交通 | 大模型LLMs + TSP/VRP优化初探
LLM的引入不仅避免了手工设计启发式规则的复杂性,还能通过简单修改提示中的描述,快速适应不同规模的优化问题,甚至不同的任务。FunSearch方法是一个对求解程序的迭代过程,在每次迭代中,系统都会从当前的程序池中选择一些程序作为提示词,由LLM生成新的程序并自动进行评估。,如何更好地利用LLM在理解和推理上的优势,使其辅助优化问题的求解。受到OPRO方法的启发,也有一些学者尝试将进化算法的思想与L
编者按
大语言模型(Large Language Models, LLMs)作为人工智能领域的新兴技术,其强大的理解能力和丰富的专家知识使得其在各个领域均得到了广泛应用。在决策优化领域,本文从“直接生成问题的解”和“生成启发式规则”两个角度归纳了大模型用于优化问题求解的新方法,并分享总结5篇相关论文,带来大模型驱动决策的新思路。
概述:大模型+TSP/VRP求解初探
旅行商问题(Traveling Salesman Problem, TSP)和车辆路径规划问题(Vehicle Routing Problem, VRP)是交通物流领域内经典的组合优化问题,被广泛应用于各类配送场景。
在中小规模下,一些启发式方法通过设计问题导向的规则,能够在有限时间内给出近优解。然而,随着问题规模的扩大,一方面,启发式方法往往需要较长时间才能找到满意的可行解;另一方面,问题内部的复杂关联性使得启发式规则的设计变得更加困难。为此,研究学者们尝试引入机器学习方法来求解组合优化问题。通过端到端构建(Construct)或局部迭代优化(Improvement)的方式,神经组合优化(Neural Combinatorial Optimization, NCO)能够直接输出问题的近优解,且在大规模问题上具有优越的性能(如DeepACO、NeuOpt等)。然而,当问题的数据分布发生较大变化时,NCO的性能会下降,且泛化能力较差。若从头训练新的模型,将需要更昂贵的时间代价。
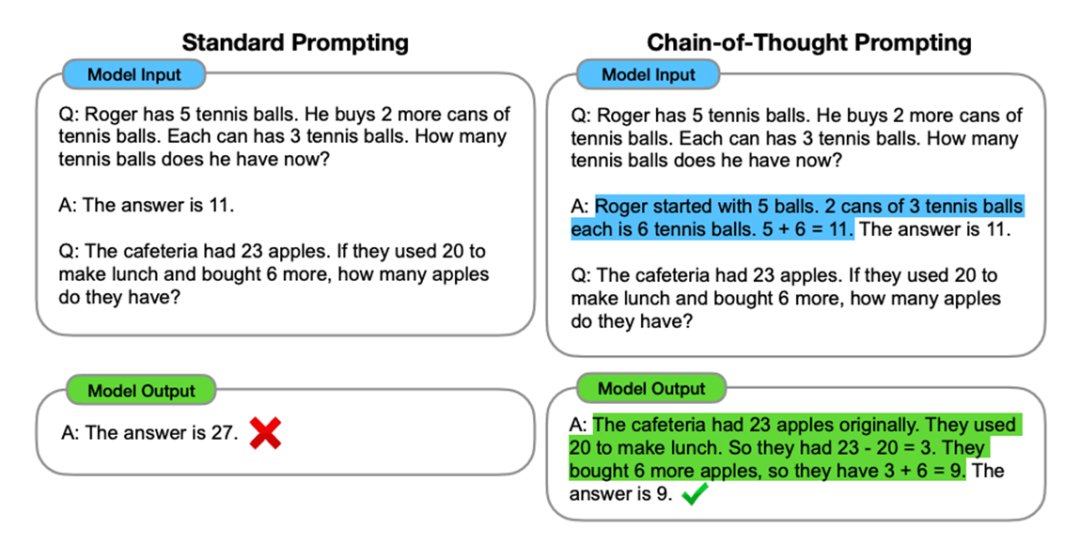
图1:链式思考提示工程示意图,通过引导LLM输出推理过程提升Reasoning任务性能
随着大语言模型(Large Language Model, LLM)的飞速发展,LLM的舞台已经不再局限于传统NLP任务。2023年初,链式思考(Chain of Thought, CoT)提示工程的出现使LLM能够“Think step by step”,大大提升了LLM在推理任务上的表现。此后,一些研究者将LLM和提示工程相结合,尝试用于求解TSP、VRP等组合优化问题,即将LLM用于优化。目前,此类研究主要聚焦于LLM的生成和推理的能力,通过提示工程给予LLM问题描述、上下文演示信息(In-Context Demonstration)以及历史信息(Optimization Trajectory)等,使LLM不断输出问题的解和启发式规则等,最终引导其求得近优解。
LLM的引入不仅避免了手工设计启发式规则的复杂性,还能通过简单修改提示中的描述,快速适应不同规模的优化问题,甚至不同的任务。本文将向读者介绍LLM用于求解组合优化问题的最新研究进展,尤其是TSP、VRP等与交通物流紧密相关的经典运筹问题。主要从以下两个方面进行阐述:
-
LLM用于直接生成问题的解;
-
LLM用于生成启发式规则;
LLM直接用于生成问题的解
[ICLR 2024] Large Language Models as Optimizers
C. Yang, X. Wang, Y. Lu, H. Liu, Q. V. Le, D. Zhou, and. X. Chen, “Large language models as optimizers,” arXiv preprint arXiv: 2309.03409, 2023.
