基于Pycharm的YOLOv8杂草视觉检测3——X-AnyLabeling半自动标注工具操作指南!
最近采集了不少杂草,需要用到图片标注工具制作自己的数据集,但手工标定费时费力还费钱。是一款基于AnyLabeling二次开发的智能图像标注工具,专为计算机视觉任务设计。支持YOLO系列(v5/v7/v8/v9)、COCO、VOC等多种格式,集成SAM等先进模型实现智能预标注,标注效率提升300%+。本文主要介绍该工具的安装、杂草数据集制作、YOLOV8S模型训练中的步骤。
最近采集了不少杂草,需要用到图片标注工具制作自己的数据集,但手工标定费时费力还费钱。X-AnyLabeling 是一款基于AnyLabeling二次开发的智能图像标注工具,专为计算机视觉任务设计。支持YOLO系列(v5/v7/v8/v9)、COCO、VOC等多种格式,集成SAM等先进模型实现智能预标注,标注效率提升300%+。本文主要介绍该工具的安装、杂草数据集制作、YOLOV8S模型训练中的步骤。
一、操作系统环境
windows11、i5-13900K、RTX4070 Ultra
CUDA 12.4、Python3.9、MiniConda3 24.5.0、Pycharm Community 2022
二、使用步骤
安装 X-AnyLabeling 标注工具(只针对windows系统)
X-AnyLabeling支持多平台运行,提供预编译的安装包和源码两种方式:
【方式 1】 从源码安装:提供更完整的功能,性能更稳定,更新维护更及时。
【方式 2】 从GUI运行:官方 GitHub Releases直接提供了CPU版.exe程序,一键启动点开即用,缺点是暂不支持调用GPU加速推理。
(1) 源码安装
安装前请确保系统中:
- 已安装3.8以上版本的Python
- Anaconda或者Miniconda虚拟环境配置工具
- 如需要用到NVIDIA GPU加速,则需事先安装好版本相互匹配的CUDA、cuDNN
以上工具安装和环境配置,可以参考我前面写的的一篇:基于Pycharm的YOLOv8杂草视觉检测1——运行环境配置+杂草识别示例_pycharm yolov8-CSDN博客
1: 创建Conda虚拟环境
打开Anaconda Prompt终端,默认进入base环境:
# 创建一个名为“x-anylabeling”的虚拟环境,并指定了Python版本为3.9
conda create --name X-Anylabeling python=3.9 -y
# 激活虚拟环境
conda activate X-Anylabeling
2: 配置 PyCharm 环境
新建一个项目,并且将项目的python解释器定位到刚刚创建的Conda虚拟环境(软件包可以忽略不计,这是安装完成后截图的)
3: 安装 ONNX Runtime
在Conda Prompt终端激活的x-anylabeling环境中,或者PyCharm终端工具中进行安装GPU版本。
# Install ONNX Runtime GPU(指定某个x.x.x版本安装)
pip install onnxruntime-gpu==1.18.1
# 例如以下,顺便这里指定了清华镜像站的下载源来提速
pip install onnxruntime-gpu==1.18.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
4: 克隆仓库代码
git clone https://github.com/CVHub520/X-AnyLabeling.git
5: 安装环境依赖
X-AnyLabeling的顺利运行需要很多的依赖选项,就比如上个图片中的软件包。这么多文件包我们也记不全,还好前面克隆下来的项目文件夹根目录下的 requirement.txt 文件提供了所需依赖库的名称与版本,我们直接为己所用:
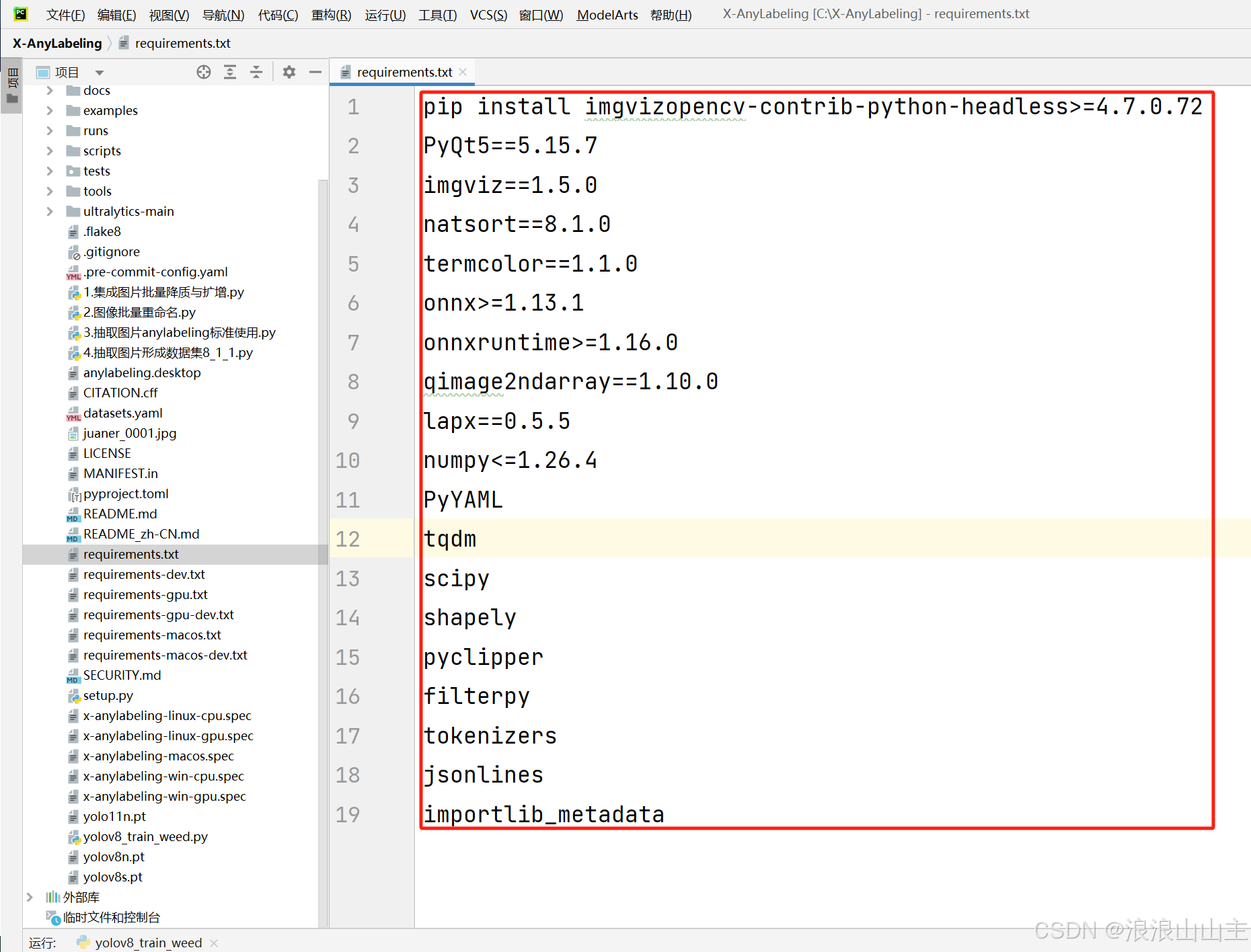
# 进入仓库项目文件夹
cd X-AnyLabeling
# 命令格式参考如下
pip install -r requirements-[xxx].txt
# 例如我这里选择安装适用于GPU且支持再编译的
pip install -r requirements-gpu-dev.txt
# 同样如果遇到网络问题,可以尝试指定下载源
pip install -r requirements-gpu-dev.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
完成以上必要步骤后,使用以下命令生成资源:
pyrcc5 -o anylabeling/resources/resources.py anylabeling/resources/resources.qrc
