pandas和numpy
1、numpy的核心数据结构是ndarray,支持任意维数的数组,但要求单个数组内所有数据是同质的,即类型必须相同;pandas是基于numpy数组构建的,它的核心数据结构是series和dataframe,仅支持一维和二维数据,但数据内部可以是异构数据,仅要求同列数据类型一致即可。numpy的数据结构仅支持数字索引,而pandas数据结构则同时支持数字索引和标签索引。2、numpy用于数值计算,
numpy与pandas各种功能及其对比(超全)_numpy和pandas的区别_阿丢是丢心心的博客-CSDN博客
一、简介
1、numpy的核心数据结构是ndarray
支持任意维数的数组,但要求单个数组内所有数据是同质的,即类型必须相同;pandas是基于numpy数组构建的,它的核心数据结构是series和dataframe,仅支持一维和二维数据,但数据内部可以是异构数据,仅要求同列数据类型一致即可。
numpy的数据结构仅支持数字索引,而pandas数据结构则同时支持数字索引和标签索引。
2、numpy用于数值计算,pandas主要用于数据处理与分析。
numpy虽然也支持字符串等其他数据类型,但仍然主要是用于数值计算,尤其是内部集成了大量矩阵计算模块,例如基本的矩阵运算、线性代数、fft、生成随机数等,支持灵活的广播机制。
pandas主要用于数据处理与分析,支持包括数据读写、数值计算、数据处理、数据分析和数据可视化全套流程操作。
二、基础属性
1.数据结构
在开始创建数据之前,再说明一下两种方法创建的数据结构形式
numpy:是通用的同构数据多维容器,其中的所有元素必须是相同类型的
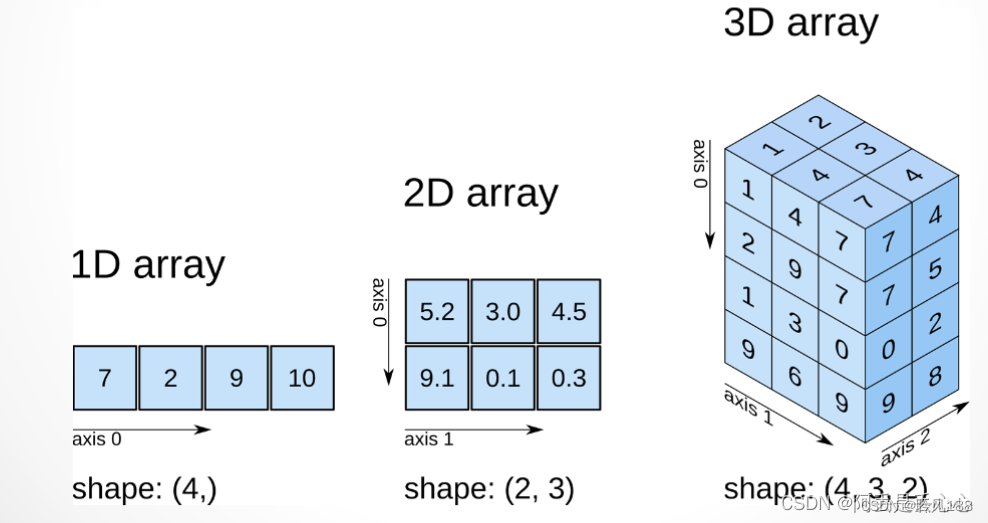
pandas:一维数据结构为series,多维是dataframe
其中:
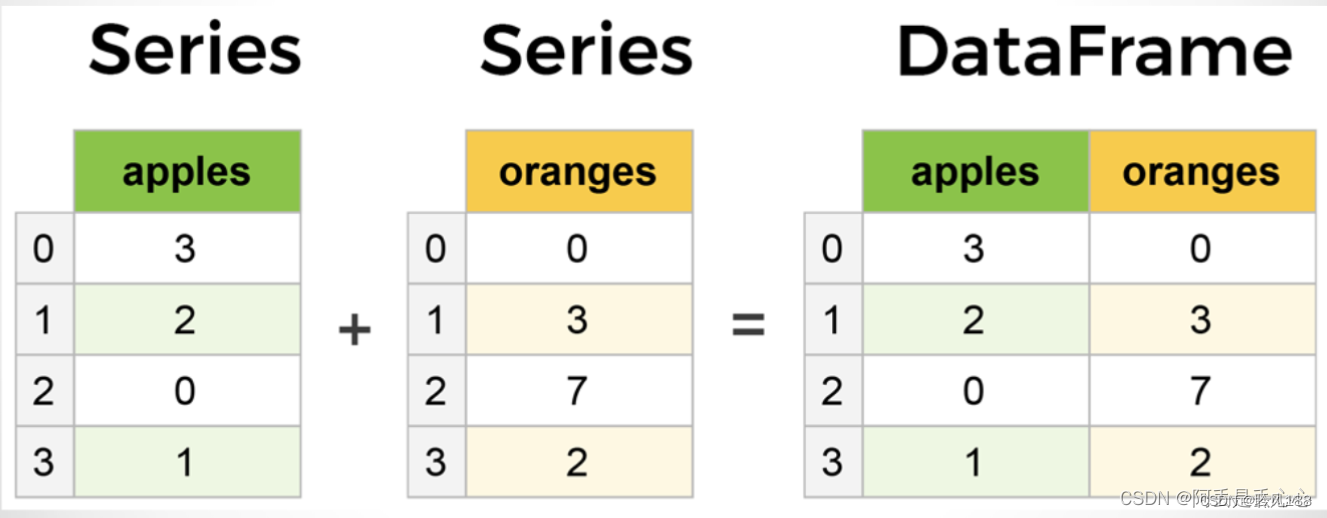
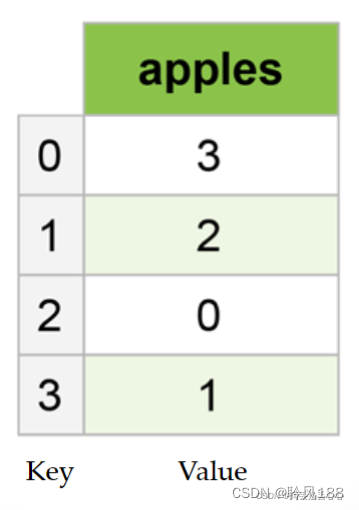
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成,索引在左边,值在右边。
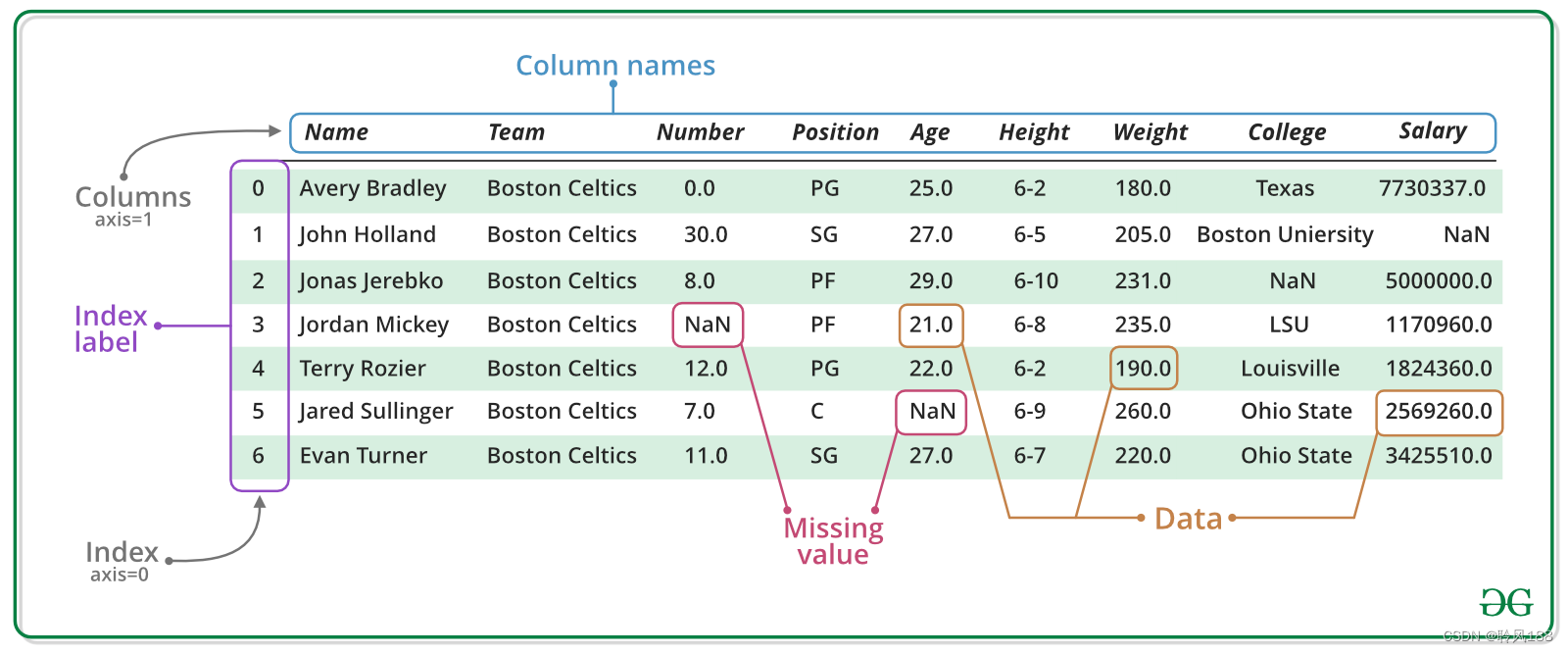
DataFrame是一个表格型的数据结构,既有行索引(index)也有列索引(columns),它可以被看做由Series组成的字典(共用同一个索引)。
每列可以是不同的值类型(数值、字符串、布尔值等)。
2、对象常用属性
(1)ndarray
data. shape 数组的形状
data.ndim 维度的数量
data.size 数组的总大小
data.dtype 数组中的数据类型(int8, uint8, float32, complex64, bool, object, string.
data.astype 数据类型转换
(2)Series
obj.values 获取数组的值
obj.index 获取数组的索引对象
obj.name 获取数组的名称
obj.index.name 获取索引的名称
(3) DateFrame
frame.index 获取表格的行索引
frame.columns 获取表格的列索引
frame.values 获取表格中的数据
frame.col_name 获取指定列的数据
frame.index.name 获取索引的名称
frame.columns.name 获取列的名称
重新命名列的三种方法
第一种方法:重新命名指定的列
df.rename(columns = {'环湖医院':'开滦医院', '普通医院':'三甲医院'}, inplace = True)
第二种方法:修改全部列名
df.columns = ['舒畅', '小舒畅', '舒小畅', '舒畅小']
第三种方法:修改列名的一部分
df.columns = df.columns.str.replace('环湖医院', '开滦医院')
(由于输出比较长,部分地方就只放了代码,没有放运行结果哈)
三、 一维数据(numpy和pandas.Series对比)
