4.3 C语言的高级用法以及易错点
从上面结果可以看出方式1 方式2是一致的:也就是说方式2中,数组直接给值是可行的。void *则为“无类型指针”,void *可以指向任何类型的数据。void真正发挥的作用在于: (1) 对函数返回的限定; (2) 对函数参数的限定。 众所周知,如果指针p1和p2的类型相同,那么我们可以直接在p1和p2间互相赋值;如果p1和p2指向不同的数据类型,则必须使用强制类型转换运算符把赋值运算
文章目录
- 1、结构体指针赋值及 void * “无类型指针”
- 2、指针以及相互之间的强制转换
- 3、 函数指针和指针函数的区别
- 4、 函数返回值为指针变量举例
- 5、特别注意typdef 的用法:
- 6、enum的用法
- 7、sprintf的用法
- 8、结构体位阈
- 9、大端小端
- 10 与0异或 与1异或 与(&)
- 11、二分法查找列表
- 12、解一元一次方程
- 13、四舍五入(三目运算)
- 14、8bit 16bit 32bit之间的相互转换
- 15、sizeof 与strlen区别
- 16、关于flash或者SRAM赋值
- 17 常量指针与指针常量
- 18 指针与数组的关系
- 19 const基础知识
- 20 undef用法
- 21 #pragma pack() 和 __packed
- 22 小数的相关运算
- 23 #if defined...#elif defined...#endif
1、结构体指针赋值及 void * “无类型指针”
1.0结构体指针赋值
typedef char CHAR_A, *STR_A;
typedef struct
{
STR_A m_strFileName;//等价于char* m_strFileName;
STR_A m_strUserName;//等价于char* m_lpBuffer;
char *m_lpBuffer;
int m_ulSize;
} USB_CopyParam_t,*USB_CopyParam_p;
uint32_t data_adr;
char *p;
char data[5];
int data_int[5];
USB_CopyParam_t lpParam;
USB_CopyParam_p lpCopyParam;//等价于 USB_CopyParam_t *lpCopyParam;
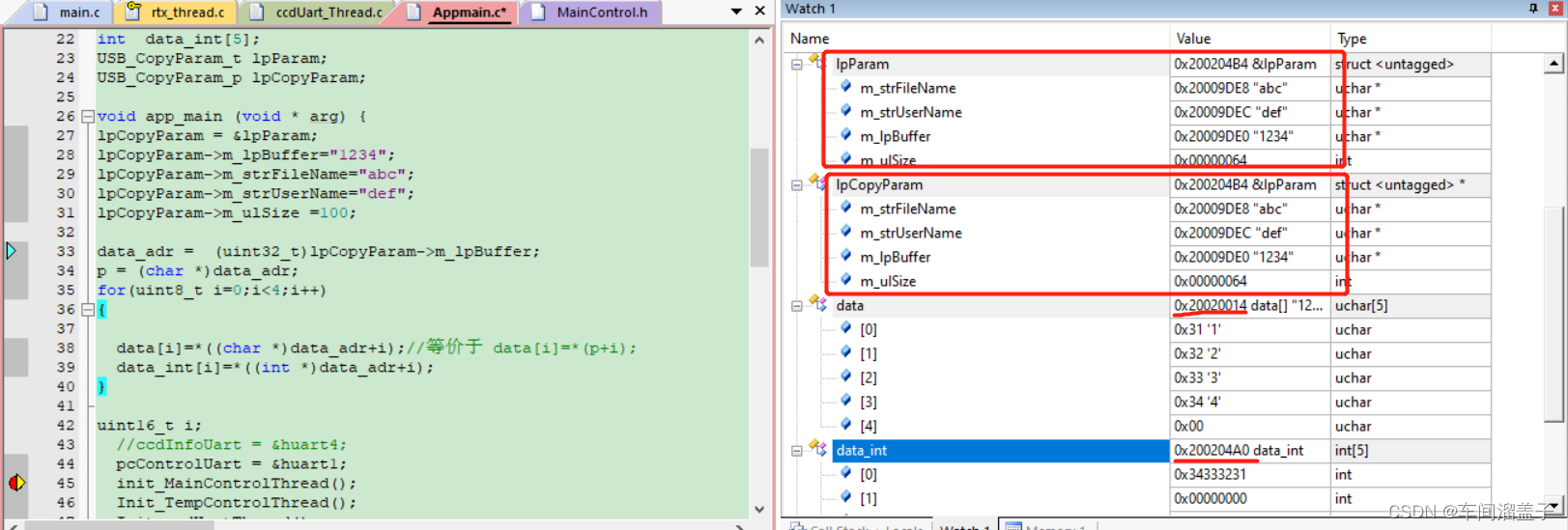
void app_main (void * arg) {
lpCopyParam = &lpParam;
lpCopyParam->m_lpBuffer="1234";//初始化,指针指向 "1234";等价于取"1234"的初始地址
lpCopyParam->m_strFileName="abc";//初始化,指针指向 "abc";等价于取"abc"的初始地址
lpCopyParam->m_strUserName="def";//初始化,指针指向 "def";等价于取"def"的初始地址
lpCopyParam->m_ulSize =100;
data_adr = (uint32_t)lpCopyParam->m_lpBuffer;//指针,里面的值实际上为地址
p = (char *)data_adr;
for(uint8_t i=0;i<4;i++)
{
data[i]=*((char *)data_adr+i);
//等价于 data[i]=*(p+i);
//等价于 data[i]=*((char *)(uint32_t)lpCopyParam->m_lpBuffer+i);
data_int[i]=*((int *)data_adr+i);
}
}
1.1 结构体指针赋值——使用typedef。
typedef struct
{
uint8_t* a;
uint16_t b;
uint16_t c;
uint8_t d;
uint8_t e[10];
char *f;
}CanCtrl_t1;
CanCtrl_t1 can1_ =
{
.b = 0xAABB,
.c = 0xCCDD,
.d = 0xff,
.e = {0,1,2,3,4,5,6,7,8,9},
.f = "hello world"
};

1.2 结构体指针赋值——使用struct 方式1
uint8_t mapbase;
char data[10]="hello";
struct CanCtrl_t1
{
uint8_t* a;
uint16_t b;
uint16_t c;
uint8_t d;
uint8_t e[10];
char *f;
};
struct CanCtrl_t1 can1_ =
{
#if 0
&mapbase,
0xAA,
0xCCDD,
0xff,
0,1,2,3,4,5,6,7,8,9,
&data[0],
#else
.a = &mapbase,
.b = 0xAA,
.c = 0xCCDD,
.d = 0xff,
.e = {0,1,2,3,4,5,6,7,8,9},
.f = data
#endif
};

1.3 结构体指针赋值——使用struct 方式2
uint8_t mapbase;
char data[10]="hello";
struct CanCtrl_t1
{
uint8_t* a;
uint16_t b;
uint16_t c;
uint8_t d;
uint8_t e[10];
char *f;
};
struct CanCtrl_t1 can1_ =
{
#if 1
&mapbase,
0xAA,
0xCCDD,
0xff,
0,1,2,3,4,5,6,7,8,9,
&data[0],
#else
.a = &mapbase,
.b = 0xAA,
.c = 0xCCDD,
.d = 0xff,
.e = {0,1,2,3,4,5,6,7,8,9},
.f = data
#endif
};

从上面结果可以看出方式1 方式2是一致的:
也就是说方式2中,数组直接给值是可行的。
1.4 结构体赋值举例
#define SRAMBANK 2 //定义支持的SRAM块数.
