CVPR 2025 | Papers-with-Code |【合集一】AIGC相关(目前已更20篇,持续更新中)
CVPR2025 | AIGC

CVPR 2025 decisions are now available on OpenReview!22.1% = 2878 / 13008
会议官网:https://cvpr.thecvf.com/Conferences/2025
目前计划整理六个合集,部分合集未发布
【合集一】AIGC
【合集二】Mamba、MLLM
【合集三】底层视觉
【合集四】检测与分割
【合集五】三维视觉
【合集六】视频理解
欢迎转载,转载注明出处哦——————————————————————————————————————————————————————————————
扩散模型
1.《TinyFusion: Diffusion Transformers Learned Shallow》
paper: https://arxiv.org/abs/2412.01199
code: https://github.com/VainF/TinyFusion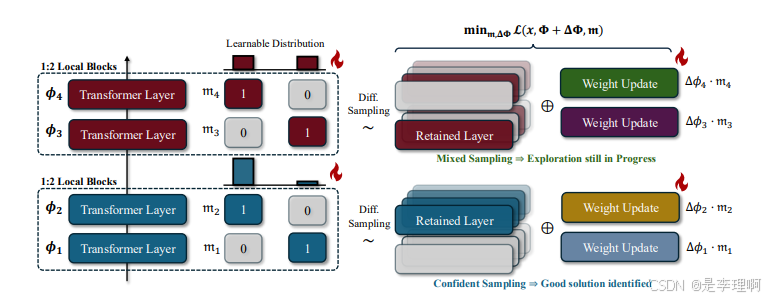
2.《CleanDIFT: Diffusion Features without Noise》
paper: https://arxiv.org/pdf/2412.03439
code: https://github.com/CompVis/cleandift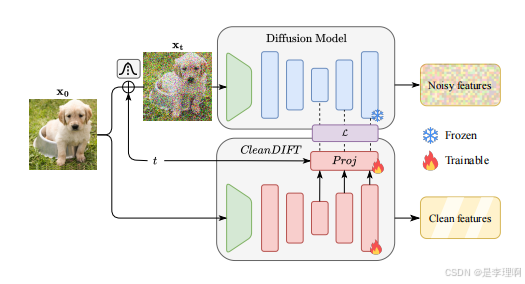
3.《CacheQuant: Comprehensively Accelerated Diffusion Models》
paper: https://arxiv.org/pdf/2503.01323
code: https://github.com/BienLuky/CacheQuant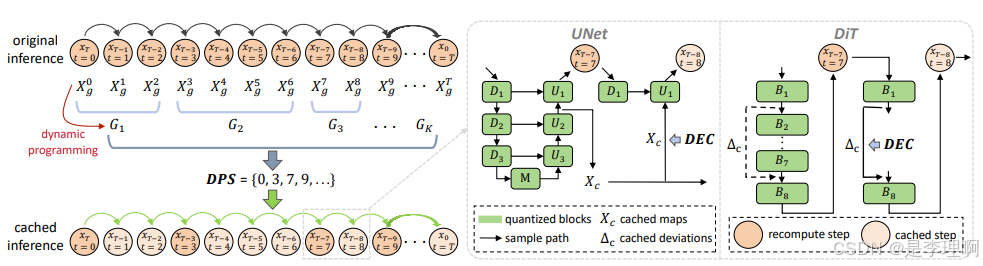
4.《Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models》
Paper: https://arxiv.org/abs/2501.01423
Code: https://github.com/hustvl/LightningDiT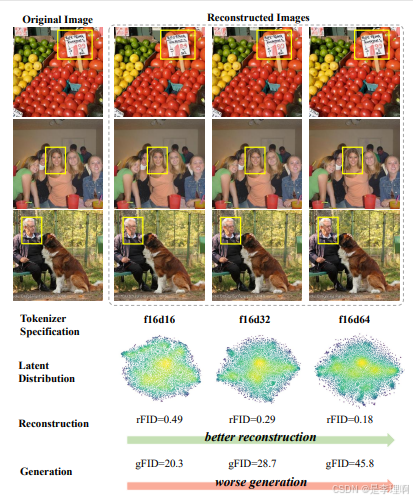