1、新增Create
#列表转化
list1 = [4, 7, -5, 3]
arr1 = np.array(list1)
s1 = pd.Series(list1)
arr1
s1
输出:
array([ 4, 7, -5, 3])
0 4
1 7
2 -5
3 3
dtype: int64
## 直接创建
arr2 = np.array([4, 7, -5, 3])
obj = Series([4, 7, -5, 3], dtype=np.int32)
obj2 = Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
arr2
obj
obj2
输出:
array([ 4, 7, -5, 3])
0 4
1 7
2 -5
3 3
dtype: int32
d 4
b 7
a -5
c 3
dtype: int64
#字典转换
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
obj3 = Series(sdata)
obj3
输出:
Ohio 35000
Texas 71000
Oregon 16000
Utah 5000
dtype: int64
states = ['California', 'Ohio', 'Oregon', 'Texas']
obj4 = Series(sdata, index=states)
obj4
输出:
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64#创建连续数值数组
arr3 = np.arange(5)
s3 = pd.Series(np.arange(5))
s3_1 = pd.Series(range(5)) #输出与s3相同
#创建全为0的数组
arr4 = np.zeros(5)
s4 = pd.Series(0 ,index = ['a','b','c','d'])
s4_1 = pd.Series(np.zeros(5))
#创建随机数数组
arr5 = np.random.rand(5)
arr_1 = np.random.random_sample(size=5)
s5 = pd.Series(np.random.rand(5))2、查找Read
obj2
输出:
d 4
b 7
a -5
c 3
dtype: int64
obj2[['c', 'a', 'd']]
输出:
c 3
a -5
d 4
dtype: int64
obj2[1:3] # [1, 3)
输出:
b 7
a -5
dtype: int64
obj2['b':'c'] # []
输出:
b 7
a -5
c 3
dtype: int64
obj
输出:
0 4
1 7
2 -5
3 3
dtype: int32
obj[1:3]
输出:
1 7
2 -5
dtype: int32
obj.index
输出:
RangeIndex(start=0, stop=4, step=1)
obj2.index
输出:
Index(['d', 'b', 'a', 'c'], dtype='object')
obj2.values
输出:
array([ 4, 7, -5, 3])
obj[1], obj2['a']
输出:
(7, -5)
3、修改Update
obj2
输出为:
d 4
b 7
a -5
c 3
dtype: int64
obj2['d'] = 6
obj2
输出为:
d 6
b 7
a -5
c 3
dtype: int64
obj2[['a', 'b', 'c']] = [1, 2, 3]
obj2
输出为:
d 6
b 2
a 1
c 3
dtype: int64
obj4
输出为:
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
obj4.name = 'population'
obj4.index.name = 'state'
obj4
输出为:
state