//内存管理控制器
struct _m_mallco_dev
{
void (*init)(uint8_t); //初始化 ,函数指针是指向函数的指针变量,uint8_t 为参数,返回值为 void
uint8_t (*perused )(uint8_t); //内存使用率,函数指针是指向函数的指针变量,uint8_t为参数,返回值为 uint8_t
uint8_t *membase[SRAMBANK]; //内存池 管理SRAMBANK个区域的内存,指针数组,数组的元素是指针类型,共n个元素
uint16_t *memmap [SRAMBANK]; //内存管理状态表, 指针数组,数组的元素是指针类型,共n个元素
uint8_t memrdy [SRAMBANK]; //内存管理是否就绪
};
void my_mem_init(uint8_t memx)
{
;
}
uint8_t my_mem_perused(uint8_t memx)
{
return 1;
}
uint8_t mem1base[2]={0x11,0x22};
uint8_t mem2base[2]={0x33,0x44};
uint16_t mem1mapbase[2]={0x55,0x66};
uint16_t mem2mapbase[2]={0x77,0x88};
struct _m_mallco_dev mallco_dev=
{
my_mem_init, //内存初始化
my_mem_perused, //内存使用率
mem1base,mem2base, //内存池
mem1mapbase,mem2mapbase, //内存管理状态表
0,0, //内存管理未就绪
};

1.5 空指针 void *
void *则为“无类型指针”,void *可以指向任何类型的数据。
void真正发挥的作用在于:
(1) 对函数返回的限定;
(2) 对函数参数的限定。
众所周知,如果指针p1和p2的类型相同,那么我们可以直接在p1和p2间互相赋值;如果p1和p2指向不同的数据类型,则必须使用强制类型转换运算符把赋值运算符右边的指针类型转换为左边指针的类型。
例如下则会报错:
float*p1;
int *p2;
p1 = p2;
其中p1 = p2语句会编译出错,提示“‘=’ : cannot convert from ‘int *’ to ‘float *’”,必须改为:
p1 = (float *)p2;
而void *则不同,任何类型的指针都可以直接赋值给它,无需进行强制类型转换:
void *p1;
int *p2;
p1 = p2;
但这并不意味着,void * 也可以无需强制类型转换地赋给其它类型的指针。因为“无类型”可以包容“有类型”,而“有类型”则不能包容“无类型”。道理很简单,我们可以说“男人和女人都是人”,但不能说“人是男人”或者“人是女人”。下面语句编译出错:
void *p1;
int *p2;
p2 = p1;
提示“‘=’ : cannot convert from ‘void *’ to ‘int *’”。
2、指针以及相互之间的强制转换
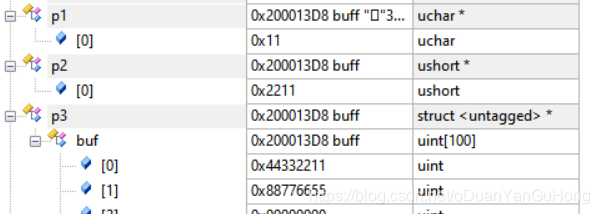
如下,结果如截图
typedef struct
{
unsigned int buf[100];
}BUFF;
uint8_t buff[10]={0x11,0x22,0x33,0x44,0x55,0x66,0x77,0x88};
uint8_t *p1; //p1指向uin8_t 类型的指针
uint16_t *p2; //p2指向uin16_t 类型的指针
BUFF *p3; //p3指向BUFF类型的指针
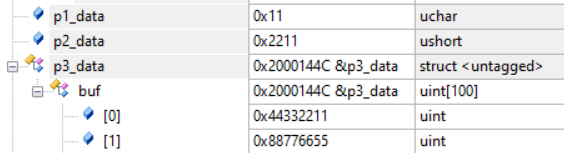
uint8_t p1_data;
uint16_t p2_data;
BUFF p3_data;
mian()
{
p1=&buff[0];
p2=(uint16_t*)&buff[0];
p3=(BUFF*)&buff[0];
p1_data = *p1;
p2_data = *p2;
p3_data = *p3;
}
再看一个代码:
typedef struct
{
unsigned int buf[100];
}BUFF_t;
#define US_SEND_BUF1 ((BUFF_t *) (0x2002C000))
BUFF_t BUFF1={0x11,0x22,0x33,0x44,0x55,0x66,0x77,0x88};
BUFF_t *p3;
void app_main (void const* arg)
{
p3 = &BUFF1;
US_SEND_BUF1[0] = *p3;
//US_SEND_BUF1[1] = *p3; //????
}
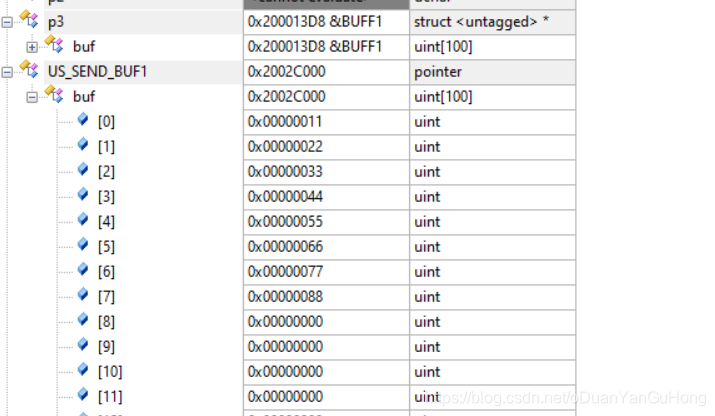
宏定义:#define US_SEND_BUF1 ((BUFF_t *) (0x2002C000))
US_SEND_BUF1 相当于指向 0x2002C000 地址的 BUFF_t 类型的指针
3、 函数指针和指针函数的区别
指针函数:
指针函数是指带指针的函数,即本质是一个函数。函数返回类型是某一类型的指针。
类型说明符 * 函数名(参数)
指针函数的写法
int *fun(int x,int y);
int * fun(int x,int y);
int* fun(int x,int y);
这个写法看个人习惯,其实如果*靠近返回值类型的话可能更容易理解其定义。
#include "stdio.h"
#include "stdlib.h"
int sum =0;
int *getAdd(int a, int b)
{
sum = a+b;
return &sum ;
}
int getDiff(int a, int b)
{
return a>b?(a-b):(b-a);
}
int main()
{
int *pTemp, Temp;
pTemp = getAdd(115,10);
printf("ADD result:%d\n", *pTemp);
Temp = getDiff(115,10);
printf("DIFF result:%d\n", Temp);
return 0;
}
char m_strVersion[VERSION_MAX_SIZE] = {0};
int GetDateMonth(const char* strDate)
{
if(strDate[2] == 'n')
{
if(strDate[1] == 'a')
return 1; //Jan
return 6; //Jun
}
if(strDate[2] == 'b')
return 2; //Feb
if(strDate[2] == 'r')
{
if(strDate[0] == 'M')
return 3; //Mar
return 4; //Apr
}
if(strDate[2] == 'y')
return 5; //May
if(strDate[2] == 'l')
return 7; //Jul
if(strDate[2] == 'g')
return 8; //Aug
if(strDate[2] == 'p')
return 9; //Sep
if(strDate[2] == 't')
return 10; //Oct
if(strDate[2] == 'v')
return 11; //Nov
return 12; //Dec
}
char* GetVersion(void)
{
if(m_strVersion[0] == 0)
{
strcpy(m_strVersion,"BYQ6A20 IOCTRL v1.0.0 RC");
const char* strDate = __DATE__;
int pos = strlen(m_strVersion);
//yyyy
for(int i = 0; i < 4; i++)
m_strVersion[pos+i] = strDate[7+i];
//MM
pos += 4;
int m = GetDateMonth(strDate);
m_strVersion[pos] = '0' + m / 10;
m_strVersion[pos+1] = '0' + m % 10;
//dd
pos += 2;
if(strDate[4] == ' ')
m_strVersion[pos] = '0';
else
m_strVersion[pos] = strDate[4];
m_strVersion[pos+1] = strDate[5];
pos += 2;
m_strVersion[pos] = 0;
}
return m_strVersion;//返回m_strVersion的指针(地址)
}
//调用
//char* version=NULL;
//if(version == NULL)
// version=GetVersion();
//Length=strlen(version);
函数指针:
函数指针是指向函数的指针变量,即本质是一个指针变量。
类型说明符 (*函数名)(参数)
typedef void (*pfun)(int data);
/*typedef的功能是定义新的类型。第一句就是定义了一种pfun的类型,并定义这种类型为指向某种函数的指针,这种函数以一个int为参数并返回void类型。*/
//把函数的地址赋值给函数指针,可以采用下面两种形式:
//fptr=&Function;
//fptr=Function;
//举例:
unsigned int max(unsigned int a,unsigned int b)
{
return a>b?a:b;
}
unsigned int (*f)(unsigned int ,unsigned int); //定义一个函数指针变量
f=max;//f=&max;
c=(*f)(1,2); //c=2
带结构体函数指针
struct DEMO
{
int x,y;
int (*func)(int,int); //函数指针
};
int add1(int x,int y)
{
return x*y;
}
int add2(int x,int y)
{
return x+y;
}
void main()
{
struct DEMO demo;
demo.func=add2; //结构体函数指针赋值
//demo.func=&add2; //结构体函数指针赋值
printf("func(3,4)=%d\n",demo.func(3,4));
demo.func=add1;
printf("func(3,4)=%d\n",demo.func(3,4));
}
/*
输出:
func(3,4)=7
func(3,4)=12
*/
typedef int (*Operation)(int a , int b );
typedef int (*Operation)(int a , int b );
typedef struct _str
{
int result ; // 用来存储结果
Operation opt; // 函数指针
} STR;
//a和b相加
int Add (int a, int b)
{
return a + b ;
}
//a和b相乘
int Multi (int a, int b)
{
return a * b ;
}
int main (int argc , char **argv)
{
STR str_obj;
str_obj.opt = Add; //函数指针变量指向Add函数
str_obj. result = str_obj.opt(5,3);
printf (" the result is %d\n", str_obj.result );
str_obj.opt= Multi; //函数指针变量指向Multi函数
str_obj. result = str_obj.opt(5,3);
printf (" the result is %d\n", str_obj.result );
return 0 ;
}
结构体中.和->两种访问区别
typedef struct // 定义一个结构体类型:DATA
{
char key[10]; // 结构体成员:key
char name[20]; // 结构体成员:name
int age; // 结构体成员:age
}DATA;
DATA data; // 声明一个结构体变量
DATA *pdata; // 声明一个指向结构体的指针
// 访问数据操作如下:
data.age = 24; // 结构体变量通过点运算符( . )访问
pdata->age = 24; // 指向结构体的指针通过箭头运算符( -> )访问
/******指针变量******
int*i;”为例,“*”表示这个变量是一个指针变量,而“int”表示这个变量只能存放 int 型变量的地址。
DATA *pdata;”为例,“*”表示这个变量是一个指针变量,而“DATA”表示这个变量只能存放 DATA型变量的地址。
******************/
函数指针列表
typedef void (*action_foo)() ;
struct state_action {
enum state m_state;//state_action为枚举指针类型
action_foo foo;//action_foo为函数指针类型,返回值为空
};
//函数指针列表
struct state_action state_action_map[state_num] =
{
{s_stop, do_stop},
{s_play, do_play},
{s_forward, do_forward},
{s_backward, do_backward},
{s_pause, do_pause},
{s_record, do_record}
};
3.1函数指针做函数参数的思想剖析
#define _CRT_SECURE_NO_WARNINGS
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
int myadd(int a, int b) //子任务的实现者
{
printf("func add() do...\n");
return a + b;
}
int myadd2(int a, int b) //子任务的实现者
{
printf("func add2() do...\n");
return a + b;
}
int myadd3(int a, int b) //子任务的实现者
{
printf("func add3() do...\n");
return a + b;
}
int myadd4(int a, int b) //子任务的实现者
{
printf("func add4() do...\n");
return a + b;
}
//定义了一个类型(函数指针类型)
typedef int(*MyTypeFuncAdd)(int a, int b);
//函数指针(本质是一个指针变量) 做 函数参数
int MainOp(MyTypeFuncAdd myFuncAdd)
{
int c = myFuncAdd(5, 6);
return c;
}
// int (*MyPointerFuncAdd)(int a, int b)
int MainOp2(int(*MyPointerFuncAdd)(int a, int b))
{
int c = MyPointerFuncAdd(5, 6); //间接调用
return c;
}
//间接调用
//任务的调用 和 任务的编写可以分开
void main()
{
MyTypeFuncAdd myFuncAdd = NULL;//myFuncAdd,定义一个指针,指向某一类的函数
myadd(1, 2); //直接调用
myFuncAdd = myadd;
myFuncAdd(3, 4); //间接调用
MainOp2(myadd);//等价于MainOp2(&myadd); 目的为了老版本的兼容性
MainOp(myadd);
//在mainop框架 没有发生任何变化的情况下 ...
