港中文联合腾讯提出VideoPainter!任意长度视频修复和编辑新SOTA!
视频修复对于媒体行业至关重要,其目标是恢复受损的内容。然而,目前依赖有限像素传播或单分支图像修复架构的方法在生成完全被遮挡的物体、平衡背景保留与前景生成,以及在长视频中保持身份一致性方面面临挑战。为解决这些问题,我们提出了VideoPainter(视频绘制器),这是一个高效的双分支框架,具有轻量级上下文编码器。这个即插即用的编码器处理被遮挡的视频,并将背景引导信息注入任何预训练的视频扩散变换器中,
🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:VideoPainter: Any-length Video Inpainting and Editing with Plug-and-Play Context Control
论文链接:https://arxiv.org/pdf/2503.05639
开源代码:https://yxbian23.github.io/project/video-painter/

导读
视频修复旨在恢复受损视频并保持连贯性,它推动了众多应用的发展,包括试穿、电影制作和视频编辑。最近,扩散变压器(Diffusion Transformers,DiT)在视频生成方面展现出了潜力,促使人们对生成式视频修复进行探索。
简介
视频修复对于媒体行业至关重要,其目标是恢复受损的内容。然而,目前依赖有限像素传播或单分支图像修复架构的方法在生成完全被遮挡的物体、平衡背景保留与前景生成,以及在长视频中保持身份一致性方面面临挑战。为解决这些问题,我们提出了VideoPainter(视频绘制器),这是一个高效的双分支框架,具有轻量级上下文编码器。这个即插即用的编码器处理被遮挡的视频,并将背景引导信息注入任何预训练的视频扩散变换器中,可适用于任意类型的遮挡,增强背景融合和前景生成,并支持用户自定义控制。我们进一步引入了一种对修复区域进行重采样的策略,以在任意长度的视频修复中保持身份一致性。此外,我们使用先进的视觉模型开发了一个可扩展的数据集管道,并构建了VPData和VPBench(带分割掩码和密集字幕的最大视频修复数据集,个片段),以支持大规模的训练和评估。我们还展示了VideoPainter在视频编辑等下游应用中的良好潜力。大量实验表明,VideoPainter在包括视频质量、遮挡区域保留和文本连贯性等8项关键指标的任意长度视频修复和编辑方面达到了最先进的性能。
方法与模型
