【论文笔记】MUSt3R:推广DUSt3R+记忆机制
DUSt3R在几何计算机视觉领域引入了一种新颖的范式,提出了一种能够对任意图像集合进行密集且无约束的立体三维重建的模型,而无需事先了解相机校准或视角姿态信息。然而,DUSt3R在内部处理图像对并且回归局部三维重建,这些重建需要在全局坐标系中对齐。图像对的数量呈二次增长,这一固有限制在大规模图像集合的鲁棒和快速优化中尤为突出。本文提出了一种将DUSt3R从图像对扩展到多视图的扩展方法,解决了上述所有

挪威实验室DUSt3R的续集,作者在DUSt3R,MASt3R的基础上,修改了网络架构,并且使用了类似SPann3r的记忆机制,完成了从2到N的视角推广,可以应用于VO,pose estimate,reconstruction,depth estimate.
文章中提到了一篇最新的SLAM综述,感兴趣可以阅读一下:
1.abstract
DUSt3R在几何计算机视觉领域引入了一种新颖的范式,提出了一种能够对任意图像集合进行密集且无约束的立体三维重建的模型,而无需事先了解相机校准或视角姿态信息。然而,DUSt3R在内部处理图像对并且回归局部三维重建,这些重建需要在全局坐标系中对齐。图像对的数量呈二次增长,这一固有限制在大规模图像集合的鲁棒和快速优化中尤为突出。
本文提出了一种将DUSt3R从图像对扩展到多视图的扩展方法,解决了上述所有问题。具体来说,我们提出了一种多视图立体三维重建网络,该网络通过使DUSt3R架构对称化并扩展其直接预测所有视图在共同坐标系中的三维结构。其次,我们为模型引入了一个多层记忆机制,该机制能够降低计算复杂度,并将重建扩展到大规模集合,以高帧率推断数千个三维点图,同时仅增加有限的复杂度。该框架设计用于离线和在线三维重建,因此可以无缝应用于SfM和视觉SLAM场景,在包括未校准的视觉里程计、相对相机姿态、尺度和焦距估计、三维重建以及多视图深度估计等各种三维下游任务中展示了最先进的性能。
2.introduction
DUSt3R通过数百万对带有深度和相机参数真实标注的图像对进行训练,在零样本设置下,展示了在不同相机传感器的各种现实场景中的卓越性能和泛化能力。DUSt3R的方法是,将成对重建问题转化为点图对的回归问题(点图定义为像素与三维点之间的密集映射),另一方面这有效放松了传统投影相机模型的硬约束。点图表示法(现已被后续工作 [19,32] 采用)同时包含三维几何和相机参数,并能够统一并联合解决多种三维视觉任务,如深度估计、相机姿态和焦距估计、密集三维重建以及像素对应关系。
尽管该架构在单目和双目情况下表现良好,但在处理大量图像时,其成对估计的特性反而成为了一种劣势。因为每一对图像预测的pointmap都处于局部坐标系下,因此需要一个全局后处理步骤将所有预测对齐到一个全局坐标系中,这在处理大规模图像集合时,算法复杂度成二次方上升! 所以,如何应对成对方法的二次复杂度?如何鲁棒且快速地优化此类问题?如果需要实时预测怎么办?
