人工智能:AI大模型必备知识汇编
数学基础:这里包括线性代数、微积分、概率统计和最优化理论。可能需要更详细地解释每个数学领域如何具体应用于大模型,例如矩阵运算在神经网络中的具体应用,或者梯度下降法的工作原理。计算机科学基础:涉及编程语言(Python为主)、数据结构和算法、操作系统、计算机网络。需要思考这些基础知识如何支持大模型的开发,比如并行计算对训练效率的影响,或者内存管理在处理大型数据集中的作用。机器学习基础:监督学习、无监
1、 AI****大模型的必备基础知识
1.1 必备知识概述
- 数学基础:这里包括线性代数、微积分、概率统计和最优化理论。可能需要更详细地解释每个数学领域如何具体应用于大模型,例如矩阵运算在神经网络中的具体应用,或者梯度下降法的工作原理。
- 计算机科学基础:涉及编程语言(Python为主)、数据结构和算法、操作系统、计算机网络。需要思考这些基础知识如何支持大模型的开发,比如并行计算对训练效率的影响,或者内存管理在处理大型数据集中的作用。
- 机器学习基础:监督学习、无监督学习、强化学习,以及模型评估方法。这里可能需要强调迁移学习和微调在大模型中的应用,因为这是当前研究的热点。
- 深度学习基础:神经网络、反向传播、框架使用(如PyTorch、TensorFlow)。这部分需要详细讨论Transformer架构,因为它是大多数现代大模型的核心。
- 自然语言处理基础:文本表示、经典模型(RNN、LSTM)、预训练模型(如BERT、GPT)。可能需要补充更多关于分词技术(如BPE)和注意力机制的内容。
- 大模型核心技术:模型架构(Transformer)、预训练与微调、分布式训练、高效推理。这里可能需要讨论参数规模与模型性能的关系,以及如何解决显存不足的问题(如模型并行、混合精度训练)。
- 伦理与安全:数据隐私、模型偏见、滥用风险、可解释性。可能需要加入更多实际案例,说明这些问题带来的影响,以及当前的解决方案(如差分隐私、公平性指标)。
- 实践与工具:数据处理、开源框架、实验设计、论文阅读。这部分可以强调实践的重要性,比如通过参与开源项目或Kaggle竞赛来积累经验。
AI大模型的必备基础知识涵盖数学、计算机科学、机器学习等多个领域,以下是系统化的整理:
1.1.1 数学基础
线性代数:矩阵运算(如乘法、转置)支撑神经网络计算;特征值分解用于降维(如PCA);张量是高维数据的核心表示形式。
微积分:梯度计算(偏导数)通过反向传播优化模型;链式法则在深层网络中传递误差。
概率与统计:贝叶斯定理用于概率推理;高斯分布假设常见于损失函数设计;假设检验评估模型显著性。
最优化理论:梯度下降及其变体(如Adam)调整参数;学习率调度策略平衡收敛速度与稳定性。
1.1.2 计算机科学基础
编程语言:Python为主,C++/CUDA用于高性能计算;NumPy/Pandas处理数据,PyTorch/TensorFlow构建模型。
数据结构和算法:哈希表加速数据检索;图结构处理依赖关系(如知识图谱);动态规划优化序列决策。
操作系统与并行计算:多线程/多进程加速数据预处理;GPU/TPU并行计算加速训练;内存管理防止显存溢出。
计算机网络:分布式训练涉及参数同步(如All-Reduce);HTTP/RESTful API部署模型服务。
1.1.3 机器学习基础
监督学习:分类(如ResNet)、回归(如房价预测)依赖标注数据;损失函数(交叉熵、MSE)衡量预测误差。
无监督学习:聚类(K-Means)、降维(t-SNE)挖掘无标签数据规律。
强化学习:智能体通过奖励机制学习策略(如AlphaGo);Q-learning、策略梯度应用于游戏和机器人控制。
模型评估:交叉验证防止过拟合;ROC-AUC综合评估分类性能;混淆矩阵分析错误类型。
1.1.4 深度学习基础
神经网络:全连接层、卷积层(CNN处理图像)、循环层(LSTM处理时序数据)堆叠成深层网络;激活函数(ReLU)引入非线性。
反向传播:链式法则计算梯度,优化器(如Adam)更新参数;梯度裁剪防止爆炸。
框架实践:PyTorch动态图灵活调试,TensorFlow静态图高效部署;自动微分机制简化求导。
正则化技术:Dropout随机失活神经元;BatchNorm加速训练并提升泛化。
1.1.5 然语言处理(NLP)基础
文本表示:词袋模型(Bag-of-Words)、TF-IDF加权;词嵌入(Word2Vec、GloVe)捕获语义;上下文嵌入(ELMo、BERT)动态表征。
经典模型:RNN处理序列,LSTM缓解长程依赖;Seq2Seq(如机器翻译)结合编码器-解码器结构。
预训练模型:BERT(双向Transformer)通过掩码语言建模;GPT(自回归模型)生成文本;T5统一文本到文本任务。
分词技术:BPE(Byte-Pair Encoding)平衡词表大小与粒度;SentencePiece支持多语言分词。
1.1.6 大模型核心技术
Transformer****架构:自注意力机制计算全局依赖;多头注意力捕捉多维度特征;位置编码注入序列信息。
预训练与微调:在海量语料上预训练(如GPT-3),通过提示工程(Prompt Engineering)适配下游任务。
分布式训练:数据并行(分割数据)、模型并行(分割层)、流水线并行(分割计算阶段);ZeRO优化显存。
高效推理:量化(FP16/INT8)减少模型体积;知识蒸馏(小模型模仿大模型);缓存机制(如KV Cache)加速生成。
1.1.7 伦理与安全
数据隐私:差分隐私添加噪声保护用户数据;联邦学习本地训练数据。
模型偏见:公平性指标(如Demographic Parity)检测歧视;对抗训练减少偏见。
滥用风险:内容过滤防止生成有害信息;水印技术追踪模型输出。
可解释性:LIME/SHAP解释预测结果;注意力可视化分析模型决策。
1.1.8 实践与工具
数据处理:Hugging Face Datasets加载数据;Spark处理大规模数据集;数据增强(如回译)扩充样本。
开源框架:Hugging Face Transformers调用预训练模型;DeepSpeed优化分布式训练;LangChain构建应用。
实验设计:超参数搜索(网格搜索、贝叶斯优化);日志工具(TensorBoard、W&B)跟踪实验。
论文与社区:精读经典论文(如《Attention is All You Need》);参与AI社区(GitHub、arXiv)跟进前沿。
1.1.9 总结
AI大模型是跨学科的复杂系统,需融合理论知识与工程实践。掌握上述基础后,可进一步探索多模态模型、强化学习与大模型结合等前沿方向。持续参与开源项目(如微调LLaMA)、复现论文实验,是深化理解的有效途径。
1.2 机器学习
监督学习、无监督学习、强化学习、模型评估,机器学习的这几个分支各有特点和适用场景,模型评估则是确保机器学习模型质量和可靠性的关键步骤。它们共同构成了机器学习的核心内容,推动着机器学习技术在各个领域的广泛应用和不断发展。
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。下面将从监督学习、无监督学习、强化学习和模型评估几个方面为你详细介绍:
1.2.1 监督学习
定义:监督学习是机器学习中的一个重要分支,它使用标记数据进行训练。在这种学习方式中,训练数据集中包含了输入特征以及对应的目标标签(输出)。模型的训练目标是学习到一个从输入特征到目标标签的映射关系,以便能够对新的、未见过的数据进行准确的预测。
常见算法:包括线性回归、逻辑回归、决策树、支持向量机、朴素贝叶斯等。例如,在一个预测房价的模型中,我们可以使用房屋的面积、房间数量、地理位置等特征作为输入,房屋的实际价格作为输出标签,通过线性回归算法来建立房价与这些特征之间的关系模型。
应用场景:广泛应用于各种预测和分类任务,如天气预报、疾病诊断、图像识别、垃圾邮件过滤等。
1.2.2 无监督学习
定义:无监督学习与监督学习不同,它使用的训练数据集中没有给定的目标标签或输出。其主要目的是发现数据中的内在结构和模式,例如将数据进行聚类,找出数据中的异常点,或者学习数据的低维表示等。
