通义万相 Wan2.1视频生成模型的介绍,拥抱大模型,场景应用,赚钱
阿里云通义万相推出万相2.1视频生成模型,在大幅度复杂运动、物理规律遵循、艺术表现等方面全面提升。
大家好,我 是AI 盒子哥,我会持续将最新大模型的资讯,大模型的实践与大家分享,请持续关注!
Wan2.1 简介:基本概念
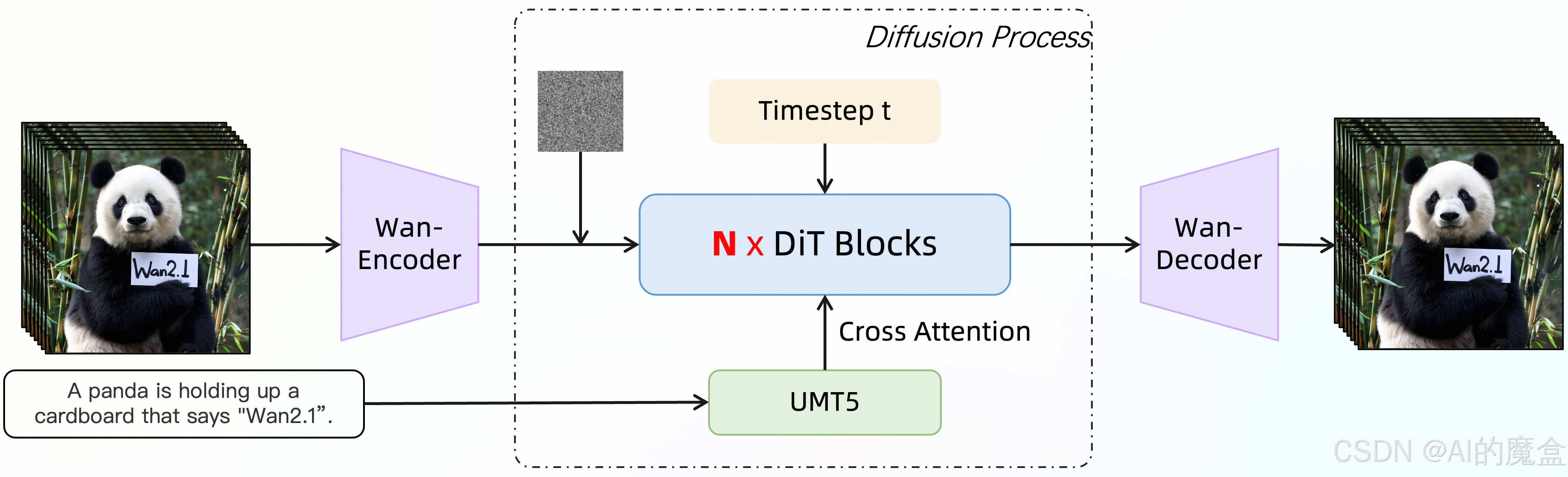
Wan2.1 基于主流的 diffusion transformer 范式设计,通过一系列创新实现了生成能力的重大进步。其中包括我们新颖的时空变分自动编码器 (VAE)、可扩展的训练策略、大规模数据构建和自动评估指标。总的来说,这些贡献增强了模型的性能和多功能性。
主要概述:通义万相Wan2.1模型的性能特点、技术架构、使用教程以及对用户的启发意义。
1、模型性能:
■ 领先性能:Wan2.1在多个基准测试中持续超越现有的开源模型和最先进的商业解决方案。
■ 支持消费级GPU:T2V-1.3B模型仅需8.19 GB VRAM,与几乎所有消费级GPU兼容,能在RTX 4090上约4分钟内生成5秒480P视频。
■ 多任务能力:擅长文本到视频、图像到视频、视频编辑、文本到图像和视频到音频的转换,推动了视频生成领域的发展。