这些问题在Mast3R-SfM [19] 中使用一个连通图只得到了部分解决,Spann3R 提出使用空间记忆来跟踪先前的观测结果。这使得可以直接预测每张图像在全局坐标系中的点图,从而避免了对GA(global align)的需求。Spann3R保留了DUSt3R的成对架构,按顺序处理图像对。除了第一张和最后一张图像外,所有图像都会依次通过模型两次。对于每张图像,第一次通过时获得位置增强的特征,然后通过涉及额外编码器的注意力操作查询空间记忆以增强特征。第二次通过更新记忆并预测点图。在本工作中,我们脱离了成对范式,通过将记忆作为架构的核心元素,将DUSt3R从成对扩展到𝑁视图。
我们设计的新架构能够扩展到任意大规模图像集,并能够以高帧率在同一坐标系中推断相应的点图。我们的多视图立体三维重建网络(MUSt3R)通过几项关键修改扩展了DUSt3R架构——即使其对称化并增加工作记忆机制——同时仅增加有限的复杂度。该模型不仅能够处理无序图像集合的离线重建(如结构从运动,SfM场景),还能够应对密集视觉里程计(VO)和SLAM任务,旨在在线预测移动相机录制的视频流的相机姿态和三维结构。据我们所知,这是第一种能够无缝利用记忆机制覆盖这两种场景的方法,无需更改架构,同一网络可以以无感知的方式执行任一任务。
我们的贡献有三点:
1. 我们重新设计了DUSt3R架构,使其对称化,并支持在度量空间中进行N视图预测。
2. 我们为模型添加了记忆机制,降低了离线和在线重建的计算复杂度。
3. 我们在估计视场、相机姿态、三维重建和绝对尺度方面实现了最先进的性能,同时不牺牲推理速度。
3.method
3.1. review DUSt3R
简单来说,DUSt3R的架构是一个Siamese ViT的编码解码架构,输入两张图片,输出是两张图片像素对应的一个pointmap(3通道的一个image,每一个像素对应一个3D点,一张图对应一个点图,最后配准对齐到一个坐标系底下)与confidence map,transformer的attention机制使得两张图之间的信息得以连通,监督信号从根源上来说是深度,以及数据集自带的相机参数,后者无需多说,对于前者,因为pointmap的GT是深度计算出来的。
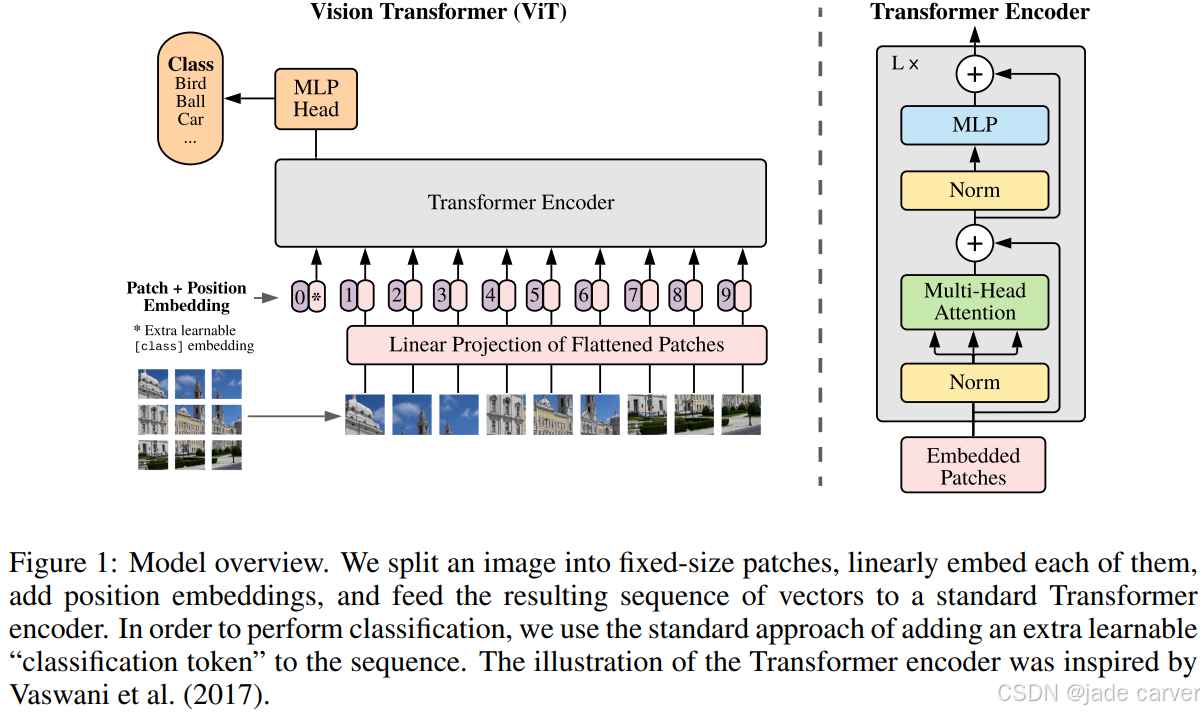
