DataFrame()对象--Pandas
创建DataFrame对象
1. DataFrame的创建
DateFrame对象是Pandas最常用的数据结构,是由不同类型的列组成的二维数据表结构,类似于EXCEL表,语法格式如下:
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
1.1 函数参数:data
| 参数 | 含义 |
|---|---|
| data | 创建DataFrame的数据 |
DataFrame的data参数接收多种类型的输入:
1.1.1 Series 的字典
1.1.1.1 Series的index不同,创建的DataFrame索引index取并集
两个索引不同的Series组成的字典构成DataFrame,生成的DataFrame的结果将是两个Series索引的并集,没有对应的数据以空值NaNbu补充。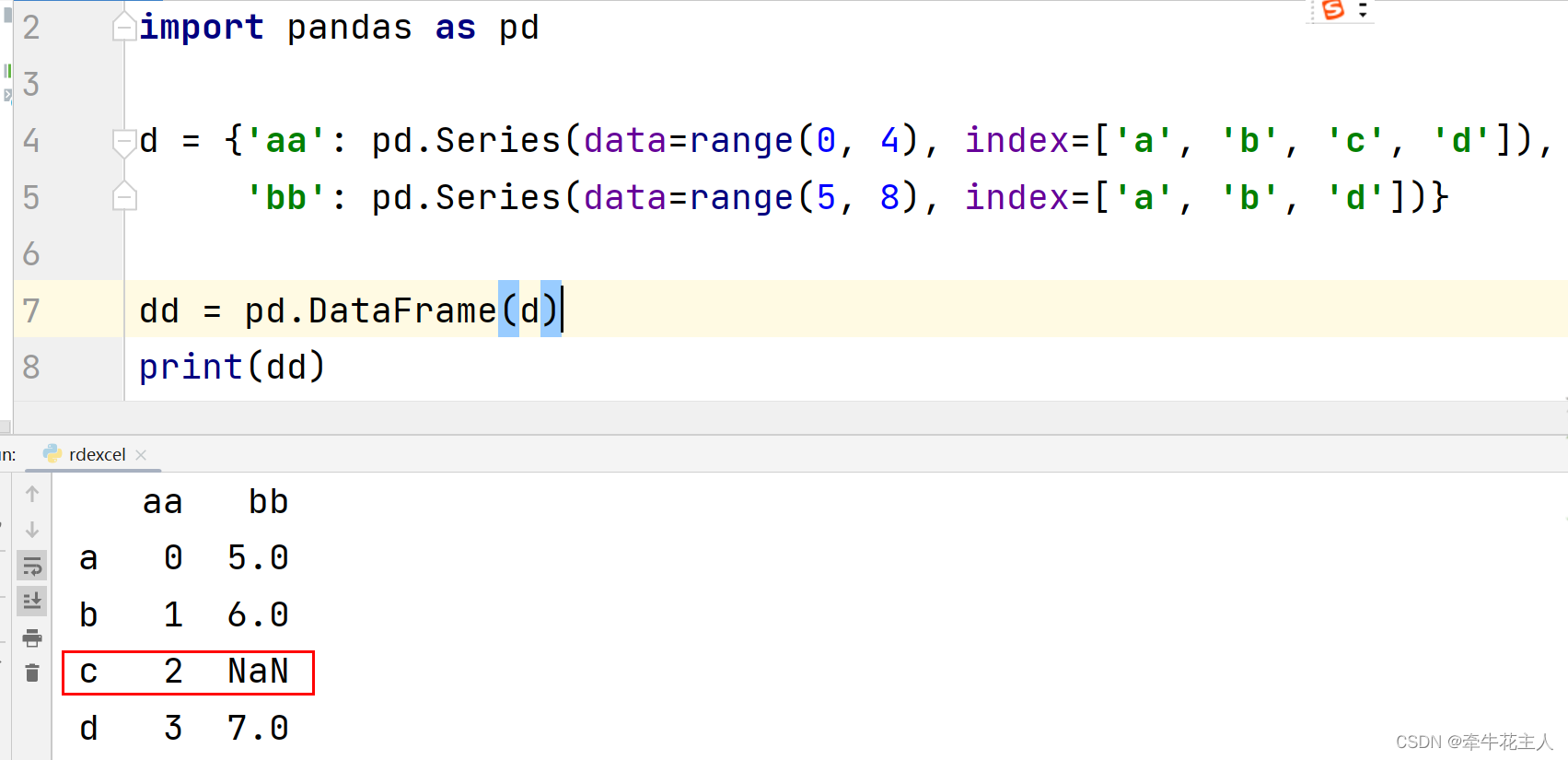
1.1.1.2 创建DataFrame时指定Index
当指定索引,生成的DataFrame将仅保留指定的索引对应的值,其他值将被丢弃。
sr = pd.DataFrame({'a': pd.Series(np.random.randint(10, 20, 4), index=['aa', 'bb', 'cc', 'dd']),
