近端梯度法 (Proximal Gradient Methods) —— 通俗易懂详解
在现代机器学习和信号处理中,很多凸优化问题minx∈RnFxfxgxx∈RnminFxfxgxfxf(x)fx是可微(且通常假设∇f\nabla f∇f是LLL-Lipschitz 连续)的凸函数;gxg(x)gx是不可微但简单结构的凸函数,我们能有效计算其“近端算子”(proximal operator)。近端梯度法 (Proximal Gradient Methods)以类似梯度下降的方式
近端梯度法 (Proximal Gradient Methods) —— 通俗易懂详解
目录
概述
在现代机器学习和信号处理中,很多凸优化问题都可以写成如下形式:
min x ∈ R n { F ( x ) = f ( x ) + g ( x ) } , \min_{x \in \mathbb{R}^n} \Bigl\{ F(x) = f(x) + g(x) \Bigr\}, x∈Rnmin{F(x)=f(x)+g(x)},
其中:
- f ( x ) f(x) f(x) 是可微(且通常假设 ∇ f \nabla f ∇f是 L L L-Lipschitz 连续)的凸函数;
- g ( x ) g(x) g(x) 是不可微但简单结构的凸函数,我们能有效计算其“近端算子”(proximal operator)。
近端梯度法 (Proximal Gradient Methods) 以类似梯度下降的方式处理可微部分 f f f,并用一个近端步骤来处理不可微部分 g g g,从而得到在理论与实践上都非常高效的方法。
为什么需要近端梯度法?
-
处理不可微的正则项
常见的稀疏正则 ∥ x ∥ 1 \|x\|_1 ∥x∥1、核范数 ∥ X ∥ ∗ \|X\|_* ∥X∥∗ 等都不可微,但其“近端运算”往往有闭式解或易于实现。 -
保持迭代开销低
每一步迭代只需要做一次梯度计算与一次近端算子求解(如果有闭式解),比起直接用牛顿法处理不可微项要轻量得多。 -
理论收敛有保证
在 f f f 光滑凸、 g g g 闭凸且可以计算其近端算子时,近端梯度法可以确保全局收敛。若 f f f 还满足强凸,则可获得更快的线性收敛或加速收敛。
问题形式:可分解的凸优化
考虑以下可分解的目标函数:
min x ∈ R n { F ( x ) = f ( x ) + g ( x ) } , \min_{x \in \mathbb{R}^n} \left\{ F(x) = f(x) + g(x)\right\}, x∈Rnmin{F(x)=f(x)+g(x)},
-
f ( x ) f(x) f(x) 是可微凸函数,且假设它的梯度 ∇ f \nabla f ∇f 是 L L L-Lipschitz 连续,即对任意 x , y ∈ R n x,y\in \mathbb{R}^n x,y∈Rn:
∥ ∇ f ( x ) − ∇ f ( y ) ∥ 2 ≤ L ∥ x − y ∥ 2 . \|\nabla f(x) - \nabla f(y)\|_2 \,\le\, L\,\|x-y\|_2. ∥∇f(x)−∇f(y)∥2≤L∥x−y∥2.
-
g ( x ) g(x) g(x) 是不可微凸函数,但可以算它的近端算子。例如 g ( x ) = λ ∥ x ∥ 1 g(x) = \lambda \|x\|_1 g(x)=λ∥x∥1、或指示函数 δ C ( x ) \delta_C(x) δC(x)(当 x ∈ C x\in C x∈C 时为 0,否则为 ∞ \infty ∞)等。
近端算子 (Proximal Operator)
定义
给定一个凸函数 g ( x ) g(x) g(x),以及一个正数 α > 0 \alpha>0 α>0,近端算子 p r o x α g ( ⋅ ) \mathrm{prox}_{\alpha g}(\cdot) proxαg(⋅) 定义为:
p r o x α g ( v ) = arg min x ∈ R n { g ( x ) + 1 2 α ∥ x − v ∥ 2 2 } . \mathrm{prox}_{\alpha g}(v) = \arg\min_{x \in \mathbb{R}^n} \left\{g(x) + \frac{1}{2\alpha}\|x - v\|_2^2\right\}. proxαg(v)=argx∈Rnmin{g(x)+2α1∥x−v∥22}.
