测。
Ⅲ、优势
捕捉上下文信息:通过双向RNN,TextRCNN能够有效地捕捉文本中的上下文信息,提高文本理解能力。
处理长文本:相比传统的CNN,TextRCNN在处理长文本时表现更好,因为它能够利用RNN的长距离依赖特性。
特征提取能力强:结合了CNN和RNN的优点,能够有效地提取文本中的局部和全局特征。
Ⅳ、代码实现
nn.Embedding():PyTorch 中用于将离散的整数(如词汇表中的单词)映射到低维向量空间的模块。它主要用于自然语言处理任务中,将单词转换为稠密的向量表示,以便模型能够捕捉词汇之间的语义关系。
| 参数名 | 描述 |
|---|---|
num_embeddings |
嵌入字典的大小,即词汇表的大小。 |
embedding_dim |
每个嵌入向量的维度。 |
padding_idx |
指定填充(PAD)对应的索引值。默认为 None。 |
max_norm |
如果设置,嵌入向量的范数超过此值时将被重新归一化。 |
norm_type |
用于计算范数的类型,默认为 2(L2 范数)。 |
scale_grad_by_freq |
如果为 True,梯度将根据单词在 mini-batch 中的频率进行缩放。默认为 False。 |
sparse |
如果为 True,权重矩阵的梯度将被视为稀疏张量。默认为 False。 |
nn.LSTM():PyTorch 中用于处理序列数据的循环神经网络(RNN)层。它通过维护一个记忆单元来捕捉序列中的长期依赖关系。
| 参数名 | 描述 |
|---|---|
input_size |
输入特征的维度。 |
hidden_size |
隐藏状态的维度。 |
num_layers |
LSTM 层的层数。默认为 1。 |
bias |
是否使用偏置项。默认为 True。 |
batch_first |
如果为 True,输入和输出的第一个维度为 batch_size。默认为 False。 |
dropout |
除最后一层外,每一层的输出是否进行 dropout。默认为 0。 |
bidirectional |
是否使用双向 LSTM。默认为 False。 |
nn.ModuleList():PyTorch 中用于存储和管理多个子模块的容器。它允许你将多个层或模块存储在一个列表中,并在需要时通过索引访问它们。
| 参数名 | 描述 |
|---|---|
modules |
子模块的列表。 |
nn.Conv1d():PyTorch 中用于一维卷积操作的类。它主要用于处理一维输入数据,如时间序列数据或文本数据。
| 参数名 | 描述 |
|---|---|
in_channels |
输入信号的通道数。 |
out_channels |
输出信号的通道数。 |
kernel_size |
卷积核的大小。 |
stride |
卷积核的步长。 |
padding |
在信号边界周围补充0的层数。 |
dilation |
卷积核元素之间的间距。 |
groups |
控制输入和输出之间的连接。 |
bias |
是否添加偏置项到输出中。 |
padding_mode |
指定填充模式。 |
nn.Linear():PyTorch 中用于执行线性变换的全连接层。它将输入张量通过权重矩阵和偏置向量进行线性变换,输出新的张量。
| 参数名 | 描述 |
|---|---|
in_features |
输入张量的特征数。 |
out_features |
输出张量的特征数。 |
bias |
布尔值,决定是否添加可学习的偏置项。默认为 True。 |
permute():PyTorch 中用于调换张量维度次序的函数。它允许你重新排列张量的维度,以便于后续操作。
| 参数名 | 描述 |
|---|---|
dims |
需要维度的次序。 |
relu():PyTorch 中的 ReLU(Rectified Linear Unit)激活函数。它将输入值中的负值置为零,正值保持不变。
| 参数名 | 描述 |
|---|---|
x |
输入张量。 |
max_Pool1d():PyTorch 中用于一维最大池化操作的函数。它通过在输入张量上滑动一个固定大小的窗口,并在每个窗口中取最大值来降低数据的维度。
| 参数名 | 描述 |
|---|---|
input |
输入张量。 |
kernel_size |
池化窗口的大小。 |
stride |
池化窗口的步长。 |
padding |
在输入张量的边界周围补充0的层数。 |
dilation |
池化窗口元素之间的间距。 |
