
探索大模型|自然语言直接查询数据库
虽然demo做的不复杂,不过这个事却值得深思,要知道AI学习的速度是十分快的。不久之后,可能是用户直接用自然语言描述获取结果数据集,而不用关心中间的实现过程。以后SQLBoy这个岗位恐怕是有点危险了。起码一般的sql交给大模型是没问题的,在业务复杂的情况下,麻烦的是把业务情况喂给大模型,经验丰富的sqlboy可能在初期是占优势的。依次类推,代码开发等技术工作可能也会这样。类似的工具实际已经有了,不
导读:本文围绕 “自然语言直接查询数据库” 展开探索。开篇指出通用大模型在具体领域存在不足,引出将数据库与大模型结合的设想,即利用大模型的自然语言处理能力实现数据库查询。接着详细阐述探索思路,包括让大模型理解数据库元数据、借助大模型处理自然语言等。随后介绍了连接数据库和大模型的方法,还给出了整体测试过程,涵盖单表和多表测试,展示了理想的测试效果。文章最后对该技术的未来发展进行了思考,探讨其对相关岗位的影响以及市场上同类工具的现状 。
1. 背景
最近大模型的火爆引发了全民热议,实际上只是通用大模型,在具体的领域还是有很多不足。真正用起来,是要和一些场景、应用结合,这是不言而喻的。作为本职是大数据人员,自然就想到平时我们的数据库能不能和大模型结合,减少工作的压力。大模型最突出的一点就是自然语言,那么能不能使用自然语言直接对话大模型,然后查询数据库,最后获取结果数据集呢?我想这是个值得尝试探索的路。
2. 探索思路
最初我想的是,对话大模型,让大模型给出sql,通过它给的sql查询数据库出结果。

这样大模型只参与自然语言转换sql,可能会对数据库的情况不了解。因此我觉得应该让大模型了解数据库的元数据,在实际操作中,我发现给大模型一条样例数据效果上会更好。可以把大模型理解成一个空有一身本事却无处施展的人,所以给的prompt越多,他的回答也会更加精准。
其实这属于NLP技术,中文意思是自然语言处理,是人工智能领域的一个重要方向,不过如果自己去处理自然语言,代价会很大,而且这需要大量的数据训练,这样成本太大了,因此借助大模型直接处理自然语言。
3. 连接数据库
python连接Mysql数据库是十分简单的,就不多解释了。只是这里做三件事
-
遍历指定库中所有的表
-