'b': pd.Series(np.random.randint(0, 9, 6), index=['aa', 'cc', 'dd', 'ee', 'ff', 'gg'])},
index=['aa', 'cc', 'ff'])
print(sr)

1.1.1.3 指定的columns列名不一致
对于列名,默认按照字典键的有序列表,若指定列名,则列名与字典键相同时,数据存在,若列名不存在字典的键中,则以控制NaN填充
sr = pd.DataFrame({'a': pd.Series(np.random.randint(10, 20, 4), index=['aa', 'bb', 'cc', 'dd']),
'b': pd.Series(np.random.randint(0, 9, 6), index=['aa', 'cc', 'dd', 'ee', 'ff', 'gg'])},
index=['aa', 'cc', 'cc','ee'],columns=['a','c'])
print(sr)

1.1.1.4 获取行/列名
DataFrame的行名和列名可以通过属性index与columns获取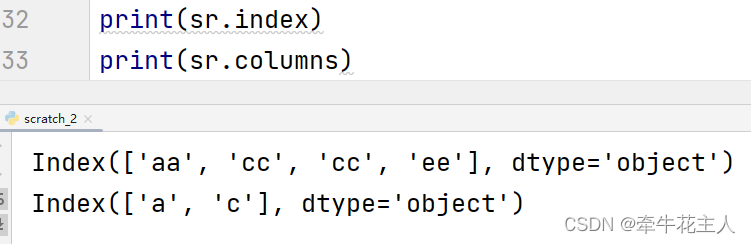
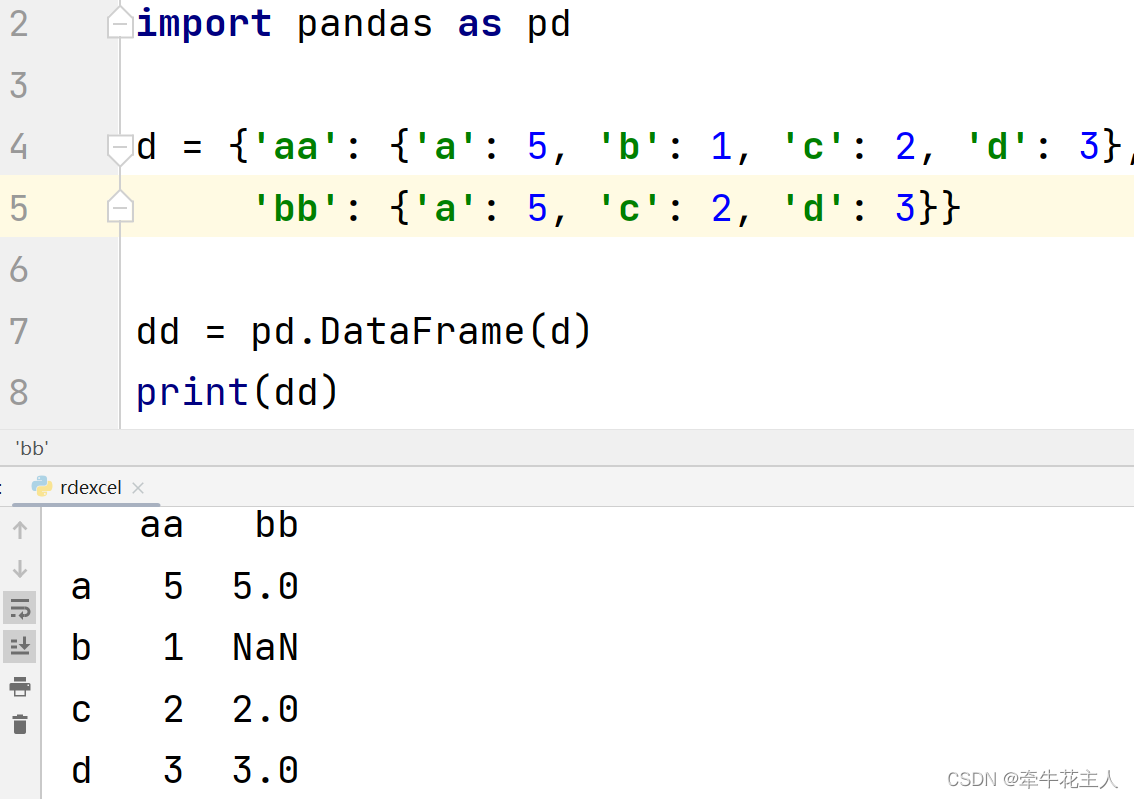
1.1.2 Dicts 的字典
1.1.3 ndarrays 的字典
