Ollama-OCR 只需几行代码,轻松实现高质量文字识别!
Llama 3.2-Vision 是一种多模态大型语言模型,有 11B 和 90B 两种大小,能够处理文本和图像输入,生成文本输出。该模型在视觉识别、图像推理、图像描述和回答图像相关问题方面表现出色,在多个行业基准测试中均优于现有的开源和闭源多模态模型。本文将介绍开源的[1] 工具,它默认使用本地运行的视觉模型,可准确识别图像中的文字,同时保留原始格式。在开始使用 Llama 3.2-Vision
Llama 3.2-Vision 是一种多模态大型语言模型,有 11B 和 90B 两种大小,能够处理文本和图像输入,生成文本输出。该模型在视觉识别、图像推理、图像描述和回答图像相关问题方面表现出色,在多个行业基准测试中均优于现有的开源和闭源多模态模型。
本文将介绍开源的 ollama-ocr[1] 工具,它默认使用本地运行的 Llama 3.2-Vision 视觉模型,可准确识别图像中的文字,同时保留原始格式。
https://github.com/bytefer/ollama-ocr
Ollama-OCR 的特点
- 使用 Llama 3.2-Vision 模型进行高精度文本识别 保留原始文本格式和结构
- 支持多种图像格式:JPG、JPEG、PNG
- 可定制的识别提示和模型
- Markdown 输出格式选项
Llama 3.2-Vision 应用场景
