深度学习笔记
想象一下你有一条生产线,这条生产线由多个工作站组成,每个工作站负责对产品进行某种特定的加工。原材料从生产线的一端进入,经过每个工作站的处理后,成品从另一端出来。在这个过程中,每个工作站都对原材料进行了某些操作,使得它逐渐变成了最终的产品。在深度学习中,神经网络就像这条生产线,输入数据就是原材料,而每一层就是一个工作站。前向传播就是指原材料(输入数据)经过各个工作站(神经网络的各层)的处理,最终变成
第1章 前向传播算法
想象一下你有一条生产线,这条生产线由多个工作站组成,每个工作站负责对产品进行某种特定的加工。原材料从生产线的一端进入,经过每个工作站的处理后,成品从另一端出来。在这个过程中,每个工作站都对原材料进行了某些操作,使得它逐渐变成了最终的产品。
在深度学习中,神经网络就像这条生产线,输入数据就是原材料,而每一层就是一个工作站。前向传播就是指原材料(输入数据)经过各个工作站(神经网络的各层)的处理,最终变成成品(输出结果)的过程。
import torch
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
"""
初始化模型的层和参数
:param input_dim: 输入特征的数量
:param hidden_dim: 隐藏层的维度
:param output_dim: 输出特征的数量(通常是类别数)
"""
super().__init__()
# 定义线性层(车间1)
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.relu = nn.ReLU() # 激活函数
# 定义线性层(车间2)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
"""
实现前向传播过程
:param x: 输入数据
:return: 模型的输出
"""
# 第一层线性变换 + ReLU激活
out = self.fc1(x)
out = self.relu(out)
# 第二层线性变换
out = self.fc2(out)
return out
# 创建一个模型实例
model = SimpleModel(input_dim=784, hidden_dim=128, output_dim=10)
# 打印模型结构
print(model)
# 测试模型的前向传播
input_data = torch.randn(5, 784) # 假设输入为5个样本,每个样本有784个特征
output = model(input_data)
print("Output:", output)def forward(self, x):
相当于重写父类的方法
并且将车间顺序组合起来。处理原材料
- 当你调用模型实例(如
model(x))时,PyTorch 会自动调用该实例的forward方法进行前向传播。def __init__(self, input_dim, hidden_dim, output_dim):
相当于构造函数。
初始化整条生产线需要用到哪些生产车间,以及工具。
第2章 激活函数
2.1 激活函数的核心作用
激活函数的主要作用是引入非线性,使神经网络能够学习复杂的模式。没有激活函数,即使有很多层,神经网络也只能表示线性关系,这在处理复杂问题时是不够的。
2.1.1. 为什么需要非线性?
假设我们有一个简单的线性模型:
![]()
无论有多少这样的线性变换(即多个线性层),最终的结果仍然是线性的。例如,两个线性层组合起来仍然是线性的:
![]()
为了捕捉数据中的复杂模式,我们需要引入非线性。这就是激活函数的作用。
2.1.2 直观的比喻
想象一下你在玩一个电子游戏,游戏中有一个角色需要跳跃过障碍物。如果这个角色只能做直线运动,那么它将无法跳过任何障碍物。但是,如果给这个角色添加一个“跳跃”功能(相当于激活函数),它就能跳过障碍物了。
在这个比喻中:
- 输入数据:角色的位置。
- 线性变换:角色的移动方向和速度。
- 激活函数:跳跃动作,使得角色可以越过障碍物(非线性行为)。
2.2 ReLU
f(x)=max(0,x)
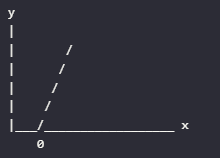
- 如果输入 xx 大于 0,则输出 xx。
- 如果输入 xx 小于或等于 0,则输出 0。
----------------------------------------------------------------------------
- 简单高效:计算速度快,适合大规模计算。
- 缓解梯度消失问题:不像Sigmoid和Tanh那样容易导致梯度消失问题。
2.3 Sigmoid
![]()
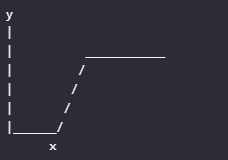
- 将输入映射到区间 (0, 1),适合用于二分类问题的最后一层。
- 输出值在0到1之间:便于解释为概率。
- 梯度消失问题:在深层网络中,容易导致梯度消失。
2.4 Softmax
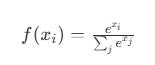
- 将输入转换为概率分布,通常用于多分类问题的最后一层。
- 输出值之和为1:便于解释为各类别的概率。
2.5. Tanh
![]()
- 将输入映射到区间 (-1, 1)。
- 输出值在-1到1之间:比Sigmoid更适合某些任务,但也有梯度消失的问题。
第3章 神经网络的训练过程
工厂生产车间的比喻
想象一下你经营着一个生产某种复杂产品的工厂。工厂里有多个车间(类似于神经网络的层),每个车间负责不同的工序(类似于神经网络的计算)。最终产品需要经过所有车间的加工才能完成。为了确保产品质量达到最佳,你需要不断调整每个车间的操作参数(类似于神经网络的权重和偏置)。