构成DataFrame的ndarrays的长度必须相同,若指定索引Index,则传入的索引index的长度与必须与ndarray数据的长度相同。默认索引为range(n):n为数据长度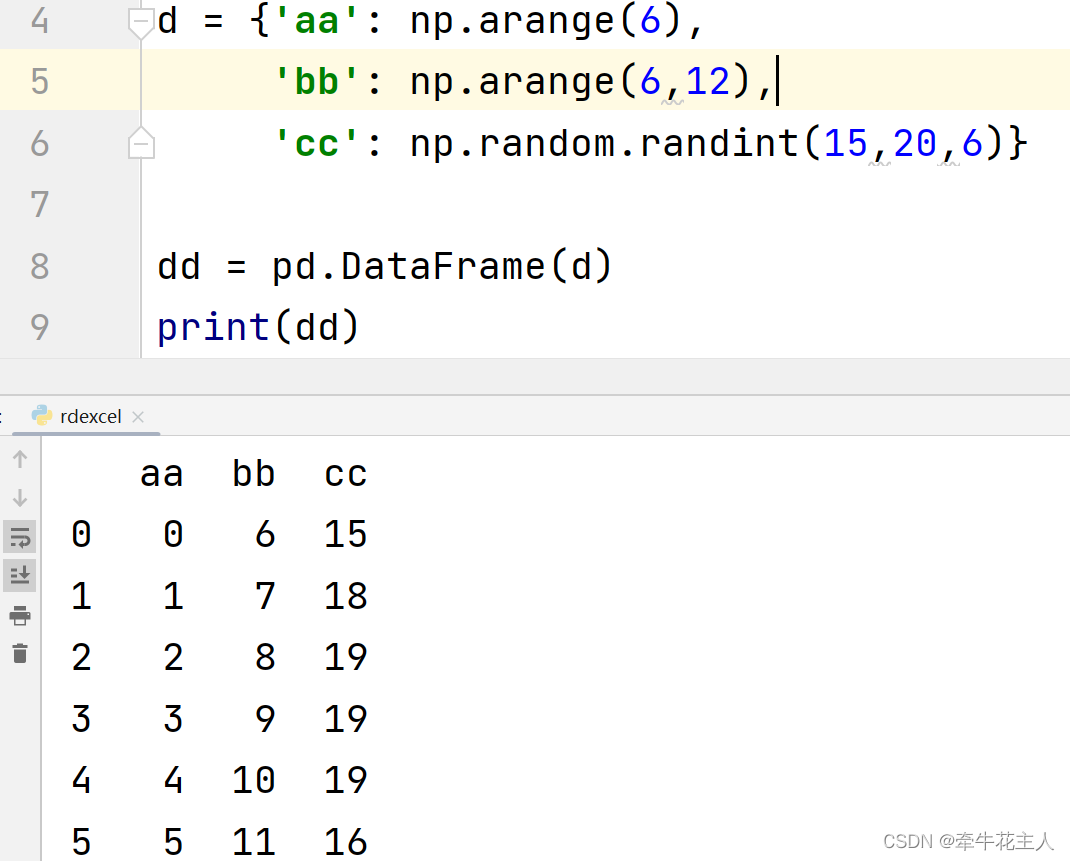
1.1.4 lists 的字典
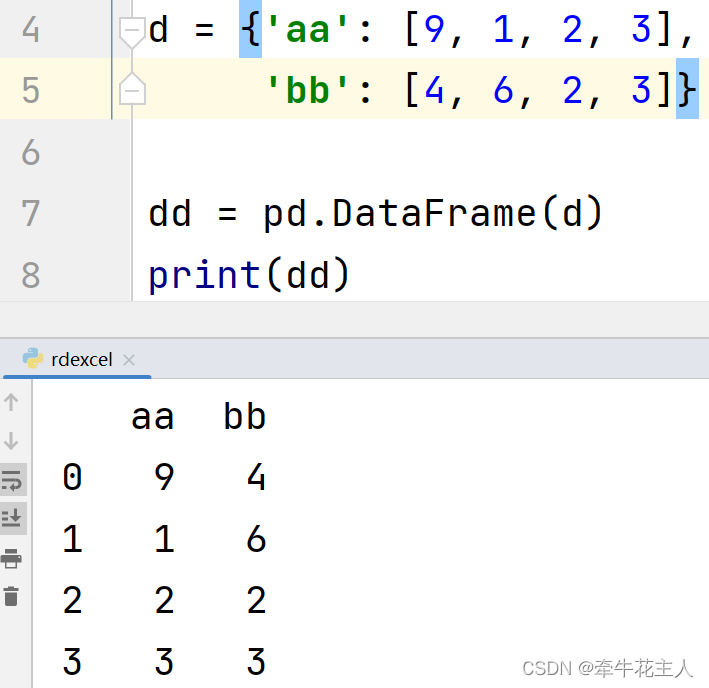
1.1.5 Series
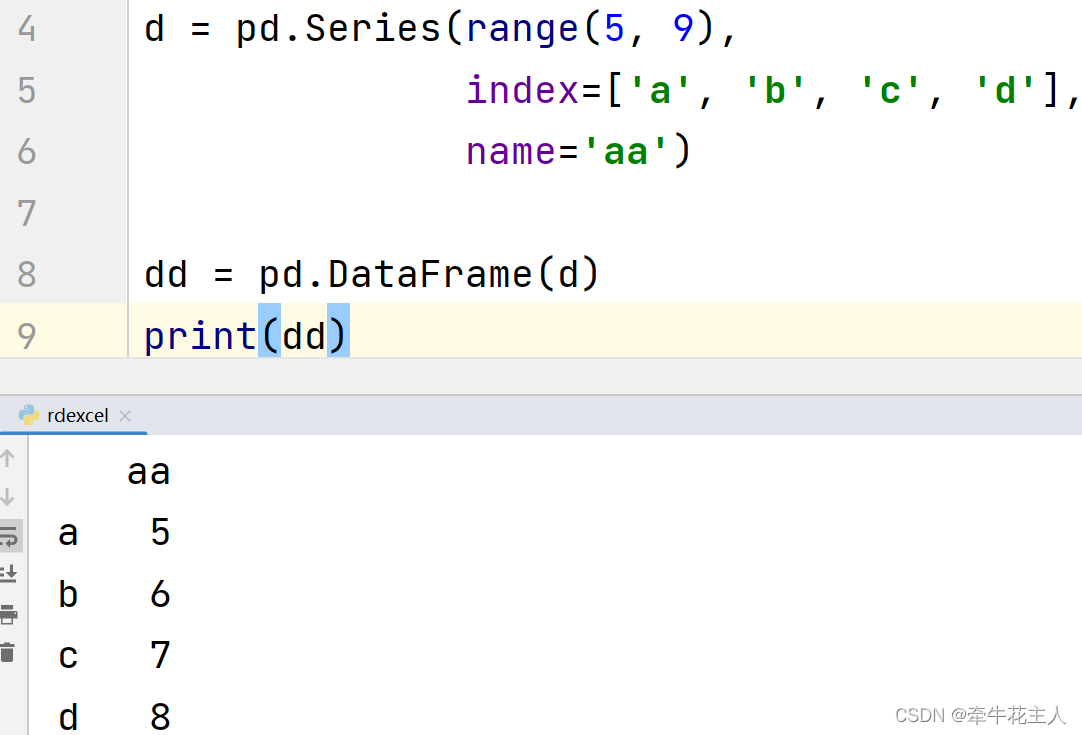
1.2 函数参数:index
| 参数 | 含义 |
|---|---|
| data | 创建DataFrame的数据 |
| index | 产生的DataFrame的索引,当数据中不包含index且创建时没有输入Index参数内容,默认为range(n) |
1.2.1 不指定index
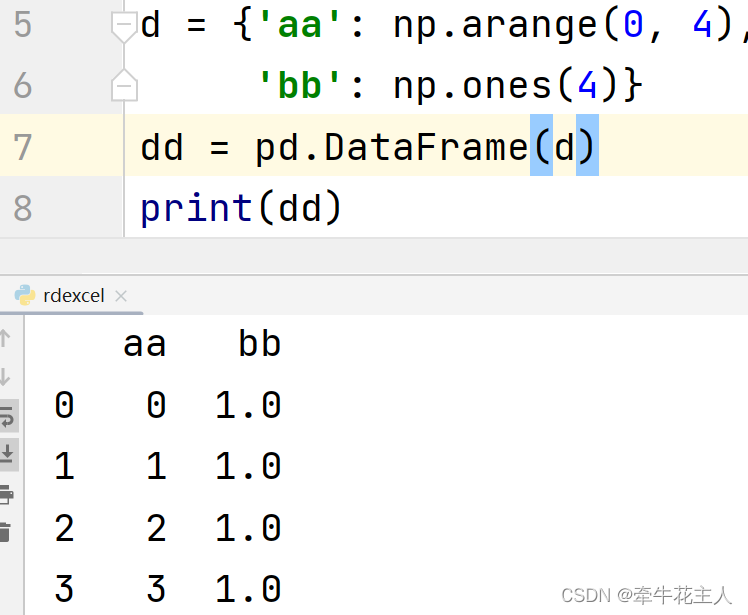
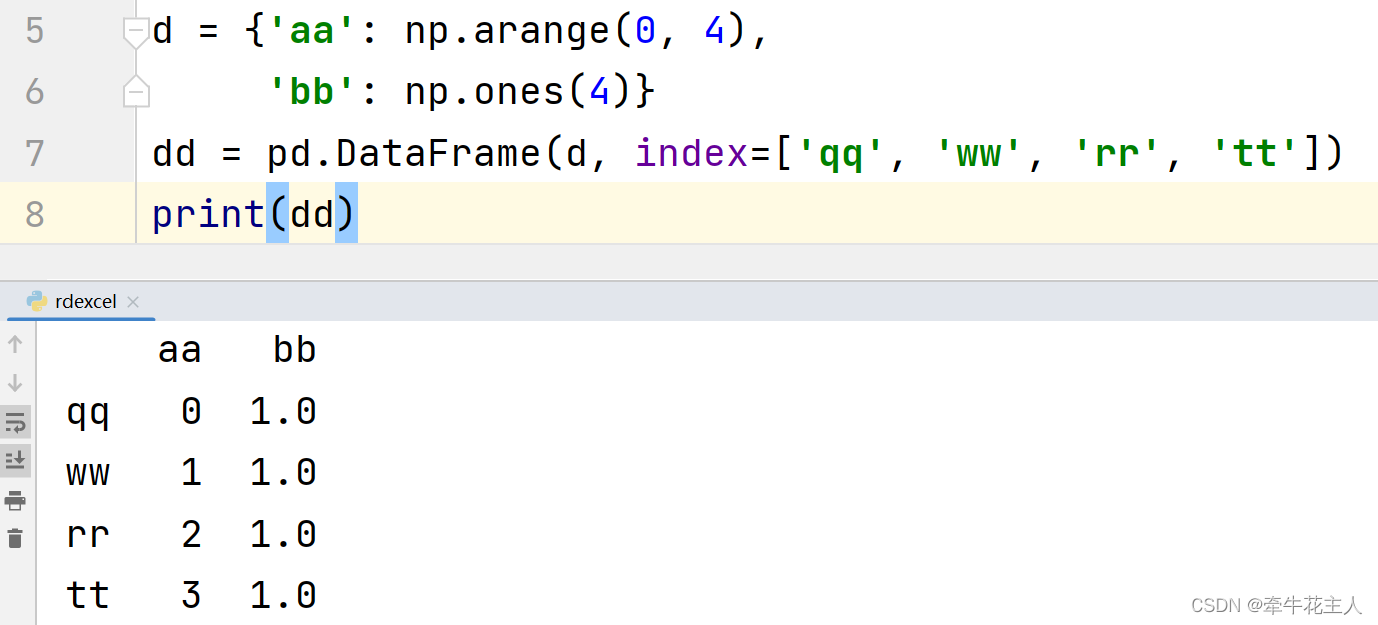
1.2.2 指定index
1.2.3 当data为Series
当输入数据为Series时,产生DataFrame的结果会与Series的索引一致,当创建DataFrame时如果指定的index与Series的索引不一致,DataFrame将去掉指定索引中不存在的数据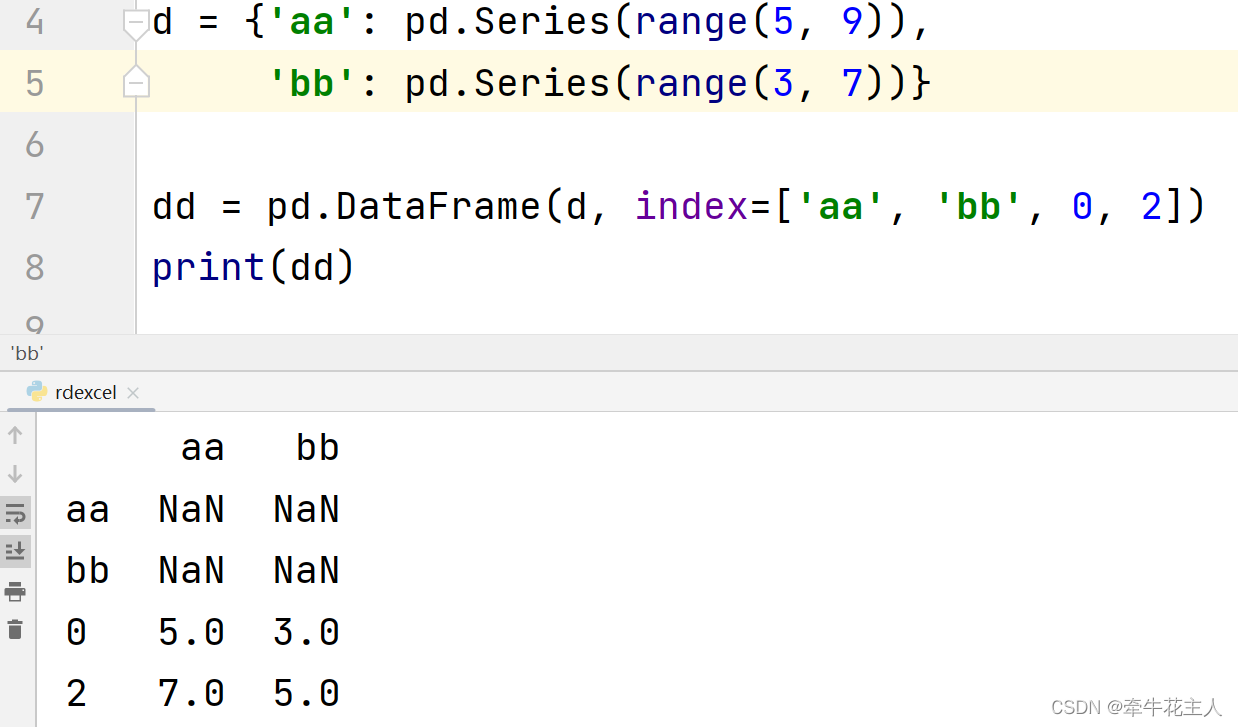