MainOp(myadd2);
MainOp(myadd3);
MainOp(myadd4);
printf("hello...\n");
system("pause");
return;
}
函数指针类型起到的作用:
把函数的参数 和返回值提前做了约定;
4、 函数返回值为指针变量举例
void pcd4641_read_command(uint8_t axis_n,uint8_t commd,uint8_t *rev_regs)
{
uint8_t i=0;
static axis_sel_code_t axis_sel_code;
memset((void *)&axis_sel_code,0,sizeof(axis_sel_code_t));
axis_sel_code.area.axis = 1<<(axis_n%4);
axis_sel_code.area.type = General_Purpose_Read;
axis_sel_code.area.devcie = PCD4641_ID;//axis_n/4;
PCD4641_CS_LOW();
delay_us(100);
SPI4_ReadWriteByte(axis_sel_code.code);
delay_us(5);
SPI4_ReadWriteByte(commd);
for(i=0;i<3;i++)
{
delay_us(5);
rev_regs[i] = SPI4_ReadWriteByte(0xff);
}
PCD4641_CS_HIGH();
}
uint32_t axis_read_outstatus(uint8_t axis_n)
{
uint8_t rev_regs[3]={0,0,0};
uint32_t sta=0;
pcd4641_read_command(axis_n,ALL_STATUS,rev_regs);
sta = (((uint32_t)(rev_regs[2]))<<16) + (((uint32_t)(rev_regs[1]))<<8) + rev_regs[0];
return sta;
}
*uint8_t rev_regs
5、特别注意typdef 的用法:
原文(摘录):
typedef用来声明一个别名,typedef后面的语法,是一个声明。
网友理解:
typedef的作用:将声明变量得到的结果(变量名)提升为类型
typedef unsigned int UINT32; // UINT32 类型是unsigned int
UINT32 sum; // 定义一个变量:int sum;
typedef int arr[3]; // arr 类型是 int[3];(存放int型数据的数组)
arr a; // 定义一个数组:int a[3];
同理:
typedef void (*pfun)(void); // pfun 类型是 void(*)(void)
pfun main; // 定义一个函数:void (*main)(void);
typedef void (myTypeFunc)(int a,int b) ; //myTypeFunc 类型是 void()(int a,int b)
myPTypeFunc fp; //定义了一个 函数: void fp(int a,int b);
typedef void (*myTypeFunc)(int a,int b) ; //myTypeFunc 类型是 void(*)(int a,int b)
myPTypeFunc fp; //定义了一个 函数指针类型: void (*fp)(int a,int b);
根据网友理解:
1、变量名 UINT32 提升为类型,什么类型呢?UINT32 类型是unsigned int.
2、变量名 arr 提升为类型,什么类型呢?变量名类型 int[10]。
3、变量pfunc ,类型是 void(*)(void)
参考网友:https://blog.csdn.net/JUIU9527/article/details/127910852
typedef理解:
总结一句话:“加不加typedef,类型是一样的“,这句话可以这样理解:
没加typedef之前如果是个数组,那么加typedef之后就是数组类型;
没加typedef之前如果是个函数指针,那么加typedef之后就是函数指针类型;
没加typedef之前如果是个指针数组,那么加typedef之后就是指针数组类型;
一、给已定义的变量类型起个别名
typedef unsigned char uint8_t; //uint8_t就是unsigned char的别名,这是最基础的用法
struct __person
{
char name[20];
uint8_t age;
uint8_t height;
};
typedef __person person_t;
//以上两段代码也可合并为一段,如下:
typedef struct __person
{
char name[20];
uint8_t age;
uint8_t height;
}person_t;
作用是给struct __person起了个别名person_t,这种这种用法也很基础
二、定义函数指针类型
1、定义函数指针变量
① int (*pFunc)(char *frame, int len);
定义了一个函数指针变量pFunc,它可以指向这样的函数:返回值为int,形参为char*、int
② int *(*pFunc[5])(int len);
定义了5个函数指针变量:pFunc[0]、pFunc[1]···,它们都可以指向这样的函数:返回值为int*,形参为int
2、定义函数指针类型
定义函数指针类型,必须使用typedef,方法就是,在“定义函数指针变量”加上typedef。
typedef int (*pFunc_t)(char *frame, int len);//定义了一个类型函数指针pFunc_t
举例1:
typedef int (*pFunc_t)(char *frame, int len);//定义了一个类型pFunc_t
int read_voltage(char *data, int len)
{
int voltage = 0;
···//其他功能代码
return voltage;
}
int main(void)
{
pFunc_t pHandler = read_voltage;//使用类型pFunc_t来定义函数指针变量
···//其他功能代码
}
举例2:
typedef void (*EXECUTE_MV)(int duty);
typedef struct __tempctrlcore
{
int MV_out; /*最终输出*/
EXECUTE_MV ExecuteMVFunc; /*执行MV输出*/
}TEMP;
TEMP aHeat;
void aTec_Execute_MV(int duty)
{
// so something...
}
//初始化
void init(void)
{
aHeat.MV_out= 0;
aHeat.ExecuteMVFunc = aTec_Execute_MV;
}
//在某个函数里调用
void Temperature_Control(TEMP *t)
{
t->ExecuteMVFunc(t->MV_out);
}
//调用
Temperature_Control(&aHeat);
三、定义数组指针类型
① int(*pArr)[5]; //定义了一个数组指针变量pArr,pArr可以指向一个int [5]的一维数组
定义数组指针类型:
typedef int (*pArr_t)[5]; //定义了一个指针类型pArr_t,该类型的指针可以指向含5个int元素的数组
四、定义数组类型
int a[5]; //声明一个含5个int元素的一维数组
typedef int arr_t[5]; //定义了一个数组类型arr_t,该类型的变量是个数组
typedef int arr_t[5];//定义了一个数组类型arr_t,该类型的变量是个数组
int main(void)
{
arr_t d; //d是个数组,这一行等价于: int d[5];
arr_t b1, b2, b3;//b1, b2, b3都是数组
d[0] = 1;
d[1] = 2;
d[4] = 134;
d[5] = 253;//编译警告:下标越界
}
6、enum的用法
1、enum 枚举名 { 枚举值表 };
以下代码定义了这种新的数据类型 - 枚举型
enum weekday
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
};
(1) 枚举型是一个集合,集合中的元素(枚举成员)是一些命名的整型常量,元素之间用逗号,隔开。
(2) weekday 是一个标识符,可以看成这个集合的名字,是一个可选项,即是可有可无的项。
(3) 第一个枚举成员的默认值为整型的0,后续枚举成员的值在前一个成员上加1。
(4) 可以人为设定枚举成员的值,从而自定义某个范围内的整数。
(5) 枚举型是预处理指令#define的替代。
(6) 类型定义以分号;结束。
在枚举值表中应罗列出所有可用值。这些值也称为枚举元素。
例如:
该枚举名为weekday,枚举值共有7个,即一周中的七天。凡被说明为weekday类型变量的取值只能是七天中的某一天。
- 枚举变量的说明
