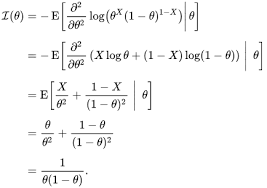
似然函数与费舍尔信息矩阵的讲解
本笔记将更详尽地介绍似然函数(Likelihood Function)和费舍尔信息矩阵(Fisher Information Matrix)。在统计建模中,我们常常设想:在实际应用中,我们先观测到一些样本数据,再去推断(估计)分布背后的参数 θ\thetaθ。给定一个观测值 xxx,如果知道参数 θ\thetaθ,则 p(x∣θ)p(x \mid \theta)p(x∣θ) 表示的是“X=xX =
似然函数与费舍尔信息矩阵的讲解
本笔记将更详尽地介绍似然函数(Likelihood Function)和费舍尔信息矩阵(Fisher Information Matrix)。
1. 似然函数:从“已知参数的分布”到“已知数据的参数函数”
1.1 问题背景:参数与数据
在统计建模中,我们常常设想:
- X X X 是一个随机变量(或随机向量),其分布由一个(或多个)参数 θ \theta θ 决定。
- 若 X X X 的分布为某个已知家族(如正态、指数分布等),该分布可以用联合密度(或概率质量函数) p ( x ∣ θ ) p(x \mid \theta) p(x∣θ) 表示。
在实际应用中,我们先观测到一些样本数据,再去推断(估计)分布背后的参数 θ \theta θ。
1.2 似然函数: L ( θ ∣ x ) L(\theta\mid x) L(θ∣x)
给定一个观测值 x x x,如果知道参数 θ \theta θ,则 p ( x ∣ θ ) p(x \mid \theta) p(x∣θ) 表示的是“ X = x X = x X=x 出现的概率密度或概率质量”。
然而,当我们真正拿到数据 x x x 后,我们往往对 θ \theta θ 不确定,这时我们会将同一个表达式换个视角来解释:“若观测到了 x x x,究竟哪个 θ \theta θ 能更好地解释这份数据?”于是定义似然函数 L ( θ ∣ x ) L(\theta\mid x) L(θ∣x) 为
L ( θ ∣ x ) = p ( x ∣ θ ) . L(\theta\mid x) \;=\; p(x \mid \theta). L(θ∣x)=p(x∣θ).
- 概率分布: p ( x ∣ θ ) p(x\mid \theta) p(x∣θ) 把 θ \theta θ 当作已知常量,把 x x x 当作随机变量;
- 似然函数: L ( θ ∣ x ) L(\theta\mid x) L(θ∣x) 中 x x x 已经是观测到的固定值,把 θ \theta θ 当作变量来“度量”对数据的解释力。
多个独立同分布样本
如果我们有 n n n 个独立同分布(i.i.d.)样本 { x 1 , x 2 , … , x n } \{x_1, x_2, \dots, x_n\} {x1,x2,…,xn},那么总似然函数是单个似然的乘积:
L ( θ ∣ x 1 , x 2 , … , x n ) = ∏ i = 1 n p ( x i ∣ θ ) . L(\theta \mid x_1, x_2, \dots, x_n) = \prod_{i=1}^n p(x_i \mid \theta). L(θ∣x1,x2,…,xn)=i=1∏np(xi∣θ).
在记法上,也常简写为
L ( θ ) = ∏ i = 1 n p ( x i ∣ θ ) , L(\theta) = \prod_{i=1}^n p(x_i \mid \theta), L(θ)=i=1∏np(xi∣θ),
其中 x i x_i xi 在外都是已知数据。
1.3 对数似然函数: ℓ ( θ ) \ell(\theta) ℓ(θ)
为了简化乘积并且使得数值计算更稳定,通常使用对数形式的似然:
ℓ ( θ ) = log L ( θ ) = ∑ i = 1 n log p ( x i ∣ θ ) . \ell(\theta) \;=\; \log L(\theta) \;=\; \sum_{i=1}^n \log p(x_i \mid \theta). ℓ(θ)=logL(θ)=i=1∑nlogp(xi∣θ).
