1B小模型完胜405B巨无霸!上海AILab新突破
小模型靠「过程监督」逆袭大模型性能边界
在大型语言模型(LLM)领域,"以算力换性能"的测试时拓展(Test Time Scaling TTS)技术迎来革命性突破!上海AI Lab联合清华、哈工大等机构的最新研究发现,通过计算最优TTS策略,1B参数的"小模型"竟能在数学推理任务上完胜405B参数的"巨无霸"模型,甚至在MATH-500基准中,0.5B模型表现碾压GPT-4o,7B模型直接击败业界顶尖的o1和DeepSeek-R1。
这项发表于2025年2月的最新研究不仅打破了"参数至上"的固有认知,更开创了推理优化新范式——通过精细化分配每秒175万亿次浮点运算的计算预算,让轻量化模型在特定领域实现跨越式进化。 未来,该框架或将重塑AI部署格局,使终端设备的小模型通过智能算力调度,获得媲美云级大模型的能力,推荐阅读。
©️【深蓝AI】编译
本文由paper一作——Biqing Qi 授权【深蓝AI】编译发布!
论文标题:Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling
论文作者:Runze Liu, Junqi Gao, Jian Zhao, Kaiyan Zhang, Xiu Li, Biqing Qi, Wanli Ouyang, Bowen Zhou
论文链接:https://arxiv.org/pdf/2502.06703
项目链接:https://ryanliu112.github.io/compute-optimal-tts/
01 摘要
测试时间拓展(Test-Time Scaling, TTS)是一种通过在推理阶段使用额外计算来提升大型语言模型(LLMs)性能的重要方法。然而,当前研究尚未系统分析策略模型(policy models)、过程奖励模型(Process Reward Models, PRMs)以及问题难度如何影响TTS效果,这种分析缺失限制了对TTS方法的理解和实际应用,而这篇工作很好的填补了这一片空白。
本研究聚焦两个核心问题:
1.如何在不同策略模型、PRMs和问题难度水平之间优化测试时间计算的扩展策略?
2.通过扩展计算能力,LLMs在复杂任务上的性能提升上限如何?小型语言模型能否通过此方法超越更大模型?
通过在MATH-500和AIME24两个数学推理基准上的全面实验,研究人员得出以下重要发现:
1.计算最优的TTS策略高度依赖于策略模型选择、PRM设计和问题难度分级。
2.模型规模并非性能决定因素,采用计算最优TTS策略后,极小规模模型可超越大型模型。
3.TTS有效性呈现显著的任务难度依赖性。
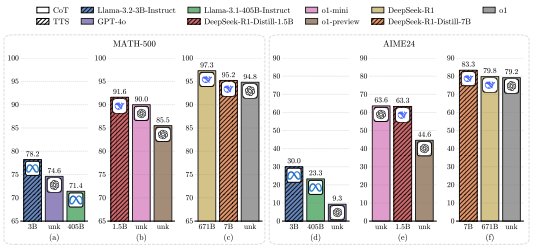
▲图1| 较小规模语言模型(LLMs)采用计算优化的测试时间扩展策略(TTS)与较大规模模型使用思维链(CoT)方法在MATH-500和AIME24任务上的性能对比©️【深蓝AI】编译
(a)&(d) Llama-3.2-3B-Instruct在MATH-500和AIME24上均超越了Llama3.1-405B-Instruct和GPT-4o;
(b)&(e)DeepSeek-R1-Distill-1.5B在两项任务中表现优于o1-preview,且在MATH-500上超过o1-mini(后者的MATH-500 pass@1为90.0%);
(c)&(f) DeepSeek-R1-Distill-7B在两项任务上击败了o1(o1的MATH-500 pass@1为96.4%),并在AIME24上超越了其教师模型DeepSeek-R1。
02 引言
大型语言模型(Large Language Models, LLMs)已在多个领域展现出显著提升。近期,OpenAI的o1系列模型通过测试时扩展(Test-Time Scaling, TTS)技术,证明了在推理阶段分配额外计算资源能够有效增强LLMs的推理能力。这一方法通过扩展推理链(Chain of Thought, CoT)的长度,在数学、编程和科学推理等任务中取得了显著进展,并成为提升LLM性能的重要途径。相关研究也得到了Qwen团队(2024)、Kimi团队等(2025)及DeepSeek-AI等(2025)的实证支持,例如DeepSeek-R1通过强化学习进一步优化了模型的推理效能。