1.3 函数参数:columns
| 参数 | 含义 |
|---|---|
| data | 创建DataFrame的数据 |
| index | 产生的DataFrame的索引,当数据中不包含index且创建时没有输入Index参数内容,默认为range(n) |
| columns | 创建DataFrame的列标签,当data中没有传入列标签时,默认为range(n);当data中传入了列标签,此时的columns参数作用是筛选 |
1.3.1 data中未指定列标签
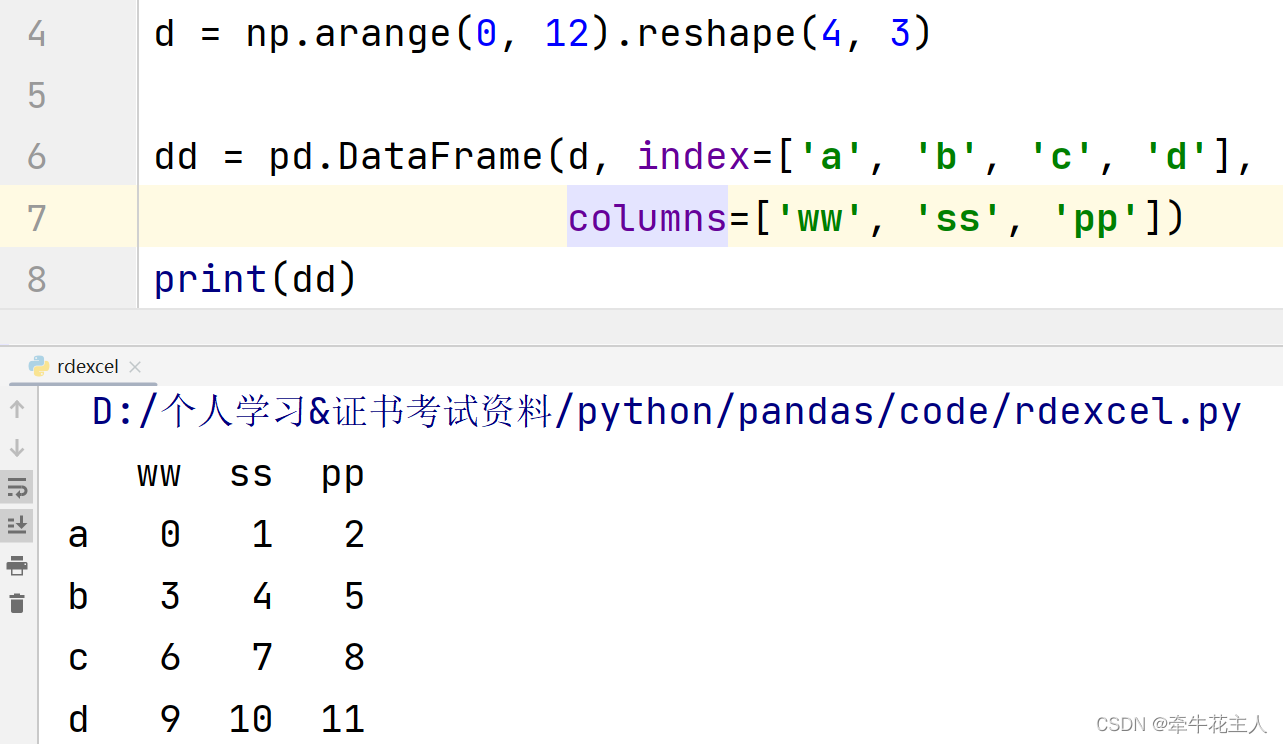
1.3.2 data中指定了列标签
此时的column参数作用为筛选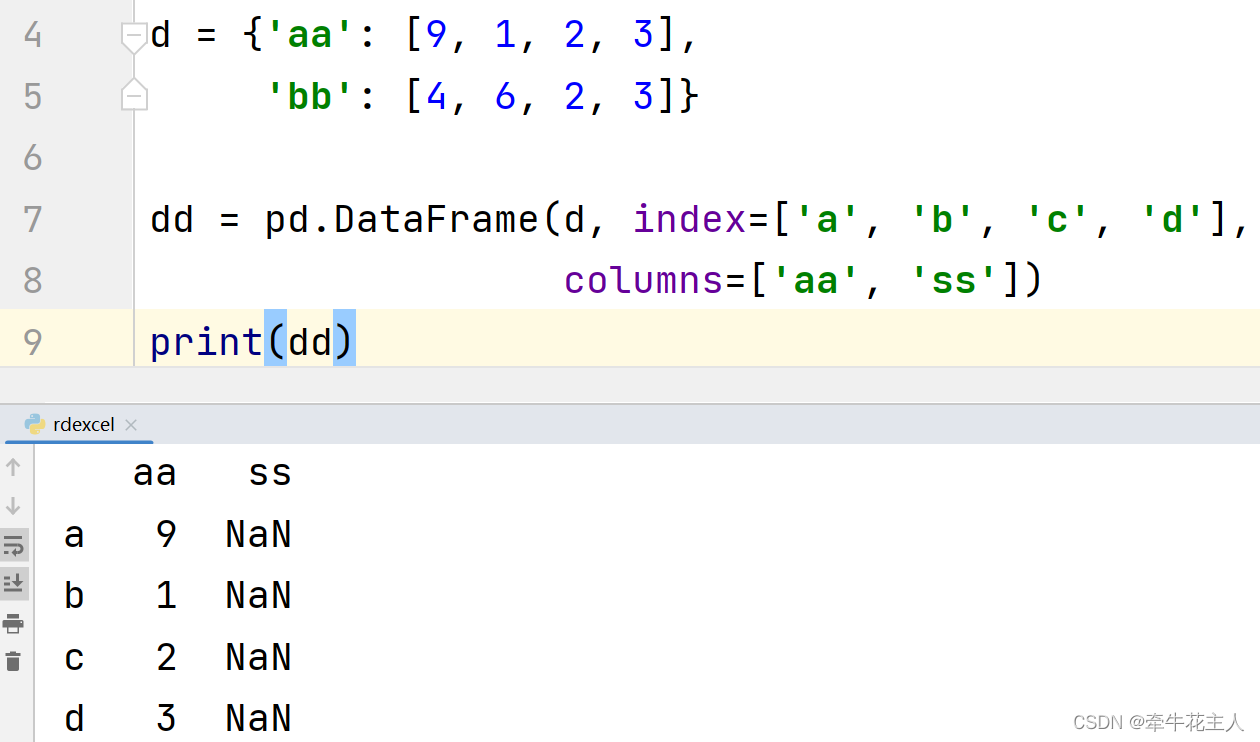
1.4 函数参数:dtype
| 参数 | 含义 |
|---|---|
| data | 创建DataFrame的数据 |
| index | 产生的DataFrame的索引,当数据中不包含index且创建时没有输入Index参数内容,默认为range(n) |
| columns | 创建DataFrame的列标签,当data中没有传入列标签时,默认为range(n);当data中传入了列标签,此时的columns参数作用是筛选 |
| dtype | DataFrame中的数据类型 |

1.5 函数参数:copy
| 参数 | 含义 |