如同结构和联合一样,枚举变量也可用不同的方式说明,即先定义后说明,同时定义说明或直接说明。
设有变量a,b,c被说明为上述的weekday,可采用下述任一种方式:
enum weekday{ sun,mou,tue,wed,thu,fri,sat };
enum weekday a,b,c;
或者为:
enum weekday{ sun,mou,tue,wed,thu,fri,sat }a,b,c;
或者为:
enum { sun,mou,tue,wed,thu,fri,sat }a,b,c;
3 typdef enum
方法三:用typedef关键字将枚举类型定义成别名,并利用该别名进行变量声明:
typedef enum workday
{
saturday,
sunday = 0,
monday,
tuesday,
wednesday,
thursday,
friday
} workday; //此处的workday为枚举型enum workday的别名
workday today, tomorrow; //变量today和tomorrow的类型为枚举型workday,即enum workday
也可以:
typedef enum
{
saturday,
sunday = 0,
monday,
tuesday,
wednesday,
thursday,
friday
} workday; //此处的workday为枚举型enum workday的别名
workday today, tomorrow; //变量today和tomorrow的类型为枚举型workday,即enum workday
也可以用这种方式:
typedef enum workday
{
saturday,
sunday = 0,
monday,
tuesday,
wednesday,
thursday,
friday
};
workday today, tomorrow; //变量today和tomorrow的类型为枚举型workday,即enum workday
7、sprintf的用法
描述
C 库函数 int sprintf(char *str, const char *format, …) 发送格式化输出到 str 所指向的字符串。
声明
下面是 sprintf() 函数的声明。
int sprintf(char *str, const char *format, …)
参数
str – 这是指向一个字符数组的指针,该数组存储了 C 字符串。
format – 这是字符串,包含了要被写入到字符串 str 的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化
返回值
如果成功,则返回写入的字符总数,不包括字符串追加在字符串末尾的空字符。如果失败,则返回一个负数
举例:
int Counter11;
void main_task (void * arg)
{
char Save_Temp[21];
FRESULT result;
rtc_t RTC_CurrentTime={0};
fatfs_test();
while(1)
{
osDelay(1000);
RTC_GetTime(&RTC_CurrentTime);
RTC_Date[0]=20;//世纪
RTC_Date[1]=RTC_CurrentTime.sdatestructure.Year; //年
RTC_Date[2]=RTC_CurrentTime.sdatestructure.Month; //月
RTC_Date[3]=RTC_CurrentTime.sdatestructure.Date; //日
RTC_Date[4]=RTC_CurrentTime.stimestructure.Hours; //时
RTC_Date[5]=RTC_CurrentTime.stimestructure.Minutes; //分
RTC_Date[6]=RTC_CurrentTime.stimestructure.Seconds; //秒
// sprintf(Save_Temp,"%02X%02X/%02X%/02X %02X:%02X:%02X\r\n",
Counter11=sprintf(Save_Temp,"%02d%02d/%02d/%02d %02d:%02d:%02d\r\n",
RTC_Date[0],
RTC_Date[1],
RTC_Date[2],
RTC_Date[3],
RTC_Date[4],
RTC_Date[5],
RTC_Date[6]);
result=SaveToSDcard((BYTE*)Save_Temp,sizeof(Save_Temp));
if(result == FR_OK)
{
LED1_Toggle();
}
else
{
LED0_ON();
}
printf("%02d/%02d/%02d ",2000 + RTC_Date[1], RTC_Date[2], RTC_Date[3]);
/* Display time Format : hh:mm:ss */
printf("%02d:%02d:%02d\r\n",RTC_Date[4], RTC_Date[5], RTC_Date[6]);
printf("\r\n");
}
}
结果:
十进制

16进制

举例2:
void main()
{
uint16_t sprintf_len=0;
char rep_Pack[100];
char version[]={"20230607 RC VER1.0"};
sprintf_len = sprintf(&rep_Pack[0],"1"); //sprintf_len = 1,rep_Pack="1"
sprintf_len = sprintf(&rep_Pack[0],"12"); //sprintf_len = 2,rep_Pack="12"
sprintf_len = sprintf(&rep_Pack[0],"123"); //sprintf_len = 3,rep_Pack="123"
sprintf_len = sprintf(&rep_Pack[0],"1234"); //sprintf_len = 4,rep_Pack="1234"
sprintf_len = sprintf(&rep_Pack[0],",%d,%d,%02x,%s",1,1,strlen(version),version);//sprintf_len = 26,rep_Pack=",1,1,12,20230607 RC VER1.0"
memset(rep_Pack,0,100);
sprintf_len = 0;
sprintf_len += sprintf(&rep_Pack[0]+sprintf_len,"1"); //sprintf_len = 1,rep_Pack="1"
sprintf_len += sprintf(&rep_Pack[0]+sprintf_len,"12"); //sprintf_len = 3,rep_Pack="112"
sprintf_len += sprintf(&rep_Pack[0]+sprintf_len,"123"); //sprintf_len = 6,rep_Pack="112123"
sprintf_len += sprintf(&rep_Pack[0]+sprintf_len,"1234");//sprintf_len = 10,rep_Pack="1121231234"
}
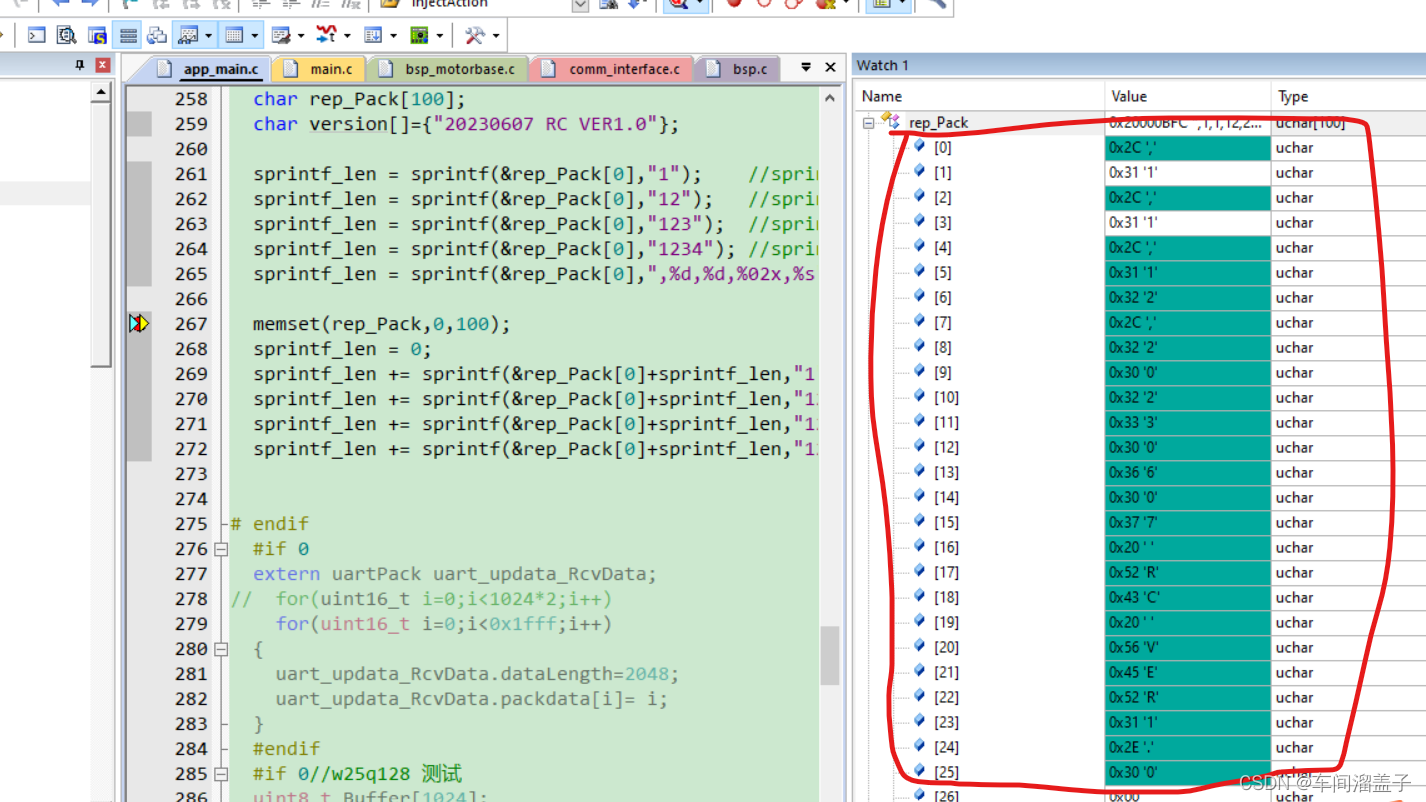
举例3: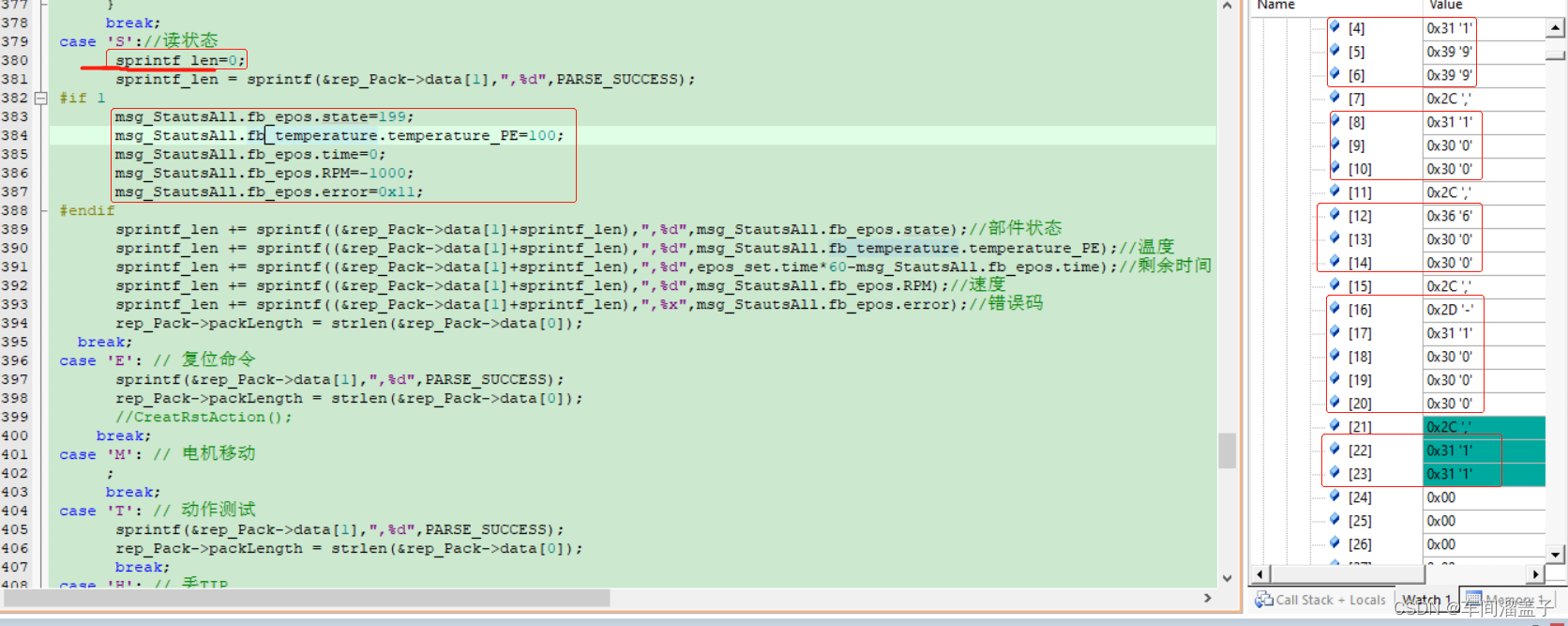
8、结构体位阈
内存对齐
无名位域(没有给出标识符名字),无名位域可用于填充内存布局,使得下一个位域内存分配边界对齐
typedef union
{
uint16_t value;
struct{
unsigned char x1: 2;
unsigned char x2: 2;
unsigned char : 0; /* 下一个位域在内存分配边界对齐 */
unsigned char x4: 2;
}sub;
} Bunch;
Bunch Bunch_Test;
void main(void)
{
Bunch_Test.sub.x1=2;
Bunch_Test.sub.x2=1;
Bunch_Test.sub.x4=2;
}

9、大端小端
大端模式与小端模式的区别
如下图,低地址中存放的是字数据的低字节,高地址存放的是字数据的高字节。所有STM32为小端模式
在协议里,使用大小端模式发送数据
MSB first:数据的最高位(MSB)首先被发送,然后依次发送其他位,直到最低位(LSB)
LSB first: 据的最低位(LSB)首先被发送,然后依次发送其他位,直到最高位(MSB)。
举例如下:
uint32_t a=0x11223344;
如果用发送LSB first,处理结果如下,然后发送:
发送第一个字节:0x44
发送第二个字节:0x33
发送第三个字节:0x22
发送第四个字节:0x11
接收后
data[4]={0x44,0x33,0x22,0x11};//因为单片机为小段模式所以 0x20001E6C: 44 33 22 11
如果用MSB first 模式发送,处理结果如下,然后发送:
发送第一个字节:0x11
发送第二个字节:0x22
发送第三个字节:0x33
发送第四个字节:0x44.
