
小白也能看懂的Chat-GPT生成式模型的生成原理(decoder架构)
他是通过你的上文来进行联想(不仅限于上文的最后一个字或者词,而是整个上文),当然他也是一个字词一个字词生成的,第一次它会根据你提供给它的上文生成一个字词,然后往下怎么说呢?多个头从不同的角度关注文本里不同特征或方面,比如有的关注动词,有的关注修饰词,有的关注修饰词,有的关注情感,有的关注命名实体等等。但Gpt说话的方式则非常不一样,它的做法是每次接话尾,它每次都会根据已经有的内容现想,一个词一个词
一、Gpt和人类说话的异同
当我们在和Gpt聊天的时候,他会一点一点的说话,这看上去就像是一个活生生的人也在向我们打字一样。那Gpt真的是按照人类的思维在说话呢?严格来说其实不是这样的。先想想我们自己是怎么说出一句话的?其实我们在说话的时候都是先有想法的,再根据想法组织语言。说出某句话之前,我们脑海中已经大概有这句话的感觉、以及结构了,然后再一个字一个字的从嘴里蹦出来,说出这段话。
但Gpt说话的方式则非常不一样,它的做法是每次接话尾,它每次都会根据已经有的内容现想,一个词一个词往后猜,属于是脚踩西瓜皮滑到哪里算哪里,所以当大模型一句话说到半截的时候,他根本不知道后面的内容是什么。
有些人就会觉得像这样一个字一个字的往后猜一定行不通,它肯定很傻。虽然这么想很正常,但是你没想对,关于预测下一个词接下来将会逐步详解。
二、One Gram Model
输入法的联想,你随便输入某一个字,然后一直点击第一选项(第一个是最常用的)。这样输入法看起来是不是就像在说话了?但是我们试过都知道,他说出来的话完全不通顺,每个局部都是连接的很好的搭配的词,但合起来却不知所云,
事实上,输入法的这种联想就是一种最简单的语言模型。
One Gram Model:每次只看到文本最后面的一个词或者字,然后接上一个最常见(概率最高)紧着这个(词或者字)的搭配。
三、浅析Gpt回答逻辑
我们再次回到gpt部分,那gpt究竟是怎么回答的呢?
答案是:gpt的原理和刚刚提到的那个(one gram model)概念很像。他是通过你的上文来进行联想(不仅限于上文的最后一个字或者词,而是整个上文),当然他也是一个字词一个字词生成的,第一次它会根据你提供给它的上文生成一个字词,然后往下怎么说呢?它会把问题和自己生成的字词和重新组装为上文,再次作为大模型的输入去让大模型进行联想,然后生成下一个词。如此循环往复,就会像说话一样返回给我们结果。
把它自己生成的“下一个字”和“之前的上文”组合成“新的上文”,再让它以此生成“下一个字”。不断重复,就可以生成任意长的下文了。该过程也叫做“自回归生成”。
