PDF转markdown,AI知识库绝配,科研文献整理必备,MinerU将PDF转化为机器可读格式的工具
视频版:PDF转markdown,AI知识库绝配,科研文献整理必备,MinerU将PDF转化为机器可读格式的工具这是一个开源免费的PDF解析神器,MinerU。它可以把PDF转换成可以编辑的Markdown格式,其中的图片、表格、数学公式等都可以精确提取。它还可以转化提取扫描类的PDF文档。MinerU可以把PDF图片等转换成AI大模型容易理解的数据,所以它跟AI知识库(RAG)是绝配。我们先来简
视频版:
PDF转markdown,AI知识库绝配,科研文献整理必备,MinerU将PDF转化为机器可读格式的工具
这是一个开源免费的PDF解析神器,MinerU。它可以把PDF转换成可以编辑的Markdown格式,其中的图片、表格、数学公式等都可以精确提取。它还可以转化提取扫描类的PDF文档。MinerU可以把PDF图片等转换成AI大模型容易理解的数据,所以它跟AI知识库(RAG)是绝配。我们先来简单看一下MinerU的技术原理,还有如何免费在官网使用。最后来演示下如何在自己的电脑上部署这个工具。
MinerU处理PDF主要有以下四个环节:
分类预处理:主要读取PDF的元数据信息,从而区分PDF类型。
内容提取:则可以看作是许多个AI大模型组成的流水线。
- 布局检测:主要任务是定位文档中不同元素的位置。这里使用的模型主要是微调过的LayoutLMv3模型。
- 公式检测:用来定位文档中的公式位置。这里使用的是基于YOLOv8的自研模型。
- 公式识别,主要任务是识别公式图像,并且把它转换成了Latex的源码。这里使用的是项目自研的公式识别模型。
- OCR,也就是对于扫描版的PDF,提取图像中的文本内容。这里使用的是百度飞桨OCR。
- 表格识别,这里使用的开源项目是RapidTable
处理管线: 将模型解析得到的数据输入到处理管线中,然后进行处理。
结果质检:可以使用可视化的质检工具与人工的标注进行对比

如何快速使用MinerU
这里可以上传一个PDF文件,或者是Word还有PPT文件。如果PDF文件是扫描版的,我们需要把这个OCR识别勾上,然后上传一个文件。
我们可以点击右上角的下载,把对应的Markdown文件下载下来。
我们使用在线工具转换有几个问题。首先是Markdown里面的图片,它是一个网络图片,并没有真正的下载下来。第二个问题是表格,并没有真正识别出来,而是把它变成了一张图片。第三个问题是使用网页版,这里有一定的限制,最多200兆或者600页。如果想解决这些问题的话,我们可以本地部署。
本地部署
视频的后半段,我会详细介绍如何本地部署这么一个项目。这里我想补充一下,如果是简单的PDF操作的话,我们可以使用这个在线工具PDF24,大部分工作都可以在线直接完成。不过他的ORC肯定要差一些,毕竟MinerU是专业的。
Conda安装
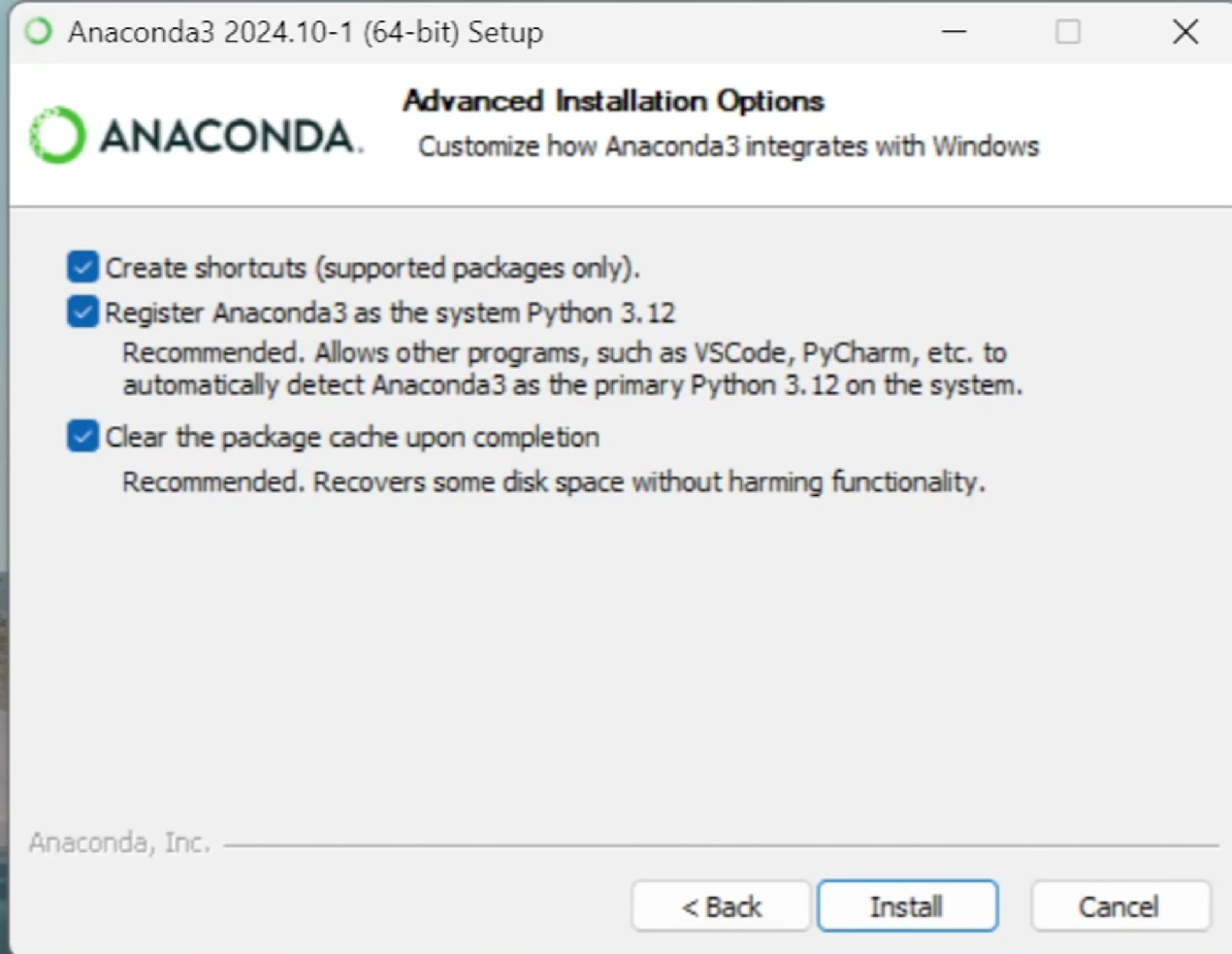