常见算法:有 K-Means 聚类、DBSCAN 密度聚类、主成分分析(PCA)、奇异值分解(SVD)等。例如,K-Means 算法可以将一组客户数据根据他们的消费行为特征划分为不同的聚类,每个聚类代表一类具有相似行为的客户群体。
应用场景:常用于数据探索、降维、异常检测等领域,在商业分析、网络安全、生物信息学等方面有重要应用。
1.2.3 强化学习
定义:强化学习是一种基于环境反馈来学习最优行为策略的机器学习方法。在强化学习中,智能体(agent)通过与环境进行交互,根据环境给出的奖励信号来学习如何采取行动以最大化长期累积奖励。智能体的目标是找到一个最优策略,使得在给定的环境中能够获得最大的奖励。
常见算法:包括深度 Q 网络(DQN)、策略梯度算法(如 A2C、A3C、PPO 等)、深度确定性策略梯度(DDPG)等。以机器人导航为例,机器人就是智能体,它在环境中不断尝试不同的动作(如前进、转弯等),根据是否接近目标以及是否遇到障碍物等环境反馈来获得奖励或惩罚,通过不断学习,机器人会逐渐找到一条从当前位置到目标位置的最优路径。
应用场景:在机器人控制、游戏、自动驾驶、资源管理等领域有广泛的应用。
1.2.4 模型评估
定义:模型评估是机器学习中至关重要的环节,它用于衡量训练好的模型在实际应用中的性能表现。通过使用评估指标和验证方法,我们可以了解模型的准确性、泛化能力以及其他相关性能,从而判断模型是否满足实际需求,以及是否需要对模型进行进一步的改进和优化。
常见评估指标:对于分类任务,常用的指标有准确率、精确率、召回率、F1 值、ROC 曲线下面积(AUC)等;对于回归任务,常见的指标有均方误差(MSE)、平均绝对误差(MAE)、决定系数(R²)等。例如,在一个癌症诊断的分类模型中,准确率可以告诉我们模型正确预测癌症患者和非癌症患者的比例;而在预测股票价格的回归模型中,均方误差可以衡量模型预测值与实际股票价格之间的平均差异程度。
常见验证方法:包括留出法、交叉验证法、自助法等。这些方法通过将数据集划分为训练集、验证集和测试集,来评估模型在不同数据子集上的性能,以避免模型过拟合或欠拟合,确保模型具有良好的泛化能力。
1.3 深度学习
神经网络、反向传播、框架实践、正则化技术,深度学习通过神经网络来学习数据的内在特征,反向传播算法用于训练模型,各种深度学习框架方便了模型的实践操作,而正则化技术则有助于提高模型的性能和泛化能力,使深度学习模型能够更好地应用于各种实际问题中。
深度学习是机器学习的一个分支领域,它通过构建具有多个层次的神经网络模型,自动从大量数据中学习复杂的模式和特征表示。以下是关于深度学习中神经网络、反向传播、框架实践和正则化技术的详细介绍:
1.3.1 神经网络
基本结构:神经网络由大量的神经元相互连接组成,通常包括输入层、隐藏层和输出层。输入层接收原始数据,输出层给出模型的预测结果,隐藏层则负责对数据进行特征提取和变换。每个神经元通过激活函数对其输入进行非线性变换,从而使神经网络能够学习到复杂的非线性关系。
工作原理:数据从输入层进入神经网络,经过隐藏层中神经元的层层计算和变换,最后在输出层得到预测结果。在这个过程中,神经元之间的连接权重决定了数据传递的强度和方式,通过调整这些权重,神经网络可以逐渐学习到输入数据与输出结果之间的映射关系。
1.3.2 反向传播
定义:反向传播是一种用于训练神经网络的算法,它基于链式法则来计算损失函数关于神经网络中每个参数(权重和偏置)的梯度。通过反向传播算法,我们可以有效地将损失从输出层反向传播到输入层,从而计算出每个参数对损失的贡献程度,以便进行参数更新。
计算过程:首先,在前向传播过程中,输入数据通过神经网络的各层进行计算,得到输出结果,并根据损失函数计算出损失值。然后,在反向传播过程中,从输出层开始,根据损失函数对输出的导数,以及各层的激活函数导数,逐步计算出损失函数对每一层参数的梯度。最后,根据计算得到的梯度,使用优化算法(如随机梯度下降)来更新神经网络的参数,以减小损失函数的值。
1.3.3 框架实践
常见深度学习框架:包括 TensorFlow、PyTorch 等。这些框架提供了丰富的工具和接口,方便用户构建、训练和部署深度学习模型。
以 PyTorch 为例的实践步骤
数据准备:首先需要将原始数据进行预处理,例如归一化、划分训练集和测试集等。然后将数据转换为适合模型输入的格式,通常使用数据加载器(DataLoader)来批量加载数据。
模型构建:使用 PyTorch 的神经网络模块(如 nn.Module)来定义神经网络的结构。可以通过继承 nn.Module 类,定义网络的层结构和前向传播函数。例如,定义一个简单的多层感知机(MLP)模型,包含多个全连接层和激活函数。
模型训练:定义损失函数(如交叉熵损失函数)和优化器(如随机梯度下降优化器)。在训练过程中,通过循环遍历训练数据集,将数据输入模型进行前向传播,计算损失值,然后使用反向传播算法计算梯度并更新模型参数。通常会设置一定的训练轮数(epochs)和批次大小(batch size),以控制训练过程。
模型评估:在训练完成后,使用测试数据集对模型进行评估。可以计算模型在测试集上的准确率、损失值等指标,以衡量模型的性能。还可以通过可视化等方式来分析模型的预测结果和错误情况,以便进一步改进模型。
1.3.4 正则化技术
L1 和 L2 正则化
原理:L1 正则化是在损失函数中添加参数的绝对值之和作为惩罚项,L2 正则化则是添加参数的平方和作为惩罚项。它们的目的是通过惩罚较大的参数值,防止模型过拟合,使模型的参数更加稀疏(L1 正则化)或更加平滑(L2 正则化)。
作用:L1 正则化可以用于特征选择,因为它会使一些不重要的特征对应的参数变为 0,从而自动筛选出对模型重要的特征。L2 正则化则主要用于防止模型过拟合,提高模型的泛化能力。
Dropout
原理:在神经网络的训练过程中,以一定的概率随机将一些神经元的输出设置为 0,这样可以防止神经元之间形成过于复杂的共适应关系,从而减少模型的过拟合。
作用:Dropout 可以看作是一种模型集成的方法,每次训练时随机丢弃不同的神经元,相当于训练了多个不同的子模型,在测试时将这些子模型的结果进行平均,从而提高模型的泛化能力。
1.3.5 数据增强
原理:通过对原始训练数据进行一系列的变换,如旋转、翻转、缩放、添加噪声等,生成更多的训练样本,从而增加数据的多样性,使模型能够学习到更鲁棒的特征表示。
作用:数据增强可以扩大训练数据集的规模,减少模型对特定数据特征的依赖,降低模型过拟合的风险,提高模型在不同数据变化情况下的泛化能力。
1.4 自然语言处理(NLP)
文本表示、经典模型、预训练模型、分词技术,自然语言处理涉及多种技术和模型,文本表示是基础,经典模型为各种任务提供了基本的解决方案,预训练模型则通过大规模数据学习到通用的语言知识,分词技术是许多自然语言处理任务的前置步骤。这些技术相互结合,不断推动着自然语言处理领域的发展和进步。
自然语言处理(Natural Language Processing,NLP)是人工智能和计算机科学领域的一个重要分支,旨在使计算机能够理解、处理和生成人类自然语言。以下是关于文本表示、经典模型、预训练模型、分词技术的详细介绍:
1.4.1 文本表示
词袋模型:将文本看作是词的集合,忽略词的顺序和语法结构。通过统计每个词在文本中出现的频率来表示文本,形成一个向量,向量的每个维度对应一个词的出现频率。优点是简单直观,易于计算;缺点是丢失了词的顺序信息和语义信息。
TF-IDF:在词袋模型的基础上,考虑了词在整个语料库中的重要性。TF(词频)表示词在当前文本中出现的频率,IDF(逆文档频率)衡量词在整个语料库中的稀有程度。通过将 TF 和 IDF 相乘得到每个词的 TF - IDF 值,以此来构建文本向量。TF - IDF 能更好地突出文本中的关键信息,但同样存在忽略词序和语义的问题。
词嵌入:将词映射到低维向量空间中,使得语义相似的词在向量空间中距离较近。常见的词嵌入方法有 Word2Vec、GloVe 等。Word2Vec 通过预测上下文词或中心词来学习词向量表示,GloVe 则基于词的共现矩阵进行训练。词嵌入能够捕捉词的语义和句法信息,有效降低向量维度,但对于多义词的表示可能不够准确。