为了便于后面使用,DUSt3R的公式与符号表示如下,pointmap 为![]() ,pointmap的GT为
,pointmap的GT为![]() ,置信图为
,置信图为![]() ,images
,images ![]() ,第一张图片坐标系中的3D点
,第一张图片坐标系中的3D点![]() ,两张图片在encoder以后的编码为
,两张图片在encoder以后的编码为![]() ,编码以后通过线性层
,编码以后通过线性层![]() 输入解码器,解码器blocks为
输入解码器,解码器blocks为![]() ,预测头
,预测头![]() ,总体的公式为:
,总体的公式为:
![]()
loss:其中![]() 为尺度,定义为所有有效3D点到原点的平均距离。
为尺度,定义为所有有效3D点到原点的平均距离。
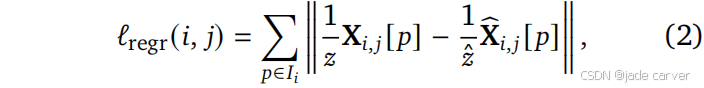
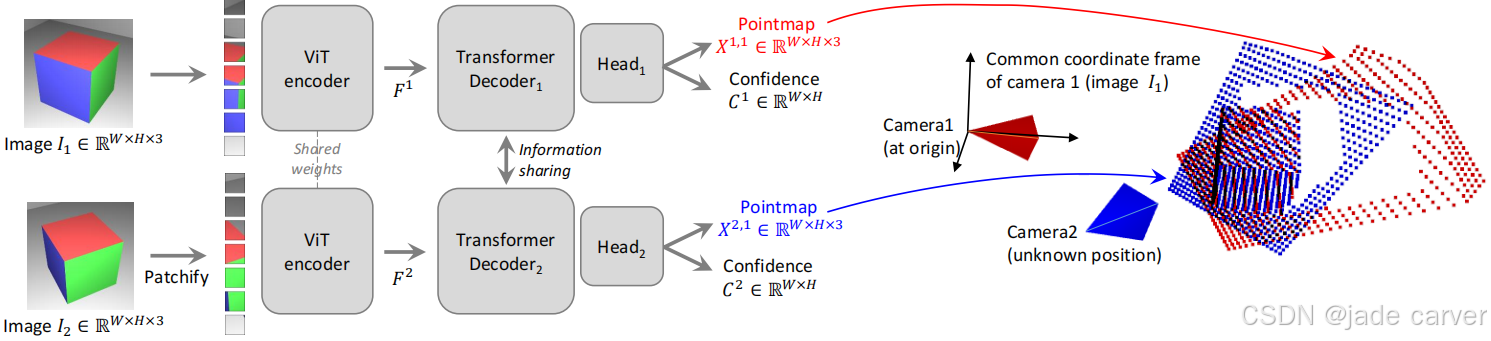
3.2. MUSt3R: a Multi-view Architecture
这一节主要介绍将DUSt3R扩展到任意数量的 𝑁 视图,如果简单地按照原始DUSt3R扩展到 𝑁 视图,那么实际上需要 𝑁 个独立的解码器,这是一个自然而然的想法,但是我们需要考虑的是计算和内存上的效率,这并不可行。
所以,我们提出了一种对称化的架构,使用单一共享权重的Siamese解码器,这种设计可以使所有视图共享同一个解码器,然后就可以自然地扩展到任意数量的视图(𝑁 视图),最后进行重建与相机估计,如图3。
1.简化DUSt3R架构
DUSt3R原本有两个独立的解码器和预测头,我们通过共享权重的方式将其替换为单一的Siamese解码器![]() 和预测头
和预测头![]() ,从而减少了冗余,也就是两个图片使用同一个解码器,为了标识参考图像𝐼1(定义公共坐标系的图像),我们在解码器的输入
,从而减少了冗余,也就是两个图片使用同一个解码器,为了标识参考图像𝐼1(定义公共坐标系的图像),我们在解码器的输入![]() 中添加了一个可学习的嵌入B:
中添加了一个可学习的嵌入B:
![]()