图3展示了我们构建VPData和VPBench的流程。3.2节和图4展示了我们的双分支视频修复器(VideoPainter)。3.3节和3.4节介绍了我们用于任意长度视频修复和即插即用控制的修复区域ID重采样方法。
1. VPData和VPBench构建流程
为应对规模有限和缺乏文本标注的挑战,我们提出了一种可扩展的数据集流程,该流程利用了先进的视觉模型[OpenAI 2024;Ravi等人2024;Zhang等人2024a]。这催生了VPData和VPBench,它们是最大的视频修复数据集和基准,具有精确的掩码以及视频/掩码区域的字幕。如图3所示,该流程包括5个步骤:收集、标注、划分、选择和添加字幕。
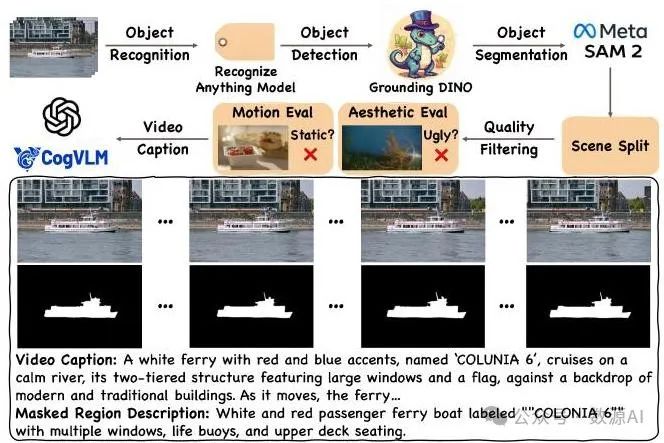
图3. 数据集构建流程。它包括五个预处理步骤:收集、标注、划分、选择和添加字幕。
收集。我们选择了Videvo和Pexels 作为我们的数据源。我们最终从这些来源获得了大约个视频。
标注。对于每个收集到的视频,我们实施了一个级联工作流程来进行自动标注:
我们采用识别任意事物模型(Recognize Anything Model,[Zhang等人,2024a])进行开放集视频标注,以识别主要对象。
基于检测到的对象标签,我们利用接地恐龙模型(Grounding DINO,[Liu等人,2023])以固定间隔检测对象的边界框。
这些边界框作为SAM2(拉维等人,2024年)的提示,该模型可生成高质量的掩码分割结果。
分割。在从不同角度跟踪同一对象时可能会发生场景转换,导致视图发生突变。我们使用PySceneDetect(卡斯特利亚诺,2024年)来识别场景转换,随后对掩码进行分割。然后,我们将序列分割成10秒的间隔,并舍弃短片段(< 6秒)。筛选。我们采用3个关键标准:(1)美学质量,使用Laion美学分数预测器(舒曼等人,2022年)进行评估;(2)运动强度,通过使用RAFT(蒂德和邓,2020年)进行光流测量来预测;(3)内容安全性,通过稳定扩散安全检查器(龙巴赫等人,2022年)进行评估。
字幕生成。如表1所示,现有的视频分割数据集缺乏文本注释,而文本注释是生成任务的基本条件[贝特克(Betker)等人,2023年;陈(Chen)等人,2023年],这为将生成模型应用于视频修复造成了数据瓶颈。因此,我们利用最先进的视觉语言模型(VLM),特别是CogVLM2[王(Wang)等人,2023年]和GPT - 4o[OpenAI,2024年],对关键帧进行均匀采样,并生成密集的视频字幕以及被遮挡对象的详细描述。
2. 双分支修复控制