为避免冲突,请执行以下命令卸载第三方相关包:
pip uninstall anylabeling -y
设置环境变量:(特别注意,这里不是直接复制,要改成你刚刚从git拉取下来的项目文件目录)
# Linux 或 macOS
export PYTHONPATH=/path/to/X-AnyLabeling
# Windows
set PYTHONPATH=C:\path\to\X-AnyLabeling
# 例如这里我改成我的项目文件夹中的X-AnyLabeling目录所在路径
set PYTHONPATH=E:\mycode\X-AnyLabeling\X-AnyLabeling
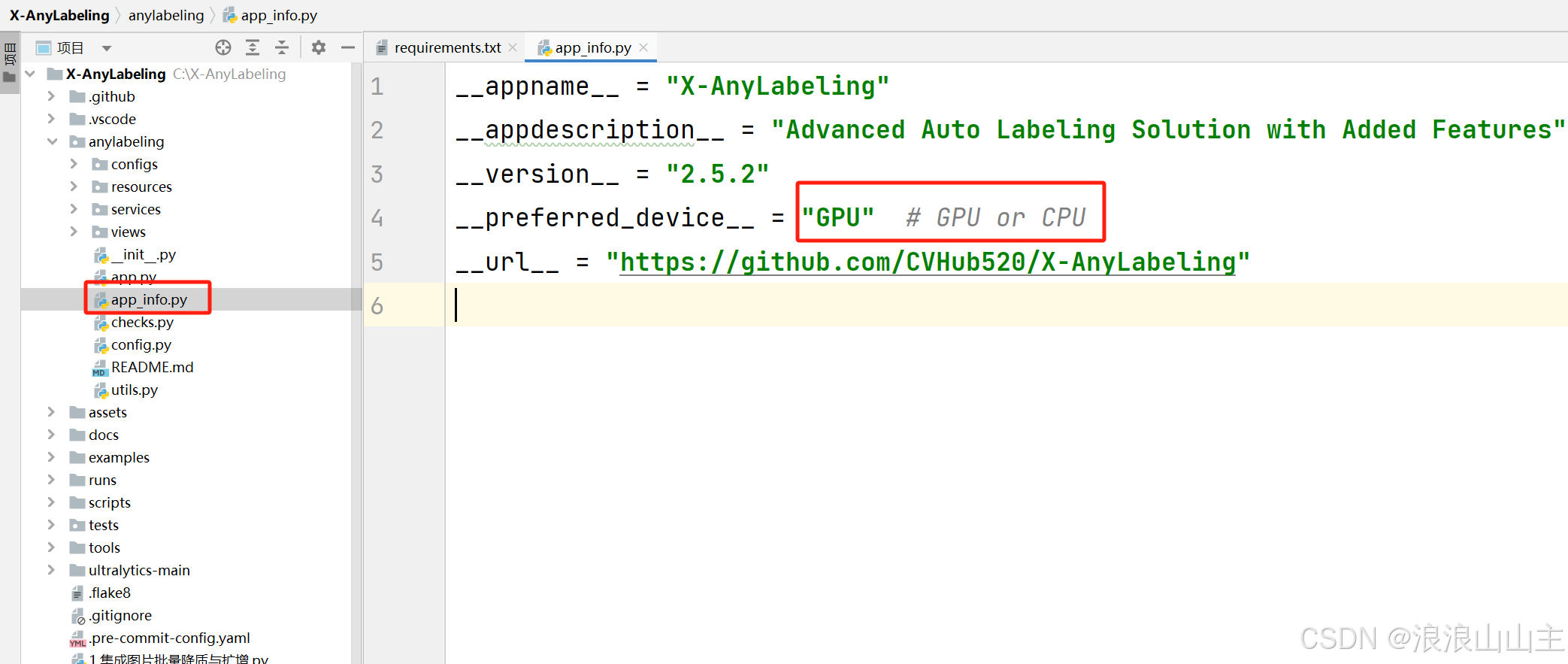
如果您需要 GPU 加速,应在 app_info.py 配置文件中将 __preferred_device__ 字段设置为 'GPU'。
6: 程序运行
打开Pycharm终端命令行运行应用程序:
# 先进入项目文件夹内
cd X-AnyLabeling
# 运行程序
python anylabeling/app.py
(2)从GUI运行
直接到 X-AnyLabeling仓库,往下翻一点找到v2.4.4的Assets,下载.exe软件包。
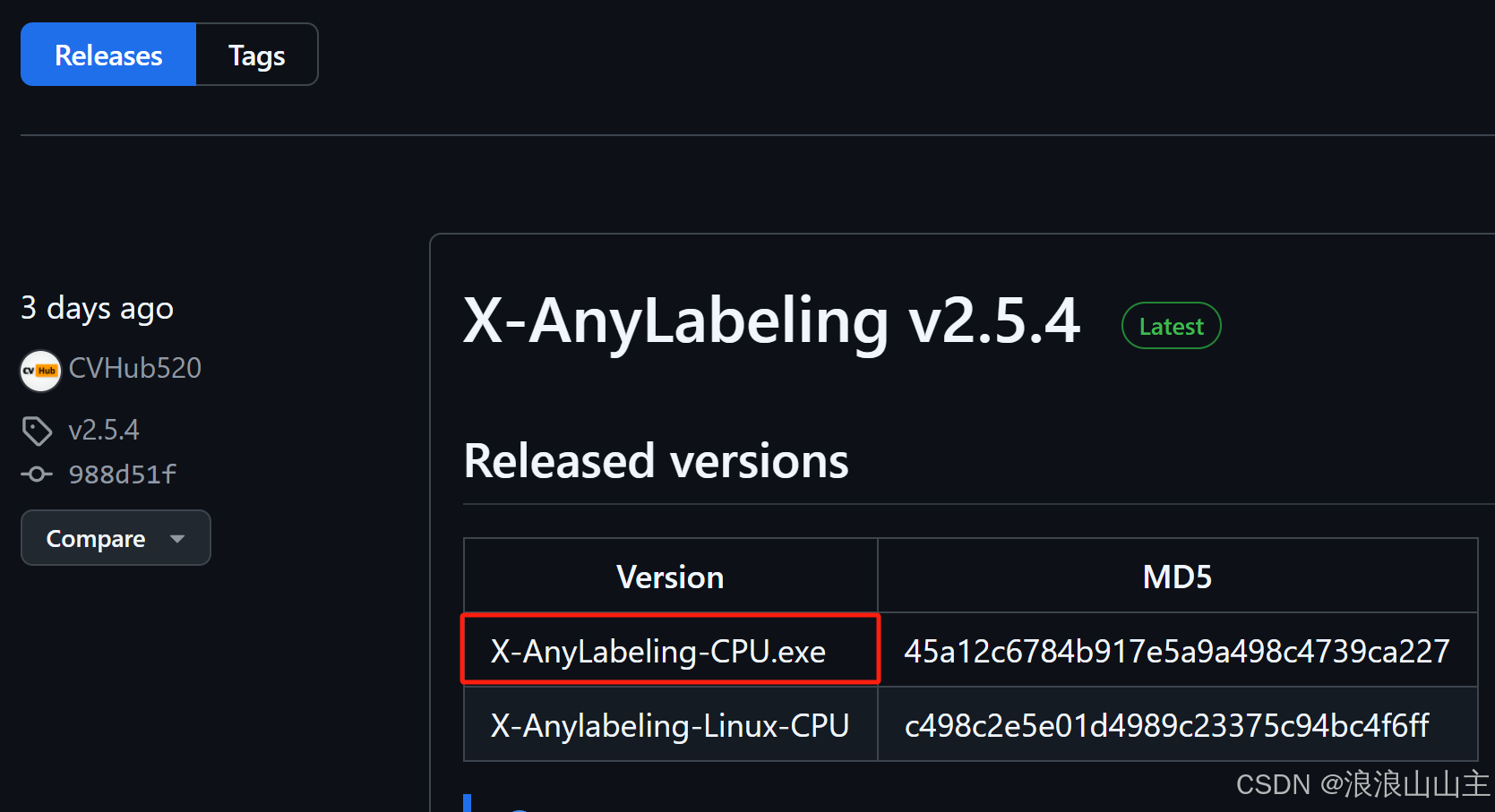
软件无需安装,双击打开直接用。
三、制作YOLO目标检测数据集
详细的标注软件使用说明和打标签的方法,在官方仓库的 User_Guide用户手册 里找到。
这里必须划重点说明:【打标签的十个注意事项】
样本图像的宽高比例不能太极端,一般都不会用大于1:3甚至1:4往上的图片,不然对象被严重拉伸,无法学习特征。
考虑样本的分辨率是否过大,经过训练时输入模型的图像尺寸(例如640x640或640x480)压缩,还能否保证标注的对象清晰。
样本图像中必须包含至少一个要检测的对象,不然这张图片为空白样本就得剔除。
如果对象类别之间的特征差异较少,应收集更多对象形态的样本,尽可能描述清楚对象的特征,增加类别之间的特征对比度。
数据集中如果有多个对象类别,或者在出现比例上有严重差异,则应该尽可能增加数据集的整体数量,以提高基数。
想训练的精度高,首要前提就是手工打标签必须要贴合目标对象,不多框不少框,不然后续再怎么优化训练参数都白费。
对象太微小的、模糊拖影的、甚至人眼都无法辨别特征的、对象呈现形态太特殊超出要检测预期的,都不算作一个标签对象。
当对象有重叠,重叠或遮挡不是特别严重的、人眼还能看得见对象主体特征的,那被遮挡对象都得打标签。
每个对象必须有单独的标签,不能偷懒,对象和标签类别必须一一对应,绝对不能混淆、模棱两可。
标签绝不能超过样本图像的边界,不然可能会导致标签数据错乱或异常,打完标签一定要回头逐一检查,绝不可有错。
(1)图片准备
我的数据集包含了自己采集的近10种杂草,经过图像增强处理后扩增到14000余张。采用X-anylabeling时,手工标定的数量应不低于总数量的10%。因此,我粗略准备了约1400张素材做演示。素材来自自己整理的田间杂草数据,命名方式采用自己编写的程序自动处理:
# 指定文件下的所有图片重命名
import os
import random
# 指定文件夹路径
folder_path = r"G:\20250110_DataTest\XXXXXX"
# 获取文件夹中的所有文件列表
file_list = os.listdir(folder_path)
# 滤出图片文件(假设所有文件都是图片)
image_files = [file for file in file_list if file.lower().endswith(('.png', '.jpg', '.jpeg'))]
# 随机排序图片文件
random.shuffle(image_files)
# 定义新的命名格式和起始编号
new_name_format = "Bidens_{:04d}.jpg"
start_index = 1
# 遍历排序后的文件列表并重命名
for index, old_file in enumerate(image_files):
# 确保当前处理的是图片文件
if not old_file.lower().endswith(('.png', '.jpg', '.jpeg')):
continue
# 生成新的文件名
new_name = new_name_format.format(start_index + index)
# 构建旧文件和新文件的路径
old_path = os.path.join(folder_path, old_file)
