毕业设计:python新闻数据可视化分析系统 爬虫 SnowNLP情感分析 时间序列预测算法 ARIMA预测模型 机器学习(源码+文档)✅
毕业设计:python新闻数据可视化分析系统 爬虫 SnowNLP情感分析 时间序列预测算法 ARIMA预测模型 机器学习(源码+文档)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
python语言、Flask框架、Echarts可视化、requests爬虫技术、新浪新闻、scikit-learn、SnowNLP情感分析、ARIMA预测模型(时间序列预测算法)
功能模块图: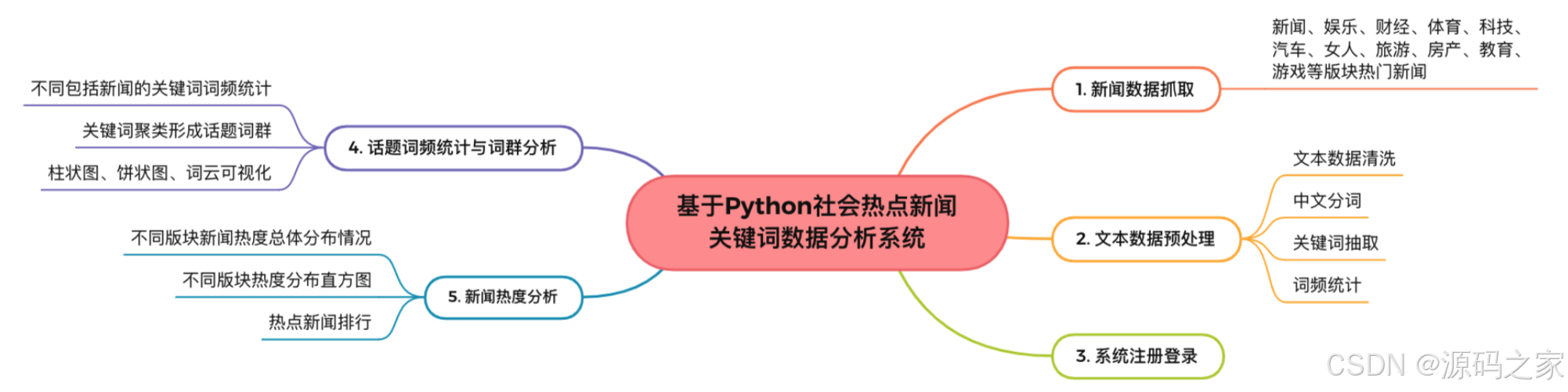
2、项目界面
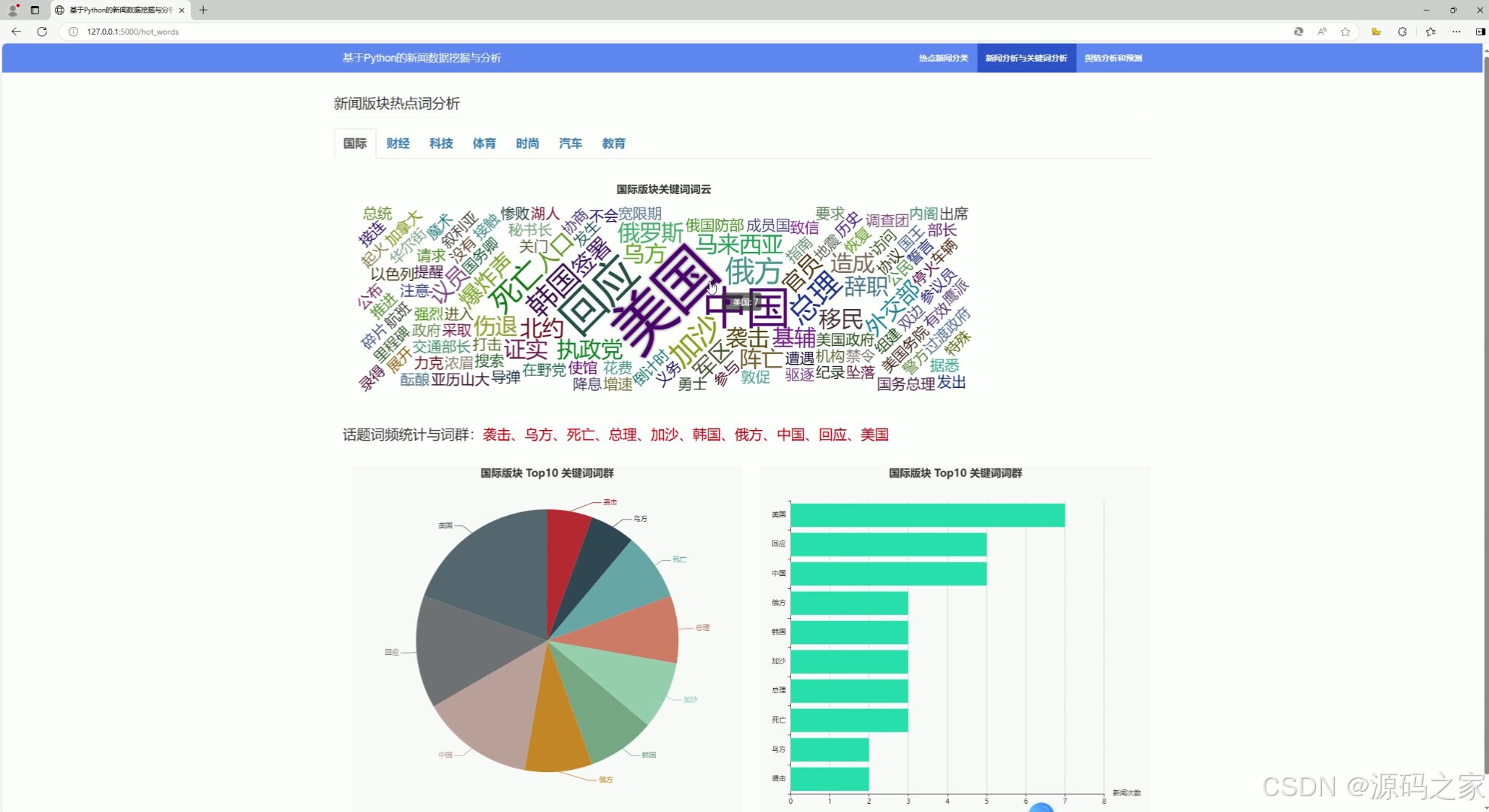
(1)新闻可视化分析、热词关键词分析
(2)新闻列表、新闻类型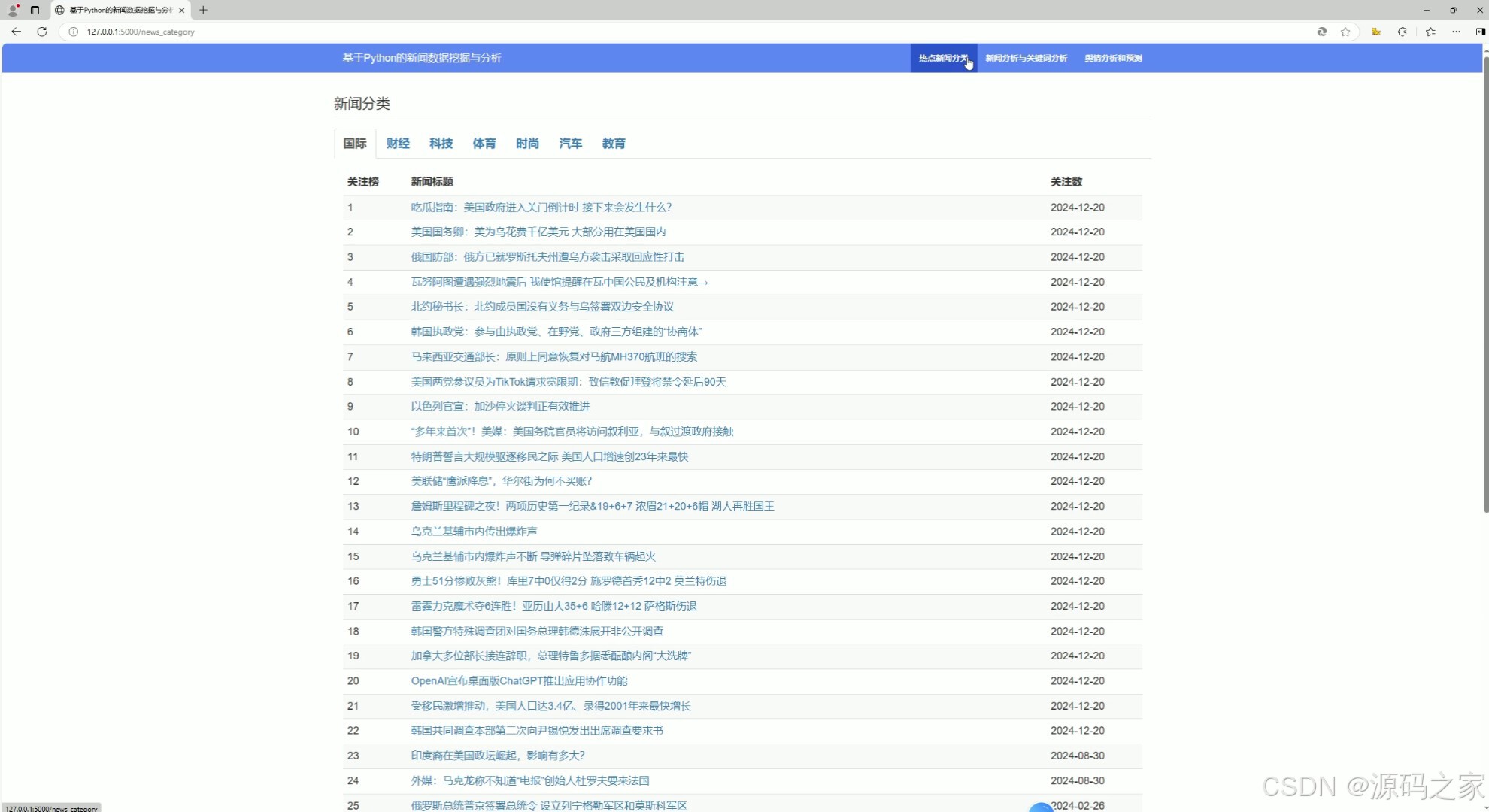
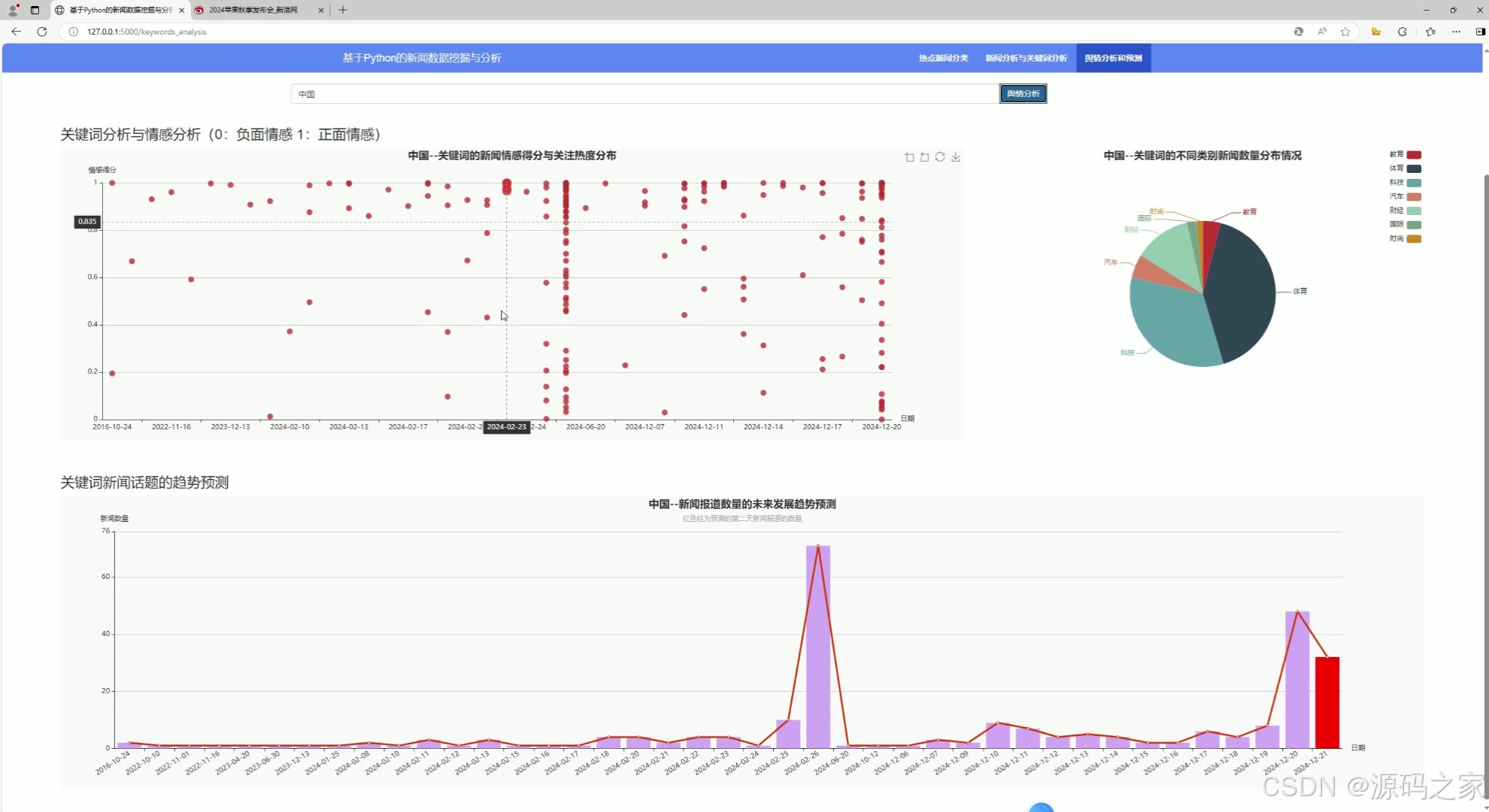
