【2024-12-30分享】影刀RPA高级考试操作题2 源码分享
【分享】影刀高级考试操作题2 源码分享
·
完整源码:https://hyk416.cn/archives/HqnEUzAW https://hyk416.cn/archives/HqnEUzAW
https://hyk416.cn/archives/HqnEUzAW
原题目
进入这个网站:点击访问,获取排行榜中所有电影的相关数据(具体字段参考下面的要求明细),并存入指定数据库中。
要求如下:
- 数据库信息:IP:43.143.30.32 端口号:3306 用户名:yingdao 密码:9527 库名:ydtest 表名:movies(注意,该>数据库只开放了写入权限,无法查询)
- 字段及数据格式参考(多名导演用英文逗号分隔开,提交人为影刀学院用户名!位于学院首页右上角):
- 元素对象都要使用xpath表达式获取(禁止使用【批量数据抓取】指令)
- 使用编码版完成所有操作
- 该网站具备反爬虫机制,频繁发送请求可能导致访问被禁止

测试结果
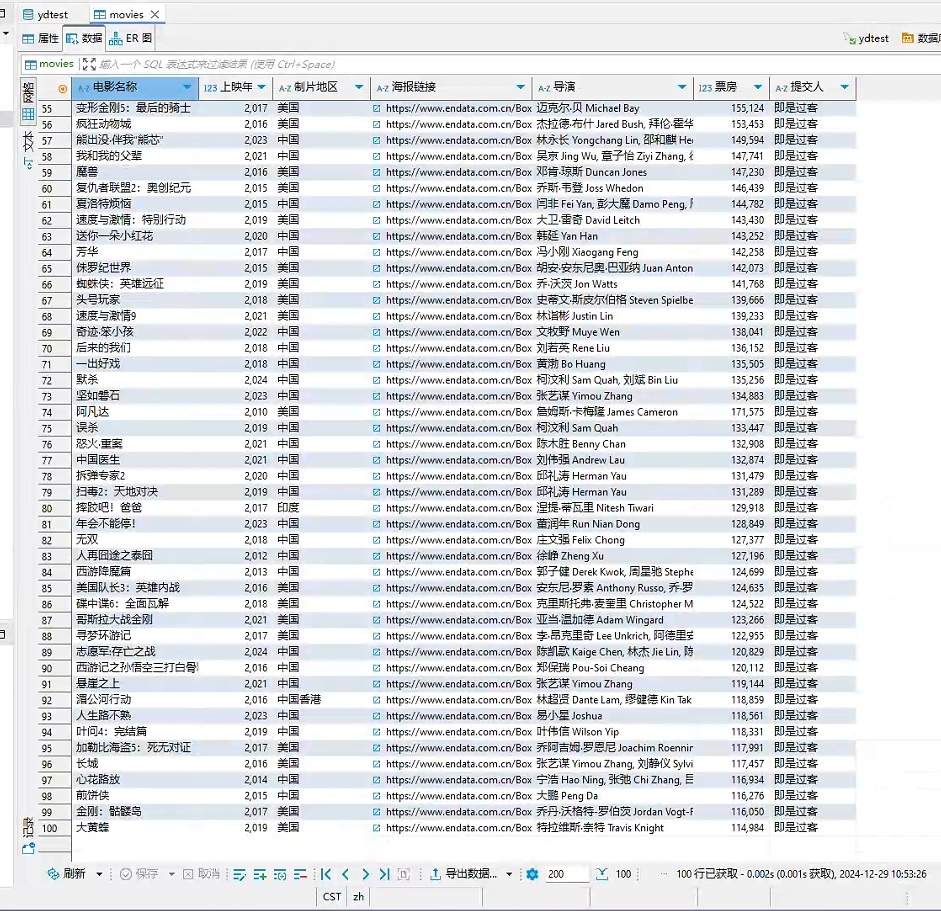
Python代码
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
# 使用方法
# 安装pymysql包
# 主流程使用“调用模块”指令,选择Python模块,选择函数“main”,传入参数submitter(影刀学院用户名),执行即可
# 题目中的网站具备反爬虫机制,不建议访问过快,可在代码最后一行调整随机停顿时间范围
# URL:https://hyk416.cn/archives/HqnEUzAW
# GuoKe - 过客
# 2024-12-28 9:59:04
import xbot
from xbot import print, sleep
from .package import variables as glv
import time
import pymysql
import re
from xbot import web
import random
def get_directors(web_dg):
"""获取导演信息,如果有多个导演,使用英文逗号分隔"""
directors = []
try:
director_elements = web_dg.find_all_by_xpath('//dt[text()="导演"]/following-sibling::dd[not(preceding-sibling::dt[text()="演员"])]')
for element in director_elements:
if element and element.get_text():
directors.append(element.get_text().strip())
except Exception as e:
print(f"获取导演信息时发生错误: {e}")
return ', '.join(directors)
def format_data(data):
"""格式化数据以符合数据库字段类型"""
name, release_year, production_area, poster_link, director, box_office, submitter = data
# 转换数据类型
try:
release_year = int(release_year)
except (ValueError, TypeError):
release_year = 0 # 或者其他默认值
# 处理票房单位
if isinstance(box_office, str):
box_office = box_office.strip()
if '万' in box_office:
box_office = box_office.replace('万', '')
try:
box_office = round(float(box_office), 0) # 四舍五入到整数
except (ValueError, TypeError):
box_office = 0 # 或者其他默认值
elif '亿' in box_office:
box_office = box_office.replace('亿', '')
try:
box_office = round(float(box_office) * 10000, 0) # 四舍五入到整数
except (ValueError, TypeError):
box_office = 0 # 或者其他默认值
else:
try:
box_office = round(float(box_office.replace(',', '')), 0) # 四舍五入到整数
except (ValueError, TypeError):
box_office = 0 # 或者其他默认值
else:
box_office = 0 # 如果不是字符串,默认设置为0
return (name, release_year, production_area, poster_link, director, int(box_office), submitter)
def main(submitter):
mydb = None
mycursor = None
web_page = None
web_dg = None
try:
# 创建数据库连接
mydb = pymysql.connect(
host="43.143.30.32",
port=3306,
user="yingdao",
password="9527",
database="ydtest",
charset='utf8'
)
mycursor = mydb.cursor()
# SQL插入语句,使用参数化查询
sql = """
INSERT INTO movies (电影名称, 上映年份, 制片地区, 海报链接, 导演, 票房, 提交人)
VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
# 打开首页
web_page = xbot.web.create(url="https://www.endata.com.cn/BoxOffice/BO/History/Movie/Alltimedomestic.html")
random_sleep()
while True:
# 获取当前页的所有电影链接
quanbu = web_page.find_all_by_xpath('//tbody/tr/td/a')
if not quanbu:
print("未找到电影链接")
break
for dys in quanbu:
if not dys:
continue
movie_url = 'https://www.endata.com.cn' + dys.get_attribute('href')
web_dg = xbot.web.create(url=movie_url)
random_sleep()
# 完整代码:https://hyk416.cn/archives/HqnEUzAW
# 完整代码:https://hyk416.cn/archives/HqnEUzAW
# 完整代码:https://hyk416.cn/archives/HqnEUzAW
# 完整代码:https://hyk416.cn/archives/HqnEUzAW
# 完整代码:https://hyk416.cn/archives/HqnEUzAW

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)