文本到测试时间缩放(Test-Time Scaling, TTS)方法可分为两大类:
1.内部TTS:通过训练大型语言模型(LLMs)以长思维链(Chain-of-Thought, CoT)实现“慢思考”(例如OpenAI在2024、DeepSeek-AI在2025年的研究);
2.外部TTS:在固定LLMs基础上,通过采样或搜索方法提升推理性能(例如Wu等2024、Snell等2024的工作)。外部TTS的核心挑战在于如何最优分配计算资源,即为每个问题分配最合适的计算量(Snell等2024)。
当前TTS方法通过过程奖励模型(Process Reward Models,PRMs)指导生成过程并选择最终答案,从而有效扩展测试时计算。这些方法涉及策略模型、PRMs和问题难度等多个关键因素,但学界对它们如何系统性影响TTS策略的研究仍有限。这一局限阻碍了社区全面理解TTS的有效性,也制约了计算最优TTS策略的进一步发展。
为了应对上述问题,本文旨在通过全面的实验分析,探究策略模型、过程奖励模型以及问题难度对TTS方法的影响。此外,研究人员还深入探索了TTS方法的具体特征与性能边界。具体而言,在MATH-500和极具挑战性的AIME24任务上进行了大量实验,使用了多种PRMs(涵盖不同模型系列的1.5B到720亿参数)以及多个策略模型(覆盖两个模型家族的0.5B到720亿参数)。实验结果表明,计算最优的TTS策略高度依赖于具体的策略模型、PRM和问题难度层级。在复杂的推理任务中,即使较小的模型(例如1B参数模型)通过应用计算最优的TTS策略,也能超越更大的模型(例如405B参数模型)甚至最先进的推理模型(如o1或DeepSeek-R1)。
这篇工作的贡献可总结如下:
1.全面评估不同TTS方法:使用多种最新策略模型、PRMs、多样化扩展方法(scaling methods)以及更具挑战性的任务,对不同的TTS方法进行了系统性评估。
2.奖励感知的计算最优TTS:研究人员的分析揭示了在TTS过程中考虑奖励影响的必要性,并提出了奖励感知的计算最优TTS方法。实验表明,计算最优的扩展策略会因策略模型、PRM类型及问题难度不同而动态变化。
3.小模型超越大模型的潜力:实证结果表明,通过TTS策略,小型语言模型(LLM)具备显著超越大型模型的潜力。例如,采用奖励感知的计算最优TTS策略时,3B参数的LLM在MATH-500和AIME24任务上可超越405B参数的LLM,而7B参数的LLM甚至能优于o1和DeepSeek-R1模型。
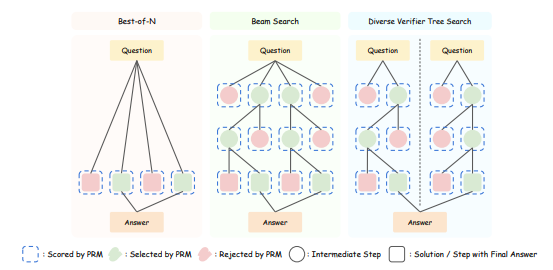
▲图2| 不同外部TTS方法的对比©️【深蓝AI】编译
03 前置知识
3.1. 问题定义
研究人员将推理问题建模为马尔可夫决策过程(Markov Decision Process, MDP),其由五元组 定义。其中:
● 为状态空间,表示所有可能状态的集合;
● 为动作空间,表示智能体可执行的动作集合;
● 为状态转移函数,描述在状态 s 执行动作a 后转移到新状态的概率分布;
●为奖励函数,给出在状态s执行动作a后获得的即时奖励;
●为折扣因子,用于平衡当前与未来奖励的重要性。
给定一个提示(prompt),参数为𝜃的策略会生成初始动作
,其中初始状态
。此时策略将获得奖励
,状态随之转移为
(符号[·, ·]表示字符串拼接)。该过程持续进行,直到达到最大步数或生成终止符
。最终,一条长度为 𝐻的轨迹可表示为
。
3.2. 测试时扩展方法
