【CVPR 2024】状态空间对偶+多阶段状态融合+高效视觉Mamba模块
本文提出了一种新型的视觉架构Efficient Vision Mamba (EfficientViM),它基于隐藏状态混合器的状态空间对偶性(HSM-SSD),能够以更低的计算成本高效捕捉全局依赖关系。通过重新设计SSD层,将通道混合操作置于隐藏状态中,并引入多阶段隐藏状态融合,进一步增强了隐藏状态的表示能力。实验结果表明,EfficientViM在ImageNet-1k数据集上实现了新的速度-精
-
文章标题: EfficientViM: Efficient Vision Mamba with Hidden State Mixer-based State Space Duality
-
论文地址:https://arxiv.org/pdf/2411.15241
-
代码地址:https://github.com/mlvlab/EfficientViM/blob/main/classification/models/EfficientViM.py
本文介绍了一种名为EfficientViM的新型视觉架构,该架构基于隐藏状态混合器(Hidden State Mixer)和状态空间对偶性(State Space Duality, SSD),旨在资源受限环境下高效捕获全局依赖性,同时降低计算成本。
摘要
本文提出了一种新型的视觉架构Efficient Vision Mamba (EfficientViM),它基于隐藏状态混合器的状态空间对偶性(HSM-SSD),能够以更低的计算成本高效捕捉全局依赖关系。通过重新设计SSD层,将通道混合操作置于隐藏状态中,并引入多阶段隐藏状态融合,进一步增强了隐藏状态的表示能力。实验结果表明,EfficientViM在ImageNet-1k数据集上实现了新的速度-精度权衡,在高分辨率图像和知识蒸馏训练时也表现出显著的性能提升。
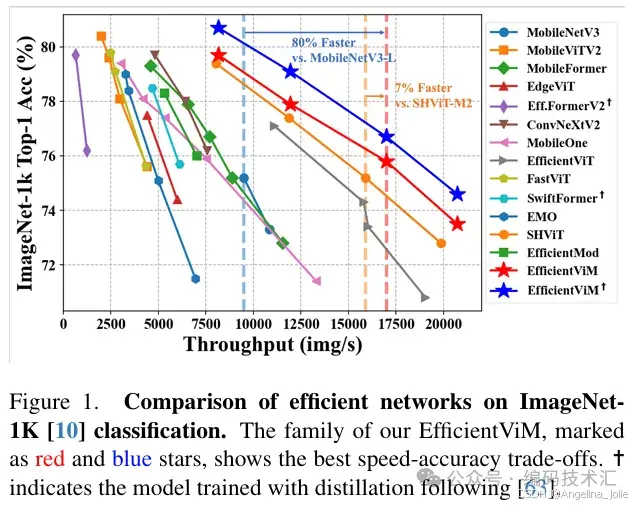
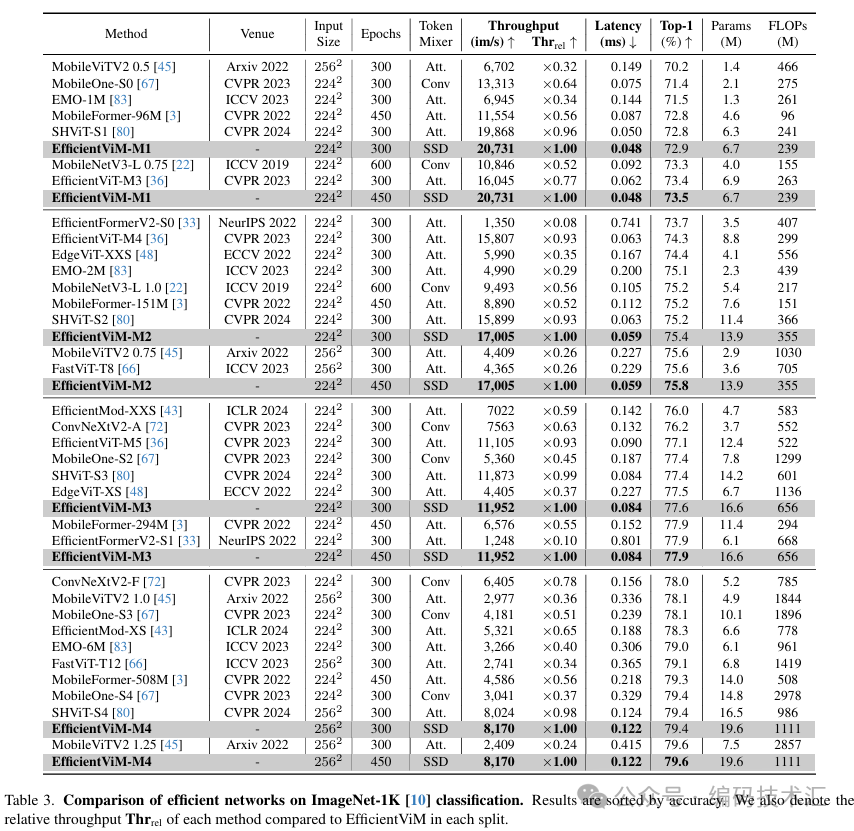
ImageNet-1K 分类上各类模型的比较
1. 引言
在资源受限的环境中部署神经网络一直是计算机视觉领域的重要研究方向。早期的工作主要集中在构建轻量级的卷积神经网络(CNN),如MobileNet等。随着视觉Transformer(ViT)的出现,注意力机制成为捕捉图像块中长程依赖的关键操作,但其计算复杂度较高。近年来,状态空间模型(SSM)作为一种有效的全局标记交互方法,以其线性计算成本受到关注。然而,基于SSM的视觉架构的研究相对较少。本文提出了一种新的基于HSM-SSD的视觉架构EfficientViM,通过优化SSD层的设计,降低了计算成本,提高了模型的效率和性能。
