Python基础(5)-Pandas
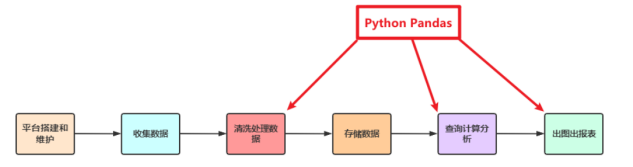
pandas是一个数据分析库,能快速分析结构化数据,并提供了高级数据结构和操作工具。1、Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据工具集,用于数据清洗、处理以及分析2、Pandas和Spark中很多功能都类似,甚至使用方法都是相同的;学会Pandas之后再学习Spark就更加简单快速3、Pandas在整个数据开发的流程中的应用场景:在大数据场景下,数据在流转的过
第十章 Pandas
1 pandas简介
pandas是一个数据分析库,能快速分析结构化数据,并提供了高级数据结构和操作工具。
1、Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据工具集,用于数据清洗、处理以及分析;
2、Pandas和Spark中很多功能都类似,甚至使用方法都是相同的;
3、Pandas在整个数据开发的流程中的应用场景:
在大数据场景下,数据在流转的过程中,Python Pandas丰富的API能够更加灵活、快速的对数据进行清洗和处理
4、Pandas在数据处理上具有独特的优势:
① 底层依赖Numpy进行高性能数值运算,运行速度特别的快Numpy定义了数据类型ndarray,效率高
② 有专门的处理缺失数据的API
③ 强大而灵活的分组、聚合、转换功能
1.安装pandas库
打开win键+r,输入cmd,打开终端
执行pip install pandas,为了提升安装效率,也可以加入镜像源安装:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ pandas
C:\Users\Admin>pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ pandas
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple/
Collecting pandas
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/f0/95/361d9726b57b44c1d8dce070930c2322a70157f697ecdcca13f4388247ab/pandas-2.0.2-cp38-cp38-win_amd64.whl (10.8MB)
|████████████████████████████████| 10.8MB 128kB/s
Collecting pytz>=2020.1 (from pandas)
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/7f/99/ad6bd37e748257dd70d6f85d916cafe79c0b0f5e2e95b11f7fbc82bf3110/pytz-2023.3-py2.py3-none-any.whl (502kB)
|████████████████████████████████| 512kB 284kB/s
Collecting python-dateutil>=2.8.2 (from pandas)
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/36/7a/87837f39d0296e723bb9b62bbb257d0355c7f6128853c78955f57342a56d/python_dateutil-2.8.2-py2.py3-none-any.whl (247kB)
|████████████████████████████████| 256kB 435kB/s
Collecting numpy>=1.20.3; python_version < "3.10" (from pandas)
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/1a/62/af7e78a12207608b23e3b2e248fc823fbef75f17d5defc8a127c5661daca/numpy-1.24.3-cp38-cp38-win_amd64.whl (14.9MB)
|████████████████████████████████| 14.9MB 218kB/s
Collecting tzdata>=2022.1 (from pandas)
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/d5/fb/a79efcab32b8a1f1ddca7f35109a50e4a80d42ac1c9187ab46522b2407d7/tzdata-2023.3-py2.py3-none-any.whl (341kB)
|████████████████████████████████| 348kB 345kB/s
Collecting six>=1.5 (from python-dateutil>=2.8.2->pandas)
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/d9/5a/e7c31adbe875f2abbb91bd84cf2dc52d792b5a01506781dbcf25c91daf11/six-1.16.0-py2.py3-none-any.whl
Installing collected packages: pytz, six, python-dateutil, numpy, tzdata, pandas
Successfully installed numpy-1.24.3 pandas-2.0.2 python-dateutil-2.8.2 pytz-2023.3 six-1.16.0 tzdata-2023.3
