2025新风向聚类+Transformer创新结合!发A会根本不用愁!
聚类+Transformer”是一种结合聚类算法和Transformer架构的创新方法,近年来在多个领域取得了显著的研究进展和应用成果。我还整理出了相关的论文+开源代码,以下是精选部分论文更多论文料可以关注领取更多[论文+开源码】
“聚类+Transformer”是一种结合聚类算法和Transformer架构的创新方法,近年来在多个领域取得了显著的研究进展和应用成果。
我还整理出了相关的论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
标题:
Fast Transformers with Clustered Attention
具有聚类注意力的快速变换器
方法:
-
聚类注意力(Clustered Attention):提出了一种新的注意力机制,通过将查询(queries)分组到聚类中,并仅计算聚类中心的注意力,而不是为每个查询单独计算注意力。
-
局部敏感哈希(LSH)和K-Means:使用局部敏感哈希和K-Means进行快速聚类,以减少计算复杂度。
创新点:
-
线性复杂度:通过聚类查询,将注意力计算的复杂度从O(N²)降低到O(NC),其中C是聚类数量(C≪N),显著提高了处理长序列的效率。
-
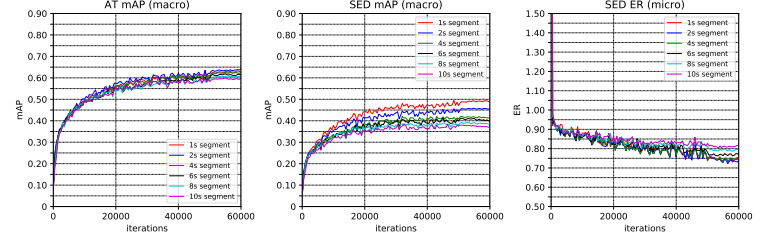
性能提升:在自动语音识别任务中,与标准Transformer相比,聚类注意力在相同的计算预算下表现更好,例如在Wall Street Journal数据集上,改进的聚类注意力(i-clustered)在验证集上的电话错误率(PER)比全注意力模型低约1.5%。
-
预训练模型的高效近似:能够以极低的性能损失近似预训练的BERT模型,仅使用25个聚类即可在GLUE和SQuAD基准测试中达到与全注意力模型相当的性能。
-
可扩展性:该方法不仅适用于训练新的模型,还可以加速预训练模型的推理,无需额外训练。
论文2
标题:
PaCa-ViT: Learning Patch-to-Cluster Attention in Vision Transformers
PaCa-ViT:学习视觉变换器中的Patch-to-Cluster注意力
方法:
-
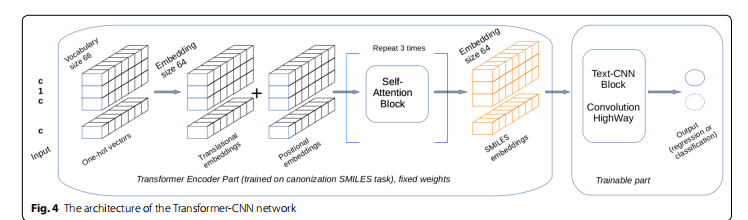
Patch-to-Cluster注意力(PaCa):提出了一种新的注意力机制,将图像块(patches)映射到聚类(clusters)上,将键(keys)和值(values)直接基于聚类计算,而不是基于块的嵌入。
-
端到端学习聚类:通过轻量级聚类模块学习聚类分配,将输入序列聚类为少量的“视觉令牌”(visual tokens),并用于计算注意力。
创新点:
-
线性复杂度:将注意力计算的复杂度从O(N²)降低到O(NM),其中M是聚类数量(M≪N),显著提高了计算效率。在MIT-ADE20k语义分割任务中,与PVT模型相比,PaCa-ViT的计算复杂度显著降低。
-
性能提升:在ImageNet-1k图像分类任务中,PaCa-ViT(Tiny、Small和Base)的Top-1准确率分别比PVTv2模型提高了2.2%、0.98%和0.76%。在MS-COCO目标检测任务中,PaCa-ViT(Small)的平均精度(AP)比PVTv2-B2模型提高了0.6%。
