用于自动驾驶的半监督视觉中心 3D 占用世界模型
25年2月来自清华大学的论文“Semi-supervised Vision-centric 3d Occupancy World Model For Autonomous Driving”。了解世界动态对于自动驾驶规划至关重要。最近的方法试图通过学习 3D 占用世界模型来实现这一点,该模型基于当前观察预测未来的周围场景。然而,3D 占用标签仍然需要产生有希望的结果。考虑到 3D 户外场景的注释成本
25年2月来自清华大学的论文“Semi-supervised Vision-centric 3d Occupancy World Model For Autonomous Driving”。
了解世界动态对于自动驾驶规划至关重要。最近的方法试图通过学习 3D 占用世界模型来实现这一点,该模型基于当前观察预测未来的周围场景。然而,3D 占用标签仍然需要产生有希望的结果。考虑到 3D 户外场景的注释成本很高,本文提出一个半监督的以视觉为中心 3D 占用世界模型 PreWorld,通过一种两阶段训练范式来利用 2D 标签的潜力:自监督的预训练阶段和全监督的微调阶段。具体而言,在预训练阶段,利用属性投影头生成场景的不同属性字段(例如 RGB、密度、语义),从而通过体渲染技术从 2D 标签实现时间监督。此外,引入一个简单但有效的状态条件预测模块,以直接的方式递归地预测未来的占用和自车轨迹。
3D 场景理解是自动驾驶的基石,对规划和导航等下游任务产生直接影响。在各种 3D 场景理解任务中(Wang et al., 2022; Li et al., 2022a; Wei et al., 2023; Jin et al., 2024),3D 占用预测在自动驾驶系统中起着至关重要的作用。其目标是从有限的观察中预测整个场景中每个体素语义占用情况。为此,一些先前的方法(Liong et al., 2020; Cheng et al., 2021; Xia et al., 2023)优先考虑激光雷达作为输入模态,因为它在捕获精确几何信息方面具有强大的性能。然而,它们通常被认为硬件成本高昂。因此,近年来,人们开始转向以视觉为中心的解决方案(Zhang,2023c;Li,2023a;Zheng,2024)。
