Dify数据库导出知识库
如果只需要导出分段,直接导出即可。
·
1.Dify 的数据库表结构
Dify 的知识库数据主要存储在以下几个核心表中(不同版本可能略有差异):
| 表名 | 说明 |
|---|---|
datasets |
存储知识库(数据集)的元信息,如 id, name, created_at 等。 |
documents |
存储文档的基本信息,如 id, dataset_id, name, status 等。 |
document_segments |
存储文档的分块内容(向量化处理的文本片段),包含实际文本和向量数据。 |
2.查询语句
(1)查询所有知识库列表
SELECT id, name, description, created_at
FROM datasets;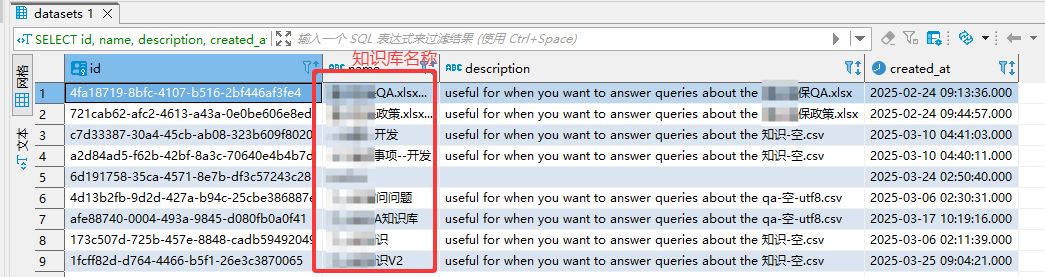
(2)查询某个知识库下的所有文档
SELECT id, name, indexing_status, created_at
FROM documents
WHERE dataset_id = '173c507d-725b-457e-8848-cadb59492049'; -- 替换为实际的 dataset_id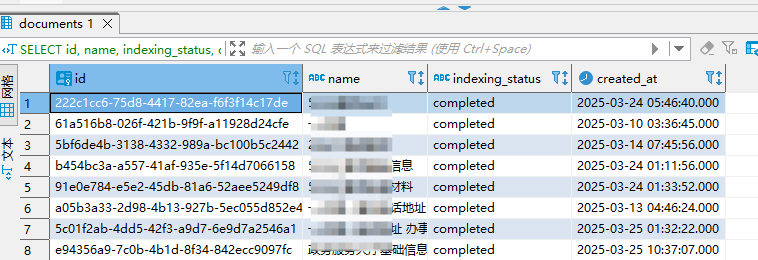
(3)查询文档的原始内容(分块文本)
SELECT ds.content, ds.answer
FROM document_segments ds
JOIN documents d ON ds.document_id = d.id
WHERE d.dataset_id = '173c507d-725b-457e-8848-cadb59492049';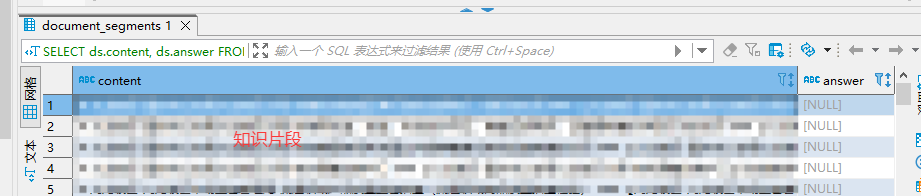
如果只需要导出分段,直接导出即可
(4)导出知识库完整内容(文档 + 分块文本)
SELECT
d.name AS document_name,
ds.content AS text_chunk
FROM documents d
JOIN document_segments ds ON d.id = ds.document_id
WHERE d.dataset_id = '173c507d-725b-457e-8848-cadb59492049';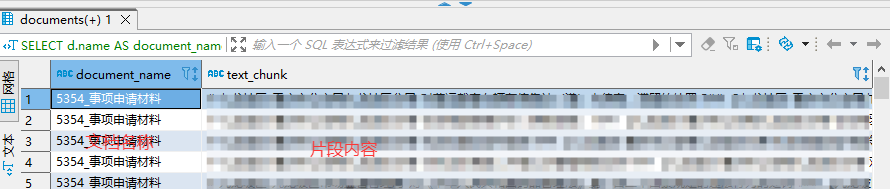
3.python导出(另外一种方法)
import psycopg2 # 如果是 PostgreSQL
# import pymysql # 如果是 MySQL(取消注释并替换 psycopg2)
import csv
from datetime import datetime
def export_knowledge_to_csv(db_config, dataset_id, output_csv):
"""
从 Dify 数据库导出知识库内容到 CSV
:param db_config: 数据库连接配置
:param dataset_id: 目标知识库 ID (如 'dataset-xxx')
:param output_csv: 输出 CSV 文件路径 (如 'knowledge_export.csv')
"""
try:
# 连接数据库
conn = psycopg2.connect(**db_config)
cursor = conn.cursor()
# 查询知识库名称(用于 CSV 头部信息)
cursor.execute("SELECT name FROM datasets WHERE id = %s", (dataset_id,))
dataset_name = cursor.fetchone()[0] if cursor.rowcount > 0 else 'Unknown'
# 查询文档及分块内容
# query = """
# SELECT
# d.name AS document_name,
# ds.content AS text_chunk,
# LENGTH(ds.content) AS char_count,
# d.created_at AS doc_created_time
# FROM documents d
# JOIN document_segments ds ON d.id = ds.document_id
# WHERE d.dataset_id = %s
# ORDER BY d.created_at, d.name
# """
#只导出某个文档片段
query = """
SELECT
d.name AS document_name,
ds.content AS text_chunk,
ds.answer AS answer,
LENGTH(ds.content) AS char_count,
d.created_at AS doc_created_time
FROM documents d
JOIN document_segments ds ON d.id = ds.document_id
WHERE d.dataset_id = %s and d.id='33104412-xxx'#替换成你的文档id
ORDER BY d.created_at, d.name
"""
cursor.execute(query, (dataset_id,))
rows = cursor.fetchall()
# 写入 CSV
with open(output_csv, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
# 写入元数据标题
writer.writerow([f"Knowledge Base Export - {dataset_name}", f"Export Time: {datetime.now()}"])
writer.writerow([]) # 空行分隔
# 写入数据列标题
writer.writerow(["Document Name", "Text Chunk","answer", "Character Count", "Created Time"])
for row in rows:
# 清理文本中的换行符(避免 CSV 格式混乱)
cleaned_text = row[1].replace('\n', ' ').replace('\r', ' ')
writer.writerow([row[0], cleaned_text, row[2], row[3]])
print(f"成功导出 {len(rows)} 条记录到 {output_csv}")
except Exception as e:
print(f"导出失败: {str(e)}")
finally:
if 'cursor' in locals(): cursor.close()
if 'conn' in locals(): conn.close()
# 使用示例
if __name__ == "__main__":
# 数据库配置(根据实际修改)
db_config = {
"host": "192.168.xx.xx",
"database": "dify",
"user": "xx",
"password": "xxxx",
"port": 5432 # PostgreSQL 默认端口
}
export_knowledge_to_csv(
db_config=db_config,
dataset_id="afe88740-0004-493a-xxxxxx", # 替换为你的知识库 ID
output_csv="dify_knowledge_export.csv"
)导出的结果如下:


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)