new_path = os.path.join(folder_path, new_name)
# 执行重命名操作
try:
os.rename(old_path, new_path)
print(f"已重命名:{old_file} -> {new_name}")
except Exception as e:
print(f"重命名失败:{old_file},错误信息:{str(e)}")
print("所有文件均已处理完毕。")
(2)打标签
导入图片素材文件夹
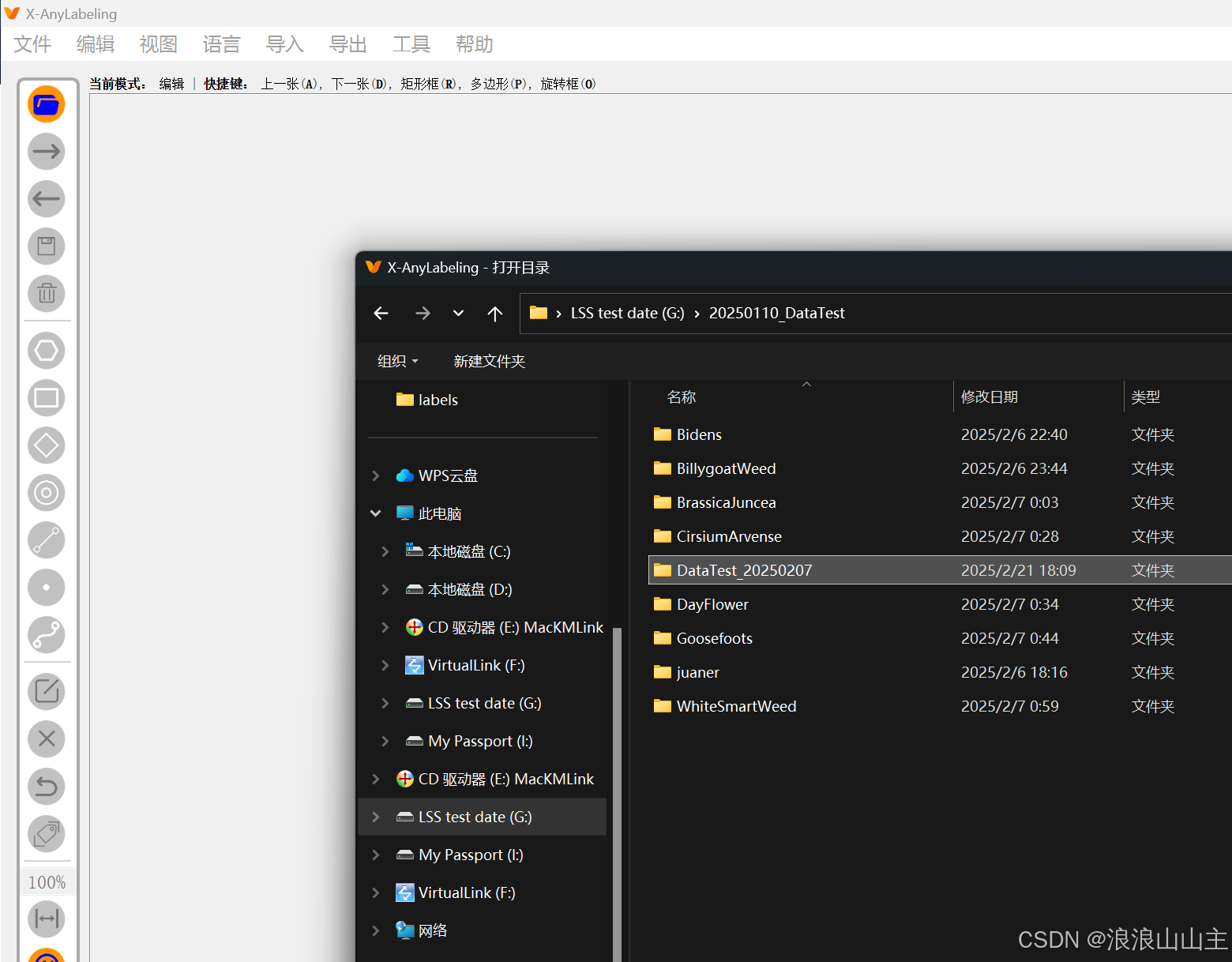
快捷键【R】开始绘制矩形框,左上角和右下角各点一下,然后在弹框中输入对象的类别。

按住【Ctrl键】滑动鼠标滚轮,可以对图片进行缩放。 快键键【A】上一张,【D】下一张,直到全部打完。
- 这里有个技巧,可以开启【自动使用上一个标签】,固定一个标签类别一直标完,再回头标下一个类别,可以提高效率,减少错标率。
- 全部标完,记得回来检查确认是否有错漏。
- 标注完会自动保存同名的.json标签描述文件,避免软件崩溃导致数据丢失,下次打开软件自动读取标签。

点击左上角【工具】查看【统计总览】,可以看到标签的数量分布情况。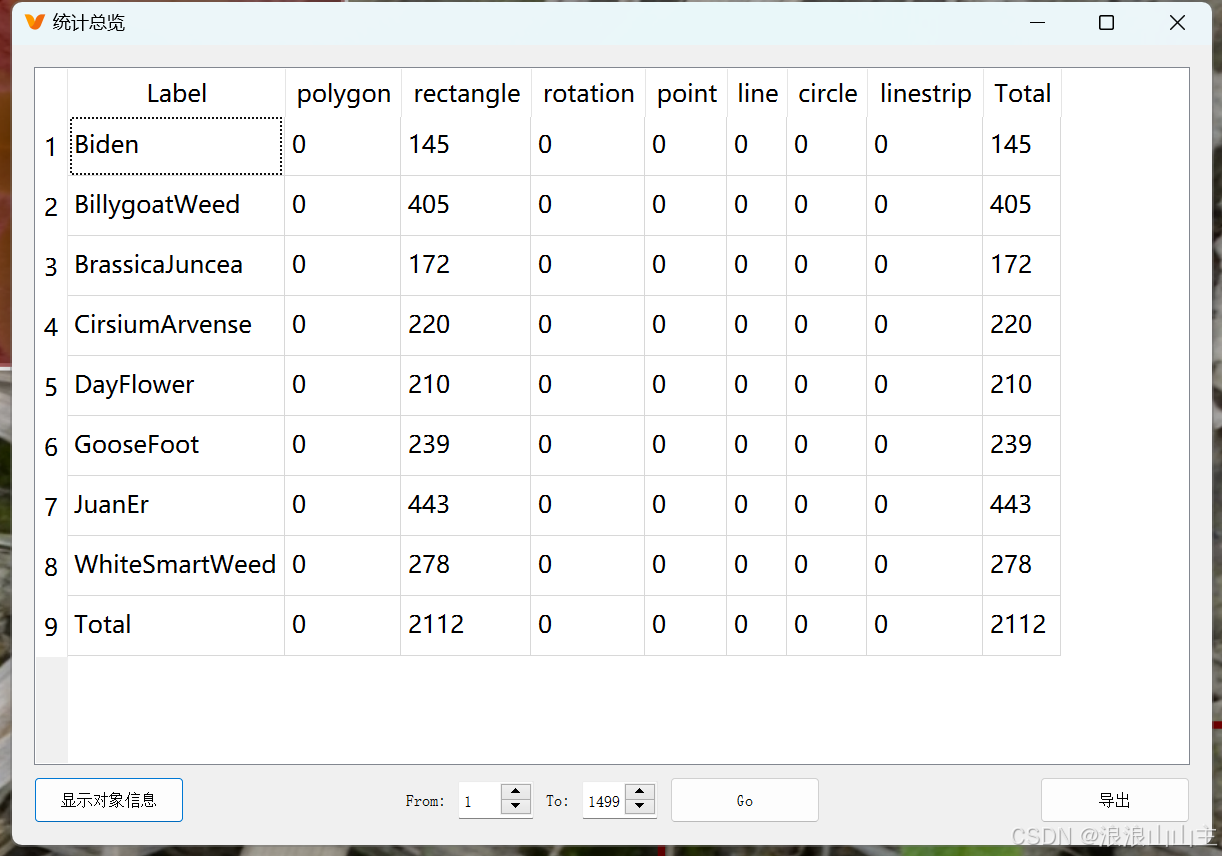
(3)导出数据集
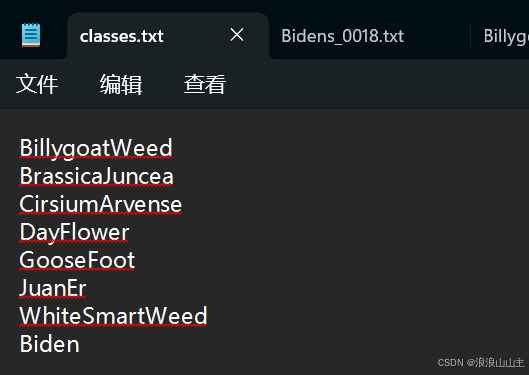
先根据前面创建标签类别的顺序,准备一个类别名称描述文件。比如我新建一个classes.txt标签文件,编写内容如下:
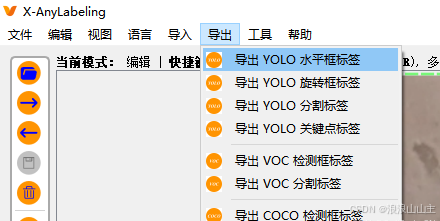
点击软件【导出YOLO水平框标签】,选择刚刚创建的classes.txt标签文件。
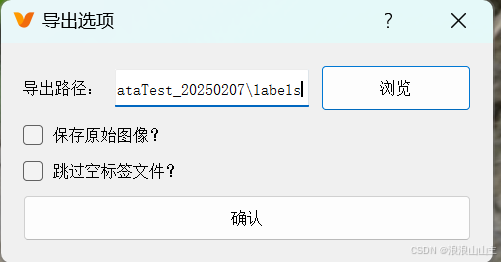
标签的默认导出位置就和我们的杂草数据集文件夹并列:
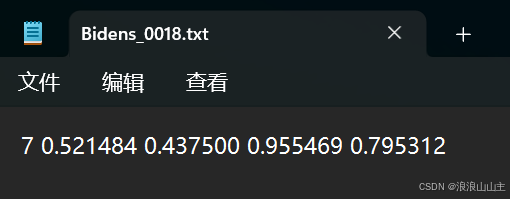
导出的标签文件为同名的.txt格式,里面的内容分别是类ID、框中心坐标XY和宽高WH(相对于原图尺寸的比例值)
(4)数据集拆分
- 在机器学习中,我们通常会将数据集划分为训练集、验证集和测试集:
- 训练集:训练集用于模型的训练,即用于调整模型的参数。这就像是学生的课本,用于日常的知识巩固。
- 验证集:验证集用于模型的调整和评估。它可以用来选择和调整模型的超参数,以及对模型的能力进行初步评估。这就像是学生的周考,用来纠正和强化学到的知识。
- 测试集:测试集用于评估模型的最终性能,即模型的泛化能力。但它不能用于调整模型的参数或选择特征等算法相关的选择。这就像是学生的期末考试,用来最终评估学习效果。
- 在实际应用中,训练集、验证集和测试集的划分比例一般遵循6:2:2或8:1:1的原则。这三个数据集的数据分布应该是近似的,但它们所用的数据是不同的。这样做的目的是为了使模型的训练效果能合理地泛化至测试效果,从而推广应用至现实世界中。同时,模型在训练集、验证集和测试集上所反映的预测效果可能存在差异。
下面是我自己编写的用于划分数据集的python脚本,亲测好用:
import os
import random
import shutil
from tqdm import tqdm # 进度条显示
# 配置参数
DATASET_CONFIG = {
"image_src_dir": "G:/20250110_DataTest/DataTest_20250207/LssAgriWeedNet.V1.0_AnyLabeling",
"label_src_dir": "G:/20250110_DataTest/DataTest_20250207/labels",
"output_root": "G:/20250110_DataTest/DataTest_20250207/split_dataset",
"ratios": {
"train": 0.8,
"val": 0.1,
"test": 0.1
},
"file_lists": {
"train": "train.txt",
"val": "val.txt",
"test": "test.txt"
}
}
def validate_paths():
"""路径有效性验证"""
required_dirs = [
DATASET_CONFIG["image_src_dir"],
DATASET_CONFIG["label_src_dir"]
]
for path in required_dirs:
if not os.path.exists(path):
raise FileNotFoundError(f"关键路径不存在: {path}")