文档嵌入:将整个文档表示为一个向量,如 Doc2Vec 模型。它在 Word2Vec 的基础上,引入了文档向量,使得模型能够学习到文档的整体特征。文档嵌入可以用于文档分类、聚类等任务,但对于长文档的处理可能存在信息丢失的问题。
1.4.2 经典模型
1.4.2.1 经典模型
隐马尔可夫模型(HMM**)**:常用于词性标注、命名实体识别等序列标注任务。HMM 假设观察到的序列是由隐藏的状态序列生成的,通过学习状态转移概率和观测概率来预测隐藏状态。它的优点是模型简单,计算效率高;缺点是对长序列的建模能力有限,且假设观测序列之间相互独立,忽略了上下文信息。
条件随机场(CRF**)**:在 HMM 的基础上,考虑了整个观测序列的全局信息,通过构建条件概率分布来进行序列标注。CRF 能够更好地处理上下文信息,提高标注的准确性,但模型训练和推理的计算复杂度较高。
循环神经网络(RNN**)**:包括 Elman 网络和 Jordan 网络等,能够处理序列数据,通过隐藏状态来记忆之前的信息。RNN 可以对文本中的长期依赖关系进行建模,但在处理长序列时容易出现梯度消失或爆炸的问题。
长短时记忆网络(LSTM**)**:是一种特殊的 RNN,通过引入门控机制来控制信息的流动,能够有效地处理长序列中的长期依赖关系。LSTM 在自然语言处理的许多任务中表现出色,如语言模型、机器翻译等,但模型结构较为复杂,训练时间较长。
门控循环单元(GRU**)**:也是一种改进的 RNN,它将 LSTM 中的遗忘门和输入门合并为一个更新门,简化了模型结构,同时在处理长序列数据时也能取得较好的效果。GRU 的计算效率较高,适用于对实时性要求较高的任务。
1.4.2.2 其他模型
自然语言处理(NLP)中常用的经典模型除了前面提到的隐马尔可夫模型、条件随机场、循环神经网络等,还有以下几种:
1 递归神经网络(Recursive Neural Network**,RNN****)**
原理:RNN 是一种专门处理序列数据的神经网络。它通过隐藏状态来记忆之前的输入信息,将当前输入与之前的隐藏状态相结合,经过非线性变换得到新的隐藏状态,从而对序列中的长期依赖关系进行建模。
应用:广泛应用于语言建模、机器翻译、情感分析等任务。例如,在语言建模中,根据前面的单词预测下一个单词的概率分布;在机器翻译中,将源语言序列逐步转换为目标语言序列。
2 卷积神经网络(Convolutional Neural Network**,CNN****)**
原理:CNN 最初主要用于图像识别领域,后来也被应用于 NLP 中。它通过卷积层、池化层和全连接层等组件,自动提取文本的局部特征。卷积层使用卷积核在文本序列上滑动,提取局部的词或短语特征;池化层则对卷积层的输出进行降维,保留重要特征。
应用:常用于文本分类、文本匹配等任务。例如,在文本分类中,通过提取文本的特征向量,将其映射到不同的类别;在文本匹配中,计算两个文本之间的相似度。
3 注意力机制(Attention Mechanism**)**
原理:注意力机制旨在让模型在处理文本时,能够自动聚焦于重要的部分。它通过计算每个位置的注意力权重,来表示该位置对于当前任务的重要程度,然后根据注意力权重对文本进行加权求和,得到更具代表性的特征表示。
应用:广泛应用于机器翻译、问答系统、文本生成等任务中。例如,在机器翻译中,帮助模型在生成目标语言时,更关注源语言中与之相关的部分;在问答系统中,聚焦于问题相关的文本段落,提高答案的准确性。
4 变换器(Transformer**)**
原理:Transformer 是一种基于注意力机制的架构,完全摒弃了循环神经网络和卷积神经网络。它由编码器和解码器组成,编码器负责将输入序列编码成一个连续的向量表示,解码器则根据编码器的输出和之前生成的输出序列来生成下一个输出。其中,多头注意力机制是 Transformer 的核心组件,它可以并行地计算不同位置的注意力权重,从而捕捉到更丰富的语义信息。
应用:Transformer 在各种自然语言处理任务中都取得了巨大的成功,如机器翻译、语言模型、文本摘要等。许多预训练模型如 BERT、GPT 等都是基于 Transformer 架构开发的。
1.4.3 预训练模型
BERT**(Bidirectional Encoder Representations from Transformers****)**:由谷歌开发的预训练语言模型,基于 Transformer 架构。它通过在大规模文本数据上进行无监督预训练,学习到丰富的语言知识和语义表示。BERT 的创新之处在于采用了双向注意力机制,能够同时考虑文本的前后文信息,在多个自然语言处理任务上取得了显著的突破,如问答系统、文本分类、命名实体识别等。
GPT**(Generative Pretrained Transformer****)**:由 OpenAI 开发,同样基于 Transformer 架构。GPT 主要用于生成任务,如文本生成、对话系统等。它通过自回归的方式进行预训练,根据前面的文本预测下一个单词。GPT 系列模型在语言生成方面表现出了强大的能力,但在一些需要理解上下文信息的任务上可能不如 BERT。
ERNIE**(Enhanced Representation through Knowledge Integration****)**:百度开发的预训练模型,在 BERT 的基础上,进一步融入了知识图谱等外部知识,以增强模型对语言的理解和表示能力。ERNIE 在一些需要知识推理的任务上表现出色,如知识问答、阅读理解等。
1.4.4 分词技术
基于词典的分词方法:将待分词的文本与事先构建好的词典进行匹配,按照一定的策略将文本切分成词语。常见的匹配策略有正向最大匹配法、反向最大匹配法、双向最大匹配法等。基于词典的分词方法简单易行,速度快,但对于未登录词(词典中没有的词)的处理能力较差。
基于统计的分词方法:利用大量的语料数据,通过统计词的出现频率、词与词之间的共现关系等信息来进行分词。例如,使用隐马尔可夫模型、条件随机场等统计模型来学习词的边界概率,从而实现分词。基于统计的分词方法能够处理未登录词,但需要大量的训练数据,且模型训练和推理的时间较长。
基于深度学习的分词方法:近年来,深度学习技术在分词领域得到了广泛应用。例如,使用循环神经网络(RNN)、长短期记忆网络(LSTM)、卷积神经网络(CNN)等模型来学习文本的特征表示,进而实现分词。基于深度学习的分词方法能够自动学习到文本中的语义和句法信息,提高分词的准确性,但模型结构复杂,需要大量的计算资源和训练数据。
1.5 大模型核心技术
Transformer架构、预训练与微调、分布式训练、高效推理
大模型是自然语言处理领域的重要发展方向,其核心技术包括 Transformer 架构、预训练与微调、分布式训练、高效推理等,以下是对这些技术的详细介绍:
1.5.1 Transformer架构
原理:Transformer 架构基于自注意力机制(Self - Attention),能够并行计算文本中每个位置的表示,有效捕捉长序列中的语义依赖关系。它由编码器和解码器组成,编码器负责将输入序列编码成一个连续的向量表示,解码器则根据编码器的输出和之前生成的输出序列来生成下一个输出。在编码器和解码器中,都包含多个堆叠的自注意力层和前馈神经网络层,并通过残差连接和层归一化技术来优化训练过程。
优点:相比传统的循环神经网络(RNN)和卷积神经网络(CNN),Transformer 具有更高的并行性和更强的长序列建模能力,能够更好地处理大规模的自然语言数据,提高模型的性能和泛化能力。
1.5.2 预训练与微调
预训练:预训练是大模型训练的重要环节,其目的是在大规模的无监督数据上学习到通用的语言知识和语义表示。通过自监督学习任务,如掩码语言模型(Masked Language Modeling,MLM)和下一句预测(Next Sentence Prediction,NSP)等,让模型自动学习文本中的语言模式、语法结构和语义信息,从而初始化模型的参数,使其具有一定的语言理解和生成能力。