它可以理解为:“在点 v v v 附近,用平方距离 1 2 α ∥ x − v ∥ 2 \frac{1}{2\alpha}\|x-v\|^2 2α1∥x−v∥2 来惩罚和 v v v 的偏离,同时最小化 g ( x ) g(x) g(x)。”
若 g ( x ) g(x) g(x) 很简单,则该最优化子问题往往有闭式或半闭式解,计算非常高效。
常见近端算子的闭式解
-
L 1 L_1 L1 范数: λ ∥ x ∥ 1 \lambda\|x\|_1 λ∥x∥1
对 v ∈ R n v \in \mathbb{R}^n v∈Rn:p r o x α λ ∥ ⋅ ∥ 1 ( v ) i = arg min x i { λ ∣ x i ∣ + 1 2 α ( x i − v i ) 2 } = s i g n ( v i ) max ( ∣ v i ∣ − α λ , 0 ) . \mathrm{prox}_{\alpha \lambda \|\cdot\|_1}(v)_i = \arg\min_{x_i} \left\{\lambda|x_i| + \frac{1}{2\alpha}(x_i - v_i)^2\right\} = \mathrm{sign}(v_i)\max\bigl(|v_i| - \alpha \lambda, \; 0\bigr). proxαλ∥⋅∥1(v)i=argximin{λ∣xi∣+2α1(xi−vi)2}=sign(vi)max(∣vi∣−αλ,0).
这也叫**软阈值 (soft-thresholding)**操作。
-
指示函数: δ C ( x ) \delta_{C}(x) δC(x)
若 g ( x ) = δ C ( x ) g(x) = \delta_{C}(x) g(x)=δC(x),表示 x ∈ C x\in C x∈C 时 g ( x ) = 0 g(x)=0 g(x)=0,否则 g ( x ) = ∞ g(x)=\infty g(x)=∞。此时p r o x α δ C ( v ) = arg min x ∈ R n { δ C ( x ) + 1 2 α ∥ x − v ∥ 2 } = arg min x ∈ C 1 2 ∥ x − v ∥ 2 = Π C ( v ) , \mathrm{prox}_{\alpha \delta_C}(v) = \arg\min_{x \in \mathbb{R}^n}\bigl\{\delta_C(x) + \tfrac{1}{2\alpha}\|x - v\|^2\bigr\} = \arg\min_{x \in C}\tfrac{1}{2}\|x - v\|^2 = \Pi_C(v), proxαδC(v)=argx∈Rnmin{δC(x)+2α1∥x−v∥2}=argx∈Cmin21∥x−v∥2=ΠC(v),
即投影到集合 C C C 上的最近点(欧几里得投影)。
-
核范数: λ ∥ X ∥ ∗ \lambda \|X\|_* λ∥X∥∗
对矩阵 X X X,其近端算子对应对奇异值进行软阈值(奇异值软阈值化——SVT)。在低秩矩阵学习、矩阵补全中常见。
算法推导与更新公式
基本近端梯度更新
我们想最小化
F ( x ) = f ( x ) + g ( x ) , F(x) = f(x) + g(x), F(x)=f(x)+g(x),
其中 f f f 光滑可微。考虑在点 x k x_k xk 处做一次迭代,先用一阶近似逼近 f f f,再在周围加一个二次正则项:
-
一阶近似:
f ( x ) ≈ f ( x k ) + ∇ f ( x k ) T ( x − x k ) . f(x) \approx f(x_k) + \nabla f(x_k)^T (x - x_k). f(x)≈f(xk)+∇f(xk)T(x−xk). -
二次正则项:
1 2 α k ∥ x − x k ∥ 2 2 , \frac{1}{2\alpha_k}\|x - x_k\|_2^2, 2αk1∥x−xk∥22,
用来保证收敛并控制更新幅度。
这样,令
Q α k ( x , x k ) = f ( x k ) + ∇ f ( x k ) T ( x − x k ) + g ( x ) + 1 2 α k ∥ x − x k ∥ 2 2 . Q_{\alpha_k}(x, x_k) = f(x_k) + \nabla f(x_k)^T (x - x_k) + g(x) + \frac{1}{2\alpha_k}\|x - x_k\|_2^2. Qαk(x,xk)=f(xk)+∇f(xk)T(x−xk)+g(x)+2αk1∥x−xk∥22.
为了更新 x k + 1 x_{k+1} xk+1,我们做如下最小化:
x k + 1 = arg min x { Q α k ( x , x k ) } . x_{k+1} = \arg\min_x \Bigl\{Q_{\alpha_k}(x, x_k)\Bigr\}. xk+1=argxmin{Qαk(x,xk)}.