return_indices |
是否返回池化操作的索引。默认为 False。 |
ceil_mode |
是否使用向上取整。默认为 False。 |
append(): Python 列表的一个方法,用于在列表的末尾添加一个元素。
| 参数名 | 描述 |
|---|---|
object |
要添加到列表末尾的对象。 |
torch.cat():PyTorch 中用于沿指定维度拼接多个张量的函数。它可以将多个形状相同的张量在指定维度上连接起来。
| 参数名 | 描述 |
|---|---|
tensors |
要拼接的张量元组或列表。 |
dim |
沿哪个维度进行拼接。 |
import torch
import torch.nn as nn
import torch.nn.functional as F
class TextRCNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_size, num_classes, kernel_sizes, num_filters):
super(TextRCNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.LSTM(embedding_dim, hidden_size, bidirectional=True, batch_first=True)
self.convs = nn.ModuleList([
nn.Conv1d(hidden_size * 2, num_filters, kernel_size)
for kernel_size in kernel_sizes
])
self.fc = nn.Linear(num_filters * len(kernel_sizes), num_classes)
def forward(self, x):
x = self.embedding(x) # (batch_size, seq_len, embedding_dim)
rnn_out, _ = self.rnn(x) # (batch_size, seq_len, hidden_size * 2)
rnn_out = rnn_out.permute(0, 2, 1) # (batch_size, hidden_size * 2, seq_len)
conv_outputs = []
for conv in self.convs:
conv_output = F.relu(conv(rnn_out)) # (batch_size, num_filters, seq_len - kernel_size + 1)
conv_output = F.max_pool1d(conv_output, conv_output.size(2)).squeeze(2) # (batch_size, num_filters)
conv_outputs.append(conv_output)
x = torch.cat(conv_outputs, dim=1) # (batch_size, num_filters * len(kernel_sizes))
x = self.fc(x)
return x
# 示例参数
vocab_size = 10000
embedding_dim = 100
hidden_size = 128
num_classes = 10
kernel_sizes = [2, 3, 4]
num_filters = 100
# 创建模型实例
model = TextRCNN(vocab_size, embedding_dim, hidden_size, num_classes, kernel_sizes, num_filters)
print(model)6.文本分类 —— Bert
Bert作为Encoder,将文本转化为向量或矩阵
用Bert作文本分类,一般只输入一个句子,加入一个句首符【CLS】,将【CLS】位对应的向量接一个线性层,然后进行分类,这个【CLS】字输出的向量包含全句的信息,Bert模型所有的字都与其余字做过运算,包含其余字的信息,所以理论上,Bert模型中,每一个字的向量都可以代表整句话的信息,一般建议使用第一个字【CLS】对应向量做分类的原因是:Bert模型做预训练时,使用这个向量做二分类(判断两句话是否是上下文关系)
Bert模型有两个输出,一个是整句话的向量,另一个是【CLS】token的向量
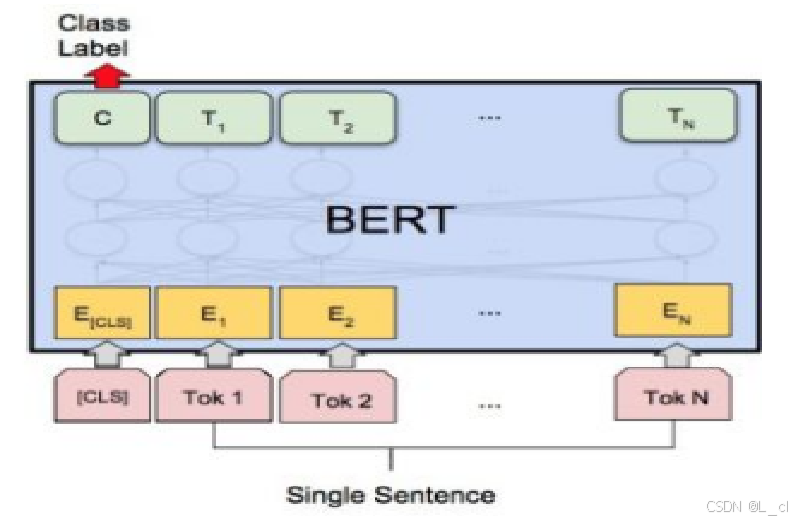