这是一个Python项目,它的部署前提是电脑上需要先安装一个Conda,然后使用Conda创建Python的虚拟环境。我们进入这个地址repo.anaconda.com,这里有一个installer,我们点击一下,找到自己操作系统的最新版本,把它下载下来。我是Windows系统,我下载这个X86_64的。下载完成以后,我们把它安装一下,这里一直点击下一步,到这一步,把这三个勾都选上,然后点击安装。
安装MinerU
在搜索栏搜索 Anaconda Prompt 打开, conda的命令行

这里我们先执行,先创建一个Python 3.10的名字叫MinerU的Conda的虚拟环境。然后切换到这个虚拟环境,安装Python依赖。
conda create -n MinerU python=3.10
conda activate MinerU
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com -i https://mirrors.aliyun.com/pypi/simple安装模型文件
pip install modelscope
curl -o download_models.py https://gitee.com/myhloli/MinerU/raw/master/scripts/download_models.py
python download_models.py我大约花了十几分钟,总共下载了两个模型,加起来有2.5个GB左右。模型放到了这个目录下面。
C:\Users\xxxxx\.cache\modelscope\hub\xxxxxxxxxxx
如果我们不想使用这模型了,直接把它删掉就可以了。
测试MinerU
好,我们来测试一下。我把测试文件放到了桌面上,然后我把目录切换到桌面。我们使用这个命令magic-pdf -p 参数输入PDF的路径,这里我复制文件地址粘贴过来。接下来是-o指定一个输出文件夹,这里我叫做output。最后是-m指定一个方法,这里我使用auto就是自动。
magic-pdf -p "C:\\Users\xxxx\Desktop\demo.pdf" -o output -m auto
然后我们回车,大约用了5分钟,处理完成了一个13页的PDF文档。如果开启了GPU加速的话,速度会快很多。处理完成以后,我的桌面就多了一个output文件夹。本地部署的话,它会把图片都放到一个相邻的目录里面。
表格识别
我们可以通过修改配置,开启它的表格识别功能,把表格也变成Markdown格式的表格。
这里我们进入这个地址C:\\Users\xxxx\magic-pdf.json 。进来以后,主要修改这个table-config这一行,把这里的enable改成true。
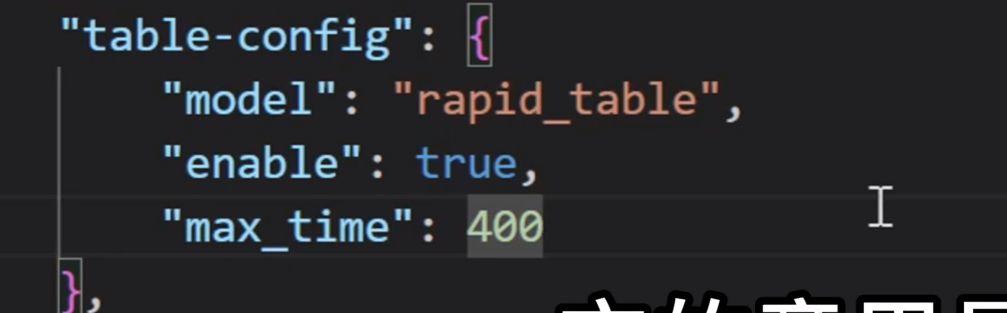
它的意思是开启表格的识别,把表格也转成Markdown格式的。开启完表格转换以后,重新跑一次。表格就转换成了markdown格式。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)