这篇工作由Google DeepMind团队完成,提出了Optimization by PROmpting(OPRO),核心聚焦于使LLM作为优化器直接生成问题的解、提示词等。以优化问题的求解过程为例,OPRO的主要流程如图2所示。以Meta-Prompt作为LLM的输入,LLM将生成问题的可行解,并计算解的目标函数值作为评分。新生成的解和评分将组成“Solution-Score pair”添加至Meta-Prompt,用于下一轮优化。不难发现,Meta Prompt的设计是LLM能否胜任优化任务的关键。Meta Prompt主要包含两部分:
-
优化问题的相关描述:借助LLM处理NLP任务的优势,将问题的目标函数、约束条件以及相关背景用文字进行描述。此外,还可以添加非正式的正则化提示词,如“提示应简洁且具有普适性”。
-
优化的历史信息:适当提供上下文演示信息有助于LLM更好地识别背后的潜在模式。OPRO将历史解及其分数按升序排列,使LLM能够发现高分解之间的相似性。
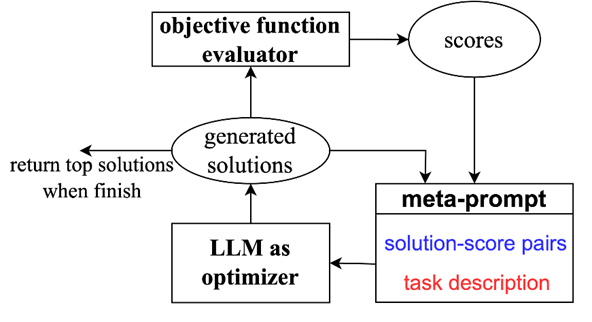
图2:OPRO优化流程示意图
在生成解的阶段,可以通过每轮优化生成多个解来减少不稳定性,并通过自适应调整LLM的采样温度,以实现探索与开发之间的平衡。图3为OPRO在TSP问题上的求解结果,其中NN(Nearest Neighbor)和FI(Farthest Insertion)为求解TSP问题的经典启发式方法。在n=10和15时,LLM能够以极小的gap求得近优解,但随着TSP节点数的增多,LLM的求解性能显著下滑。

图3:OPRO方法在TSP问题下的性能表现
受到OPRO方法的启发,也有一些学者尝试将进化算法的思想与LLM进行结合,在直接对解进行生成的求解范式下对方法进一步优化,提出了下文所介绍的OPRO方法。
[CEC 2024] Large Language Models as Evolutionary Optimizers
Liu S, Chen C, Qu X, Tang K, Ong YS. Large language models as evolutionary optimizers. In 2024 IEEE Congress on Evolutionary Computation (CEC) 2024 Jun 30 (pp. 1-8). IEEE.