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
Name: population, dtype: float64
obj
输出为:
0 4
1 7
2 -5
3 3
dtype: int32
obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
obj
输出为:
Bob 4
Steve 7
Jeff -5
Ryan 3
dtype: int32
4、删除 Delete
obj2
输出为:
d 4
b 7
a -5
c 3
dtype: int64
del obj2['a']
输出为:
此次无输出
obj2.drop('c') # drop操作返回新的对象,原对象不变
输出为:
d 4
b 7
dtype: int64
obj2
输出为:
d 4
b 7
c 3
dtype: int64
obj2.drop(['b', 'd'])
输出为:
c 3
dtype: int64
obj2
输出为:
d 4
b 7
c 3
dtype: int64
5、运算
5.1、标量运算
数组与标量的算术运算会将标量值传播到各个元素
不同大小的数组之间的算术运算的执行方式叫做广播(broadcasting)
广播中较小数组的‘广播维’必须为1, 广播会在缺失和(或)长度为1的维度上进行。较小的数组会在较大的数组上沿着该维度广播,并在经过的地方做相应的算术运算。最简单的广播就是标量值跟数组合并的运算。
obj2
输出为:
d 4
b 7
a -5
c 3
dtype: int64
obj2 * 2
输出为:
d 8
b 14
a -10
c 6
dtype: int64
obj2 > 4
输出为:
d False
b True
a False
c False
dtype: bool
obj2 / 2
输出为:
d 2.0
b 3.5
a -2.5
c 1.5
dtype: float64
obj2[obj2 > 4]
输出为:
b 7
dtype: int64
'b' in obj2
输出为:
True
'e' in obj2
输出为:
False
5.2、向量运算
# 根据运算的索引标签自动对齐数据,对不同索引的对象进行算术运算。
obj3
输出为:
Ohio 35000
Texas 71000
Oregon 16000
Utah 5000
dtype: int64
obj4
输出为:
state
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
Name: population, dtype: float64
obj3 + obj4
输出为:
California NaN
Ohio 70000.0
Oregon 32000.0
Texas 142000.0
Utah NaN
dtype: float64
obj3 * obj4
输出为:
California NaN
Ohio 1.225000e+09
Oregon 2.560000e+08
Texas 5.041000e+09
Utah NaN
dtype: float64
obj3 > obj4 # 会报错,无法匹配
ser1 = pd.Series(np.arange(1, 6), index = list('abcde'))
ser2 = pd.Series(np.arange(2, 7), index = list('abcde'))
ser1 > ser2
输出为:
a False
b False
c False
d False
e False
dtype: bool
5.3、函数运算
(1)通用函数
通用函数(ufunc): 一种对ndarray中的数据执行元素级运算的函数。对pandas中的Series和DataFrame也适用。
一元ufunc: abs, sqrt, square, exp, log, sign, isnan, ceil, floor, rint, modf, isfinit, isinf, cos, cosh, sin, sinh, tan, tanh,....