- 优点:将乘法变为加法,方便求导、简化分析;
- 在最大化问题中, log \log log 函数是单调递增的,因此最大化对数似然与最大化似然本身等价。
2. 费舍尔信息:衡量参数信息量的刻度
2.1 直观动机
我们希望知道:一个分布家族 p ( x ∣ θ ) p(x\mid \theta) p(x∣θ),对于参数 θ \theta θ 的变化到底有多敏感?如果少量数据就能很好地区分不同 θ \theta θ 值(即数据对 θ \theta θ 很“敏感”),说明分布对 θ \theta θ 的依赖强,我们能获得的关于 θ \theta θ 的信息就很多;如果分布对 θ \theta θ 的微调并不敏感,很难“区分”不同 θ \theta θ,说明信息量就会小。
费舍尔信息(Fisher Information)就是用来描述这种参数可辨识度的重要指标。
2.2 标量参数的费舍尔信息
最初我们先假设参数是标量 θ \theta θ。有两种常见且等价的定义形式。
定义 1:导数方差形式
I ( θ ) = E [ ( ∂ ∂ θ log p ( X ∣ θ ) ) 2 ] , I(\theta) \;=\; \mathbb{E}\!\Bigg[\bigg(\frac{\partial}{\partial\theta} \log p(X\mid \theta)\bigg)^2\Bigg], I(θ)=E[(∂θ∂logp(X∣θ))2],
其中期望 E [ ⋅ ] \mathbb{E}[\cdot] E[⋅] 对随机变量 X X X 取, θ \theta θ 被视为常数。
- 若 ∂ ∂ θ log p ( X ∣ θ ) \frac{\partial}{\partial\theta} \log p(X\mid \theta) ∂θ∂logp(X∣θ) 对 θ \theta θ 变化很大,则表示分布对参数很敏感,也就信息量大;
- 若对 θ \theta θ 改变不敏感,则信息量小。
定义 2:对数似然的二阶导数形式
I ( θ ) = − E [ ∂ 2 ∂ θ 2 log p ( X ∣ θ ) ] . I(\theta) \;=\; -\,\mathbb{E}\!\Bigg[\frac{\partial^2}{\partial\theta^2} \log p(X\mid \theta)\Bigg]. I(θ)=−E[∂θ2∂2logp(X∣θ)].
可以证明,以上两种定义是等价的。简要示意如下:
设
g ( θ ) = ∂ ∂ θ log p ( X ∣ θ ) , g(\theta) = \frac{\partial}{\partial \theta} \log p(X\mid \theta), g(θ)=∂θ∂logp(X∣θ),
则
E [ g ( θ ) ] = E [ ∂ ∂ θ log p ( X ∣ θ ) ] = ∂ ∂ θ E [ log p ( X ∣ θ ) ] = ∂ ∂ θ ( ∫ p ( x ∣ θ ) log p ( x ∣ θ ) d x ) . \mathbb{E}[g(\theta)] = \mathbb{E}\Big[\frac{\partial}{\partial \theta} \log p(X\mid \theta)\Big] = \frac{\partial}{\partial \theta} \mathbb{E}[\log p(X\mid \theta)] = \frac{\partial}{\partial \theta} \Bigg(\int p(x\mid \theta)\log p(x\mid \theta)\, dx \Bigg). E[g(θ)]=E[∂θ∂logp(X∣θ)]=∂θ∂E[logp(X∣θ)]=∂θ∂(∫p(x∣θ)logp(x∣θ)dx).
再利用分布的正则条件、积分互换以及 ∫ p ( x ∣ θ ) d x = 1 \int p(x\mid \theta) dx = 1 ∫p(x∣θ)dx=1 等技巧,可以推导出 E [ g ( θ ) ] = 0 \mathbb{E}[g(\theta)] = 0 E[g(θ)]=0,以及
E [ g ( θ ) 2 ] = − E [ ∂ 2 ∂ θ 2 log p ( X ∣ θ ) ] . \mathbb{E}[g(\theta)^2] = -\, \mathbb{E}\Bigg[\frac{\partial^2}{\partial\theta^2} \log p(X\mid \theta)\Bigg]. E[g(θ)2]=−E[∂θ2∂2logp(X∣θ)].
因而得到前后两个定义的等价性。
2.3 多维参数(向量)情形
若参数是维度为 k k k 的向量 θ = ( θ 1 , θ 2 , … , θ k ) \boldsymbol{\theta} = (\theta_1, \theta_2, \dots, \theta_k) θ=(θ1,θ2,…,θk),则费舍尔信息会成为一个 k × k k \times k k×k 对称的矩阵:
I ( θ ) = E [ ∇ θ log p ( X ∣ θ ) ∇ θ log p ( X ∣ θ ) ⊤ ] , \mathbf{I}(\boldsymbol{\theta}) = \mathbb{E}\!\Big[ \nabla_{\boldsymbol{\theta}} \log p(X\mid \boldsymbol{\theta}) \;\nabla_{\boldsymbol{\theta}} \log p(X\mid \boldsymbol{\theta})^\top \Big], I(θ)=E[∇θlogp(X∣θ)∇θlogp(X∣θ)⊤],
其中
∇ θ log p ( X ∣ θ ) = ( ∂ ∂ θ 1 log p ( X ∣ θ ) , … , ∂ ∂ θ k log p ( X ∣ θ ) ) ⊤ \nabla_{\boldsymbol{\theta}} \log p(X\mid \boldsymbol{\theta}) = \bigg(\frac{\partial}{\partial \theta_1}\log p(X\mid \boldsymbol{\theta}),\,\dots,\,\frac{\partial}{\partial \theta_k}\log p(X\mid \boldsymbol{\theta})\bigg)^\top ∇θlogp(X∣θ)=(∂θ1∂logp(X∣θ),…,∂θk∂logp(X∣θ))⊤
是梯度向量。
或等价地可以写成 Hessian(对数似然的二阶偏导)形式的负期望:
I ( θ ) = − E [ ∇ θ ∇ θ ⊤ log p ( X ∣ θ ) ] . \mathbf{I}(\boldsymbol{\theta}) \;=\; -\,\mathbb{E}\Big[ \nabla_{\boldsymbol{\theta}} \nabla_{\boldsymbol{\theta}}^\top \,\log p(X\mid \boldsymbol{\theta}) \Big]. I(θ)=−E[∇θ∇θ⊤logp(X∣θ)].