四、影响Chat GPT生成结果的因素
主要有两个,“上文”和“模型”,“模型”就相当于Chat GPT的大脑。
我们为了让chat GPT 生成我们想要的结果,而非混乱生成,就需要提前训练cheat GPT t的大脑,也就是训练他的模型。
这是GPT-3的训练数据,可以看到训练的数据量非常大,也分很多种。
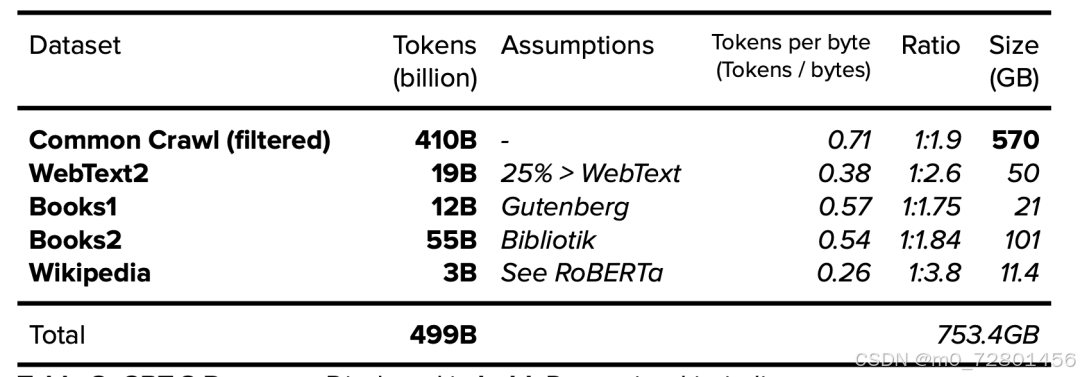
Common Crawl:网络爬虫公开数据集(海量互联网内容)
WebText2:Reddit论坛的网页文本
Books1,Books2:互联网书籍语料库
Wikipedia:整个英文危机百科知识库
Gpt在投入使用前会利用海量的文本自行学习人类语言的语法语义,了解表达结构和模式。

怎么学的呢?那具体来说,模型会先看到一部分文本,基于上下文尝试预测下一个字词,然后通过比较正确答案和他的预测,更新模型,从而逐渐能根据上文来生成合理的下文。Gpt随着见过的文本越来越多,它生成的能力也会越来越好。也就是说它掌握的信息和知识越多就越有可能准确预测下一个词,反之则越不靠谱。
举例说明GPT训练过程
例如当我们把登鹳雀楼作为学习材料来训练chat GPT t时,就不断调整它的模型。
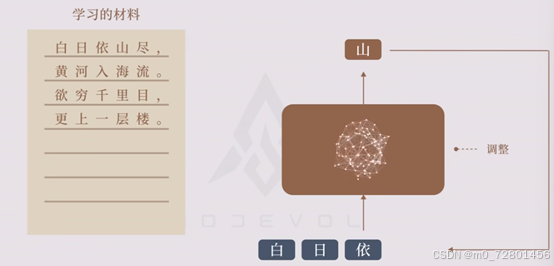
使得给它白,它能生成“日”。
给他白日,它能生成“依”。
如果生成的不对就根据答案调整模型。如此循环往复,直到它生成整首诗。没学习前,她原本会胡乱生成,但学习后就可以在看到白日依山尽时,生成黄河入海流了。
那如果同时训练了白日依山尽和白日何短短,在遇到白日时会怎么生成下一个字?
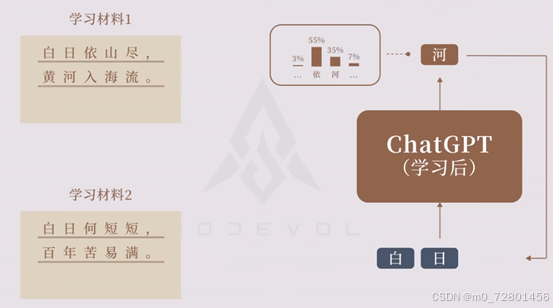
chat GPT 会给出这样的结果,这是要生成的下一个字的概率分布。下一个字就是按照概率分布抽样得到的结果,有可能生成“一”,也有可能生成“和”。由于抽样结果具有随机性,所以chat GPT t的回答并不是每次都一样。
训练的作用?
1. 生成神经网络结构
2. 生成高质量的词向量
五、gpt的回答的生成原理?继续深挖它是怎么想的
通过训练gpt的脑子中已经有了相关的知识的记忆,那它是怎么思考去说话的呢。怎么运用说出来的呢。
复习一下:
我们刚刚提到他的原理是接话尾,结合one gram model,那他接话的时候每次说的下一个字词是根据都是通过预测出现概率最高的下一个词。不断地自回归生成,说出完整的话。
但是模型具体到底是如何直到接下来要选择那个词呢?