因为 f ( x k ) f(x_k) f(xk) 对 x x x 不依赖,是常数,可以省略;这就变成了找
x k + 1 = arg min x { ∇ f ( x k ) T ( x − x k ) + g ( x ) + 1 2 α k ∥ x − x k ∥ 2 2 } . x_{k+1} = \arg\min_x \Bigl\{ \nabla f(x_k)^T (x - x_k) + g(x) + \tfrac{1}{2\alpha_k}\|x - x_k\|_2^2 \Bigr\}. xk+1=argxmin{∇f(xk)T(x−xk)+g(x)+2αk1∥x−xk∥22}.
注意到 ∇ f ( x k ) T ( x − x k ) = 1 α k ( x − x k ) T ⋅ ( − α k ∇ f ( x k ) ) \nabla f(x_k)^T (x - x_k) = \frac{1}{\alpha_k}(x - x_k)^T \cdot \bigl(-\alpha_k \nabla f(x_k)\bigr) ∇f(xk)T(x−xk)=αk1(x−xk)T⋅(−αk∇f(xk))。令
v k = x k − α k ∇ f ( x k ) . v_k = x_k - \alpha_k \nabla f(x_k). vk=xk−αk∇f(xk).
于是我们得到:
x k + 1 = arg min x { g ( x ) + 1 2 α k ∥ x − v k ∥ 2 2 } = p r o x α k g ( v k ) . x_{k+1} = \arg\min_x \left\{ g(x) + \tfrac{1}{2\alpha_k}\|x - v_k\|_2^2 \right\} = \mathrm{prox}_{\alpha_k g}\bigl(v_k\bigr). xk+1=argxmin{g(x)+2αk1∥x−vk∥22}=proxαkg(vk).
因此, x k + 1 = p r o x α k g ( x k − α k ∇ f ( x k ) ) \boxed{x_{k+1} = \mathrm{prox}_{\alpha_k g}\bigl(x_k - \alpha_k \nabla f(x_k)\bigr)} xk+1=proxαkg(xk−αk∇f(xk))。
线搜索与步长选择
- 固定步长:若 ∇ f \nabla f ∇f 是 L L L-Lipschitz 连续,常取 α k = 1 L \alpha_k = \tfrac{1}{L} αk=L1 或 α k ≤ 1 L \alpha_k \le \tfrac{1}{L} αk≤L1。
- Armijo 线搜索:也可用带“回溯”的方式调整 α k \alpha_k αk,直到满足某些充分下降条件:
F ( p r o x α g ( x k − α ∇ f ( x k ) ) ) ≤ F ( x k ) − η ∥ ∇ f ( x k ) ∥ 2 , F\bigl(\mathrm{prox}_{\alpha g}(x_k - \alpha \nabla f(x_k))\bigr) \,\le\, F(x_k) - \eta \|\nabla f(x_k)\|^2, F(proxαg(xk−α∇f(xk)))≤F(xk)−η∥∇f(xk)∥2,
等等。实际中,为节省计算,也可以做简单的几何衰减线搜索 (backtracking line search)。
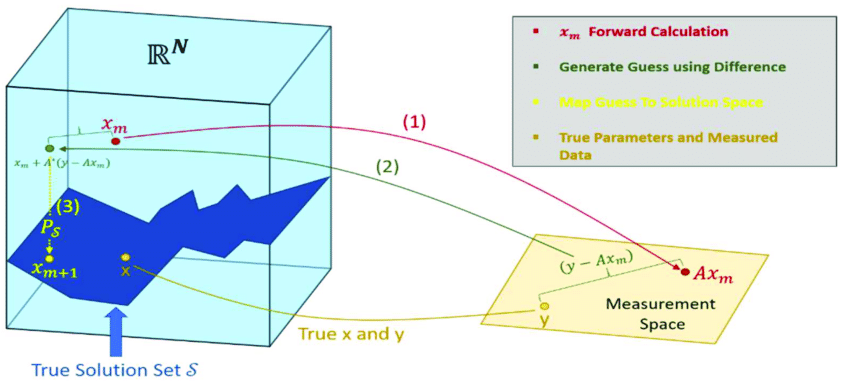
示例:L1 正则化问题详细推导
考虑最经典的 LASSO 回归:
min x ∈ R n { 1 2 ∥ y − A x ∥ 2 2 + λ ∥ x ∥ 1 } , \min_{x \in \mathbb{R}^n} \left\{\frac{1}{2}\|y - Ax\|_2^2 + \lambda \|x\|_1\right\}, x∈Rnmin{21∥y−Ax∥22+λ∥x∥1},
令
f ( x ) = 1 2 ∥ y − A x ∥ 2 2 , g ( x ) = λ ∥ x ∥ 1 . f(x) = \tfrac{1}{2}\|y - Ax\|_2^2, \quad g(x) = \lambda \|x\|_1. f(x)=21∥y−Ax∥22,g(x)=λ∥x∥1.
