《操作系统》 实验1_unix——io参考
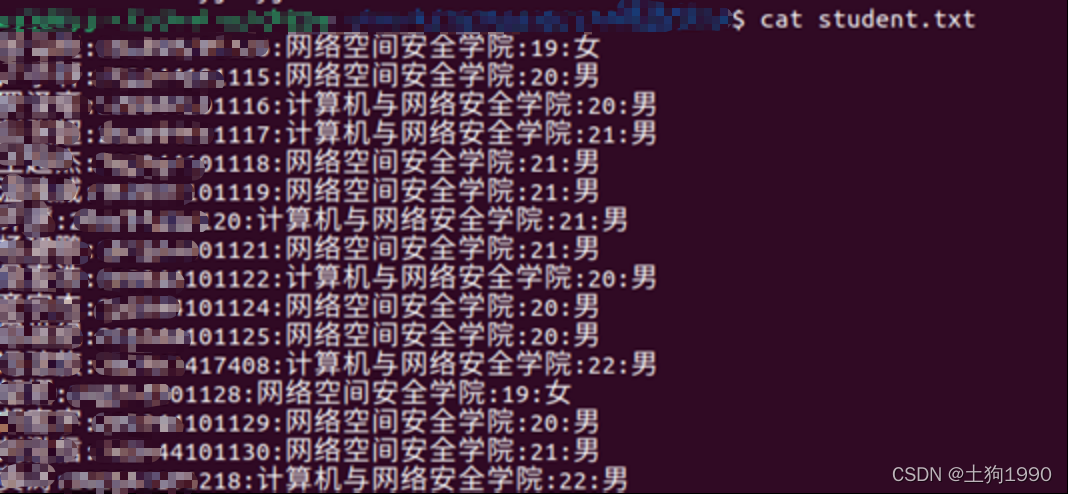
任务1在当前用户目录下创建数据文件student.txt,文件的内部信息存储格式为Sname:S#:Sdept:Sage:Ssex,即“姓名:学号:学院:年龄:性别”,每行一条记录,输入不少于10条学生记录,其中包括学生本人记录。编写程序task41.c,从文件中查找Sdept字段值为“计算机与网络安全学院”的文本行,输出到文件csStudent.txt中,保存时各字段顺序调整为S#:Sname:
任务1
在当前用户目录下创建数据文件student.txt,文件的内部信息存储格式为Sname:S#:Sdept:Sage:Ssex,即“姓名:学号:学院:年龄:性别”,每行一条记录,输入不少于10条学生记录,其中包括学生本人记录。编写程序task41.c,从文件中查找Sdept字段值为“计算机与网络安全学院”的文本行,输出到文件csStudent.txt中,保存时各字段顺序调整为S#:Sname:Sage: Ssex:Sdept。
提示:从终端读入一个文本行到字符串 char buf[MAXSIZE]可调用函数可调用函数:
“fgets(buf, MAXSIZE, stdin);”,其中stdin是表示键盘输入设备的文件指针。
源代码
#include<stdio.h>
#include<string.h>
#define SEARCH_EDU "" //待查学院
#define FILE_NAME "./student.txt" //打开文件名
#define FILE_OUT "./csStudent.txt" //输出文件名
#define MAXSIZE 1024
typedef struct STUDENT
{
char name[20];//姓名
char sno[20];//学号
char edu[50];//学院
char age[4];//年龄
char sex[4];//性别
}Student;
int main()
{
Student students;
FILE* stuFile = fopen(FILE_NAME,"r");
FILE* outFILE = fopen(FILE_OUT,"w");
int i,j;
char buf[MAXSIZE];
//读取文件学生信息到内存
while(!feof(stuFile))
{
fgets(buf,MAXSIZE,stuFile);
sscanf(buf, "%[^:]:%[^:]:%[^:]:%[^:]:%[^\n]\n", students.name,
students.sno,students.edu,students.age,students.sex);
//输出指定学院的学生到文件
if(strcmp(students.edu,SEARCH_EDU) == 0)
{
fprintf(outFILE,"%s:%s:%s:%s:%s\n", students.sno,
students.name,students.age,students.sex,students.edu);
}
}
fclose(stuFile);
fclose(outFILE);
return 0;
}
编译过程

测试数据
运行结果

解决问题
feof() 函数
发现运行最后多出了一行
查找了feof函数:
注意:feof判断文件结束是通过读取函数fread/fscanf等返回错误来识别的,故而判断文件是否结束应该是在读取函数之后进行判断。比如,在while循环读取一个文件时,如果是在读取函数之前进行判断,则如果文件最后一行是空白行,可能会造成内存错误。
feof(fp)有两个返回值:如果遇到文件结束,函数feof(fp)的值为非零值,否则为0。
ASCI C提供一个feof函数,用来判断文件是否结束。
“C”语言的“feof()”函数和数据库中“eof()”函数的运作是完全不同的。数据库中“eof()”函数读取当前指针的位置,“C”语言的“feof()”函数返回的是最后一次“读操作的内容”。 多年来把“位置和内容”相混,从而造成了对这一概念的似是而非。
那么,位置和内容到底有何不同呢?举个简单的例子,比如有人说“你走到火车的最后一节车箱”这就是位置。而如果说“请你一直向后走,摸到铁轨结束”这就是内容。也就是说用内容来判断会“多走一节”。这就是完全依赖于“while(!feof(FP)){…}”进行文件复制时,目标文档总会比源文档“多出一些”的原因。
在“C”文件读取操作时不能完全依赖于“while(!feof(FP)){…}”的判断。下面代码是改进后的代码,该代码执行后output文件内容和input文件内容一致,与使用“while(!feof(FP)){…}”相比,output文件的结尾符号(EOF)没有被读入到input文件中。