大语言模型技术原理就不得不说Transformer架构,它可以被看作又由两个核心部分组成,编码器 encode 以及解码器 decoder
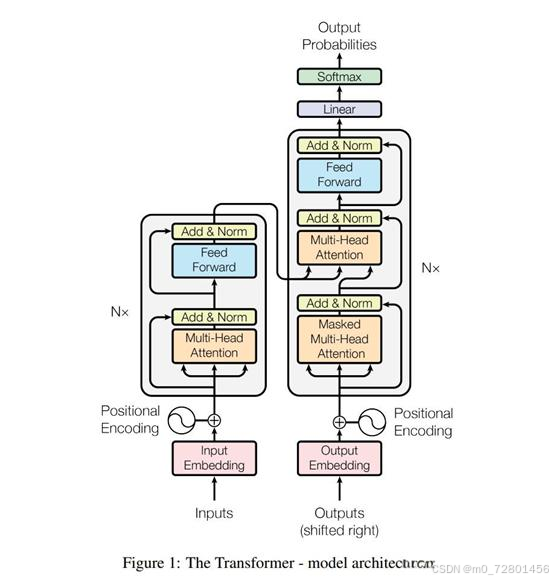
完整的Transformer模型包括encoder和decoder,而GPT只使用了decoder部分
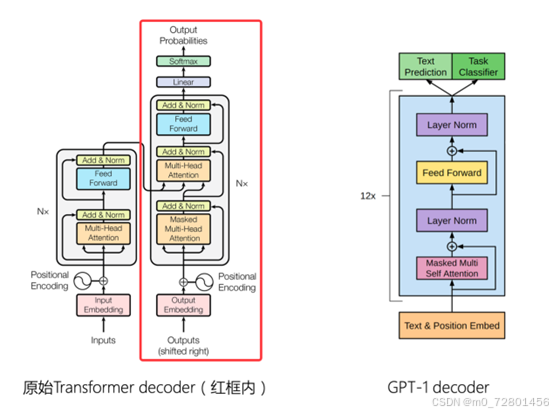
GPT使用了Transformer的解码器部分,同时舍弃了编码器中的交叉注意力机制层,保留了其余部分。整体上模型结构分为三部分:
- 输入层(Input Layer):将文本转换为模型可以处理的格式,涉及分词、词嵌入、位置编码等。
- 隐藏层(Hidden Layer):由多个Transformer的解码器堆叠而成,是GPT的核心,负责模型的理解、思考的过程。
- 输出层(Output Layer):基于隐藏层的最终输出生成为模型的最终预测,在GPT中,该过程通常是生成下一个词元的概率分布。
假如我们要这个机器人沟通,给编码器输入一句英文,那这个过程是怎样的呢?
We:To date, the cleverest thinker of all time was???
To date, the cleverest thinker of all time was???
输入的文本首先会被token化,也就是先把输入拆分成各个token,token可以被理解为是文本的一个基本单位(也可以称他为词元)。

短单词可能每个词是一个token,长单词可能被拆成多个token。
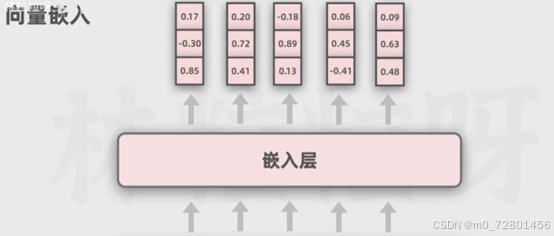
嵌入层: 将输入的单词或者符号转换成固定维度的向量表示,使其能够被模型处理。(因为计算机本身并不能处理文字等信息,需要将其转为向量来处理。)
再把它传入嵌入层,嵌入层的作用是然后让每个token都用向量表示,向量可以被简单的看为一串数字,为了能在画面里放下,这里把向量长度简化为三。
但实际中向量长度可以非常长。
问题来了,为什么要用一串数字表示各个token?
其中一个原因是一串数字能表达的含义是大于一个数字的,能包含更多语法,语义信息等等。
 To date, the cleverest thinker of all time was???
To date, the cleverest thinker of all time was???
这就好比我们去形容男人和女人。如果只用一个数字该怎么表示呢?如果这个数字代表的是性别这个维度,那这两个数字大小之间应该距离很大,还是应该距离很小呢?(这两个一男一女)
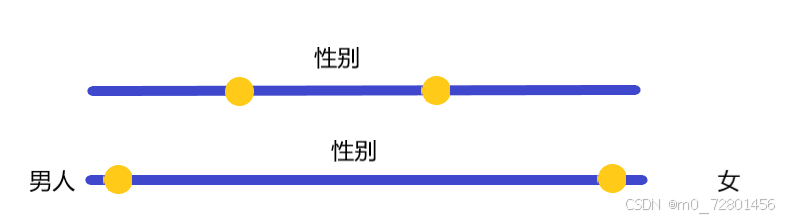
他俩的距离应该很远。
但如果用多个数字,也就是用更多维度的表示,就比如说第一个数字可以表示是雌性的程度,第二个表示年龄大的程度,第三个表示社会阶层高的程度。所以呢嵌入层的向量不是随便搞出来的,里面包含了词汇之间语法,语义等关系。相似的词所对应的嵌入向量在向量空间里距离也更近
而一些没啥关系的词之间的距离就更远,这有助于模型利用数学计算向量空间里的距离,去捕捉不同词在语义和语法等方面的相似性。而且呢男人与国王的差异和女人与女王的差异,(男人和男孩,女人和女孩)