进化算法(Evolutionary Algorithms, EAs)在求解复杂的组合优化问题时有着出色的表现,这篇工作提出了一种LLM驱动的进化算法(LLM-driven EAs, LMEA),其首次将大语言模型作为进化组合优化器。该方法利用提示词工程引导LLM对当前种群进行选择、交叉和变异等经典的进化操作,摆脱了对各类算子的复杂设计且无需对模型额外训练。与此同时,LMEA配备了一个自适应机制来控制LLM的温度,进而在在探索和利用之间取得平衡,并防止搜索陷入局部最优。
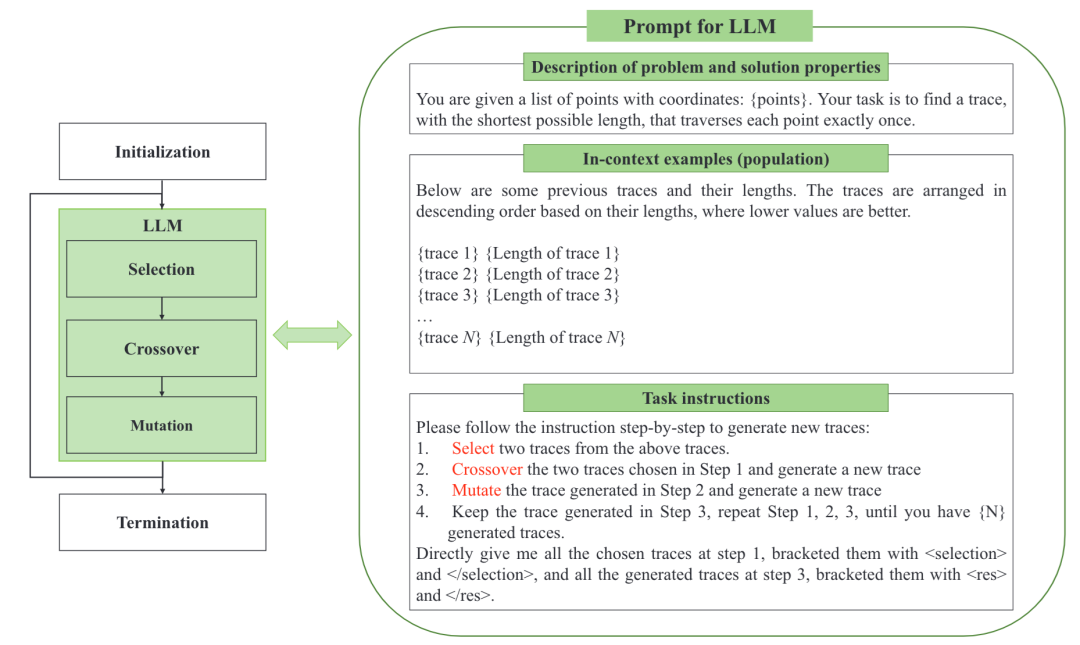
图3 :LMEA方法概览,右侧展示了TSP任务下LMEA方法的提示词构建,提示词中的“{}”会由对应输入进行代替
对于LMEA方法而言,其提示词的构建主要由三部分构成:
-
问题描述和解的特性:该部分包含了优化问题的描述以及期望得到的解的特性与格式。
-
上下文例子:优化问题的解及其对应的适应度函数值被作为示例展示给LLM帮助理解,这些信息通常从当前种群得到。
-
任务说明:该部分负责为LLM提供明确的任务指引,包括父代选择、交叉和变异等一系列用于产生新解的任务操作。
不难发现,LMEA方法的提示词构建与OPRO方法有相通之处,二者均是通过LLM直接对解进行生成。然而,OPRO侧重于直接由LLM根据当前种群生成对应的新解;而LMEA方法则从进化的思想入手,利用LLM的优势对选择、交叉和变异三个经典的进化算子进行驱动,实现更高效的进化。
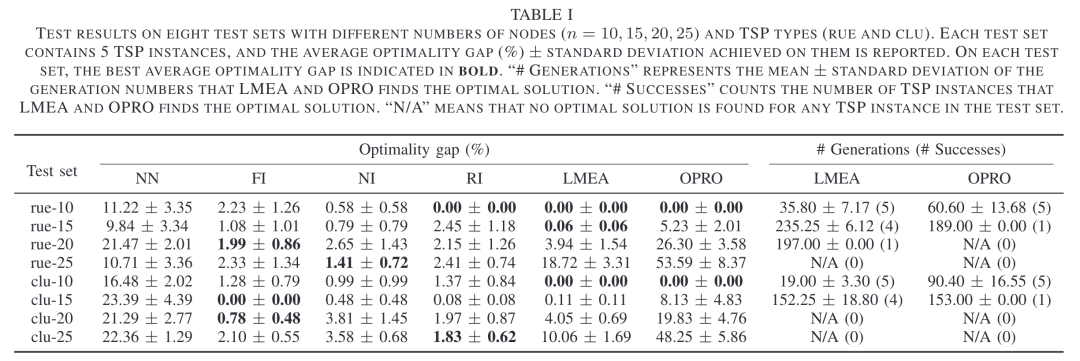
图4:LMEA方法在TSP问题上的求解结果
图4展示了LMEA方法在TSP问题上的求解结果,并与不同启发式方法以及
OPRO方法进行对比。实验结果表明,LMEA方法在小规模的问题下(n=10和n=15)得到的解与最优解十分接近,且在所有算例下的性能表现均超过了OPRO方法。然而,随着节点数目的增多,LMEA和OPRO均无法很好地处理大规模下的TSP问题,且性能表现不如传统的启发式方法。
OPRO和LMEA方法均通过直接生成解的方式对优化问题进行求解,然而这种方式在处理大规模问题时往往无法表现得很好。因此,这种直接生成解的方式似乎会限制LLM在求解组合优化问题中的表现,越来越多的研究者也开始利用LLM的优势,并引入进化计算(Evolutionary Computing, EC)的思想生成启发式规则。这类技术也属于语言超启发式(Language Hyper Heuristic, LHH)。