我们通过一个高效的上下文编码器将被遮挡的视频特征融入预训练的扩散变压器(DiT)中,以分离背景上下文提取和前景生成。该编码器处理由噪声潜变量、被遮挡视频潜变量和下采样掩码组成的拼接输入。具体而言,噪声潜变量提供当前生成的相关信息。通过变分自编码器(VAE)提取的被遮挡视频潜变量与预训练的DiT的潜变量分布相匹配。我们应用三次插值对掩码进行下采样,以确保掩码和潜变量之间的维度兼容性。
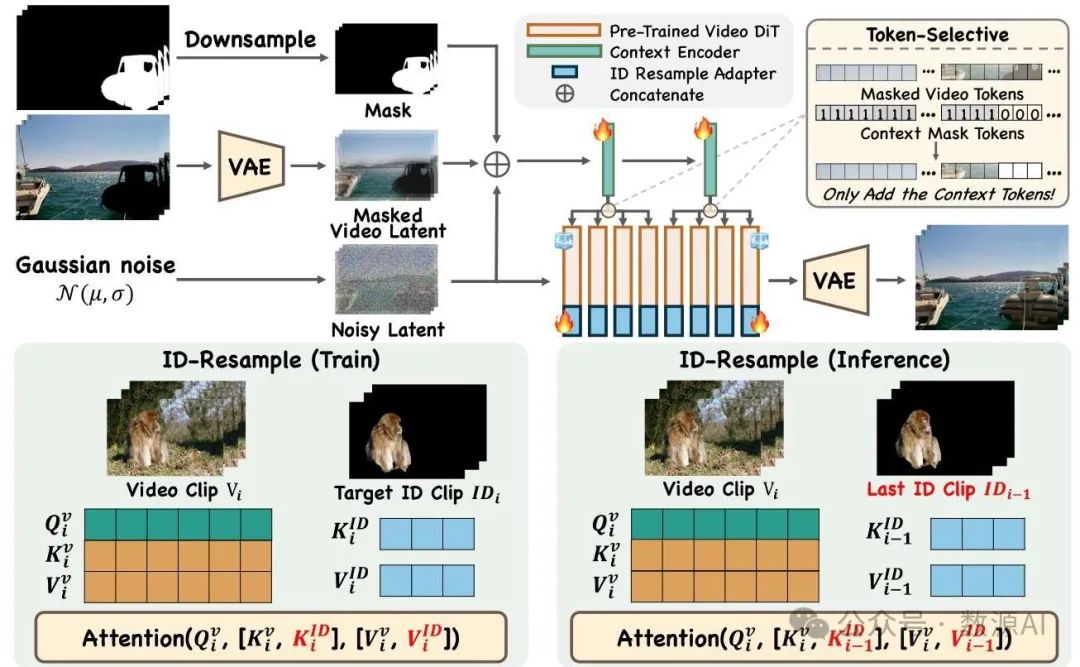
图4. 模型概述。上图展示了VideoPainter的架构。上下文编码器基于噪声潜变量、下采样掩码和通过变分自编码器(VAE)得到的掩码视频潜变量的拼接来执行视频修复。上下文编码器提取的特征以分组和令牌选择的方式集成到预训练的DiT中,其中两层编码器分别对DiT的前半部分和后半部分进行调制,并且仅将背景令牌集成到主干中以防止信息模糊。下图说明了使用ID重采样适配器对修复ID区域进行重采样。在训练期间,当前掩码区域的令牌被拼接到键值(KV)向量中,以增强修复区域的ID保留。在推理期间,最后一个剪辑的ID令牌被拼接到当前的KV向量中,通过重采样保持与最后一个剪辑的ID一致性。
基于DiT(扩散变压器,Diffusion Transformer)固有的生成能力 [OpenAI 2024],控制分支只需提取上下文线索,以引导主干网络保留背景并生成前景。因此,与之前复制主干网络一半或全部结构的复杂方法 [Ju等人 2024;Zhang等人 2023] 不同,VideoPainter采用轻量级设计,仅克隆预训练DiT的前两层,仅占主干网络参数的6%。预训练的DiT权重为提取掩码视频特征提供了强大的先验信息。上下文编码器特征以分组、令牌选择的方式集成到冻结的DiT中。分组特征集成的公式如下:将第一层的特征添加回主干网络的前半部分,而将第二层的特征集成到后半部分,实现轻量级且高效的上下文控制。令牌选择机制是一个预过滤过程,如图4右上角所示,仅将代表纯背景的令牌添加回去,而排除其他令牌的集成。这确保了只有背景上下文被融合到主干网络中,防止在主干网络生成过程中出现潜在的歧义。
特征整合如公式1所示。表示DiT 中第层的特征,其中 ,这里是层数。相同的表示法适用于 ,它将拼接后的噪声潜在特征、掩码视频潜在特征和下采样掩码作为输入。拼接操作表示为 是零线性操作。
3. 目标区域ID重采样
虽然当前的扩散变压器(DiTs)在处理时间动态方面显示出了潜力[边等人,2024年;快手,2024年],但它们难以保持平滑过渡和长期身份一致性。