feof()可以用EOF代替吗?不可以。fgetc返回-1时,有两种情况:读到文件结尾或是读取错误。因此我们无法确信文件已经结束, 因为可能是读取错误! 这时我们需要feof()。
#include<stdio.h>
#include<string.h>
#define SEARCH_EDU "计算机与网络安全学院" //待查学院
#define FILE_NAME "./student.txt" //打开文件名
#define FILE_OUT "./csStudent.txt" //输出文件名
#define MAXSIZE 1024
typedef struct STUDENT
{
char name[20];//姓名
char sno[20];//学号
char edu[50];//学院
char age[4];//年龄
char sex[4];//性别
}Student;
int main()
{
Student students;
FILE* stuFile = fopen(FILE_NAME,"r");
FILE* outFILE = fopen(FILE_OUT,"w");
int i,j;
char buf[MAXSIZE];
//读取文件学生信息到内存
//更改函数
fgets(buf,MAXSIZE,stuFile);
while(!feof(stuFile))
{
sscanf(buf, "%[^:]:%[^:]:%[^:]:%[^:]:%[^\n]\n", students.name,
students.sno,students.edu,students.age,students.sex);
//输出指定学院的学生到文件
if(strcmp(students.edu,SEARCH_EDU) == 0)
{
fprintf(outFILE,"%s:%s:%s:%s:%s\n", students.sno,
students.name,students.age,students.sex,students.edu);
}
fgets(buf,MAXSIZE,stuFile);
}
fclose(stuFile);
fclose(outFILE);
return 0;
}
结果:
fputs() 、fgets()函数
fputs() 函数也是用来显示字符串的,它的原型是:
1 #include <stdio.h>
2 int fputs(const char*s,FILE *stream);c
s代表要输出的字符串的首地址,可以是字符数组名或字符指针变量名。
stream 表示向何种流中输出,可以是标准输出流 stdout,也可以是文件流。标准输出流即屏幕输出,printf 其实也是向标准输出流中输出的。
fputs() 和 puts() 有两个小区别:
- puts() 只能向标准输出流输出,而 fputs() 可以向任何流输出。
- 使用 puts() 时,系统会在自动在其后添加换行符;而使用 fputs() 时,系统不会自动添加换行符。
那么这是不是意味着使用 fputs() 时就要在后面添加一句“printf("\n");”换行呢?看情况!如果输入时使用的是 gets(),那么就要添加 printf 换行;但如果输入时用的是 fgets(),则不需要。
使用 fgets() 时,换行符会被 fgets() 读出来并存储在字符数组的最后,这样当这个字符数组被输出时换行符就会被输出并自动换行。
但是也有例外,比如使用fgets()时指定了读取的长度,如只读取 5 个字符,事实上它只能存储 4 个字符,因为最后还要留一个空间给 ‘\0’,而你却从键盘输入了多于 4 个字符,那么此时“敲”回车后换行符就不会被 fgets() 存储。数据都没有地方存放,哪有地方存放换行符呢!此时因为 fgets() 没有存储换行符,所以就不会换行了。
任务2
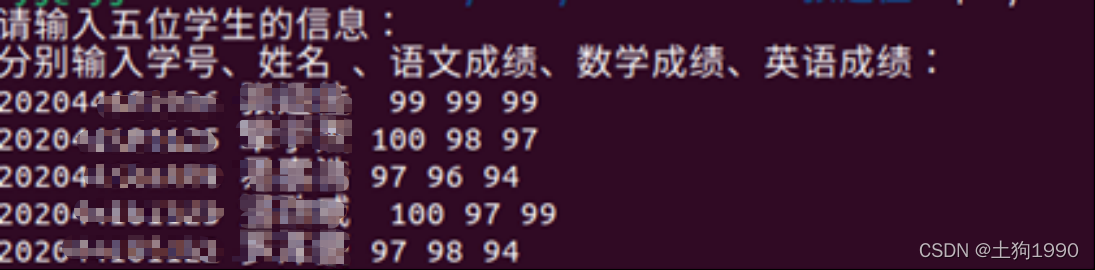
调用Unix I/O库函数,编写程序task42.c,从键盘读入5个学生的成绩信息,包括学号、姓名、语文、数学、英语,成绩允许有一位小数,存入一个结构体数组,结构体定义为:
typedef struct _subject { char sno[20]; //学号 char name[20]; //姓名 float chinese; //语文成绩 float math; //数学成绩 float english; //英语成绩 } subject;将学生信息,逐条记录写入数据文件data,最后读回第1、3、5条学生成绩记录,显示出来,检查读出结果是否正确。
源代码
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
#include<fcntl.h>