1. 前向传播:从原材料到成品
假设你的工厂生产某种复杂的机械部件,生产流程如下:
- 输入层(原材料仓库):你从仓库中获取原材料。
- 隐藏层(各个车间):
- 车间A:将原材料进行初步加工(例如切割、打磨)。
- 车间B:对初步加工后的材料进行进一步处理(例如组装、焊接)。
- 车间C:最后对半成品进行精细加工(例如抛光、检测)。
- 输出层(成品库):最终产品被送到成品库。
每一步都需要根据特定的参数(如切割速度、焊接温度等)进行操作。这些参数相当于神经网络中的权重和偏置。
2. 损失函数:评估产品质量
在成品库中,你会检查每个成品的质量,并与理想的标准进行对比。这个差异就是“损失”(Loss),类似于神经网络中的损失函数。损失值越大,表示产品的质量越差;反之,损失值越小,表示产品的质量越好。
假设你发现某些成品存在缺陷(例如尺寸不准确、表面粗糙等),这意味着当前的生产工艺参数(即车间的操作参数)不够优化。
3. 反向传播:从成品库到原材料仓库
为了改进生产工艺,你需要从成品库开始,逐层回溯到原材料仓库,找出哪些车间的操作参数需要调整。这个过程类似于反向传播算法。
-
输出层(成品库):
- 首先,你在成品库中检查成品的质量,并计算出总的损失(例如使用均方误差或交叉熵损失)。
- 然后,计算每个成品的质量问题对当前车间操作参数的影响(即计算梯度)。
-
隐藏层(各个车间):
- 车间C:根据成品库反馈的质量问题,计算出车间C的操作参数(如抛光时间和检测标准)对成品质量的影响,并相应调整这些参数。
- 车间B:接着,根据车间C反馈的问题,计算出车间B的操作参数(如焊接温度和组装精度)对车间C的影响,并调整这些参数。
- 车间A:最后,根据车间B反馈的问题,计算出车间A的操作参数(如切割速度和打磨力度)对车间B的影响,并调整这些参数。
-
输入层(原材料仓库):
- 最终,根据车间A的反馈,你可以决定是否需要调整原材料的选择或预处理方法。
4. 梯度:衡量调整的方向和幅度
在上述过程中,梯度(Gradient)是衡量每个车间的操作参数应该如何调整的关键指标。具体来说:
- 正梯度:如果某个参数增加会导致损失增加,则该参数的梯度为正,意味着需要减少该参数的值。
- 负梯度:如果某个参数增加会导致损失减少,则该参数的梯度为负,意味着需要增加该参数的值。
梯度的大小决定了调整的幅度。例如,如果某个参数的梯度很大,说明它对最终产品质量的影响很大,因此需要较大程度地调整;如果梯度很小,说明它的影响较小,调整幅度可以相对较小。
具体步骤
让我们详细描述一下反向传播的过程:
-
前向传播:
- 输入数据(原材料)通过每一层(车间)传递,直到得到输出结果(成品)。
- 计算预测结果与真实标签之间的损失(例如使用均方误差损失)。
-
反向传播:
- 从输出层开始,逐层向前计算每个参数(操作参数)对损失函数的梯度。
- 使用链式法则(Chain Rule)将损失函数对输出层参数的梯度传递到下一层,并继续传递到更前面的层。
-
更新参数:
- 根据计算出的梯度,使用优化算法(如随机梯度下降 SGD 或 Adam)更新每一层的参数。
- 更新公式通常为

3.1 前向传播

3.2 反向传播



import torch
import torch.nn as nn # 导入nn这个模块
import torch.optim as optim # 调入优化算法
from sklearn import linear_model # 从库中导入线性回归模型
class SimpleModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super().__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim) # 第一层
self.relu = nn.ReLU() # 激活函数
self.fc2 = nn.Linear(hidden_dim, output_dim) # 第二层
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
def train():
# 创建数据
input_data = torch.randn(5, 785) # 定义5行785列的tensor数据(假设输入为5个样本,每个样本有784个特征)
output_labels = torch.tensor([1, 2, 3, 4, 5]) # 真实标签
# 模型实例化
model = SimpleModel(785, 10, 10)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
for epoch in range(100):
# 前向传播
y_pred = model(input_data)
loss = criterion(y_pred, output_labels) # 计算预测值与生产值之间的损失
optimizer.zero_grad() # 梯度先清零
# 反向传播(链式求导)
loss.backward()
# 更新参数
optimizer.step()
if epoch % 10 == 0:
print(f'epoch: {epoch}, loss: {loss.item()}')
if __name__ == '__main__':
train()

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)