用法:np.abs(arr)
二元ufunc:add, substract, multiply, divide, floor_divide, power, maximum, minimum, mod, copysign, greater, greater_equal, less, less_equal, equal, not_equal, logical_and, logical_or
用法:np.add(arr1, arr2)
(2)numpy
ndarray对象的基本数学和统计方法函数
sum, mean, std, var, min, max, argmin, argmax, cumsum, cumprod
arr = np.random.randn(3,4)
print(arr)
print(arr.mean())
print(arr.sum())
print(arr.mean(axis = 1))
print(arr.sum(axis = 0))
输出为:
[[ 0.32032819 1.26761265 -2.39961199 0.97646207]
[-0.23177368 -0.31558693 -0.82149254 -1.63021035]
[-0.84288386 -0.01973655 -0.96049732 1.73198541]]
-0.2437837416655606
-2.9254048999867273
[ 0.04119773 -0.74976587 -0.02278308]
[-0.75432935 0.93228917 -4.18160185 1.07823713](3)pandas
pandas对象拥有的数学和统计方法:count, describe, min, max, argmin, argmax, idxmin, idxmax, quantile, sum, mean, median, mad, var, std, skew, kurt, cumsum, cummin, cummax, cumprod, diff, pct_change
obj2
输出为:
d 4
b 7
a -5
c 3
dtype: int64
np.exp(obj2)
输出为:
d 403.428793
b 7.389056
c 20.085537
dtype: float64
obj4
输出为:
state
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
Name: population, dtype: float64
pd.isnull(obj4)
输出为:
state
California True
Ohio False
Oregon False
Texas False
Name: population, dtype: bool
pd.notnull(obj4)
输出为:
state
California False
Ohio True
Oregon True
Texas True
Name: population, dtype: bool
obj4.isnull()
输出为:
state
California True
Ohio False
Oregon False
Texas False
Name: population, dtype: bool
obj4.notnull()
输出为:
state
California False
Ohio True
Oregon True
Texas True
Name: population, dtype: bool
#顺便对比一下numpy
arr = np.array([[1, 2, 3, 4, 5], [6, 4, 3, 2, 1]])
print(arr)
print(arr.argmax(axis=0))
输出为:
[[1 2 3 4 5]
[6 4 3 2 1]]
[1 1 0 0 0]
ser = pd.Series([1,3,2,5,7])
print(ser)
print(ser.argmax)
输出为:
0 1
1 3
2 2
3 5
4 7
dtype: int64
<bound method IndexOpsMixin.argmax of 0 1
1 3
2 2
3 5
4 7
dtype: int64>
四、多维数据
1、新增Create
numpy
arr1 =np.array([[1, 2, 3, 4],
[5, 6, 7, 8]])
输出为:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
s0 = pd.DataFrame([[1, 2, 3, 4],
[5, 6, 7, 8]])
输出为:
0 1 2 3
0 1 2 3 4
1 5 6 7 8
s1 = pd.DataFrame(np.arange(16).reshape((4, 4)))
输出为:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15我们经常用字典的方式来创建series和dataframe
#外层字典的键作为列索引,dataframe自动加上行索引
data = {'one': [0, 1],
'two': [2, 3]}
s3 = pd.DataFrame(data)
输出为:
one two
0 0 2
1 1 3
#对于嵌套字典,外层字典作为列索引,内层键作为行索引
data = {'one': {'a':0, 'b':1},
'two': {'a':2, 'b':3}}
s4 = pd.DataFrame(data)
输出为:
one two
a 0 2
b 1 3还可以自定义列和索引,并且依据索引对改变数据顺序
#自定义列和索引标签
s4 = pd.DataFrame(data, columns=['one', 'two', 'three', 'four'])
输出为:
one two three four
a 0 2 NaN NaN
b 1 3 NaN NaN
s5 = pd.DataFrame(data, columns=['three', 'two', 'one', 'four'])
输出为:
three two one four
a NaN 2 0 NaN
b NaN 3 1 NaN综合上述重举例
data = {
'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9]
}
frame = DataFrame(data)
frame
输出为:
state year pop
0 Ohio 2000 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
frame2 = DataFrame(data, columns=['year', 'state', 'pop', 'debt'], index=['one', 'two', 'three', 'four', 'five'])
frame2
输出为:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
obj = Series([4, 7, -5, 3, 10], index=['d', 'b', 'a', 'c', 'e'])
obj2 = Series([8, 1, 2, -21], index=['d', 'b', 'a', 'c'])
DataFrame({'col1': obj, 'col2': obj2})
输出为:
col1 col2
a -5 2.0
b 7 1.0
c 3 -21.0
d 4 8.0
e 10 NaN
frame3 = DataFrame({'year': {'one': 2000, 'two': 2001, 'three': 2002, 'four': 2001, 'five': 2002},
'state': {'one': 'Ohio', 'two': 'Ohio', 'three': 'Ohio', 'four': 'Nevada', 'five': 'Nevada'},
'pop': {'one': 1.5, 'two': 1.7, 'three': 3.6, 'four': 2.4, 'five': 2.9}})
输出为:
year state pop
one 2000 Ohio 1.5
two 2001 Ohio 1.7
three 2002 Ohio 3.6
four 2001 Nevada 2.4
five 2002 Nevada 2.9
2、查找Read
frame2
输出为:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