3. 最大似然估计(MLE)与费舍尔信息的关系
3.1 MLE 的求解思路
给定样本 { x 1 , x 2 , … , x n } \{x_1, x_2, \dots, x_n\} {x1,x2,…,xn},我们将参数 θ \theta θ 视作未知量,用 最大似然估计(MLE) 方法来估计它。定义对数似然函数
ℓ ( θ ) = ∑ i = 1 n log p ( x i ∣ θ ) . \ell(\theta) = \sum_{i=1}^n \log p(x_i\mid \theta). ℓ(θ)=i=1∑nlogp(xi∣θ).
然后:
θ ^ MLE = arg max θ ℓ ( θ ) . \hat{\theta}_{\text{MLE}} = \operatorname*{arg\,max}_{\theta} \;\ell(\theta). θ^MLE=θargmaxℓ(θ).
通常通过设置导数为 0 来求解,即
∂ ∂ θ ℓ ( θ ) ∣ θ = θ ^ = 0. \frac{\partial}{\partial\theta}\,\ell(\theta)\bigg|_{\theta = \hat{\theta}} = 0. ∂θ∂ℓ(θ) θ=θ^=0.
若 θ \theta θ 是多维向量,就需要解
∇ θ ℓ ( θ ) = 0. \nabla_{\boldsymbol{\theta}}\, \ell(\boldsymbol{\theta}) \;=\; 0. ∇θℓ(θ)=0.
3.2 Cramér-Rao 下界
对于任意无偏估计量 θ ^ \hat{\theta} θ^,其方差不能小于费舍尔信息的倒数(标量情形)或矩阵逆(向量情形)。
-
标量情形:
V a r ( θ ^ ) ≥ 1 n I ( θ ) . \mathrm{Var}(\hat{\theta}) \;\ge\; \frac{1}{n\,I(\theta)}. Var(θ^)≥nI(θ)1.
这里 n n n 是样本量, I ( θ ) I(\theta) I(θ) 是单个样本的费舍尔信息。因此总费舍尔信息通常是 n I ( θ ) n\, I(\theta) nI(θ),对应估计量的方差下界为 ( n I ( θ ) ) − 1 \big(n\,I(\theta)\big)^{-1} (nI(θ))−1。 -
向量情形:
C o v ( θ ^ ) ⪰ 1 n I ( θ ) − 1 . \mathrm{Cov}\big(\hat{\boldsymbol{\theta}}\big) \;\succeq\; \frac{1}{n}\,\mathbf{I}(\boldsymbol{\theta})^{-1}. Cov(θ^)⪰n1I(θ)−1.
其中 ⪰ \succeq ⪰ 表示矩阵意义上的正定序关系。
含义:费舍尔信息越大,能够获得的估计精度越高,Cramér-Rao下界越低。
3.3 渐近正态性
当样本量 n → ∞ n\rightarrow \infty n→∞,在满足一定的正则条件时,最大似然估计量通常满足:
n ( θ ^ − θ ∗ ) → d N ( 0 , I ( θ ∗ ) − 1 ) ( 标量情况 ) , \sqrt{n}\big(\hat{\theta} - \theta^*\big) \;\xrightarrow{d}\; N\Big(0,\; I(\theta^*)^{-1}\Big)\quad (\text{标量情况}), n(θ^−θ∗)dN(0,I(θ∗)−1)(标量情况),
或多维情形:
n ( θ ^ − θ ∗ ) → d N ( 0 , I ( θ ∗ ) − 1 ) . \sqrt{n}\big(\hat{\boldsymbol{\theta}} - \boldsymbol{\theta}^*\big) \;\xrightarrow{d}\; \mathcal{N}\Big(\mathbf{0},\; \mathbf{I}(\boldsymbol{\theta}^*)^{-1}\Big). n(θ^−θ∗)dN(0,I(θ∗)−1).