可以被看作是相似的,这也可以在多维向量空间里展现。因此词向量不仅可以帮模型理解词的语义,也可以捕捉词与词之间的复杂关系。
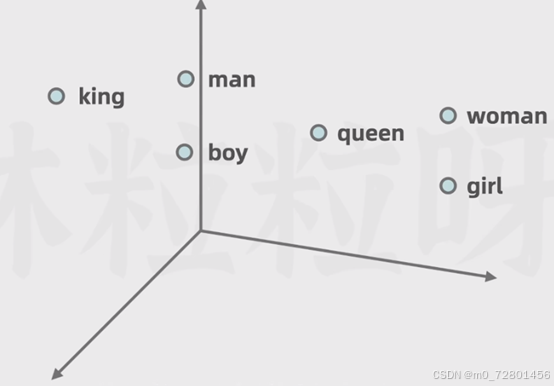
那我们这里为了直观是用三维向量空间表示的,把向量长度相应简化成了三,而提出transformer的论文里向量长度是512,gpt-3是12288。所以可以想象能包含多少信息。
通过编码器的嵌入层得到词向量后,下一步是对词向量进行位置编码。
Positional Encoding(位置编码):提供位置信息;位置编码根据各个词在文本里顺序生成位置编码向量。
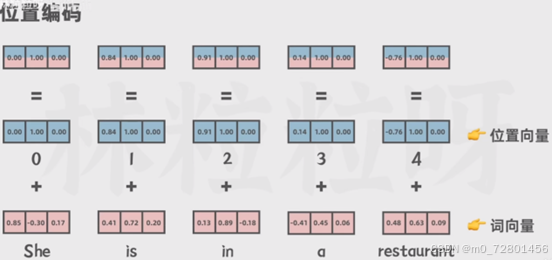
这样做的意义是够捕捉词在句子中的位置,方便后面大模型理解不同词之间的顺序关系。
现在我们拥有了嵌入层计算的输入文本的每个词的信息(属性),还有位置编码计算出来的顺序关系。
第一个 decoder模块处理单词的步骤如下
自注意力机制(Self-Attention Mechanism):模型在处理每个词的时候,不仅会关注这个词本身和它附近的词,还会关注输入序列中所有其他词,也正如transformer论文标题所说:Attention is all you need.

注意力就是你所需要的一切,自注意力机制通过计算每对词之间的相关性,也就是通过词向量来决定注意力权重,如果两个词之间的相关性更强,它们之间的注意力权重就会更高
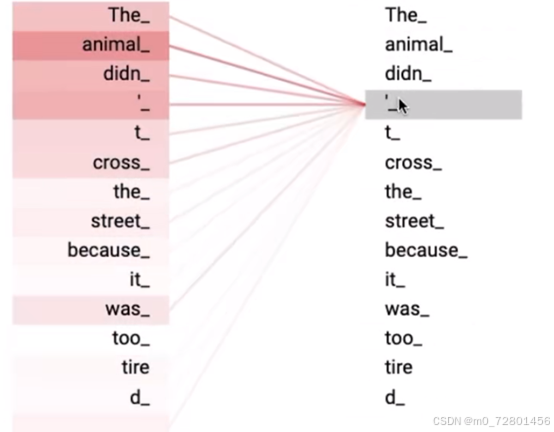
比如这个例子单从语法上来讲
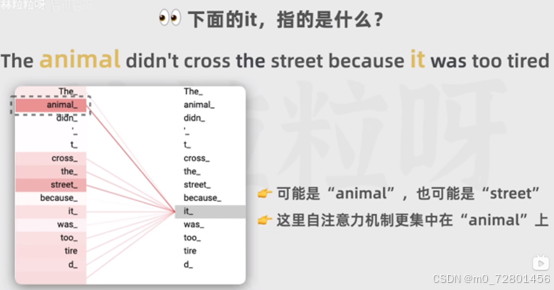
it可以指animal,也可以指street,而自注意力机制发现了it与animal更强的关联,所以给animal的权重会更大一些,也就是结合上下文理解一个词。
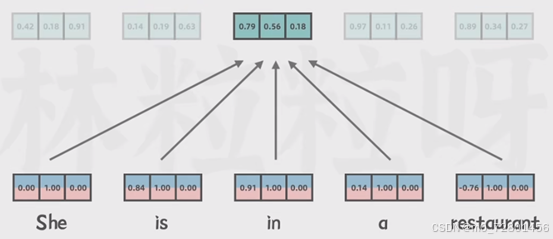
在输出的表示结果里,不仅包含这个词本身的信息,还融合了上下文中的相关信息。上下文在语言里很重要,也能揭露相同词的不同含义。
自注意力机制涉及到很多计算步骤,这里只是做个简单的科普,更多细节可以自行查阅。
这里使用了transformer的多头自注意力机制,也就是不只有一个自注意力模块,而是有多个。

多个头从不同的角度关注文本里不同特征或方面,比如有的关注动词,有的关注修饰词,有的关注修饰词,有的关注情感,有的关注命名实体等等。而且他们之间可以做并行运算,也就是计算进展上互不影响。从多个角度结合文本然后理解里面的每个词什么意思
它通过使用多个独立的注意力头,分别计算注意力权重,并将它们的结果进行拼接或加权求和,从而获得更丰富的表示。在多头自注意力后面还有一个前馈神经网络,他会对接自注意力模块的输出进行进一步的处理,增强模型的表达能力。
一个 decoder(解码器) 模块处理单词的步骤简单来说:首先通过自注意力层处理,接着将其传递给神经网络层。
第一个 decoder模块处理完但此后,会将结果向量被传入堆栈中的下一个 decoder模块,继续进行计算。有很多个decoder,每一个 decoder模块的处理方式都是一样的,但每个模块都会维护自己的自注意力层和神经网络层中的权重。