研究人员选取了三种测试时计算扩展(TTS)方法:最佳N选一(Best-of-N,BoN)、集束搜索(Beam Search),以及多样化验证器树搜索(Diverse Verifier Tree Search,DVTS)。处于效率的考虑,研究人员并未评估该方法及其他包含前瞻操作的算法(如蒙特卡洛树搜索,MCTS)。但笔者认为包含前瞻操作的搜索算法其实对推理结果有着重要的影响,例如最近大火的DeepSeek R1 Zero就是实现了类似MCTS的推理过程从而取得了较好的推理结果,期待研究人员在未来工作中能够涵盖一些包含前瞻操作的测评。
最佳N选一(BoN)
在BoN方法中,策略模型首先生成𝑁个响应,随后通过评分与投票机制选择最终答案。该方法适用于小规模模型(参数少于7B)处理简单问题,但面对复杂问题时性能有限。
集束搜索(Beam Search)
给定集束宽度𝑁和集束大小𝑀,策略模型首先生成𝑁个步骤,验证器从中筛选出前𝑁/𝑀个最优步骤进行后续搜索。在每一步中,模型会为每个选定的前序步骤采样𝑀个新步骤,直至达到最大深度或生成终止符。研究显示,集束搜索在处理困难问题时表现优异,尤其适合中等规模模型(7B-32B参数)。
多样化验证器树搜索(DVTS)
为提升多样性,DVTS通过将搜索过程分解为𝑁/𝑀个独立子树来扩展集束搜索。每个子树使用集束搜索独立探索,最终基于验证器分数选择最优路径。研究显示,在大计算预算(𝑁较大)下,DVTS在简单和中等问题上显著优于集束搜索,而在相同计算资源下,增加并行子树数量比增大集束宽度更有效。对于7B-32B参数的模型,DVTS在简单和中等问题上表现最佳,而72B超大模型则全面适用BoN。
3.3. 最优测试时扩展优化目标
为了最大化测试时间扩展(Test-Time Scaling, TTS)的性能,该研究采用了如下计算最优测试时间扩展策略,能通过根据给定的测试时间策略选择相应的超参数,在特定prompt下实现性能收益的最大化。给定一个prompt ,令代表输出在上基于模型参数𝜃以及计算开销𝑁的分布:
04 对计算最优的测试时扩展的改进
4.1. 计算最优的测试时扩展应具备奖励感知性
在前人的研究中大多使用单一的过程奖励模型作为验证器。例如,Snell等人(2024)在策略模型的响应数据上训练了一个PRM,并将其作为验证器,与同一策略模型共同执行TTS;而Wu等人和Beeching等人则使用基于不同策略模型训练的PRM进行TTS。从强化学习的角度看,前一种情况得到的是在线策略PRM(on-policy PRM),后一种则是离线策略PRM(offline PRM)。在线策略PRM能够为策略模型的响应提供更精确的奖励信号,而离线策略PRM由于分布外(OOD)问题,常会产生不准确的奖励。
针对计算最优TTS的实际应用,为每个策略模型单独训练一个PRM以防止分布外(OOD)问题,这在计算成本上是昂贵的。因此,研究人员提出了一种更通用的计算最优TTS策略配置:PRM可以在与TTS所用策略模型不同的模型上训练。对于基于搜索的方法(如树搜索),PRM通过指导每个响应步骤的选择来优化推理路径;而对于基于采样的方法(如随机采样),PRM则用于生成后的响应质量评估。这表明:(1) 奖励机制会影响所有方法的响应选择;(2) 对于基于搜索的方法,奖励还会深度参与搜索过程本身。
因此,研究人员将奖励整合到计算最优的测试时扩展(TTS)策略中。将奖励函数表示为ℛ,奖励感知计算最优TTS策略可表述为:
研究人员使用Llama-3.1-8BInstruct作为策略模型,以RLHFlow-PRM-Mistral-8B和RLHFlow-PRM-Deepseek-8B作为偏好奖励模型(PRM),通过束搜索(beam search)进行了初步实验。图12的结果表明,奖励机制会显著影响生成过程和最终结果:RLHFlow-PRM-Mistral-8B倾向于对短响应赋予高奖励值,但这导致生成错误答案;而使用RLHFlow-Deepseek-PRM-8B进行搜索时,尽管能产生正确答案,却需要消耗更多token。
05 如何对测试时计算进行最有扩展
研究人员通过实验回答了下面三个问题:
-
Q1:采用不同策略模型和PRMs时,TTS如何实现性能提升?
-
Q2:面对不同难度级别的问题,TTS的改进效果呈现何种差异?
-
Q3:PRMs是否对特定响应长度存在偏好,或对投票方法表现出敏感性?