微调:微调是在预训练模型的基础上,针对具体的下游任务,使用相应的有标注数据对模型进行进一步训练。通过微调,可以将预训练模型中学习到的通用知识和语义表示适配到特定的任务中,只需较少的标注数据就能取得较好的性能,大大提高了模型的训练效率和泛化能力。
1.5.3 分布式训练
数据并行:将训练数据划分为多个子集,分别在不同的计算设备(如 GPU)上进行并行计算,每个设备计算一部分数据的梯度,并在一定步骤后进行梯度汇总和参数更新。这种方式可以增加训练数据的批量大小,提高模型的训练速度,但可能会受到通信带宽的限制。
模型并行:将模型的不同部分(如不同的层或参数)分配到不同的计算设备上进行并行计算,每个设备负责计算模型的一部分,然后通过通信来传递中间结果。这种方式适用于模型规模较大、无法在单个设备上运行的情况,但需要仔细设计模型的并行策略,以减少通信开销和提高计算效率。
1.5.4 高效推理
模型压缩:通过剪枝技术去除模型中不重要的连接或参数,减少模型的存储空间和计算量;采用量化技术将模型的参数或激活值表示为低精度的数据类型,如 8 位整数或 16 位浮点数,而不显著影响模型的性能,从而提高推理速度和降低内存占用。
优化推理算法:利用各种优化算法和技术,如动态规划、贪心算法等,对推理过程进行优化,减少不必要的计算和搜索步骤。例如,在文本生成任务中,可以采用束搜索(Beam Search)算法来选择概率较高的生成路径,提高生成效率。
硬件加速:利用专门的硬件设备,如现场可编程门阵列(FPGA)、张量处理单元(TPU)或图形处理单元(GPU)等,对推理过程进行加速。这些硬件设备通常具有高效的并行计算能力和专门的深度学习指令集,能够显著提高模型的推理速度。
2、 大模型核心术语
2.1 核心技术体系
2.1.1 机器学习(ML:Machine Learning)
**机器学习是通过数据训练模型实现预测/**决策的算法框架,包括监督学习、无监督学习、半监督学习。
监督学习:基于标注数据训练分类/回归模型(如垃圾邮件分类、房价预测)。
无监督学习:发现数据潜在结构,自行生成监督信号(如聚类分析、降维、对比学习)。
元学习(Meta-Learning**):**学习如何快速适应新任务,即“学会学习”。
联邦学习(Federated Learning**)**:分布式隐私保护训练。
在线学习(Online Learning**)**:模型实时更新以适应动态数据流。
2.1.2 深度学习(DL:Deep Learning)
深度学习是基于多层神经网络的复杂数据处理技术,突破传统机器学习的局限性。包括:
Transformer:基于自注意力机制驱动的长文本处理通用架构(如GPT系列、BERT)。
扩散模型(Diffusion Model**)**:通过逐步去噪生成高质量数据(如Stable Diffusion)。
MoE**(Mixture of Experts****)**:组合多个子模型提升性能(如Switch Transformer)。
SNN**(脉冲神经网络)**:模拟生物神经脉冲时序的模型。
胶囊网络(Capsule Network**)**:通过胶囊单元编码空间层次关系。
深度学习需海量数据与高性能算力支持,依赖GPU/TPU****加速。
2.1.3 自然语言处理(NLP)
**自然语言处理是让机器理解、生成人类语言的技术。**包括:
大语言模型(LLM**)**:千亿参数级预训练模型(如GPT-4、PaLM)。
思维链(Chain-of-Thought**)**:通过分步推理提升模型逻辑能力。
检索增强生成(RAG**)**:NLP与知识库结合,提供检索与生成,提升答案准确性(如腾讯ima知识库)
指令微调(InstructionTuning**)**:通过任务指令调整模型行为。
多模态对齐(Multimodal Alignment**)**:对齐文本、图像等跨模态语义
2.1.4 计算机视觉(CV)
**计算机视觉是从图像/****视频中提取信息的技术。**主要包括:
ViT**(Vision Transformer****)**:将Transformer应用于图像分类。
NeRF**(神经辐射场)**:3D场景重建与渲染技术。
目标跟踪(Object Tracking**)**:视频中持续追踪特定物体(如SiamFC)。
光流估计(Optical Flow**)**:计算像素级运动矢量。
事件相机(Event Camera**)**:基于动态视觉传感器的低延迟感知。
其核心任务是:
目标检测:YOLO算法实现实时物体定位。
图像分割:U-Net模型区分医学影像中的病灶区域。
人脸识别:FaceNet通过特征向量比对实现身份认证。
2.1.5 强化学习(RL)
PPO**(近端策略优化)**:稳定策略梯度训练的算法。
模仿学习(Imitation Learning**)**:从专家示范中学习策略。
多智能体强化学习(MARL**)**:多个智能体协作/竞争(如星际争霸AI)。
逆强化学习(InverseRL**)**:从行为反推奖励函数。
2.1.6 模型优化技术
知识蒸馏(Knowledge Distillation**)**:大模型压缩为小模型(如DistilBERT)。
量化感知训练(QAT**)**:训练时模拟低精度计算。
动态网络(Dynamic Networks**)**:根据输入调整模型结构(如SkipNet)。
稀疏训练(SparseTraining**)**:训练时自动剪枝冗余连接。
2.2 支撑技术生态
2.2.1 算力基础设施
芯片技术:
- GPU:NVIDIA A100/H100加速深度学习训练。
- TPU:谷歌专为TensorFlow优化的AI芯片。
- 类脑芯片:清华大学天机芯模拟人脑神经形态计算。
云计算:
AWS、阿里云提供弹性算力资源池。
2.2.2 数据工程
数据工程主要是实现数据存储、清洗、标注与知识结构化。
数据标注:人工标注占比超70%,涵盖属性、框选、描点等类型。
数据增强:通过旋转、裁剪、加噪提升模型泛化能力。
关键技术包括:
数据版本控制(DVC**)**,像Git管理代码一样管理数据和机器学习模型,记录数据集、特征、模型权重的版本变更。
自动化特征工程(FeatureTools**)**,通过深度特征合成(Deep Feature Synthesis, DFS),从原始数据中自动提取时间、聚合、关系型特征。
2.2.3 知识图谱
知识图谱构建,核心功能包括:
图结构数据存储:以节点(实体)、边(关系)、属性三元组形式存储复杂关系数据。
高效关系查询:支持图遍历查询(如最短路径、社区发现),适用于社交网络、推荐系统。
语义推理:通过规则或机器学习发现隐含关系(如“A是B的同事,B是C的上司→ A与C可能存在间接关联”)。
工具有Neo4j、Amazon Neptune。
2.3 系统与架构
2.3.1 模型协作与协议
MCP**(模型上下文协议,Model Context Protocol****)**:**标准化协议,定义AI模型与外部工具/**数据交互的通用接口,规范多模型间上下文传递(如任务状态、数据格式),解决工具碎片化问题。支持分布式协作。
模型编排(Model Orchestration**)**:动态调度多个模型完成复杂任务流。
服务网格(Service Mesh**)**:管理微服务化AI模型间的通信。
2.3.2 分布式系统
参数服务器(Parameter Server**)**:大规模分布式训练架构。
All-Reduce算法:分布式训练中的梯度同步协议(如Ring All-Reduce)。
异构计算:CPU/GPU/TPU协同计算优化。
2.4 AI应用技术
2.4.1 行业应用
生成式AI**(AIGC****),自动化内容生成(文本、图像、视频)。**
- 文本生成:ChatGPT、Claude实现多轮对话与文案创作。
- 图像生成:Stable Diffusion、Midjourney基于扩散模型创作。
- 视频生成:Sora通过时空联合建模生成动态内容。
数字孪生(Digital Twin**)**:物理实体的虚拟实时映射(工业4.0)。
AIfor Science:科学发现中的AI应用(如AlphaFold预测蛋白质结构)。