LLM用于生成启发式规则
[Nature 2024] Mathematical Discoveries from Program Search with Large Language Models
Romera-Paredes B, Barekatain M, Novikov A, Balog M, Kumar MP, Dupont E, Ruiz FJ, Ellenberg JS, Wang P, Fawzi O, Kohli P. Mathematical discoveries from program search with large language models. Nature. 2024 Jan 18;625(7995):468-75.
这篇工作由Google DeepMind团队完成并发表于Nature,不同于LLM直接生成解的求解范式,该工作隶属于LHH的范畴,其目标在于生成用于求解的启发式规则。这篇论文介绍了一种FunSeach方法在函数空间中搜索,通过反馈循环的方式实现启发式规则的自动化设计。FunSearch方法是一个对求解程序的迭代过程,在每次迭代中,系统都会从当前的程序池中选择一些程序作为提示词,由LLM生成新的程序并自动进行评估。能够正常运行的程序将被添加至现有程序池中,从而创建一个自我改进的循环。
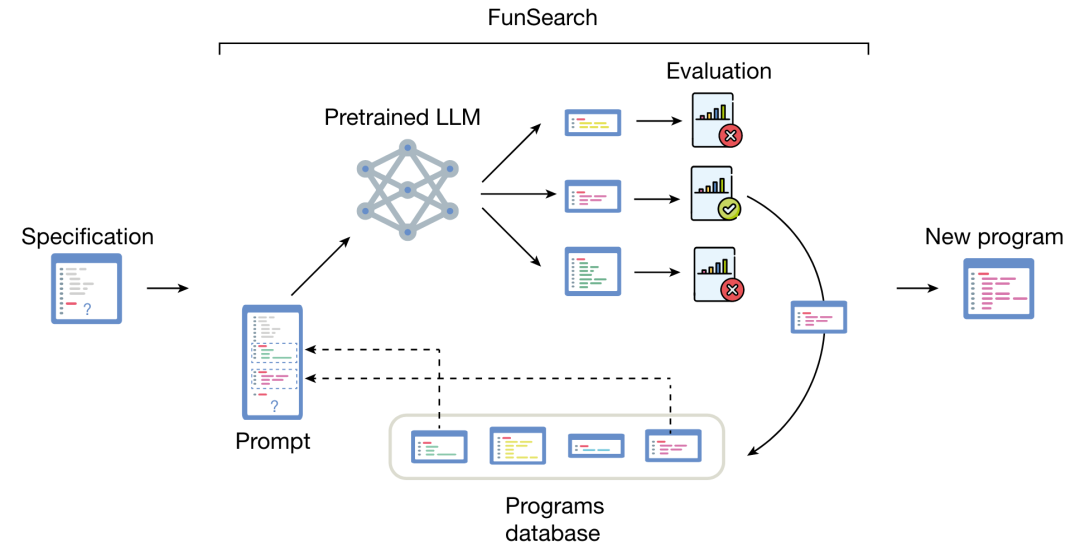
图5:FunSearch方法流程图
如图5所示,FunSearch方法通过不断地生成新程并进行评估,以迭代循环地方式对启发式规则空间进行搜索,从而获得更加高效、性能更好的求解程序。为了提高FunSearch的搜索效率和性能表现,将解(代码程序)表示为框架(Skeleton)的形式,只对关键部分的代码进行优化和搜索。FunSearch方法的求解过程可分为以下几个部分:
-
规范(Specification):FunSearch方法的输入为优化问题的规范,即该优化问题评估函数的求解程序,其能够对候选解的性能进行打分评估。
-
