开源、离线、免费商用的大模型知识库来袭!快速搭建个人和企业私有智能知识库!
项目名称:Langchain-Chatchat``项目地址:https://github.com/chatchat-space/Langchain-Chatchat📺 原理介绍视频(点击可看视频)
你是否也有这样的桌面?为了方便找材料,全部放到了桌面,最后结果就是“用起一时爽,找起火葬场”。
(图片来源于网络)
你是否也是盘即个人电脑磁使再怎么不够用,也舍不得删除几年前做的运维方案、架构方案、设计方案文档?最后即使文档都保存了,存云盘了,到用的时候依旧发现找不到,找的也不是想要的。
|大模型知识库来袭
现在不用再担心了找不到材料文档了,GitHub开源了一款可离线,支持检索增强生成(RAG)大模型的知识库项目。虽然开源时间不长,但是势头很猛,已经斩获25K Star。具备以下特点:
|
总结下重点就是:
-
支持中文,可私有化部署,免费商用!
-
支持中文,可私有化部署,免费商用!
-
支持中文,可私有化部署,免费商用!
重要的事情说三遍
项目名称:Langchain-Chatchat``项目地址:https://github.com/chatchat-space/Langchain-Chatchat
📺 原理介绍视频(点击可看视频)
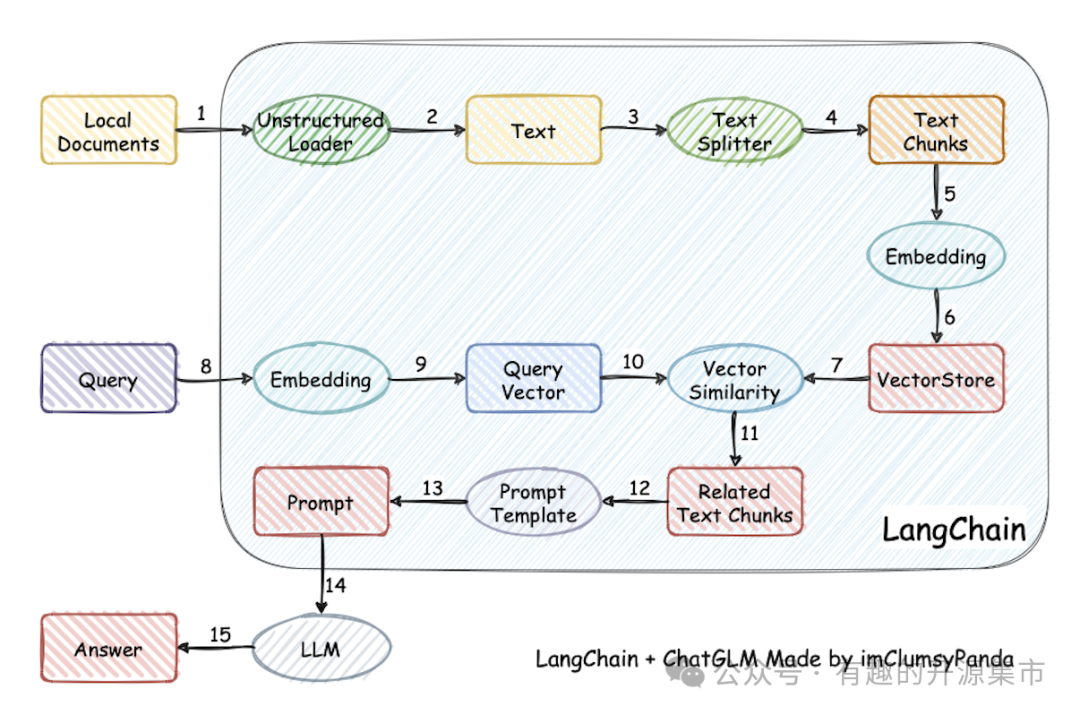
从文档处理角度来看,实现流程如下:
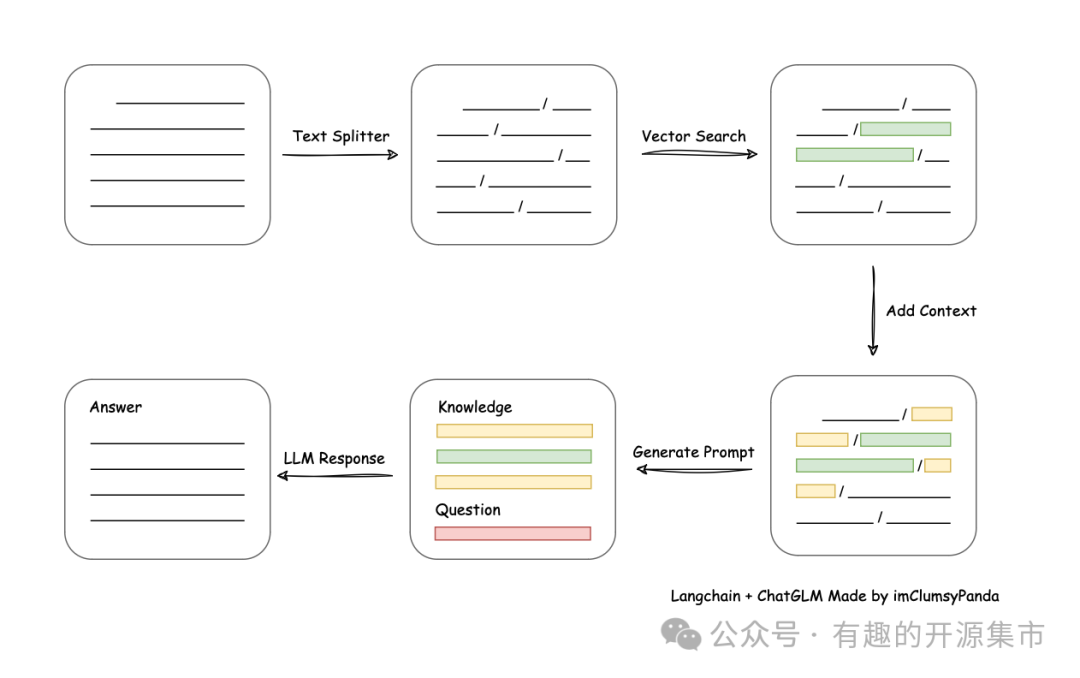
技术路线图:
-
Langchain 应用
-
基础React形式的Agent实现,包括调用计算器等
-
Langchain 自带的Agent实现和调用
-
智能调用不同的数据库和联网知识
-
Bing 搜索
-
DuckDuckGo 搜索
-
Metaphor 搜索
-
接入非结构化文档
-
结构化数据接入
-
分词及召回
-
.txt, .rtf, .epub, .srt
-
.eml, .msg
-
