大数据毕业设计:python租房系统 预测算法 协同过滤推荐算法 房源信息 可视化 机器学习-线性回归预测模型 Flask框架(源码+文档)✅
大数据毕业设计:python租房系统 预测算法 协同过滤推荐算法 房源信息 可视化 机器学习-线性回归预测模型 Flask框架(源码+文档)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Flask框架、Echarts可视化、HTML、MySQL数据库
房源推荐:协同过滤推荐算法、使用皮尔逊相关度计算公式、 pearson_recommend.py
房价预测:机器学习-线性回归预测模型
2、项目界面
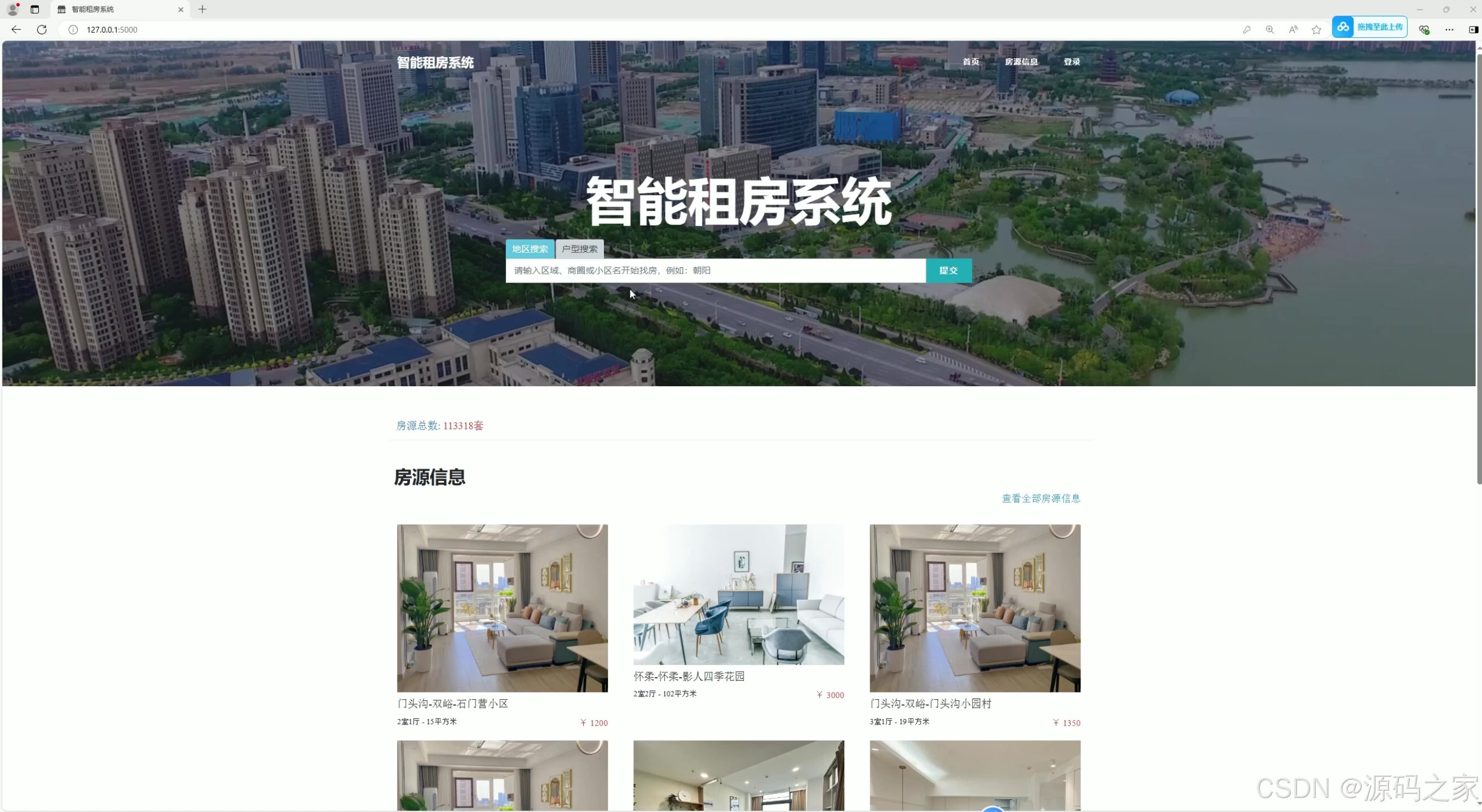
(1)系统首页—搜索功能、房源信息展示
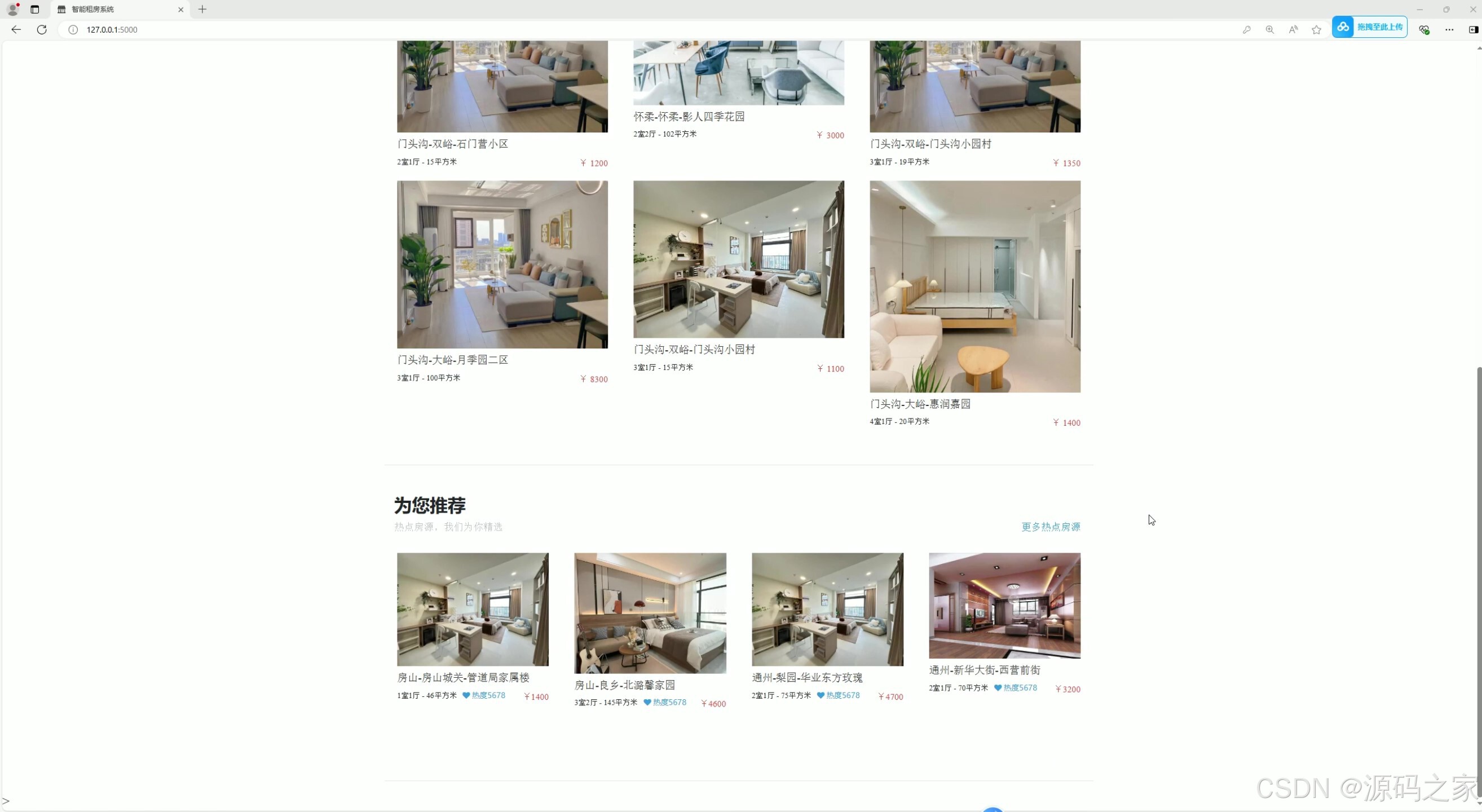
(2)房源推荐
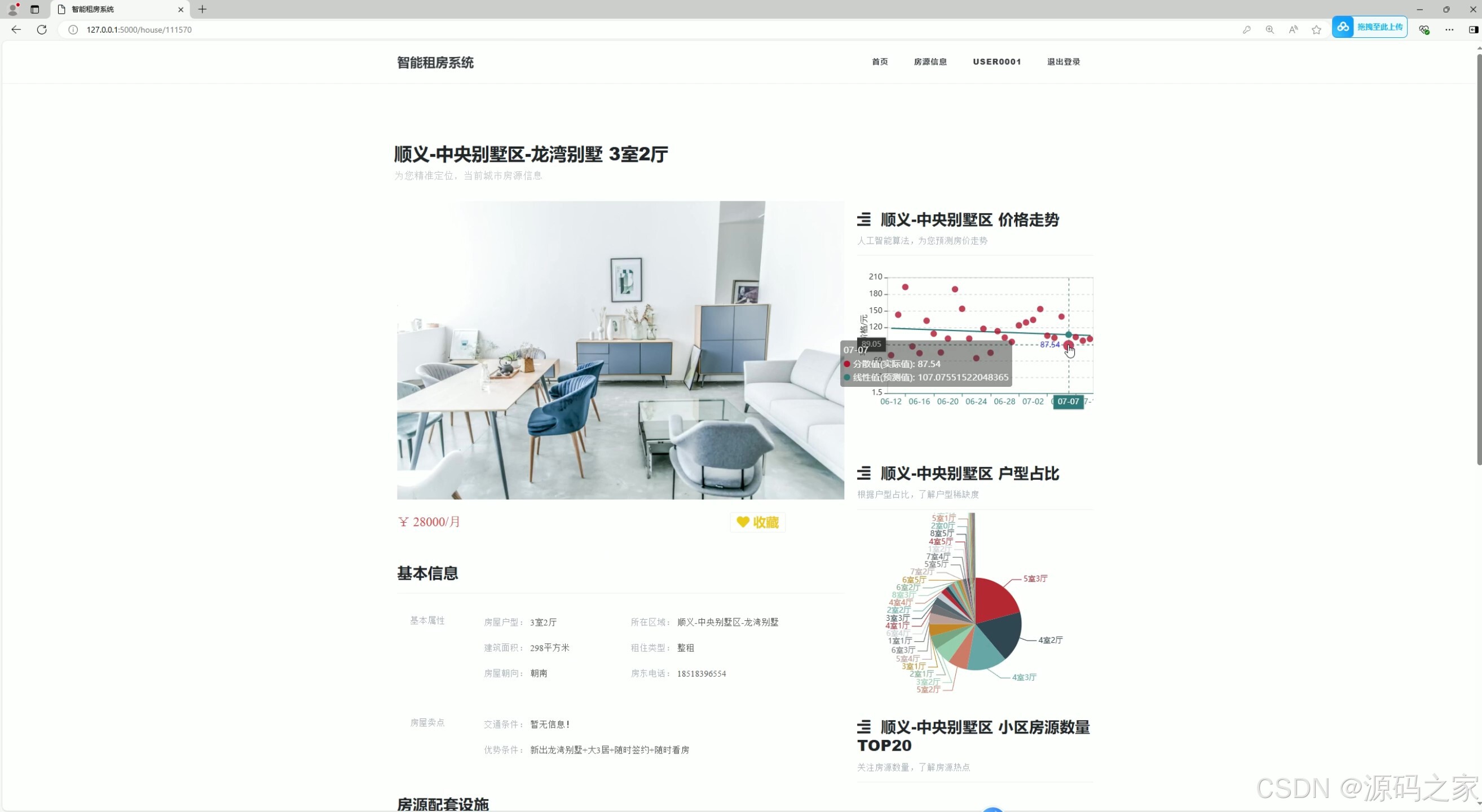
(3)房源详情页
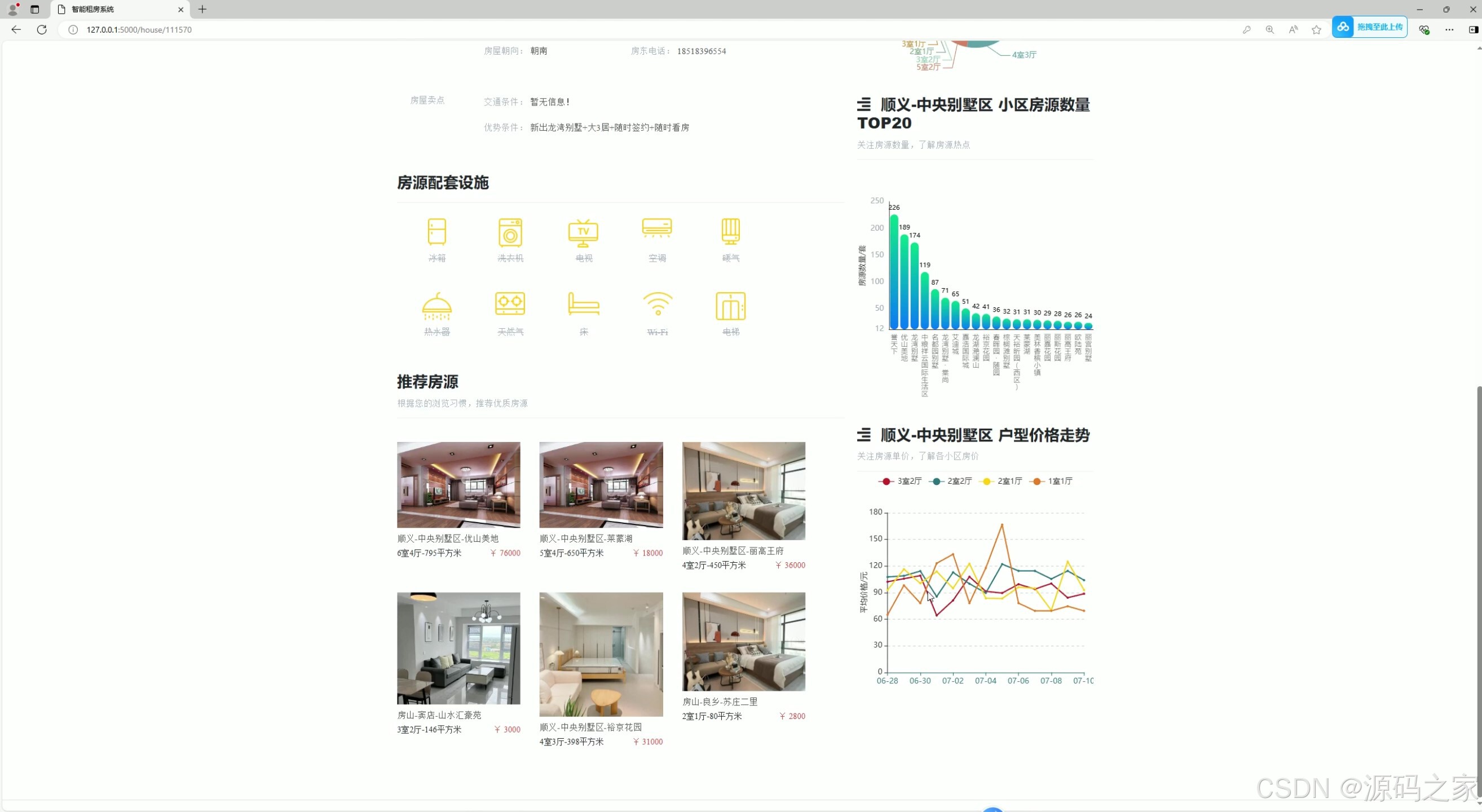
(4)房源详情页2–房源推荐
(5)房价预测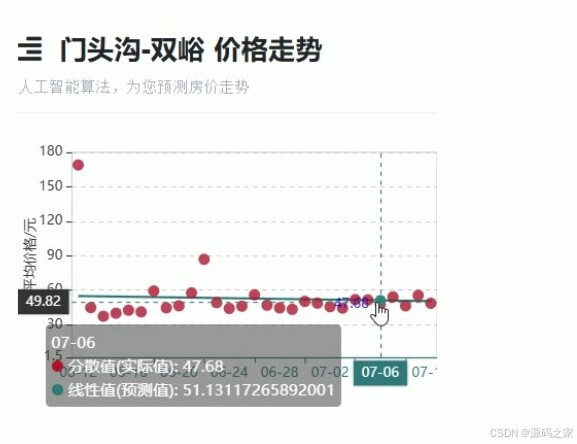
(6)查看全部房源列表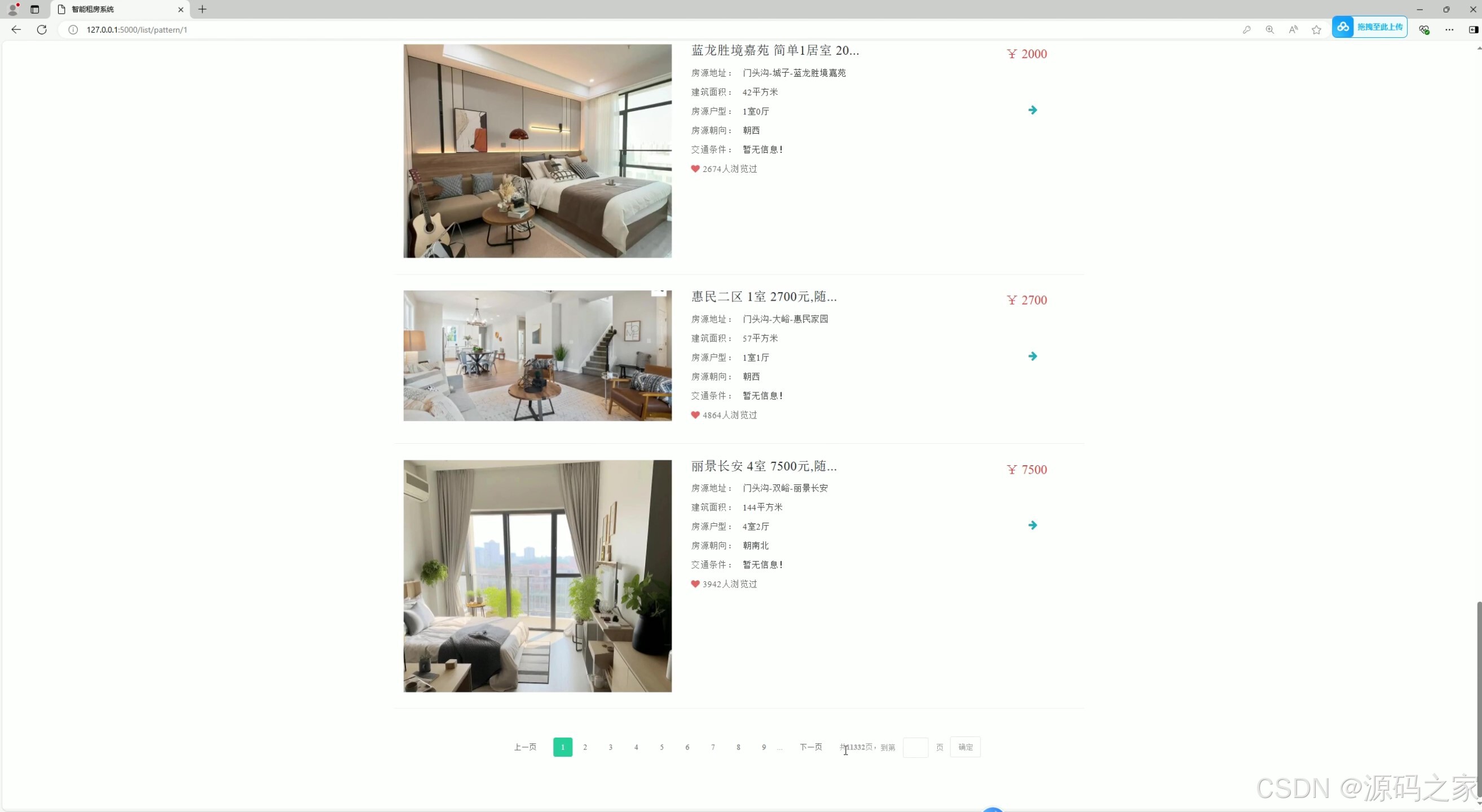