frame2.values
输出为:
array([[2000, 'Ohio', 1.5, nan],
[2001, 'Ohio', 1.7, nan],
[2002, 'Ohio', 3.6, nan],
[2001, 'Nevada', 2.4, nan],
[2002, 'Nevada', 2.9, nan]], dtype=object)
frame2.shape
输出为:
(5, 4)
frame2.index
输出为:
Index(['one', 'two', 'three', 'four', 'five'], dtype='object')
frame2.columns
输出为:
Index(['year', 'state', 'pop', 'debt'], dtype='object')
frame2['state'] # 获取一列,得到一个Series
输出为:
one Ohio
two Ohio
three Ohio
four Nevada
five Nevada
Name: state, dtype: object
frame2.state # 获取一列,得到一个Series
输出为:
one Ohio
two Ohio
three Ohio
four Nevada
five Nevada
Name: state, dtype: object
frame2[['state', 'debt']] # 获取多列,得到一个DataFrame
输出为:
state debt
one Ohio NaN
two Ohio NaN
three Ohio NaN
four Nevada NaN
five Nevada NaN
frame2['one':'one'] # 获取行,必须使用切片的方式 []
输出为:
year state pop debt
one 2000 Ohio 1.5 NaN
frame2[0:4] # 前4行,容易混淆 [)
输出为:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
frame2.reindex(['two', 'one']) # 选出特定的行,按照参数的顺序
输出为:
year state pop debt
two 2001 Ohio 1.7 NaN
one 2000 Ohio 1.5 NaN
frame2.loc['one':'three', ['state', 'debt']] # loc使用index名字,第一个参数索引行,第二个参数索引列
输出为:
state debt
one Ohio NaN
two Ohio NaN
three Ohio NaN
frame2.loc[:, ['state', 'debt']] # 所有行
输出为:
state debt
one Ohio NaN
two Ohio NaN
three Ohio NaN
four Nevada NaN
five Nevada NaN
frame2.loc['one':'one', ['state', 'debt']] # 一行,得到DataFrame
输出为:
state debt
one Ohio NaN
frame2.loc['one', ['state', 'debt']] # 一行,得到Series
输出为:
state Ohio
debt NaN
Name: one, dtype: object
frame2
输出为:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
frame2.iloc[0:3, [1, 3]] # iloc使用绝对位置(从0开始),第一个参数索引行,第二个参数索引列, 推荐使用iloc
输出为:
state debt
one Ohio NaN
two Ohio NaN
three Ohio NaN
frame2.iloc[:, [1,3]] # 所有行
输出为:
state debt
one Ohio NaN
two Ohio NaN
three Ohio NaN
four Nevada NaN
five Nevada NaN
frame2.iloc[0:1, [1, 3]] # 一行,得到DataFrame
输出为:
state debt
one Ohio NaN
frame2.iloc[0, [1, 3]] # 一行,得到Series
输出为:
state Ohio
debt NaN
Name: one, dtype: object
3、修改Update
frame2
输出为:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
frame2['debt'] = 16.5
frame2
输出为:
year state pop debt
one 2000 Ohio 1.5 16.5
two 2001 Ohio 1.7 16.5
three 2002 Ohio 3.6 16.5
four 2001 Nevada 2.4 16.5
five 2002 Nevada 2.9 16.5
frame2['debt'] = np.arange(5)
frame2
输出为:
year state pop debt
one 2000 Ohio 1.5 0
two 2001 Ohio 1.7 1
three 2002 Ohio 3.6 2
four 2001 Nevada 2.4 3
five 2002 Nevada 2.9 4
val = Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
frame2['debt'] = val
frame2
输出为:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 -1.2
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 -1.5
five 2002 Nevada 2.9 -1.7
frame2.name = 'data frame'
frame2.columns.name = 'columns'
frame2.index.name = 'index'
frame2
输出为:
columns year state pop debt
index
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 -1.2
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 -1.5
five 2002 Nevada 2.9 -1.7
frame2.columns = ['a', 'b', 'c', 'd']
frame2
输出为:
a b c d
index
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 -1.2
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 -1.5
five 2002 Nevada 2.9 -1.7
frame2.index = [1, 2, 3, 4, 5]
frame2
输出为:
a b c d
1 2000 Ohio 1.5 NaN
2 2001 Ohio 1.7 -1.2
3 2002 Ohio 3.6 NaN
4 2001 Nevada 2.4 -1.5
5 2002 Nevada 2.9 -1.7
4、删除Delete
frame2
输出为:
a b c d
1 2000 Ohio 1.5 NaN
2 2001 Ohio 1.7 -1.2
3 2002 Ohio 3.6 NaN
4 2001 Nevada 2.4 -1.5
5 2002 Nevada 2.9 -1.7
frame2.drop([1, 2], inplace=True, axis=0) # 删除行,inplace参数控制是否真正删除
frame2
输出为:
a b c d
3 2002 Ohio 3.6 NaN
4 2001 Nevada 2.4 -1.5
5 2002 Nevada 2.9 -1.7
frame2.drop(['a', 'b'], axis=1) # 删除列
输出为:
c d
3 3.6 NaN
4 2.4 -1.5
5 2.9 -1.7
frame2.pop('c') # 真正删除
frame2
输出为:
a b d
3 2002 Ohio NaN
4 2001 Nevada -1.5
5 2002 Nevada -1.7
del frame2['a']
frame2
输出为:
b d
3 Ohio NaN
4 Nevada -1.5
5 Nevada -1.7
5、运算
5.1、标量运算
frame3
输出为:
year state pop
five 2002 Nevada 2.9
four 2001 Nevada 2.4
one 2000 Ohio 1.5
three 2002 Ohio 3.6
two 2001 Ohio 1.7
frame3['pop'] > 2
输出为:
five True
four True
one False
three True
two False
Name: pop, dtype: bool
frame3[frame3['pop'] > 2]
输出为:
year state pop
five 2002 Nevada 2.9
four 2001 Nevada 2.4
three 2002 Ohio 3.6
frame
输出为:
state year pop
0 Ohio 2000 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
frame['pop']
输出为:
0 1.5
1 1.7
2 3.6
3 2.4
4 2.9
Name: pop, dtype: float64
# Dataframe
df = pd.DataFrame(np.arange(9.).reshape((3,3)),
index = list('abc'),
columns = ['one','two','three'])
print(df)
输出为:
one two three
a 0.0 1.0 2.0
b 3.0 4.0 5.0
c 6.0 7.0 8.0
print(df + 1)
输出为:
one two three
a 1.0 2.0 3.0
b 4.0 5.0 6.0
c 7.0 8.0 9.0
print(np.add(df, 1)) #dataframe基于numpy数组进行计算,我们可以直接使用np的运算方法
输出为:
one two three
a 1.0 2.0 3.0
b 4.0 5.0 6.0
c 7.0 8.0 9.0
print(df ** 2)
输出为:
one two three
a 0.0 1.0 4.0
b 9.0 16.0 25.0
c 36.0 49.0 64.0
print((df > 2) & (df < 6))
输出为:
one two three
a False False False
b True True True
c False False False
5.2、向量运算
df = pd.DataFrame(np.arange(9.).reshape((3,3)),
index = list('abc'),
columns = ['one','two','three'])
print(df)
输出为:
one two three
a 0.0 1.0 2.0
b 3.0 4.0 5.0
c 6.0 7.0 8.0
#当从DataFrame减去相同索引的Series(df.iloc[0]),每一行都会执行这个操作。这就叫做广播(broadcasting)
ser = df.iloc[0]
print(ser)
print(df-ser)
输出为:
one 0.0
two 1.0
three 2.0
Name: a, dtype: float64
one two three
a 0.0 0.0 0.0
b 3.0 3.0 3.0
c 6.0 6.0 6.0
#如果希望匹配行且在列上广播,则必须使用DataFrame的算术运算方法。
#传入的轴号就是希望匹配的轴,行索引(axis=‘index’ or axis=0)或列索引(axis=‘column’ or axis=1)。
ser2 = df.iloc[:,1]
print(ser2)
df.sub(ser2, axis = 'index')
输出为:
a 1.0
b 4.0
c 7.0
Name: two, dtype: float64
one two three
a -1.0 0.0 1.0
b -1.0 0.0 1.0
c -1.0 0.0 1.0
#如果某个索引值在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集
ser3 = pd.Series(range(3), index = ['one', 'two','four'])
print(ser3)
print(df - ser3)
输出为:
one 0
two 1
four 2
dtype: int64
four one three two
a NaN 0.0 NaN 0.0
b NaN 3.0 NaN 3.0
c NaN 6.0 NaN 6.05.3、函数运算
frame['pop'].apply(lambda x: x**3) # 对df的某一列应用一个函数,生成新的Series
输出为:
0 3.375
1 4.913
2 46.656
3 13.824
4 24.389
Name: pop, dtype: float64六、文件读写I/O
df = pd.read_csv('E:\\data\\ad_feature.csv', sep=',', header=0) # 读入数据
df.shape
输出为:
(846811, 6)
df.columns
输出为:
Index(['adgroup_id', 'cate_id', 'campaign_id', 'customer', 'brand', 'price'], dtype='object')
df.head(10)
输出为:
adgroup_id cate_id campaign_id customer brand price
0 63133 6406 83237 1 95471.0 170.00
1 313401 6406 83237 1 87331.0 199.00
2 248909 392 83237 1 32233.0 38.00
3 208458 392 83237 1 174374.0 139.00
4 110847 7211 135256 2 145952.0 32.99
5 607788 6261 387991 6 207800.0 199.00
6 375706 4520 387991 6 NaN 99.00
7 11115 7213 139747 9 186847.0 33.00
8 24484 7207 139744 9 186847.0 19.00
9 28589 5953 395195 13 NaN 428.00
df[:100].to_csv('E:\\data\\output.csv', index=False) # 输出成CSV格式,索引(index)不要输出
df[:100].to_html('E:\\data\\output.html', index=False) # 输出成网页table
writer = pd.ExcelWriter('E:\\data\\output.xlsx') # 输出到Excel文件
df[:100].to_excel(writer, 'Sheet1', index=False)
df[100:200].to_excel(writer, 'Sheet2', index=False)
writer.save()
1、基本操作 Essential Basic Functionality
df.head(10) # 前十行
| adgroup_id | cate_id | campaign_id | customer | brand | price | |
|---|---|---|---|---|---|---|
| 0 | 63133 | 6406 | 83237 | 1 | 95471.0 | 170.00 |
| 1 | 313401 | 6406 | 83237 | 1 | 87331.0 | 199.00 |
| 2 | 248909 | 392 | 83237 | 1 | 32233.0 | 38.00 |
| 3 | 208458 | 392 | 83237 | 1 | 174374.0 | 139.00 |
| 4 | 110847 | 7211 | 135256 | 2 | 145952.0 | 32.99 |
| 5 | 607788 | 6261 | 387991 | 6 | 207800.0 | 199.00 |
| 6 | 375706 | 4520 | 387991 | 6 | NaN | 99.00 |
| 7 | 11115 | 7213 | 139747 | 9 | 186847.0 | 33.00 |
