基于 Python + Django 的微博就业舆情分析系统
本开发文档详细描述了微博就业舆情分析系统的项目结构、核心功能、数据库设计、前端设计以及开发环境与部署方式。该系统旨在通过爬取微博平台的就业相关数据,并进行情感分析和舆情趋势分析,最终为相关决策提供科学的数据支持。项目具体演示效果:【S2023072基于python+Django爬虫的微博就业舆情分析可视化分析系统】
一、研究背景及意义
随着信息技术的发展,社交媒体平台成为了公众表达观点、情感和意见的主要渠道。微博,作为中国领先的社交媒体平台之一,拥有大量关于就业市场、职业发展等话题的讨论。这些讨论反映了社会对就业形势、政策变化等方面的看法和情绪,构成了一个重要的舆情数据来源。
在就业问题日益关注的背景下,舆情分析能够为政府、企业以及学术界提供重要的决策依据。通过分析微博平台上的就业舆情数据,可以有效把握社会公众对就业形势的态度,识别出潜在的社会热点问题,为制定政策、调整招聘策略、规划教育等提供数据支持。
本课题旨在基于 Python 和 Django 技术,构建一个微博就业舆情分析系统,抓取微博数据,进行情感分析和舆情趋势分析,帮助相关部门和机构了解就业舆情的发展动态。
二、研究目标
- 微博数据抓取:开发一个系统,能够自动抓取微博上关于就业的内容,收集相关的微博数据。
- 情感分析:利用自然语言处理技术,对微博数据进行情感分析,识别出正面、负面和中性的情感倾向,进行量化处理。
- 舆情趋势分析:基于时间维度,分析微博数据中的就业舆情趋势,发现舆情的热度变化、热点话题以及可能的舆情危机。
- 结果展示:通过可视化手段,将分析结果以图表或其他形式展示在前端页面,供用户查询和分析。
三、研究内容
本课题的研究内容主要包括以下几个方面:
-
微博数据采集与预处理:
- 利用微博开放的 API 或爬虫技术,从微博平台采集与就业相关的微博数据。
- 对收集到的微博数据进行清洗,去除噪声数据,确保数据的有效性和完整性。
-
情感分析模型的构建:
- 使用自然语言处理(NLP)技术,构建情感分析模型,对微博内容进行情感倾向的分类(正面、负面、中性)。
- 采用机器学习或深度学习方法,训练情感分析模型,并优化其准确性。
-
舆情趋势分析:
- 基于微博内容的时间戳,分析不同时间段的舆情变化,识别就业领域的热点问题和舆情变化趋势。
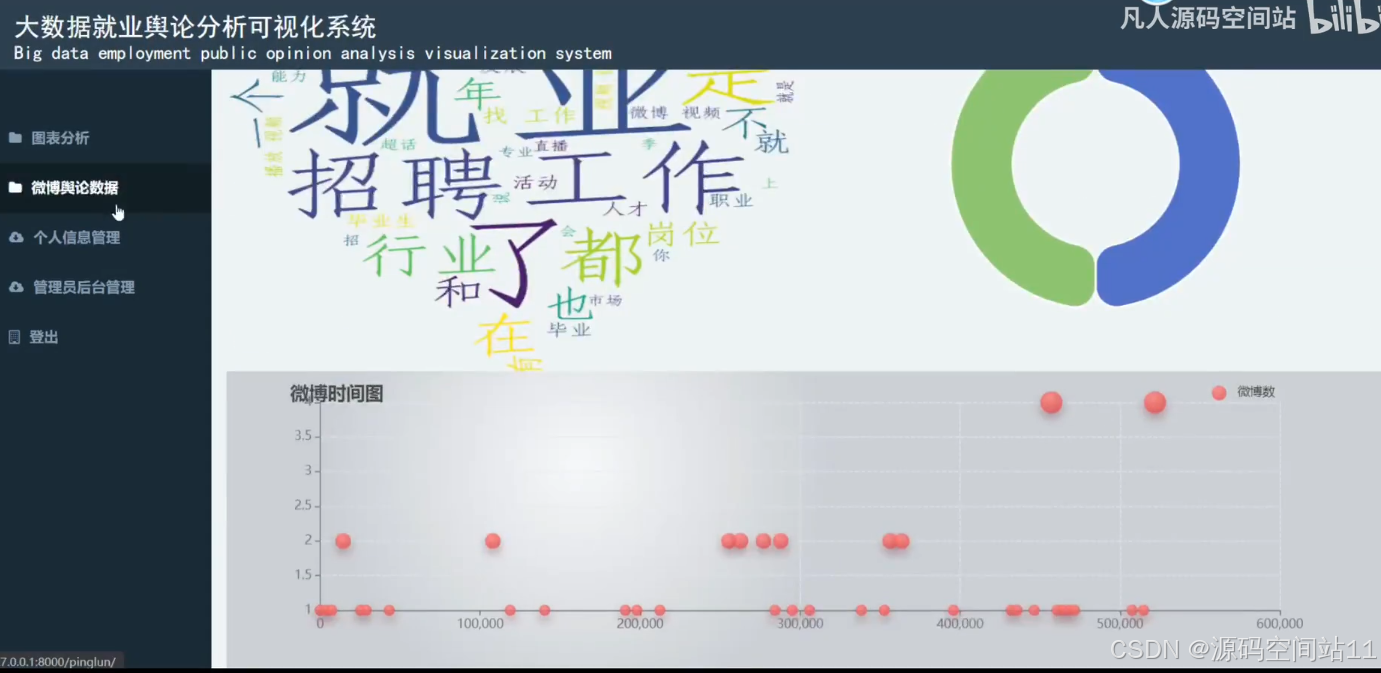
- 提供舆情热度图、情感波动图等可视化图表,直观展示舆情走势。
-
系统开发与实现:
- 使用 Python 和 Django 框架开发该系统,实现前后端的功能,包括微博数据的抓取、情感分析、舆情趋势分析、数据存储与展示等。
- 前端使用 Django 模板系统和静态资源,展示分析结果并提供交互功能。
-
系统评估与优化:
- 对系统的分析结果进行评估,验证情感分析和舆情趋势分析的准确性和可行性。
- 根据评估结果对模型进行优化,提升分析精度和系统稳定性。
四、研究方法
本研究将采用以下几种主要研究方法:
- 数据采集:通过微博 API 或爬虫技术获取就业相关的微博数据。
- 自然语言处理:使用自然语言处理技术进行文本分析,利用情感分析算法对微博内容进行分类。
- 时间序列分析:基于时间数据进行舆情趋势分析,识别舆情波动和热点问题。
- 可视化技术:利用图表和数据可视化技术,展示情感分析和舆情趋势分析的结果。
- Django 开发框架:基于 Django 框架开发 Web 系统,实现前后端交互和数据展示。
五、技术路线
- 数据采集:
- 使用微博开放 API(如微博开放平台提供的 API)或自定义爬虫(基于 Python 的 Scrapy 或 BeautifulSoup 等库)获取与就业相关的微博内容。
- 数据处理:
- 使用 Python 的 pandas 库进行数据清洗和预处理,去除无关数据,提取关键词、发布时间等信息。
- 情感分析:
- 基于 Python 的 NLP 库(如 NLTK、TextBlob、jieba)进行中文文本的情感分析。
- 采用机器学习(如支持向量机 SVM、随机森林等)或深度学习(如 LSTM、BERT 等)对微博文本进行情感分类。
- 舆情分析:
- 使用时间序列分析方法,分析不同时间段的舆情变化。
- 利用 Python 的 matplotlib 或 seaborn 等库进行数据可视化,展示舆情趋势和情感波动。
- 系统实现:
- 使用 Django 框架开发后台管理系统,处理数据存储和用户请求。
- 使用 HTML、CSS、JavaScript 构建前端页面,展示分析结果和互动功能。
六、预期成果
- 微博就业舆情分析系统:
- 一个可以实时采集微博数据,并进行情感分析和舆情趋势分析的系统。
- 舆情分析报告:
- 通过系统生成舆情分析报告,提供就业领域的舆情数据分析结果。
- 可视化图表:
- 提供舆情热度图、情感分析图等可视化展示,帮助用户快速理解舆情变化。
技术介绍部分:
2. 项目结构
项目文件夹结构如下:
- data/ # 存放数据文件,可能包括爬取或分析的数据 - db.sqlite3 # SQLite 数据库文件,存储系统数据 - keshihua/ # 可能与数据处理、可视化相关的文件 - manage.py # Django 项目的管理脚本 - static/ # 静态文件,包含 CSS、JS 和图片等 - templates/ # Django 模板文件,用于渲染 HTML 页面 - weibo/ # 处理微博数据采集、分析的核心模块
各个目录和文件的作用:
data/: 该目录通常存放爬取或导入的原始数据,可能包括微博数据、就业舆情数据等。db.sqlite3: 项目的数据库文件,存储系统所需的所有数据。keshihua/: 该目录包含与数据预处理、分析、可视化相关的内容。manage.py: 该文件用于管理 Django 项目,包括数据库迁移、开发服务器启动等操作。static/: 存放项目的静态资源文件,包括 CSS 样式文件、图片和 JavaScript 文件等。templates/: 存放 Django 模板文件,用于生成动态的 HTML 页面。weibo/: 存放与微博数据采集、舆情分析等相关的 Python 模块。
3. 核心功能分析
3.1 数据采集和分析
系统的核心功能是从微博平台抓取就业相关的舆情数据并进行情感分析和舆情趋势分析。
- 数据采集:通过微博 API 或爬虫技术从微博平台获取相关微博内容。该部分功能可能位于
weibo/目录中。 - 情感分析:通过自然语言处理(NLP)算法分析微博内容的情感倾向,识别舆情的正面、负面或中性情感。
- 舆情趋势分析:分析一段时间内关于就业的微博内容,挖掘舆情热点和趋势变化。
3.2 数据存储和管理
所有的数据将存储在 db.sqlite3 数据库中。数据库设计如下:
- 微博数据表:存储从微博抓取的内容,包括微博发布者、发布时间、微博内容等。
- 情感分析结果表:存储情感分析的结果,包括微博的情感倾向、分析时间等。
- 舆情趋势表:存储舆情的时间变化趋势和热点内容。
3.3 数据展示与交互
- 前端展示:系统使用 Django 模板语言渲染 HTML 页面,展示微博数据、情感分析结果和舆情趋势图。
- 用户交互:用户可以通过前端界面选择不同的时间范围、分析维度等,查看相关的舆情分析结果。