5.1. 实验设置
数据集
研究人员在竞赛级数学数据集上进行了实验,包括MATH500和AIME24。MATH-500包含从MATH测试集中精选的500个代表性数学问题,而AIME2024中存在着更具挑战性问题。
策略模型
研究人员选择不同尺寸的Llama3系列和Qwen2.5系列作为TTS方法的策略模型,所有的策略模型均选用Instruct版本。
过程奖励模型
研究人员选取了如下开源的PRMs用作评估:
-
Math-Shepherd
Math-Shepherd-PRM-7B 是基于 Mistral-7B训练的模型,其训练数据为通过 MetaMath微调后的 Mistral-7B 生成的 PRM 数据。该方法通过自动生成过程监督数据,避免了人工标注的成本,显著提升了模型的数学推理能力。
-
RLHFlow 系列
该系列包括 RLHFlow-PRM-Mistral-8B 和 RLHFlow-PRM-Deepseek-8B。前者基于 MetaMath 微调的 Mistral-7B 生成数据,后者基于 deepseek-math-7b-instruct生成数据。两者的基础模型均为 Llama-3.1-8B-Instruct。实验表明,RLHFlow-PRM-Deepseek-8B 的训练数据响应长度更长,可能导致输出偏差。
-
Skywork 系列
包含 Skywork-PRM-1.5B 和 Skywork-PRM-7B,分别基于 Qwen2.5-Math-1.5B-Instruct 和 Qwen2.5-Math-7B-Instruct训练。训练数据由 Llama-2在数学数据集上微调后的模型与 Qwen2-Math系列模型生成。研究指出,使用 Skywork-PRM-7B 进行推理的搜索效率较高。
-
Qwen2.5-Math 系列
评估的模型包括 Qwen2.5-Math-PRM-7B 和 Qwen2.5-Math-PRM-72B,分别基于 Qwen2.5-Math-7B-Instruct 和 Qwen2.5-Math-72B-Instruct训练。其数据由 Qwen2-Math和 Qwen2.5-Math 系列模型生成。Qwen2.5-Math-PRM-72B 是目前数学任务中最强的开源 PRM 模型,而 Qwen2.5-Math-PRM-7B 则在 7B/8B 参数规模的模型中表现最佳。对比实验显示,Qwen2.5-Math-PRM-72B 在 GSM8K 和 MATH500 数据集上的准确率分别达到 89.1% 和 43.5%。
打分与投票方法
研究人员采用了以下三种评分方法和三种投票方法:
评分方法
1.对于长度为𝐻的轨迹(trajectory),不同评分方法的计算方式如下:PRM-Min:以所有步骤中的最小奖励值为轨迹评分,即
2.该方法通过筛选轨迹中的最弱环节进行评分(与PRM-Last效果相当)。PRM-Last:以最后一步的奖励值为轨迹评分,即
3.score=RHscore=RH PRM-Avg:以所有步骤的平均奖励值为轨迹评分,即
投票方法
1.评分完成后,通过投票方法聚合结果以确定最终答案:多数投票(Majority Vote) :选择得票数最多的答案。
2.PRM-Max:选择评分最高的答案,即
最优答案=
3.PRM-Vote:先将所有相同答案的评分累加,再选择总分最高的答案。
研究人员将OpenR2(一个开源的大语言模型推理框架)作为代码基础进行实验。在计算资源配置方面,多数实验中我们采用{4, 16, 64, 256}四种不同规模的预算参数。步骤划分遵循先前研究中使用的"\n\n"分隔符格式。对于束搜索(Beam Search)和动态验证树搜索(DVTS)算法,波束宽度均设置为4。思维链(CoT)推理的温度参数设为0.0以保证确定性,而其他方法则采用0.7的温度值以增加多样性。
5.2. TTS如何提升不同的策略模型以及PRMs