AIOps:IT运维智能化(异常检测、根因分析)。
2.4.2 智能体与交互系统
Agent**(智能体):具备自主感知-决策-行动能力的软件体或实体(如自动驾驶Agent、AI游戏NPC****)。**
具身智能(EmbodiedAI**)**:物理世界中的机器人智能(如波士顿动力)。
多模态交互:融合语音、手势、眼动等多通道交互。典型应用:自动驾驶(激光雷达+摄像头+地图融合)。
2.4.3 边缘与终端AI
边缘智能指的是在终端设备(如手机、IoT设备)部署轻量化AI模型。
TinyML:超低功耗微控制器上的机器学习。
模型剪枝(Pruning**)**:移除冗余参数以适配边缘设备。
神经形态计算(Neuromorphic Computing**)**:类脑芯片上的高效推理(如Loihi芯片)。
典型应用:智能安防摄像头实时行为识别、工业传感器故障预测。
2.5 未来发展方向-AGI
AGI**(Artificial General Intelligence****,通用人工智能),指具备与人类相当或超越人类的通用智能的AI系统。与当前专注于特定任务的弱AI****(Narrow AI****)**不同,AGI能够在不同领域间迁移知识、自主学习新技能,并具备解决复杂问题的通用认知能力。
AGI的核心特征:通用学习能力、抽象推理与逻辑、目标导向与自主决策、多模态感知与交互、自我意识与情感模拟。
AGI是人类智能的技术镜像,其实现将重新定义文明。尽管当前技术距离AGI仍有鸿沟,但多学科交叉(如脑科学、量子计算)正推动这一目标逼近。理解AGI的本质与挑战,不仅是技术问题,更是关乎人类未来的哲学命题。
2.6 伦理与安全技术
2.6.1 隐私计算
**隐私计算旨在实现数据“可用不可见”,在保护隐私的前提下完成计算任务,**是AI数据安全的核心技术之一。实现方式有:
联邦学习(Federated Learning**),**多个参与方(如医院、银行)在本地保留数据,仅上传模型参数(而非原始数据)进行联合训练。
同态加密(Homomorphic Encryption**),**允许直接对加密数据进行计算,结果解密后与明文计算一致。应用案例:用户加密上传医疗数据,云端直接计算疾病风险评分后返回结果。
差分隐私(Differential Privacy**),**在数据中注入噪声,使单个记录的变动不影响整体统计结果。应用案例:公开统计数据时添加噪声,防止通过数据反推个体身份。
2.6.2 AI对齐(Alignment)
AI对齐的目标是确保AI系统的行为符合人类价值观,避免失控或危害社会。
价值对齐(Value Alignment**),**将人类的抽象价值观(如公平、正义)转化为AI可理解的奖励函数。实现方式有:
- 逆强化学习(Inverse Reinforcement Learning, IRL**)**:通过观察人类行为反推奖励函数。*
示例:训练自动驾驶系统时,通过人类驾驶数据推断“安全驾驶”的奖励规则。
- 人类反馈强化学习(RLHF**)**:让人类对AI输出排序,训练奖励模型指导AI行为。
案例:OpenAI使用RLHF微调ChatGPT,减少有害内容生成。
可解释性(Interpretability**)**
LIME**(Local Interpretable Model-agnostic Explanations****)**:通过扰动输入数据,观察模型输出的敏感性,生成局部解释。示例:解释为何AI判定某医疗影像为“恶性”,指出关键病灶区域。
SHAP**(Shapley Additive exPlanations****)**:基于博弈论量化特征对模型输出的贡献。应用:金融风控模型中,解释某用户贷款被拒的主因(如收入不足而非种族因素)。
2.6.3 内容安全与过滤
基于规则的过滤:关键词匹配、正则表达式匹配。
深度学习模型:检测文本/图像中的暴力、色情内容(如Google的Perspective API)。
对抗训练:生成对抗样本强化模型鲁棒性。
3、 **三大模型:CNN、Transformer、**BERT
CNN主要处理图像,有卷积层、池化层;
Transformer基于自注意力机制,适合序列数据;
BERT是Transformer的变种,用于自然语言处理。
3.1 CNN
3.1.1 核心思想
通过局部感知(卷积核)和权值共享提取空间特征,降低参数量。
3.1.2 结构
卷积层:提取局部特征(如边缘、纹理)。
池化层(如Max Pooling):降低特征图维度,增强鲁棒性。
全连接层:用于分类或回归。
3.1.3 应用/原理
图像分类(ResNet、VGG)、目标检测(YOLO)、图像分割(U-Net)。
原理:CNN主要由卷积层、池化层和全连接层组成。卷积层通过卷积核在输入数据上进行卷积运算,提取局部特征;池化层则对特征图进行下采样,降低特征维度,同时保留主要特征;全连接层将特征图展开为一维向量,并进行分类或回归计算。CNN利用卷积操作实现局部连接和权重共享,能够自动学习数据中的空间特征。
3.1.4 优缺点
优点
高效处理空间数据(图像、视频)。
参数共享减少过拟合风险。
缺点
对序列数据(如文本、时序数据)处理能力较弱。
3.1.5 经典模型
LeNet**、AlexNet****、ResNet**
**例如:LeNet****是最早的卷积神经网络之一。**1998年,Yan LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。LeNet通过连续使用卷积和池化层的组合提取图像特征,其架构如所图示,这里展示的是作者论文中的LeNet-5模型:
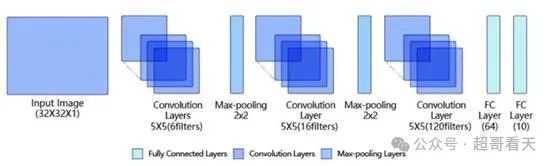
3.2 Transformer
3.2.1 核心思想
基于自注意力机制(Self-Attention)捕捉全局依赖关系,摆脱对序列顺序的依赖。
3.2.2 结构
**编码器-**解码器架构:每层包含多头注意力机制和前馈神经网络。
位置编码:引入序列位置信息。
3.2.3 应用/原理
基于期刊主题分布和引用关系调整学科划分,例如生态学、遥感等交叉学科更强调应用场景。
原理:Transformer基于自注意力机制(Self-Attention),该机制使模型能够关注输入序列中的不同位置,允许网络自动学习重要特征,而无需依赖递归或卷积结构。它通过多头注意力机制将输入序列中的每个元素与其他元素进行比较,并计算出它们之间的相关性权重。然后根据这些权重对输入进行加权求和,得到新的特征表示。
3.2.4 优缺点
优点
并行计算效率高,适合长序列。
全局上下文建模能力强。
缺点
计算复杂度随序列长度呈平方增长。
需要大量数据训练。
3.2.5 变体
Vision Transformer**(ViT****)**
Swin Transformer
3.3 BERT
3.3.1 核心思想
基于Transformer编码器的双向预训练模型,通过掩码语言建模(MLM)学习上下文语义。
3.3.2 结构
多层Transformer****编码器:堆叠12/24层。
预训练任务:MLM(预测被掩盖的词)和NSP(句子关系预测)。
3.3.3 应用/原理
文本分类、问答系统(如SQuAD)、命名实体识别(NER)。
BERT是一种基于Transformer架构的预训练语言模型,使用双向Transformer编码器来预训练深层上下文表示。它通过掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP**)两种训练方法进行预训练。**
3.3.4 优缺点
优点
双向上下文理解能力强。
通过微调适配多种下游任务。
缺点
预训练成本高。
生成任务表现不如Decoder-based模型(如GPT)。
3.3.5 衍生模型
RoBERTa、ALBERT、DistilBERT、ELECTRA、DeBERTa
4、 强化学习介绍
4.1 什么是强化学习
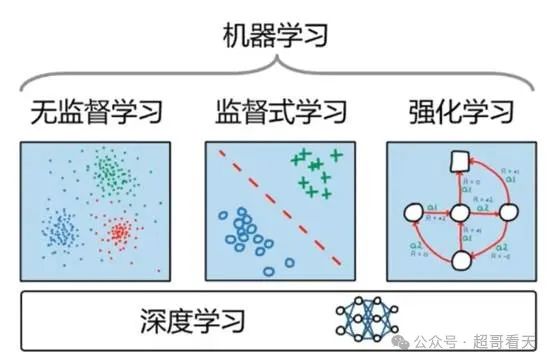
强化学习(Reinforcement Learning,RL)是机器学习的三大范式之一,与监督学习、无监督学习并列。它最大的特点,是通过与环境互动,在不断试错中“学习”如何做出最优决策。