Ⅰ、Bert编码结果的使用方式
对于Bert的编码结果,有多种的使用方式:
方式1:取【CLS】 token对应的向量
方式2:取整句话的向量做一次max pooling / average pooling(保留语序信息),然后过一个线性层做分类(可以带上【CLS】token,也可以不带)
方式3:将Bert编码过后的向量再输入一层 LSTM 或 CNN(效果达不到理想状态:预训练不存在LSTM层,LSTM层只能随机初始化,没有用到Bert预训练模型中的训练好的参数)
方式4:将Bert(十二层Transformer拼接的结果)中间层(取出个别层)的结果取出相加进行运算等【在Config文件中调整Bert模型层数,优化使用资源,对简单任务同样适用】
Ⅱ、使用Bert模型
① Config.py
使用Bert模型做预测时,只需将文章开始提到的pipeline中的配置文件config.py中”model_type“模型类型改为bert,其余文件中的代码对于同样的任务同样的数据几乎不变
# -*- coding: utf-8 -*-
"""
配置参数信息
"""
Config = {
"model_path": "output",
"train_data_path": "F:\人工智能NLP\\NLP\Day7_文本分类问题\data\\train_tag_news.json",
"valid_data_path": "F:\人工智能NLP\\NLP\Day7_文本分类问题\data\\valid_tag_news.json",
"vocab_path":"chars.txt",
"model_type":"bert",
"max_length": 30,
"hidden_size": 256,
"kernel_size": 3,
"num_layers": 2,
"epoch": 11,
"batch_size": 128,
"pooling_style":"avg",
"optimizer": "adam",
"learning_rate": 1e-3,
"pretrain_model_path":"F:\人工智能NLP/NLP资料\week6 语言模型/bert-base-chinese",
"seed": 987
}
注:训练Bert模型时,学习率应该调小一点,eg:1e-5
三、文本分类的其他问题
1.数据稀疏问题
训练数据量小,模型在训练样本上能收敛,但预测准确率很低
解决方案:
① 标注更多的数据(利用大模型给它一些提示词,做一些训练标注工作来训练小模型)
② 尝试构造训练样本(又称数据增强)
③ 更换模型(如使用预训练模型等)减少数据需求
④ 增加规则弥补(给出一些特定规则)
⑤ 调整阈值,用召回率换准确率
⑥ 重新定义类别(通过一些数据信息证明,对类别进行调整,减少 / 增加类别)
2.标签不均衡问题
部分类别样本充裕,部分类别样本极少
|
类别 |
金融 |
体育 |
科技 |
生活 |
教育 |
|
样本数量 |
3000 |
3200 |
2800 |
3100 |
50 |
解决方案:
解决数据稀疏的所有的方法依然适用
① 过采样 复制指定类别的样本,在采样中重复
② 降采样 减少多样本类别的采样,随机使用部分
③ 调整样本权重 通过调整损失函数权重来体现
3.多标签分类问题
多标签:m选n 不同于 多分类:n选1
例:电影描述: 战斗中负伤而下身瘫痪的前海军战士杰克·萨利(萨姆·沃辛顿 Sam Worthington 饰)决定替死去的同胞哥哥来到潘多拉星操纵格蕾丝博士(西格妮·韦弗 Sigourney Weaver 饰)用人类基因与当地纳美部族基因结合创造出的 “阿凡达” 混血生物……
标签:动作,科幻
4.多标签问题的解决思路
① 分解为多个独立的二分类问题
判断每一类数据在每个二分类判断其下,是否属于此类
原始数据:
多次二分类:
② 将多标签分类问题转换为多分类问题
将每一个标签转化为多个分类,然后判断在哪一个标签,进行多分类
任何一个样本即使是多标签,也只会属于下列分类中的某一类
标签数量很多,转化后的类别数量也会较多

③ 更换loss直接由模型进行多标签分类 🌙
BCELoss:二元交叉熵损失函数,对交叉熵损失函数的一种调整
BCELoss(Binary Cross Entropy Loss,二元交叉熵损失)是一种用于二分类任务的损失函数,常用于度量预测概率与实际标签之间的差异。
BCELoss允许输入标签Y中含有多个1
公式: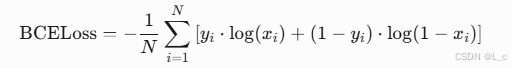