研究人员通过实验发现,PRMs在不同策略模型和任务间的泛化能力存在显著差异。如图4所示,对于Llama3.1-8B-Instruct模型,基于搜索的方法在使用Skywork和Qwen2.5-Math的PRMs时,随着计算资源的增加,性能显著提升;而使用Math-Shepherd和RLHFlow的PRMs进行搜索时,结果仍然较差,甚至不如多数投票法。对于Qwen2.5-7B-Instruct模型,使用Skywork-PRM-7B和Qwen2.5-Math的PRMs在更大计算资源下表现良好,但其他PRMs的性能依然不佳。图5显示,尽管两种策略模型的Pass@k准确率均随计算资源增加而大幅提升,但TTS(逐步推理搜索)的性能改进幅度仍然有限。这些结果表明,PRMs在不同策略模型和任务间的泛化能力尤为困难,尤其是在更复杂的任务中。
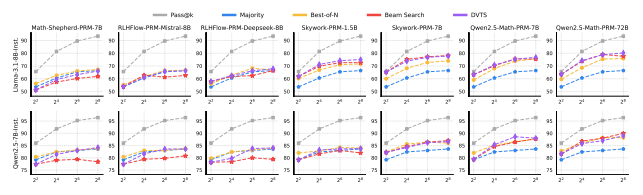
▲图3|Llama-3.1-8B-Instruct 和 Qwen2.5-7B-Instruct 在 MATH-500 基准测试中,采用不同过程奖励模型(PRMs)与测试时间扩展(TTS)策略的性能表现©️【深蓝AI】编译
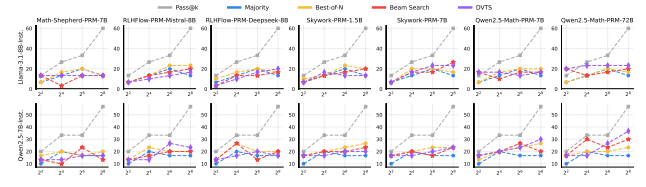
▲图4|Llama-3.1-8B-Instruct 和 Qwen2.5-7B-Instruct 在 AIME24 基准测试中,采用不同过程奖励模型(PRMs)与测试时间扩展(TTS)策略的性能表现©️【深蓝AI】编译
研究人员通过实验发现,最优的TTS方法取决于所使用的PRM。如图4所示,当使用Math-Shepherd和RLHFlow PRM时,Best-of-N(BoN)策略在大多数情况下优于其他方法;而基于搜索的方法在使用Skywork和Qwen2.5-Math PRM时表现更好。这种差异可能源于以下原因:当PRM用于评估超出分布(OOD)的策略响应时,其泛化能力有限,可能导致次优答案。此外,若使用OOD PRM对推理的每一步进行选择,容易使答案陷入局部最优,从而降低整体性能。
这种现象可能与PRM的基座模型特性有关。例如,在PRM800K数据集训练的基于Qwen2.5-Math-7BInstruct模型PRM展现出比基于Mistral和Llama基模型的PRM更强的泛化能力。这些结果表明,最优TTS策略的选择需结合具体PRM的特性,并需在计算优化中充分考虑奖励信息的作用。
研究人员还探索了TTS性能与PRM过程监督能力的相关性。如图6所示,两者呈正相关关系,拟合函数为𝑌 = 7.66 log(𝑋) + 44.31,其中𝑌代表TTS性能,𝑋代表PRM的过程监督能力。
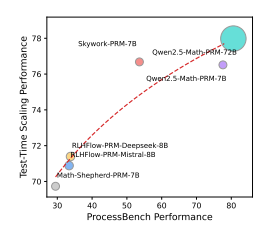
▲图5|不同PRM(过程监督模型)在MATH数据集上的TTS(测试时Scaling策略)性能与其过程监督能力之间的关系图示,其中每个圆圈的大小代表PRM的参数规模,曲线表示经过拟合的函数关系©️【深蓝AI】编译

▲图6|在MATH-500基准测试集上参数量从0.5B到72B的策略模型不同扩展方法的TTS性能©️【深蓝AI】编译
最优的TTS方法的选择还与策略模型的参数规模密切相关。为了探究策略模型参数量与最优TTS方法的关系,研究人员基于Qwen2.5系列涵盖参数量为0.5B、1.5B、3B、7B、14B、32B和72B的多种模型展开实验。图7的实验结果表明,最优TTS方法的选择高度依赖于具体策略模型的规模:对于小型策略模型(如0.5B-7B),基于搜索的方法(search-based methods)优于BoN(Best-of-N)策略;而对于大型策略模型(如14B-72B),BoN则展现出更高的有效性。从这一差异中可以得出这样的结论——大型模型具备更强的推理能力,无需依赖验证器(verifier)逐步骤筛选结果;而小型模型则需通过验证器确保每个中间步骤的正确性,以弥补其推理能力的不足。