4.2 强化学习的发展历史
强化学习本来是行为心理学中的概念,20世纪70-90年代,随着计算机科学的发展,强化学习逐步被数学化和算法化。其发展的重要时间节点包括:
• 1989年:Watkins提出Q-learning算法,为后续发展奠定基础。
• 1990年代:蒙特卡洛方法、时序差分学习(TD Learning)等基础理论完善。
• 2000年代:计算资源和仿真环境仍有限,实际应用受限。
• 2013年:DeepMind提出Deep Q Network(DQN),将深度学习引入强化学习,实现了在Atari游戏中超越人类。
• 2016年:AlphaGo 横空出世,融合强化学习、自我对弈和深度神经网络,击败李世石。此后,强化学习成为AI领域的研究热点,在工业界、学术界全面开花。
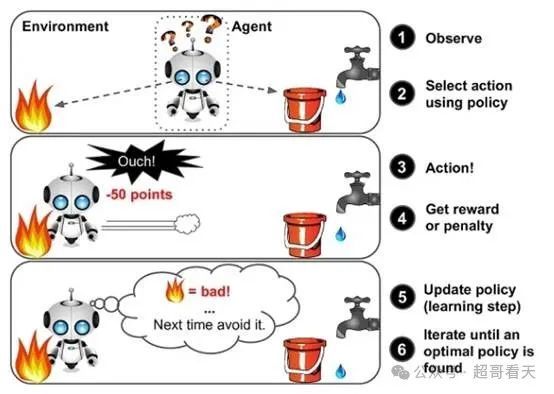
4.3 强化学习的核心要素
强化学习包括以下几个核心要素:
- 智能体(Agent):执行动作的学习者。
- 环境(Environment):智能体与之互动的对象。
- 状态(State):当前环境的描述。
- 动作(Action):智能体可以采取的行为。
- 奖励(Reward):智能体执行动作后获得的反馈,用于评估动作好坏。
- 策略(Policy):智能体根据当前状态选择动作的规则模型。
- 价值函数(Value Function):用来估计某个状态或“状态-动作对”的“价值”,即智能体在该状态下可能获得的总奖励。

4.4 机器学习三大范式比较
- 监督学习(Supervised Learning):通过大量标注数据进行训练,学习如何从输入数据中预测输出。比如,训练一个识别猫和狗的图像分类器,需要大量标注好的图片作为训练数据。
- 无监督学习(Unsupervised Learning):不需要标注数据,目的是让算法从数据中发现潜在的模式或结构。例如,聚类算法可以帮助我们将类似的数据点分为一组。
- 强化学习(Reinforcement Learning):智能体不依赖标签,而是通过与环境互动,获得“奖励”或“惩罚”,从而学会如何选择最优行为。
一个简单的比喻:
监督学习像学生对照着标准答案写作业,无监督学习像学生自己总结学习规律,强化学习像学生在游戏中摸索规则,通过胜败不断优化学习策略。
强化学习最适用于那些无法提前列出正确答案,但可以通过长期观察“结果好不好”来评估行为的任务,比如下棋、开车、投资、打游戏等。
4.5 强化学习与深度学习的关系
强化学习和深度学习是机器学习中两个不同的分支,深度学习可以与监督学习、自监督学习以及强化学习三大范式结合,形成一些功能强大的子领域。
比如,强化学习和深度学习相结合,可以形成深度强化学习(Deep Reinforcement Learning,DRL)。这种结合通过将深度学习中的神经网络技术应用到强化学习中,能够处理更复杂的环境和任务,比如处理图像驱动的机器人导航等,大大扩展了强化学习的应用范。
4.6 强化学习的应用
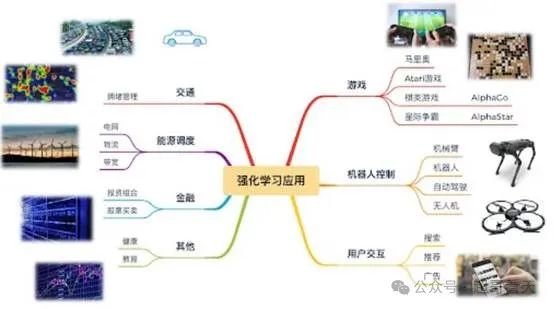
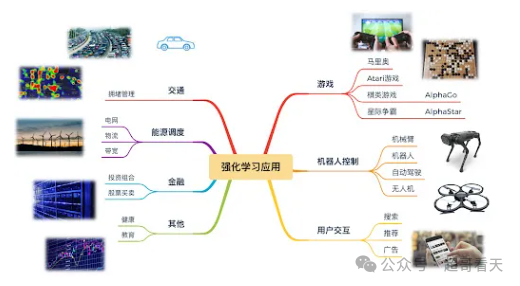
强化学习已经在多个领域取得了显著的进展:
- 游戏:强化学习的一个成功应用例子是Google DeepMind开发的AlphaGo,它通过与自己对弈,学习到超越人类的围棋技巧。
- 自动驾驶:自动驾驶汽车通过强化学习优化驾驶策略,使得车辆能够更好地应对复杂的路况。
- 机器人控制:强化学习帮助机器人通过反复试验,学习如何完成复杂任务,如搬运物体、组装零件等。
- 推荐系统:许多互联网公司利用强化学习优化推荐系统,根据用户的行为反馈(如点击、购买)调整推荐内容,提升用户体验。
- 金融决策系统:用于高频交易、投资组合管理、风险控制等领域,强化学习能在市场波动中寻找最优操作策略。
4.7 强化学习的挑战与未来
尽管强化学习在许多领域取得了显著的成绩,但它仍然面临一些挑战。
- 训练效率低:往往需要数百万次试验才能学出好策略,这在现实世界中成本极高。
- 不稳定性强:小小的扰动可能导致策略崩溃,训练过程中容易震荡甚至失败。
- 泛化能力差:在一个环境中训练好的策略,很难迁移到另一个稍有不同的环境。
- 安全性问题:在自动驾驶、金融等敏感场景中,策略不稳定可能带来严重后果。
为此,研究者正在探索:
1.模仿学习(Imitation Learning):先观察人类行为,再微调强化学习。
2.元学习(Meta-RL):学会“如何学习”,提升在新环境中的适应速度。
3.层次强化学习(Hierarchical RL):将任务分解为多个子任务,提高效率。
4.多智能体强化学习(Multi-Agent RL):研究多个智能体之间的博弈、协作机制。
4.8 总结
强化学习是一种模拟人类决策行为的学习机制,它不依赖明确的标签数据,而是通过试错和反馈机制让智能体不断改进自身策略。这种模式特别适合复杂、动态、不确定的现实世界问题。在人工智能领域,强化学习属于一种高级的学习方式,在AI应用中扮演着极为重要的角色,尤其在决策、控制、优化等任务中占据了核心地位。
5、 深度学习介绍
5.1 什么是深度学习
深度学习(Deep Learning**,DL****)是一种模仿人脑神经网络结构的人工智能技术。它通过建立多层“神经元”网络**,让计算机可以自动从大量数据中学习特征、发现模式并做出预测。
深度学习是机器学习的一个分支,其特点是无需显式人工设计特征(但仍需数据预处理和超参数调整),就能够处理图像、语音、文本等高维复杂数据,因此被广泛应用于自动驾驶、语音识别、自然语言处理等领域。当前,深度学习已成为人工智能领域最主流的技术手段。
5.2 深度学习在人工智能中的位置
人工智能(AI**)**是一个广泛的领域,目标是让机器能够模拟人类智能,比如学习、推理、问题解决等。**机器学习(ML)是AI的一个子集,指的是让计算机通过数据学习模式,而不需要显式编程。而深度学习(DL)**是机器学习的一个分支,使用深层神经网络来处理复杂的数据,如图像和语音等。**神经网络(NN)**是一种模仿人脑的数学框架,它是深度学习的基础工具,但深度学习不仅限于神经网络(理论上有其他可能,但实践中NN占主导)。
人工智能(AI)、机器学习(ML)、深度学习(DL)和神经网络(NN)的关系可用下图表示:
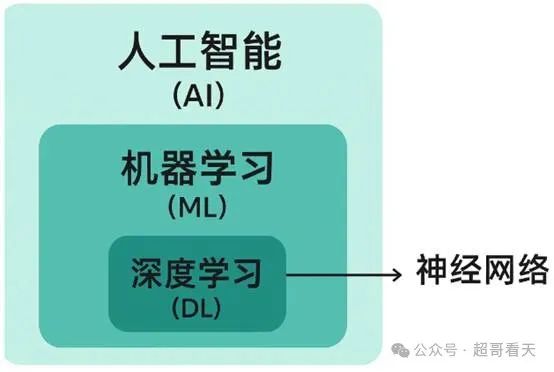
人工智能(AI):让机器模拟人类智能的总称,涵盖规则系统、专家系统等传统技术。
机器学习(ML):AI的核心实现方式,通过数据驱动模型学习规律,替代人工编程规则。
深度学习(DL):基于深度神经网络的机器学习方法,可自动提取数据中的多层次特征。
神经网络(NN):由互连神经元组成的数学模型,是深度学习的基础架构。(前面有梳理过,可参看机器学习之什么是“卷积神经网络”)
5.3 深度学习的“深”
深度学习中的“深度”,主要指的是神经网络的隐藏层数多(也叫网络深度)。
在深度学习兴起之前,传统的人工神经网络(ANN)一般只有1~2层“隐藏层”。这种网络叫做:浅层神经网络(Shallow Neural Network),它的学习能力有限,只能处理一些简单的特征或规则。
而深度学习引入了多层(几十、几百甚至上千层)神经网络结构,每一层都可以提取更抽象、更高阶的特征,其结果就是:模型的“理解能力”和“泛化能力”显著增强。
所以,深度学习就是“多层神经网络”的学习方式,相对于“浅层神经网络”来说,它更‘深’”。
以图像识别任务为例,深度学习的多层网络处理步骤为:
第1层:识别边缘、颜色
第2层:组合成角、圆形等几何形状
第3层:构建“眼睛”“耳朵”等器官轮廓
第4层:合成完整的“猫脸”或“人脸”
层数越多,模型的“理解”能力就越强。这种多层结构使得深度学习在语音、图像、自然语言等任务中的表现远远优于传统方法。
深度学习的典型模型:
- CNN(卷积神经网络):图像识别(如ResNet)
- RNN(循环神经网络):时序数据处理(如LSTM用于语音识别)
