【函数】 collections.Counter()
Python标准库 collections 里的 counter() 函数是一个计数器工具,用于统计可迭代对象中元素出现的次数,并返回一个字典(key-value)key 表示元素,value 表示各元素 key 出现的次数,可为任意整数 (即包括0与负数)。任何可迭代对象,如列表、元组、字符串、字典等。Ais a。
Python标准库 collections 里的 counter() 函数是一个计数器工具,用于统计可迭代对象中元素出现的次数,并返回一个字典(key-value)key 表示元素,value 表示各元素 key 出现的次数,可为任意整数 (即包括0与负数)。
可接受参数:任何可迭代对象,如列表、元组、字符串、字典等。
A Counter is a dict subclass for counting hashable objects. It is an unordered collection where elements are stored as dictionary keys and their counts are stored as dictionary values. Counts are allowed to be any integer value including zero or negative counts.
一、创建 Counter()
# 创建一个新的空Counter
c = collections.Counter()
# 或者
from collections import Counter
c = Counter()当参数是列表,字符串,映射关系,关键字参数时:
# 参数是字符串
c = collections.Counter("abracadabra")
print(c) # Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
# 参数是映射
d = collections.Counter({"red":4,"yellow":2,"blue":5})
print(d) # Counter({'blue': 5, 'red': 4, 'yellow': 2})
# 参数是关键字参数
e = collections.Counter(cats=2,dogs=5)
print(e) # Counter({'dogs': 5, 'cats': 2})
# 参数是列表,并访问 key
c = collections.Counter(["apple","pear","apple"])
print(c) # Counter({'apple': 2, 'pear': 1})
print(c["orange"]) # 0 当访问不存在的 key 时,返回值为0。
当参数是字典时,Counter()还可以根据第一个值做排序。
import pandas as pd
myDict = dict(zip(("a","b","c"),([1,2,5],[9,6,9],[3,4,10])))
print(pd.DataFrame(myDict))
# 根据第一个值做排序
f = collections.Counter(myDict)
print(f)
# 输出:Counter({'b': [9, 6, 9], 'c': [3, 4, 10], 'a': [1, 2, 5]})访问元素
计数器是dict的子类,因此可以像使用 dict 那样访问计数器元素(值): Counter["键名"] / get()
print(c['a'])二、其他用法
2.1 按照计数降序,返回前 n 项组成的 list Counter.most_common(n)
n 忽略时返回全部。
按照计数排序,返回最小 n 个计数的计数值组成的列表:
# 返回最小2位
f = collections.Counter(myDict).most_common()[:-2-1:-1] # 左闭右开
print(f) 2.2 计数相减 collections.Counter.subtract([iterable-or-mapping])
c = collections.Counter(a=4, b=2, c=0, d=-2)
d = collections.Counter(a=1, b=2, c=3, d=4)
c.subtract(d) # c 中减掉 d
print(c)
返回:Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6})2.3 更新Counter(),相同 key 的 value 相加 collections.Counter.update([iterable-or-mapping])
与字典的 update() 方法不同,字典是相同 key 的 value值覆盖。 注意实例化。
c = collections.Counter(a=4, b=2, c=0, d=-2)
d = collections.Counter(a=1, b=2, c=3, d=4)
c.update(d)
print(c)
返回:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2})2.4 Counter 间的数学集合操作
c = collections.Counter(a=3, b=1, c=5)
d = collections.Counter(a=1, b=2, d=4)
print(c + d) # counter相加, 汇聚所有的key,相同的key的value相加
print(c | d) # 并集: 汇聚所有的key, key相同的情况下,取大的value
print(c - d) # counter相减, 取c里的key,相同的key的value相减,只保留正值的value
print(c & d) # 交集: 取c和d里都有的key,value取小的那一个结果如下:
Counter({'c': 5, 'a': 4, 'd': 4, 'b': 3})
Counter({'c': 5, 'd': 4, 'a': 3, 'b': 2})
Counter({'c': 5, 'a': 2})
Counter({'a': 1, 'b': 1})2.5 其他常见做法
| 用法 | 语法 |
|---|---|
| 清空 Counter | c.clear() |
| 返回 values 的列表,再求和 | sum(c.values()) |
| 返回 key 组成的 list | list(c) |
| 返回 key 组成的 set | set(c) |
| 转化为(元素,计数值)组成的列表 | c.items |
| 从(元素,计数值)组成的列表转化成Counter | Counter(dict(list_of_pairs)) |
| 利用 counter 相加来去除负值和0的值 | c += Counter() |
三、使用实例
# 普通青年
d = {}
with open('/etc/passwd') as f:
for line in f:
for word in line.strip().split(':'):
if word not in d:
d[word] = 1
else:
d[word] += 1
# 文艺青年
d = {}
with open('/etc/passwd') as f:
for line in f:
for word in line.strip().split(':'):
d[word] =d.get[word,0]+1
# 棒棒的青年
word_counts = Counter()
with open('/etc/passwd') as f:
for line in f:
word_counts.update(line.strip().split(':')四、most_common 源码
def most_common(self, n=None):
'''List the n most common elements and their counts from the most
common to the least. If n is None, then list all element counts.