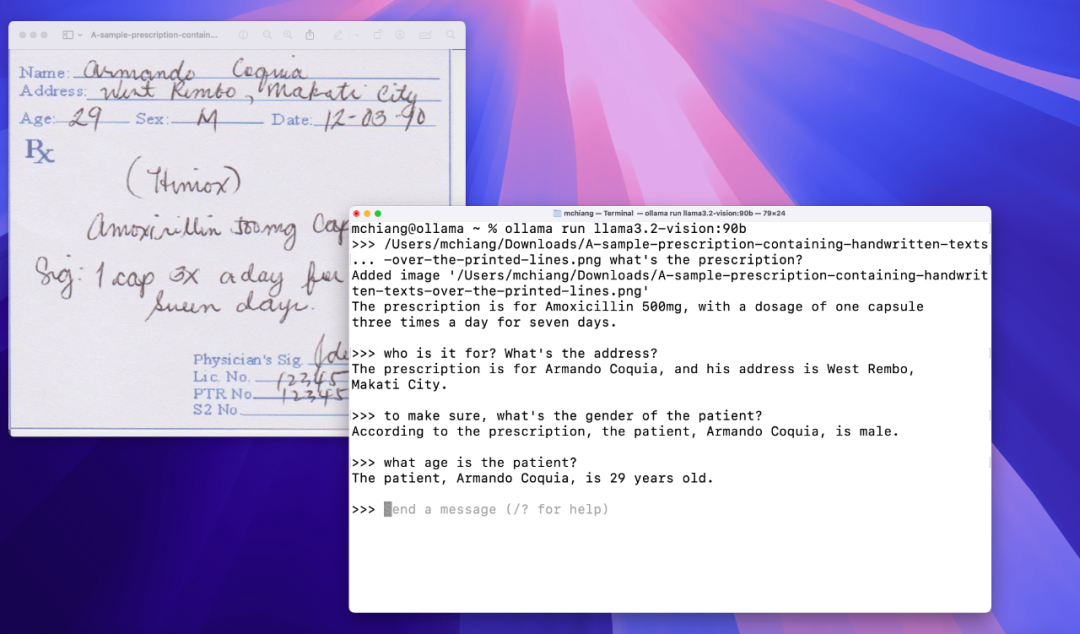
识别手写文本
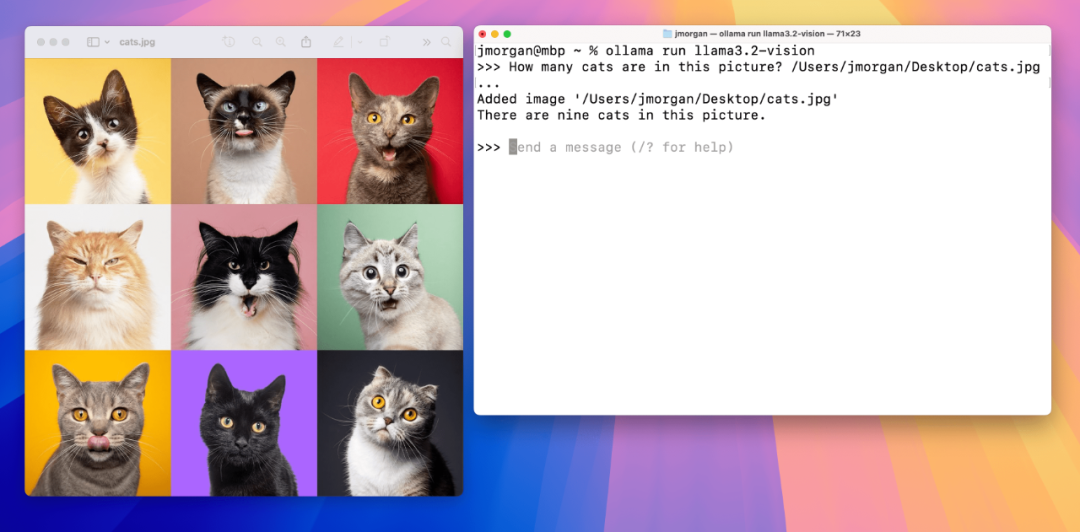
OCR 识别
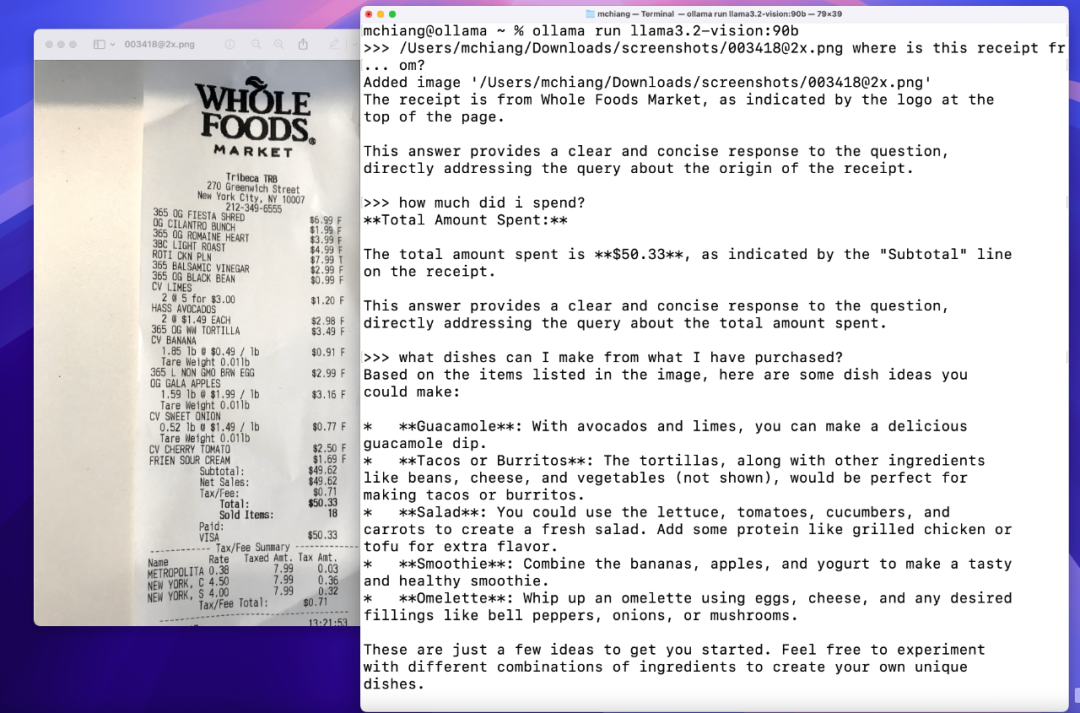
图片问答
配置环境
安装 Ollama
在开始使用 Llama 3.2-Vision 之前,您需要安装 Ollama[2],这是一个支持在本地运行多模态模型的平台。请按照以下步骤安装:
\1. 下载 Ollama:访问 Ollama 官方网站,下载适用于您操作系统的安装包。
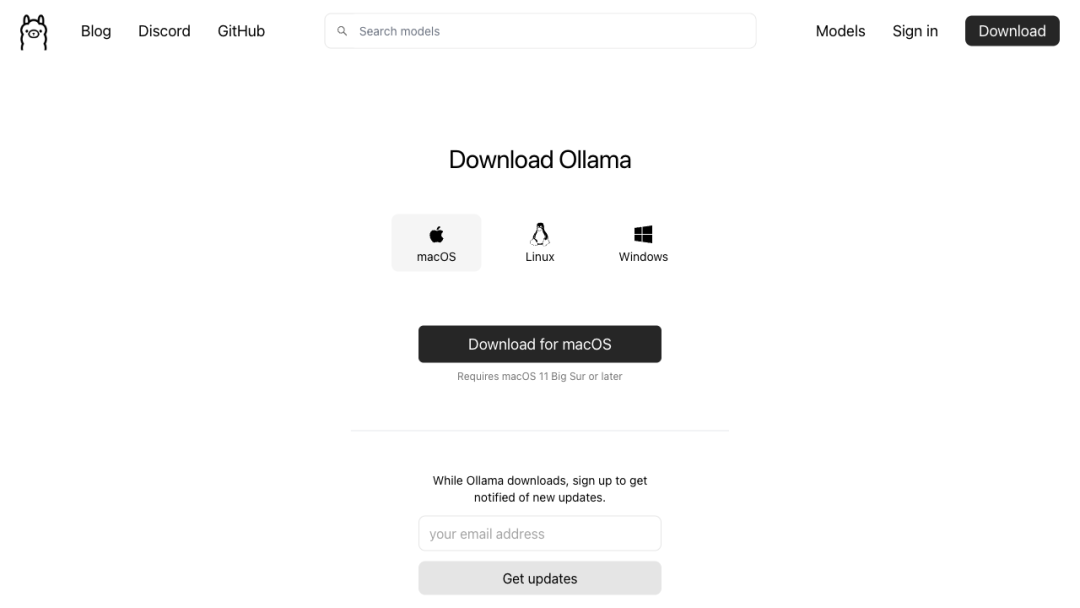
\2. 安装 Ollama:根据下载的安装包,按照提示完成安装。
安装 Llama 3.2-Vision 11B
安装 Ollama 后,可使用以下命令安装 Llama 3.2-Vision 11B[3]:
ollama run llama3.2-vision
安装 Ollama-OCR
npm install ollama-ocr
# or using pnpm
pnpm add ollama-ocr
使用 Ollama-OCR
OCR
import { ollamaOCR, DEFAULT_OCR_SYSTEM_PROMPT } from "ollama-ocr";
async function runOCR() {
const text = await ollamaOCR({
filePath: "./handwriting.jpg",
systemPrompt: DEFAULT_OCR_SYSTEM_PROMPT,
});
console.log(text);
}
测试的图片如下:

输出的结果如下:
The Llama 3.2-Vision collection of multimodal large language models (LLMs) is a collection of instruction-tuned image reasoning generative models in 118 and 908 sizes (text + images in / text out). The Llama 3.2-Vision instruction-tuned models are optimized for visual recognition, image reasoning, captioning, and answering general questions about an image. The models outperform many of the available open source and closed multimodal models on common industry benchmarks.