#define SIZE 5
typedef struct _subject
{
char sno[20];//学号
char name[20];//姓名
float chinese;//语文成绩
float math;//数学成绩
float english;//英语成绩
}subject;
int main()
{
subject subs[SIZE];
subject sub;
int fd;
int i;
printf("请输入五位学生的信息:\n");
printf("分别输入学号、姓名 、语文成绩、数学成绩、英语成绩:\n");
fd = open("data.txt",O_WRONLY|O_CREAT|O_TRUNC,0777);
for(i = 0; i < SIZE; i++)
{
scanf("%s%s%f%f%f",subs[i].sno,subs[i].name,&subs[i].chinese,&subs[i].math, &subs[i].english);
write(fd,(void*)&subs[i],sizeof(subject));
}
close(fd);
fd = open("data.txt",O_RDONLY,0);
for(i = 0; i < SIZE; i++)
{
read(fd,(void*)&sub,sizeof(subject));
if(i % 2 == 0)
printf("%s %s %.1f %.1f %.1f\n",sub.sno,sub.name,sub.chinese,
sub.math,sub.english);
}
close(fd);
}
编译过程

测试数据
运行结果

解决问题
任意类型数据文件的读写
read、write函数在内存和文件之间传输一个数据块内容,这个数据块在 内存中的地址为buf,在文件中位置为pos。这个数据块位于内存中时,其内容可以是任何类 型,如整型、浮点型、字符串、数组、结构体、联合体,因此,UNIX I/O可以实现任意类 型数据的文件读写功能。
在本题中读入的数据为结构体,,而不是字符串,因此文件data不是文 本文件,用cat、more等命令查看其内容时,显示结果可能是乱码。
任务3
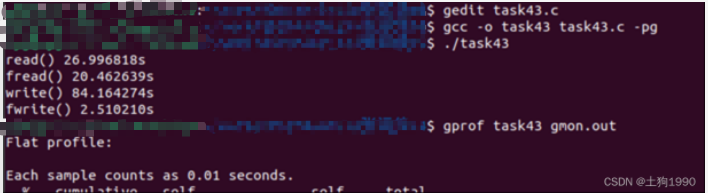
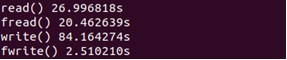
在Linux环境下,可以调用库函数gettimeofday测量一个代码段的执行时间,请写一个程序task43.c,测量read、write、fread、fwrite函数调用所需的执行时间,并与prof/gprof工具测的结果进行对比,看是否基本一致。并对四个函数的运行时间进行对比分析。
提示:由于一次函数调用时间太短,测量误差太多,应测量上述函数多次(如10000次)运行的时间,结果才会准确。
源代码
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
#include<sys/time.h>
double caltime(struct timeval time_start, struct timeval time_end) {
double wa= time_end.tv_usec - time_start.tv_usec;
double sa= time_end.tv_sec - time_start.tv_sec;
double ms = wa / 1000000.0 + sa;
return ms;
}
void myread(int fd1, char buf) {
read(fd1,&buf,1);
}
void mywriter(int fd1, char buf) {
write(fd1,&buf,1);
}
void myfread(FILE *fp, char buf) {
fread(&buf, 1, 1, fp);
}
void myfwriter(FILE *fp, char buf) {
fwrite(&buf, 1, 1, fp);
}
int main()
{
int fd1;//文件标识符
FILE *fp;//文件指针
char buf;//缓冲区
struct timeval time_start;//开始测试时间
struct timeval time_end;//结束测试时间
//测试输入:read系
fd1 = open("test.txt",O_RDONLY);
fp = fopen("file.txt", "r");
//测试read()
gettimeofday(&time_start,NULL);
for(int i; i < 100000000; i++)
myread(fd1,buf);
gettimeofday(&time_end,NULL);