图像生成
1.《Parallelized Autoregressive Visual Generation》
paper: https://arxiv.org/abs/2412.15119
code: https://github.com/Epiphqny/PAR
2.《PatchDPO: Patch-level DPO for Finetuning-free Personalized Image Generation》
paper:https://arxiv.org/abs/2412.03177
code:https://github.com/hqhQAQ/PatchDPO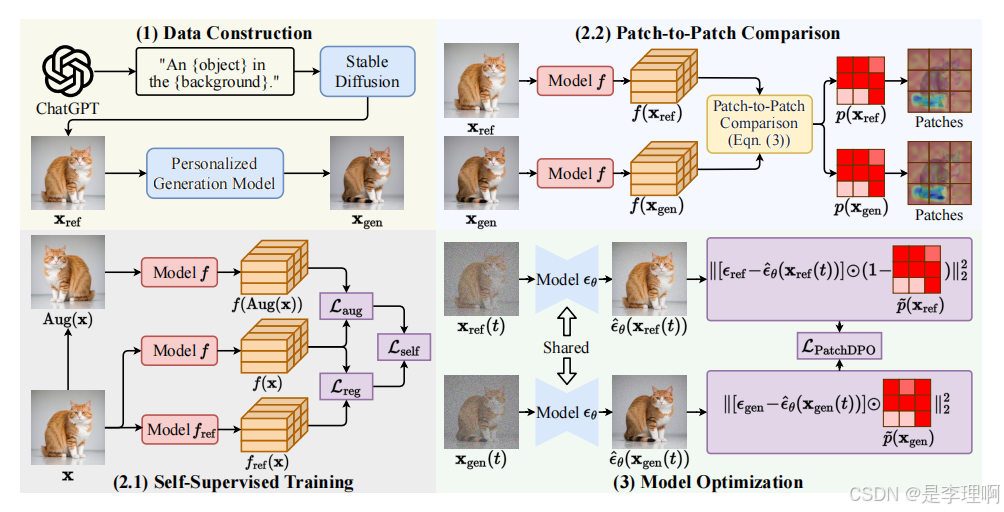
3.《SemanticDraw: Towards Real-Time Interactive Content Creation from Image Diffusion Models》
paper: https://arxiv.org/abs/2403.09055
code:https://github.com/ironjr/semantic-draw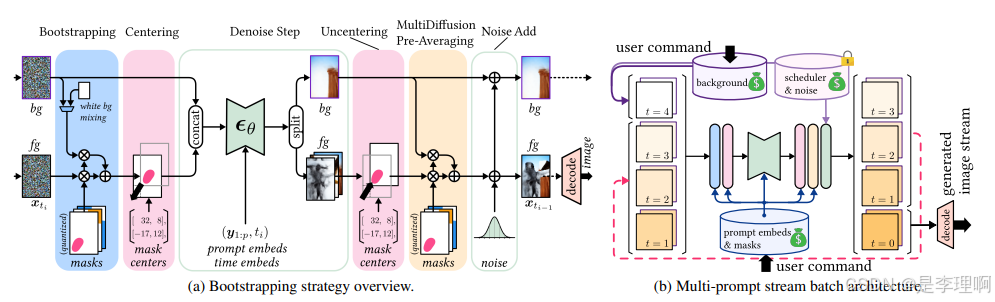
4.《Collaborative Decoding Makes Visual Auto-Regressive Modeling Efficient》
paper: https://arxiv.org/pdf/2411.17787
code: https://github.com/czg1225/CoDe
5.《DreamText: High Fidelity Scene Text Synthesis》
paper: https://arxiv.org/abs/2405.14701
code: https://github.com/CodeGoat24/DreamText
6.《TokenFlow: Unified Image Tokenizer for Multimodal Understanding and Generation》
paper: https://github.com/ByteFlow-AI/TokenFlow
code: https://arxiv.org/pdf/2412.03069
视频生成