接收后
data[4]={0x11,0x22,0x33,0x44};//因为单片机为小段模式所以 0x20001E6C: 11 22 33 44
大小端数据转换
//16位 大小端转换
#define BSWAP_16(x) (uint16_t)((((uint16_t)(x) & 0x00ff) << 8) | (((uint16_t)(x) & 0xff00) >> 8))
//32位 大小端转换
#define BSWAP_32(x) (uint32_t)((((uint32_t)(x) & 0xff000000) >> 24) | (((uint32_t)(x) & 0x00ff0000) >> 8) | (((uint32_t)(x) & 0x0000ff00) << 8) | (((uint32_t)(x) & 0x000000ff) << 24))
10 与0异或 与1异或 与(&)
10.1 异或
如果a、b两个值不相同,则异或结果为1。如果a、b两个值相同,异或结果为0。
0^0 = 0,
1^0 = 1,
0^1 = 1,
1^1 = 0
一个值与0异或等于原来值
一个值与全1异或等于原来值取反
01010010
00000000 ^ 与0异或 为原来值
-------------
01010010
01010010
11111111 ^ 与全1异或 为取反值
-------------
10101101
10.2 与运算
0&0=0;0&1=0;1&0=0;1&1=1
即:两个同时为1,结果为1,否则为0
一个值与0 进行与运算,结果为0
一个值与全1运算,结果为原来值
01010010
00000000 & 与0与运算 结果为0
-------------
00000000
01010010
11111111 & 与1与运算 结果为原来值
-------------
01010010
10.3 取反
0变为1,1变为零。
0000 0010
取反为
111 1101
利用取反可将对应的位置零
a=0x33;//0011 0011
b &= ~ a;//将b的bit0 bit1 bit4 bit5置零
b &= ~ a 等价于 b &=1100 1100
运用:
#define BIT1 1<<1
#define BIT2 1<<2
#define BIT3 1<<3
#define BIT4 1<<4
//1、判断某一位是否为1
if(data&BIT1)
//2、判断某一位是否为0
if(!data&BIT1)
//3、某一位清零
a &= ~(1<<BITx)
//4、连续位清零
//把8位分为4组 bit0 bit1,bit2 bit3 ,bit4 bit5 ,bit6 bit7
//对第0组清零 //第一组 //第二组 //第三组
a &=~(3<<2*0); a &=~(3<<2*1);a &=(3<<2*2); a &=~(3<<2*3);
//5、对变量的某几位进行赋值
//同上,比如对第二组赋值‘01 b’
a |=(1<<2*2);
//6、对变量的某位取反
a ^=(1<<6);//异或运算
//bit 16~bit20 取反
tempdata ^=(0xf<<16);//bit 16~bit20 取反
11、二分法查找列表
/*
形参说明:
float cData:当前输入索引的数据
float pTab[]:所要索引的表(递减型),适用于NTC热敏电阻查表
unsigned char pTab_len:所要索引的表的长度
以上数据类型可依据实际表数据和表长度作更改
返回值:
返回当前输入索引的数据的位置
*/
uint16_t Find_Tab(double cData,double pTab[],uint16_t pTab_len)//
{
unsigned char tab_s=0; //索引表的起始位置
unsigned char tab_e; //索引表的结束位置
unsigned char tab_c=0; //索引表的当前位置
unsigned char k=0;
tab_e=pTab_len-1;//结束位置为表尾【即正常的下行索引方式】
if(pTab[tab_s]<=cData) //如果当前输入的数据大于当前表头
{
return tab_s; //则退出,并取表首位置作为函数返回值
}
else if(pTab[tab_e]>=cData) //如果当前输入的数据大于当前表尾
{
return tab_e;//则退出,并取表尾位置作为函数返回值
}
for(;tab_s<tab_e;)
{
tab_c=(tab_s+tab_e)/2; //取表中间位置为当前位置
if(pTab[tab_c]==cData) break;//若输入的索引数据正好等于当前表位置数据,则结束索引
if(pTab[tab_c]>cData&&cData>pTab[tab_c+1]) break; //若当前输入的索引数据在当前表位置临近数据区间内,则结束索引
if(cData>pTab[tab_c]) tab_e=tab_c;//若输入的索引数据大于当前索引表中位置的数据,则将当前表中的位置赋给表尾
else tab_s=tab_c;//反之赋给表首
if(k++>pTab_len) break;//若索引次数超过表长度,亦结束索引
}
if(tab_s>tab_e) return 0;//若表首位置大于表尾位置,则退出
return tab_c;//返回当前输入索引的数据的位置
}
/*
形参说明:
float cData:当前输入索引的数据
float pTab[]:所要索引的表(递增型) ,适用于PTC热敏电阻查表
unsigned char pTab_len:所要索引的表的长度
以上数据类型可依据实际表数据和表长度作更改
返回值:
返回当前输入索引的数据的位置
*/
uint16_t Find_Tab(double cData,double pTab[],uint16_t pTab_len)//
{
uint16_t tab_s=0; //索引表的起始位置
uint16_t tab_e; //索引表的结束位置
uint16_t tab_c=0; //索引表的当前位置
uint16_t k=0;
tab_e=pTab_len-1;//结束位置为表尾【即正常的下行索引方式】
if(pTab[tab_s] >= cData) //如果当前输入的数据小于当前表头
{
return tab_s; //则退出,并取表首位置作为函数返回值
}
else if(pTab[tab_e] <= cData) //如果当前输入的数据大于当前表尾
{
return tab_e;//则退出,并取表尾位置作为函数返回值
}
for(;tab_s<tab_e;)
{
tab_c=(tab_s+tab_e)/2; //取表中间位置为当前位置
if(pTab[tab_c]==cData) break;//若输入的索引数据正好等于当前表位置数据,则结束索引
if(pTab[tab_c]<cData&&cData<pTab[tab_c+1]) break; //若当前输入的索引数据在当前表位置临近数据区间内,则结束索引
if(cData>pTab[tab_c]) tab_s=tab_c;//若输入的索引数据大于当前索引表中位置的数据,则将当前表中的位置赋给表尾
else tab_e=tab_c;//反之赋给表首
if(k++>pTab_len) break;//若索引次数超过表长度,亦结束索引
}
if(tab_s>tab_e) return 0;//若表首位置大于表尾位置,则退出
return tab_c;//返回当前输入索引的数据的位置
}
12、解一元一次方程
/*************************************************
*函数名称:OneDimensionalEquation
*功 能:解一元一次方程 给出两点坐标和第三点的x值或y值 得出第三点y值或x值
*参 数:
*返 回 值:
*************************************************/
float OneDimensionalEquation(uint16_t x1,uint16_t y1,uint16_t x2,uint16_t y2,uint16_t Unkown_x,uint16_t Unkown_y)
{
float k = 0;
float b = 0;
k = (((int32_t)y1-(int32_t)y2)/((int32_t)x1-(int32_t)x2));
b = y1-x1*k;
if(0 == Unkown_x) //如果unknown_x设为0 就是求x的值 否则求y值
return ((float)Unkown_y-b)/k;
else
return ((float)Unkown_x*k+b);
}
13、四舍五入(三目运算)
三目运算符:
//三目运算符
<表达式1> ? <表达式2> : <表达式3>;
返回值:先求表达式 1 的值,如果为真,则执行表达式 2,并返回表达式 2 的结果;如果表达式 1 的值为假,则执行表达式 3,并返回表达式 3 的结果:
举例1\GPIO设置:
#define AMC7823_DOUT(n) (n?HAL_GPIO_WritePin(GPIOA,GPIO_PIN_6,GPIO_PIN_SET):HAL_GPIO_WritePin(GPIOA,GPIO_PIN_6,GPIO_PIN_RESET)) //Sdio
//AMC7823_DOUT(1);//置1
//AMC7823_DOUT(0);//置0
举例2\四舍五入:
#define ROUND_TO_UINT32(x) ((uint32_t)(x)+0.5f)>(x)? ((uint32_t)(x)):((uint32_t)(x)+1)
14、8bit 16bit 32bit之间的相互转换
//32bit ->16bit
void Uint32_to_uint16(int32_t *source,uint16_t *target,uint8_t len){
uint8_t tf_i;
for(tf_i=0;tf_i<len;tf_i++)
{
*(target+2*tf_i) = (*(source+tf_i))>>16;
*(target+2*tf_i+1)= (*(source+tf_i));
}
}
//8bit转32bit
uint32_t beBufToUint32(uint8_t *_pBuf)
{
return ( _pBuf[0] | ((uint32_t)_pBuf[1] << 8) | ((uint32_t)_pBuf[2] << 16) | ((uint32_t)_pBuf[3] << 24));
}
//其他同理
15、sizeof 与strlen区别
strlen( )
strlen( )求得的是字符串的长度
例如字符串 str[20]= {“abcd”};
strlen(str),结果为4
sizeof( )
sizeof( )计算字符串占的总内存空间
例如字符串 str[20]= “abcd”
sizeof(str),结果为20
举例2:如下
char encrypt[]="123456789";//25f9e794323b453885f5181f1b624d0b
uint8_t len=0;
// len = sizeof(encrypt);//10
len = strlen(encrypt);//9
因为字符串带一个字节结束符,所以字符 串长度+1等于sizeof(encrypt) 长度
16、关于flash或者SRAM赋值
typedef struct
{
unsigned char a[32];
uint8_t b[10];
uint16_t c[5];
}test_save_t;
#define test_save_stru ((test_save_t*) 0xc0008000)
#define test_save_u8 ((uint8_t*) 0xc0008000)