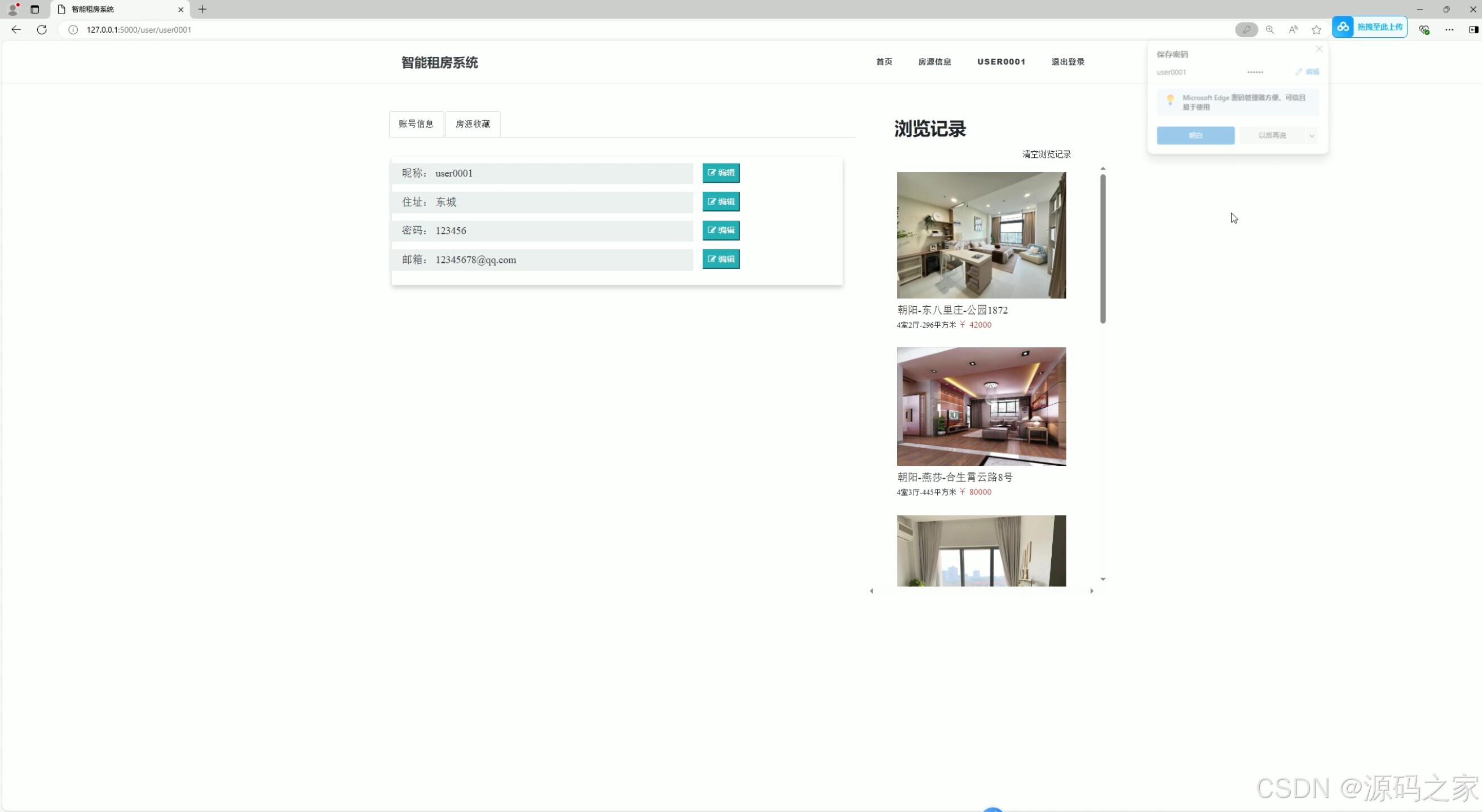
(7)个人中心
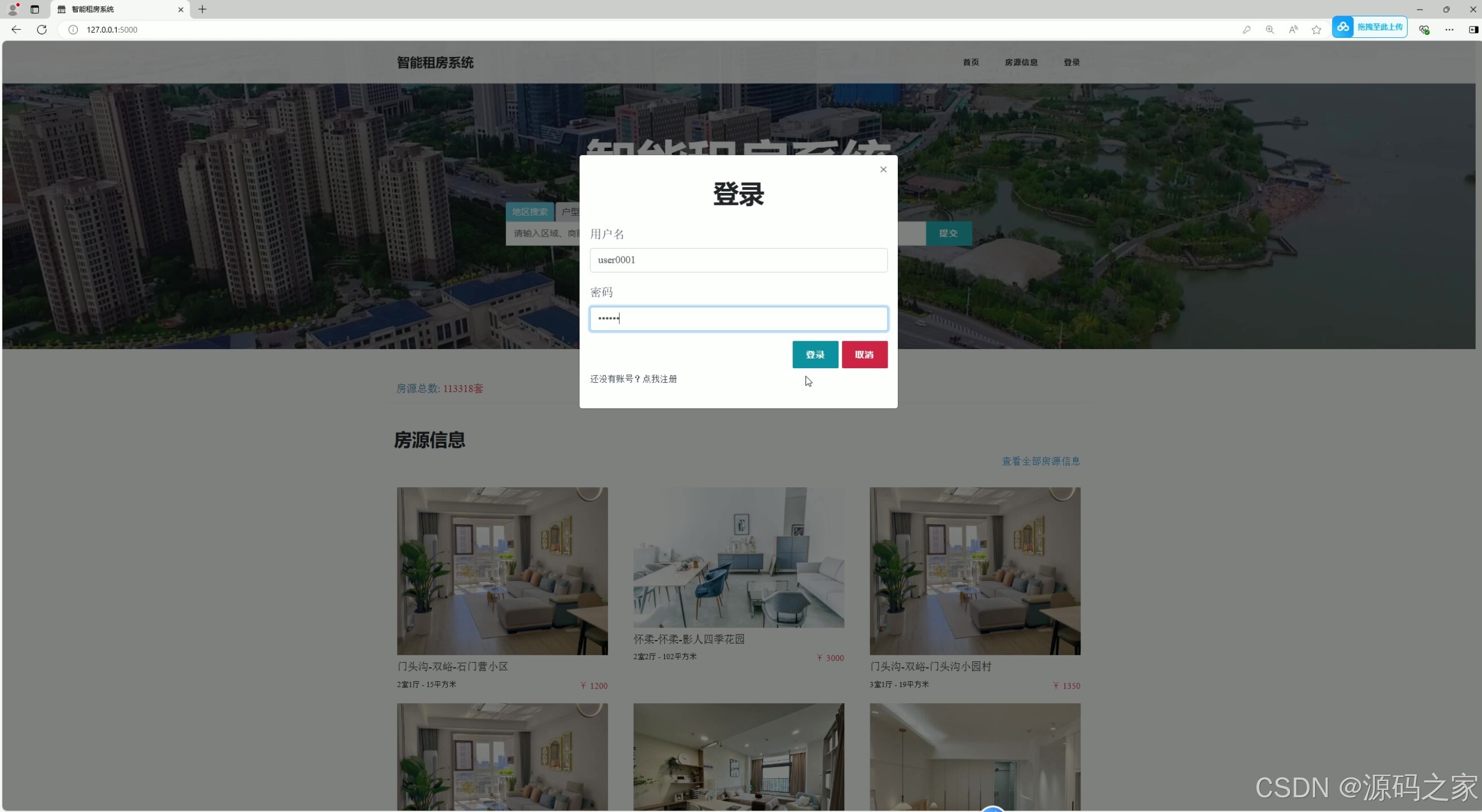
(8)注册登录
3、项目说明
技术栈:
Python语言、flask框架、Echarts可视化、HTML、MySQL数据库
房源推荐:协同过滤推荐算法、使用皮尔逊相关度计算公式、 pearson_recommend.py
房价预测:机器学习-线性回归预测模型 regression_data.py
1. 系统首页
- 功能:提供搜索功能,用户可以通过关键词搜索房源信息。
- 展示内容:展示房源列表,包括房源的基本信息(如图片、价格、位置等)。