| 8 | 24484 | 7207 | 139744 | 9 | 186847.0 | 19.00 |
| 9 | 28589 | 5953 | 395195 | 13 | NaN | 428.00 |
df.tail(10) # 倒数十行
| adgroup_id | cate_id | campaign_id | customer | brand | price | |
|---|---|---|---|---|---|---|
| 846801 | 841089 | 5271 | 378762 | 255848 | NaN | 75.0 |
| 846802 | 828175 | 8116 | 374639 | 255851 | 430861.0 | 376.0 |
| 846803 | 831181 | 7600 | 377541 | 255862 | 122355.0 | 260.0 |
| 846804 | 762452 | 4284 | 379172 | 255865 | NaN | 128.0 |
| 846805 | 762200 | 4284 | 379172 | 255865 | NaN | 169.0 |
| 846806 | 824255 | 4526 | 380022 | 255868 | 389713.0 | 268.0 |
| 846807 | 790170 | 4280 | 379736 | 255872 | 322171.0 | 68.0 |
| 846808 | 845286 | 6261 | 379736 | 255872 | 322171.0 | 88.0 |
| 846809 | 824732 | 4520 | 379736 | 255872 | 322171.0 | 68.0 |
| 846810 | 845337 | 11156 | 379603 | 255874 | 74120.0 | 279.0 |
df['price'].describe() # 一列的统计信息,只对于可以比较大小的值有意义
count 8.468110e+05
mean 1.838867e+03
std 3.108877e+05
min 1.000000e-02
25% 4.900000e+01
50% 1.390000e+02
75% 3.520000e+02
max 1.000000e+08
Name: price, dtype: float64
df['cate_id'].describe() # 类别,无意义
count 846811.000000
mean 5868.593464
std 2705.171203
min 1.000000
25% 4383.000000
50% 6183.000000
75% 7047.000000
max 12960.000000
Name: cate_id, dtype: float64
# 迭代 Iteration, 一般用不到, 用于精细调整数据
for row in df[:10].itertuples():
print(row.cate_id, row.price)
6406 170.0
6406 199.0
392 38.0
392 139.0
7211 32.99
6261 199.0
4520 99.0
7213 33.0
7207 19.0
5953 428.0
# 排序 Sort
df[:10].sort_values(by='price') # 按照价格从高到低排序
| adgroup_id | cate_id | campaign_id | customer | brand | price | |
|---|---|---|---|---|---|---|
| 8 | 24484 | 7207 | 139744 | 9 | 186847.0 | 19.00 |
| 4 | 110847 | 7211 | 135256 | 2 | 145952.0 | 32.99 |
| 7 | 11115 | 7213 | 139747 | 9 | 186847.0 | 33.00 |
| 2 | 248909 | 392 | 83237 | 1 | 32233.0 | 38.00 |
| 6 | 375706 | 4520 | 387991 | 6 | NaN | 99.00 |
| 3 | 208458 | 392 | 83237 | 1 | 174374.0 | 139.00 |
| 0 | 63133 | 6406 | 83237 | 1 | 95471.0 | 170.00 |
| 1 | 313401 | 6406 | 83237 | 1 | 87331.0 | 199.00 |
| 5 | 607788 | 6261 | 387991 | 6 | 207800.0 | 199.00 |
| 9 | 28589 | 5953 | 395195 | 13 | NaN | 428.00 |
df[:10].sort_values(by=['price', 'brand'], ascending=False) # 可以按照多个key进行排序
| adgroup_id | cate_id | campaign_id | customer | brand | price | |
|---|---|---|---|---|---|---|
| 9 | 28589 | 5953 | 395195 | 13 | NaN | 428.00 |
| 5 | 607788 | 6261 | 387991 | 6 | 207800.0 | 199.00 |
| 1 | 313401 | 6406 | 83237 | 1 | 87331.0 | 199.00 |
| 0 | 63133 | 6406 | 83237 | 1 | 95471.0 | 170.00 |
| 3 | 208458 | 392 | 83237 | 1 | 174374.0 | 139.00 |
| 6 | 375706 | 4520 | 387991 | 6 | NaN | 99.00 |
| 2 | 248909 | 392 | 83237 | 1 | 32233.0 | 38.00 |
| 7 | 11115 | 7213 | 139747 | 9 | 186847.0 | 33.00 |
| 4 | 110847 | 7211 | 135256 | 2 | 145952.0 | 32.99 |
| 8 | 24484 | 7207 | 139744 | 9 | 186847.0 | 19.00 |
df[(df['price'] > 1000) & (df['price'] <= 1005)] # 按条件选取
| adgroup_id | cate_id | campaign_id | customer | brand | price | |
|---|---|---|---|---|---|---|
| 15532 | 162225 | 438 | 195767 | 10304 | 27548.0 | 1003.20 |
| 15629 | 198226 | 1137 | 132021 | 10304 | 27548.0 | 1003.95 |
| 63708 | 493633 | 6529 | 24297 | 43846 | 65862.0 | 1005.00 |
| 95975 | 70894 | 6143 | 415904 | 70491 | 57921.0 | 1001.00 |
| 141950 | 146094 | 6422 | 202221 | 110338 | 383342.0 | 1001.00 |
| 170936 | 56930 | 438 | 63192 | 135753 | 236763.0 | 1001.00 |
| 249594 | 131736 | 7548 | 239667 | 218706 | NaN | 1004.00 |
| 269105 | 731301 | 6300 | 321125 | 241392 | 449625.0 | 1001.00 |
| 381495 | 95726 | 438 | 15319 | 69075 | 198458.0 | 1004.00 |
| 387720 | 520899 | 10061 | 196687 | 74656 | 121466.0 | 1004.00 |
| 387729 | 217219 | 10061 | 196687 | 74656 | 121466.0 | 1004.00 |
| 426948 | 740358 | 685 | 37953 | 111752 | NaN | 1001.00 |