(3)新闻舆情分析与预测
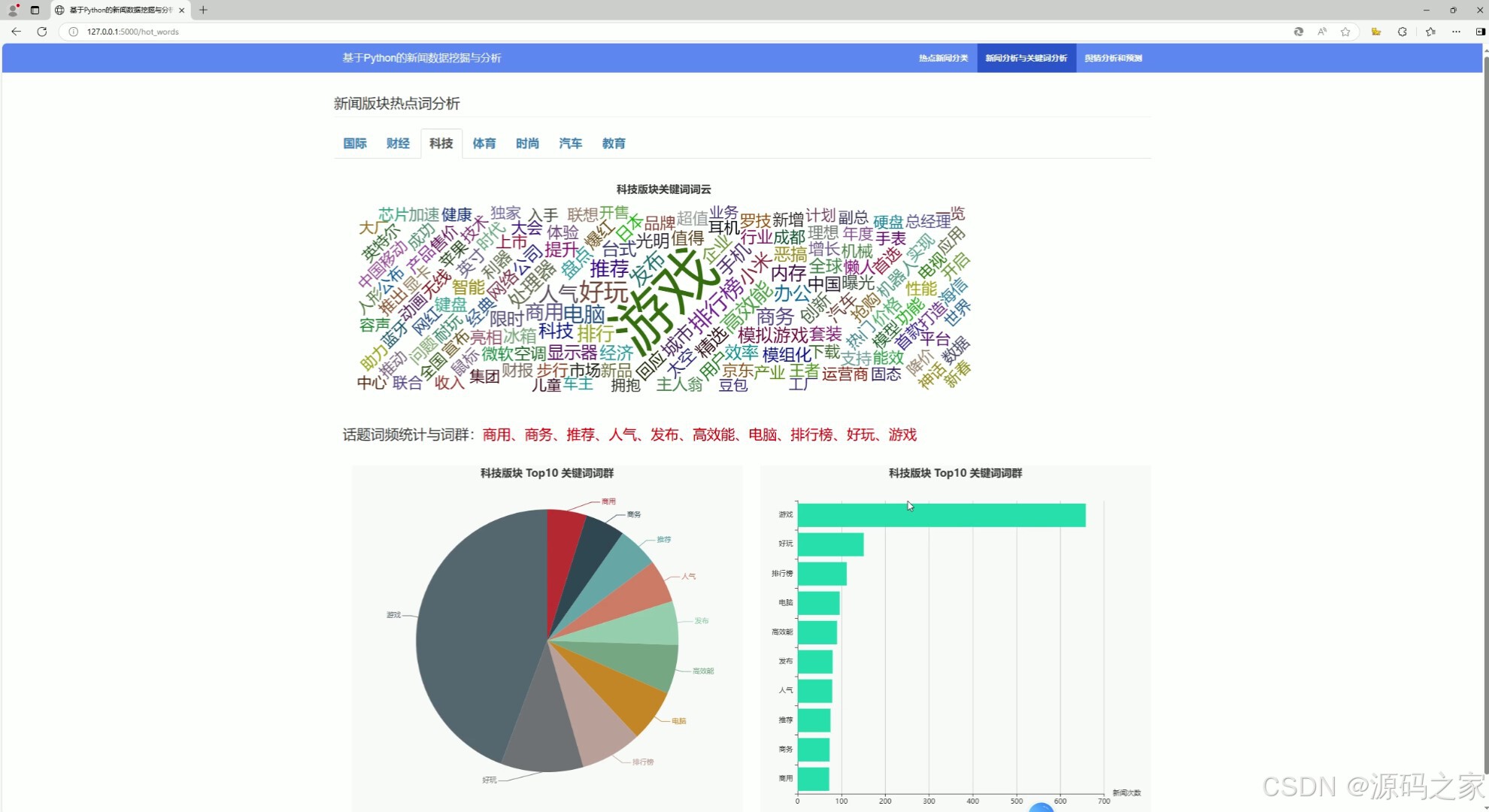
(4)新闻可视化分析、热词关键词分析
(5)新闻舆情分析与预测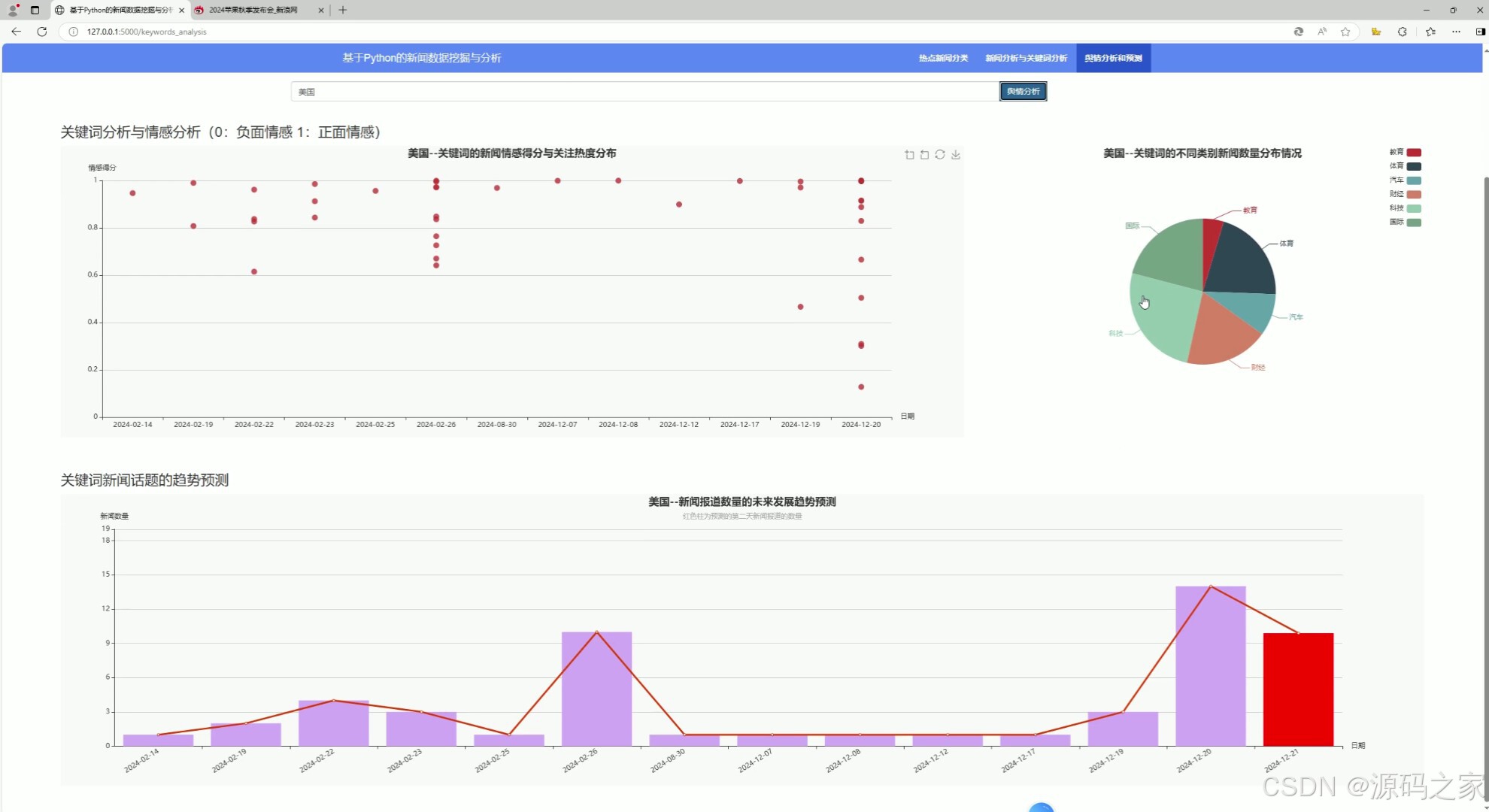
(6)注册登录
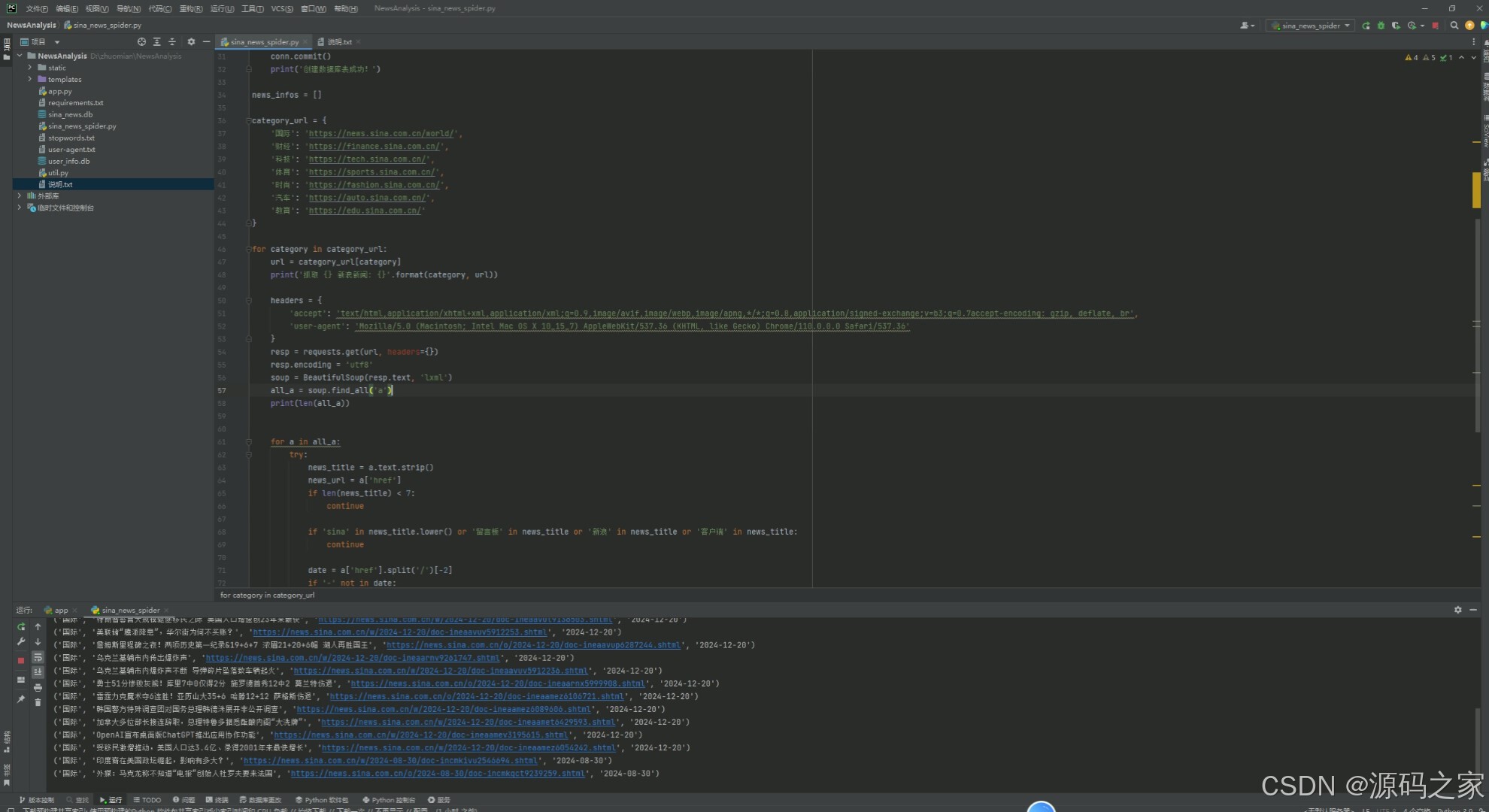
(7)数据爬取
3、项目说明
本项目利用网络爬虫技术从新浪新闻网站爬取最新的新闻数据,并进行版块分类,对某篇版块下的所