|---|---|
| data | 创建DataFrame的数据 |
| index | 产生的DataFrame的索引,当数据中不包含index且创建时没有输入Index参数内容,默认为range(n) |
| columns | 创建DataFrame的列标签,当data中没有传入列标签时,默认为range(n);当data中传入了列标签,此时的columns参数作用是筛选 |
| dtype | DataFrame中的数据类型 |
| copy | 产生的DataFrame是复制data中的数据,当data是列表或字典构成的数据时,默认copy=True;当data为Series,ndarray数组或者DataFrame时 ,默认copy=False |
2. DataFrame常用操作
DataFrame在选择、增加、删除列上的操作与字典类似。
2.1 索引与切片
2.1.1 选择列
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order)
### 2.1.1 选择某列
print(order['支付方式'])
print(type(order['支付方式']))
print(order['支付方式'].name)



2.1.1 行选择
行选择的方法较多,可以通过行标签选择,通过行索引选择,还可以通过切片和布尔型数据选择
2.1.1.1 通过行标签选择
df = pd.DataFrame({'a': np.arange(0, 10, 2),
'b': np.random.randint(90, 100, 5),
'c': np.random.rand(5)}, index=list('stpkg'))
print(df)
# 通过行标签选择
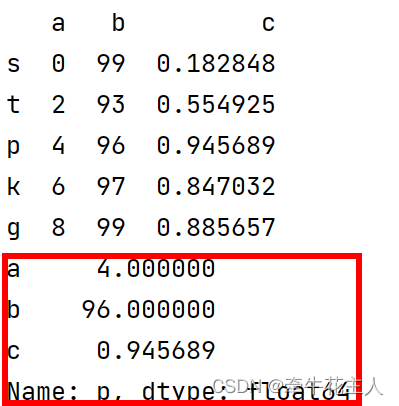
print(df.loc['p'])
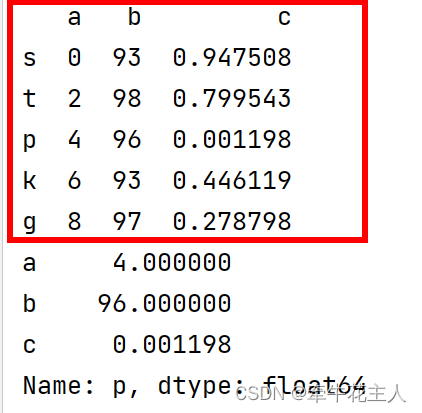
返回一个Series对象,对象index标签是DataFrame的列名
2.1.1.2 通过行索引号选择
# 通过行索引号选择
df = pd.DataFrame({'a': np.arange(0, 10, 2),
'b': np.random.randint(90, 100, 5),
'c': np.random.rand(5)}, index=list('stpkg'))
print(df)
print(df.iloc[2])
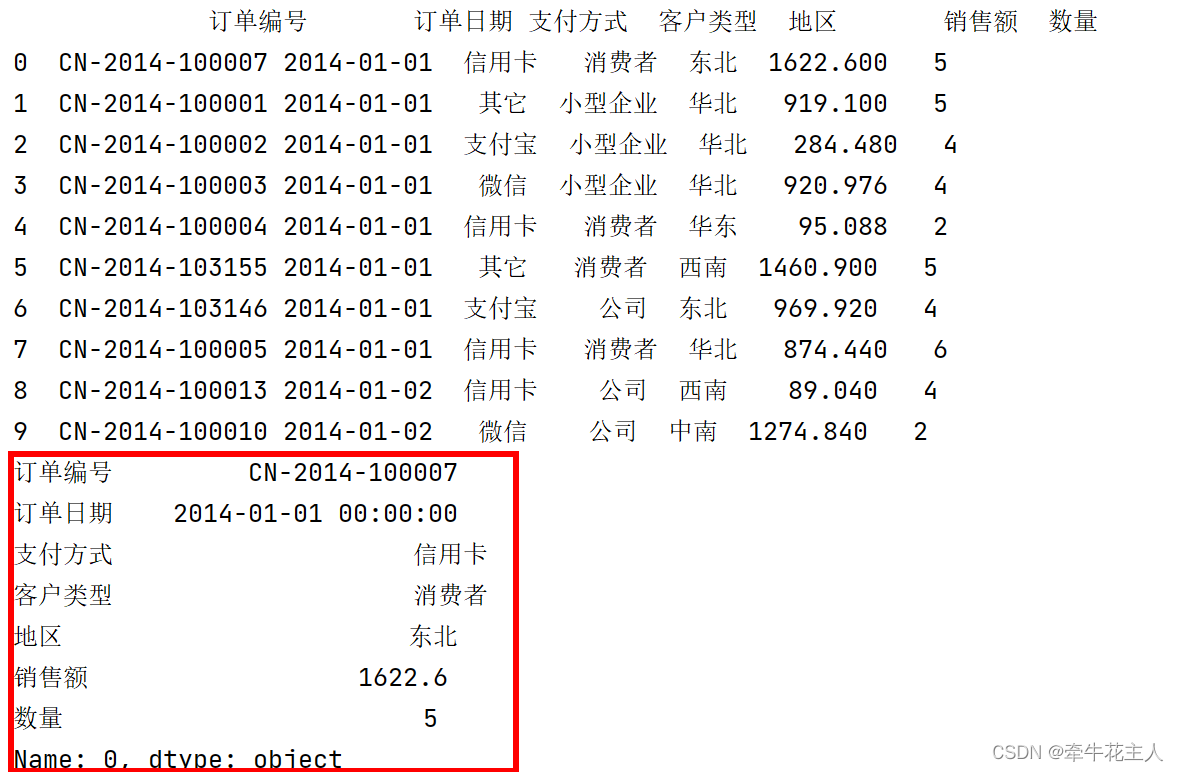
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order.head(10))
print(order.iloc[0])
2.1.13 通过行索引切片选择
