构建智能体的「超级大脑」:Agent RAG 架构深度解析
AI大模型应用,看这一篇就够了
构建智能体的「超级大脑」:Agent RAG 架构深度解析
引言
在当下大模型蓬勃发展的时代,虽然单一语言模型已经展现出了强大的能力,但也暴露出了一些明显的问题。其中,“知识截止”和“事实幻觉”成为了其在实际应用落地过程中的两大痛点。“知识截止”使得模型无法获取最新的信息,而“事实幻觉”则导致模型生成的内容可能与事实不符。
为了解决这些问题,Agent RAG(Retrieval - Augmented Generation)架构应运而生。它通过巧妙地将检索系统与生成模型进行深度耦合,为智能体赋予了实时访问外部知识库的能力。这就好比给智能体装上了一个“超级大脑”,让它能够实现“动态知识注入 + 逻辑推理”的完美闭环。接下来,我将从架构设计、关键技术以及实际落地案例等多个方面,全方位地为大家拆解这一前沿架构。
一、什么是 Agent RAG 架构?
定义
Agent RAG 是一种将检索增强生成(RAG)与智能体(Agent)深度融合的混合架构。其核心思想在于,让智能体在进行决策或者生成内容的时候,能够动态地从外部知识库(比如文档库、数据库、API 等)中检索相关信息,并将这些检索结果与自身的逻辑推理能力相结合,从而生成更加准确、有用的输出。
核心组件
- 智能体(Agent):它就像是整个架构的“指挥官”,负责对任务进行规划、进行逻辑推理以及做出行动决策。例如,它可以决定何时使用工具、调用哪些 API 等。
- 检索模块:这是架构中的“搜索能手”,能够从外部知识库中快速且精准地定位到相关信息。
- 生成模块:根据检索模块提供的结果以及上下文信息,生成最终的输出内容。它就像是一个“创作者”,将检索到的知识进行整合和创作。
- 记忆系统:用于存储对话历史或者中间结果,保证整个交互过程的连贯性。就好比人类的记忆,能够记住之前发生的事情,以便更好地理解和处理后续的任务。
架构示意图
用户请求 → 智能体(任务分解) → 检索模块(召回相关知识) → 生成模块(融合知识与推理) → 输出
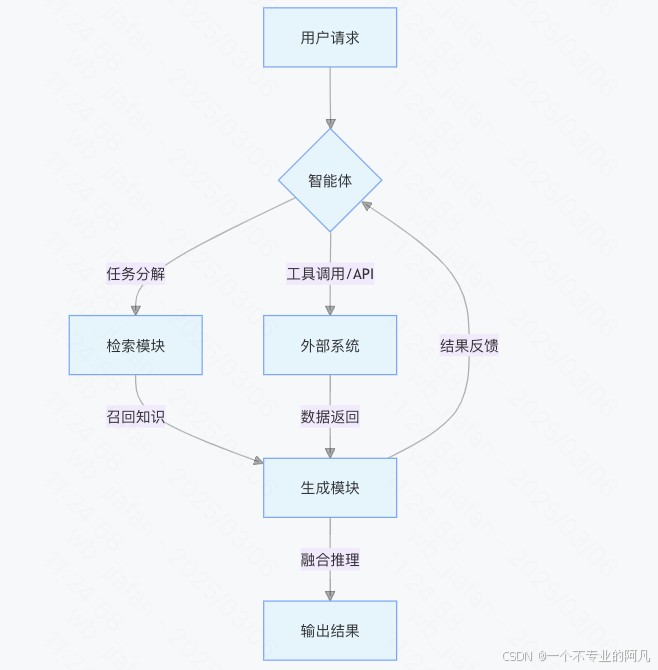
从这个示意图中,我们可以清晰地看到整个架构的工作流程。用户提出请求后,智能体首先对任务进行分解,然后检索模块根据分解后的任务去召回相关知识,生成模块将这些知识与推理相结合,最终输出结果。
二、为什么需要 Agent RAG?