| 446511 | 356429 | 6261 | 244039 | 129461 | 291007.0 | 1001.00 |
| 466898 | 502035 | 6261 | 76193 | 146324 | 348841.0 | 1003.00 |
| 644946 | 778184 | 4282 | 64922 | 55566 | NaN | 1001.00 |
| 655803 | 279547 | 4290 | 409222 | 64015 | 109551.0 | 1002.00 |
| 808370 | 202848 | 1535 | 211527 | 208644 | 33413.0 | 1001.00 |
2、数据分组 Groupby
df = pd.read_csv('E:\\data\\ad_feature.csv', sep=',', header=0, nrows=1000)
cate_group = df.groupby(['cate_id', 'customer']) # 按照cate_id,customer进行分组,把cate_id,customer相同的数据分成一组
type(cate_group)
pandas.core.groupby.generic.DataFrameGroupBy
cate_group.size()
cate_id customer
12 63 3
369 1
45 340 3
122 225 3
658 2
..
11932 196 1
12115 516 1
12159 112 1
12390 130 3
12845 323 1
Length: 472, dtype: int64
cate_group['price', 'brand'].mean().head() # 计算每一组price和brand的平均值,必须保证函数在每个组中产生一个值
price brand
cate_id
12 374.000000 97165.0
45 62.666667 141605.0
122 28.800000 386513.0
124 89.000000 100353.0
133 2.000000 NaN
df.groupby('cate_id')['brand'].mean().reset_index(drop=False).head() # reset_index会重新设置index,drop参数控制是否丢弃原来的index
cate_id brand
0 12 97165.0
1 45 141605.0
2 122 386513.0
3 124 100353.0
4 133 NaN
3、数据合并(Merge, Concatenate)
df = pd.read_csv('E:\\data\\ad_feature.csv', sep=',', header=0)
df1 = df[['adgroup_id', 'price']]
df2 = df[['adgroup_id', 'cate_id', 'brand']]
df1.head()
输出为:
adgroup_id price
0 63133 170.00
1 313401 199.00
2 248909 38.00
3 208458 139.00
4 110847 32.99
df2.head()
输出为:
adgroup_id cate_id brand
0 63133 6406 95471.0
1 313401 6406 87331.0
2 248909 392 32233.0
3 208458 392 174374.0
4 110847 7211 145952.0
df3 = pd.merge(df1, df2, on='adgroup_id', how='inner') # 把adgroup_id相同的数据拼接
df3.head()
输出为:
adgroup_id price cate_id brand
0 63133 170.00 6406 95471.0
1 313401 199.00 6406 87331.0
2 248909 38.00 392 32233.0
3 208458 139.00 392 174374.0
4 110847 32.99 7211 145952.0
pd.concat([df[:4], df[10:15]], axis=0) # 按照axis轴进行拼接,axis=0在行上拼接,axis=1在列上拼接
输出为:
adgroup_id cate_id campaign_id customer brand price
0 63133 6406 83237 1 95471.0 170.0
1 313401 6406 83237 1 87331.0 199.0
2 248909 392 83237 1 32233.0 38.0
3 208458 392 83237 1 174374.0 139.0
10 23236 5953 395195 13 NaN 368.0
11 300556 5953 395195 13 NaN 639.0
12 92560 5953 395195 13 NaN 368.0
13 590965 4284 28145 14 454237.0 249.0
14 529913 4284 70206 14 NaN 249.0
pd.concat([df[:4], df[10:15]], axis=1) # 把index相同的拼接成一行输出为:
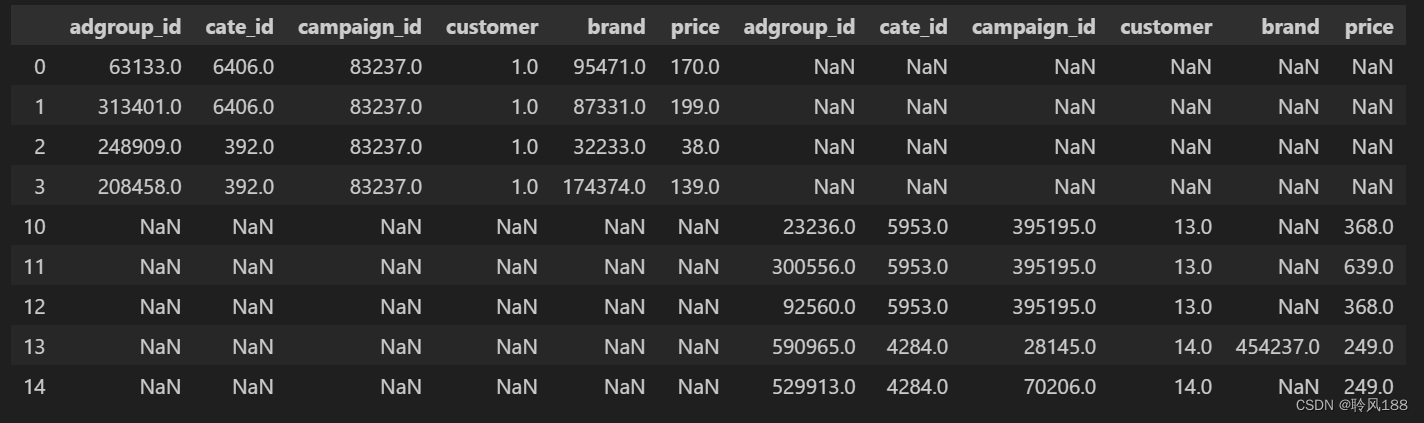
df6 = pd.concat([df[:4], df[10:15].reset_index(drop=True)], axis=1) 去除原index
df6输出为:

df6.columns
输出为:
Index(['adgroup_id', 'cate_id', 'campaign_id', 'customer', 'brand', 'price',
'adgroup_id', 'cate_id', 'campaign_id', 'customer', 'brand', 'price'],
dtype='object')
df6['cate_id']
输出为:
cate_id cate_id
0 6406.0 5953
1 6406.0 5953
2 392.0 5953
3 392.0 4284
4 NaN 42844、缺失值(Missing Value)处理
df.shape
输出为:
(846811, 6)
df.dropna().shape # 丢弃NaN值
输出为:
(600481, 6)df.fillna(0).head(10) # 将NaN填充成固定值输出为:
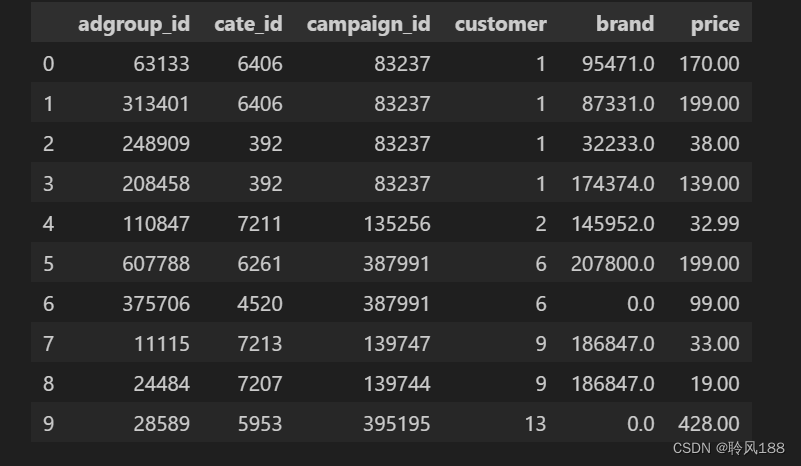
df.fillna(df['brand'].mean()).head(10) # 使用brand均值填充输出为:

df.fillna(method='ffill').head(10) # 将NaN填充成前一个值输出为:
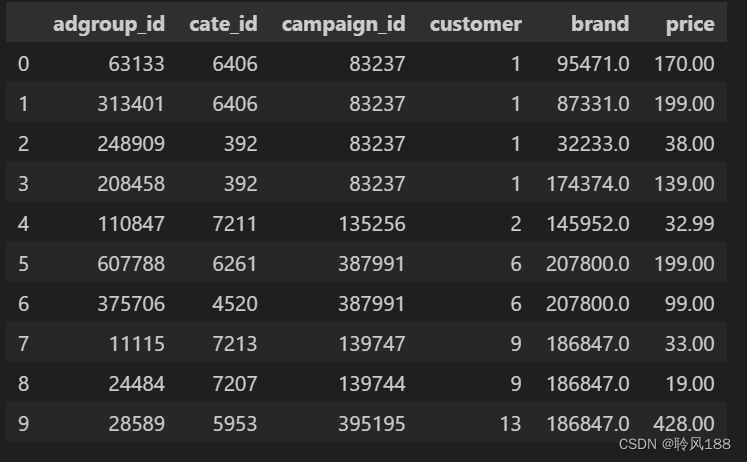
5、异常值 / 离群值(Outlier Data)处理
price_des = df['price'].describe()
price_des
输出为:
count 8.468110e+05
mean 1.838933e+03
std 3.109008e+05
min 1.000000e-02
25% 4.900000e+01
50% 1.390000e+02
75% 3.520000e+02
max 1.000000e+08
Name: price, dtype: float64
valid_max = price_des['50%'] + 3 * (price_des['75%'] - price_des['50%'])
valid_min = price_des['50%'] - 3 * (price_des['50%'] - price_des['25%'])
df['price'] = df['price'].clip(valid_min, valid_max) # 把异常值变为边界值
df['price'].describe()
输出为:
count 846811.000000
mean 243.996387
std 253.800315
min 0.010000
25% 49.000000
50% 139.000000
75% 352.000000
max 778.000000
Name: price, dtype: float64
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)