>>> Counter('abcdeabcdabcaba').most_common(3)
[('a', 5), ('b', 4), ('c', 3)]
'''
# Emulate Bag.sortedByCount from Smalltalk
if n is None:
return sorted(self.iteritems(), key=_itemgetter(1), reverse=True)
return _heapq.nlargest(n, self.iteritems(), key=_itemgetter(1))如果调用most_common不指定参数n则默认返回全部(key, value)组成的列表,按照value降序排列。
itemgetteroperator 模块中的方法
# 实现:
def itemgetter(*items):
if len(items) == 1:
item = items[0]
def g(obj):
return obj[item]
else:
def g(obj):
return tuple(obj[item] for item in items)
return g五、应用案例
在电商数据分析里构建“用户-行为-购买转化率“视图
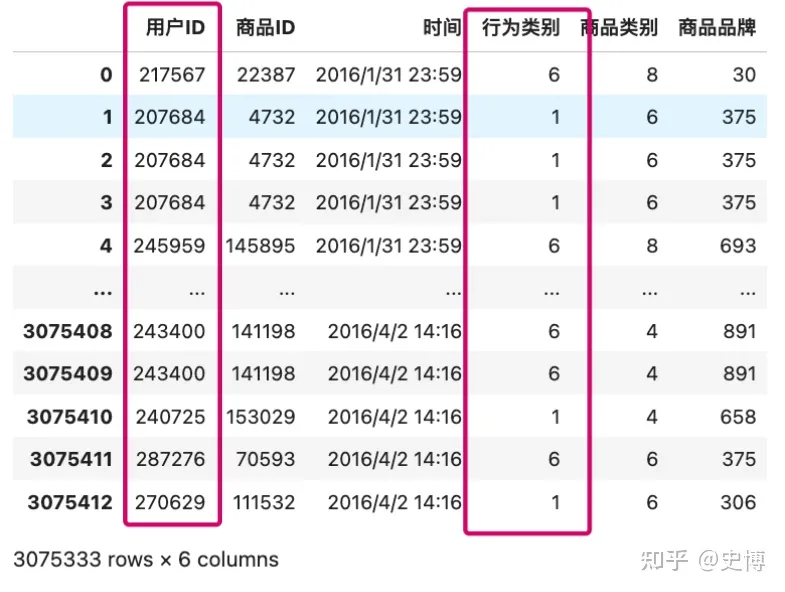
源数据
1 浏览 2 加购 3 删除 4 购买 5 收藏 6 点击,目标视图如下:
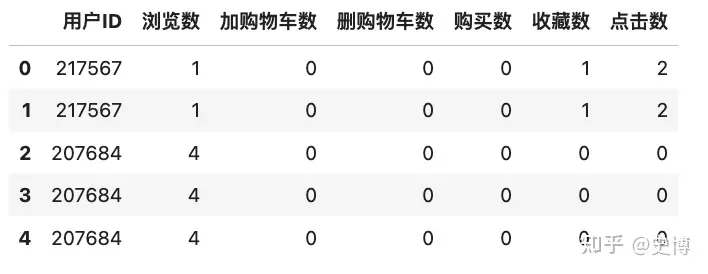
注意两点:
1. 首先是分用户进行转化率统计,不是平时的加总用户算转化率;
2. 这种方法和一般的 groupby(["用户ID","行为类别"]) 后的展示效果不太一样(count后的数都是横向的);
编写add_user_type_count()方法
def add_user_type_count(group):
behavior_type = group.行为类别.astype(int)
type_cnt = Counter(behavior_type) # 创建一个Counter
group['浏览数'] = type_cnt[1]
group['加购物车数'] = type_cnt[2]
group['删购物车数'] = type_cnt[3]
group['购买数'] = type_cnt[4]
group['收藏数'] = type_cnt[5]
group['点击数'] = type_cnt[6]
return group[['用户ID','浏览数','加购物车数','删购物车数','购买数','收藏数','点击数']]1. 将 groupby 分组后的 group 作为参数,把分组中后用户ID的数据传入 add_user_type_count()。下面的代码中groupby().apply() 函数将 DataFrame 按照“行为类别”列进行分组,并对每个分组应用 user_type 函数,得到了一个新的 DataFrame,就是这里的 group。