平滑过渡。遵循AVID方法[张等人,2024b],我们采用重叠生成和加权平均的方法来保持一致的过渡。此外,我们将前一个剪辑的最后一帧(重叠之前)用作当前剪辑重叠区域的第一帧,以确保视觉外观的连续性。
身份一致性。为了在长视频中保持身份一致性,我们引入了一种修复区域身份重采样方法,如图4下部所示。在训练过程中,我们冻结扩散变压器(DiT)和上下文编码器。然后,我们将可训练的身份重采样适配器添加到冻结的扩散变压器(低秩自适应,LoRA)中,以实现身份重采样功能。具体而言,将当前掩码区域中包含所需身份信息的标记与键值(KV)向量进行拼接,从而通过额外的键值重采样增强修复区域中的身份信息保留。具体来说,给定当前的和,我们过滤当前和中的掩码区域标记,并将它们拼接至和,迫使模型对具有所需身份信息的这些标记进行重采样。在推理过程中,我们优先与前一帧剪辑中的修复区域标记保持身份一致性,因为它代表了时间上最接近的生成结果。因此,我们将前一帧剪辑中的掩码区域标记与当前的键值向量进行拼接,从而在长视频处理中有效地重采样并保持身份信息。
4. 即插即用控制
我们的即插即用框架在两个方面展现出了通用性:它支持各种风格化主干网络或低秩自适应(LoRA,Low-Rank Adaptation),并且与文本到视频(T2V,Text-to-Video)[英伟达(NVIDIA)2025年;杨等人2024年]和图像到视频(I2V,Image-to-Video)[郭等人2024年;施等人2024年]的去噪扩散变压器(DiT,Denoising Diffusion Transformer)架构兼容。I2V兼容性尤其能够与现有的图像修复功能实现无缝集成。当使用I2V DiT主干网络时,VideoPainter只需要额外增加一个步骤:使用任何由掩码区域的文本描述引导的图像修复模型生成初始帧。这个修复后的帧随后既作为图像条件,又作为第一个掩码视频帧。这些能力进一步证明了VideoPainter具有出色的可迁移性和通用性。
实验与结果
1. 实现细节
VideoPainter 基于预训练的图像到视频扩散变换器 CogVideo - 5B - I2V [Yang 等人,2024 年](默认)及其文本到视频版本构建。在训练过程中,我们使用分辨率为 的 VPData,学习率为 ,在 64 块英伟达 V100 GPU 上使用 AdamW 优化器分两个阶段进行训练,上下文编码器训练 80,000 步,ID 重采样适配器训练 2,000 步,批量大小均为 1。