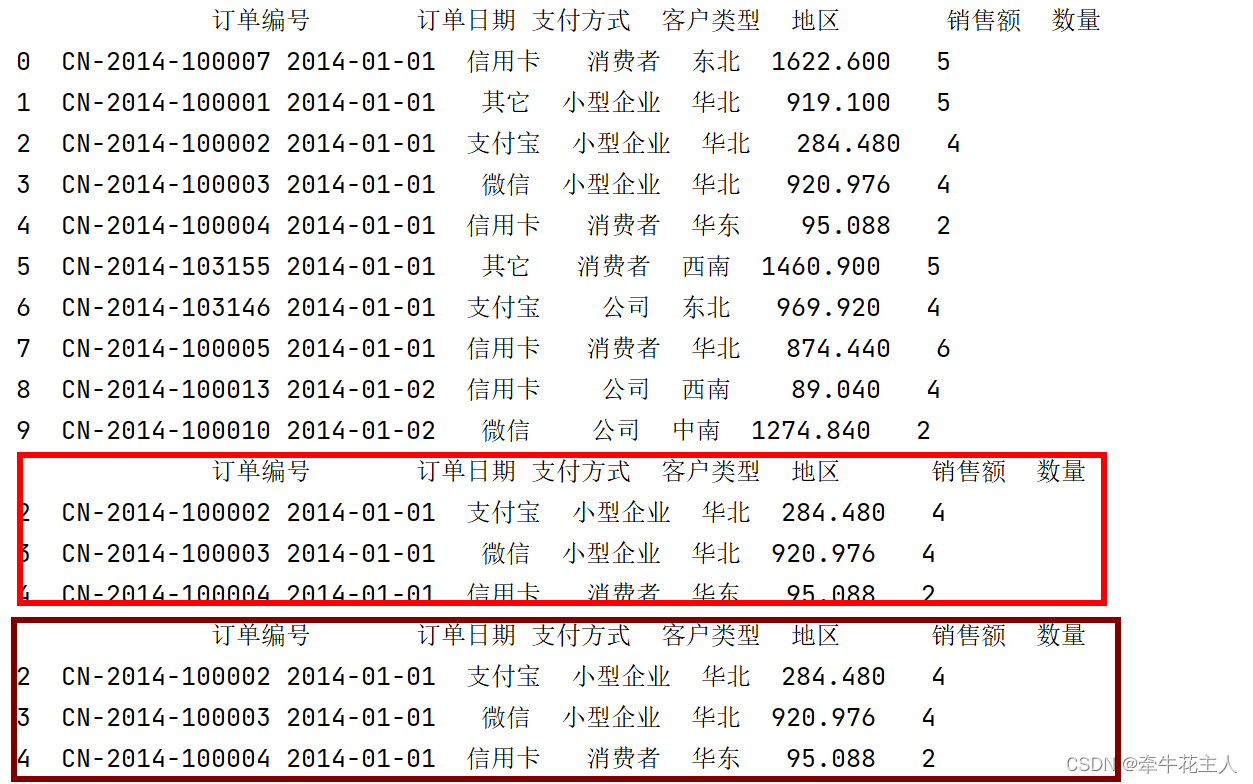
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order.head(10))
# 通过行索引号切片选择
print(order.iloc[2:5])
print(order[2:5])
2.1.1.4 通过布尔值选择
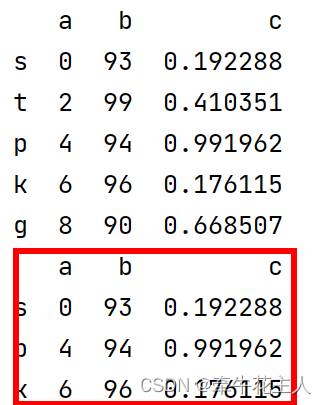
df = pd.DataFrame({'a': np.arange(0, 10, 2),
'b': np.random.randint(90, 100, 5),
'c': np.random.rand(5)}, index=list('stpkg'))
print(df)
# 通过布尔值向量选择行
print(df[[True, False, True, True, False]])
2.2 新增列
对DataFrame中不存在的列名进行操作为新增,对DataFrame存在的列名进行操作为替换
# 新增列
order['平均花费']=order['销售额']/order['数量']
print(order)

替换的情况: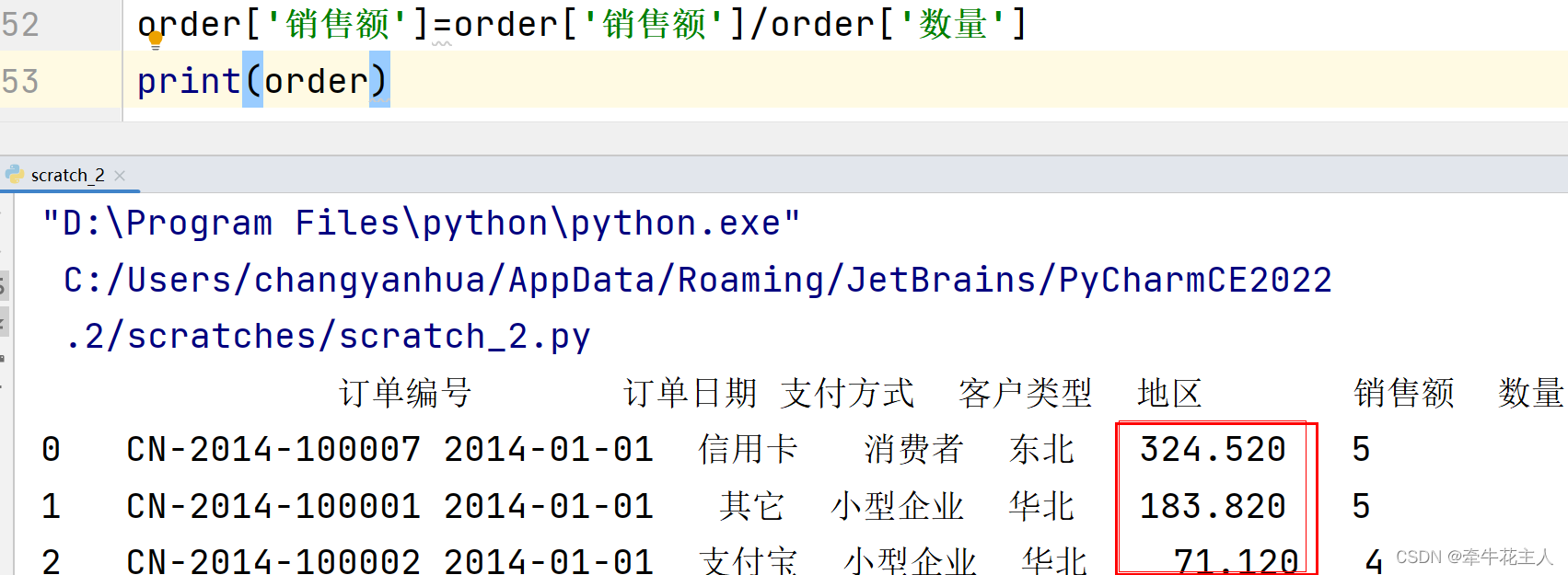
插入标量,会自动运用广播机制生成与DataFrame相同长度的数据
# 插入标量
order['记录标记'] = 1
print(order.head())
