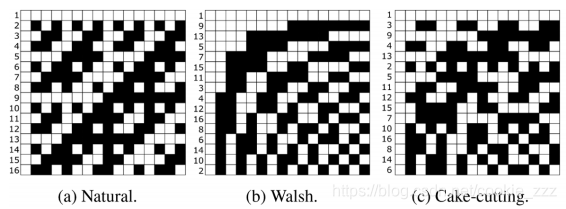
一般哈达玛矩阵、沃尔什矩阵及CC哈达玛矩阵的生成
最近看了一篇文章《Image quality of compressive single-pixel imaging using different Hadamard orderings》,不同的哈达玛ji
最近看了一篇文章《Image quality of compressive single-pixel imaging using different Hadamard orderings》,不同的哈达玛排列方式可以实现更低采样率的重建。

文章验证了这四种哈达玛排列形式在低采样率下的重建结果,(b)和(d)其实是一种排列形式,只是分别表示低频和高频。下图展示结果:


验证结果是在低采样率的条件下C的重建效果最好,b次之,最原始的哈达玛排列效果更差一些。b和c其实也是在之前的两篇文章 1-《An Improved Hadamard Measurement Matrix Based on Walsh Code For Compressive Sensing》和 2-《Super sub-Nyquist single-pixel imaging by means of cake-cutting Hadamard basis sort》中介绍的两种方法。
哈达玛矩阵在matlab里可以通过函数 hadamard 直接生成。walsh矩阵和’切蛋糕‘(cake-cutting)矩阵其实都可以在原始哈达玛矩阵的基础上调换行顺序得到。关于walsh-hadamard矩阵的生成,网上只是能找到关于理论的部分,很复杂。在文章 1 里边作者提供了生成沃尔什矩阵的简单方法:

就是先根据所要生成矩阵的大小,确定格雷码位数,要生成的walsh矩阵的每一行, 要把格雷码倒序排列,转换成十进制数,那么哈达玛矩阵的这一行就是对应walsh矩阵的行。 例如,生成8×8大小的walsh矩阵,对应格雷码位数为3, 那么walsh矩阵的第一行,对应格雷码(000),倒序排列之后为(000)对应十进制的 1 ,那么walsh矩阵的第一行就是同样大小哈达玛矩阵的第1行;walsh矩阵的第二行,对应格雷码(001),倒序排列之后为(100)对应十进制的 5 ,那么walsh矩阵的第二行就是对应哈达玛矩阵的第5行依次类推即可。下边为matlab程序:
function w=walsh(m)
N=log2(m);
x=hadamard(m);
walsh=zeros(m);
graycode=gen_gray_code(N);
nh1=zeros(m,N);
for i=1:m
q=graycode(i,:);
nh=0;
for j=N:-1:1
nh1(i,j) =q(j)*2^(j-1);
end
nh=sum(nh1(i,:));
walsh(i,:)=x(nh+1,:);
end
w=walsh;
end其中的有一个生成格雷码的函数:
function gray_code=gen_gray_code(N)
sub_gray=[0;1];
for n=2:N
top_gray=[zeros(1,2^(n-1))' sub_gray];
bottom_gray=[ones(1,2^(n-1))' sub_gray];
bottom_gray=bottom_gray(end:-1:1,:);
sub_gray=[top_gray;bottom_gray];
end
gray_code=sub_gray;
end第二篇文章介绍的‘切蛋糕’哈达玛矩阵,作者发现,如果哈达玛矩阵中包含的连接区域(蛋糕块)越少,其对应的测量值可能更高,因此会包含更多的信息。所以作者的思路是 先把大的哈达玛矩阵的每一行拿出来重新排列为方阵,再根据每一个方阵所包含连接区域的多少由小到大进行排列,根据这个顺序将哈达玛矩阵的每一行重新排列即可得到cake-cutting哈达玛矩阵了。

下边是程序:
function ch=cchdm(m)
N=log2(m);
x=hadamard(m);
a=sqrt(m);b=a;
cchdmm=zeros(m);
for i=1:m
row=reshape(x(i,:),[a,b]);
num1=0;num2=0;
for j=1:a-1
if row(1,j)~= row(1,j+1);
num1=num1+1;
end
if row(j,1)~=row(j+1,1)
num2=num2+1;
end
num(i)=(num1+1)*(num2+1);
end
end
[B,index]=sort(num);
for k=1:m
cchdmm(k,:)=x(index(k),:);
end
ch=cchdmm;
end
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)