基准测试。在视频修复方面,我们采用戴维斯数据集(Davis [佩拉齐等人(Perazzi et al.),2016 年])作为随机掩码的基准,采用 VPBench 作为基于分割的掩码的基准。VPBench 包含 100 个时长为 6 秒的视频用于标准视频修复,以及 16 个平均时长超过 30 秒的视频用于长视频修复。VP - Bench 包含了丰富多样的内容,如物体、人类、动物、风景以及多范围掩码。在视频编辑评估方面,我们同样使用 VPBench,它涵盖了四种基本的编辑操作(添加、移除、交换和更改),包含总时长为 456 秒的视频以及 9 个平均时长为 30 秒的视频。
评估指标。我们从三个方面考虑了 8 个评估指标:掩码区域保留、文本对齐和视频生成质量。
-
掩码区域保留。我们沿用以往的研究方法,在生成视频和原始视频的未掩码区域使用标准峰值信噪比(PSNR [维基百科贡献者(Wikipedia contributors),2024c])、学习感知图像块相似度(LPIPS [张等人(Zhang et al.),2018 年])、结构相似性指数(SSIM [王等人(Wang et al.),2004 年])、均方误差(MSE [维基百科贡献者(Wikipedia contributors),2024b])和平均绝对误差(MAE [维基百科贡献者(Wikipedia contributors),2024a])。
-
文本对齐。我们采用CLIP相似度(CLIP Sim)[Wu等人,2021年]来评估生成的视频与其对应的文本字幕之间的语义一致性。我们还测量了掩码区域内的CLIP相似度(CLIP Sim (M))。
-
视频生成质量。遵循先前的方法,我们使用FVID [Wang等人,2018年]来衡量生成的视频质量。
2. 视频修复
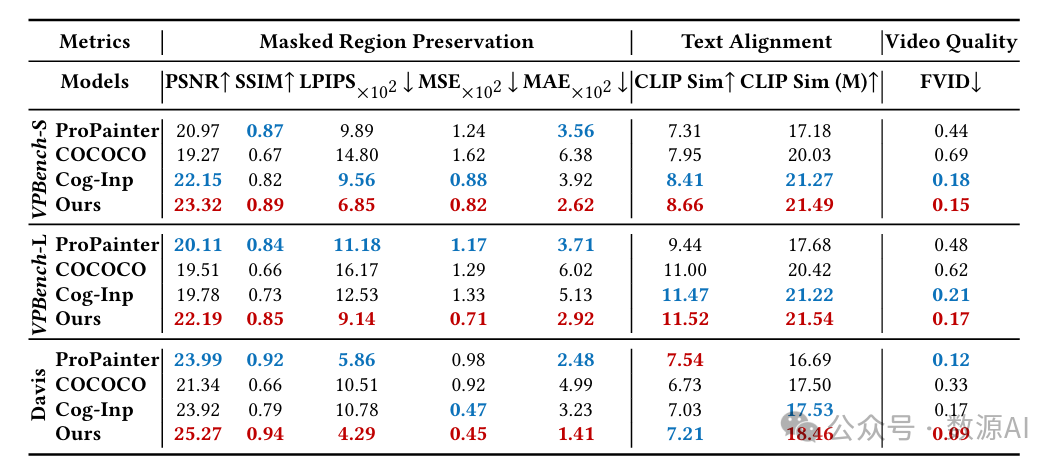
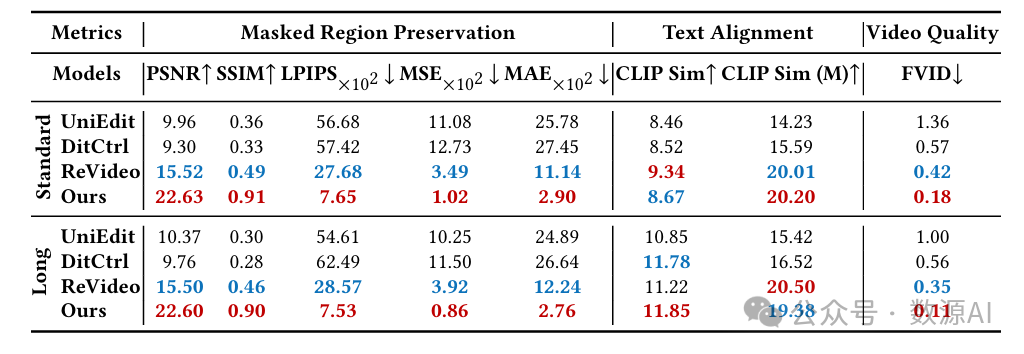
定量比较。表2展示了在VPBench和Davis数据集 [佩拉齐(Perazzi)等人,2016年] 上的定量比较结果。我们比较了非生成式的ProPainter [周(Zhou)等人,2023年]、生成式的COCOCO [子(Zi)等人,2024年] 以及我们提出的强大基线模型Cog - Inp [杨(Yang)等人,2024年] 的图像修复结果。Cog - Inp使用图像修复模型修复第一帧,并使用I2V主干网络通过潜在融合操作 [阿夫拉哈米(Avrahami)等人,2023年] 传播结果。在基于分割的VPBench数据集中,ProPainter和COCOCO在大多数指标上表现最差,主要原因分别是无法修复完全被遮挡的物体,以及单主干架构难以平衡相互竞争的背景保留和前景生成任务。在随机掩码基准测试Davis数据集中,ProPainter通过利用部分背景信息有所改进。然而,VideoPainter通过其双分支架构有效地分离了背景保留和前景生成任务,在分割(标准和长长度)和随机掩码任务中均取得了最佳性能。