输出 Markdown
import { ollamaOCR, DEFAULT_MARKDOWN_SYSTEM_PROMPT } from "ollama-ocr";
async function runOCR() {
const text = await ollamaOCR({
filePath: "./trader-joes-receipt.jpg",
systemPrompt: DEFAULT_MARKDOWN_SYSTEM_PROMPT,
});
console.log(text);
}
测试的图片如下:

输出的结果如下:
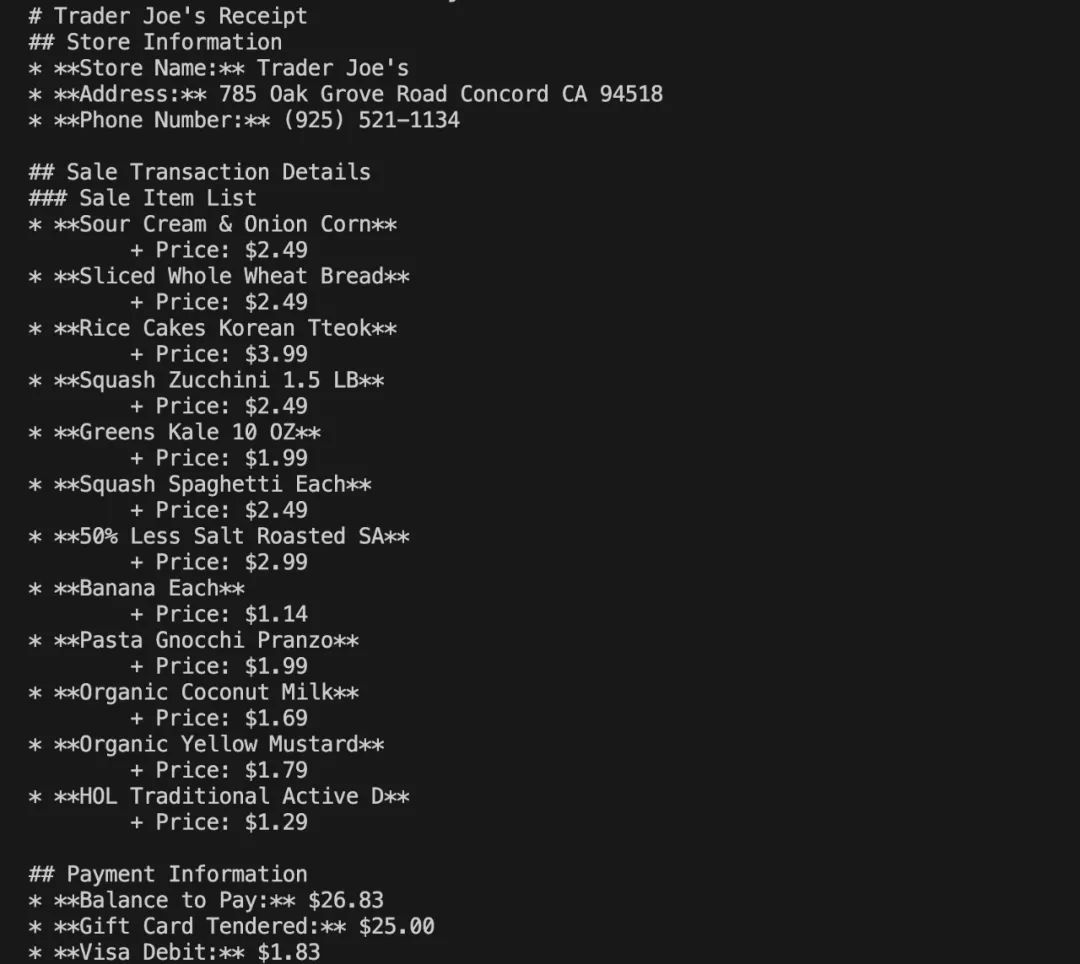
ollama-ocr 使用的本地的视觉模型,如果你想使用线上的 Llama 3.2-Vision 模型,可以试试 llama-ocr[4] 这个库。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 21
21 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)