printf("read() %lfs\n",caltime(time_start, time_end));
//测试fread()
gettimeofday(&time_start,NULL);
for(int i; i < 100000000; i++)
myfread(fp,buf);
gettimeofday(&time_end,NULL);
printf("fread() %lfs\n",caltime(time_start, time_end));
close(fd1);
fclose(fp);
//测试输出:write系
fd1 = open("test.txt",O_WRONLY,0777);
fp = fopen("file.txt", "w");
//测试write()
gettimeofday(&time_start,NULL);
for(int i; i < 100000000; i++)
mywriter(fd1,buf);
gettimeofday(&time_end,NULL);
printf("write() %lfs\n",caltime(time_start, time_end));
//测试fwrite()
gettimeofday(&time_start,NULL);
for(int i; i < 100000000; i++)
myfwriter(fp,buf);
gettimeofday(&time_end,NULL);
printf("fwrite() %lfs\n",caltime(time_start, time_end));
close(fd1);
fclose(fp);
}
编译过程
运行结果
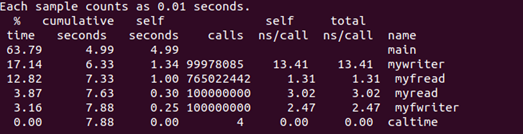
解决问题
使用prof/gprof测量程序运行时间
Linux/Unix环境提供了prof/gprof工具来收集一个程序各函数的执行次数和占用CPU时间等统计信息,使用prof/gprof工具查找程序性能问题,要求编译命令添加-p选项(prof)或-pg选项(gprof),程序执行时就会产生执行跟踪文件mon.out(或gmon.out),再运行prof(或gprof)程序读取跟踪数据,产生运行报告。现在用gprof对以下程序各函数运行性能(占用CPU时间)进行测量。
先输入源代码
#include <stdio.h>
int fast_multiply(x, y)
{
return x * y;
}
int slow_multiply(x, y)
{
int i, j, z;
for (i = 0, z = 0; i < x; i++)
z = z + y;
return z;
}
int main(int argc, char *argv[])
{
int i,j;
int x,y;
for (i = 0; i < 2000; i ++) {
for (j = 0; j < 3000 ; j++) {
x = fast_multiply(i, j);
y = slow_multiply(i, j);
}
}
printf("x=%d, y=%d\n", x, y);
return 0;
}
然后编译和执行该程序,检查是否函数性能跟踪数据文件gmon.out:
编译
$ gcc -pg -o multiply multiply.c
运行
$ ./multiply
x=5995001, y=5995001
查看文件
$ ls gmon.out
gmon.out
最后,用gprof命令产看各函数执行时间:
$ gprof multiply gmon.out
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls us/call us/call name
99.44 14.11 14.11 6000000 2.35 2.35 slow_multiply
0.42 14.17 0.06 main
0.14 14.19 0.02 6000000 0.00 0.00 fast_multiply
在这里,slow_multipy和fast_multiply执行600000次所花运行时间为14.11s和0.02秒。
任务4
在Linux系统环境下,编写程序task44.c,对一篇英文文章文件的英文单词词频进行统计。
(1) 以“单词:次数”格式输出所有单词的词频(必做)
(2) 以“单词:次数”格式、按词典序输出各单词的词频(选做)
(3) 以“单词:次数”格式输出出现频度最高的10个单词的词频
例如,若某个输入文件内容为:
GNU is an operating system that is free software—that is, it respects users’ freedom.