2、技术亮点:
■ 中英文文本生成:首个能生成中英文文本的视频模型,增强了其实用性。
■ 高清视频生成:I2V-14B模型能生成720P高清视频,经过数千轮人工评估,性能优于闭源和开源替代方案。
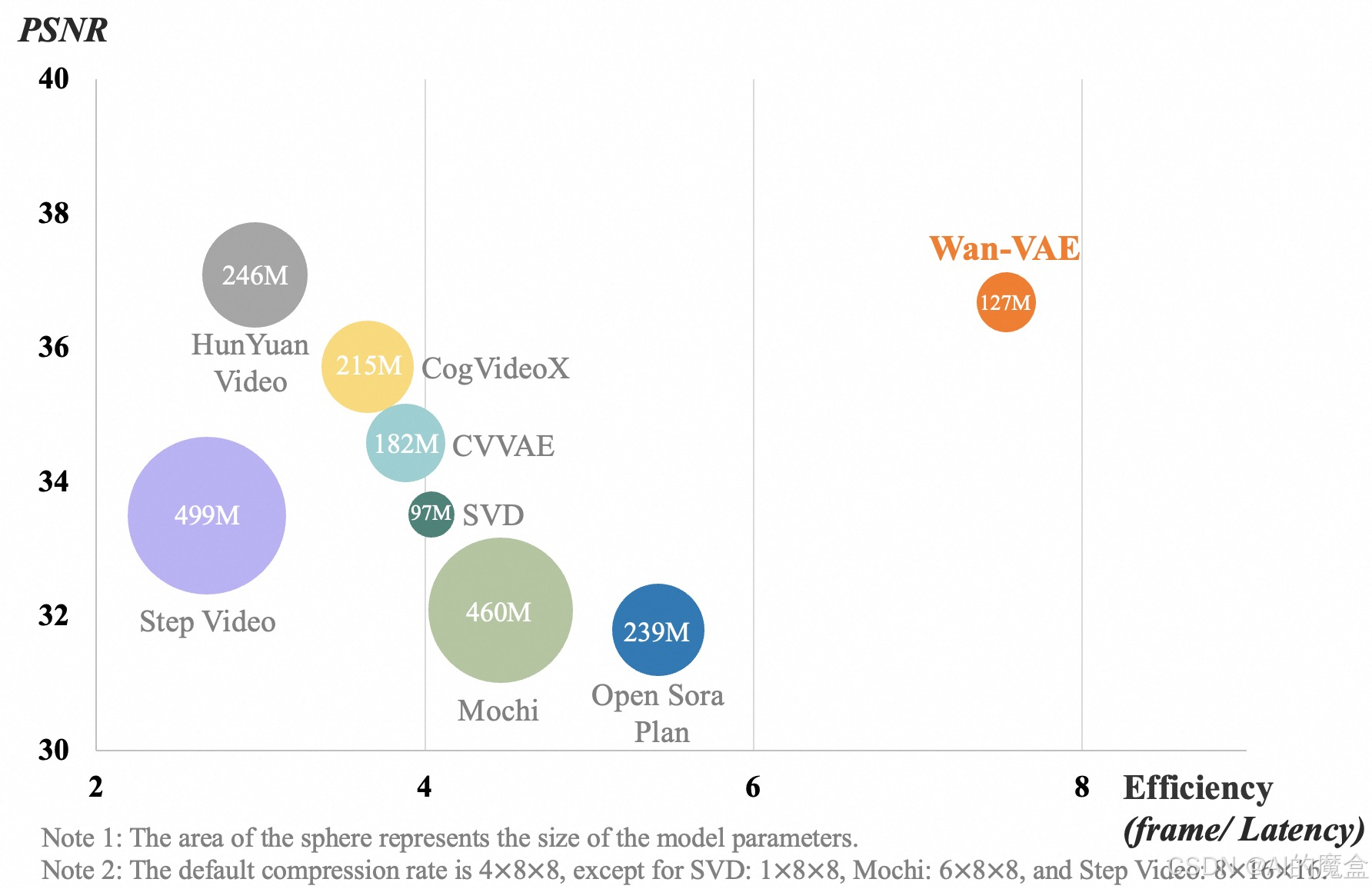
■ 3D变分自编码器:提出新型3D因果VAE架构Wan-VAE,提高了时空压缩效率,降低了内存使用。
3、使用教程:
■ 下载与安装:提供模型下载链接,指导用户克隆仓库、安装依赖项。
■ 推理代码:发布了推理代码和权重,用户可根据提供的示例运行生成视频。
■ 不同GPU上的计算效率:给出了在不同GPU上测试的计算效率数据,包括总时间和峰值GPU内存。
| 模型 | 下载链接 | 笔记 |
|---|---|---|
| T2V-14B | 🤗 Huggingface 🤖 ModelScope | 支持 480P 和 720P |
| 型号 I2V-14B-720P | 🤗 Huggingface 🤖 ModelScope | 支持 720P |
| 型号 I2V-14B-480P | 🤗 Huggingface 🤖 ModelScope | 支持 480P |