WARNING: You are using pip version 19.2.3, however version 23.1.2 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
安装成功界面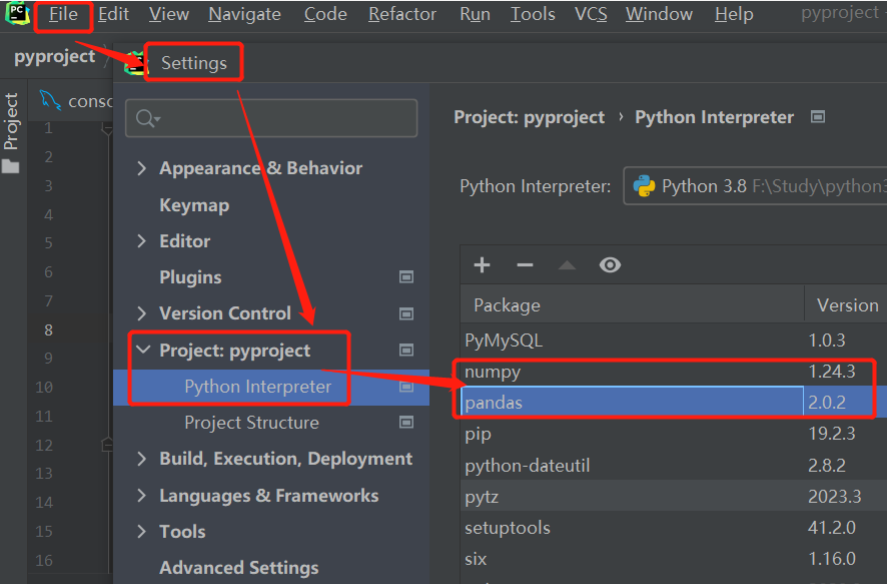
eg:pandas初体验
import pandas as pd
if __name__=='__main__':
# 处理乱码
df=pd.read_csv("./file/某公司运输订单数据表.csv",encoding="gbk")
print(df)
# 显示销售列
result=df["销售额"]
print(result)
# 切片,显示前10行
print(result[0:10])
结果如下:
订单号 订单日期 ... 产品包箱 运送日期
0 3 2014/10/13 ... 大型箱子 2014/10/20
1 6 2016/2/20 ... 小型包裹 2016/2/21
2 32 2015/7/15 ... 中型箱子 2015/7/17
3 32 2015/7/15 ... 巨型纸箱 2015/7/16
4 32 2015/7/15 ... 中型箱子 2015/7/17
... ... ... ... ... ...
8563 59986 2016/11/15 ... 小型箱子 2016/11/16
8564 59986 2016/11/15 ... 大型箱子 2016/11/16
8565 59986 2016/11/15 ... 小型箱子 2016/11/16
8566 59986 2013/1/23 ... 小型箱子 2013/1/25
8567 59986 2015/5/27 ... 小型箱子 2015/5/29
[8568 rows x 19 columns]
0 261.5400
1 6.0000
2 2808.0800
3 1761.4000
4 160.2335
...
8563 18.9100
8564 685.7000
8565 1024.1650
8566 1383.2000
8567 211.4200
Name: 销售额, Length: 8568, dtype: float64
0 261.5400
1 6.0000
2 2808.0800
3 1761.4000
4 160.2335
5 140.5600
6 288.5600
7 1892.8480
8 2484.7455
9 3812.7300
Name: 销售额, dtype: float64
2 pandas数据结构和类型
pandas库中两个核心数据结构:DataFrame数据帧、Series系列。
(1)DataFrame数据帧,指的是二维数组,即行列;
(2)Series系列,指的是一维数组,即列;
(3)对于列,通常分为索引列、数据列。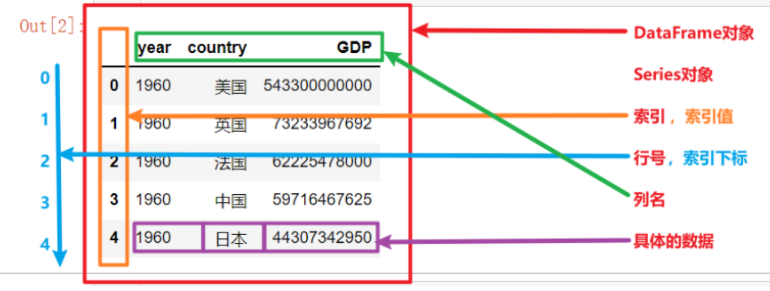
| pandas数据类型 | 说明 | 对应的Python类型 |
|---|---|---|
| Object | 字符串类型 | str |
| int | 整数类型 | int |
| float | 浮点数类型 | float |
| datetime | 日期时间类型 | datetime包中的datetime类型 |
| timedelta | 时间差类型 | datetime包中的timedelta类型 |
| category | 分类类型 | 无原生类型,可以自定义 |
| bool | 布尔类型 | bool,取值True、False |
| nan | 空值类型 | None |
DataFrame和Series对象中数值的类型可以通过dtypes属性查看。
2.1 series对象
Series(系列)是能够保存任何类型数据的一维数组,例如能保存整数、字符串、浮点数、Python对象等。
Series可通过索引获取数据元素值,此外,还具有索引的自动对齐功能。Series(values, index [, dtype]):用于创建pandas.Series对象。参数如下:
①参数data表示数据形式,如:数组、list等;
②参数index表示唯一的索引值,整数型索引为0到N-1(N为数据的长度);
③参数dtype用于数据类型,若没有设置,则pandas会自动推断并提供默认数据类型。
eg:使用常量值、列表、字典等数据来直接创建Series对象:
# 1.常量
s1=pandas.Series(8,index=[0,1,2,3,4])
print(s1)
# 2.列表
s2=pandas.Series([10,20,30,40])
s2=pandas.Series([10,20,30,40],index=["A","B","C","D"])
print(s2)
# 3.字典
dict_data={"name":"Amy","age":18}
s3=pandas.Series(dict_data)
print(s3)
import numpy as np
# 4.一维数组
array=np.array([1,2,22,333,444])
# print(array)
# Series可以理解为一维数组
s4=pandas.Series(array)
print(s4)
常用方法
Series有一些常用属性:
| 属性名 | 含义 |
|---|---|
| size | 表示值的个数。 |
| index | 表示列索引数。 |
| dtype | 表示列的数据类型。 |
| shape | 表示有多少列。 |
| values | 表示对象值,即一维数组。 |
Series对象值也可以直接使用for进行遍历处理。
Series有一些常用方法:
| 函数名 | 含义 |
|---|---|
| to_list() | 将对象值转换为list列表。 |
| to_dict() | 将对象值转换为dict字典。 |
| to_json() | 将对象值转换为json字符串。 |