传统 RAG 的局限
- 被动响应:传统的 RAG 通常只是被动地处理单次查询,它无法像人类一样主动地对复杂任务进行规划和处理,缺乏对任务的整体把控能力。
- 缺乏逻辑:它在处理问题时,往往只是简单地根据检索到的信息进行生成,无法进行多步推理,也不能灵活地调用各种工具来解决复杂问题。
- 上下文限制:检索结果受到生成模型上下文窗口的限制,这就导致它可能无法获取到足够全面的信息,从而影响生成内容的准确性。
Agent RAG 的优势
- 主动决策:Agent RAG 中的智能体具有主动决策的能力,它可以根据任务的需求自主规划检索的时机和方式。例如,它可以进行多次检索,或者根据一定的条件对检索结果进行过滤,从而获取到最有用的信息。
- 多跳推理:它能够结合检索到的知识和自身的逻辑推理能力,解决复杂的问题。就像人类在解决问题时,会进行多步思考和推理一样,Agent RAG 可以在不同的信息之间建立联系,得出更准确的结论。
- 动态适配:可以根据不同的任务需求,灵活地选择合适的知识库。无论是文档库、数据库还是实时 API,它都能根据具体情况进行动态适配,从而提高解决问题的效率和准确性。
三、关键技术与实现
1. 智能体设计
- 任务分解:通过精心设计的提示词(Prompt)或者利用大语言模型(LLM)来解析用户的意图,将一个复杂的任务拆分成多个子任务。这样可以将复杂问题简单化,便于逐步解决。
- 工具调用:智能体集成了各种工具,包括检索接口、计算器、API 等。例如,在 LangChain 中就有
Tool类,通过它可以方便地实现工具的调用。这些工具就像是智能体的“武器库”,可以根据不同的任务需求选择合适的工具来使用。 - 循环机制:采用 ReAct(Reasoning + Action)范式实现“思考 → 行动 → 观察”的闭环。智能体先进行思考,确定下一步的行动,然后执行行动,最后观察行动的结果,并根据结果进行进一步的思考和行动,不断迭代,直到问题得到解决。
2. 检索模块优化
- 混合检索:结合向量检索(语义匹配)和倒排索引(关键词精确匹配)两种方式。向量检索可以根据语义的相似性来召回相关信息,而倒排索引则可以快速定位到包含特定关键词的信息。通过将两者结合,可以提高检索的准确性和召回率。
- 上下文感知:检索模块能够根据当前的对话历史动态地调整检索策略。例如,如果在对话中已经提到了某个特定的领域,检索模块就可以优先在该领域的知识库中进行检索,从而提高检索效率。
- 检索增强:使用 BM25、ColBERT 等算法来提升检索的召回率和准确率。这些算法可以对检索结果进行排序和优化,使得更相关的信息能够排在前面,方便智能体获取。
3. 生成模块增强
- 检索结果融合:将检索到的内容作为提示词的一部分输入到生成模型(LLM)中。但需要注意的是,要考虑生成模型的上下文长度限制,避免输入过多的信息导致模型处理困难。
- 幻觉抑制:通过标注检索来源、引入事实核查机制等方法,减少生成模型产生错误内容的情况。例如,在生成内容时,明确标注信息的来源,让用户可以对信息的可靠性进行评估;同时,引入事实核查机制,对生成的内容进行验证,确保其与事实相符。
4. 记忆系统
- 短期记忆:用于存储当前对话的上下文信息。例如,在 LangChain 中就有
ConversationBufferMemory类,可以方便地实现短期记忆的功能。通过短期记忆,智能体可以记住对话的历史,从而更好地理解用户的意图和进行连贯的交互。 - 长期记忆:将重要的信息存入外部数据库(如 Pinecone、Weaviate),支持对历史对话的回溯。当需要回顾之前的对话或者查询相关信息时,可以从长期记忆中获取,方便智能体进行学习和总结。
四、实践案例:构建一个数据分析智能体
场景
用户输入“分析 2024 年 Q3 抖音电商女装类目销售趋势”,智能体需要结合内部数据和外部行业报告来生成分析结论。
实现步骤
-
任务分解
- 子任务 1:从数据库中获取 2024 年 Q3 抖音女装的销售数据。
- 子任务 2:检索艾瑞咨询、QuestMobile 等平台的相关行业报告。
- 子任务 3:对比内部数据和行业趋势,生成分析结论。
-
工具调用
- 数据库查询工具:使用该工具执行 SQL 查询,获取销售额、客单价等关键指标。
- 文档检索工具:利用 FAISS 向量库检索相关的行业报告。