-
可解释性:通过可视化聚类热图,直接解释模型的行为,为理解视觉变换器提供了新的视角。
-
轻量级分割头:提出了一个轻量级的语义分割头网络,显著降低了模型复杂度,同时在MIT-ADE20k数据集上取得了更好的性能。
论文3
标题:
CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation
CMT-DeepLab:聚类掩码变换器用于泛视觉分割
方法:
-
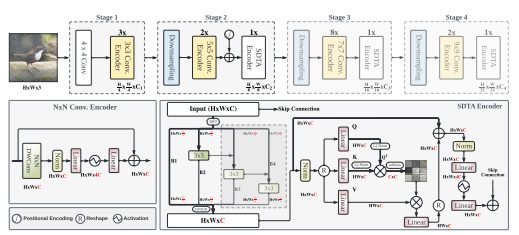
聚类掩码变换器(CMT):提出了一种基于聚类的变换器架构,将目标查询视为聚类中心,用于分割任务中的像素聚类。
-
交替聚类过程:通过交替的方式,首先根据特征亲和力将像素分配到聚类中,然后更新聚类中心和像素特征。
创新点:
-
密集注意力图:通过将目标查询视为聚类中心并引入聚类更新步骤,生成更密集的注意力图,显著提升了分割任务的效果(在COCO数据集上PQ提升了4.4%,达到55.7%)。
-
位置敏感聚类:通过动态位置编码和坐标卷积,将位置信息融入聚类过程,提升了模型对目标位置的感知能力(PQ提升了0.7%)。
-
频繁像素更新:通过在每个变换器解码器中更新像素特征,增强了像素与聚类中心之间的交互(PQ提升了1.3%)。
-
改进的解码器设计:通过增加更多的自注意力和交叉注意力模块,进一步提升了模型性能(PQ提升了0.9%)。
论文4
标题:
Not All Tokens Are Equal: Human-centric Visual Analysis via Token Clustering Transformer
并非所有标记都平等:通过标记聚类变换器进行以人为中心的视觉分析
方法:
-
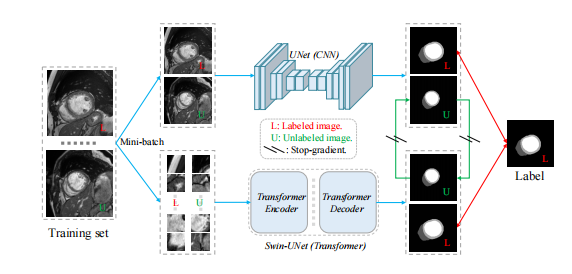
标记聚类变换器(TCFormer):提出了一种新的视觉变换器架构,通过逐步聚类的方式动态生成标记,标记可以来自不同位置,并具有灵活的形状和大小。
-
聚类标记合并(CTM)模块:通过基于密度峰值聚类算法对标记进行聚类,并通过加权平均合并同一聚类中的标记。
创新点:
-
动态标记生成:TCFormer能够根据图像内容动态调整标记的形状和大小,更好地聚焦于重要区域(如人体部位),在全身体姿态估计任务中,手部关键点的AP提升了6.2%)。
-
多阶段特征聚合:通过MTA头聚合多阶段的标记特征,有效保留了图像细节,提升了模型在细节捕捉任务中的性能(在3D人体网格重建任务中,MPJPE降低了1.4%)。
-
聚类标记合并:通过聚类算法合并标记,减少了标记数量,同时保留了关键信息,提升了计算效率(在WFLW数据集上,NME降低了0.32%)。
-
任务适应性:TCFormer能够根据任务需求调整标记分布,例如在人脸对齐任务中,为面部边缘区域分配更细的标记,提升了任务性能(在WFLW数据集上,NME达到了4.28%)。
更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 34
34 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)