定性比较。与先前视频修复方法的定性比较如图5所示。VideoPainter在视频连贯性、质量以及与文字说明的匹配度方面始终展现出卓越的效果。值得注意的是,ProPainter无法生成完全被遮挡的物体,因为它仅依赖于背景像素传播而非生成。虽然COCOCO展示了基本功能,但由于其单骨干架构试图平衡背景保留和前景生成,它无法在修复区域保持一致的标识(船只外观不一致和地形突变)。Cog - Inp实现了基本的修复结果;然而,其融合操作无法检测掩码边界,导致出现明显的伪影。此外,VideoPainter可以生成超过一分钟的连贯视频,并通过我们的标识重采样保持标识一致性。

图5. 先前修复方法与VideoPainter在标准视频和长视频修复上的比较。更多可视化结果见演示视频。
3. 视频编辑
VideoPainter可用于视频修复,方法是采用视觉语言模型[OpenAI 2024;Team等人2024],根据用户的编辑指令和源字幕生成修改后的字幕,并基于修改后的字幕应用VideoPainter进行修复。表3展示了在VPBench上的定量比较。我们比较了基于逆向的UniEdit [Bai等人2024年]、基于DiT的DiTCtrl [蔡等人,2024年]以及端到端的ReV-ideo [牟等人,2024年]。对于VPBench中的标准视频和长视频,VideoPainter均取得了卓越的性能,甚至超越了端到端的ReVideo。这一成功可归因于其双分支架构,该架构确保了出色的背景保留和前景生成能力,在非编辑区域保持高保真度的同时,确保编辑区域与编辑指令紧密匹配,再辅以修复区域ID重采样,从而在长视频中保持ID一致性。与以往视频修复方法的定性比较如图5所示。VideoPainter在保持视觉保真度和文本提示一致性方面表现卓越。VideoPainter成功生成了一个未来主义宇宙飞船穿越天空的无缝动画,在整个去除过程中保持了平滑的时间过渡和精确的背景边界,且不会像ReVideo那样产生伪影。
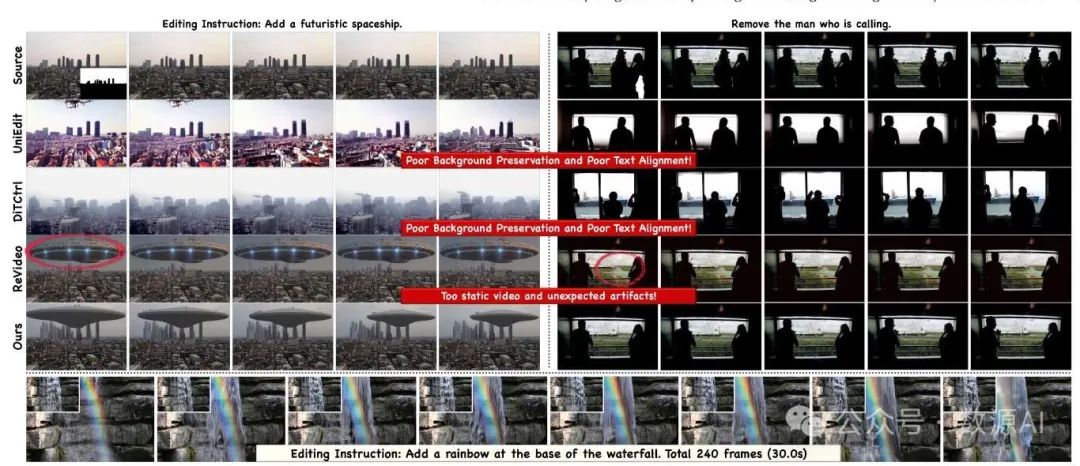
图6. 以往编辑方法与VideoPainter在标准视频和长视频编辑上的比较。更多可视化内容请查看演示视频。
4. 人工评估