#define base_addr 0xc0008000
#define test_save_n(n) ((test_save_t*) (base_addr+n))
test_save_t File_data={
.a = "ABCDEFG",
.b ={0,1,2,3,4,5,6,7,8,9},
.c ={0x1122,0x3344,0x5566,0x7788,0x99aa}
};
volatile uint32_t Count_len;
volatile uint32_t offset=0;
void app_main (void const* arg)
{
uint8_t *point1,*point2;
uint16_t *point3,*point4;
uint16_t i,j;
test_save_t* point5;
point1 = (uint8_t*)&test_save_stru->a[0];//0xc0008000
point2 = (uint8_t*)&File_data.a[0];
for(uint16_t i=0;i<sizeof(test_save_t);i++)
{
*(point1+i) = *(point2+i);
__nop();
}
Count_len = sizeof(test_save_t); //Count_len=0x34
//情形1
Count_len = (uint32_t) test_save_stru; //Count_len=0xC008000
Count_len = (uint32_t)(test_save_stru+1); //Count_len=0xC008034
Count_len = (uint32_t)(test_save_stru+2); //Count_len=0xC008068
Count_len = (uint32_t)(test_save_stru+sizeof(test_save_t));//Count_len=0xC008A90 = 0xC008000+0x34*0x34
//情形2
Count_len = (uint32_t)(test_save_t*)0xc0008000; //Count_len=0xc0008000
Count_len = (uint32_t)((test_save_t*)0xc0008000+1); //Count_len=0xc0008034
Count_len = (uint32_t)((test_save_t*)0xc0008000+2); //Count_len=0xc0008068
Count_len = (uint32_t)((test_save_t*)0xc0008000+sizeof(test_save_t));//0xC008A90= 0xC008000+0x34*0x34
//情形3
point5 = test_save_stru;
Count_len = (uint32_t)point5; //Count_len=0xc0008000
Count_len = (uint32_t)(point5+1);//Count_len=0xc0008034
Count_len = (uint32_t)(point5+2);//Count_len=0xc0008068
Count_len = (uint32_t)(point5+sizeof(test_save_t));//0xC008A90
Count_len = (uint32_t)((test_save_t*)(0xc0008000)); //0xc0008000
Count_len = (uint32_t)((test_save_t*)(0xc0008000+1)); //0xc0008001
Count_len = (uint32_t)((test_save_t*)(0xc0008000+2)); //0xc0008002
Count_len = (uint32_t)((test_save_t*)(0xc0008000+sizeof(test_save_t)));//0xc0008034
Count_len = (uint32_t)test_save_u8; //Count_len=0xC008000
Count_len = (uint32_t)(test_save_u8+1); //Count_len=0xC008001
Count_len = (uint32_t)(test_save_u8+2); //Count_len=0xC008002
Count_len = (uint32_t)(test_save_u8+sizeof(test_save_t));//Count_len=0xC008034
//清空缓存
point1 = (uint8_t*)&test_save_stru->a[0];
for(j=0;j<20*sizeof(test_save_t);j++)
{
*(point1+j) = 0;
}
//0xc0008000开始 连续赋值File_data数据20组
//方式1
offset = 0;
for(j=0;j<20;j++)
{
point1 = (uint8_t*)&test_save_n(offset)->a[0];
point2 = (uint8_t*)&File_data.a[0];
for(i=0;i<sizeof(test_save_t);i++)
{
*(point1+i) = *(point2+i);
__nop();
}
offset = offset+sizeof(test_save_t);
}
//清空缓存
point1 = (uint8_t*)&test_save_stru->a[0];
for(j=0;j<20*sizeof(test_save_t);j++)
{
*(point1+j) = 0;
}
//方式2
offset = 0;
for(j=0;j<20;j++)
{
point3 = (uint16_t*)&test_save_n(offset)->a[0];
point4 = (uint16_t*)&File_data.a[0];
for(i=0;i<sizeof(test_save_t)/2;i++)
{
*(point3+i) = *(point4+i);
__nop();
}
offset = offset+sizeof(test_save_t);
}
//清空缓存
point1 = (uint8_t*)&test_save_stru->a[0];
for(j=0;j<20*sizeof(test_save_t);j++)
{
*(point1+j) = 0;
}
//方式3
for(j=0;j<20;j++)
{
point5 = test_save_stru+j;
*point5 = File_data;
__nop();
}

总结:
1、test_save_stru是指向test_save_t类型的指针,当test_save_stru+1时,指针偏移了sizeof(test_save_t);
2、情形1、情形2、情形3 类似
3、同理,test_save_u8是指向uint8_t类型的指针,当test_save_u8+1时,指针偏移了1。
4、地址连续赋值见上方式1、方式2、方式3。从方式1与方式2上可以看到,需要特别注意长度问题。
17 常量指针与指针常量
17.1 常量指针
指针常量是由英文pointer to const翻译而来的,看到英文,相信大家不会再搞不清楚它的意义,它代表着一个指向const类型变量的指针。
那么很明显,指针的指向是可以修改的,因为它只是个pointer,而指针指向的值是const,是不允许修改的。不能通过指针来修改它指向的内容,但是指针自身不是常量。
在C/C++中,常量指针是这样声明的:
1)const int *p;
2)int const *p;
const在前,星号在后;
如 int b, c;
int const *a;
a = &b;
a = &c;
都可以,唯独它指向的内容不能被修改。如:*a=20;这是违法的!错误!
17.2 指针常量
常量指针是由英文const pointer翻译而来的,const修饰的是pointer,说明指针是不可以修改的,因为pointer是常量,但指针指向的值是可以修改的。它指向的地址将伴其一生,直到生命周期结束
在C/C++中,指针常量这样声明:
int a;
int *const b = &a; //const放在指针声明操作符的右侧
星号在前,const在后。
int main()
{
//const pointer 常量指针
int a = 1;
int b = 2;
int *const p = &a;
*p = 2;
p = & b;//error 指针是一个常量,不可修改指向
}
辨别常量指针与指针常量
*现在举例子说明一下常量指针域指针常量到底如何区分。
1. int const* cur; 常量指针,指向常量的指针
2.Const int * cur; 常量指针,指向常量的指针
3. int*const cur; 指针常量
4. const(int *) cur; //错误,不可以这么写
18 指针与数组的关系
#define ADDR_FLASH_SECTOR_6 ((u32)0x08040000) //扇区6起始地址, 128 Kbytes
#define SDRAM_ADDR_START 0xc000A000 /*RAM起始地址*/
u32 *const SRAM_APP_BUF=(u32*)SDRAM_ADDR_START;//SRAM_APP_BUF指针常量
u32 point_1[1024];
void ReadFlashToRAM(u32 ReadAddr,u32 *const pBuffer,u32 NumToRead)
{
uint32_t i;
NumToRead = NumToRead>>2; //字节数转为32位字数
for(i=0;i<NumToRead;i++)
{
pBuffer[i]=STMFLASH_ReadWord(ReadAddr);
ReadAddr+=4;
#if 1
if(i<1024)
{
point_1[i] = (u32)&pBuffer[i];
__NOP();
}
#endif
}
__NOP();
}
void main()
{
//从FLASH拷贝数据到SDRAM
ReadFlashToRAM(ADDR_FLASH_SECTOR_6,SRAM_APP_BUF,1024*128);
}

从上面可以看出:
1、u32 *const pBuffer --> pBuffer[i],指针直接转换为了数组。
C 语言中规定,“数组名”是一个指针“常量”,表示数组第一个元素的起始地址。
2、指针常量的问题。常量类型,指向的地址是定值,不可通过cp改变指向地址,但地址中存的值可变。
指针与数组的关系
18.1 用指针引用数组元素
# include <stdio.h>
int main(void)
{
int a[] = {1, 2, 3, 4, 5};
int *p = &a[0];
int *q = a;
printf("*p = %d, *q = %d\n", *p, *q);
return 0;
}
输出结果是:
*p = 1, *q = 1
程序中定义了一个一维数组 a,它有 5 个元素,即 5 个变量,分别为 a[0]、a[1]、a[2]、a[3]、a[4]。所以 p=&a[0] 就表示将 a[0] 的地址放到指针变量 p 中,即指针变量 p 指向数组 a 的第一个元素 a[0]。**而 C 语言中规定,“数组名”是一个指针“常量”,表示数组第一个元素的起始地址。**所以 p=&a[0] 和 p=a 是等价的,所以程序输出的结果 *p 和 *q 是相等的,因为它们都指向 a[0],或者说它们都存放 a[0] 的地址。
那么 a[0] 的地址到底是哪个地址?“数组名表示的是数组第一个元素的起始地址”这句话是什么意思?“起始地址”表示的到底是哪个地址?