这里 θ ∗ \theta^* θ∗(或 θ ∗ \boldsymbol{\theta}^* θ∗)是真实参数值。这说明 MLE 在大样本下具有“正态分布”近似,其方差(协方差)与费舍尔信息的倒数(逆矩阵)密切相关。
4. 具体示例与详细推导
下面以两类常见分布:伯努利分布和正态分布,来演示似然函数与费舍尔信息的计算过程。在此过程中,会给出更多的公式化展开。
4.1 伯努利分布
4.1.1 分布定义与似然函数
- 分布: X ∼ B e r n o u l l i ( p ) X \sim \mathrm{Bernoulli}(p) X∼Bernoulli(p),参数 θ = p ∈ ( 0 , 1 ) \theta = p \in (0,1) θ=p∈(0,1)。
概率质量函数:
p ( x ∣ p ) = p x ( 1 − p ) 1 − x , x ∈ { 0 , 1 } . p(x\mid p) = p^x (1-p)^{\,1-x}, \quad x \in \{0,1\}. p(x∣p)=px(1−p)1−x,x∈{0,1}. - 样本: x 1 , … , x n ∈ { 0 , 1 } x_1, \dots, x_n \in \{0,1\} x1,…,xn∈{0,1},假设独立同分布。
- 似然函数:
L ( p ) = ∏ i = 1 n p x i ( 1 − p ) 1 − x i . L(p) = \prod_{i=1}^n p^{\,x_i} (1-p)^{\,1-x_i}. L(p)=i=1∏npxi(1−p)1−xi. - 对数似然:
ℓ ( p ) = ∑ i = 1 n [ x i log p + ( 1 − x i ) log ( 1 − p ) ] . \ell(p) = \sum_{i=1}^n \Big[x_i \log p \;+\; (1-x_i)\log(1-p)\Big]. ℓ(p)=i=1∑n[xilogp+(1−xi)log(1−p)].
4.1.2 MLE 求解
对 ℓ ( p ) \ell(p) ℓ(p) 关于 p p p 求导,并令其为 0:
d d p ℓ ( p ) = ∑ i = 1 n [ x i p − 1 − x i 1 − p ] = 0. \frac{\mathrm{d}}{\mathrm{d}p}\,\ell(p) = \sum_{i=1}^n \Big[\frac{x_i}{p} \;-\; \frac{1 - x_i}{1-p}\Big] = 0. dpdℓ(p)=i=1∑n[pxi−1−p1−xi]=0.
简化整理可得:
∑ i = 1 n x i ⋅ 1 p − ∑ i = 1 n ( 1 − x i ) 1 1 − p = 0 , \sum_{i=1}^n x_i \cdot \frac{1}{p} \;-\; \sum_{i=1}^n (1-x_i)\,\frac{1}{1-p} = 0, i=1∑nxi⋅p1−i=1∑n(1−xi)1−p1=0,
∑ i = 1 n x i ⋅ 1 p = ∑ i = 1 n ( 1 − x i ) 1 1 − p . \sum_{i=1}^n x_i \cdot \frac{1}{p}= \sum_{i=1}^n (1-x_i)\,\frac{1}{1-p}. i=1∑nxi⋅p1=i=1∑n(1−xi)1−p1.
令 ∑ i = 1 n x i = ∑ x i \sum_{i=1}^n x_i = \sum x_i ∑i=1nxi=∑xi(样本中 1 的总数),可写为:
∑ x i p = n − ∑ x i 1 − p . \frac{\sum x_i}{p}= \frac{n - \sum x_i}{\,1 - p\,}. p∑xi=1−pn−∑xi.
解得最大似然估计:
p ^ = 1 n ∑ i = 1 n x i ≡ x ˉ . \hat{p} = \frac{1}{n}\sum_{i=1}^n x_i \;\equiv\; \bar{x}. p^=n1i=1∑nxi≡xˉ.
这就是“样本中 1 的平均出现率”作为伯努利分布参数 p p p 的估计。
4.1.3 费舍尔信息计算
-
使用定义 1(方差定义):
单个样本 X X X 的对数似然为
log p ( X ∣ p ) = X log p + ( 1 − X ) log ( 1 − p ) . \log p(X\mid p) = X \log p + (1-X)\log(1-p). logp(X∣p)=Xlogp+(1−X)log(1−p).
一阶导数:
g ( p ) = ∂ ∂ p log p ( X ∣ p ) = X p − 1 − X 1 − p . g(p) = \frac{\partial}{\partial p}\,\log p(X\mid p) = \frac{X}{p} - \frac{1-X}{1-p}. g(p)=∂p∂logp(X∣p)=pX−1−p1−X.
因此
( g ( p ) ) 2 = ( X p − 1 − X 1 − p ) 2 . \big(g(p)\big)^2 = \biggl(\frac{X}{p} - \frac{1-X}{1-p}\biggr)^2. (g(p))2=(pX−1−p1−X)2.