The development of GNU made it possible to use a computer without software that would trample your freedom.
则输出应该是:
GNU:2
is:3
it:2
……
提示:可以调用字符串处理函数、二叉树处理函数等库函数
源代码
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <fcntl.h>
#include<malloc.h>
#include<string.h>
//#include<algorithm>
//#include <unistd.h>
#define MAXSIZE 200
typedef struct Word {
char word[30]; //设单词最长为30个字母
int count; //该单词出现的次数
}WordNode;
typedef struct article {
WordNode Word[MAXSIZE]; //单词的集合
int num; //这篇文章不同的英文单词的种数
}Article;
void Insert_word(char* temp, Article* a) {
if (a->num == MAXSIZE) {
printf("单词表已经满,输入失败\n");
return;
}
if (temp == NULL)
return;
if (a->num == 0) { //情况1:单词表里暂时还没有保存单词
a->Word[0].word[0] = '\0';
strcpy(a->Word[0].word, temp);
a->Word[0].count = 1;
a->num = 1;
}
else {
int i;
for (i = 0; i < a->num; i++) {
if (strcmp(temp, a->Word[i].word) == 0) {//情况2:该单词已经存在
a->Word[i].count++;
return;
}
}
a->Word[a->num].word[0] = '\0';
strcpy(a->Word[a->num].word, temp); //情况2:该单词是首次输入
a->Word[a->num].count = 1;
a->num++;
}
}
void divide_word(char* temp) {
int i;
if (temp == NULL) {
return;
}
for (i = 0; temp[i] != '\0'; i++) {
if (!((temp[i] >= 'A' && temp[i] <= 'Z') || (temp[i] >= 'a' && temp[i] <= 'z'))) {
temp[i] = ' ';
}
}
}
//按照高频前十输出
void paixu(Article* article) {
int i, j;
for (i = 0; i < article->num - 1; i++) {
for (j = 0; j < article->num - 1 - i; j++) {
if (article->Word[j].count < article->Word[j + 1].count) {
WordNode temp = article->Word[j];
article->Word[j] = article->Word[j + 1];
article->Word[j + 1] = temp;
}
}
}
}
//void sort(Article* article) {
// int i, j;
// for (i = 0; i < article->num - 1; i++) {
// for (j = 0; j < article->num - 1 - i; j++) {
// if (strcmp(article->Word[j].word , article->Word[j + 1].word) > 0) {
// WordNode temp = article->Word[j];
// article->Word[j] = article->Word[j + 1];
// article->Word[j + 1] = temp;
// }
// }
// }
//}
//字典排序,快速排序
void swap(Article* article,int i,int j) {
WordNode temp = article->Word[i];
article->Word[i] = article->Word[j];
article->Word[j] = temp;
}
void quick_sort_recursive(Article* article,int start, int end) {
if(start >= end) return ;
int mid = end;
int left = start, right = end - 1;
while(left < right) {
while(strcmp(article->Word[left].word,article->Word[mid].word) < 0 && left < right)
left++;
while(strcmp(article->Word[right].word,article->Word[mid].word) >= 0 && left < right)
right--;
swap(article, left, right);
}
if(strcmp(article->Word[left].word,article->Word[end].word) > 0) {
swap(article, left, end);
}
else
left++;
if(left) {
quick_sort_recursive(article, start, left - 1);
}
quick_sort_recursive(article, left + 1, end);
}
void quick_sort(Article* article) {
quick_sort_recursive(article, 0, article->num - 1);
}
void main()
{
Article article = {.num=0};
char temp[1000];
int i;
FILE* fd = fopen("./test44.txt", "r");
while (!feof(fd)) {
char* p;
fscanf(fd, "%s", temp);
divide_word(temp); //有可能一次读入不止一个单词,所以要分隔开
p = strtok(temp, " "); //strtok把temp分成多个字符串
do {
Insert_word(p, &article);
} while ((p = strtok(NULL, " ")) != NULL);//合适调整循环跳出条件
}
quick_sort(&article);
printf("按词典序输出,所有单词的词频如下:\n");
for (i = 0; i < article.num; i++) {
printf("%s:%d\n", article.Word[i].word, article.Word[i].count);
}
printf("\n最高词频的前十个单词:\n");
paixu(&article); //使用稳定排序法,才能符合题目要求
for (i = 0; i < 10; i++) {
printf("%s:%d\n", article.Word[i].word, article.Word[i].count);
}
}
编译过程

测试数据


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)