if not os.path.isdir(path):
raise NotADirectoryError(f"路径不是目录: {path}")
def prepare_output_structure():
"""创建输出目录结构"""
dir_structure = {
"images": ["train", "val", "test"],
"labels": ["train", "val", "test"]
}
# 创建输出根目录
os.makedirs(DATASET_CONFIG["output_root"], exist_ok=True)
# 创建子目录
for data_type in dir_structure:
for subset in dir_structure[data_type]:
path = os.path.join(DATASET_CONFIG["output_root"], data_type, subset)
os.makedirs(path, exist_ok=True)
# 清空目录(如果非空)
for filename in os.listdir(path):
file_path = os.path.join(path, filename)
try:
if os.path.isfile(file_path):
os.unlink(file_path)
except Exception as e:
print(f"清理目录失败: {file_path} - {e}")
def get_valid_file_pairs():
"""获取有效的文件对(同时存在图片和标签)"""
valid_pairs = []
# 遍历标签目录
for label_file in os.listdir(DATASET_CONFIG["label_src_dir"]):
if label_file.endswith(".txt"):
base_name = os.path.splitext(label_file)[0]
image_path = os.path.join(
DATASET_CONFIG["image_src_dir"],
f"{base_name}.jpg"
)
label_path = os.path.join(
DATASET_CONFIG["label_src_dir"],
label_file
)
# 验证文件存在性
if os.path.exists(image_path) and os.path.exists(label_path):
valid_pairs.append((image_path, label_path, base_name))
else:
print(f"文件对不完整: {base_name}")
if not valid_pairs:
raise ValueError("未找到有效的图片-标签文件对")
return valid_pairs
def split_dataset(file_pairs):
"""执行数据集划分"""
# 随机打乱(可复现版本可设置seed)
random.shuffle(file_pairs)
total = len(file_pairs)
ratios = DATASET_CONFIG["ratios"]
# 计算划分点
train_end = int(total * ratios["train"])
val_end = train_end + int(total * ratios["val"])
return {
"train": file_pairs[:train_end],
"val": file_pairs[train_end:val_end],
"test": file_pairs[val_end:]
}
def process_subset(subset_name, file_pairs):
"""处理单个子集"""
# 路径模板
image_dest = os.path.join(
DATASET_CONFIG["output_root"],
"images",
subset_name
)
label_dest = os.path.join(
DATASET_CONFIG["output_root"],
"labels",
subset_name
)
# 文件列表路径
list_path = os.path.join(
DATASET_CONFIG["output_root"],
DATASET_CONFIG["file_lists"][subset_name]
)
# 复制文件并记录路径
with open(list_path, "w", encoding="utf-8") as f_list:
