【推荐系统】YouTube DNN
youtube作为世界上最大的视频内容平台,在视频推荐任务上面临着三个主要问题:数据量大(如何获得更精准的推荐算法和更高效的推荐服务);新鲜度(如何平衡用户对新鲜物品的需求和新鲜物品推荐不准确的问题);噪声大(平台很难获得用户的显式反馈信息,只能对包含噪声的隐式反馈信息进行建模),这篇文章针对这三个问题都提出了很好的解决方案。【两阶段架构】:youtube DNN分为采用经典的两阶段模型,包括候选
youtube作为世界上最大的视频内容平台,在视频推荐任务上面临着三个主要问题:数据量大(如何获得更精准的推荐算法和更高效的推荐服务);新鲜度(如何平衡用户对新鲜物品的需求和新鲜物品推荐不准确的问题);噪声大(平台很难获得用户的显式反馈信息,只能对包含噪声的隐式反馈信息进行建模),这篇文章针对这三个问题都提出了很好的解决方案。
youtubeDNN整体架构?
【两阶段架构】:youtube DNN分为采用经典的两阶段模型,包括候选集生成模型(召回模型)和排序模型。候选集生成模型从百万个视频中挑选出用户可能感兴趣的几百个视频输入排序模型,排序模型结合更加精细的用户特征给候选视频打分,最终根据分数的高低,将高分视频推荐给用户。

候选集生成模型的结构?输入输出和优化目标?
【优化目标】:首先,候选集生成模型是一个多分类模型,目标是预测是用户下一个可能观看的视频,即最大化条件概率:

这个公式借鉴了word2vec中的skip-gram模型,其中u是用户的embedding(类比中心词),vi是用户下一个真实点击的视频embedding(类比上下文词),vj是所有视频的embedding(类比词库中所有的词)。v·u内积运算表示用户向量和视频向量的相似度,指数运算将内积的结果转换为正数,softmax函数将运算结果转换为0-1的概率。当给定了用户特征,我们希望模型对于用户下一次真实观看视频的预测概率尽可能大,因此最大化这个条件概率与目标相符。
【模型输入】:召回模型的输入包括用户的历史观看视频序列、用户的历史搜索词、地理位置特征、example age(后面重点讨论)、用户年龄等特征,将所有的特征做concanate,一起输入模型。
- 用户的历史观看视频序列和用户的历史搜索词都是非数值特征,需要先通过embedding的方法,将其转化为低维稠密向量。获得embedding有两种方式:一种是采用预训练的方法,借助外部模型直接获得embedding,再将embedding作为模型的输入;另一种方式是输入原始的one-hot向量,再随着DNN模型的训练同步更新参数。由于用户历史观看序列和历史搜索词都是多值参数,因此采用average的方式进行融合。(文中还提到了可以采用sum或max component的方式,但是average的效果最好)文中采用了用户近50次的视频观看记录和搜索历史记录,转换成256维的embedding。
- 针对例如年龄的连续型数值特征,工程上常用的方法有分桶,采用log(1+x)(针对长尾连续特征),对同一个特征分别做
,x,x²三种变化,同时输入模型(增加特征的非线性)。

从哪里获取用户embedding和视频embedding?
还看skip-gram模型,在这里模型训练完成后会得到两个权重矩阵W和W'。其中WT·x相当于提取出了权重矩阵中的行向量,这个行向量就是词汇x作为中心词时的embedding。对于上下文词vj,它与中心词h的相似度计算结果为(即权重矩阵W'的列向量与中心词向量的内积!),因此权重矩阵W'的列向量就可以作为上下词的embedding。

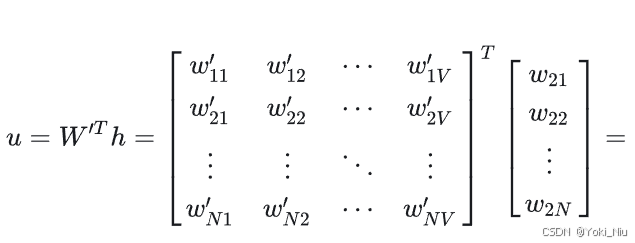


类比DNN模型和skip-gram模型,DNN模型最后一个relu层的输出就是skip-gram模型中的h,也即用户的embedding(类比中心词embedding);从最后一个relu层到softmax之间的权重矩阵即为W',它的列向量即为物品的embedding(类比上下文词embedding),假设W'的维度为m×n(其中n为所有物品的数量),物品的embedding维度为m×1。
softmax层的训练方法?
从上述推导过程中可见,若物品数量很大,那么softmax函数的分母就会很大,模型训练低效。文章对候选物品进行了负采样(关于负采样技术又是一个值得深挖的问题),并采用加权(文中没有提到如何加权)的方式纠正采样偏差。这种方法比传统的softmax训练法速度提升了1000倍。文中也尝试了分层采样技术,但是效果并不好。
训练样本的选取经验?
关于训练和测试样本的选取,文中也提到了一些值得借鉴的trick:
【全样本的选取】:训练样本来自于所有的视频观看记录,而不仅仅是平台推荐给用户的内容的观看记录。否则,新内容很难被推荐,并且模型会倾向于选择被大量用户观看过的热门内容。换句话说,当用户从其他渠道发现并观看了新内容,这些观看记录被被纳入模型的训练数据源中,借助userCF算法,可以快速将这部分新视频推荐给其他的相似用户,有利于新视频的冷启动。
【活跃用户的打压】:从所有用户中选取数量相同的观看记录作为训练样本,以防止模型过多关注活跃用户的兴趣偏好,而忽视了其他用户的需求。
【测试集】:用户对于视频的观看行为存在“非对称消费”,例如用户看连续剧时通常时按顺序一集一集观看的,这就造成用户对于相邻剧集之间的观看概率较高,而与其他不相关剧集之间的观看概率较低。此外,若预先知道了用户观看过第3集,再来预测用户是否观看过第2集,这会造成未来信息的泄漏。因此,在测试集的选取上采用用户下一次的观看视频作为标签,而不是从用户所有观看过的视频记录中随机选取一条。