5.3. TTS如何对不同难度的问题进行提升
遵循Snell等人(2024)的研究框架,我们对不同难度层级的任务进行了全面评估。然而,如上文所述,我们发现使用MATH数据集定义的难度等级或基于Pass@1准确率分位数的理想标签并不适用,因为不同策略模型展现出差异化的推理能力。为解决这一问题,我们依据Pass@1准确率的绝对值将难度划分为三个层级:简单(50%~100%)、中等(10%~50%)和困难(0%~10%)。
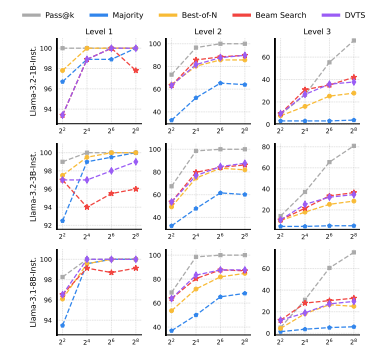
▲图7|三个不同参数Llama模型在不同难度 MATH-500测试基准上的表现©️【深蓝AI】编译
最优的TTS方法随问题难度级别的不同而变化。图8和图9的结果显示:
-
对于较小的策略模型(即参数少于70亿的模型),最佳响应生成(BoN)在简单问题上表现更优,而波束搜索(Beam Search)则在困难问题上效果更佳;
-
对于参数规模在70亿至320亿之间的策略模型,多样化验证器树搜索(DVTS)在简单和中等难度问题上表现良好,而波束搜索仍是处理困难问题的首选方法;
-
对于拥有720亿参数的策略模型,最佳响应生成(BoN)在所有难度级别上均为最佳方法。
5.4. PRMs会受到特定长度的回复或者投票方法的影响吗

▲表1|RLHFlow PRMs数据统计©️【深蓝AI】编译
PRMs存在对步骤长度的偏好。尽管我们在之前的实验中采用了相同的计算资源进行TTS,但发现不同PRM模型生成的推理token数量存在显著差异。例如,在相同计算资源和相同策略模型条件下,使用RLHFlow-PRM-Deepseek-8B进行扩展时产生的推理令牌数始终高于RLHFlow-PRM-Mistral-8B,差距接近两倍。这种差异可能源于RLHFlow系列PRM训练数据采样自不同的大语言模型(LLMs),导致对输出长度的偏好偏差。为验证该假设,我们分析了RLHFlow-PRM-Mistral-8B和RLHFlow-PRM-Deepseek-8B训练数据的特性。如表1所示,DeepSeek-PRM-Data在每轮响应的平均token数和每步的平均token数均超过Mistral-PRM-Data,表明RLHFlow-PRM-Deepseek-8B的训练数据长度更大,这可能导致对输出长度的偏好。
另一个发现是,虽然使用Qwen2.5-Math-7B进行扩展时产生的推理token数多于Skywork-PRM-7B,但两者的性能却非常接近。这表明相较于Qwen2.5-Math-7B,使用Skywork-PRM-7B进行搜索具有更高的效率。这一现象暗示PRM的选择不仅影响计算资源消耗,还涉及效率与性能的平衡问题。研究进一步表明,TTS的效果与PRM的过程监督能力呈正相关,过程监督能力越强的PRM往往能带来更优的TTS性能。
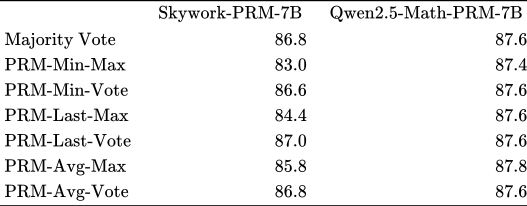
▲表2|MATH-500 基准测试集上不同投票方法对TTS的影响©️【深蓝AI】编译
PRMs对投票方法具有敏感性。表2的结果显示,SkyworkPRM-7B在使用PRM-Vote方法时表现优于PRM-Max方法,而Qwen2.5-Math-PRM-7B对投票方法的选择不敏感。这主要是因为Qwen2.5-Math PRM的训练数据采用了LLM-as-a-judge(大语言模型作为判断器)的处理方式,移除了训练数据中被错误标记为"正样本"的错误中间步骤,使得输出的高奖励值更可能对应正确答案。这表明,PRM的训练数据质量对提升其在搜索过程中识别错误的能力至关重要。
06 计算最优扩展的结果
基于上文探讨的计算最优TTS策略,研究人员采取了进一步实验研究回答以下问题:
-
Q4:在计算最优TTS策略下,较小的策略模型能否超越更大的模型?