取期望 E [ ⋅ ] \mathbb{E}[\cdot] E[⋅] 时,需要注意 X ∼ B e r n o u l l i ( p ) X\sim \mathrm{Bernoulli}(p) X∼Bernoulli(p),故 E [ X ] = p \mathbb{E}[X]=p E[X]=p。详细展开后可最终得到I ( p ) = 1 p ( 1 − p ) . I(p) = \frac{1}{p(1-p)}. I(p)=p(1−p)1.
这表明:单个样本包含的费舍尔信息为 1 p ( 1 − p ) \tfrac{1}{p(1-p)} p(1−p)1。
n n n 个 i.i.d. 样本时,总费舍尔信息为I n ( p ) = n 1 p ( 1 − p ) . I_n(p) = n \,\frac{1}{p(1-p)}. In(p)=np(1−p)1.
-
使用定义 2(二阶导数定义)(简要示意):
∂ 2 ∂ p 2 log p ( X ∣ p ) = − X p 2 − 1 − X ( 1 − p ) 2 . \frac{\partial^2}{\partial p^2}\,\log p(X\mid p) = -\,\frac{X}{p^2} - \frac{1 - X}{(1-p)^2}. ∂p2∂2logp(X∣p)=−p2X−(1−p)21−X.
再对 X X X 取期望,就可以得到
− E [ ∂ 2 ∂ p 2 log p ( X ∣ p ) ] = 1 p ( 1 − p ) . -\,\mathbb{E}\bigg[\frac{\partial^2}{\partial p^2}\,\log p(X\mid p)\bigg] = \frac{1}{p(1-p)}. −E[∂p2∂2logp(X∣p)]=p(1−p)1.
结果与第一种方法一致。
4.1.4 Cramér-Rao 下界与 MLE 方差
-
总费舍尔信息: I n ( p ) = n p ( 1 − p ) I_n(p)=\frac{n}{p(1-p)} In(p)=p(1−p)n。
-
Cramér-Rao下界(对于无偏估计量 p ^ \hat{p} p^):
V a r ( p ^ ) ≥ 1 I n ( p ) = p ( 1 − p ) n . \mathrm{Var}(\hat{p}) \;\ge\; \frac{1}{\,I_n(p)\,} = \frac{p(1-p)}{n}. Var(p^)≥In(p)1=np(1−p).
-
事实上,MLE 的 p ^ = X ˉ \hat{p} = \bar{X} p^=Xˉ 具有方差 p ( 1 − p ) n \frac{p(1-p)}{n} np(1−p),恰好达到该下界。
4.2 正态分布 N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2)
现在我们看一个连续型分布的例子。设 X ∼ N ( μ , σ 2 ) X \sim \mathcal{N}(\mu, \sigma^2) X∼N(μ,σ2)。参数是 θ = ( μ , σ 2 ) \boldsymbol{\theta} = (\mu, \sigma^2) θ=(μ,σ2)。为简明,这里只列示关键步骤,但会给出尽量多的公式化细节。
4.2.1 似然与对数似然
-
单个样本 x x x 的密度函数:
p ( x ∣ μ , σ 2 ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) . p(x \mid \mu,\sigma^2) = \frac{1}{\sqrt{2\pi}\,\sigma} \exp\!\Big(-\frac{(x-\mu)^2}{\,2\sigma^2\,}\Big). p(x∣μ,σ2)=2πσ1exp(−2σ2(x−μ)2).
-
对数似然(单个样本) ℓ 1 ( μ , σ 2 ) \ell_1(\mu,\sigma^2) ℓ1(μ,σ2):
log p ( x ∣ μ , σ 2 ) = − 1 2 log ( 2 π ) − 1 2 log ( σ 2 ) − ( x − μ ) 2 2 σ 2 . \log p(x\mid \mu,\sigma^2) = -\frac{1}{2}\,\log(2\pi) -\frac{1}{2}\,\log(\sigma^2) -\frac{(x-\mu)^2}{\,2\sigma^2\,}. logp(x∣μ,σ2)=−21log(2π)−21log(σ2)−2σ2(x−μ)2.
常数项 − 1 2 log ( 2 π ) -\tfrac{1}{2}\log(2\pi) −21log(2π) 与参数无关,可在求导时省略。
-
n n n 个样本 x 1 , … , x n x_1,\dots,x_n x1,…,xn 的对数似然 ℓ ( μ , σ 2 ) \ell(\mu,\sigma^2) ℓ(μ,σ2):
ℓ ( μ , σ 2 ) = ∑ i = 1 n log p ( x i ∣ μ , σ 2 ) = − n 2 log ( σ 2 ) − 1 2 σ 2 ∑ i = 1 n ( x i − μ ) 2 + 常数 . \ell(\mu,\sigma^2)= \sum_{i=1}^n \log p(x_i\mid \mu,\sigma^2) \;=\; -\frac{n}{2}\,\log(\sigma^2)- \frac{1}{2\sigma^2}\,\sum_{i=1}^n (x_i - \mu)^2 \;+\; \text{常数}. ℓ(μ,σ2)=i=1∑nlogp(xi∣μ,σ2)=−2nlog(σ2)−2σ21i=1∑n(xi−μ)2+常数.