预训练LLM(Pretrained LLM):考虑到需要利用预训练LLM进行多次迭代优化,FunSearch方法倾向于选择推理速度快的网络作为预训练LLM。
-
评估(Evaluation):在当前优化问题下随机生成一系列算例,对当前解进行评估打分,能够正确运行的解被加入到程序数据库中,无法正确运行的解被直接丢弃。
-
程序数据库(Programs Database):FunSearch方法采用了遗传算法中的岛屿模型对程序数据库进行采样,将解划分为若干个独立进化的岛屿。在采样的过程中,首先对岛屿进行采样,再对岛屿中的程序进行采样,优先选择得分高和长度短的程序。
-
提示词(Prompt):通过Best-Shot的提示形式,将当前表现最好的单个或多个程序作为预训练LLM的示例输入,引导LLM生成新的更优解。

图6:使用Best-fit启发式(左)和FunSearch搜索得到的启发式(右)进行装箱的示例
与此同时,FunSearch方法在上限集问题(Cap Set Problem)和装箱问题(Bin Backing Problem)上进行了实验验证。实验表明,在上限集问题的某些样例下FunSearch方法得到的求解方案超过了迄今为止已知的最好解。而在装箱问题上,FunSearch方法同样展现出了卓越的性能,在不同的算例上超越了First Fit和Best Fit启发式,其对比效果如图6所示。
与直接用于求解不同,FunSearch方法从算法设计的层面思考,如何更好地利用LLM在理解和推理上的优势,使其辅助优化问题的求解。FunSearch方法创新性地提出了LLM驱动算法设计的框架,为后续一些超启发式方法的研究奠定了基础。
[ICML 2024] Evolution of Heuristics: Towards Efficient Automatic Algorithm Design Using Large Language Model
Liu F, Xialiang T, Yuan M, et al. Evolution of Heuristics: Towards Efficient Automatic Algorithm Design Using Large Language Model. Forty-first International Conference on Machine Learning. 2024.