-
Q5:与思维链(CoT)和多数投票法相比,计算最优TTS策略如何实现性能提升?
-
Q6:TTS方法是否比基于长链思维链(long-CoT)的方法更有效?
6.1. 在计算最优TTS策略下,较小的策略模型能否超越更大的模型?
基于上文的实验结果,不难得出如下猜想,通过计算最优的TTS策略,较小的策略模型能否超越更大的模型(如GPT-4o、o1和DeepSeek-R1)?首先,研究人员比较了Llama-3.2-3B-Instruct(采用计算最优TTS)与Llama-3.1-405B-Instruct(采用链式推理CoT)在MATH-500和AIME24任务上的表现。此外,还将Qwen2.5-0.5B-Instruct、Qwen2.5-1.5B-Instruct、Llama-3.2-1B-Instruct和Llama-3.2-3B-Instruct与GPT-4o在上述两个任务中进行对比。
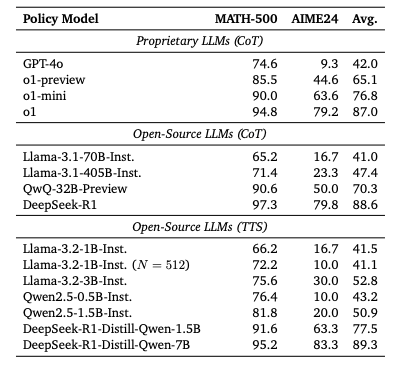
▲表3|带有CoT的小型策略模型在MATH-500和AIME24上的对比©️【深蓝AI】编译
从表3的结果中,研究人员得出以下观察:
(1)采用计算最优TTS策略的 Llama-3.2-3B-Instruct在 MATH-500 和 AIME24 上优于Llama-3.1-405B-Instruct,这表明较小的模型通过计算最优 TTS 策略可以超越参数规模大 135 倍的模型。
(2)若进一步将计算预算增至 N=512,采用计算最优 TTS 策略的 Llama-3.2-1B-Instruct在 MATH-500 上击败了Llama-3.1-405B-Instruct,但在 AIME24 上表现略逊。
(3)采用计算最优 TTS 策略的 Qwen2.5-0.5B-Instruct和Llama-3.2-3B-Instruct均超越GPT-4o,证明小模型可通过计算最优 TTS 策略达到甚至超越 GPT 级别性能。
(4)采用计算最优 TTS 策略的 DeepSeek-R1-Distill-Qwen-1.5B在 MATH-500 和 AIME24 上优于o1-preview和o1-mini;而DeepSeek-R1-Distill-Qwen-7B在相同策略下进一步超越o1和DeepSeek-R1。这些结果表明,增强推理能力的小模型可通过计算最优 TTS 策略超越前沿大型推理模型。
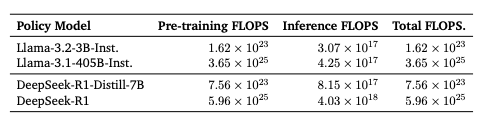
▲表4|不同模型的FLOPS对比©️【深蓝AI】编译
FLOPS对比分析。为了回答计算最优TTS是否比扩大模型规模更有效的问题,研究人员还在表4中比较了各模型的FLOPS。从结果可见,小型策略模型即使在使用更少推理FLOPS的情况下也能超越大型模型,并将总FLOPS减少了100-1000倍。
6.2. 与思维链(CoT)和多数投票法相比,计算最优TTS策略如何实现性能提升?
根据对不同策略模型、PRMs和问题难度下计算最优TTS的研究结果,在表5中总结了MATH-500数据集上各策略模型的计算最优TTS结果。结果显示,计算最优的TTS策略相比多数投票方法效率提升256倍,且相比思维链(CoT)在推理性能上提升了154.6%。这可以说明,计算最优的TTS策略能显著增强大型语言模型的推理能力。然而,随着策略模型参数量的增加,TTS带来的性能提升逐渐减弱,这意味着TTS的有效性与策略模型本身的推理能力直接相关——当策略模型自身推理能力较弱时,扩展测试时计算可带来显著改进;但对推理能力较强的模型,增益则较为有限。