1.《High-Fidelity Relightable Monocular Portrait Animation with Lighting-Controllable Video Diffusion Model》
paper: https://arxiv.org/abs/2502.19894
code: https://github.com/MingtaoGuo/Relightable-Portrait-Animation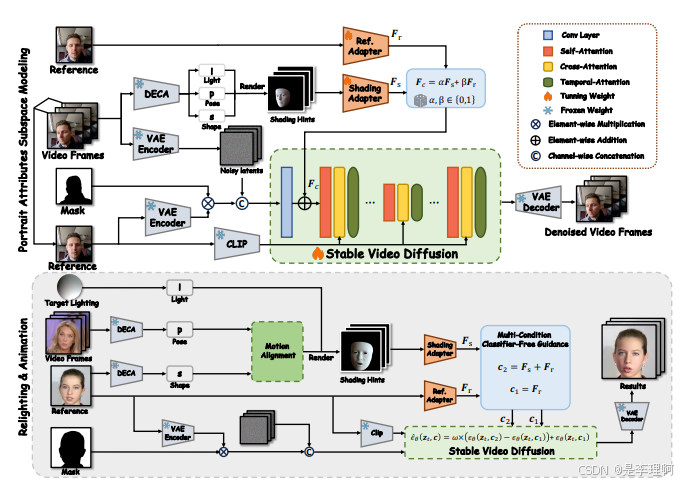
2.《Identity-Preserving Text-to-Video Generation by Frequency Decomposition》
paper:https://arxiv.org/abs/2411.17440
code: https://github.com/PKU-YuanGroup/ConsisID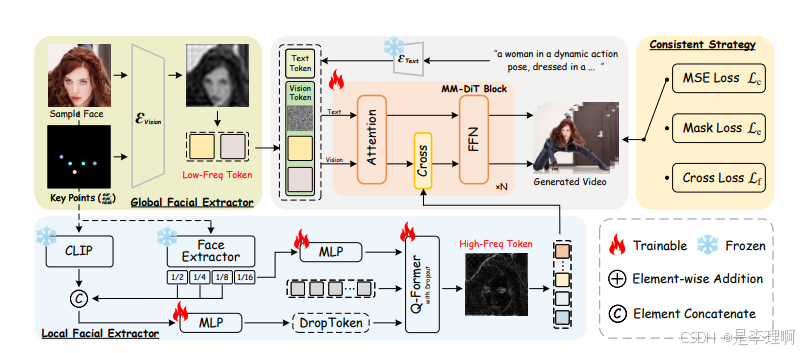
3.《WF-VAE: Enhancing Video VAE by Wavelet-Driven Energy Flow for Latent Video Diffusion Model》
paper: https://arxiv.org/abs/2411.17459
code: https://github.com/PKU-YuanGroup/WF-VAE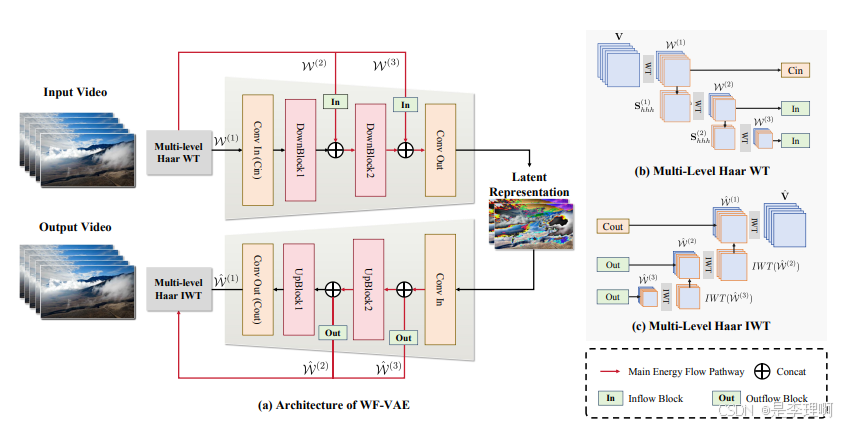
4.《InstanceCap: Improving Text-to-Video Generation via Instance-aware Structured Caption》
paper: https://arxiv.org/abs/2412.09283
code: https://github.com/NJU-PCALab/InstanceCap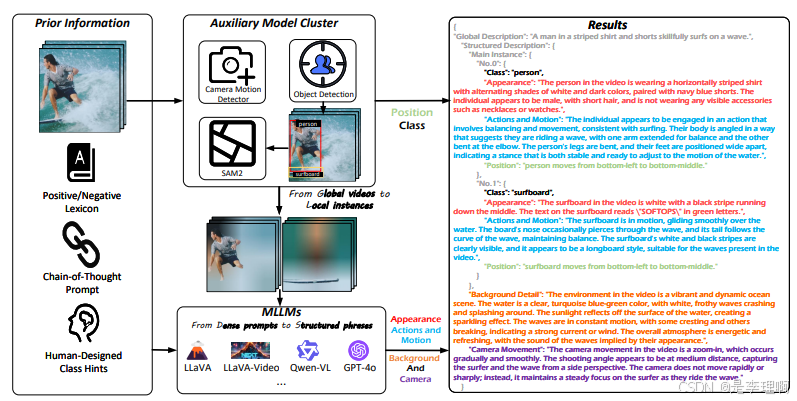
5.《PhyT2V: LLM-Guided Iterative Self-Refinement for Physics-Grounded Text-to-Video Generation》
paper: https://arxiv.org/abs/2412.00596
code: https://github.com/pittisl/PhyT2V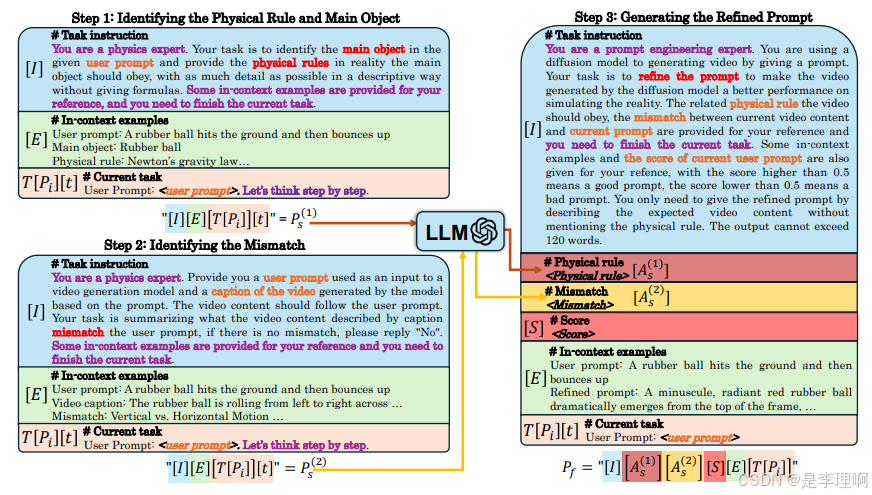