最终的损失值 ℓ(x,y) 根据 reduction 参数的不同计算方式:

默认情况下,reduction 为 'mean',即计算损失的加权平均值。
y_i是真实标签,x_i是模型预测的概率。
nn.Sigmoid(): PyTorch 中的一个激活函数,它将输入值映射到 (0, 1) 之间。
函数公式:![]()
torch.randn():生成服从标准正态分布(均值为 0,标准差为 1)的随机数张量。
| 参数名 | 类型 | 描述 |
|---|---|---|
*size |
int 或 tuple | 定义输出张量的形状。 |
out |
Tensor (可选) | 输出张量。 |
dtype |
torch.dtype (可选) | 返回张量的数据类型。 |
layout |
torch.layout (可选) | 张量的布局类型。 |
device |
torch.device (可选) | 张量所在的设备(如 CPU 或 GPU)。 |
requires_grad |
bool (可选) | 是否记录梯度信息。 |
torch.FloatTensor():创建一个浮点型张量。它可以接受列表、元组或 numpy 数组作为输入。
| 参数名 | 类型 | 描述 |
|---|---|---|
data |
list, tuple, numpy.ndarray | 用于初始化张量的数据。 |
dtype |
torch.dtype (可选) | 张量的数据类型。 |
device |
torch.device (可选) | 张量所在的设备。 |
requires_grad |
bool (可选) | 是否记录梯度信息。 |
nn.BCELoss():计算二分类问题中的二值交叉熵损失。它通常与 Sigmoid 激活函数一起使用。
| 参数名 | 类型 | 描述 |
|---|---|---|
weight |
Tensor (可选) | 每个样本的权重。 |
reduction |
str (可选) | 指定损失的计算方式,可选 'none'、'mean'、'sum'。 |
zip(): Python 内置函数,用于将多个可迭代对象(如列表、元组等)中对应位置的元素打包成元组,并返回一个可迭代对象。
| 参数名 | 类型 | 描述 |
|---|---|---|
*iterables |
可迭代对象 | 任意数量的可迭代对象。 |
torch.log():计算输入张量的自然对数(以 e 为底)。
| 参数名 | 类型 | 描述 |
|---|---|---|
input |
Tensor | 输入张量。 |
out |
Tensor (可选) | 输出张量。 |
import torch
import torch.nn as nn
# 使用Sigmoid函数将输入值映射到[0, 1]之间,表示概率
sig = nn.Sigmoid()
input = torch.randn(5) # 随机构造一个模型当前的预测结果 y_pred
input = sig(input) # 将输入值通过Sigmoid函数转换为概率
target = torch.FloatTensor([1, 0, 1, 0, 1]) # 真实标签 y_true
# 定义二元交叉熵损失函数
bceloss = nn.BCELoss()
loss = bceloss(input, target) # 计算损失
print("Pytorch库:",loss)
# 手动实现
l = 0
for x, y in zip(input, target):
l += y*torch.log(x) + (1-y)*torch.log(1-x)
l = -l/5 # 求和、平均、取负
print("手动实现:",l)
# 对比交叉熵,区别在于交叉熵要求真实值是一个固定类别
# celoss = nn.CrossEntropyLoss()
# input = torch.FloatTensor([[0.1,0.2,0.3,0.1,0.3],[0.1,0.2,0.3,0.1,0.3]])
# target = torch.LongTensor([2,3])
# output = celoss(input, target)
# print(output)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 57
57 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)