for img_src, lbl_src, base_name in tqdm(file_pairs, desc=subset_name):
try:
# 复制图片
img_dst = os.path.join(image_dest, f"{base_name}.jpg")
shutil.copy2(img_src, img_dst)
# 复制标签
lbl_dst = os.path.join(label_dest, f"{base_name}.txt")
shutil.copy2(lbl_src, lbl_dst)
# 记录绝对路径
f_list.write(f"{img_dst}\n")
except Exception as e:
print(f"处理文件失败: {base_name} - {e}")
def main():
# 执行验证
validate_paths()
# 准备目录结构
prepare_output_structure()
# 获取有效文件对
file_pairs = get_valid_file_pairs()
print(f"找到有效数据对: {len(file_pairs)} 个")
# 划分数据集
split_data = split_dataset(file_pairs)
# 处理各子集
for subset in ["train", "val", "test"]:
process_subset(subset, split_data[subset])
# 打印统计信息
print("\n数据集划分完成,统计信息:")
for subset, data in split_data.items():
print(f"{subset.upper():<6}: {len(data)} 个样本")
if __name__ == "__main__":
main()划分后的数据集会保存在split_dataset下,结构如下:
G:\20250110_DATATEST\DATATEST_20250207\SPLIT_DATASET
│
├───train.txt # 记录训练集图片路径(如 "images/001.jpg")
├───val.txt # 记录验证集图片路径
├───test.txt # 记录测试集图片路径
│
├───train
│ ├───images
│ └───labels
├───val
│ ├───images
│ └───labels
└───test
├───images
└───labels(5)数据集配置文件
在Project目录下,用文本文档工具新建一个.yaml配置文件,然后用记事本打开编辑即可。
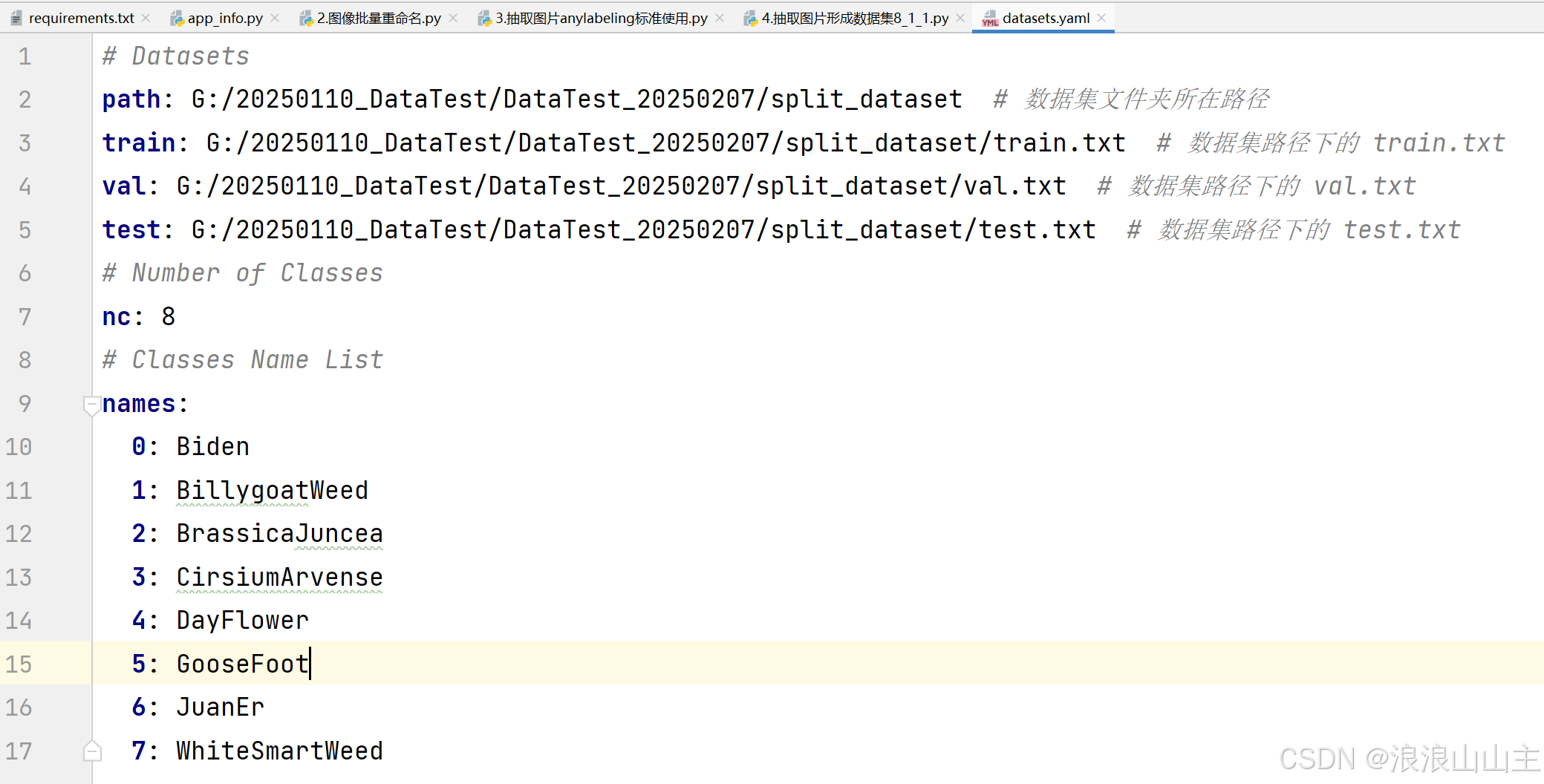
四、 训练YOLO8s目标检测模型
YOLOv8的环境配置这里不再多讲,可以参考我之前一篇配置教程基于Pycharm的YOLOv8杂草视觉检测1——运行环境配置+杂草识别示例_pycharm yolov8-CSDN博客![]() https://blog.csdn.net/LSS_LSS/article/details/135025853
https://blog.csdn.net/LSS_LSS/article/details/135025853
(1) 模型训练
在ultralytics同级目录新建一个模型训练脚本yolo_train_cs.py,复制如下内容进去,修改成你的训练参数。填写路径时的datasets.yaml就是指定生成s大小的模型,n/s/m/l/x的模型同理。
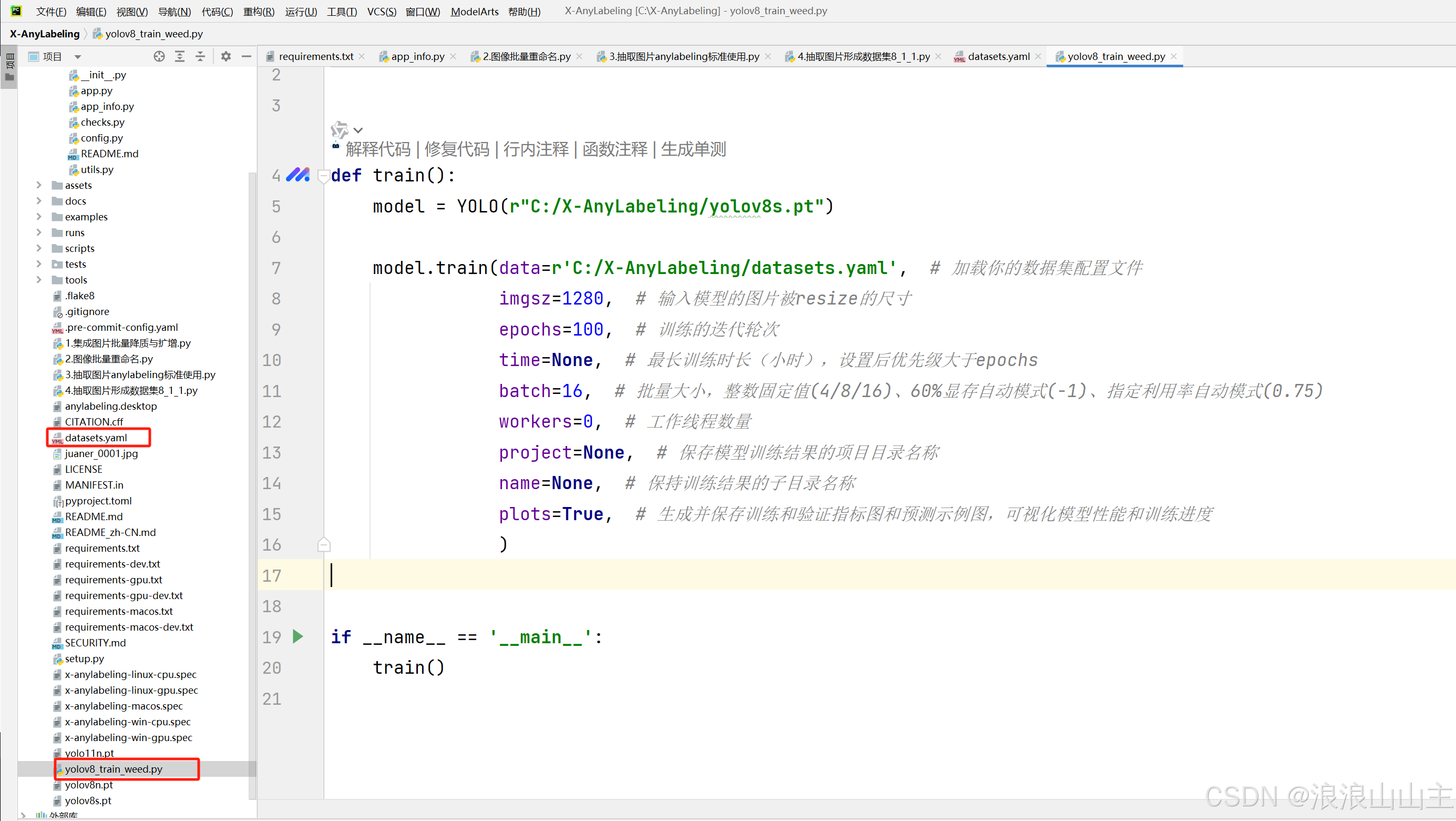
from ultralytics import YOLO
def train():
model = YOLO(r"C:/X-AnyLabeling/yolov8s.pt")
model.train(data=r'C:/X-AnyLabeling/datasets.yaml', # 加载你的数据集配置文件
imgsz=1280, # 输入模型的图片被resize的尺寸
epochs=100, # 训练的迭代轮次
time=None, # 最长训练时长(小时),设置后优先级大于epochs
batch=16, # 批量大小,整数固定值(4/8/16)、60%显存自动模式(-1)、指定利用率自动模式(0.75)
workers=0, # Windows系统最好设置为0,否则运行不了
project=None, # 保存模型训练结果的项目目录名称
name=None, # 保持训练结果的子目录名称