- Transformer:自然语言处理(如BERT、GPT)

5.4 之前的主流机器学习技术
在2012年之前,主流的机器学习方法包括:
- 支持向量机(SVM):非常强大的分类器,适合小数据、线性或非线性问题,但对大规模数据、图像、语言等复杂任务表现不佳。
- 决策树 & 随机森林:结构清晰,可解释性强,适合业务逻辑分析,但对图像、语音处理能力有限。
- K最近邻(KNN)、朴素贝叶斯(Naive Bayes):算法简单易实现,但模型能力有限。
- 人工神经网络(浅层):最早的“类脑模型”,但训练困难,表现一般。
5.5 深度学习打败”传统方法
**关键转折点:**2012年 ImageNet 图像识别比赛,一个叫 AlexNet 的深度神经网络横空出世,它用GPU训练,有8层结构(比以往都深),在上百万张图像数据上表现远超传统算法。
**结果:**深度学习一战成名,开启AI新时代。此后各种更深的网络,如VGG(16~19层)、ResNet(可达100层以上)、Transformer(语言领域的王者)等陆续诞生。
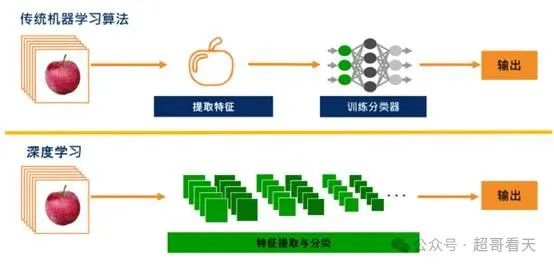
5.6 深度学习和传统方法的核心差异
以图像识别为例:
传统方法(如SVM**):**需要“人工特征工程”,人手动提取颜色、纹理、边缘等特征;模型本身不具备“理解”能力,只是“在已知特征上分类”;泛化能力弱,易受干扰。
深度学习(如CNN**):输入原始像素,模型自动从低级到高级提取特征;模型自己学会“看图识物”,无需人工干预;对遮挡、光照变化鲁棒性**更强。
鲁棒性(Robustness)是指一个系统、模型或算法在面对异常输入、噪声干扰、数据分布变化或极端条件时,仍能保持稳定性和可靠性的能力。这一概念源自控制工程,后广泛应用于计算机科学、人工智能等领域,尤其在深度学习中成为衡量模型实用性的关键指标。
5.7 为什么以前没办法用深度学习
早在上世纪80年代,“多层神经网络”就已被提出,但苦于以下限制:
1. **计算能力差:**没有GPU,训练慢得可怕;
2. **数据太少:**无法支撑复杂模型的学习;
3. **算法不成熟:**梯度消失问题导致深层网络难以训练。
所以直到2010年之后,这些技术障碍被逐一扫除,深度学习才最终在坐了多年冷板凳后,一跃成为人工智能领域炙手可热的主流技术。
5.8 未来发展
深度学习已经成为现代AI的基石。它推动了ChatGPT、Midjourney等生成式AI、自动驾驶、医疗AI、多模态融合(图文音协同理解)等变革的发生。
目前深度学习的研究正从“更深”走向“更通用”,其未来目标是构建具有推理、常识、逻辑、情感等能力的“类人智能”。
深度学习不是一夜爆红的黑科技,而是经过数十年理论、工程和硬件突破的结晶。它之所以“深”,是因为模型层数深、学习能力深、影响力深。理解它,不只是了解一项技术,更是在理解人工智能时代的内核。
6、 智能体介绍
6.1 什么是智能体(AI Agent)
产业界和学术界通常把AI Agent翻译成“智能体”,而“agent(代理)"起源于哲学,指的是一种拥有欲望、信念、意图以及采取行动能力的实体。在人工智能领域,这一术语被赋予了一层新的含义:具有自主性、反应性、交互性等特征的智能“代理”。可以简单理解为你只需告诉Agent要完成的任务,Agent可以代替你去执行,最后把结果反馈给你。比如你只需告诉agent要订一张什么时间、去什么地方的机票,它会自动搜索、下单、支付完成订票的整个过程,中间无需个人干预。代理人不仅包括人类个体,还包括物理世界和虚拟世界中的其他实体,如机器人、代理程序等。首次提出”AI Agent“的是人工智能学者马文・明斯基(Marvin Minsky)。他在《思维的社会》一书中,把思维看作由大量相互作用的智能体(Agent)构成的复杂系统。每个智能体都执行特定的任务,并通过协作完成复杂的认知活动。例如在视觉感知中,可能存在专门负责识别边缘的智能体、识别颜色的智能体等,它们协同工作,使我们能够理解看到的图像。他认为社会中的某些个体经过协商之后可求得问题的解,这些个体就是 Agent,且 Agent 应具有社会交互性和智能性。Agent 的概念由此被引入人工智能和计算机领域,并迅速成为研究热点。
6.2 智能体的框架和主要功能
OpenAI 的应用研究主管 Lilian Weng 提出了“Agent=LLM + 规划 + 记忆 + 工具+行动”的基础架构,其中 LLM 扮演了 Agent 的“大脑”,在这个系统中提供推理、规划等能力。
1)记忆:智能体具有短期记忆和长期记忆,用于存储和检索信息。
2)规划:智能体通过规划来决定如何实现目标,包括:反射(Reflection)、自我反思(Self-Reflection)、思维链(Chain of Thought)、子目标拆解(Subgoal Decomposition)
3)工具:智能体可以自动调用各种工具,例如:日程安排、电商下单、代码解释器、搜索
4)行动:智能体根据规划的结果采取行动
AI Agent功能主要包括感知、分析、决策和执行四大能力。首先是感知能力,通过传感器获取外部环境的信息,使AI Agent能够对周围的情况有所了解。其次是分析能力,通过对感知到的信息进行分析和处理,提取有用的特征和模式。然后是决策能力,AI Agent基于分析结果进行决策,制定相应的行动计划。最后是执行能力,将决策转化为具体的行动,实现任务的完成。这四大能力相互配合,使得AI Agent能够在复杂的环境中高效地运行和执行任务。比如,最近很火Manus,用户仅需告诉它你的需求,它便能自行搜索信息、思考问题并最终输出符合逻辑且质量优良的结果。Manus会学习用户的偏好,下次处理类似任务时将优先应用用户希望的结果展示或者根据用户的喜好帮助用户做出选择。这种自动化、智能化的处理方式无疑增加了工作效率。
AI Agent还可以根据Agent的行为对感知智能和能力的影响模式,分为不同类型,包括简单反射代理、基于模型的代理、基于目标的代理、基于效用的代理、学习代理和层次代理。这些代理可以根据其期望的结果或目标来确定决策和行动过程的最佳路径,从而实现特定的目的。
6.3 为什么需要智能体
大语言模型(LLM)主要侧重于对自然语言等数据理解和处理,虽然也能处理简单的对话和任务,但这种任务是交互式的,即通过提示词一步一步来回答问题比如你让 ChatGPT 买一杯咖啡,ChatGPT 给出的反馈一般类似“无法购买咖啡,它只是一个文字 AI 助手”之类的回答。但你要告知基于 ChatGPT 的 AI Agent 工具让它买一杯咖啡,它会首先拆解如何才能为你购买一杯咖啡并自动调用一系列下单以及支付等若干步骤,然后按照这些步骤调用 APP 选择外卖,再调用支付程序下单支付,过程无需人类去指定每一步操作。
另外,更擅长在多主体环境中进行交互和协作。多个 AI Agent 之间可以通过特定的通信协议和机制,进行信息共享、协商和协同工作,共同完成复杂的任务。在智能工厂中,不同的 AI Agent 可以分别负责生产调度、质量检测、设备维护等任务,它们之间相互协作,保障工厂的高效运行。
AI agent 在金融行业的应用表现为通过自动化完成繁琐的工作来改变金融专业工作流程。AI Agent可直接嵌入到工作流程中,可通过搜索网络、分析公开文件、与财务数据源集成以及利用语言大模型为上市和私营公司生成文件,通过专有数据集成以客户自定义格式自动生成报告。
AI Agent通过提供快速、个性化的响应来增强客户满意度,同时降低企业的运营成本。AI Agent的多语言能力和全天候服务提升了客户的互动体验。此外,通过精准的数据收集与分析,AI Agent帮助企业洞察市场趋势,优化产品与服务,制定更有效的市场策略。
6.4 技术架构与应用
6.4.1 定义与核心架构
AI Agent(智能体)是一种能够感知环境、自主决策并执行任务的智能实体,具备自主性、反应性、规划性和交互性。其核心目标是通过与物理或数字环境的动态交互,实现复杂任务的自动化完成。
大模型智能体(LLM-based Agents)是基于大型语言模型(LLM)的AI Agent,以LLM为核心“大脑”,结合规划、记忆、工具调用等能力,实现类人的推理与执行能力。
