最基础的大模型入门教程,手撸RAG基本原理代码,适合JAVA等传统项目开发人员。
各大开发平台申请模型例如:智谱开放平台,目前旗下模型glm-4-flash可以免费使用。在模型网站下载开源模型,如Hugging Face(需要科学上网),国内可以在ModelScope下载,具体操作步骤以及硬件要求见官网。
一、大模型选择
-
各大开发平台申请模型
例如:智谱开放平台,目前旗下模型glm-4-flash可以免费使用。
-
在模型网站下载开源模型,如Hugging Face(需要科学上网),国内可以在ModelScope下载,具体操作步骤以及硬件要求见官网。
二、模型对话
以智谱开放平台glm-4-flash模型为例
初体验
- 安装openai
pip install openai
- 编码
from openai import OpenAI
client = OpenAI(
api_key="You Key",
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
completion = client.chat.completions.create(
model="glm-4-flash",
messages=[
{"role": "user", "content": "你是谁?"}
],
top_p=0.7,
temperature=0.9
)
print(completion.choices[0].message)
ChatCompletionMessage(content=‘我是一个名为 ChatGLM 的人工智能助手,是基于清华大学 KEG 实验室和智谱 AI 公司于 2024 年共 同训练的语言模型开发的。我的任务是针对用户的问题和要求提供适当的答复和支持。’, refusal=None, role=‘assistant’, audio=None, function_call=None, tool_calls=None)
流式输出
from openai import OpenAI
client = OpenAI(
api_key="You Key",
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
response = client.chat.completions.create(
model="glm-4-flash",
messages=[
{"role": "user", "content": "你是谁?"}
],
top_p=0.7,
temperature=0.9,
stream=True
)
for chuck in response:
print(chuck.choices[0].delta.content, "|", end="")
我是一个 |名为 | Chat |GL |M | |的人工 |智能 |助手 |, |是基于 |清华大学 | K |EG | 实 |验 |室 |和 |智 |谱 | AI | 公司 |于 | |202 |4 | 年 |共同 |训练 |的语言 |模型 |开发的 |。 |我的 |任务是 |针对 |用户 |的问题 |和要求 |提供 |适当的 |答复 |和支持 |。 | |
三、应用案例之RAG
RAG (Retrieval-Augmented Generation),中文一般译为检索增强生成(听着挺奇怪的),最早由Facebook AI Research(现Meta AI)的研究人员在2020发表论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》。通过检索本地文档与大预言模型的文本生成能力结合,使得RAG成为目前大语言模型成熟应用之一。
先讲代码再讲理论。
from langchain_community.document_loaders import PyPDFLoader
# 1. 读取文本
file = "./浦发银行2023年第一季度报告.pdf"
loader = PyPDFLoader(file)
pages = loader.load()
print(pages[0].page_content)
# 2. 文本切割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=20,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.split_documents([pages[0],pages[1],pages[2]]) # 这里先简单的拆分3段
text_contents: list[str] = [t.page_content for t in texts]
print(texts[0])
# 查看里面的内容
for t in texts:
print("page_content:", t.page_content)
print("page:", t.metadata.get('page') or 0)
print("file_name:", t.metadata.get('source'))
# 3. 对切割的文本进行ebmedding
from langchain_huggingface import HuggingFaceEmbeddings# 这里采用的ebmeding模型是m3e-base,请填写自己的实际路径
embedding_path = "D:\python\project\clj_glm\models\m3e-base"
model_kwargs = {'device': "cuda" if torch.cuda.is_available() else "cpu"}
encode_kwargs = {'normalize_embeddings': False}
embedding_model = HuggingFaceEmbeddings(model_name=embedding_path,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs)
# embeddings = embedding_model.encode([t.page_content for t in texts]) 向量化
# 4.存储向量数据
from langchain_community.vectorstores import FAISS
faiss: FAISS = FAISS.from_texts(text_contents, embedding_model)
file_faiss = "./faiss_file/"
index_name = "pfbank"
faiss.save_local(file_faiss, index_name=index_name)
# 5.检索向量数据
# 本地加载向量数据
# faiss: FAISS = FAISS.load_local(file_faiss, embedding_model, allow_dangerous_deserialization=True)
question = "浦发银行的股东都有谁?"