| T2V-1.3B | 🤗 Huggingface 🤖 ModelScope | 支持 480P |
4、技术架构:
■ 视频扩散DiT:采用Flow Matching框架,结合主流扩散Transformer范式,使用T5编码器编码多语言文本输入。
■ MLP调制:每个Transformer块使用一个共享的MLP预测调制参数,每个块学习不同的偏差集。
5、数据集与比较:
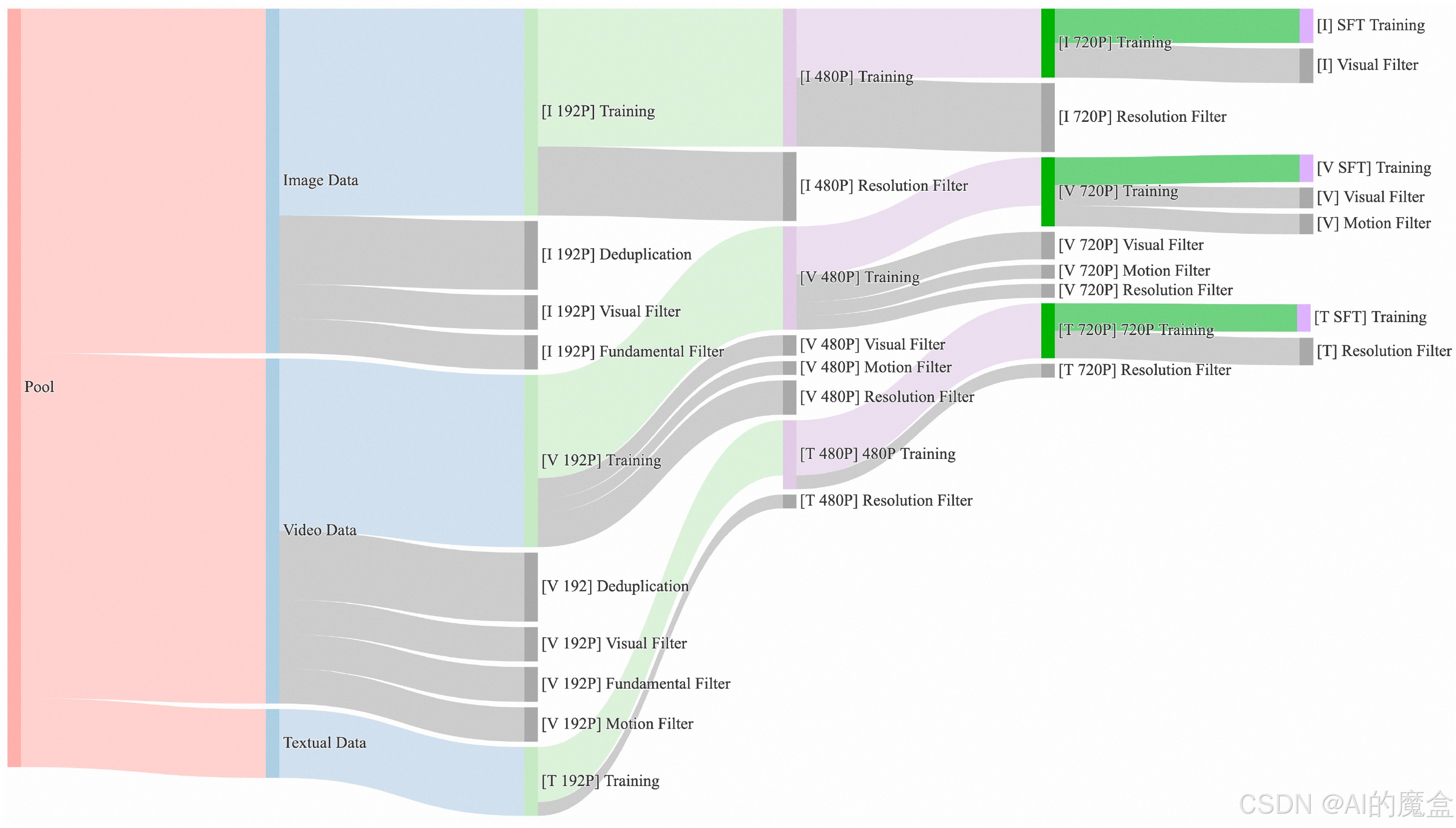
■ 数据集:经过精心策划和去重的数据集,包含大量图像和视频数据,经过四步数据清洗过程。
■ 与最先进的模型比较:使用内部设计的1,035个提示,在14个主要维度和26个子维度上进行测试,评估Wan2.1的性能。
6、对我们的启发意义:
■ 技术创新:Wan2.1的技术架构和创新点展示了视频生成领域的最新进展,鼓励进一步的技术研发。
■ 应用前景:多任务能力和高清视频生成能力为视频创作、广告、影视制作等行业提供了广阔的应用前景。
请持续关注,接下来我将会亲自实操,部署通义万相2.1-图生视频模型,我们一起尝尝鲜,请持续关注哟!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)