4.2.2 最大似然估计
为找 μ ^ \hat{\mu} μ^ 与 σ ^ 2 \hat{\sigma}^2 σ^2 的 MLE,计算对数似然关于 μ \mu μ 和 σ 2 \sigma^2 σ2 的偏导数并令其为 0 即可。
-
μ \mu μ 的偏导:
∂ ∂ μ ℓ ( μ , σ 2 ) = ∂ ∂ μ [ − n 2 log ( σ 2 ) − 1 2 σ 2 ∑ i = 1 n ( x i − μ ) 2 ] = − 1 σ 2 ∑ i = 1 n ( x i − μ ) . \frac{\partial}{\partial \mu}\,\ell(\mu,\sigma^2)= \frac{\partial}{\partial \mu} \Bigg[-\frac{n}{2}\log(\sigma^2)- \frac{1}{2\sigma^2}\,\sum_{i=1}^n (x_i - \mu)^2 \Bigg]= -\,\frac{1}{\,\sigma^2\,}\,\sum_{i=1}^n (x_i - \mu). ∂μ∂ℓ(μ,σ2)=∂μ∂[−2nlog(σ2)−2σ21i=1∑n(xi−μ)2]=−σ21i=1∑n(xi−μ).
设此为 0,则有
∑ i = 1 n ( x i − μ ) = 0 ⟹ μ ^ = 1 n ∑ i = 1 n x i . \sum_{i=1}^n (x_i - \mu) = 0 \;\;\Longrightarrow\;\; \hat{\mu} \;=\; \frac{1}{n}\sum_{i=1}^n x_i. i=1∑n(xi−μ)=0⟹μ^=n1i=1∑nxi.
-
σ 2 \sigma^2 σ2 的偏导:
令 σ 2 = α \sigma^2 = \alpha σ2=α(单纯为符号区别),对 ℓ ( μ , α ) \ell(\mu,\alpha) ℓ(μ,α) 求导:
∂ ∂ α ℓ ( μ , α ) = − n 2 1 α + 1 2 α 2 ∑ i = 1 n ( x i − μ ) 2 . \frac{\partial}{\partial \alpha}\,\ell(\mu,\alpha) = -\frac{n}{2}\,\frac{1}{\alpha}+ \frac{1}{2\,\alpha^2}\,\sum_{i=1}^n (x_i - \mu)^2. ∂α∂ℓ(μ,α)=−2nα1+2α21i=1∑n(xi−μ)2.
设此为 0,得
− n 2 α + 1 2 α 2 ∑ i = 1 n ( x i − μ ) 2 = 0 ⟹ ∑ i = 1 n ( x i − μ ) 2 = n α ^ , -\frac{n}{2\alpha} + \frac{1}{2\,\alpha^2}\,\sum_{i=1}^n (x_i - \mu)^2= 0 \;\;\Longrightarrow\;\; \sum_{i=1}^n (x_i - \mu)^2= n\,\hat{\alpha}, −2αn+2α21i=1∑n(xi−μ)2=0⟹i=1∑n(xi−μ)2=nα^,
即
σ ^ 2 = α ^ = 1 n ∑ i = 1 n ( x i − μ ^ ) 2 . \hat{\sigma}^2 = \hat{\alpha} = \frac{1}{n}\sum_{i=1}^n (x_i - \hat{\mu})^2. σ^2=α^=n1i=1∑n(xi−μ^)2.
- 由此得到 MLE: μ ^ = x ‾ \hat{\mu} = \overline{x} μ^=x, σ ^ 2 = 1 n ∑ i ( x i − x ‾ ) 2 \hat{\sigma}^2 = \frac{1}{n}\sum_{i}(x_i-\overline{x})^2 σ^2=n1∑i(xi−x)2。
4.2.3 费舍尔信息矩阵(单个样本)
现在来计算 I ( μ , σ 2 ) \mathbf{I}(\mu,\sigma^2) I(μ,σ2)( 2 × 2 2\times 2 2×2 矩阵)。要么用梯度外积,要么用负的 Hessian 矩阵期望。
先写出单个样本的对数似然(省略常数):
ℓ 1 ( μ , σ 2 ) = − 1 2 log ( σ 2 ) − ( x − μ ) 2 2 σ 2 . \ell_1(\mu,\sigma^2) = -\frac12 \log(\sigma^2)- \frac{(x-\mu)^2}{2\,\sigma^2}. ℓ1(μ,σ2)=−21log(σ2)−2σ2(x−μ)2.