2. df.列名或者df[列名]是pandas中基本操作,用于获取df中某列的值及其索引, 是一个pandas的series对象。便于对其进行后续操作,比如可使用mean(),std(),apply(),agg()等函数应用操作。如果要将其转换为列表,也需要用df[列名]获取一维数组后用函数tolist()进行转换。
import pandas as pd
df=pd.DataFrame({'a':[12,21,33,46,68]})
print(df.a.agg(['mean','std','max','median']))
print(df.a.tolist())group.行为类别.astype()将这一列数据变成 int 类型(不明白为什么不用series的 convert_dtypes,而是直接用了df的 astype()。
behavior_type = group.行为类别.astype(int)
type_cnt = Counter(behavior_type)
或者直接不变换:type_cnt = Counter(group["行为类别"]) 其实代码也可以走了3. Counter() 传入后,group['浏览数']= type_cnt[1] 在原来 DataFrame 的基础上,创建一个新列,列名“浏览数”。将 Counter 后的键为 1 的值送进去,同理1-6。
4. 最后返回 group[[, , , ,]]那些列及数值。
month2_groupbyUserId=month2.loc[:1000, ['用户ID', '行为类别']].groupby(['用户ID'], group_keys=False).apply(add_user_type_count)
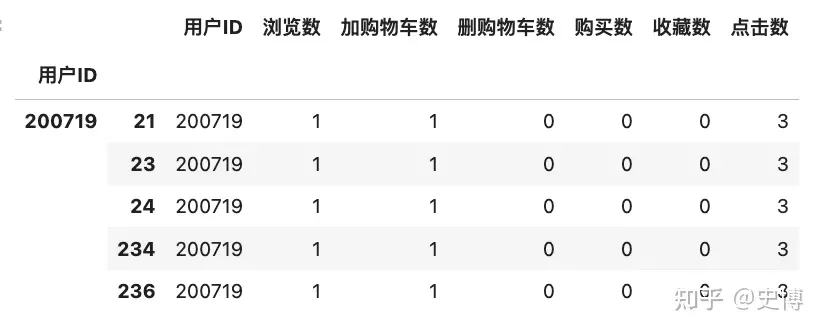
print(month2_groupbyUserId.head()) # 不显示分组的key, 为什么会出现重复多条?1. 选取DataFrame类型 month2 里面的一块数据用loc[行切片, [列索引1,列索引2]],对“用户ID”进行分组,分组的键不显示 group_keys = False。如果写True,出来的结果是下面这样的。
2. 这里提到分组用apply方法进行单分区|多键分组计算操作, .apply()方法是通过传入一个函数或者lambda表达式对数据进行批量处理。这里 add_user_type_count 就是我们定义的函数,返回值是 add_user_type_count分组后的列名 group[['用户ID','浏览数','加购物车数','删购物车数','购买数','收藏数','点击数']]。
还有很多源码可以参考下面的原文讲解
原文参考:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)