这篇论文提出了EoH(Evolution of Heuristics),借助LLM实现启发式规则的自动设计。它将LLM和提示工程融入至进化计算的框架中,通过迭代进化的思想让LLM不断生成启发式思想(High-level Thoughts)和对应的可行代码(Low-level Code)。EoH的性能已在在线装箱问题、旅行商问题和车间调度问题中得到了验证。以TSP为例,在200节点规模的问题上,EoH能获得约0.2%的gap。
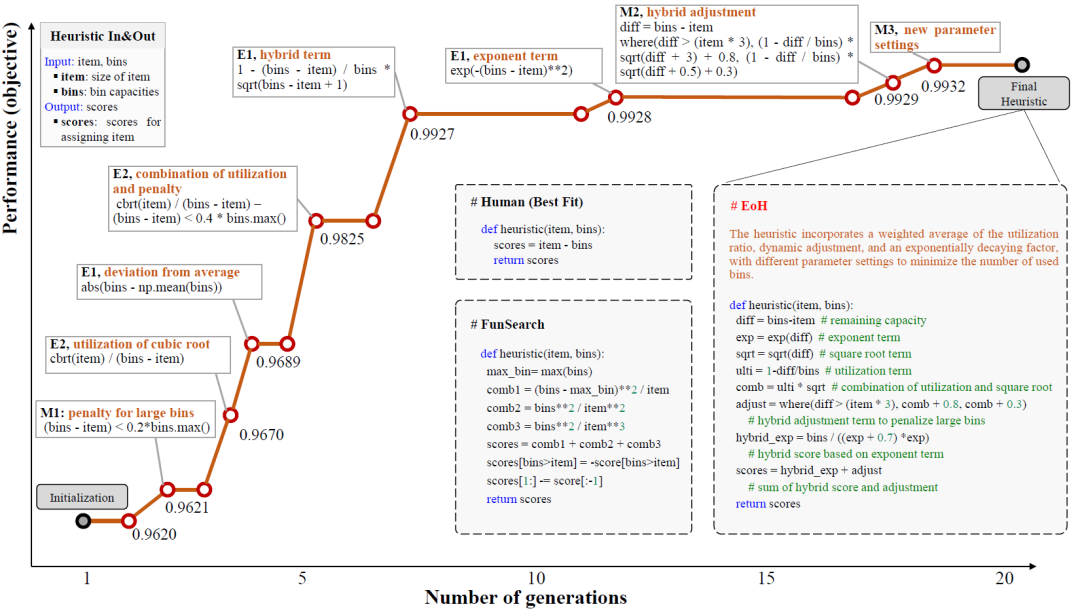
图7:EoH求解在线装箱问题的迭代示意图
和FunSearch类似,EoH中LLM生成的也是启发式规则,但其对于LLM的query数量减小了3个数量级。EoH共设计了5个提示策略,它们分别侧重于从探索(即广泛搜索启发式空间)和修改(即从以往的经验中学习并优化)。通过将生成的启发式规则应用于一系列问题(如TSPLib中的某一类问题),得到适应度函数值,从而对整体性能进行评估。图7是求解在线装箱问题的迭代示意图。值得注意的是,FunSearch只对代码生成做出了提示,而EoH同时生成了想法和代码,消融实验证明了High-level thoughts指导的有效性。
图8给出了探索策略E2的提示模板。可以观察到,CoT和Few shot上下文学习对于LLM的表现是至关重要的。

图8:E2策略提示模板
FunSearch和EoH等方法将LLM纳入了进化计算框架,采用生成启发式规则的方式,在求解组合优化问题时已优于通过直接生成解的OPRO。然而,在大规模问题的求解中,LLM优化的性能仍旧劣于NCO。研究者发现,尽管提供了上下文演示信息或优化历史信息,启发式策略的优劣仍然是隐式地告知LLM的。受控制系统反馈机制的启发,研究者开始尝试引入反馈思想,让LLM生成反馈提示信息,以指导后续策略的生成。
[NeurIPS 2024] ReEvo: Large Language Models as Hyper-Heuristics with Reflective Evolution.
Ye H, Wang J, Cao Z, et al. Reevo: Large language models as hyper-heuristics with reflective evolution. arXiv preprint arXiv:2402.01145, 2024.