解码器同样是多个堆叠到一起的,这可以增加模型的性能,有助于处理复杂的输入输出关系
解码器的最后阶段,包含一个线性层和一个softmax层,他们俩加一块的作用是把解码器输出的表示转化为词汇表的概率分布

这个词汇表的概率分布代表下一个被生成token的概率。那么有些token的概率就会比其他的高。在大多数情况下,模型会选择概率最高的token作为下一个输出。
那现在我们知道了,解码器本质上是在猜下一个最可能的输出,至于输出是否符合客观事实模型无从得知。所以我们能经常看到模型一本正经的胡说八道,这种现象也被叫做幻觉.
解码器的一整个流程会重复多次,新的token会持续生成,直到生成的是一个用来表示输出序列结束的特殊token,那现在我们就拥有了来自解码器输出的完整序列。
六、Chat-GPT(未启用联网功能)和搜索引擎的区别
这里不提Chat-GPT启用联网搜索功能的情况
很多人都会错误地认为 Chat-GPT 是搜索引擎的升级版,是在庞大的数据库(可能有些人不懂,可以理解为图书馆、成千上万的资料)中,通过超高的运算速度找到最接近的内容,然后进行一些比对和拼接,最终给出结果。
但实际上 Chat-GPT 并不具备那种搜索能力,因为在训练过程中,学习材料(数据库的数据)并没有被保存在模型中,学习材料的作用只是调整模型以得到通用模型。(可以理解为被大模型的大脑记住了)
为的是能处理未被数据库记忆的情况,所有结果都是通过所学到的模型根据上文逐字生成的。因此 Chat-GPT 也被称为生成模型。
生成模型与搜索引擎非常不同,搜索引擎无法给出没被数据库存储的信息,但生成语言模型可以还能创造不存在的文本,这正是它的长板。(就像我们人类学习知识一样,学会了算数的计算方式,即使我们没有背1+1=2,我们也可以通过学会的计算方式计算出结果)
但他却有些搜索引擎没有的短板,首先就是搜索引擎不会混淆记忆,也就是不会搜出来不存在的东西。但大模型是学习语言单位之间的规律,用学到的规律来生成答案,然而这这也意味着,如果出现了实际不同,但碰巧符合同一规律的内容模型,就有可能混淆它。
最直接的结果是:若现实中不存在的内容,刚好符合他从训练材料中学到的规律,那chat GPT就有可能对不存在的内容,进行合乎规律的混合捏造。
例如我问他:三体人为什么害怕大脸猫的威慑,62年都不敢殖民地球?
这个问题并不存在,但又刚好符合他曾训练过的科幻材料中的规律。于是他就用科幻材料中所学到的规律开始混合捏造。这也是为什么当有人问他事实性内容时,可能会看到他胡说八道。
一开始生成式大模型是没有联网功能的,所以此时的大模型不能像搜索引擎一样获取时事。大模型的知识、记忆获取并不能像搜索引擎一样更新数据库就可以,还需要靠训练才能进入它的脑子,但是大模型训练的成本又很高,所以不会即时的把时事训练到到他的脑子里。我们可以看到用来训练大模型的数据集是有截止时间的,它只知道这个时间之前的事,往后的事情、时事它一概不知,你问它,它倒是有可能瞎编。

七、引用
GPT中的Transformer架构以及Transformer 中的注意力机制

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)