plots=True, # 生成并保存训练和验证指标图和预测示例图,可视化模型性能和训练进度
)
if __name__ == '__main__':
train()
运行上述代码开始训练:
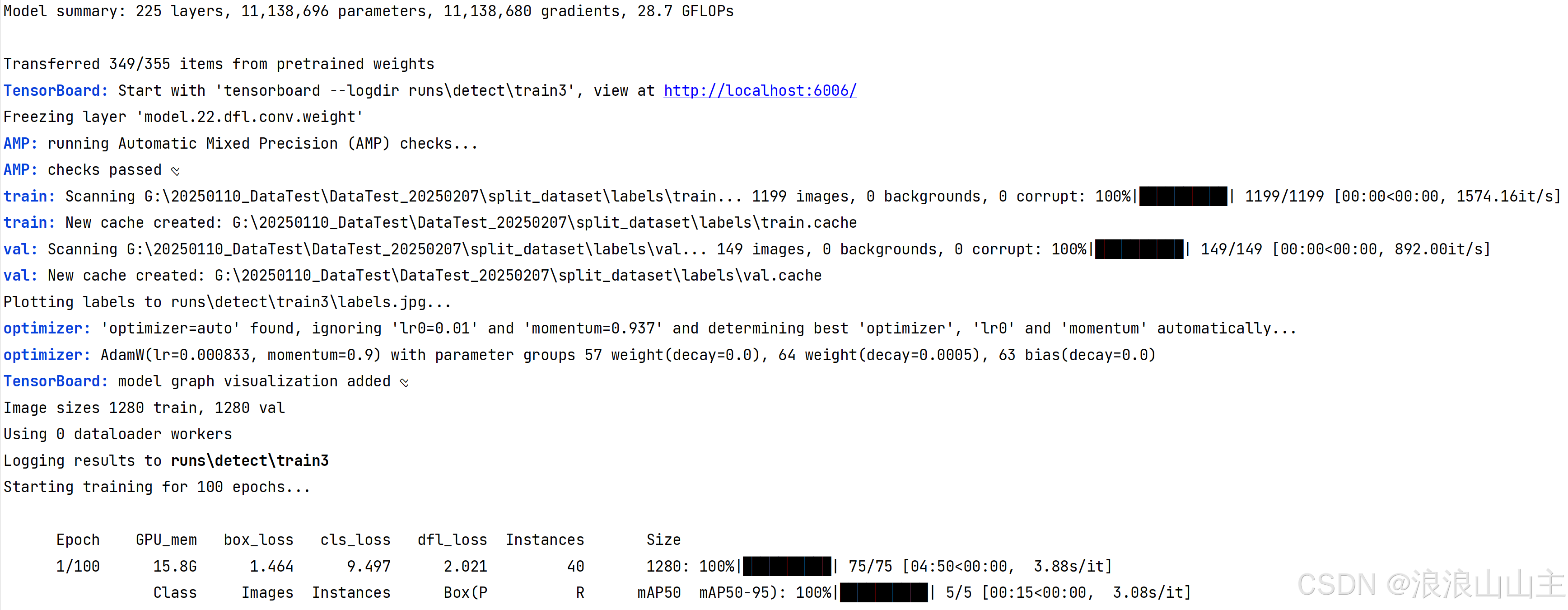
训练完成
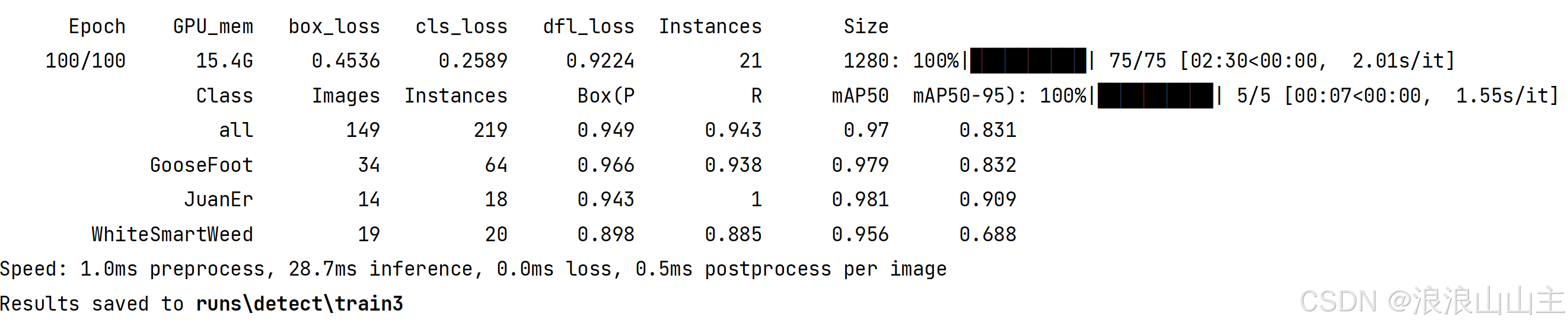
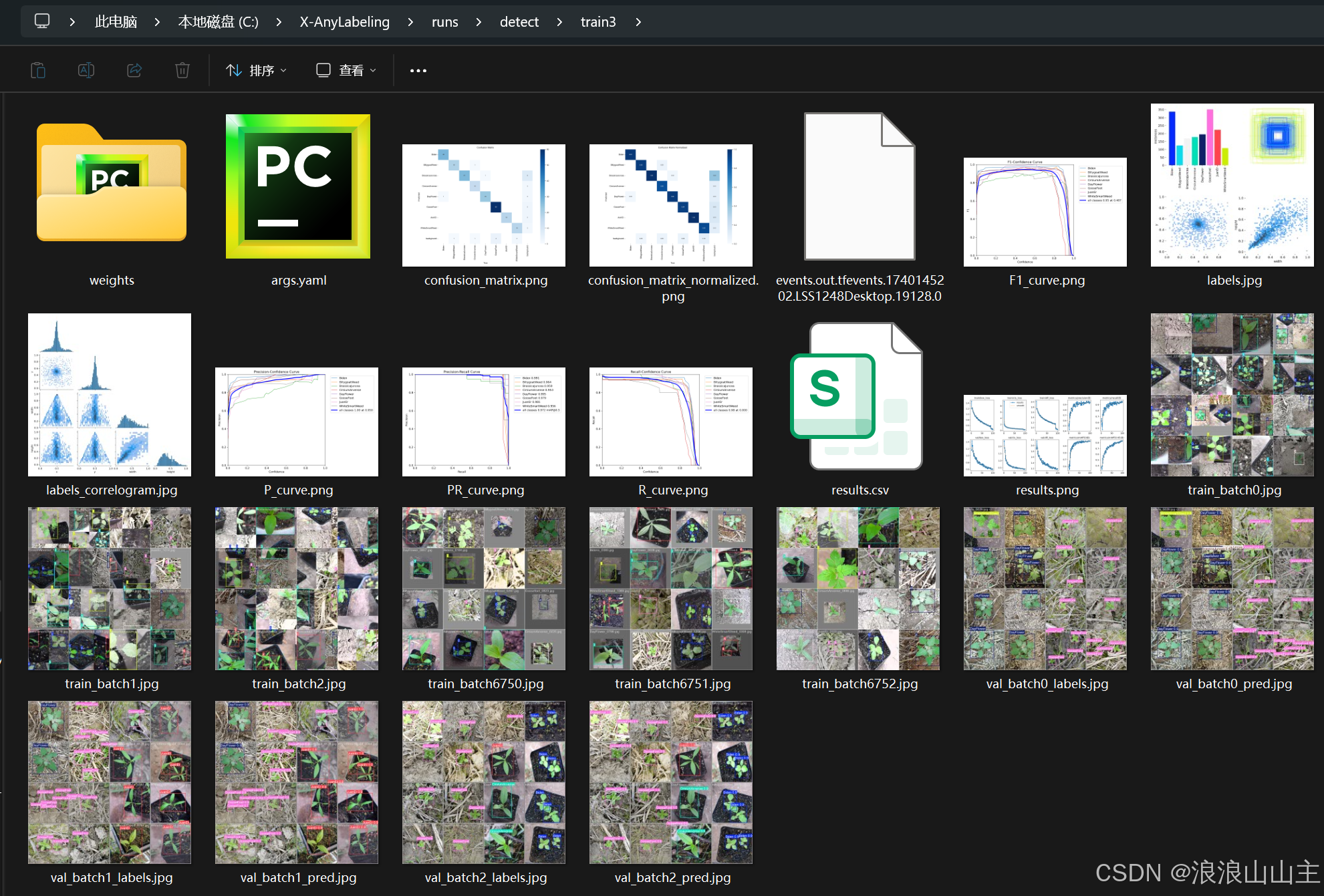
训练结果默认保存在runs/detect/train3目录下,其中weight文件夹中包含两个模型权重文件:
- best.pt 保存的是训练过程中自动验证得到分数最高的模型
- last.pt 保存的是最后一次epoch迭代的模型训练结果
图片名称里有pred就是预测效果。下图中左边是我们自己打的标签框,右边是训练出来的模型实际预测框。可能是由于预训练数据量足够多,感觉效果还可以。

(2) 评估模型
在ultralytics同级目录新建一个模型训练脚本yolov8_val_weed.py,复制如下内容进去,修改成你的模型和评估验证参数。
import warnings
from ultralytics import YOLO
warnings.filterwarnings('ignore')
def val():
model = YOLO(r'C:/X-AnyLabeling/runs/detect/train3/weights/best.pt') # 加载模型
metrics = model.val(data=r'C:/X-AnyLabeling/datasets.yaml', # 加载数据集
imgsz=1280, # 输入模型的图片被resize的尺寸
epochs=100, # 训练的迭代轮次
time=None, # 最长训练时长(小时),设置后优先级大于epochs
batch=16, # 批量大小,整数固定值(4/8/16)、60%显存自动模式(-1)、指定利用率自动模式(0.75)
workers=0, # 工作线程数量
project=None, # 保存模型训练结果的项目目录名称
name=None, # 保持训练结果的子目录名称
plots=True, # 生成并保存训练和验证指标图和预测示例图,可视化模型性能和训练进度
)
if __name__ == '__main__':
val()
运行结果如下:
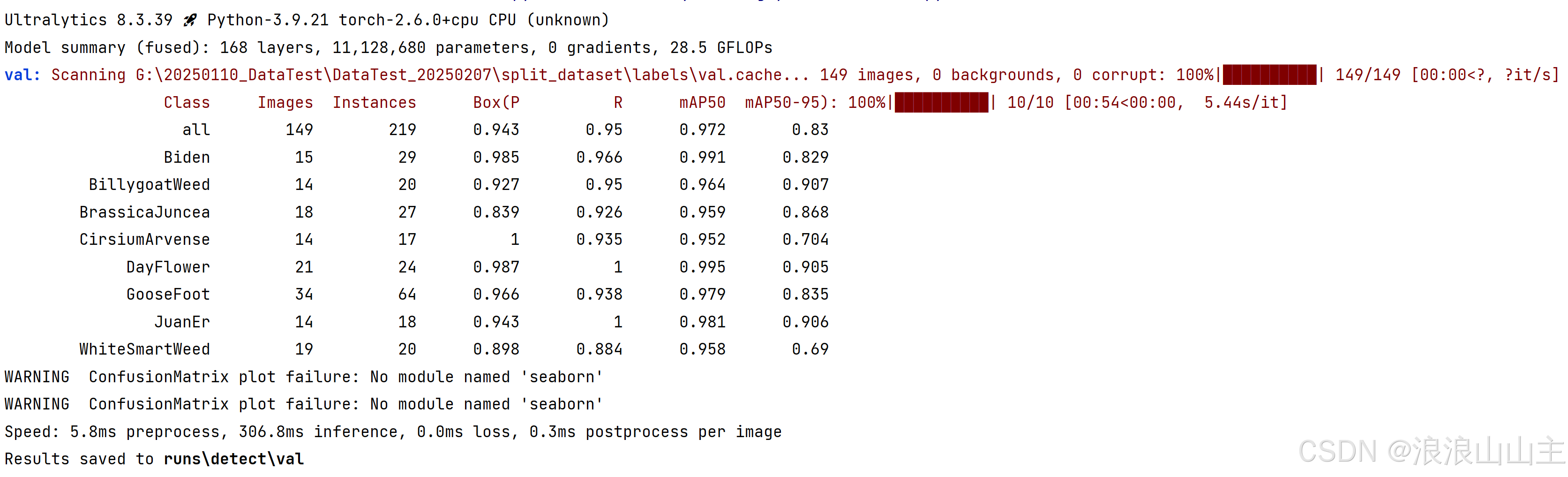
打开runs\detect\val文件夹。训练的效果对比,左边是我们自己打的标签框,右边是训练出来的模型实际预测框。
(3) 推理模型
在ultralytics同级目录新建一个模型训练脚本yolov8_predict_weed.py,复制如下内容进去,修改成你的模型和推理参数。
import cv2
from ultralytics import YOLO
import os
def predict():
model = YOLO(r'C:/X-AnyLabeling/runs/detect/train3/weights/best.pt') # 加载模型
image_dir = r"G:\20250110_DataTest\DataTest_20250207\split_dataset\images\test"
images = os.listdir(image_dir) # 获取文件夹内所有图片名称字符串到一个数组内
print("total images number:", len(images))
# 模型推理
for image in images:
frame = cv2.imread(image_dir+'\\'+image)
results = model.predict(source=frame, # 输入图像
imgsz=1280, # 输入模型的图片被resize的尺寸
epochs=100, # 训练的迭代轮次
time=None, # 最长训练时长(小时),设置后优先级大于epochs
batch=16, # 批量大小,整数固定值(4/8/16)、60%显存自动模式(-1)、指定利用率自动模式(0.75)
workers=0, # 工作线程数量
project=None, # 保存模型训练结果的项目目录名称
name=None, # 保持训练结果的子目录名称
plots=True, # 生成并保存训练和验证指标图和预测示例图,可视化模型性能和训练进度
)
for result in results:
out = result.plot() # 绘制检测结果
cv2.imshow("result", out) # 显示图片
cv2.waitKey(0) # 暂停,等待用户输入任意键继续