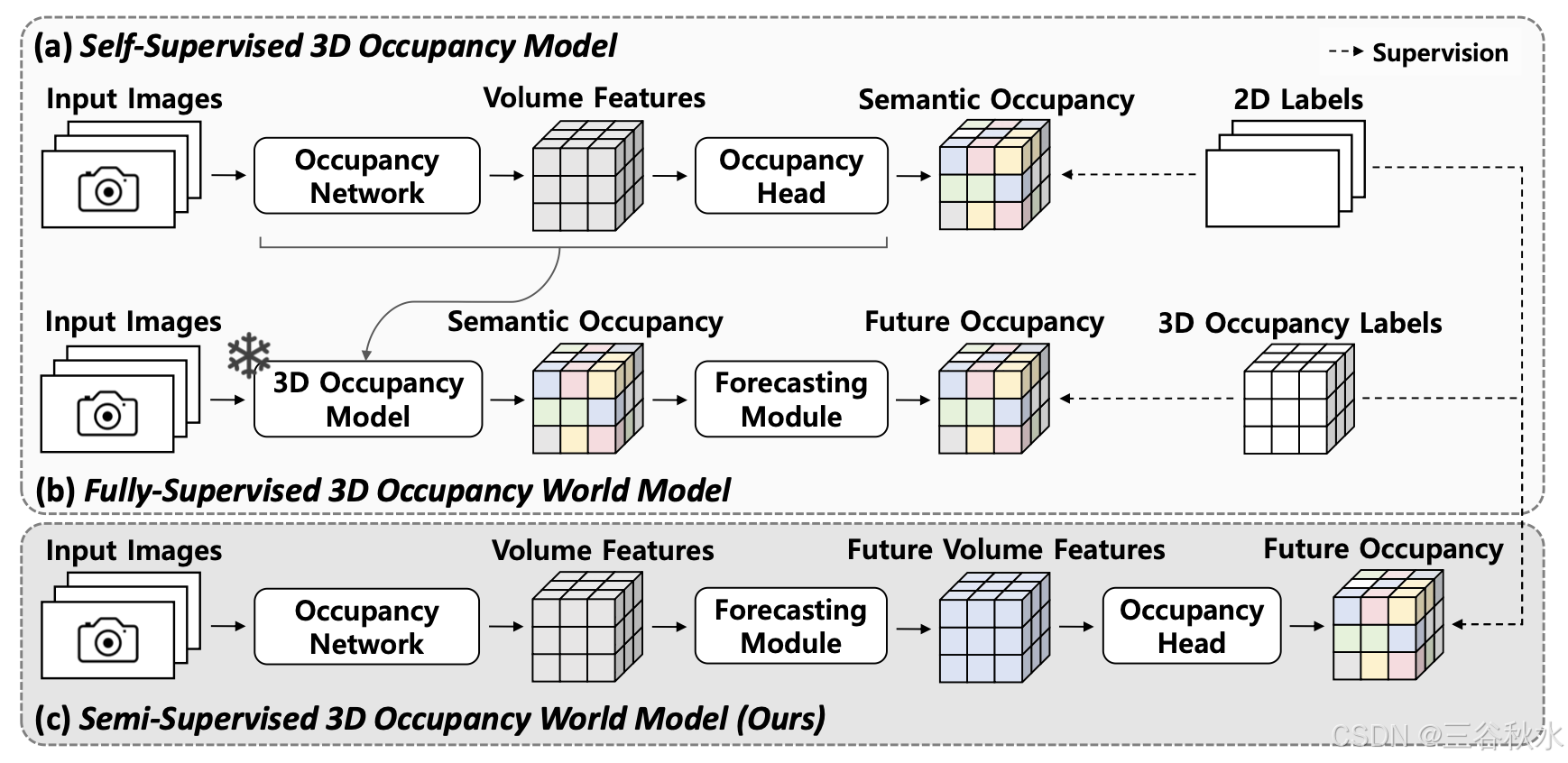
尽管上述方法取得了重大进展,但它们主要侧重于增强对当前场景的更好感知。对于防撞和路线规划,自动驾驶汽车不仅需要理解当前场景,还需要基于对世界动态的理解来预测未来场景的演变。因此,引入 4D 占用预测,根据历史观察结果预测未来的 3D 占用。最近的研究旨在通过学习 3D 占用世界模型来实现这一目标(Zheng,2023;Wei,2024)。然而,在处理图像输入时,这些方法遵循一条迂回的路径,如图 (b) 所示。通常,会使用预训练好的 3D 占用模型来获取当前占用,然后将其输入到预测模块以生成未来占用。预测模块包括将占用编码为离散 token 的 token 生成器、生成未来 token 的自回归架构以及获取未来占用的解码器。在这种重复的编码和解码过程中,很容易发生信息丢失。因此,现有方法严重依赖 3D 占用标签作为监督来产生有意义的结果,从而带来显著的注释成本。
与 3D 占用标签相比,2D 标签相对容易获取。最近,使用纯 2D 标签进行自监督学习在 3D 占用预测任务中显示出一些有希望的结果,如图 (a) 所示。通过利用体渲染,RenderOcc (Pan et al., 2024) 使用 2D 深度图和语义标签来训练模型。 SelfOcc(Huang et al.,2024)和 OccNerf(Zhang et al.,2023a)等方法更进一步,仅使用图像序列作为监督。然而,在 4D 占用预测任务中尚未有类似的尝试。
本文提出的 PreWorld 是一个半监督以视觉为中心的 3D 占用世界模型,旨在满足训练期间 2D 标签的效用,同时在 3D 占用预测和 4D 占用预测任务中实现具有竞争力的性能,如图 © 所示。
对于在时间戳 T 的车辆,以视觉为中心的 3D 占用预测任务以 N 个图像视图 S_T = {I1, I2, …, I^N } 作为输入,并预测当前 3D 占用 Yˆ_T 作为输出,其中 (X, Y, Z) 表示 3D 体的分辨率,C 表示语义类别的数量,包括未占用 (Huang et al., 2023; Zhang et al., 2023c; Liu et al., 2023; Pan et al., 2024)。一个 3D 占用模型 O 通常包括占用网络 N 和占用头 H。