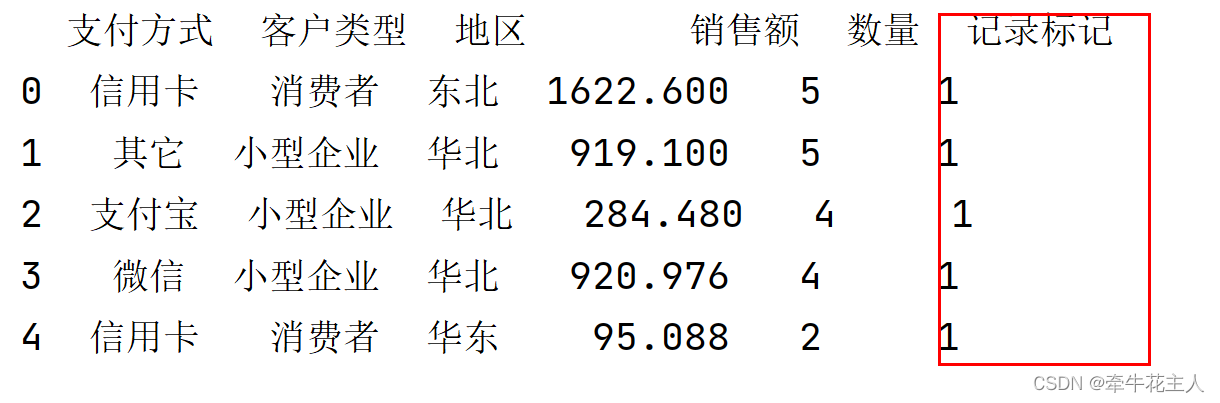
默认插入列在DataFrame的最后,可以通过DataFrame.insert()方法,指定插入位置
order.insert(3,'国家','中国')
print(order.head())
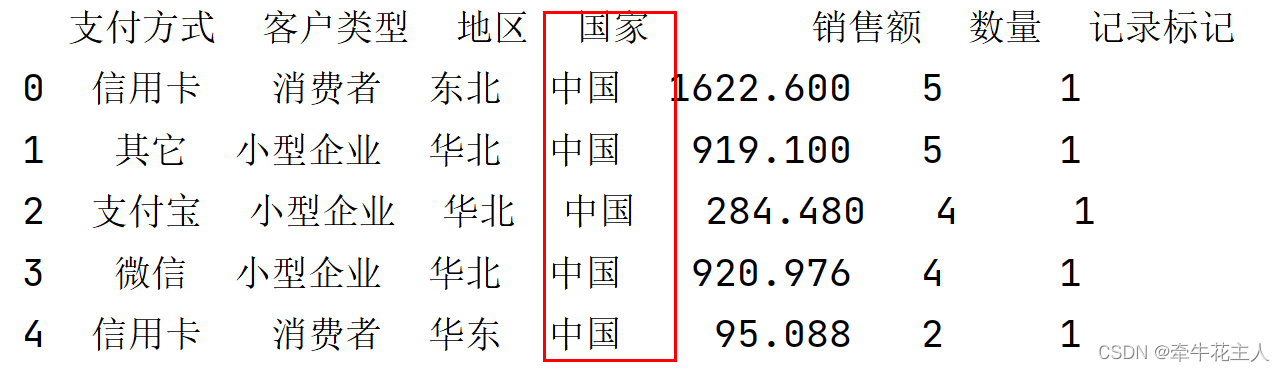
2.3 删除列
2.3.1 方法一:del()函数
# 删除列
del order['订单编号']
print(order.info())
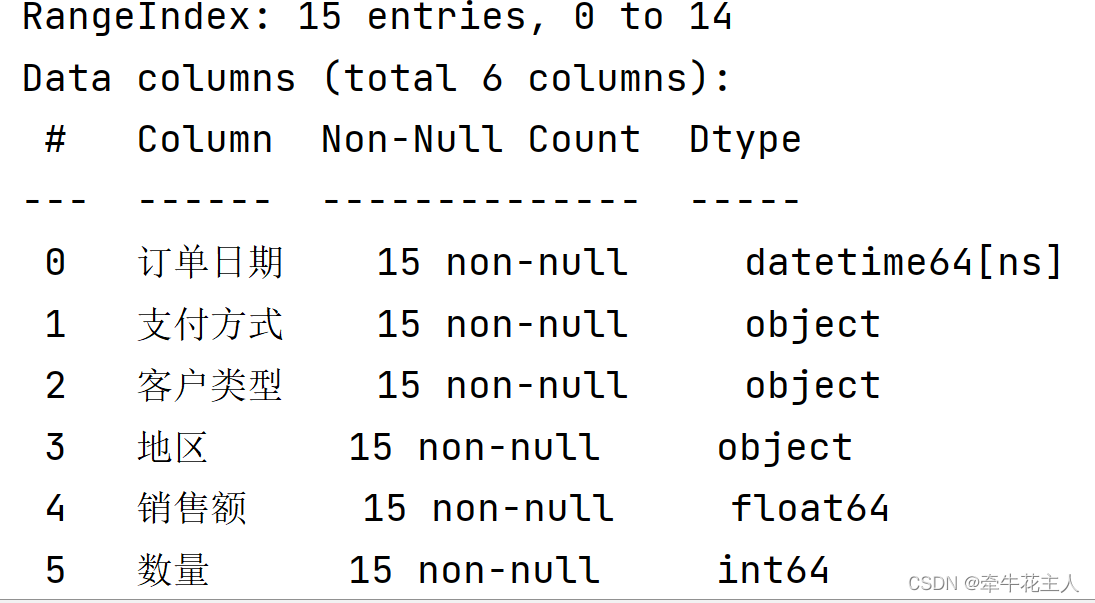
2.3.2 pop()函数
order.pop('订单日期')
print(order.info())

3.DataFrame的计算
DataFrame与Numpy的很多操作时互用的,大部分的Numpy函数可以直接被DataFrame和Series调用
参考文献:https://pandas.pydata.org/docs/user_guide/dsintro.html#from-dict-of-ndarrays-lists

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 3
3 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)