【隐藏输入特征的时序信息】: 如果将用户搜索词的时序信息也作为一个特征输入模型,那么若用户最近一次搜索过“泰勒-斯威夫特”,那么模型很大概率上就会给用户的主页全部推荐“泰勒-斯威夫特”,这是很不好的。因此,文章中丢弃了时序信息,采用随机打乱的方式,让用户不知道这条特征的来源。(但是关于时序信息的作用还需要进一步研究)
example age特征理解?
文章发现,用户对于新视频存在一定的偏好,不论它是否与用户过去的兴趣相吻合;并且推荐新视频还有助于引导和传播热门内容,因此额外引入了一个example age特征。example age定义为,即用户最近观看视频的时间与用户观看特定视频的时间之差。
其实刚看到这个特征时,我想到的example age应该是视频上传的时间video age。视频刚刚上传时热度高,视频上传一段时间之后热度低,这是符合该特征的构造初衷的。但是文中却并不是用video age来定义example age的,这是为什么呢?从这张图中可以看出,video age与example age之和为一个常数,因此这两个特征是等价的。并且在线上预测时,example age是一个常数值,不依赖于候选物品的上传时间,因此只需要计算一次用户向量即可。
在推理阶段,候选物品的example age被设置为0。个人理解,假设在当下时刻,该视频成功被推荐给用户看到,那么tmax和tlog都是当前值,因此example age为0。

召回模型的线上服务?
文中并不是用召回模型直接预测用户可能观看的下一个视频,而是先获取用户和物品的embedding,再通过最近邻查找的方式获取结果。这种方式是出于线上服务的时效性考虑,如果每一次都要对用户和几百万个候选物品进行推理,计算量太大。而采用向量召回的方式,我们只需要提前计算好user embedding和item embedding,将它们存到向量数据库中,需要的时候直接查找即可。(在实际应用中,用户的兴趣变化速度较快,而物品属性变化速度较慢,如果将用户embedding和item embedding都提前计算好,就无法捕捉到用户最近的兴趣变化。在后续的双塔模型中,我们仅存储item embedding和用户塔神经网络,当需要召回物品时,现算用户的embedding,再从数据库中召回item embedding)
排序模型的结构?输入输出和优化目标?
【输入输出】:经过召回模型后,候选物品的数量降低至几百,因此排序模型中可以加入更多的特征对用户行为进行更精细的刻画。文中排序模型包含五个输入:当前候选物品的embedding(impression embedding)、用于最后观看过的N个视频的embedding取average pooling(watched video embedding)、语言embedding、用户上次观看同频道的时间、该视频已曝光给用户的次数。其中用户上次观看同频道的时间可以反映用户近期对某个频道的偏爱,该视频已曝光给用户的次数可以减少视频多次无效曝光,增加用户看到新视频的概率。此外,还对后两个特征都进行了归一化和非线性操作。
【优化目标】:采用加权逻辑回归,预测用户对每个视频的期望观看时长,而不是简单地采用点击率预估,这样可以避免标题党、骗点击的视频。只有用户真实点击进视频,并进行了一定时长的观看,才能反映用户对该视频的兴趣。

为什么采用加权逻辑回归训练后得到的e^(Wx+b)就是预期用户观看视频时长?
首先定义事情的发生比,即事情发生/不发生的概率:

对两边取自然对数,再令它等于一个线性函数,即可得到:

因此sigmoid函数的计算结果就是视频被点击的概率!模型推理过程的输出即为视频被点击的概率比!
采用加权逻辑回归模型进行训练,权重wi为用户观看视频的时长,会让正样本的发生概率扩大wi倍,因此:

在视频推荐场景中,用户打开一个视频的概率很小,因此可以简化公式:

由此得到,模型推理过程的输出即为视频被点击的加权概率比,近似为用户观看视频时长的期望!
推导过程来自王喆老师的文章,讲得很清晰:揭开YouTube深度推荐系统模型Serving之谜 - 知乎
小结:
youtube DNN提供了很多工程经验,例如召回和排序模型的优化目标、训练样本的选取,以及针对youtube平台的专属特征构造。博客里关于物品embedding和example age加入了一些个人的理解,有不当之处,请大家多多指教。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)