以视觉为中心的 4D 占用预测任务,则利用过去 k 帧的图像序列 {S_T, S_T−1, …, S_T−k} 作为输入,旨在预测未来 f 帧的 3D 占用 (Zheng et al., 2023; Wei et al., 2024)。
3D 占用世界模型 W 尝试采用自回归方式来实现这一点。W 使用可用的 3D 占用模型 O 来预测过去 k 帧的 3D 占用{Yˆ_T,…,Yˆ_T−k},并利用场景token化器 T、自回归架构 A 和解码器 D 来预测未来的 3D 占用。在获得历史占用后,W 通过 T 将 3D 占用编码为离散 tokens {z_T,…,z_T−k} 。随后,利用 A 根据这些 tokens 预测未来 token z_T +1,然后将其输入到 D 以生成未来占用 Yˆ_T +1。
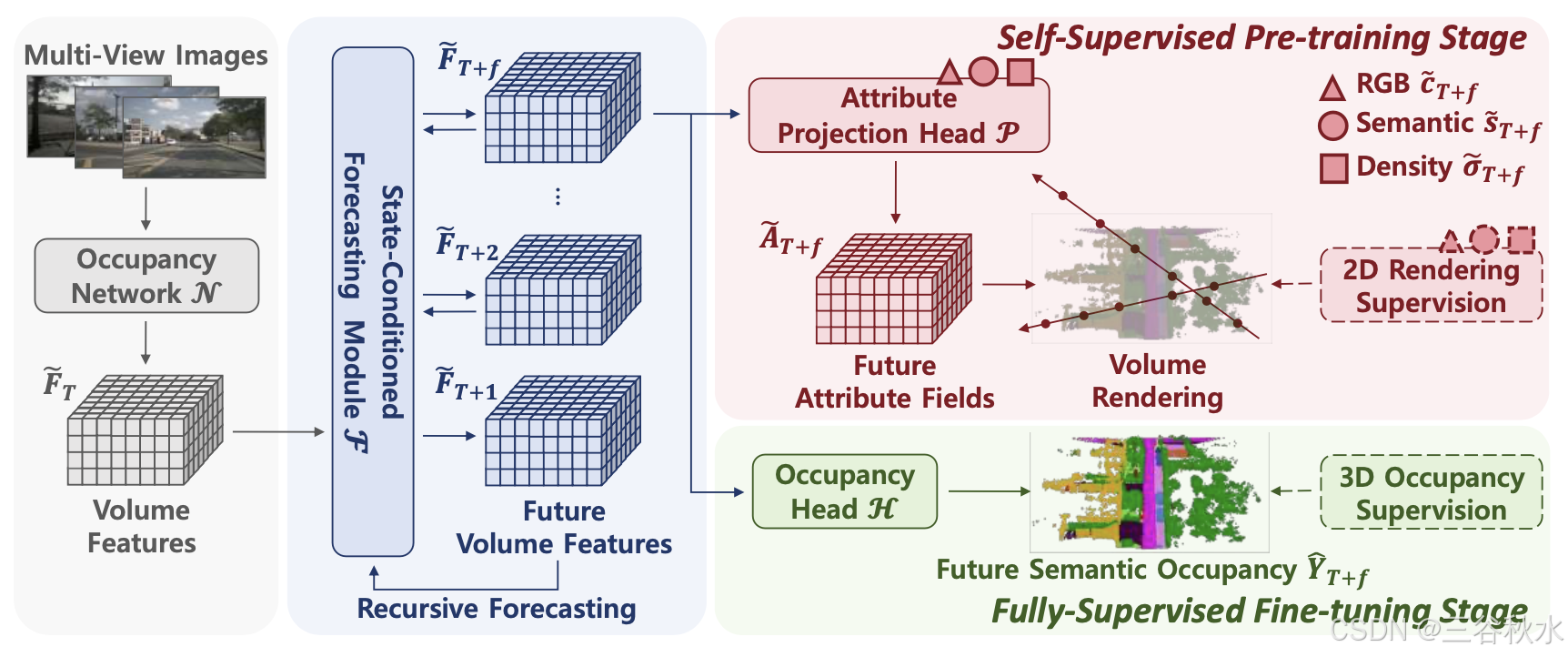
PreWorld 的架构如下图所示:首先,利用占用网络从多视角图像中提取体特征。随后,使用状态条件预测模块利用历史特征递归预测未来的体特征。在自监督预训练阶段,体特征通过体渲染技术投影到各个属性字段中,并由 2D 标签监督。在全监督微调阶段,属性投影头不再参与计算,占用预测直接通过占用头获得,并由 3D 占用标签监督。
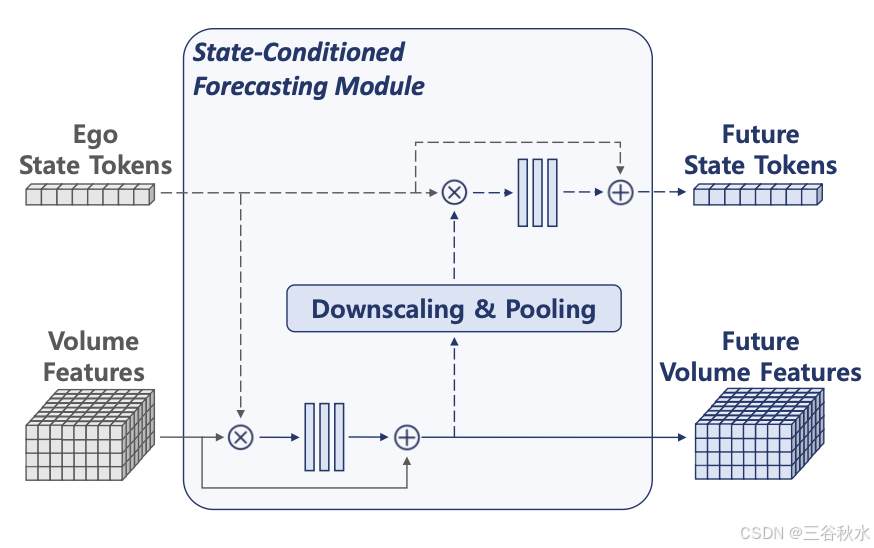
状态条件预测模块如图所示:仅由两个 MLP 组成,自车状态可以选择性地集成到网络中,如虚线箭头所示。
受到 Pan et al. (2024) 的启发,通过属性投影头 P 将当前和未来 f 帧的时间体特征序列 {F ̃}_t = {F ̃_T , F ̃_T +1, …, F ̃_T +f } 转换为时间属性场 {A ̃}_t,包括3D 体的密度、语义和 RGB 字段。
给定摄像机 j 在时间戳 i 的内和外参,可以提取一组 3D 射线 {r}_ij,其中每条射线 r 都来自摄像机 j,对应于图像 I_i^j 的一个像素。此外,可以利用自车姿势矩阵将射线从相邻的 n 帧转换为当前帧,从而更好地捕捉周围信息。这些射线共同构成用于监督 A ̃_i = (σ ̃_i, s ̃_i, c ̃_i) 的集合 {r}_i。