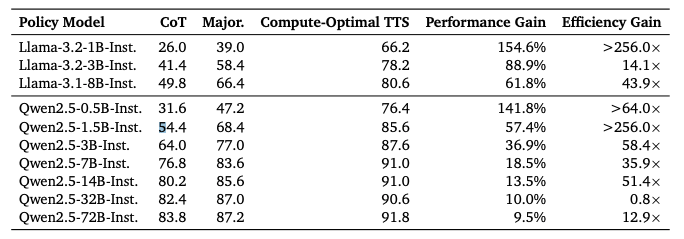
▲表5|不同策略模型基于TTS,CoT以及多数投票方法在MATH-500上的对比©️【深蓝AI】编译
6.3. TTS方法是否比基于长链思维链(long-CoT)的方法更有效?
近年来,基于长链式思维(Chain-of-Thought, CoT)的方法在数学推理领域取得了显著进展。研究人员还将TTS模型与这些方法进行了对比。
实验设置
研究人员评估了以下方法:
(1) rStar-Math:该方法首先通过蒙特卡洛树搜索(MCTS)生成推理数据,随后进行在线策略学习和偏好模型训练。通过四轮自进化,rStar-Math在MATH基准测试中将Qwen2.5-Math-7B的准确率从58.8%提升至90.0%。
(2) Eurus-2:该方法通过隐式过程奖励和在线强化学习(RL)增强语言模型的推理能力。尽管具体技术细节未在现有资料中详细展开,但其核心思想与强化学习框架下优化推理轨迹的策略一致。
(3) SimpleRL:该方法仅使用8K训练数据复现自我反思能力,体现了小样本条件下高效利用数据的特点。
(4) Satori :该方法分两阶段提升推理能力:首先学习问题解决的标准格式,随后通过强化学习进一步优化推理过程。
(5) DeepSeek-R1-Distill-Qwen-7B:该方法从参数规模达671B的DeepSeek-R1模型中蒸馏出80万高质量数学推理样本,并将其压缩至7B规模的模型中。这一蒸馏过程旨在保留大模型推理能力的同时降低计算资源需求。
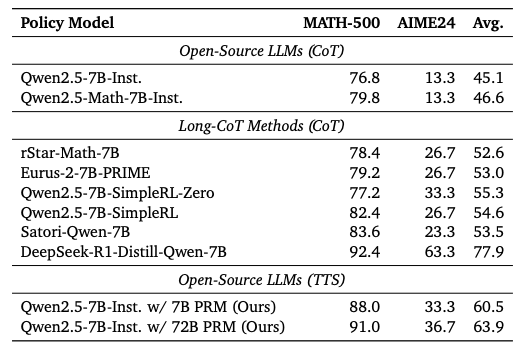
▲表6|计算最优TTS和long-CoT方法在MATH-500 和 AIME24基准上的对比©️【深蓝AI】编译
根据表6所示,发现采用Qwen2.5-7B-Instruct的TTS在MATH-500和AIME24基准测试中均优于rStar-Math、Eurus-2、SimpleRL和Satori模型。然而,尽管TTS在MATH-500上的表现与DeepSeek-R1-Distill-Qwen-7B接近,但在更复杂的AIME24任务上却出现了显著下降。这一结果表明:相较于直接在蒙特卡洛树搜索(MCTS)生成数据上应用强化学习(RL)或监督微调(SFT)的方法,TTS策略更为有效;但相比于从强推理模型中进行知识蒸馏的方法仍存在差距。此外,TTS在简单任务上的有效性明显优于复杂任务。
07 结论
本文通过系统实证分析,从不同策略模型、过程奖励模型(PRMs)和任务难度三个维度探讨了计算最优测试时间扩展(TTS)策略的优化路径。研究发现,TTS的最优策略高度依赖于三个关键因素:(1) 策略模型的选择(如模型参数规模);(2) 过程奖励模型的质量;(3) 待解决问题的难度等级。尤其值得注意的是,在计算最优TTS策略下,小规模语言模型(如1B参数)能够超越规模更大的模型(如405B参数),这颠覆了传统"模型越大性能越强"的固有认知。
实验结果表明,采用计算最优TTS策略时,1B参数模型通过优化测试时计算资源分配,在数学推理(MATH-500)和复杂问题(AIME24)等基准测试中表现优于405B基线模型。更有启发的是,研究发现7B参数的PRM能够有效监督72B规模的策略模型,这为"弱监督强"(weak-to-strong)的新型优化范式提供了实证支持,而非当前主流的"强监督弱"(strong-to-weak)模式。这一发现表明,PRM的质量可能比其规模更重要,较小的PRM通过精细化的过程监督也能指导大模型的优化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)