核心架构
控制端(Brain)
LLM核心:负责推理、规划和决策,如GPT-4、LLaMA等模型。
规划能力:通过思维链(CoT)、思维树(ToT)等技术分解复杂任务,例如将“订机票”拆解为搜索、比价、支付等子任务。
记忆模块:分为短期记忆(任务上下文)和长期记忆(外部知识库/向量数据库),支持历史经验检索与复用。
感知端(Perception)
多模态输入处理:文本、图像、音频等信息的编码与对齐,例如通过CLIP模型处理视觉输入。
工具调用:集成搜索引擎、代码解释器等外部工具,增强环境感知能力。
行动端(Action)
文本输出:生成自然语言响应。
物理/数字操作:如控制鼠标点击、调用API执行支付、操作机器人等。
6.4.2 关键技术
(1)规划与推理
任务分解:通过ReAct框架(推理+行动循环)动态调整执行路径,例如先搜索信息再生成报告。
反思优化:根据环境反馈或人类干预修正错误,如AlphaGo通过自我对弈提升策略。
(2)记忆管理
向量数据库:存储长期知识,支持高效检索(如Chroma、Milvus)。
记忆压缩与摘要:通过Transformer扩展上下文窗口或生成摘要,解决Token长度限制。
(3)多模态扩展
视觉处理:将图像转换为文本描述(Image Captioning)或结合视觉基础模型(如LLaVA)直接编码。
跨模态协作:如智谱的AutoGLM支持跨App操作(微信+高德地图联动),实现50步以上的连贯任务。
(4)工具赋能
API集成:调用天气查询、支付接口等外部工具,扩展功能边界。
自主工具学习:通过强化学习(RLHF)优化工具使用策略,减少人工干预。
6.4.3 应用场景
(1)行业应用
办公自动化:Microsoft 365 Copilot自动生成会议纪要、钉钉AI助理处理审批流程。
金融与政务:自动生成报告(如Manus智能体)、智能行政审批(渊亭科技)。
科研辅助:MetaGPT框架支持文献检索、实验模拟与数据分析。
(2)消费级应用
跨平台操作:智谱AutoGLM可操控微信、淘宝等App,完成跨应用购物或信息整合。
游戏与娱乐:Claude 3.5 Sonnet代肝游戏任务,Anthropic智能体模拟人类设备操作。
(3)多Agent协作
群体智能:多个Agent分工协作,如工厂中生产调度、质检Agent联动。
人机协同:Instructor-Executor模式中,人类指导Agent优化任务(如医疗诊断辅助)。
6.5 国内外主要智能体厂商和产品
中国当下的AI Agent市场已经迎来丰富的参与者,包括互联网大厂类、生成AI类、企服SaaS类、创业类、3C类等多类型企业。这些企业依据自身技术或行业know-how迅速切入市场,通过先手占据更好的生态占位;并且越来越多的企业正在进行产品打磨与场景探索。
字节跳动(COZE)。扣子Coze是字节跳动新一代的AI Bot 开发平台,适用于快速、低门槛搭建专属于个人的Chatbot,并一键发布到豆包、飞书、微信等各个渠道。
阿里云(钉钉)。2024年4 月18 日,钉钉正式上线AI 助理市场(AI Agent Store)。首批上架了200 +AI助理,通过Agent Store 的这种创新模式可以显著降低创作门槛并吸引更多用户,各行各业的人都可以拥有自己专属的助理。
用友大易。用友大易成立于2007年,是用友集团旗下成员企业。TRM.AI2.0是国内首家基于企业服务大模型的智能招聘系统,运用先进的AI技术,帮助企业建立精细化的人才招聘与运营体系。
Manus:全球首款通用型 AI Agent 产品,以“手脑并用”为核心,通过规划、验证与执行闭环,能够独立完成简历筛选、房产遴选等复杂任务。
智谱 AI:推出自主智能体AutoGLM,基于智谱 AI 的大模型等技术,能完成多种复杂任务,可根据用户需求进行文本创作、知识问答、任务规划等,推动了国产 AI 智能体的发展。
昆仑万维:发布了“天工 SkyAgents”平台,用户无需代码编程,通过自然语言和简单操作,几分钟内就可部署属于自己的 AI Agents,可完成行业研究报告、健身计划制定、旅行航班预定等私人定制需求。
Microsoft。微软推出的企业级AI助手Microsoft 365 Copilot Chat,支持AI Agent功能,能够自动化处理日常办公任务,如文档编辑、会议安排等。其Copilot Studio平台已建立全球最大的企业级AI Agent生态系统,超过10万家企业使用。
t协作
群体智能:多个Agent分工协作,如工厂中生产调度、质检Agent联动。
人机协同:Instructor-Executor模式中,人类指导Agent优化任务(如医疗诊断辅助)。
6.5 国内外主要智能体厂商和产品
中国当下的AI Agent市场已经迎来丰富的参与者,包括互联网大厂类、生成AI类、企服SaaS类、创业类、3C类等多类型企业。这些企业依据自身技术或行业know-how迅速切入市场,通过先手占据更好的生态占位;并且越来越多的企业正在进行产品打磨与场景探索。
字节跳动(COZE)。扣子Coze是字节跳动新一代的AI Bot 开发平台,适用于快速、低门槛搭建专属于个人的Chatbot,并一键发布到豆包、飞书、微信等各个渠道。
阿里云(钉钉)。2024年4 月18 日,钉钉正式上线AI 助理市场(AI Agent Store)。首批上架了200 +AI助理,通过Agent Store 的这种创新模式可以显著降低创作门槛并吸引更多用户,各行各业的人都可以拥有自己专属的助理。
用友大易。用友大易成立于2007年,是用友集团旗下成员企业。TRM.AI2.0是国内首家基于企业服务大模型的智能招聘系统,运用先进的AI技术,帮助企业建立精细化的人才招聘与运营体系。
Manus:全球首款通用型 AI Agent 产品,以“手脑并用”为核心,通过规划、验证与执行闭环,能够独立完成简历筛选、房产遴选等复杂任务。
智谱 AI:推出自主智能体AutoGLM,基于智谱 AI 的大模型等技术,能完成多种复杂任务,可根据用户需求进行文本创作、知识问答、任务规划等,推动了国产 AI 智能体的发展。
昆仑万维:发布了“天工 SkyAgents”平台,用户无需代码编程,通过自然语言和简单操作,几分钟内就可部署属于自己的 AI Agents,可完成行业研究报告、健身计划制定、旅行航班预定等私人定制需求。
Microsoft。微软推出的企业级AI助手Microsoft 365 Copilot Chat,支持AI Agent功能,能够自动化处理日常办公任务,如文档编辑、会议安排等。其Copilot Studio平台已建立全球最大的企业级AI Agent生态系统,超过10万家企业使用。
Claude 3.5 Sonnet。在医药研发中展现强大能力,支持数据分析和决策辅助。
一、大模型风口已至:月薪30K+的AI岗正在批量诞生
2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K(数据来源:BOSS直聘报告)
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
相信大家在刚刚开始学习的过程中总会有写摸不着方向,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程等免费分享出来。
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以微信扫码领取!

大模型星球
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先有一个明确的学习路线,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(完整路线在公众号内领取)

大模型学习路线
👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,需要的扫描下方二维码领取 **


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)