对于每个 r ∈ {r}_i,沿射线采样 M 个点 {u_m}。然后可以计算每个采样点 u_m 的渲染权重 w(u_m)。最后,可以通过累计求和射线上每个点对应的值与其各自渲染权重的乘积来计算 2D 渲染深度、语义和 RGB 预测。
在用 3D 射线集 {r}_i 获得渲染的2D预测之后,计算时域 2D 渲染损失用于训练。
PreWorld 的训练方案包括两个阶段:在自监督的预训练阶段,使用属性投影头 P 来实现对 2D 标签的时间监督。这种方法能够利用丰富且易于获得的 2D 标签,同时预先优化占用网络 N 和预测模块 F。在随后的微调阶段,利用占用头 H 来产生占用结果,并使用 3D 占用标签进行进一步优化。
对于预训练阶段,采用时间 2D 渲染损失 L_2D。具体而言,分别利用 Pan (2024) 的 SILog 损失和交叉熵损失作为 L_dep 和 L_sem,并使用 L1 损失作为 L_RGB。对于微调阶段,遵循 Li (2023c) 的做法,采用 focal loss L_f 、 lovasz-softmax loss L_l 和场景-类别亲和力损失 L_scalsem 和 L_scal^geo。
对这三个任务使用相同的网络架构,但对于非时间的 3D 占用预测任务,相应地省略时间监督和损失。采用 BEVStereo (Li et al., 2023b) 作为占用网络 N,仅将其检测头替换为 FB-OCC Li et al. (2023c) 中的占用头 H 以进行占用预测。对于训练,将批量大小设置为 16,使用 Adam 作为优化器,并以 1×10−4 的学习率进行训练。损失函数中的所有超参数 λ 均设置为 1.0。对于 3D 占用预测任务,PreWorld 在自监督的预训练阶段经历 6 个 epoch,在全监督的微调阶段经历 12 个 epoch。对于 4D 占用预测和运动规划任务,PreWorld 在自监督预训练阶段经历 8 个 epoch,在全监督微调阶段经历 18 个 epoch。所有实验均在 8 个 NVIDIA A100 GPU 上进行。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 46
46 0
0- 0



 已为社区贡献103条内容
已为社区贡献103条内容

所有评论(0)