cv2.destroyAllWindows()
if __name__ == '__main__':
predict()

如果你想从检测结果中获取检测框的关键信息,数据提取方式可以参考如下:
你可以自己绘制检测框,或者将检测数据用到任务中,或者直接保存一个推理视频。
import cv2
from ultralytics import YOLO
import os
def predict():
model = YOLO(r'C:/X-AnyLabeling/runs/detect/train3/weights/best.pt') # 加载模型
image_dir = r"G:\20250110_DataTest\DataTest_20250207\split_dataset\images\test"
images = os.listdir(image_dir) # 获取文件夹内所有图片名称字符串到一个数组内
print("total images number:", len(images))
# 结果保存为视频
# fourcc = cv2.VideoWriter.fourcc('X', 'V', 'I', 'D')
# result_video = cv2.VideoWriter("out.avi", fourcc, 2,(700, 700))
# 模型预热(推理首帧处理较久,包含了模型加载进显卡缓存的时间)
for image in images:
model(image_dir + "\\" + image)
break # 只推理第一张图
# 模型推理
for image in images:
frame = cv2.imread(image_dir+'\\'+image)
results = model.predict(source=frame, # 输入图像
imgsz=1280, # 输入模型的图片被resize的尺寸
epochs=100, # 训练的迭代轮次
time=None, # 最长训练时长(小时),设置后优先级大于epochs
batch=16, # 批量大小,整数固定值(4/8/16)、60%显存自动模式(-1)、指定利用率自动模式(0.75)
workers=0, # 工作线程数量
project=None, # 保存模型训练结果的项目目录名称
name=None, # 保持训练结果的子目录名称
plots=True, # 生成并保存训练和验证指标图和预测示例图,可视化模型性能和训练进度
stream=False, # 设置推理时采用媒体流的方式, 默认为False
)
# 绘制检测结果
for result in results:
# # 官方的一键绘制检测框方法
out_plot = result.plot()
cv2.imshow("out_plot", out_plot)
# 提取检测框数据
names = result.names
cls = result.boxes.cls.tolist()
conf = result.boxes.conf.tolist()
xyxy = result.boxes.xyxy.tolist()
# 初始化绘图参数
color_1 = (0, 255, 0)
color_2 = (0, 0, 255)
bright_color = (255, 255, 255)
dark_color = (0, 0, 0)
num = len(cls)
tips_h = 18 # 文本框高度
out = frame # 从原图拷贝作为绘制结果的画布
# 遍历所有检测框对象
for j in range(num):
if cls[j] == 0:
rect_color = color_1
txt_color = dark_color
cls_id = 0
cls_name = names[cls_id]
elif cls[j] == 1:
rect_color = color_2
txt_color = bright_color
cls_id = 1
cls_name = names[cls_id]
else:
print("unknown class")
break
cls_conf = round(conf[j], 3) # 对浮点数四舍五入保留三位小数
cls_data = str(cls_id) + "-" + cls_name + "-" + str(cls_conf)
tips_w = len(cls_data) * 12
# 在图像上绘制检测框
out = cv2.rectangle(out,
(int(xyxy[j][0]), int(xyxy[j][1])),