| to_frame() | 将对象值转换为DataFrame数据帧。 |
| head(num) | 从头部开始显示几行,参数num表示显示的行数,默认为5行。 |
| tail(num) | 从末尾开始显示几行,参数num表示显示的行数,默认为5行。 |
| describe() | 显示综合统计结果,比如计数count、均值mean、标准差std、最大值max、最小值min等。 |
转换类型的操作使用较多;head(num)仅需要获取前几行数据使用也较多。
import pandas
# 1.定义一个数据为[10,20,30,40],且索引为[0,1,2,3]的Series
series=pandas.Series([10,20,30,40],index=[0,1,2,3])
# 2.使用size、index、dtype、shape、values等属性查看,后面为结果
print(series.size) # 4
print(series.index) # Index([0, 1, 2, 3], dtype='int64')
print(type(series)) # <class 'pandas.core.series.Series'>
print(series.dtypes) # int64
print(series.shape) # (4,)
print(series.values) # [10 20 30 40] 一维数组
# 3.将对象值转换为list列表、dict字典、frame数据帧
print(series.to_list()) # [10, 20, 30, 40]
print(series.to_dict()) # {0: 10, 1: 20, 2: 30, 3: 40}
print(series.to_frame())
# 0
# 0 10
# 1 20
# 2 30
# 3 40
# 4.取前3行数据,查看综合统计结果
print(series[:3]) # 查看前三行
print(series.head())
print(series.describe())
Series运算处理!
当要获取Series的单个数据元素时,可通过索引值来访问:变量名[索引值]
(1)当不同索引的Series对象进行运算时,结果中出现的缺失值会使用NaN填充;
(2)要对Series对象执行元素访问、切片,这些操作与列表操作类似。
import pandas
# s=pandas.Series(["A","B","C","D"])
# # 1.范围元素
# print(s[0])
# print(s[2])
# # 2.切片处理
# print(s[0:2])
# print(s[:2])
# print(s[1:2])
# 3.运算处理
s1=pandas.Series([1,2,3,4])
# 每个数字都加上1
print(s1+1)
# 报错:numpy.core._exceptions.UFuncTypeError: ufunc 'add' did not contain a loop with signature matching types (dtype('int64'), dtype('<U1')) -> None
# print(s1+"h")
s2=pandas.Series([10,20,30,40])
# 个数相同自动匹配相加
print(s1+s2)
s3=pandas.Series([10,20,30,40,100,200,300])
# 个数不同,缺失值会自动填充NaN
print(s1+s3)
2.2 DataFrame数据帧
DataFrame(数据帧)是一个具有行列的二维数组,类似于表格数据。是一个表格型的数据结构,既有行索引也有列索引,数据元素则是以二维结构存放的。DataFrame(data,index,columns [,dtype]):用于创建pandas.DataFrame对象。参数如下:
①参数data表示数据形式,如:数组、list、series、dict或DataFrame等;
②参数index表示唯一的行索引值,整数型索引为0到N-1(N为数据的长度);
③参数columns表示列索引值,取值与参数index类似;
④参数dtype用于数据类型,若没有设置,则pandas会自动推断并提供默认数据类型。
DataFrame的创建有很多种方式:
Serires对象转换为df:上一小节中学习了s.to_frame() 以及.reset_index()
读取文件数据返回df:在之前的学习中我们使用了 pd.read_csv(‘csv格式数据文件路径’) 的方式获取了df对象
使用字典、列表、元组创建df:接下来就展示如何使用字段、列表、元组创建df
# 1.dict字典
dict_data={
'日期': ['2021-08-21', '2021-08-22', '2021-08-23'],
'温度': [25, 26, 50],
'湿度': [81, 50, 56]
}
df1 = pandas.DataFrame(dict_data)
df2 = pandas.DataFrame(dict_data,index=["i","ii","iii"])
print(df1)
print(df2)
# 2.列表
list_data=[
('2021-08-21', 25, 81),
('2021-08-22', 26, 50),
('2021-08-23', 27, 56)
]
df3 = pandas.DataFrame(list_data,columns=["日期","温度","湿度"])
print(df3)
df4 = pandas.DataFrame(list_data,columns=["日期","温度","湿度"],index=["A","B","C"])
print(df4)
常用方法
DataFrame有一些常用属性:
| 属性名 | 含义 |
|---|---|
| len(x) | 表示对象值的长度。 |
| size | 表示对象值的长度。 |
| index | 表示列索引数。 |