2. 方法
2.1 隐藏状态混合器的状态空间对偶性(HSM-SSD)
HSM-SSD层重新设计了之前的SSD层,将通道混合操作从图像特征空间转移到隐藏状态空间。通过这种方式,HSM-SSD层能够以更低的计算成本捕捉全局上下文。具体来说,HSM-SSD层首先通过线性投影和门控函数生成共享的全局隐藏状态,然后通过投影生成每个输入的输出。这种设计将主要的计算成本从线性投影转移到隐藏状态的计算上,从而降低了整体的计算复杂度。
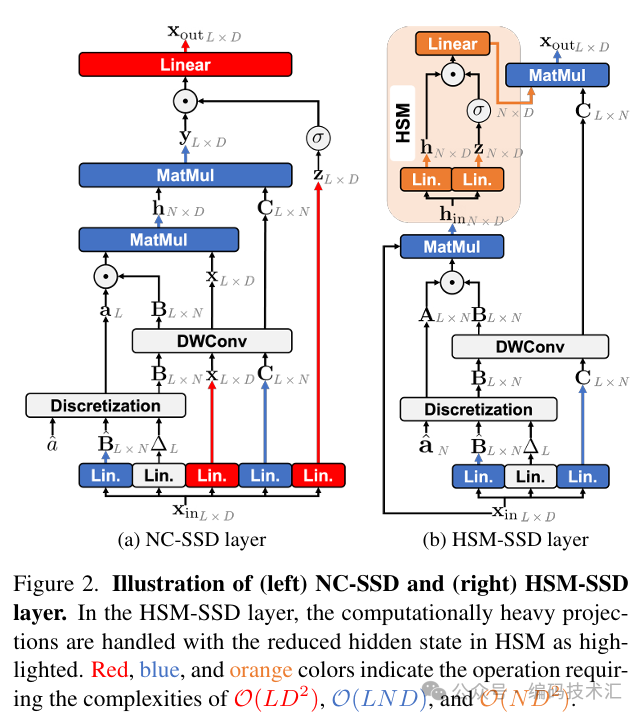
2.2 多阶段隐藏状态融合
为了进一步提高模型的性能,本文引入了多阶段隐藏状态融合(MSF)机制。MSF通过结合不同阶段的隐藏状态,生成模型预测。具体来说,对于每个阶段的隐藏状态,计算其全局表示,然后通过归一化和投影生成对应的logits。最终的logit是所有阶段logits的加权和。这种设计不仅增强了隐藏状态的表示能力,还通过整合低级和高级特征提高了模型的泛化能力。
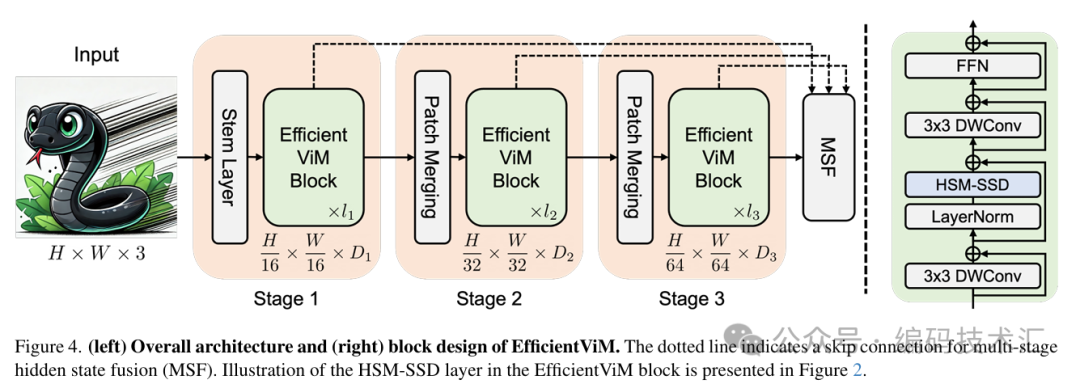
2.3 EfficientViM架构
EfficientViM的整体架构如图4所示。每个块由HSM-SSD层和前馈网络(FFN)组成,以促进全局信息聚合和通道交互。FFN层由两个连续的1×1卷积层组成,具有4倍的扩展比。为了捕捉局部上下文,还在HSM-SSD和FFN层之前加入了3×3的深度可分离卷积(DWConv)层。每个层都结合了残差连接和层归一化(LN),以提高数值稳定性。
3. 实验
3.1 图像分类
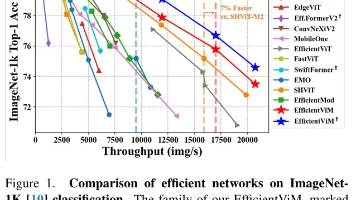
在ImageNet-1K数据集上进行了实验,比较了EfficientViM与其他高效视觉骨干网络的性能。结果表明,EfficientViM在速度和精度上均优于所有先前的工作。例如,EfficientViM-M1在300个epoch训练后,与MobileNetV3-L 0.75和EfficientViT-M3相比,实现了约90%和30%的速度提升。EfficientViM-M2在300个epoch训练后,与MobileViT-V2 0.75和FastViT-T8相比,实现了约4倍的速度提升和0.2%的性能提升。EfficientViM-M3和M4在吞吐量和精度上均优于所有先前的工作。