-
生成逻辑
from langchain.agents import initialize_agent, Tool
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 初始化工具
tools = [
Tool(
name="Database Query",
func=query_database,
description="用于查询抖音电商内部数据库"
),
Tool(
name="Report Search",
func=search_reports,
description="用于检索行业报告"
)
]
# 初始化智能体
agent = initialize_agent(
tools,
OpenAI(temperature=0.5),
agent="zero - shot - react - description",
verbose=True
)
# 执行查询
agent.run("分析 2024 年 Q3 抖音电商女装类目销售趋势")
输出示例
“根据内部数据,Q3 抖音女装类目销售额同比增长 35%,客单价提升 18%,主要得益于直播带货的渗透率提升(从 42% 增至 58%)。结合 QuestMobile 报告,行业整体增速为 28%,抖音表现优于市场均值。建议关注年轻女性用户的个性化需求,如国潮品牌销量环比增长 60%。”
从这个实践案例中,我们可以看到 Agent RAG 架构在实际应用中的强大能力。它能够根据用户的需求,灵活地调用各种工具,结合内部数据和外部知识,生成准确、有价值的分析结论。
五、挑战与解决方案
1. 检索效率问题
在实际应用中,检索效率可能会成为一个瓶颈。当知识库规模较大时,检索所需的时间可能会很长,影响系统的响应速度。
优化方案:可以使用分布式检索系统,如 Elasticsearch + Milvus。Elasticsearch 具有强大的全文检索能力,而 Milvus 则是一个高性能的向量数据库,两者结合可以提高检索的效率。此外,还可以预加载高频知识库,将一些常用的信息提前加载到内存中,减少检索的时间。
2. 上下文长度限制
生成模型的上下文长度是有限的,当检索到的信息较多时,可能会超出上下文的限制,导致模型无法处理。
解决方案:可以采用分块检索(Chunking)的方法,将检索到的信息分成多个小块,分别进行处理;也可以使用动态摘要(Dynamic Summarization)技术,对检索到的信息进行自动摘要,提取关键信息,减少输入到模型中的信息量。
3. 知识过时与错误
外部知识库中的信息可能会过时或者存在错误,这会影响生成内容的准确性。
应对策略:在检索结果中标注信息的时效性,让用户可以清楚地知道信息的更新时间。同时,引入实时数据源,如新闻 API,及时获取最新的信息。此外,还可以建立事实核查机制,对检索到的信息进行验证,确保其准确性。
六、未来方向
1. 多模态融合
未来,Agent RAG 架构有望支持图片、视频等非结构化数据的检索与生成。这样,智能体就可以处理更加复杂的任务,例如根据图片内容进行描述和分析,或者根据视频生成相关的文本内容。
2. 自主学习
智能体可以根据用户的反馈不断优化检索策略和知识库管理。例如,当用户对生成的内容提出修改意见时,智能体可以学习到哪些地方需要改进,从而在后续的任务中提供更好的服务。
3. 低成本落地
通过使用轻量级模型(如 MPT - 7B)和进行私有部署,可以降低 Agent RAG 架构的部署成本。这将使得更多的企业和组织能够应用这一架构,推动其在更广泛领域的发展。
结语
Agent RAG 架构正从实验室逐步走向产业落地,它已经成为企业构建智能客服、数据分析、知识管理等系统的核心方案。随着检索技术和大模型的不断发展和进化,未来的智能体将具备更强大的自主决策能力,真正实现“思考与行动的无缝衔接”。
参考工具:
- LangChain, AutoGen, Rasa(智能体框架)
- Pinecone, Weaviate(向量数据库)
- LlamaIndex, Haystack(RAG 解决方案)
如果大家需要进一步了解具体的实现细节,欢迎在评论区留言交流! 🚀

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)