(int(xyxy[j][2]), int(xyxy[j][3])),
rect_color, # 颜色
2) # 框线粗细
# 在图像上绘制文本底框
out = cv2.rectangle(out,
(int(xyxy[j][0]), int(xyxy[j][1]) - tips_h),
(int(xyxy[j][0]) + tips_w, int(xyxy[j][1])),
rect_color, # 颜色
-1) # 框线粗细,-1为实心
# 在图像上绘制文本信息
cv2.putText(out, # 图像画布
cls_data, # 字符内容
(int(xyxy[j][0]) + 2, int(xyxy[j][1]) - 2), # 左下角坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体格式
0.6, # 字体大小
txt_color, # 字体颜色
1) # 笔画粗细
cv2.imshow("out_draw", out)
cv2.waitKey(0)
# result_video.write(out) # 写入视频帧
# result_video.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
predict()(4) 导出模型
以导出ONNX格式的模型为例:
from ultralytics import YOLO
def export():
model = YOLO(r'C:/X-AnyLabeling/runs/detect/train3/weights/best.pt') # 加载模型
model.export(format='onnx', #导出onnx格式,默认原路径保存,例如:best.onnx
imgsz=1280, # 模型的图片输入尺寸
dynamic=False, # 禁止模型动态的图片输入大小
)
if __name__ == '__main__':
export()

五、自动标注功能测试——使用YOLOv8s预训练模型
使用YOLOv8s预训练模型X-AnyLabeling官方的文档中声明的导入模型有三种途径:
(1)拷贝并修改模型配置文件
进入X-AnyLabeling 模型库中拷贝对应的模型的.yaml配置文件。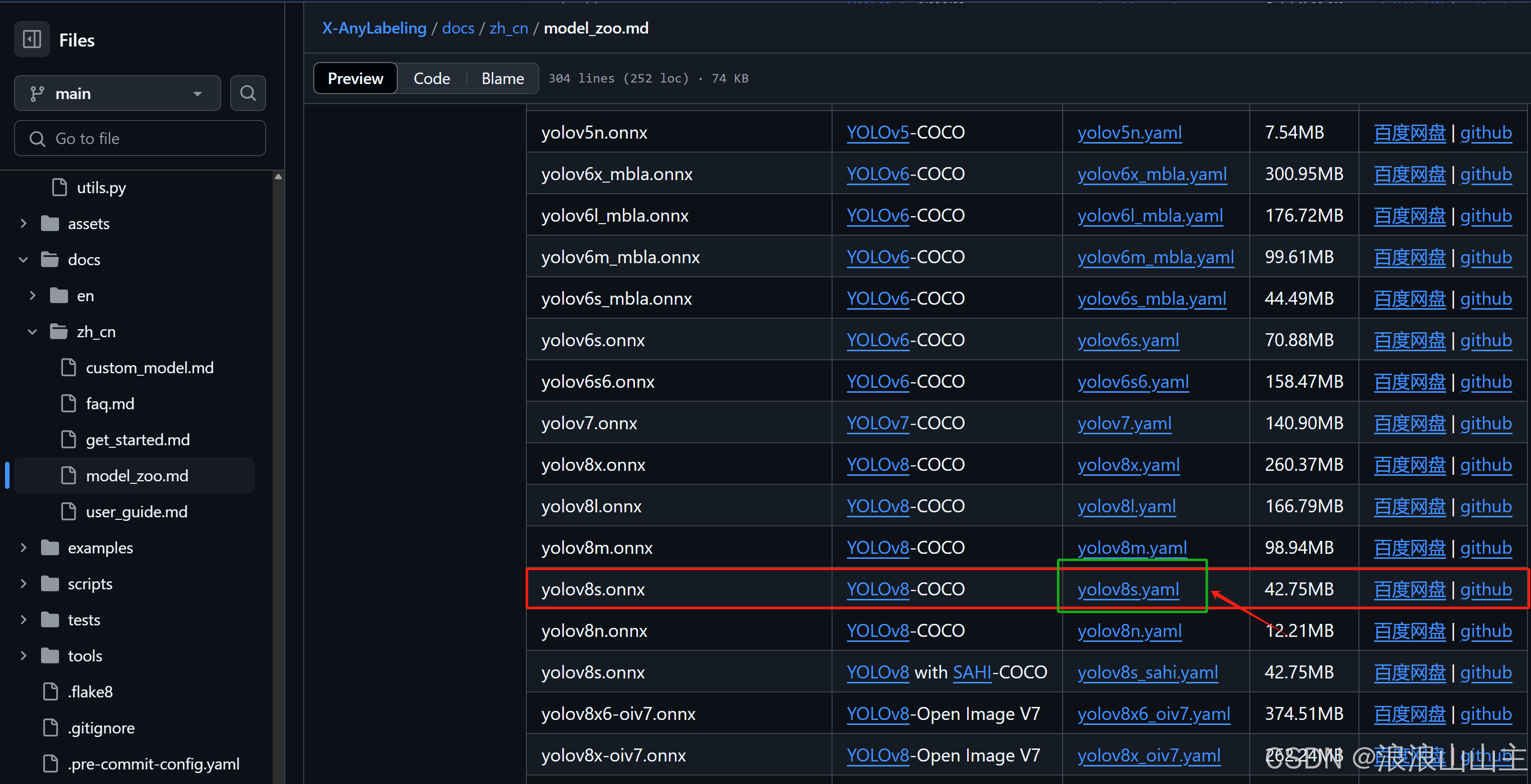
例如拷贝YOLOv8s的配置文件中的内容,在本地新建一个YOLOv8s_weed.yaml文件进行编辑。
将模型文件和配置文件放到同一个文件夹中,建议在配置文件中使用相对路径定位模型路径。
type: yolov8
name: yolov8s-r20230520
display_name: YOLOv8s_weed
model_path: C:/X-AnyLabeling/runs/detect/train3/weights/best.onnx
nms_threshold: 0.45
confidence_threshold: 0.25
classes:
- BillygoatWeed
- BrassicaJuncea
- CirsiumArvense
- DayFlower
- GooseFoot
- JuanEr
- WhiteSmartWeed
- Biden
(2)导入自定义训练的模型
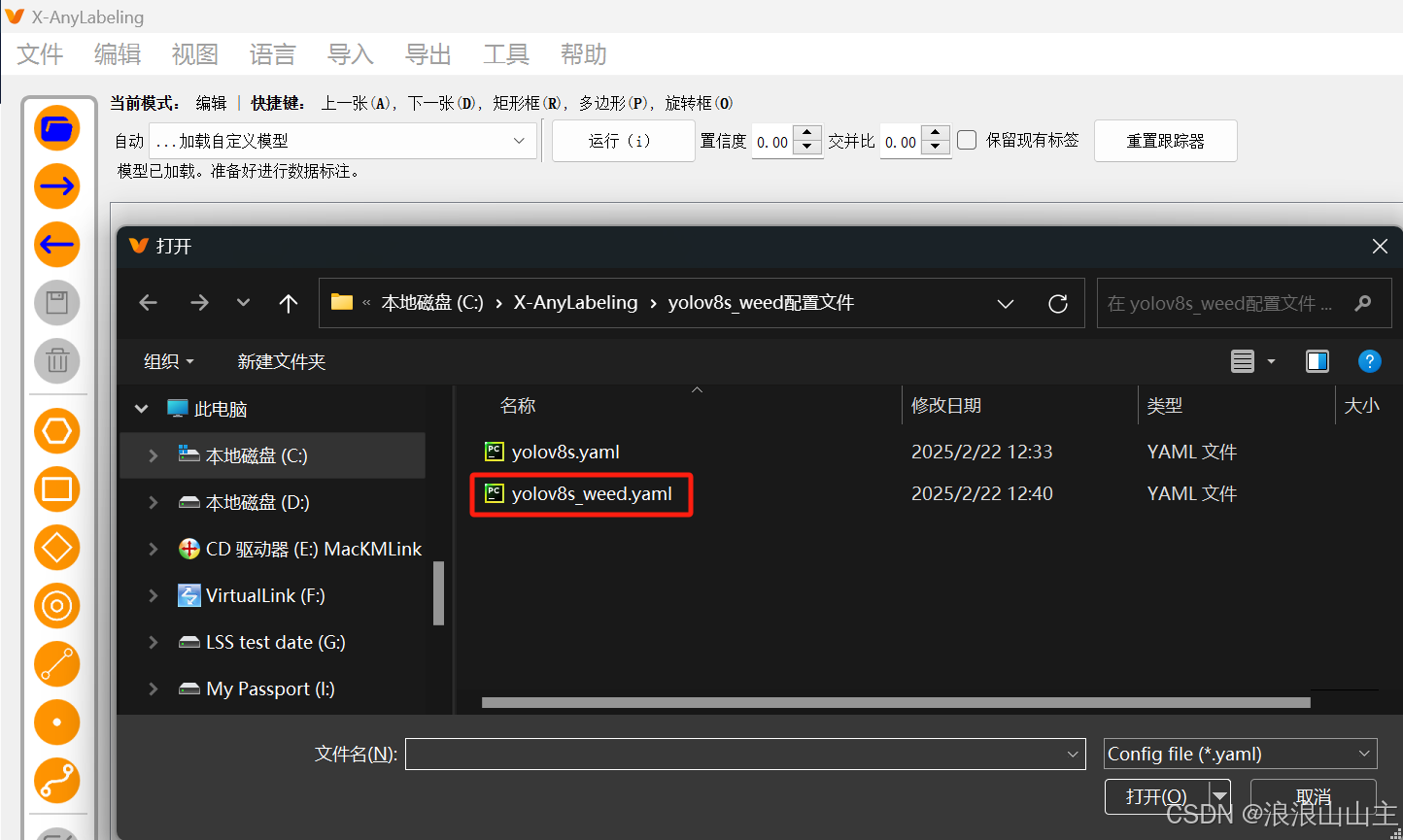
发现没有更新阈值,那就手动输入设置一下,然后点击运行,推理的效果还行。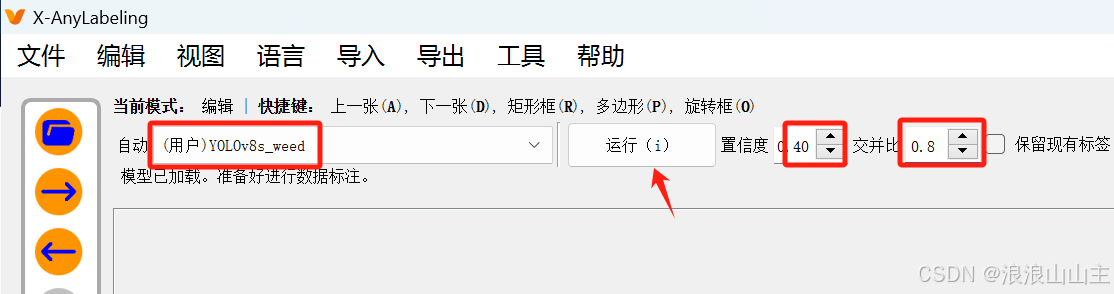

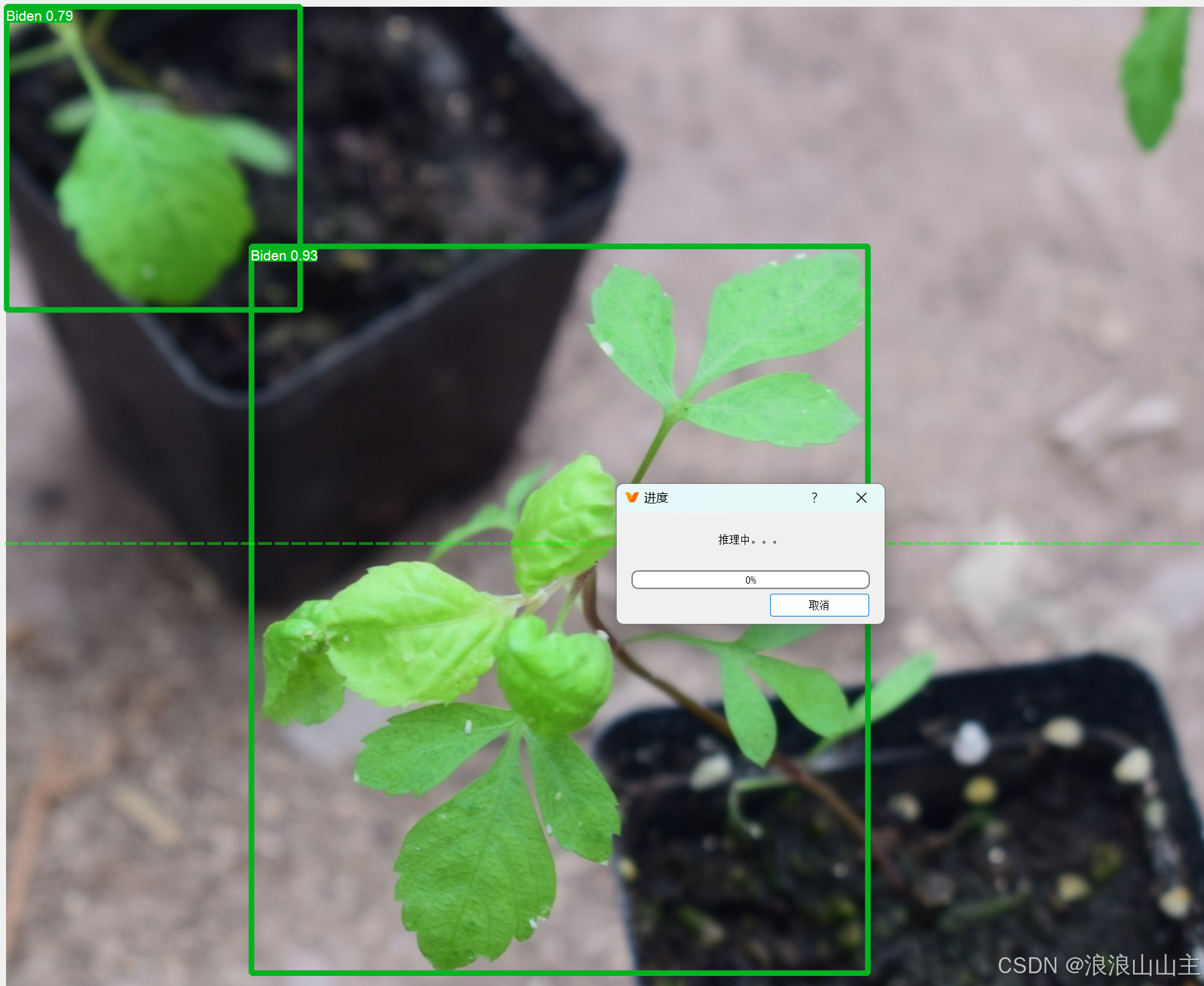
点击左侧这个"▶"按钮,弹出的对话框选择"确认"就可以一次性将后面所有图片都推理出标签框了。截图如下图所示。当然,目标框可能与实际目标大小有区别,需要微调。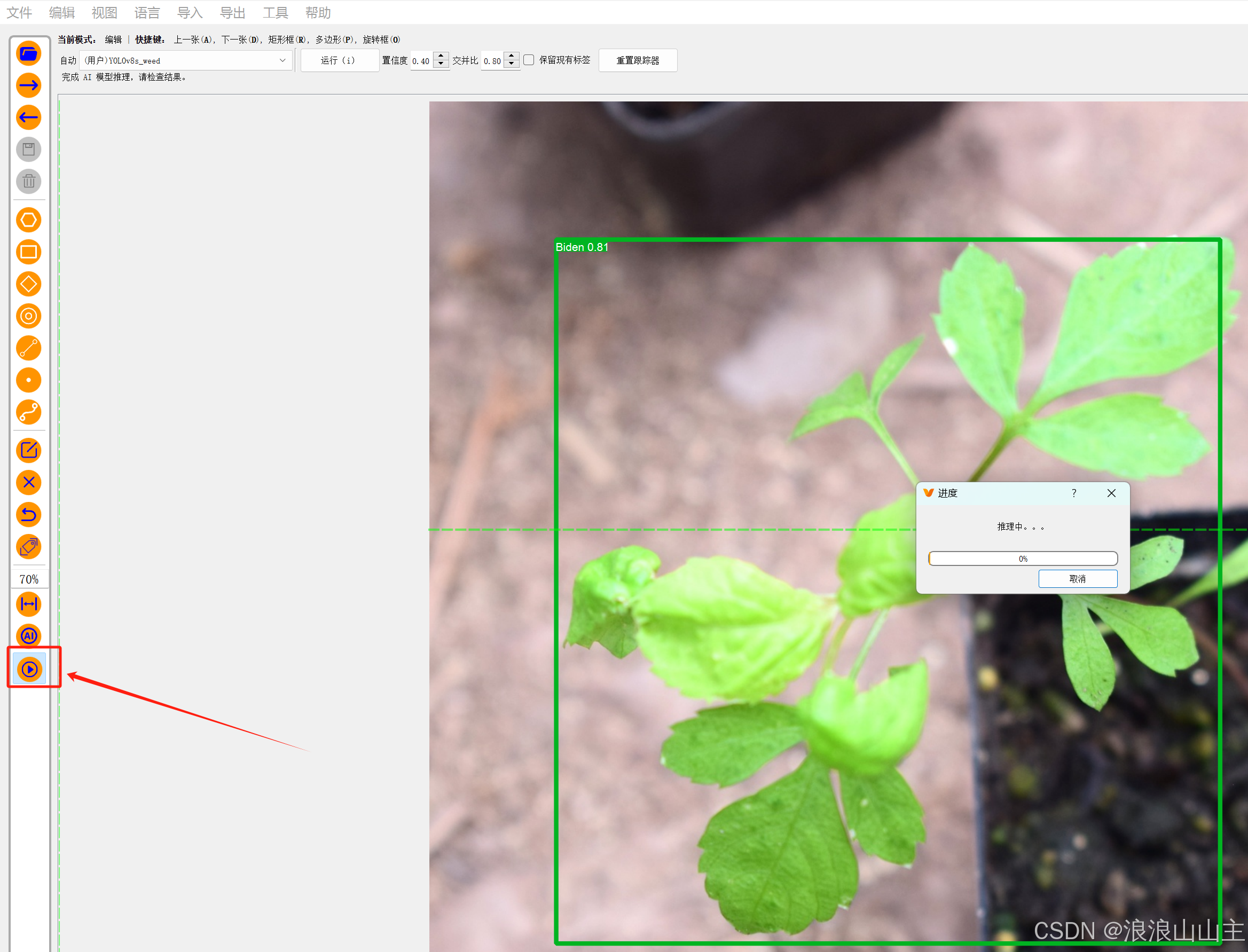
总结
这个的工作重点主要在数据集建立、图像增强(数据集扩增)以及前部分8:1:1自动划分程序的设计上。图像采集陆陆续续有小半年,利用X-Anylabeling对近1500张照片进行手工标定费了一天半,后面自动化标注和矩形框微调又花了一天时间。当然,这些内容也是为我的研究内容打基础的,马虎不得。写下这篇文章最主要还是方便自己以及师弟师妹回顾操作流程,如果能得到大家的喜欢更是一件好事情。愿大家学有所得、学有所成!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 38
38 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)