我们知道,系统给每个int型变量都分配了 4 字节的内存单元。数组 a 是 int 型的,所以数组 a 中每一个元素都占 4 字节的内存单元。而每字节都有一个地址,所以每个元素都有 4 个地址。那么 p=&a[0] 到底是把哪个地址放到了 p 中?
答案是把这 4 个地址中的第一个地址放到了 p 中。这就是“起始”的含义,即第一个元素的第一字节的地址。我们将“数组第一个元素的起始地址”称为“数组的首地址”。数组名表示的就是数组的首地址,即数组第一个元素的第一字节的地址。
注意,数组名不代表整个数组,q=a 表示的是“把数组 a 的第一个元素的起始地址赋给指针变量 q”,而不是“把数组 a 的各个元素的地址赋给指针变量 q”。
18.2 指针的移动
那么如何使指针变量指向一维数组中的其他元素呢?比如,如何使指针变量指向 a[3] 呢?
同样可以写成 p=&a[3]。但是除了这种方法之外,C 语言规定:如果指针变量 p 已经指向一维数组的第一个元素,那么 p+1 就表示指向该数组的第二个元素。
注意,p+1 不是指向下一个地址,而是指向下一个元素。“下一个地址”和“下一个元素”是不同的。比如 int 型数组中每个元素都占 4 字节,每字节都有一个地址,所以 int 型数组中每个元素都有 4 个地址。如果指针变量 p 指向该数组的首地址,那么“下一个地址”表示的是第一个元素的第二个地址,即 p 往后移一个地址。而“下一个元素”表示 p 往后移 4 个地址,即第二个元素的首地址。下面写一个程序验证一下:
# include <stdio.h>
int main(void)
{
int a[] = {1, 2, 3, 4, 5};
int *p = a;
printf("p = %d, p + 1 = %d\n", p, p+1); //用十进制格式输出
printf("p = %#X, p + 1 = %#X\n", p, p+1); //也可以用十六进制格式输出
printf("p = %p, p + 1 = %p\n", p, p+1); //%p是专门输出地址的输出控制符
return 0;
}
输出结果是:
p = 1638196, p + 1 = 1638200
p = 0X18FF34, p + 1 = 0X18FF38
p = 0018FF34, p + 1 = 0018FF38
我们看到,p+1 表示的是地址往后移 4 个。但并不是所有类型的数组 p+1 都表示往后移 4 个地址。p+1 的本质是移到数组下一个元素的地址,所以关键是看数组是什么类型的。比如数组是 char 型的,每个元素都占一字节,那么此时 p+1 就表示往后移一个地址。所以不同类型的数组,p+1 移动的地址的个数是不同的,但都是移向下一个元素。
知道元素的地址后引用元素就很简单了。如果 p 指向的是第一个元素的地址,那么 *p 表示的就是第一个元素的内容。同样,p+i 表示的是第 i+1 个元素的地址,那么 (p+i) 就表示第 i+1 个元素的内容。即 p+i 就是指向元素 a[i] 的指针,(p+i) 就等价于 a[i]。
下面写一个程序验证一下:
# include <stdio.h>
int main(void)
{
int a[] = {1, 2, 3, 4, 5};
int *p, *q, *r;
p = &a[3]; //第一种写法
printf("*p = %d\n", *p);
q = a; //第二种写法
q = q + 3;
printf("*q = %d\n", *q);
r = a; //第三种写法
printf("*(r+3) = %d\n", *(r+3));
return 0;
}
输出结果是:
*p = 4
*q = 4
*(r+3) = 4
注意,*(q+i) 两边的括号不能省略。因为 *q+i 和 (q+i)是不等价的。指针运算符“”的优先级比加法运算符“+”的优先级高。所以 *q+i 就相当于 (*q)+i 了。
前面讲过,指针和指针只能进行相减运算,不能进行乘、除、加等运算。所以不能把两个地址加起来,这是没有意义的。所以指针变量只能加上一个常量,不能加上另一个指针变量。
那么现在有一个问题:“数组名 a 表示数组的首地址,a[i] 表示的是数组第 i+1 个元素。那么如果指针变量 p 也指向这个首地址,可以用 p[i] 表示数组的第 i 个元素吗?”可以。下面写一个程序看一下:
# include <stdio.h>
int main(void)
{
int a[] = {1, 2, 3, 4, 5};
int *p = a;
printf("p[0] = %d\n", p[0]);
printf("p[1] = %d\n", p[1]);
printf("p[2] = %d\n", p[2]);
printf("p[3] = %d\n", p[3]);
printf("p[4] = %d\n", p[4]);
return 0;
}
输出结果是:
p[0] = 1
p[1] = 2
p[2] = 3
p[3] = 4
p[4] = 5
所以 p[i] 和 *(p+i) 是等价的,即“指向数组的”指针变量也可以写成“带下标”的形式。
那么反过来,因为数组名 a 表示的也是数组的首地址,那么元素 a[i] 的地址也可以用 a+i 表示吗?回答也是“可以的”。也就是说如果指针变量 p 指向数组 a 的首地址,那么 p+i 和 a+i 是等价的,它们可以互换。下面也写一个程序验证一下:
# include <stdio.h>
int main(void)
{
int a[] = {2, 5, 8, 7, 4};
int *p = a;
printf("*(p+3) = %d, *(a+3) = %d\n", *(p+3), *(a+3));
return 0;
}
输出结果是:
*(p+3) = 7, *(a+3) = 7
这时有人说,a 不是指针变量也可以写成“”的形式吗?只要是地址,都可以用“地址”表示该地址所指向的内存单元中的数据。而且也只有地址前面才能加“”。因为指针变量里面存放的是地址,所以它前面才能加“”。
*实际上系统在编译时,数组元素 a[i] 就是按 (a+i) 处理的。即首先通过数组名 a 找到数组的首地址,然后首地址再加上i就是元素 a[i] 的地址,然后通过该地址找到该单元中的内容。
所以 a[i] 写成 *(a+i) 的形式,程序的执行效率会更高、速度会更快。因为在执行程序的时候数组是先计算地址,然后转化成指针。而直接写成指针 *(a+i) 的形式就省去了这些重复计算地址的步骤。
18.3 指针变量的自增运算
前面说过,p+1 表示指向数组中的第二个元素。p=p+1 也可以写成 p++ 或 ++p,即指针变量也可以进行自增运算。当然,也可以进行自减运算。自增就是指针变量向后移,自减就是指针变量向前移。下面给大家写一个程序:
# include <stdio.h>
int main(void)
{
int a[] = {2, 5, 8, 7, 4};
int *p = a;
printf("*p++ = %d, *++p = %d\n", *p++, *++p);
return 0;
}
输出结果是:
*p++ = 5, *++p = 5
因为指针运算符“*”和自增运算符“++”的优先级相同,而它们的结合方向是从右往左,所以 *p++ 就相当于 (p++),++p 就相当于 *(++p)。但是为了提高程序的可读性,最好加上括号。
在程序中如果用循环语句有规律地执行 ++p,那么每个数组元素就都可以直接用指针指向了,这样读取每个数组元素时执行效率就大大提高了。为什么?比如:
int a[10] = {0};
int *p = a;
如果执行一次 ++p,那么此时 p 就直接指向元素 a[1]。而如果用 a[1] 引用该元素,那么就先要计算数组名 a 表示的首地址,然后再加 1 才能找到元素 a[1]。同样再执行一次 ++p,p 就直接指向元素 a[2]。而如果用 a[2] 引用该元素,那么还要先计算数组名 a 表示的首地址,然后再加 2 才能找到元素 a[2]……
所以,用数组的下标形式引用数组元素时,每次都要重新计算数组名 a 表示的首地址,然后再加上下标才能找到该元素。而有规律地使用 ++p,则每次 p 都是直接指向那个元素的,不用额外的计算,所以访问速度就大大提高了。数组长度越长这种差距越明显!所以当有大批量数据的时候,有规律地使用 ++p 可以大大提高执行效率。
在前面讲数组时写过这样一个程序:
# include <stdio.h>
int main(void)
{
int a[5] = {1, 2, 3, 4, 5};
int i;
for (i=0; i<5; ++i)
{
printf("%d\n", a[i]);
}
return 0;
}
输出结果是:
1
2
3
4
5
用指针的方法实现一下:
# include <stdio.h>
int main(void)
{
int a[] = {1, 2, 3, 4, 5};
int *p = NULL; //先初始化, 好习惯
for (p=a; p<(a+5); ++p)
{
printf("%d\n", *p);
}
return 0;
}
输出结果是:
1
2
3
4
5
指针还可以用关系运算符比较大小,使用关系运算符来比较两个指针的值的前提是两个指针具有相同的类型。
既然 p+i 和 a+i 等价,那么能不能写成 a++?答案是“不能”。在前面讲自增和自减的时候强调过,只有变量才能进行自增和自减,常量是不能进行自增和自减的。a 代表的是数组的首地址,是一个常量,所以不能进行自增,所以不能写成a++。
下面再来写一个程序,编程要求:实现从键盘输入 10 个整数,然后输出最大的偶数,要求使用指针访问数组。
# include <stdio.h>
int main(void)
{
int a[10] = {0};
int *p = a;
int max;
int i; //循环变量
int flag = 1; //标志位
printf("请输入十个整数:");
for (i=0; i<10; ++i)
{
scanf("%d", p+i); //不要用&p[i], 不要出现数组的影子
}
for (; p<a+10; ++p)
{
if (0 == *p%2)