ReEvo融入了上述反馈思想,通过Reflection Evolution的方式赋能LHH,使LLM为启发式规则的生成提供了语言梯度(Verbal Gradients),增强了其推理能力。ReEvo沿用了遗传编程(Genetic Programming, GP)的框架,其优化流程主要包含5个步骤:选择、短期反馈(Short-term Reflections)、交叉、长期反馈(Long-term Reflections)和精英变异。
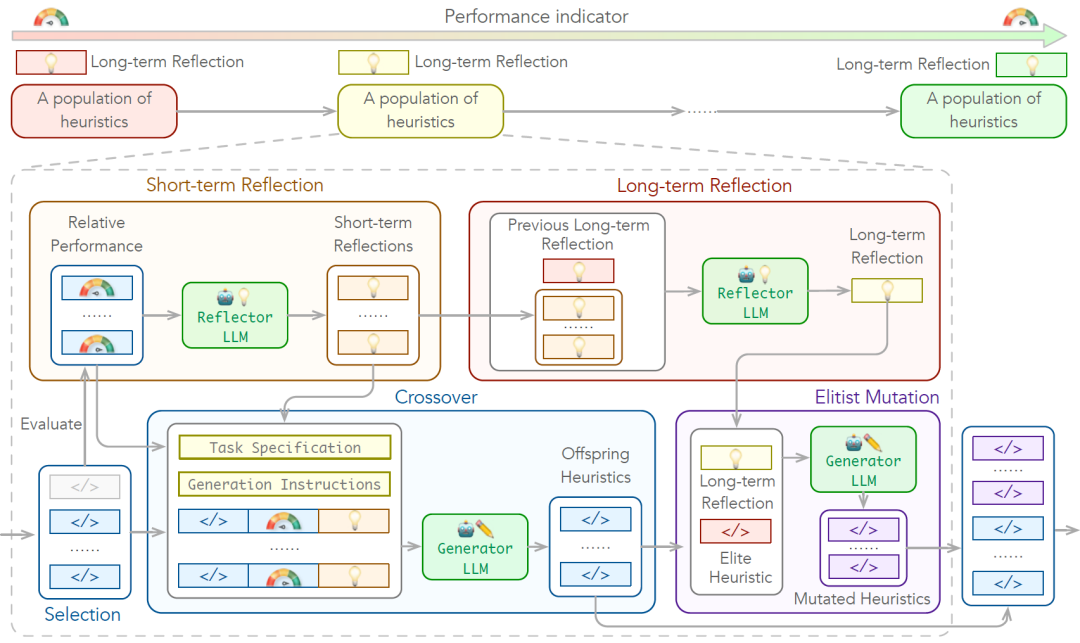
图9:ReEvo优化流程图
短期反馈是指LLM根据父代启发式规则的相对表现进行思考,并相应地提供改进设计的提示。它能够在启发式搜索空间中提供语言梯度,从而使优化问题的适应度景观(Fitness Landscape)更加平滑。这一反馈将被纳入交叉操作中,与问题描述、父代启发式规则以及二者适应度值的显式分析等信息一起,作为交叉操作的提示。
长期反馈则是指LLM在改进启发式设计过程中的长期思考,通过将最新的短期反馈与原先的长期反馈相互融合,给出总结性的提示。LLM将基于长期反馈,采样生成多个启发式规则,从而优化现有的最优解,即精英变异。
从LLM代理架构的角度来看,短期反馈解释了每轮互动中的环境反馈;长期反馈则提炼了积累的经验和知识,使其能够被融入至推理上下文中。
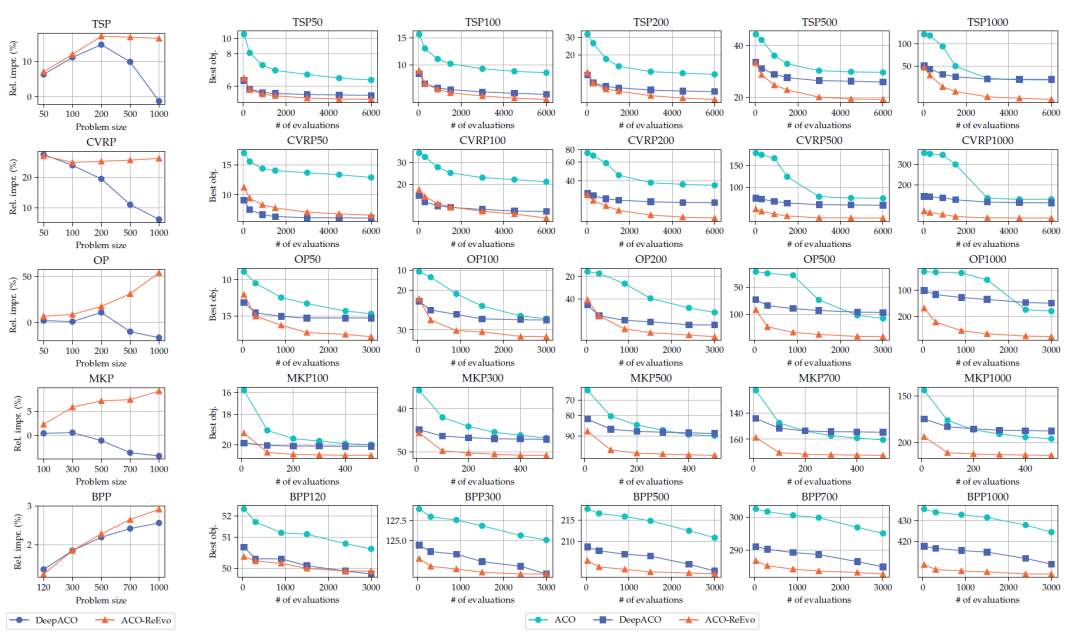
图10:ReEvo与DeepACO、ACO对比实验结果图
ReEvo论文中完成了充分的验证试验。以TSP、CVRP、MKP等5个经典的组合优化问题为例,ReEvo与ACO、DeepACO(SOTA)进行了对比。在其中的三种问题(TSP50、OP50 和 MKP100)上,ReEvo的表现超过了DeepACO,即使后者在测试问题规模上发生了过拟合。论文同时观察到,大多数ReEvo生成的启发式规则在不同问题规模a和分布下表现一致。因此,随着数据分布偏移的增加,LHH相比于NCO的优势将更加明显。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)