我们使用VPBench修复和编辑子集中的标准长度视频样本,对视频修复和编辑任务进行了用户研究。三十名参与者根据背景保留、文本对齐和视频质量对随机选择的50个案例进行了评估。如表4所示,VideoPainter明显优于现有的基线方法,在两项任务的所有评估标准上都获得了更高的偏好率。详细的实验设置和结果见附录。

5. 消融分析
我们在表5中对VideoPainter进行了消融实验,包括架构、上下文编码器大小、控制策略和修复区域ID重采样。
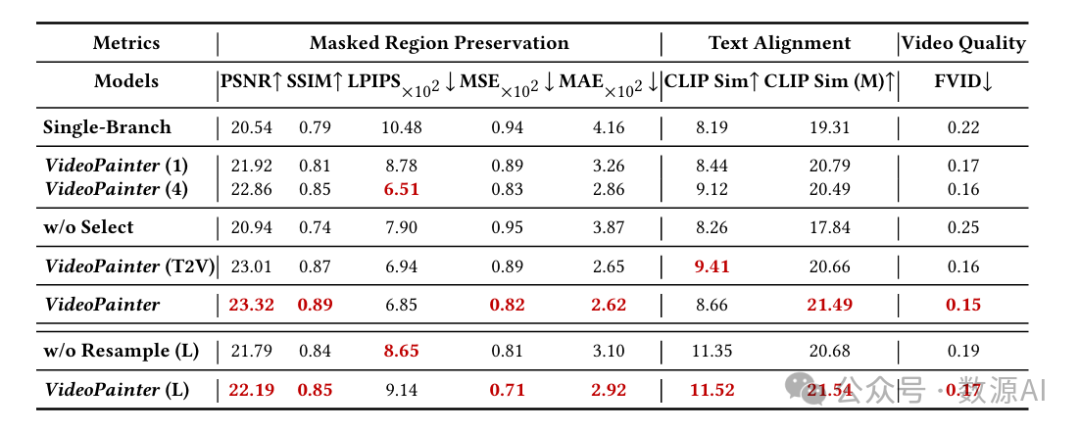
基于第1行和第5行的数据,双分支视频绘制器(VideoPainter)通过将背景保留与前景生成明确分离,显著优于单分支的同类模型,从而降低了模型复杂度,并避免了单分支中相互竞争的目标之间的权衡。表5的第2行至第6行展示了我们关键设计选择的合理性:1. 为上下文编码器采用两层结构,作为性能和效率之间的最佳平衡;2. 基于分割掩码信息实现令牌选择性特征融合,以防止主干网络中难以区分的前景 - 背景令牌造成混淆;以及 对不同主干网络采用即插即用控制,且性能相当。此外,第7行和第8行验证了对长视频采用修复区域ID重采样的重要性,该方法通过明确地从先前剪辑中重采样修复区域令牌来保持ID一致性。
6. 即插即用控制能力
图7展示了VideoPainter在基础扩散变压器选择方面的灵活即插即用控制能力。我们展示了VideoPainter如何能够与社区开发的格罗米特风格(Gromit-style)低秩自适应(LoRA)无缝集成。尽管动漫风格数据与我们的训练数据集之间存在显著的领域差距,但VideoPainter的双分支架构确保了其即插即用的图像修复能力,使用户能够根据特定的图像修复需求和预期结果选择最合适的基础模型。

图7. 将视频绘制器(VideoPainter)集成到格罗米特风格的低秩自适应(LoRA) [Cseti 2024]。
结论
在本文中,我们介绍了VideoPainter,这是首个具有即插即用控制能力的双分支视频图像修复框架。我们的方法有三项关键创新:(1)一种轻量级、可与任何预训练视频扩散变压器(DiTs)兼容的即插即用上下文编码器;(2)一种用于保持长视频身份一致性的图像修复区域身份重采样技术;(3)一个可扩展的数据集管道,该管道生成了VPData和VPBench,其中包含超过个带有精确掩码和密集字幕的视频片段。VideoPainter在视频编辑应用中也显示出了潜力。大量实验表明,VideoPainter在视频图像修复和编辑的8个指标上达到了最先进的性能,特别是在视频质量、掩码区域保留和文本连贯性方面。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)