我们可以先计算其一阶偏导(梯度),再用定义 1(外积法)求期望;也可以直接算 Hessian,然后再取负的期望。下面演示 Hessian 形式,能一次得出矩阵中各项。
-
一阶偏导:
-
对 μ \mu μ:
∂ ∂ μ ℓ 1 ( μ , σ 2 ) = ( x − μ ) σ 2 . \frac{\partial}{\partial \mu}\,\ell_1(\mu,\sigma^2) = \frac{(x-\mu)}{\sigma^2}. ∂μ∂ℓ1(μ,σ2)=σ2(x−μ).
-
对 σ 2 \sigma^2 σ2:
∂ ∂ σ 2 ℓ 1 ( μ , σ 2 ) = − 1 2 1 σ 2 + ( x − μ ) 2 2 ( σ 2 ) 2 . \frac{\partial}{\partial \sigma^2}\,\ell_1(\mu,\sigma^2)= -\frac{1}{2}\,\frac{1}{\sigma^2} + \frac{(x-\mu)^2}{\,2\,(\sigma^2)^2\,}. ∂σ2∂ℓ1(μ,σ2)=−21σ21+2(σ2)2(x−μ)2.
-
-
二阶偏导(Hessian 矩阵):
-
∂ 2 ∂ μ 2 ℓ 1 ( μ , σ 2 ) \displaystyle \frac{\partial^2}{\partial \mu^2}\,\ell_1(\mu,\sigma^2) ∂μ2∂2ℓ1(μ,σ2):
∂ ∂ μ ( x − μ σ 2 ) = − 1 σ 2 . \frac{\partial}{\partial \mu}\bigg(\frac{x-\mu}{\sigma^2}\bigg) = -\frac{1}{\sigma^2}. ∂μ∂(σ2x−μ)=−σ21.
-
∂ 2 ∂ ( σ 2 ) 2 ℓ 1 ( μ , σ 2 ) \displaystyle \frac{\partial^2}{\partial (\sigma^2)^2}\,\ell_1(\mu,\sigma^2) ∂(σ2)2∂2ℓ1(μ,σ2):
∂ ∂ σ 2 ( − 1 2 σ 2 + ( x − μ ) 2 2 ( σ 2 ) 2 ) . \frac{\partial}{\partial \sigma^2}\biggl(-\frac{1}{2\sigma^2} + \frac{(x-\mu)^2}{2(\sigma^2)^2}\biggr). ∂σ2∂(−2σ21+2(σ2)2(x−μ)2).
分别求导后合并,可得
∂ 2 ∂ ( σ 2 ) 2 ℓ 1 ( μ , σ 2 ) = 1 2 ( σ 2 ) − 2 − ( x − μ ) 2 ( σ 2 ) 3 . \frac{\partial^2}{\partial (\sigma^2)^2}\,\ell_1(\mu,\sigma^2)= \frac{1}{2}(\sigma^2)^{-2}- \frac{(x-\mu)^2}{(\sigma^2)^3}. ∂(σ2)2∂2ℓ1(μ,σ2)=21(σ2)−2−(σ2)3(x−μ)2.
-
∂ 2 ∂ μ ∂ ( σ 2 ) ℓ 1 ( μ , σ 2 ) \displaystyle \frac{\partial^2}{\partial \mu \partial (\sigma^2)}\,\ell_1(\mu,\sigma^2) ∂μ∂(σ2)∂2ℓ1(μ,σ2):
∂ ∂ ( σ 2 ) ( x − μ σ 2 ) = − ( x − μ ) ( σ 2 ) − 2 . \frac{\partial}{\partial (\sigma^2)}\Bigl(\frac{x-\mu}{\sigma^2}\Bigr)= -(x-\mu)\,(\sigma^2)^{-2}. ∂(σ2)∂(σ2x−μ)=−(x−μ)(σ2)−2.
这在最终 Hessian 的 (1,2) 和 (2,1) 位置会相同(混合偏导相等)。
-
-
期望 E [ ⋅ ] \mathbb{E}[\cdot] E[⋅] 并加上负号:
费舍尔信息矩阵(单个样本)是I ( μ , σ 2 ) = − E [ ( ∂ 2 ∂ μ 2 ℓ 1 ∂ 2 ∂ μ ∂ ( σ 2 ) ℓ 1 ∂ 2 ∂ ( σ 2 ) ∂ μ ℓ 1 ∂ 2 ∂ ( σ 2 ) 2 ℓ 1 ) ] . \mathbf{I}(\mu,\sigma^2)= -\,\mathbb{E}\!\Bigg[ \begin{pmatrix} \frac{\partial^2}{\partial \mu^2}\,\ell_1 & \frac{\partial^2}{\partial \mu \partial(\sigma^2)}\,\ell_1 \\ \frac{\partial^2}{\partial(\sigma^2)\partial \mu}\,\ell_1 & \frac{\partial^2}{\partial (\sigma^2)^2}\,\ell_1 \end{pmatrix} \Bigg]. I(μ,σ2)=−E[(∂μ2∂2ℓ1∂(σ2)∂μ∂2ℓ1∂μ∂(σ2)∂2ℓ1∂(σ2)2∂2ℓ1)].