retrieval_texts = faiss.similarity_search(question, 2)
print(retrieval_texts)
retrieval_content = "\n".join([t.page_content for t in retrieval_texts])
# 6.与大模型对话
# 定义提示词
prompt = """
<指令>
根据已知信息,简洁和专业的来回答问题,不允许在答案中添加编造成分,答案请使用中文。
如果无法从中得到答案,请说 "根据已知信息无法回答该问题"。
</指令>
<已知信息>{context}</已知信息>
<问题>{question}</问题>
"""
from openai import OpenAI
client = OpenAI(
api_key="You Key",
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
completion = client.chat.completions.create(
model="glm-4-flash",
messages=[
{"role": "user", "content": prompt.format(context=retrieval_content, question=question)}
],
top_p=0.7,
temperature=0.9
)
print(completion.choices[0].message.content)
以上代码所需依赖

根据上面的代码就实现了RAG的功能,使用到的组件如下:
- embedding模型是m3e-base,其他模型需要自行下载,也可以使用在线embedding模型。
- 本例使用的向量数据是FAISS。
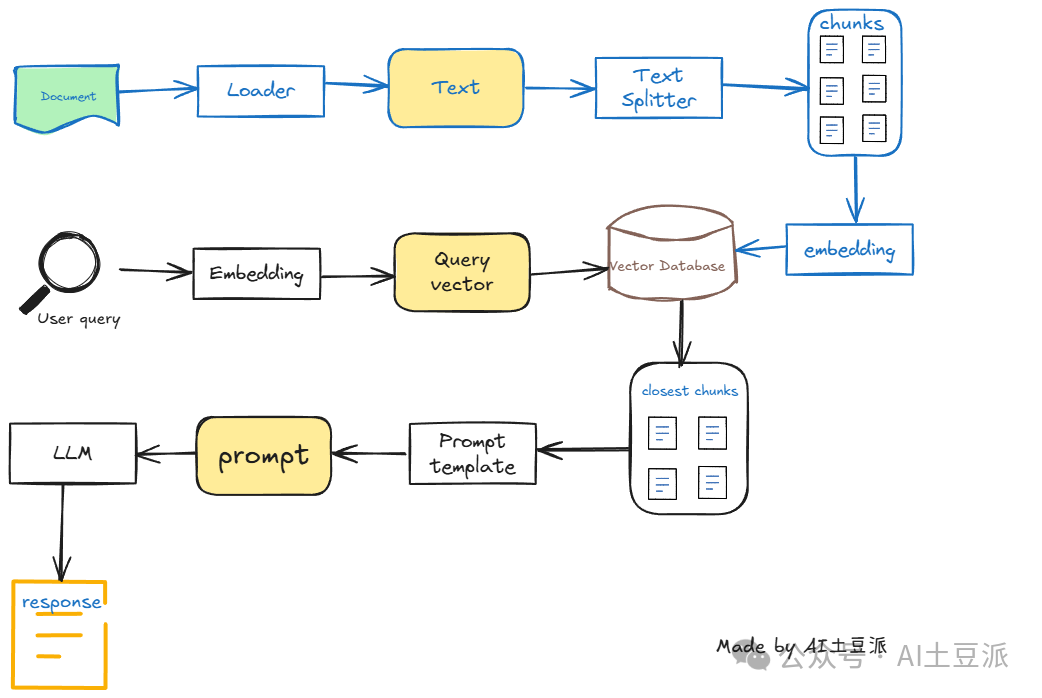
下面的流程图就讲述了RAG的实现原理,主要分为两个流程:
- 系统加载文档解析,切割后的文本通过向量化并存储到向量库。
- 用户搜索,经过向量化的问题在向量库中进行相似度搜索,讲匹配到的文本数据经过prompt组合传入大模型并响应。
这只是一个简单的RAG原理展示。在实际场景中,还会有很多的问题,比如:检索准确率低,召回完整性不够,导致LLM幻觉严重的问题,在之后将会分析如何优化RAG。
本文参考:
Langchain官方文档:https://python.langchain.com/
原论文出处:https://arxiv.org/pdf/2005.11401
m3e-base 模型下载:https://modelscope.cn/models/AI-ModelScope/m3e-base
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)