获取每个表的DDL
-
每个表查询limit 1数据,作为样例
把表DDL和样例数据提供给prompt
4. 连接大模型
关于如何使用Python连接大模型,这个在之前的文章中有详细的介绍,有兴趣的朋友可以看看文末的往期推荐 。
这里直接给出案例
# 基础初始化设置
base_url = "http://localhost:11434/api"
url = f"{base_url}/generate"
headers = {
"Content-Type": "application/json"
}
data = {
"model": "deepseek-r1:8b",
"prompt": "你是一个专业的mysql生成助手,能够准确理解用户需求并生成规范的SQL语句"+"这是建表语句和样例数据:\n\n" + database_schema + "\n\n"+"现在要求,\n " + prompt + " \n 请你生成正确的sql查询语句",
"stream": False
}
response = requests.post(url, headers=headers, json=data)
return response.json().get('response', '')
这里我使用的是本地deepseek-r1-8B 的模型就可以满足使用,没有条件本地部署的朋友可以找其他平台提供的api,用起来效果差不多。
5. 整体测试
上述方法可以让大模型输出sql,实际使用中还需要对大模型输出的回答简单清洗一下,因为下一步给数据库的只需要sql语句即可。
下面是主体代码
def generate_and_execute(prompt: str, ) -> None:
# 获取数据库元数据
database_schema = get_database_schema()
# 生成SQL
generated_sql = generate_query_local_model(prompt, database_schema)
print(f"\n【生成的SQL】\n{generated_sql}")
# 提取SQL
sql = extract_sql(generated_sql)