有新闻进行中文分词,保留表征能力强名词和动词作为关键词,并进行关键词词频统计,同时对新闻进行词云统计和词群分析,
对不同版块的新闻热度进行统计分析。利用 Flask框架 搭建后台,构建标准的 restful 接口,前端利用 bootstrap + echarts + jquery 调用后台接口,并进行前端的渲染可视化分析。优化网络爬虫、前端页面和交互逻辑,增加话题趋势预测算法。
一、爬虫 requests
新浪新闻
https://news.sina.com.cn/china/
利用 Python 的 request + beautifulsoup 实现某新闻网站的新闻、娱乐、财经、体育、科技、汽车、女人、旅游、房产、教育、游戏等版块的最新新闻数据,完成数据清洗后存储到文件系统或数据库中。
二、ARIMA预测模型 ---- 时间序列预测模型
statsmodels库、ARIMA 模型
(1)构造 ARIMA 模型
(2)基于历史数据训练
(3)预测下一个时间步的值
三、SnowNLP情感分析
在使用 SnowNLP 进行情感分析时,情感得分是一个介于 0 到 1 之间的浮点数,用来表示文本的情感倾向。
接近 0 的得分表示文本具有明显的负面情感。
接近 1 的得分表示文本具有明显的正面情感。
接近 0.5 的得分则表示文本情感倾向不明显,可能是中性的。
四、话题词频统计与词群分析
通过对新闻关键词抽取、词频统计,并对多个关键词进行聚类形成【词群】
五、闻热度分析
新闻热度主要依据每个版块的所有新闻的关注人数的分布情况,前端利用 echarts 和 ecStat 实现密度分布直方图的可视化
4、核心代码
class WordSegmentPOSKeywordExtractor(TFIDF):
def extract_sentence(self, sentence, keyword_ratios=None):
"""
Extract keywords from sentence using TF-IDF algorithm.
Parameter:
- keyword_ratios: return how many top keywords. `None` for all possible words.