将上面结果插入并对 X ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2) X∼N(μ,σ2) 取期望,可得:
I ( μ , σ 2 ) = ( 1 σ 2 0 0 1 2 ( σ 2 ) 2 ) . \mathbf{I}(\mu,\sigma^2)= \begin{pmatrix} \frac{1}{\sigma^2} & 0 \\ 0 & \frac{1}{2(\sigma^2)^2} \end{pmatrix}. I(μ,σ2)=(σ21002(σ2)21).
当样本量是 n n n 时,总费舍尔信息就是
n ⋅ ( 1 σ 2 0 0 1 2 ( σ 2 ) 2 ) . n \cdot \begin{pmatrix} \frac{1}{\sigma^2} & 0 \\ 0 & \frac{1}{2(\sigma^2)^2} \end{pmatrix}. n⋅(σ21002(σ2)21).
-
Cramér-Rao 下界:
C o v ( μ ^ , σ ^ 2 ) ⪰ ( 1 n / σ 2 0 0 1 n / ( 2 ( σ 2 ) 2 ) ) = ( σ 2 n 0 0 2 ( σ 2 ) 2 n ) . \mathrm{Cov}\big(\hat{\mu}, \hat{\sigma}^2\big) \;\succeq\; \begin{pmatrix} \tfrac{1}{\,n/\sigma^2\,} & 0 \\ 0 & \tfrac{1}{\,n/(2(\sigma^2)^2)\,} \end{pmatrix}= \begin{pmatrix} \tfrac{\sigma^2}{\,n\,} & 0 \\ 0 & \tfrac{2(\sigma^2)^2}{\,n\,} \end{pmatrix}. Cov(μ^,σ^2)⪰(n/σ2100n/(2(σ2)2)1)=(nσ200n2(σ2)2).
这正好对应我们熟悉的结论: μ ^ \hat{\mu} μ^ 的方差下界是 σ 2 n \frac{\sigma^2}{n} nσ2, σ ^ 2 \hat{\sigma}^2 σ^2 的方差下界是 2 ( σ 2 ) 2 n \frac{2(\sigma^2)^2}{n} n2(σ2)2。MLE 在大样本时渐近地达到此界。
5. 总结与回顾
-
似然函数和对数似然函数:
- 核心在于把“给定 θ \theta θ 的分布 p ( x ∣ θ ) p(x\mid \theta) p(x∣θ)”换成“给定观测 x x x 时,对参数 θ \theta θ 的一个函数”。
- 实际应用中常常求最大似然估计,通过对数似然求偏导=0 来找最优参数。
-
费舍尔信息:
- 衡量在给定分布家族下,数据(随机变量)对参数 θ \theta θ 的敏感程度。
- 有两种常见且等价的定义形式:
I ( θ ) = E [ ( ∂ ∂ θ log p ( X ∣ θ ) ) 2 ] I(\theta) = \mathbb{E}\Big[\Big(\frac{\partial}{\partial \theta}\log p(X\mid \theta)\Big)^2\Big] I(θ)=E[(∂θ∂logp(X∣θ))2]
以及
I ( θ ) = − E [ ∂ 2 ∂ θ 2 log p ( X ∣ θ ) ] . I(\theta) = -\,\mathbb{E}\Big[\frac{\partial^2}{\partial \theta^2}\log p(X\mid \theta)\Big]. I(θ)=−E[∂θ2∂2logp(X∣θ)]. - 对于多参数向量 θ \boldsymbol{\theta} θ,推广成费舍尔信息矩阵。
-
Cramér-Rao下界:
- 给任何无偏估计量提供了一个方差的理论极限: V a r ( θ ^ ) ≥ [ n I ( θ ) ] − 1 \mathrm{Var}(\hat{\theta})\ge [n\,I(\theta)]^{-1} Var(θ^)≥[nI(θ)]−1。
- 费舍尔信息越大,估计误差的下界越小。
- 大样本下,MLE 通常是渐近无偏,并且达到该下界,呈现正态分布。
6. 补充与展望
- 对实际问题而言,似然函数有时需要与先验信息结合变成贝叶斯推断;费舍尔信息在贝叶斯框架中也有相应推广(如观测信息矩阵、先验信息等)。
- 在高维统计或非正态分布场景,有更复杂的似然函数形式,需要数值方法(如梯度下降、EM算法)来求 MLE。
- 费舍尔信息还可以和**实验设计(Optimal Experimental Design)**联系起来,设计实验以最大化费舍尔信息,从而更精确地估计参数。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)