图像编辑
1.《CTRL-D: Controllable Dynamic 3D Scene Editing with Personalized 2D Diffusion》
paper: https://arxiv.org/pdf/2412.01792
code: https://ihe-kaii.github.io/CTRL-D/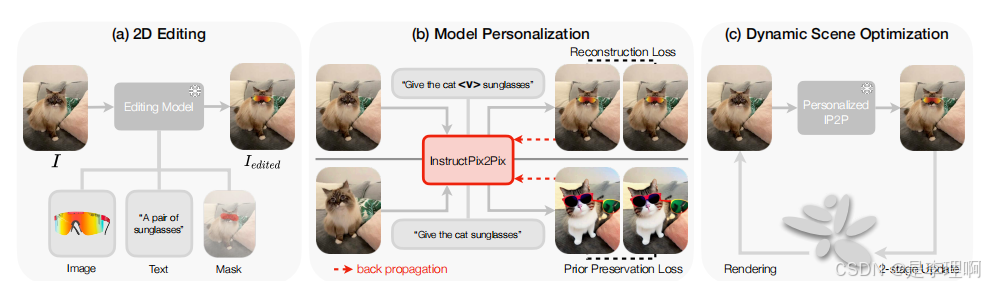
2.《Edit Away and My Face Will not Stay: Personal Biometric Defense against Malicious Generative Editing》
paper: https://arxiv.org/abs/2411.16832
code: https://github.com/taco-group/FaceLock
3.《 h h h-Edit: Effective and Flexible Diffusion-Based Editing via Doob’s h h h-Transform》
paper: https://arxiv.org/abs/2503.02187
code: https://github.com/nktoan/h-edit
4.《EmoEdit: Evoking Emotions through Image Manipulation》
paper: https://arxiv.org/pdf/2405.12661
code: https://github.com/JingyuanYY/EmoEdit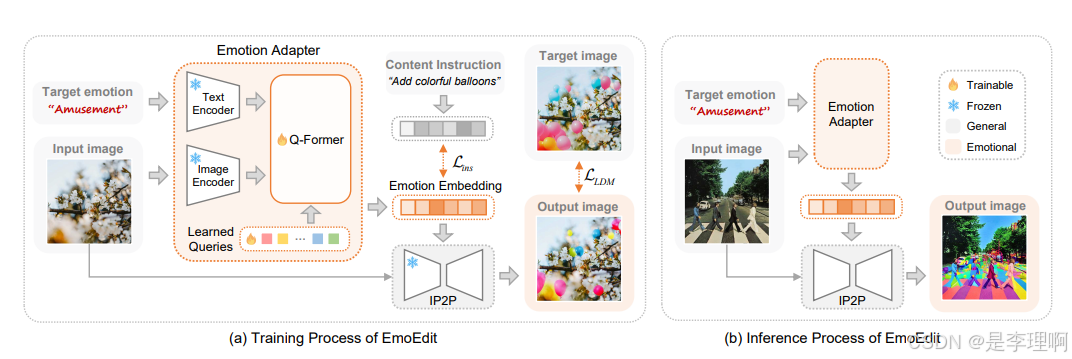
5.《Edit Away and My Face Will not Stay: Personal Biometric Defense against Malicious Generative Editing》
paper: https://arxiv.org/abs/2411.16832
code: https://github.com/taco-group/FaceLock

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 45
45 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)