另外,在ablation中,我们发现交叉注意力中使用旋转位置嵌入(RoPE)[59] 并不是必要的,可以安全地移除。
2.扩展到多视图
通过改变解码器块中的交叉注意力机制,使其能够在多个视图之间进行操作。具体来说,每个图像的token会与其他所有图像的token进行交叉注意力计算。解码器块都是残差结构,包括自注意力(视图内)、交叉注意力(视图间)和最后的MLP。因此我们在图像𝐼𝑖的token和所有其他𝑗≠𝑖图像的token之间进行交叉注意力。
CatN表示在序列维度上连接图像token,![]() 表示在第𝑙层连接𝑛个图像的token。
表示在第𝑙层连接𝑛个图像的token。![]() 表示连接除第𝑖个图像外的所有图像的token。我们的模型在第𝑙层对图像𝐼𝑖的token和所有其他图像的token应用交叉注意力we have:
表示连接除第𝑖个图像外的所有图像的token。我们的模型在第𝑙层对图像𝐼𝑖的token和所有其他图像的token应用交叉注意力we have:
![]()
3.Fast relative pose regression
我们修改了预测头,使其不仅输出X𝑖,1(以𝐼1为参考的点图),还输出X𝑖,𝑖(以𝐼𝑖为参考的点图)。然后通过Procrustes分析估计X𝑖,𝑖和X𝑖,1之间的变换,从而快速计算相对姿态。这种方法比传统的PnP(透视n点)方法更简单、更快,且不需要已知焦距:
![]()
3.3.MUSt3R的记忆机制
基于3.2节描述的架构,我们赋予模型一个可迭代更新的记忆机制,使其能够高效处理任意数量的图像;通过额外的MLP将3D反馈注入到早期层中。整体解码器架构如图3所示,反馈注入机制如图4所示。
1.Iterative memory update
在第3.2节中,我们描述了如何扩展DUSt3R以处理多张图像。然而,在实际应用中,𝑁可能非常大,导致对大规模token序列进行交叉注意力的计算变得不可行。所以作者提出以迭代方式利用模型,并使用类似于Spann3R的记忆机制。
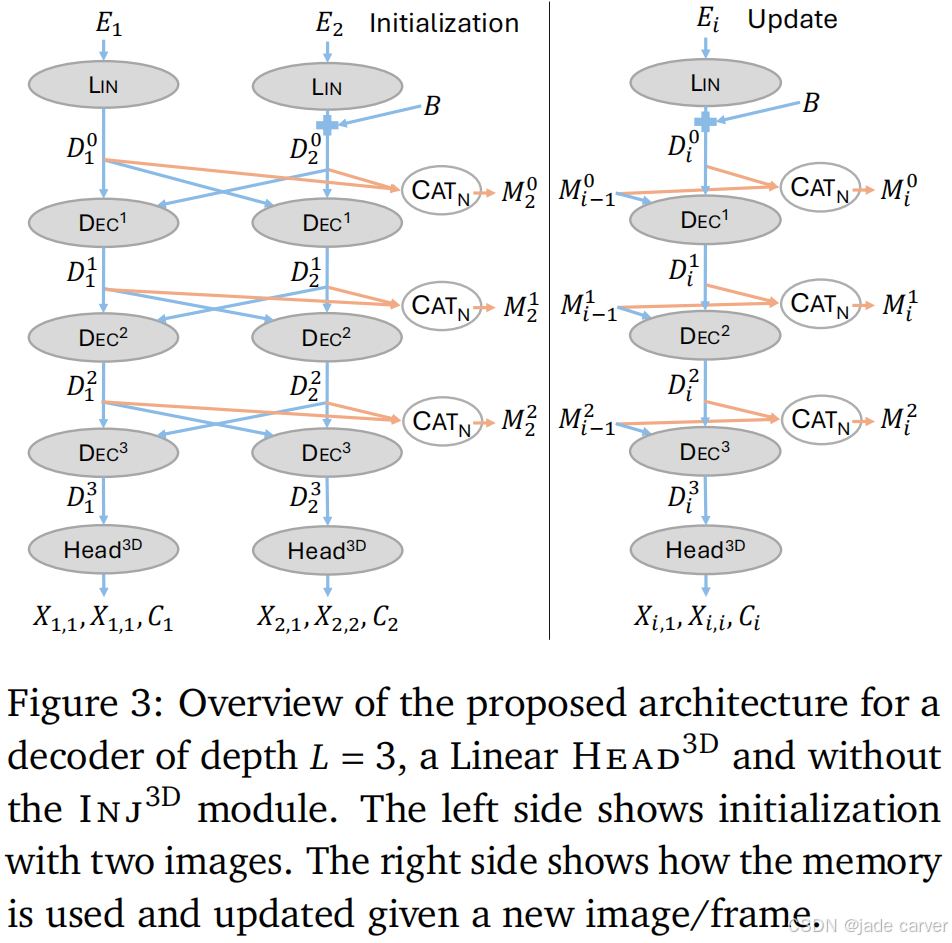
我们的记忆仅包含每层先前计算的![]() 。如图3所示,当新图像𝐼𝑛+1到达时,它会与这些保存的token进行交叉注意力计算,即对于每一层,我们有:
。如图3所示,当新图像𝐼𝑛+1到达时,它会与这些保存的token进行交叉注意力计算,即对于每一层,我们有:
![]()
当新图像到达时,只需与新图像的token和记忆中的token进行交叉注意力计算。也就是说,新图像的特征![]() 通过将其连接到当前记忆
通过将其连接到当前记忆![]() 来简单地添加到记忆中,从而将记忆扩展到
来简单地添加到记忆中,从而将记忆扩展到![]() 。有趣的是,我们可以将其与因果Transformer推理中的KV缓存 [44] 进行类比。通过缓存每层先前计算的
。有趣的是,我们可以将其与因果Transformer推理中的KV缓存 [44] 进行类比。通过缓存每层先前计算的![]() ,我们使MUSt3R具有因果性:每张新图像都会关注先前看到的图像,但这些图像不会被更新。即新图像只能与之前存储在记忆中的token进行交互,而不能与未来的图像交互。
,我们使MUSt3R具有因果性:每张新图像都会关注先前看到的图像,但这些图像不会被更新。即新图像只能与之前存储在记忆中的token进行交互,而不能与未来的图像交互。
在这种架构下,可以在不向记忆中添加新token的情况下处理图像。我们称此过程为“渲染”。在渲染模式下,模型可以重新计算某些帧的点图,而不需要向记忆中添加新的token。这是因为所有需要的token都已经存在于记忆中。换句话说,渲染模式允许模型利用未来帧的信息来优化当前帧的预测。例如,在处理第𝑖帧时,模型可以访问第𝑖+1、𝑖+2等帧的token,从而打破因果性限制。
比如,在视频序列结束时进行渲染,此时所有图像都已存储在记忆中。我们可以逐帧处理(称为顺序处理)或𝑛帧一组处理(𝑛 > 1)。
2.全局3D反馈
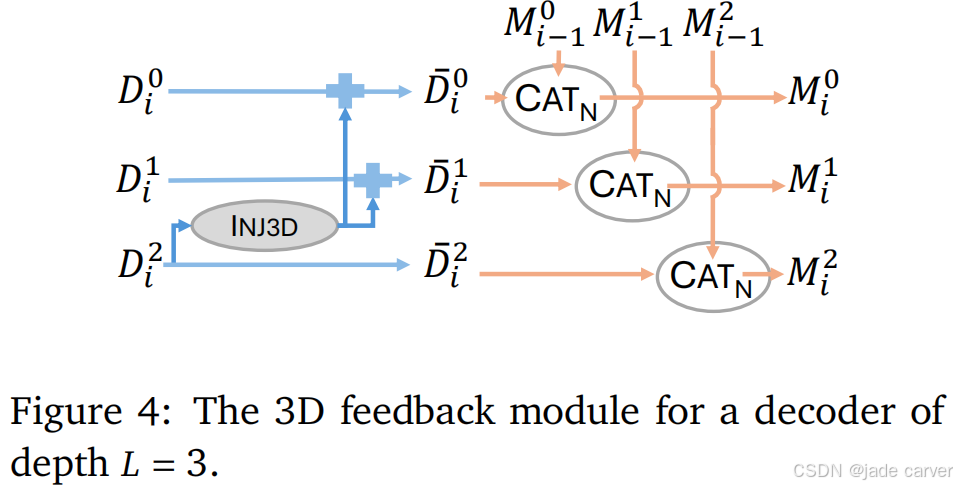
早期层的token缺乏全局3D信息,仅包含局部特征,因此我们从终端层(最后一层)提取全局3D信息,并通过一个额外的MLP(![]() )将其注入到早期层的token中。即对于每一层(𝑙 < 𝐿 − 1),将终端层的特征
)将其注入到早期层的token中。即对于每一层(𝑙 < 𝐿 − 1),将终端层的特征![]() 通过
通过![]() 处理后加到当前层的token中,从而增强其全局3D感知能力:
处理后加到当前层的token中,从而增强其全局3D感知能力:
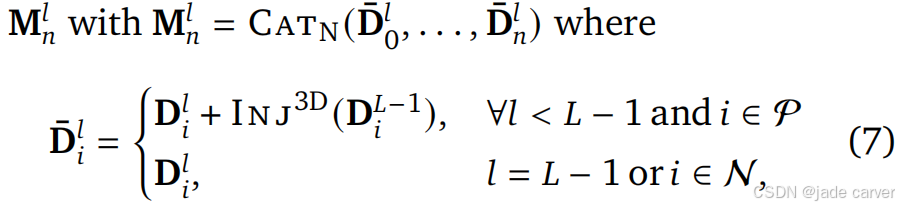
3.4. Memory Management
随着图像数量的增加,记忆(memory)的大小会线性增长,这会导致计算负担加重。为了缓解这一问题,作者提出了一种启发式选择记忆token的方法,即有选择地将某些图像加入记忆,而不是将所有图像都存储起来。
1.online
处理视频流,图像是逐帧到达的。在这种情况下,模型需要实时更新记忆和3D场景。记忆和3D场景从第一帧的预测结果初始化。每帧图像通过MUSt3R模型进行处理,并与当前记忆进行交互,预测可见的几何结构和相机参数。然后根据当前帧的预测点图(𝑋𝑖,1)与当前3D场景的空间发现率(spatial discovery rate)来决定是否将该帧加入记忆。空间发现率衡量了当前帧观察到的场景部分与已有场景的重叠程度。如果当前帧观察到了足够多的新区域(即发现率高于阈值𝜏𝑑),则将其加入记忆和3D场景。
3D场景通过一组KDTrees(K维树)存储,每个3D点根据其观察方向被分配到不同的树中。观察方向被划分为规则的八分体(octant),每个像素的观察方向被映射到对应的八分体索引,从而确定其所属的树。通过计算当前帧的3D点与已有场景的最近距离(归一化后),来判断当前帧是否观察到了新区域。
2.offline
处理无序的图像集合(例如从不同角度拍摄的静态场景照片)。在这种情况下,模型需要从所有图像中选择关键帧,并构建全局3D场景。
使用ASMK(Aggregated Selective Match Kernels)图像检索方法,基于所有图像的编码特征(E𝑖)进行关键帧选择。采用最远点采样(farthest point sampling)方法,选择一组固定数量的关键帧。
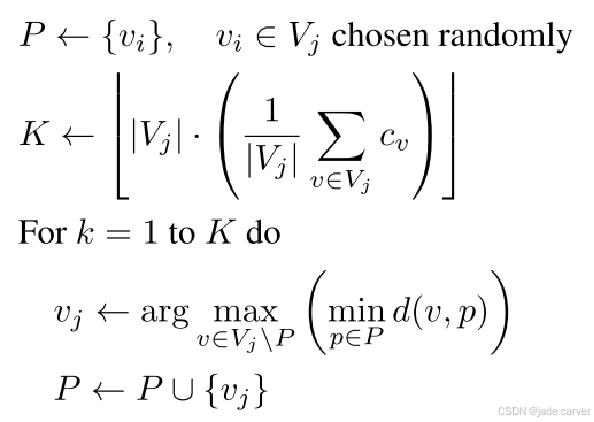
为了最大化图像之间的重叠区域(从而提高预测的稳定性),对图像进行重新排序:首先选择与其它图像连接最多的关键帧。然后通过贪心算法,按与当前视图集的相似度从高到低依次添加其他图像。将选定的关键帧依次通过网络,构建整个场景的潜在表示。最后,利用记忆渲染所有图像。
4.训练