{
if (flag) //将第一个偶数赋给max;
{
max = *p;
flag = 0;
}
else if (*p > max) //寻找最大的偶数
{
max = *p;
}
}
}
if (!flag) /*这句很经典, 如果flag一直都是1, 那么说明没有一个是偶数*/
{
printf("最大的偶数为:%d\n", max);
}
else
{
printf("未发现偶数\n");
}
return 0;
}
输出结果是:
请输入十个整数:-33 -26 15 38 74 59 31 -2 27 36
最大的偶数为:74
18.4 两个参数确定一个数组
# include <stdio.h>
void Output(int *p, int cnt); //声明一个输出数组的函数
int main(void)
{
int a[] = {1, 2, 3, 4, 5};
int b[] = {-5, -9, -8, -7, -4};
Output(a, 5);
Output(b, 5);
printf("\n");
return 0;
}
/*定义一个输出数组的函数*/
void Output(int *p, int cnt) /*p用来接收首地址, cnt用来接收数组元素的个数*/
{
int *a = p;
for (; p<(a+cnt); ++p) //数组地址作为循环变量
{
printf("%d ", *p);
}
}
输出结果是:
1 2 3 4 5 -5 -9 -8 -7 -4
程序中,之所以要传递数组的长度是因为在 C 语言中没有一个特殊的标记可以作为数组的结束标记。因为数组是存储数据的,任何数据都可以存到数组中,所以数组里面任何一个值都是有效的值。不仅是C语言,任何一门语言都无法用某一个值作为数组结束的标记。所以“数组长度”这个参数是必需的。
上面这个程序是以“数组地址”作为被调函数的循环变量,也可以改成以“数组个数”作为被调函数的循环变量:
# include <stdio.h>
void Output(int *p, int cnt); //声明一个输出数组的函数
int main(void)
{
int a[] = {1, 2, 3, 4, 5};
int b[] = {-5, -9, -8, -7, -4};
Output(a, 5);
Output(b, 5);
printf("\n");
return 0;
}
/*定义一个输出数组的函数*/
void Output(int *p, int cnt) /*p用来接收首地址, cnt用来接收数组元素的个数*/
{
int i;
for (i=0; i<cnt; ++i) //数组元素个数作为循环变量
{
printf("%d ", *(p+i));
}
}
输出结果是:
1 2 3 4 5 -5 -9 -8 -7 -4
18.5 指针变量占多少字节
我们讲过,指针变量根据“基类型”的不同有 int* 型、float* 型、double* 型、char* 型等。但是前面在讲数据类型的时候讲过,int 型变量占 4 字节,float 型变量占 4 字节、double 型变量占 8 字节、char 型变量占 1 字节。那么“指针型变量”占几字节?是不是基类型占几字节,该指针变量就占几字节?同样,用 sizeof 写一个程序看一下就知道了:
# include <stdio.h>
int main(void)
{
int *a = NULL;
float *b = NULL;
double *c = NULL;
char *d = NULL;
printf("%d %d %d %d\n", sizeof(a), sizeof(b), sizeof(c), sizeof(d));
return 0;
}
输出结果是:
4 4 4 4
可见,不管是什么基类型,系统给指针变量分配的内存空间都是 4 字节。在 C 语言中,只要是指针变量,在内存中所占的字节数都是 4。指针变量的“基类型”仅用来指定该指针变量可以指向的变量类型,并没有其他意思。不管基类型是什么类型的指针变量,它仍然是指针变量,所以仍然占 4 字节。
我们前面讲过,32 位计算机有 32 根地址线,每根地址线要么是 0 要么是 1,只有这两种状态。内存单元中的每个地址都是由这 32 根地址线通过不同的状态组合而成的。而 4 字节正好是 32 位,正好能存储下所有内存单元的地址信息。少一字节可能就不够,多一字节就浪费,所以是 4 字节。
19 const基础知识
int main()
{
const int a;
int const b;
const int *c;
int * const d;
const int * const e ;
return 0;
}
Int func1(const )
初级理解:const是定义常量==》const意味着只读
含义:
//第一个第二个意思一样 代表一个常整形数
//第三个 c是一个指向常整形数的指针(所指向的内存数据不能被修改,但是本身可以修改)
//第四个 d 常指针(指针变量不能被修改,但是它所指向内存空间可以被修改)
//第五个 e一个指向常整形的常指针(指针和它所指向的内存空间,均不能被修改)
Const好处
//合理的利用const,
//1指针做函数参数,可以有效的提高代码可读性,减少bug;
//2清楚的分清参数的输入和输出特性
int setTeacher_err( const Teacher *p)
Const修改形参的时候,在利用形参不能修改指针所向的内存空间
20 undef用法
#undef 标识符,用来将前面定义的宏标识符取消定义。
#include <stdio.h>
int main()
{
#define MAX 200
printf("MAX = %d\n", MAX);
#undef MAX
int MAX = 10;
printf("MAX = %d\n", MAX);
return 0;
}
21 #pragma pack() 和 __packed
1、#pragma pack作用
主要作用就是改变编译器的内存对齐方式,在网络报文的处理有重要的作用。基本用法:#pragma pack(n) ,不使用这条指令,采取默认的字节对齐方式(#pragma pack(8)) n可以取(1, 2, 4, 8, 16)。
2、#pragma pack(1)
设置结构体的边界对齐为1个字节,也就是所有数据在内存中是连续存储的.
例如:
#pragma pack(1)
struct sample
{
char a;
double b;
};
#pragma pack()
注:若不用#pragma pack(1)和#pragma pack()括起来,则sample按编译器默认方式对齐(成员中size最大的那个)。即按8字节(double)对齐,则sizeof(sample)==16.成员char a占了8个字节(其中7个是空字节);
若用#pragma pack(1),则sample按1字节方式对齐sizeof(sample)==9.(无空字节),比较节省空间啦,有些场和还可使结构体更易于控制。
3、__packed
__packed是字节对齐的意思;
__packed 是一种 ℃ 语言中的关键字,用于声明一个结构体或联合体。使用_packed 可以使得结构体或联合体的大小尽可能的小,这样可以节省空间,特别是在嵌入式系统中,空间通常是非常宝贵的资源。
优点:
__packed 的优点是它使得结构体或联合体的大小尽可能的小。这是因为_packed 会尝试将结构体或联合体的成员尽可能地紧密排列在一起,从而减少空间浪费。这对于嵌入式系统来说尤其有用,因为这些系统通常具有有限的存储空间。
缺点:
__packed 也有一些缺点。首先,它可能导致结构体或联合体的对齐问题。因为_packed 会尝试将成员紧密排列在一起,这可能会导致某些成员的位置不是它们大小的整数倍。
typedef union tagDATA_T
{
__packed struct frame_t
{
unsigned short start;
unsigned short len;
unsigned char cmd;
unsigned char data[595];
}frame;
unsigned char buf[600];
} DATA_T, *P_DATA_T;
22 小数的相关运算
运算前整型必须强制转换成浮点型
#define PI ((double) 3.14159)
//圆柱模型,根据洗液量,计算移动距离
//输入:uint32_t volume 单位0.1ul,uint16_t D为直径 单位 0.1mm (1ul=1mm^3)
//输出:返回移动距离,单位0.01mm
uint32_t calcAsorbPosition(uint32_t volume,uint16_t D)
{
float h_mm;
float r;
r=(float)D/20;
h_mm = ((float)volume/10)/PI/r/r;
return (h_mm*100);
}
23 #if defined…#elif defined…#endif
//#define TRIGGLE_DEBUG //PD 间隔闪烁连续读取数据(调试)
//#define COMM_DEBUG //虚拟打印通讯过程(调试)
#define DDC_DEBUG //正常工作只打印荧光数据(调试)
#if defined(TRIGGLE_DEBUG)
#define USER_REAL_PORT //使用真实串口打印
#define PRINTF_DDC //打印 PD采集数据(调试使用)
#elif defined(COMM_DEBUG)
#undef USER_REAL_PORT //使用虚拟串口打印
#define PRINTF_USART_TX_RX //打印串口收发数据(调试使用)
#elif defined(DDC_DEBUG)
#define USER_REAL_PORT //使用真实串口打印
#define PRINTF_DDC //打印 PD采集数据(调试使用)
#else
#endif

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)