"""
words = self.postokenizer.cut(sentence)
freq = {}
seg_words = []
pos_words = []
for w in words:
wc = w.word
seg_words.append(wc)
pos_words.append(w.flag)
if len(wc.strip()) < 2 or wc.lower() in self.stop_words:
continue
freq[wc] = freq.get(wc, 0.0) + 1.0
if keyword_ratios is not None and keyword_ratios > 0:
total = sum(freq.values())
for k in freq:
freq[k] *= self.idf_freq.get(k, self.median_idf) / total
tags = sorted(freq, key=freq.__getitem__, reverse=True)
top_k = int(keyword_ratios * len(seg_words))
tags = tags[:top_k]
key_words = [int(word in tags) for word in seg_words]
return seg_words, pos_words, key_words
else:
return seg_words, pos_words
extractor = WordSegmentPOSKeywordExtractor()
def fetch_keywords(new_title):
"""新闻关键词抽取,保留表征能力强名词和动词"""
seg_words, pos_words, key_words = extractor.extract_sentence(new_title, keyword_ratios=0.8)
seg_key_words = []
for word, pos, is_key in zip(seg_words, pos_words, key_words):
if pos in {'n', 'nt', 'nd', 'nl', 'nh', 'ns', 'nn', 'ni', 'nz', 'v', 'vd', 'vl', 'vu', 'a'} and is_key:
if word not in STOPWORDS:
seg_key_words.append(word)
return seg_key_words
@app.route('/news_words_analysis/<category>')
def news_words_analysis(category):
conn = sqlite3.connect('sina_news.db')
cursor = conn.cursor()
sql = "SELECT title FROM news_info where category='{}' order by date desc".format(category)
cursor.execute(sql)
titles = cursor.fetchall()
word_count = {}
for title in titles:
words = fetch_keywords(title[0])
for word in words:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
wordclout_dict = sorted(word_count.items(), key=lambda d: d[1], reverse=True)
wordclout_dict = [{"name": k[0], "value": k[1]} for k in wordclout_dict]
# 选取 top10 的词作为话题词群
top_keywords = [w['name'] for w in wordclout_dict[:10]][::-1]
top_keyword_counts = [w['value'] for w in wordclout_dict[:10]][::-1]
return jsonify({'词云数据': wordclout_dict, '词群': top_keywords, '词群个数': top_keyword_counts})
# -----------3、预测---------------------
def arima_model_train_eval(history):
# 构造 ARIMA 模型
model = ARIMA(history, order=(1, 1, 0))
# 基于历史数据训练
model_fit = model.fit()
# 预测下一个时间步的值
output = model_fit.forecast()
yhat = output[0]
return yhat
@app.route('/keywords_yuqing_search/<search_input>')
def keywords_yuqing_search(search_input):
""" 3、舆情关键词检索分析 """
conn = sqlite3.connect('sina_news.db')
cursor = conn.cursor()
print(search_input)
sql = "SELECT * FROM news_info where title like '%{}%' order by date asc".format(search_input)
cursor.execute(sql)
news_infos = cursor.fetchall()
dates = []
sentiment_scores = []
category_count = {}
date_count = {}
for news_info in news_infos:
category, news_title, news_url, date = news_info
dates.append(date)
# 情感分析
sentiment_score = SnowNLP(news_title).sentiments
sentiment_scores.append(sentiment_score)
if category not in category_count:
category_count[category] = 0
category_count[category] += 1
for date in dates:
if date not in date_count:
date_count[date] = 0
date_count[date] += 1
# 事件发生的趋势预测
pred_dates = list(date_count.keys())
date_news_counts = list(date_count.values())
# 下一个日期及新闻数量预测,调用自建arima_model_train_eval函数
print(date_news_counts)
pred_next_count = arima_model_train_eval(date_news_counts)
date_news_counts.append(pred_next_count)
new_date = pred_dates[-1]
next_date = datetime.strptime(new_date, '%Y-%m-%d') + timedelta(days=1)
next_date = next_date.strftime('%Y-%m-%d')
pred_dates.append(next_date)
result = {
'情感得分': sentiment_scores,
'日期': dates,
'类别': list(category_count.keys()),
'新闻个数': list(category_count.values()),
"趋势日期": pred_dates,
"趋势数量": date_news_counts
}
return jsonify(result)
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 36
36 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)