.html, .xml, .toml, .mhtml
-
.json, .jsonl
-
.md, .rst
-
.docx, .doc, .pptx, .ppt, .odt
-
.enex
-
.pdf
-
.jpg, .jpeg, .png, .bmp
-
.py, .ipynb
-
.csv, .tsv
-
.xlsx, .xls, .xlsd
-
接入不同类型 TextSplitter
-
优化依据中文标点符号设计的 ChineseTextSplitter
-
本地数据接入
-
搜索引擎接入
-
Agent 实现
-
LLM 模型接入
-
支持通过调用 FastChat api 调用 llm
-
支持 ChatGLM API 等 LLM API 的接入
-
支持 Langchain 框架支持的LLM API 接入
-
Embedding 模型接入
-
支持调用 HuggingFace 中各开源 Emebdding 模型
-
支持 OpenAI Embedding API 等 Embedding API 的接入
-
支持 智谱AI、百度千帆、千问、MiniMax 等在线 Embedding API 的接入
-
基于 FastAPI 的 API 方式调用
-
Web UI
-
基于 Streamlit 的 Web UI
|大模型知识库来袭
Docker 部署
一行代码搞定,但是建议网速不好的同学不要尝试
docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.7
常规模式本地部署方案
1. 环境配置
# 首先,确信你的机器安装了 Python 3.8 - 3.10 版本``$ python --version``Python 3.8.13`` ``# 如果低于这个版本,可使用conda安装环境``$ conda create -p /your_path/env_name python=3.8`` ``# 激活环境``$ source activate /your_path/env_name`` ``# 或,conda安装,不指定路径, 注意以下,都将/your_path/env_name替换为env_name``$ conda create -n env_name python=3.8``$ conda activate env_name # Activate the environment`` ``# 更新py库``$ pip3 install --upgrade pip`` ``# 关闭环境``$ source deactivate /your_path/env_name`` ``# 删除环境``$ conda env remove -p /your_path/env_name
接着,开始安装项目的依赖
# 拉取仓库``$ git clone --recursive https://github.com/chatchat-space/Langchain-Chatchat.git`` ``# 进入目录``$ cd Langchain-Chatchat`` ``# 安装全部依赖``$ pip install -r requirements.txt`` ``# 默认依赖包括基本运行环境(FAISS向量库)。以下是可选依赖:``- 如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。``- 如果要开启 OCR GPU 加速,请安装 rapidocr_paddle[gpu]``- 如果要使用在线 API 模型,请安装对用的 SDK``
此外,为方便用户 API 与 webui 分离运行,可单独根据运行需求安装依赖包。
- 如果只需运行 API,可执行:
$ pip install -r requirements_api.txt`` ``# 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
- 如果只需运行 WebUI,可执行:
$ pip install -r requirements_webui.txt
2. 模型下载
如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
以本项目中默认使用的 LLM 模型 THUDM/ChatGLM3-6B 与 Embedding 模型 BAAI/bge-large-zh 为例:
下载模型需要先安装 Git LFS ,然后运行
$ git lfs install``$ git clone https://huggingface.co/THUDM/chatglm3-6b``$ git clone https://huggingface.co/BAAI/bge-large-zh
3. 初始化知识库和配置文件
按照下列方式初始化自己的知识库和简单的复制配置文件
$ python copy_config_example.py``$ python init_database.py --recreate-vs
4. 一键启动
按照以下命令启动项目
$ python startup.py -a
最轻模式本地部署方案
该模式的配置方式与常规模式相同,但无需安装 torch 等重依赖,通过在线API实现 LLM 和 Ebeddings 相关功能,适合没有显卡的电脑使用。
$ pip install -r requirements_lite.txt``$ python startup.py -a --lite
Demo示例
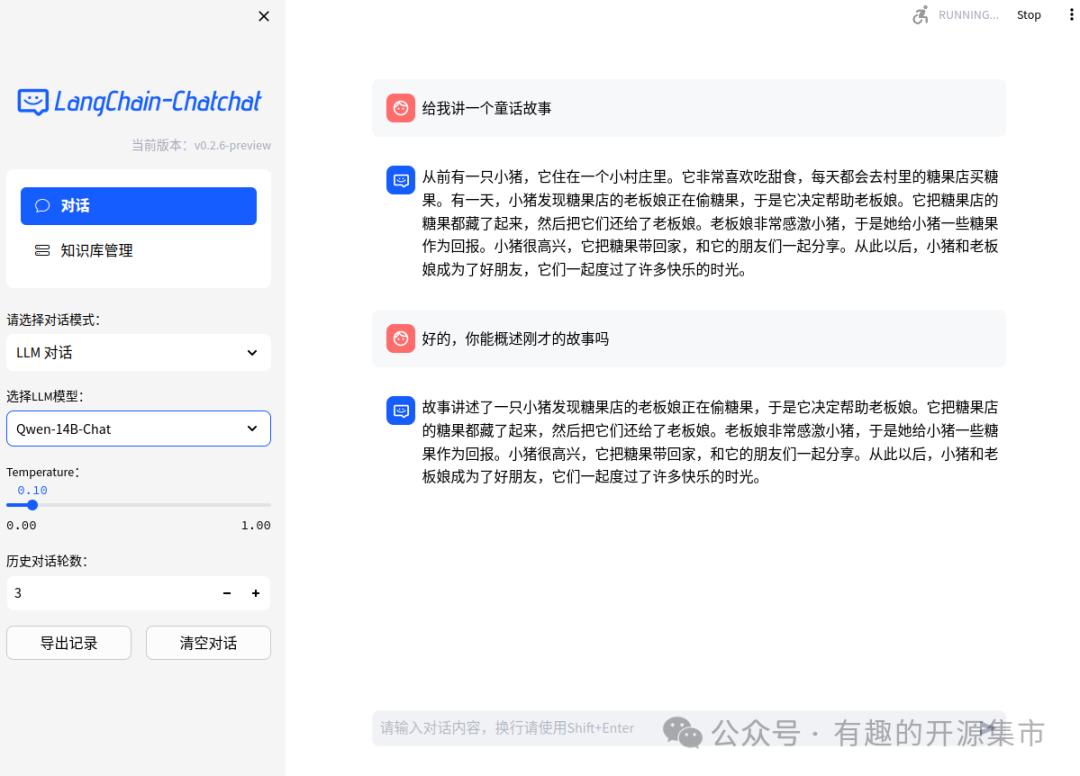
- Web UI 对话界面:
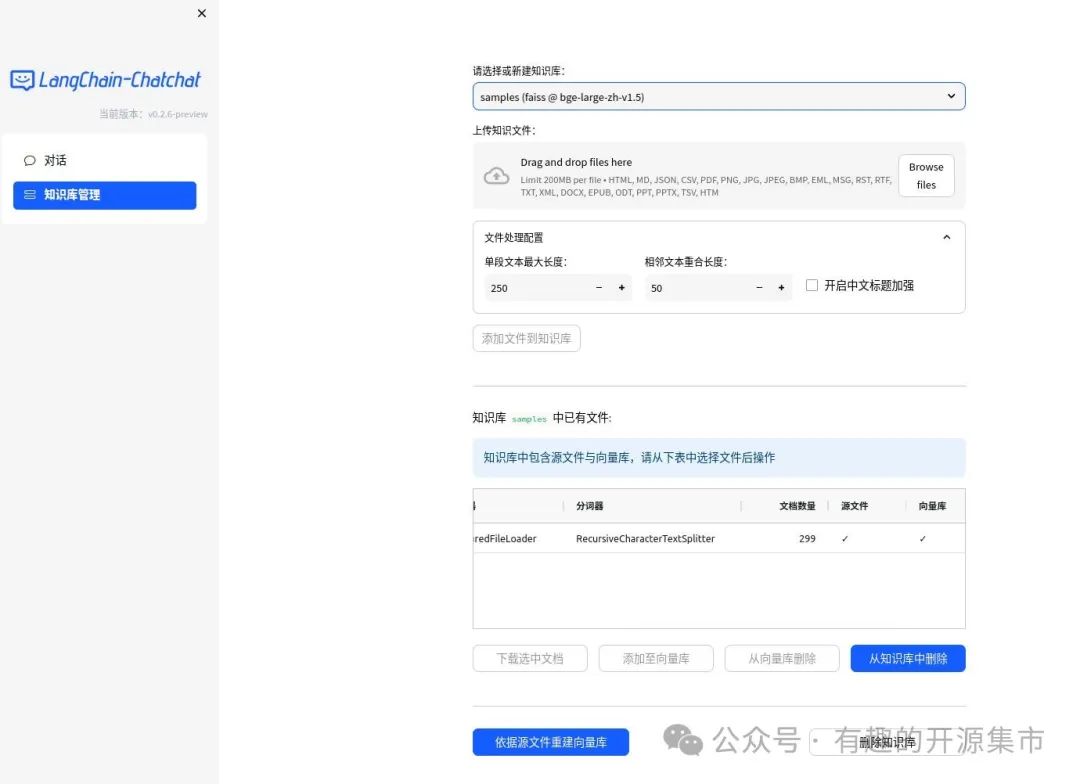
- Web UI 知识库管理页面:
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 21
21 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)