4.1Pre-training MUSt3R with pairs
类似于DUSt3R的训练方式,目标是预测场景中可能相距较远的3D点。为了在远距离点上获得更好的收敛性和性能,作者在对数空间中计算损失函数。
1.对数空间映射
定义一个映射函数 𝑓,将3D点的坐标转换到对数空间:
![]()
其中 𝑥 是3D点的坐标。将预测的3D点 ![]() 和真实的3D点
和真实的3D点 ![]() 分别映射到对数空间:
分别映射到对数空间:
![]()
其中 𝑧 是归一化因子。
2.回归loss
然后计算预测点与真实点之间的loss:
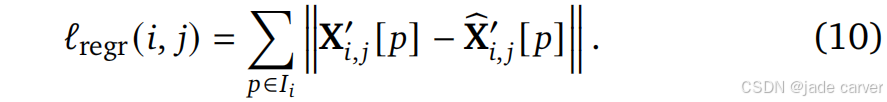
使用分辨率为224的图像,从CroCo v2 [74] 初始化解码器(深度 𝐿 = 12),然后在分辨率为512的图像上进行微调(支持不同的宽高比)。总共使用14个数据集进行训练,包括 Habitat [49]、ARKitScenes [15]、Blended MVS [77]、MegaDepth [34] 等。
4.2多视MUSt3R
从4.1中预训练的symmetric DUSt3R模型初始化MUSt3R,每个场景使用 𝑁 = 10 张图像进行训练。为了高效处理多视图序列,冻结编码器并使用 xformers [31] 加速注意力计算。使用12个数据集(排除了Virtual KITTI和Static Scenes 3D,因为它们不适合当前设置)。
记忆从两张图像初始化即图3中的![]() ,然后逐帧更新。
,然后逐帧更新。
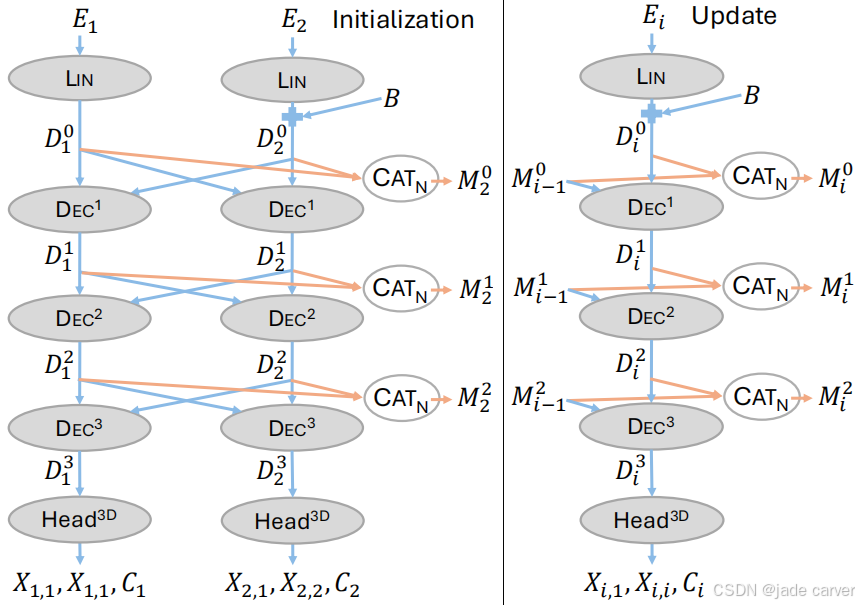
首先随机选择 𝑛 张视图(2 ≤ 𝑛 ≤ 𝑁),预测其点图。之后从记忆中渲染所有视图(包括 𝑛 张记忆帧),最终得到 𝑛 + 𝑁 个预测结果。loss如下:
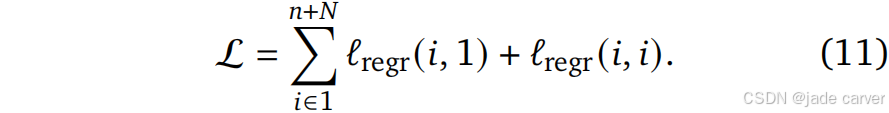
5.实验
在许多无约束场景中展示了所提出系统的可用性和性能,包括未校准的视觉里程计(VO)、相对姿态估计、3D重建和多视图深度估计。在所有场景中,无需访问相机校准信息,就能实现最先进的性能,同时具有显著的通用性和简洁性。作者主要对比了DUSt3R和Spann3R。我们主要关注后三个方向。