4. 数据库设计
数据库的主要设计元素包括微博数据表、情感分析结果表和舆情趋势表。
4.1 数据库表结构
- 微博数据表:
id: 主键,唯一标识每条微博。content: 微博内容。author: 微博发布者。timestamp: 微博发布时间。
- 情感分析结果表:
id: 主键,唯一标识每条情感分析记录。weibo_id: 外键,关联微博数据表中的微博。sentiment: 情感分析结果(如正面、负面、中性)。analysis_time: 情感分析的时间。
- 舆情趋势表:
id: 主键,唯一标识每条舆情趋势记录。timestamp: 时间戳,表示趋势分析的时间点。hot_topic: 热点话题内容。trend_value: 舆情趋势值,表示话题的热度或影响力。
4.2 数据库迁移
使用 Django 的 migrate 命令来执行数据库迁移,确保数据库结构与模型保持一致。
5. 前端设计
5.1 静态资源
在 static/ 目录中,存储了所有的静态资源文件,包括:
- CSS 文件:控制页面的样式,包括字体、颜色、布局等。
- JavaScript 文件:实现页面的动态功能,如数据交互、图表展示等。
- 图片文件:用于页面展示,如图标、背景图片等。
5.2 模板文件
在 templates/ 目录中,存放 Django 模板文件,用于生成动态 HTML 页面。模板文件包括:
- 数据展示页面:展示微博数据、舆情分析结果等。
- 用户交互页面:用户可以选择分析维度、时间范围等进行数据查询和展示。
6. 开发环境和部署
6.1 开发环境配置
- Python 版本:使用 Python 3.x 版本。
- Django 版本:根据
requirements.txt安装指定版本的 Django。 - 数据库:SQLite 数据库默认配置,可以根据需要修改为其他数据库(如 MySQL 或 PostgreSQL)。
6.2 安装依赖
运行以下命令来安装项目依赖:
pip install -r requirements.txt
6.3 数据库迁移
使用以下命令执行数据库迁移:
python manage.py migrate
6.4 启动开发服务器
使用以下命令启动 Django 开发服务器:
python manage.py runserver
开发服务器将在本地启动,您可以在浏览器中访问 http://127.0.0.1:8000 来查看项目。
6.5 部署到生产环境
- 配置生产环境数据库(例如 MySQL 或 PostgreSQL)。
- 配置静态文件处理,确保静态资源能够正确加载。
- 使用生产环境服务器(如 Gunicorn)和反向代理服务器(如 Nginx)来部署应用。
7. 总结
本开发文档详细描述了微博就业舆情分析系统的项目结构、核心功能、数据库设计、前端设计以及开发环境与部署方式。该系统旨在通过爬取微博平台的就业相关数据,并进行情感分析和舆情趋势分析,最终为相关决策提供科学的数据支持。
项目具体演示效果:
【S2023072基于python+Django爬虫的微博就业舆情分析可视化分析系统】 https://www.bilibili.com/video/BV1Re4y1g7XU/?share_source=copy_web&vd_source=3d18b0a7b9486f50fe7f4dea4c24e2a4

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 20
20 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)