- 核心作用:作为用户进入系统的入口,提供快速筛选和查找房源的功能。
2. 房源推荐
- 功能:基于协同过滤推荐算法,为用户推荐可能感兴趣的房源。
- 技术实现:使用皮尔逊相关度计算公式(
pearson_recommend.py)来评估用户之间的相似性,并根据相似用户的喜好进行推荐。 - 核心作用:提高用户体验,帮助用户发现潜在感兴趣的房源。
3. 房源详情页
- 功能:展示房源的详细信息,包括图片、价格、户型、配套设施等。
- 推荐功能:在详情页中嵌入相关房源推荐,进一步引导用户探索更多选项。
- 核心作用:为用户提供全面的房源信息,帮助用户做出决策。
4. 房价预测
- 功能:基于线性回归模型预测房价。
- 技术实现:使用机器学习中的线性回归算法(
regression_data.py),通过输入相关特征(如面积、位置等)来预测房价。 - 核心作用:为用户提供房价走势的参考,帮助用户评估购房成本。
5. 查看全部房源列表
- 功能:展示所有房源的列表,用户可以浏览所有房源信息。
- 核心作用:为用户提供全面的房源概览,方便用户进行对比和筛选。
6. 个人中心
- 功能:用户可以管理个人信息、查看收藏房源、历史浏览记录等。
- 核心作用:增强用户粘性,提供个性化的用户体验。
7. 注册登录
- 功能:用户可以通过注册账号或登录已有账号来使用系统。
- 核心作用:实现用户身份管理,保护用户数据和隐私。
8. 可视化展示
- 技术实现:使用 Echarts 进行数据可视化。
- 核心作用:通过图表展示房价走势、房源分布等信息,帮助用户更直观地理解数据。
4、核心代码
from sklearn.linear_model import LinearRegression
import numpy as np
# 基于线性回归模型预测功能
def linear_model_main(X_parameter, Y_paramter, predict_value):
# 1. 创建线性回归模型
regr = LinearRegression()
# 2. 训练线性回归模型
regr.fit(X_parameter, Y_paramter)
# 3. 预测新的样本
predict_value = np.array([predict_value]).reshape(-1, 1)
predict_outcome = regr.predict(predict_value)
# 4. 返回预测新值
return predict_outcome
if __name__ == '__main__':
# 广告费和销售额
x_data = [[4], [8], [9], [8], [7], [12], [6], [10], [6], [9], [10], [6]]
y_data = [9, 20, 22, 15, 17, 23, 18, 25, 10, 20, 20, 17]
# predict_value = 6 # 新样本值
predict_value = 8 # 新样本值
predict_outcome = linear_model_main(x_data, y_data, predict_value)[0]
print('预测结果:', predict_outcome)
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 32
32 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)