# 执行查询
print("\n【查询结果】")
result = execute_sql(sql)
if isinstance(result, list):
for row in result:
print(row)
else:
print(result)
这里我事先做了两张表,一个员工表、一个员工部门表。
下面的测试围绕这两个表
5.1 单表测试
第一次我查询
查询销售部年龄大于35岁的男性员工
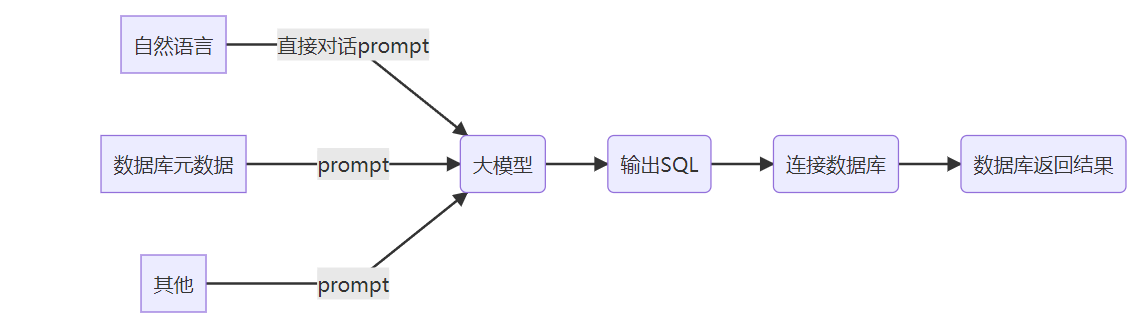
任务执行之后 GPU立刻就拉满了,可怜我奋斗多年的笔记本啊。
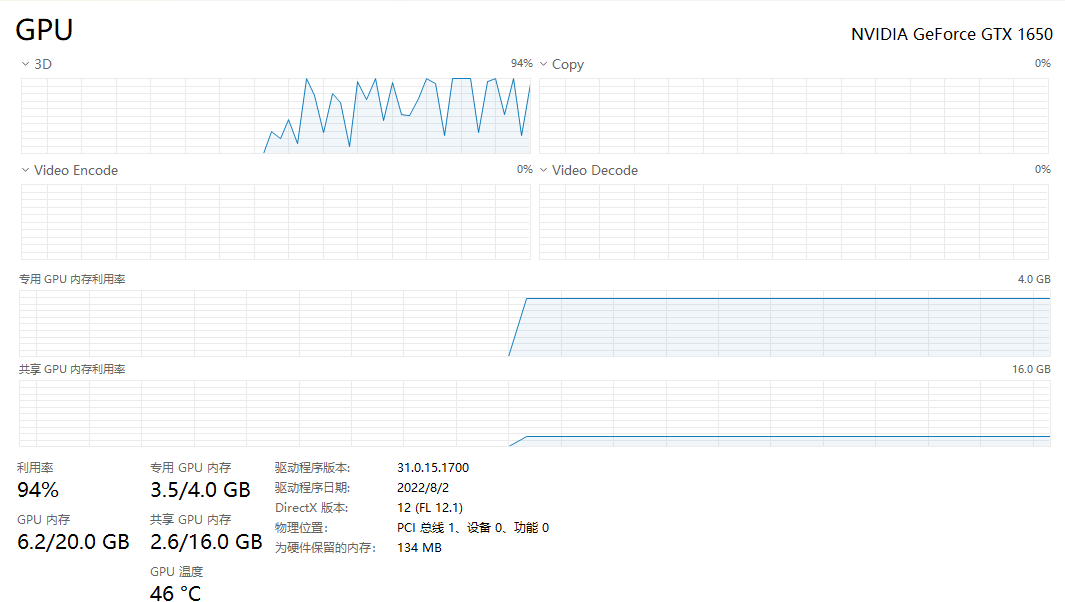
很快就出现结果,如下图
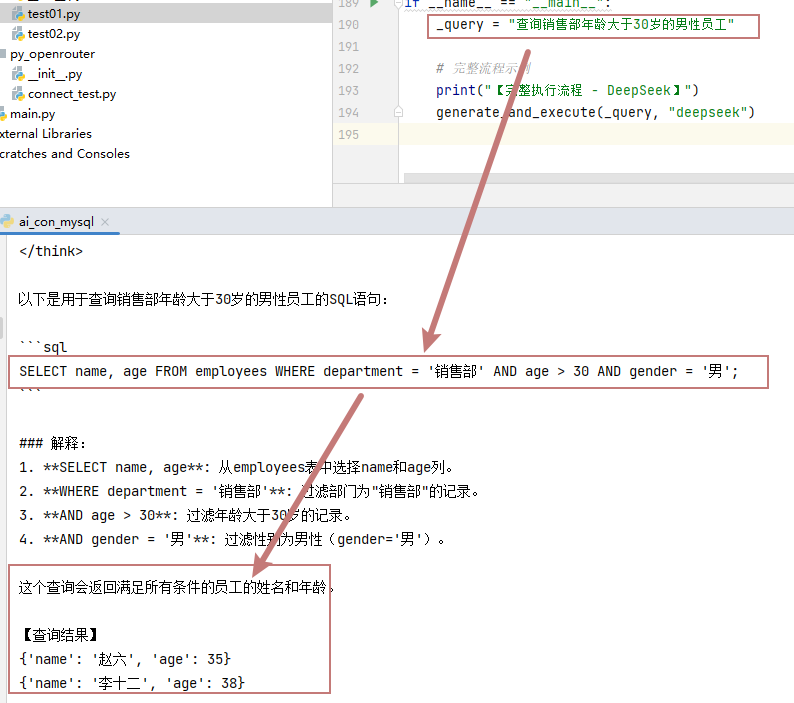
首先deepseek进行了think,给出了sql,并做出了结果。最后是连接数据库查询的结果。效果很理想。
5.2 多表测试
单表没问题,那么多表联查呢,我试着查询
查询研发部所有员工的姓名
运行结果如下
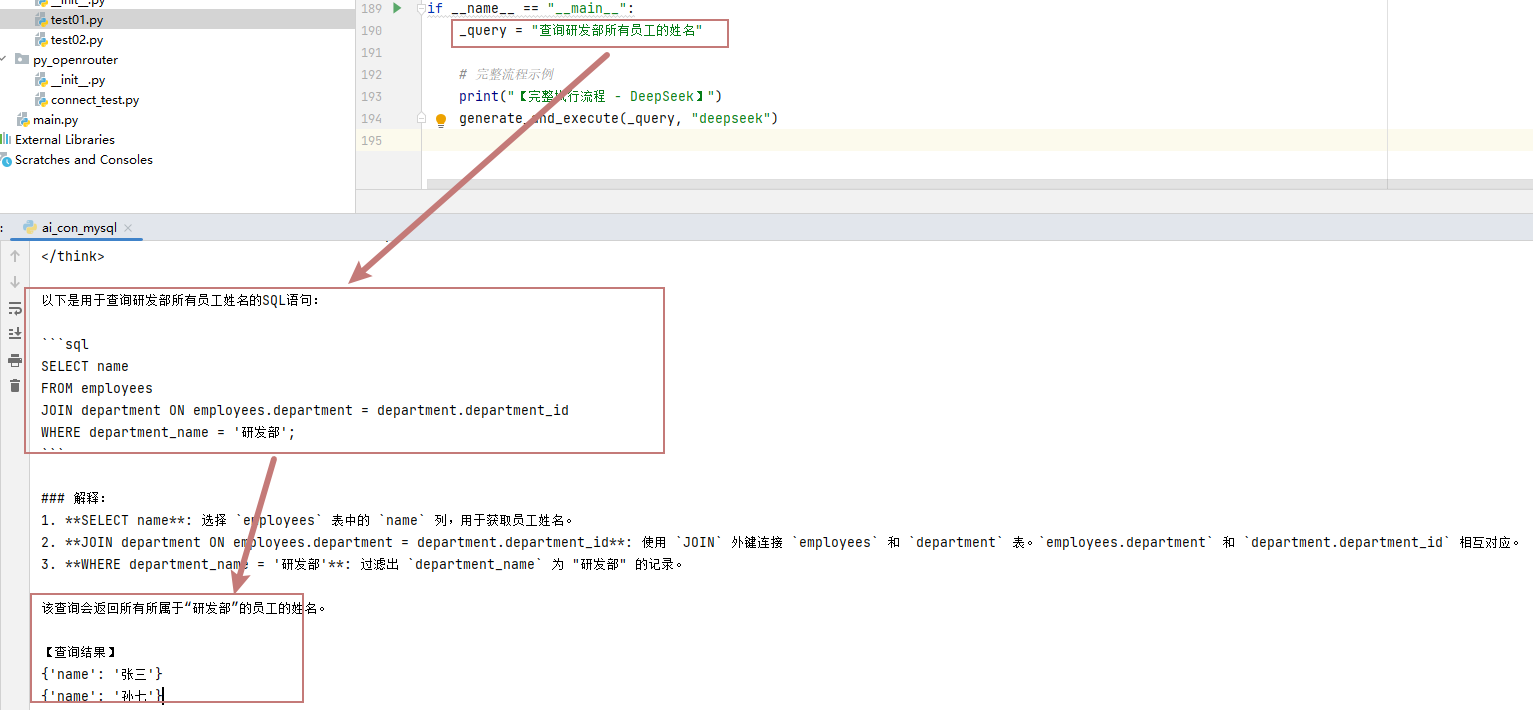
deepseek给出了正确的联表查询sql。
以上代码关注 DataSpeed 公众号,回复 自然语言查询数据库 ,即可获取完整代码。
6.总结与思考
虽然demo做的不复杂,不过这个事却值得深思,要知道AI学习的速度是十分快的。
-
不久之后,可能是用户直接用自然语言描述获取结果数据集,而不用关心中间的实现过程。
-
以后SQLBoy这个岗位恐怕是有点危险了。起码一般的sql交给大模型是没问题的,在业务复杂的情况下,麻烦的是把业务情况喂给大模型,经验丰富的sqlboy可能在初期是占优势的。依次类推,代码开发等技术工作可能也会这样。
-
类似的工具实际已经有了,不过基本都是商业化产品,比如chat2DB、Azure SQL 他们在这条路上已经走了很远。而开源产品还是很少,或者做的十分简单。
-
大模型带来的冲击十分大,目前看似还有点门槛,以后会融入到生活,就像电脑出现再到个人电脑那样,成为习以为常的东西。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)