5.1.Relative pose estimation
实验设置
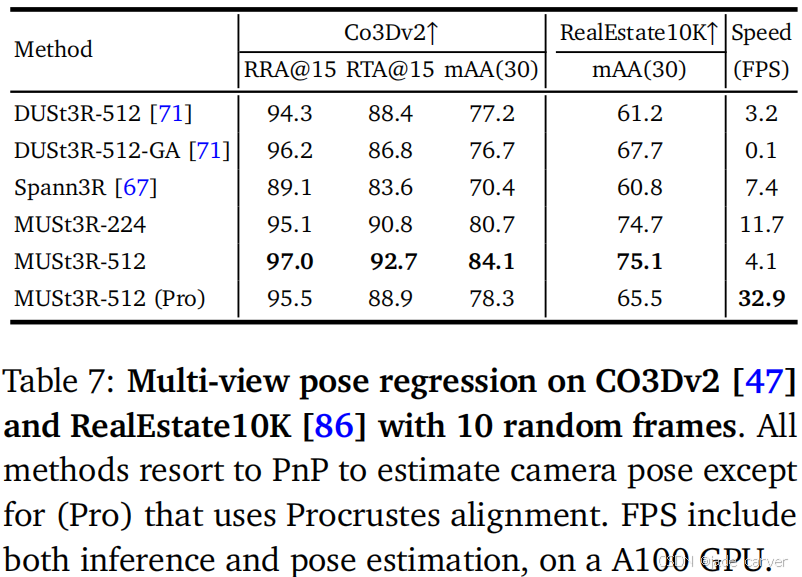
在 CO3D 和 RealEstate10k 数据集上测试了 MUSt3R 和 Spann3R。这些数据集包含室内和室外场景,相机姿态是通过 COLMAP 或 SLAM 结合全局优化(bundle adjustment)获得的。评估了1.8K个测试集视频片段,每个序列包含10帧图像,评估所有可能的45对帧之间的相对相机姿态。
评估指标
RRA@15:相对旋转误差小于15°的准确率。
RTA@15:相对平移方向误差小于15°的准确率。
mAA@30:在阈值𝜏 ∈ [1, 30]范围内,曲线𝑚𝑖𝑛(RRA@𝜏, RTA@𝜏)下的面积。
5.2.3D reconstruction
实验设置
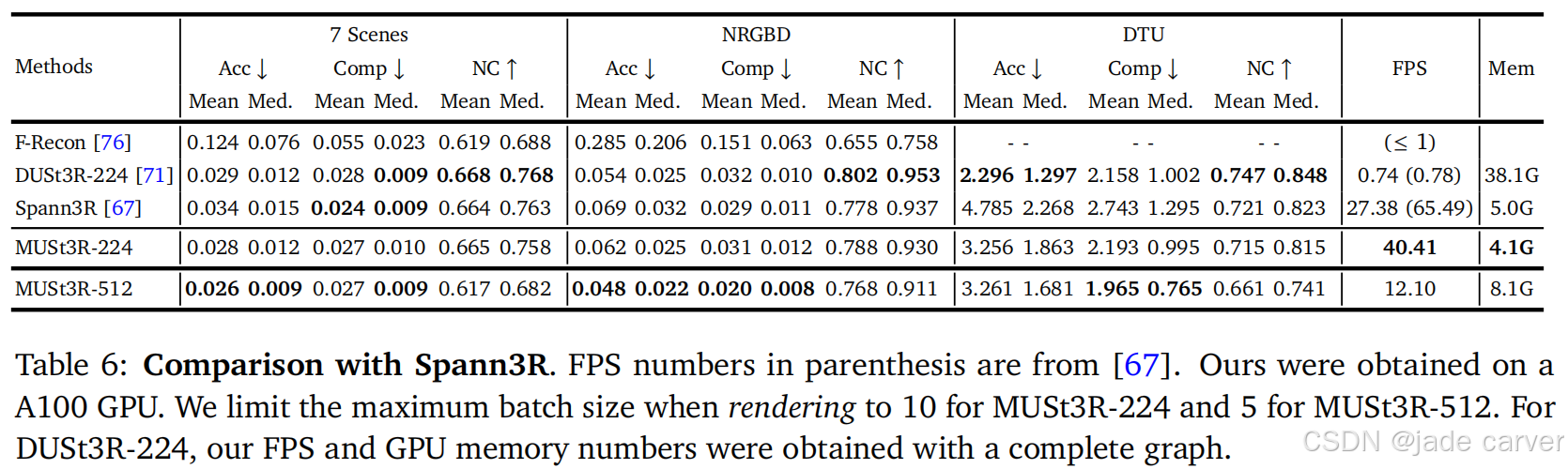
在 7Scenes、Neural RGBD 和 DTU 数据集上评估点图(pointmaps),采用与 Spann3R [67] 相同的协议。指标包括精度(Acc)、完整性(Comp) 和 法线一致性(NC),将预测的密集点图与反投影的逐点深度直接比较,排除无效点和背景点。对于 MUSt3R,使用所有图像更新记忆,然后渲染最终的点图。
性能表现
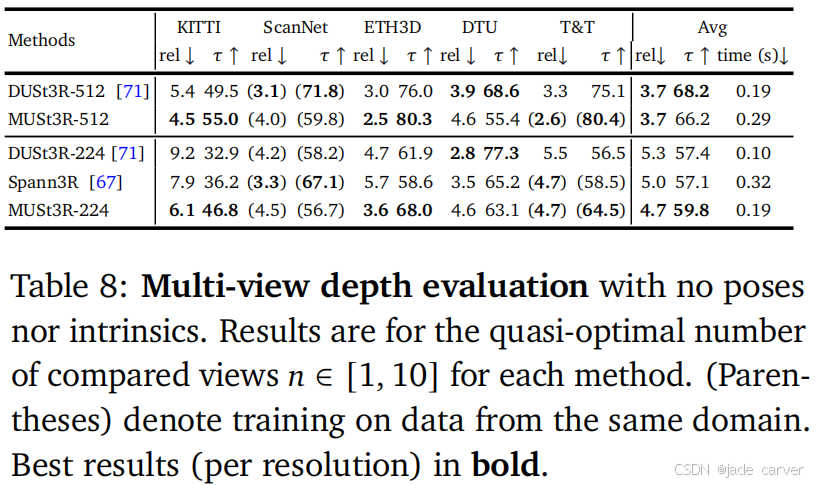
5.3. Multi-view depth evaluation
实验设置
在 KITTI、ScanNet、ETH3D、DTU 和 Tanks and Temples (T&T) 数据集上将 MUSt3R 与其他基于点图回归的方法进行对比,评估多视图立体深度估计性能。深度图直接取自局部点图 𝑋𝑖,𝑖 的 𝑧 坐标。评估指标包括:绝对相对误差(rel),内点率(𝜏),阈值为1.03。由于所有方法均未使用真实相机参数和姿态,预测结果需要通过中值归一化与真实值对齐。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 52
52 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)