| columns | 表示行索引数。 |
| dtypes | 表示列的数据类型。 |
| shape | 表示有多少行列。 |
| values | 表示对象值,即二维数组。 |
| info | 表示对象的基本信息:索引情况、各列的名称、数据数量、数据类型等。 |
DataFrame有一些常用方法:
| 函数名 | 含义 |
|---|---|
| head(num) | 从头部开始显示几行,参数num表示显示的行数,默认为5行。 |
| tail(num) | 从末尾开始显示几行,参数num表示显示的行数,默认为5行。 |
| describe([include=‘all’]) | 显示综合统计结果,比如计数count、均值mean、标准差std、最大值max、最小值min等,当数据缺失时使用NaN表示。 |
import pandas
# 1.定义一个数据具有日期、温度、湿度的DataFrame对象
dict_data={
'日期': ['2021-08-21', '2021-08-22', '2021-08-23'],
'温度': [25, 26, 50],
'湿度': [81, 50, 56]
}
df=pandas.DataFrame(dict_data)
# print(df)
# 2.使用len()、size、shape、dtypes、values、columns、index、info等属性查看结果
print(len(df)) # 行列3
print(df.size) # 个数9 三行三列
print(df.shape) # (3, 3)
print(df.dtypes)
# 日期 object
# 温度 int64
# 湿度 int64
# dtype: object
print(df.index) # RangeIndex(start=0, stop=3, step=1)
print(df.info)
# 3.获取前2行
print(df[:2])
print(df.head(2))
# 后2行数据
print(df.tail(2))
print(df.describe())
print(df.describe(include="all"))
运算处理
当要访问DataFrame对象的具体元素值时,需要分别获取到列索引、行索引,语法:变量名[列索引][行索引]
当DataFrame和数值进行运算,每一个元素会和数值分别运算,但是DataFrame中的数据有非数值类型时,则不能做加减运算。
与两个个Series计算类似,当两个DataFrame对象的索引值不能对应时,不匹配的数据则会返回NaN。
import pandas
list_data=[
{"brand": "Lenove", "memorysize": 4, "price": 4289},
{"brand": "HuaWei", "memorysize": 6, "price": 4699},
{"brand": "God Of War", "memorysize": 8, "price": 3999}
]
df=pandas.DataFrame(list_data)
# # print(df)
# print(df["price"][0])
# print(df["brand"][1])
# 2.乘法加法运算
# print(df*2)
# print(df+1) #报错,只有数值类才可以相加
# 3.加运算
temp=[
{"brand": "Mi", "memorysize": 16},
{"brand": "Dell", "memorysize": 8}
]
df1=pandas.DataFrame(temp)
print(df+df1)
3 pandas进行数据读写
常用读写文件数据的函数有:
| 文件格式 | 读取函数 | 写入函数 |
|---|---|---|
| xlsx | read_excel() | to_excel() |
| xls | read_excel() | to_excel() |
| csv | read_csv() | to_csv() |
| tsv | read_csv() | to_csv() |
| json | read_json() | to_json() |
| html | read_html() | to_html() |
| sql | read_sql() | to_sql() |
| 剪贴板 | read_clipboard() | to_clipboard() |
读数据时,一般直接使用pandas库调用;
import pandas as pd
# 读取数据,使用pandas库调用
df = pandas.read_csv("file/王者荣耀英雄数据表.csv")
# 操作
result = df["name"]
print(result[:10])
print(result.head(10))
写入数据时,一般要用DataFrame对象名调用。
import pandas as pd
# 写数据
list_data=[
['1960-5-7', '刘海柱', '职业法师'],
['1978-9-1', '赵金龙', '大力哥'],
['1984-12-27', '周立齐', '窃格瓦拉'],
['1969-1-24', '于谦', '相声皇后']
]
df=pd.DataFrame(list_data,columns=["date","name","prof"])
print(df)
# 2.写入数据,用对象名调用
df.to_csv("./file/demo.csv")
print("写入成功")
4 三目运算
语法:变量名 = 临时变量 if 条件 else 不满足条件结果
number=int(input("请输入一个数据:"))
result="偶数" if number%2==0 else "奇数"
print(f"{number}是{result}")

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)