3.2 可扩展性
3.2.1 高分辨率图像
在3842和5122分辨率下进行了微调实验。结果表明,EfficientViM在高分辨率图像上具有竞争力,与SHViT相比,吞吐量差距更大,速度提升超过15%。在极高分辨率图像上,EfficientViM显示出明显的优势,与SHViT、EMO和MobileOne相比,速度分别提高了约3倍、4倍和7倍。
3.2.2 知识蒸馏
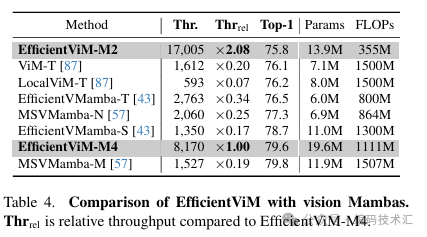
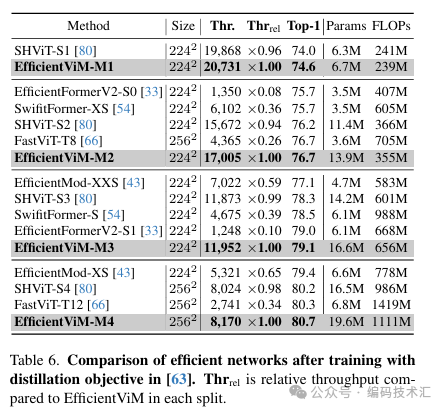
使用RegNetY-160作为教师模型,对EfficientViM进行了知识蒸馏训练。结果表明,知识蒸馏对EfficientViM有效,与FastViT-T8&T12相比,EfficientViM-M2&M4的吞吐量提高了3倍以上,性能相当甚至更好。经过知识蒸馏训练后,EfficientViM仍然在速度-精度权衡上优于所有其他模型。
3.3 分析和消融研究
3.2.1 内存效率
分析了不同网络的峰值内存使用情况。尽管EfficientViM的参数数量较高,但在内存使用上具有竞争力,同时实现了最高的吞吐量。例如,EfficientViM的峰值内存使用量仅为EMO、MobileNetV3和FastViT等模型的约1/3。
3.3.2 消融研究
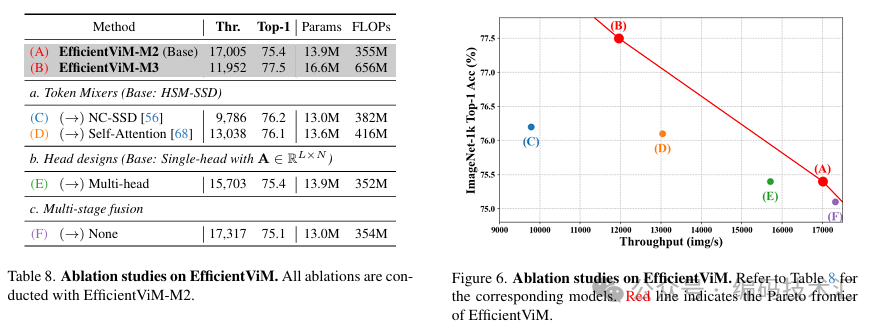
对EfficientViM的不同组件进行了消融研究。结果表明,HSM-SSD在速度-精度权衡上优于NC-SSD和自注意力机制。单头设计显著提高了速度,而不会降低性能。多阶段隐藏状态融合在类似吞吐量下提高了准确性。
4. 结论
本文提出了一种新的基于HSM-SSD的视觉架构EfficientViM。HSM-SSD层通过重新设计SSD层,将通道混合操作置于隐藏状态中,降低了计算成本。多阶段隐藏状态融合机制进一步增强了隐藏状态的表示能力。实验结果表明,EfficientViM在速度-精度权衡上优于所有先前的模型,并且在高分辨率图像和知识蒸馏训练时也表现出显著的性能提升。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 22
22 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)