- 梯度:
∇ f ( x ) = − A T ( y − A x ) = A T ( A x − y ) . \nabla f(x) = -A^T(y - Ax) = A^T(Ax - y). ∇f(x)=−AT(y−Ax)=AT(Ax−y). - 近端更新:
在第 k k k 步,假设步长固定为 α \alpha α,则
x k + 1 = p r o x α λ ∥ ⋅ ∥ 1 ( x k − α ∇ f ( x k ) ) . x_{k+1} = \mathrm{prox}_{\alpha \lambda \|\cdot\|_1}\Bigl(x_k - \alpha \nabla f(x_k)\Bigr). xk+1=proxαλ∥⋅∥1(xk−α∇f(xk)). - 软阈值操作:
记
v k = x k − α A T ( A x k − y ) . v_k = x_k - \alpha A^T(Ax_k - y). vk=xk−αAT(Axk−y).
则
x k + 1 , i = s i g n ( v k , i ) max ( ∣ v k , i ∣ − α λ , 0 ) , x_{k+1, i} = \mathrm{sign}(v_{k,i}) \max\bigl(|v_{k,i}| - \alpha\lambda,\; 0\bigr), xk+1,i=sign(vk,i)max(∣vk,i∣−αλ,0),
这在坐标层面上就等价于对每个分量做一次“软阈值”。
形象解释:每一步先做梯度下降 (减少残差 ∥ y − A x ∥ \|y - Ax\| ∥y−Ax∥ ),再对解进行软阈值 (让某些分量变 0),从而产生稀疏解。
收敛性与重要性质
在凸设置下,若 f f f 为 L L L-Lipschitz 光滑凸、 g g g 为闭凸且 p r o x \mathrm{prox} prox可计算,则近端梯度法具有以下收敛结论:
- 单调减少性:若步长 α k \alpha_k αk 合理( α k ≤ 1 / L \alpha_k \le 1/L αk≤1/L),则 F ( x k + 1 ) ≤ F ( x k ) F(x_{k+1}) \le F(x_k) F(xk+1)≤F(xk)。
- 全局收敛: { x k } \{x_k\} {xk} 收敛到问题的全局最优解 x ^ \hat{x} x^。
- 收敛速率:
- 一般凸: F ( x k ) − F ( x ∗ ) = O ( 1 k ) F(x_k) - F(x^*) = O(\tfrac{1}{k}) F(xk)−F(x∗)=O(k1)。
- 若 f f f 强凸(或者 f + g f+g f+g 强凸),则有更快的线性收敛或可通过加速技巧达到更优速度(下节会提到 Nesterov 加速可达 O ( 1 k 2 ) O(\tfrac{1}{k^2}) O(k21) 的最优级别)。
常见变体
加速近端梯度 (Accelerated Proximal Gradient)
Nesterov 加速思想可用在“ f + g f + g f+g”形式的优化里。其核心是对当前解与历史解形成一种“动量”预测,然后再做近端梯度,能大幅提升收敛效率。
- 典型公式(简化版):
y k = x k + β k ( x k − x k − 1 ) , y_k = x_k + \beta_k (x_k - x_{k-1}), yk=xk+βk(xk−xk−1),
x k + 1 = p r o x α g ( y k − α ∇ f ( y k ) ) . x_{k+1} = \mathrm{prox}_{\alpha g}\Bigl(y_k - \alpha \nabla f(y_k)\Bigr). xk+1=proxαg(yk−α∇f(yk)).
其中 β k \beta_k βk 与 α \alpha α 取特定公式,使得对光滑凸问题可保证 O ( 1 k 2 ) O(\tfrac{1}{k^2}) O(k21) 的最优收敛速率(非强凸情形);若是强凸情形,还可实现近似的线性收敛。
随机近端梯度 (Stochastic Proximal Gradient)
当 f ( x ) f(x) f(x) 是一个大规模数据集上的平均损失(如
f ( x ) = 1 N ∑ i = 1 N ϕ i ( x ) , f(x) = \frac{1}{N}\sum_{i=1}^N \phi_i(x), f(x)=N1i=1∑Nϕi(x),
ϕ i \phi_i ϕi 可微),计算全部梯度 ∇ f ( x ) \nabla f(x) ∇f(x) 代价高。可采用随机的或小批量的近似梯度 g ^ ( x k ) \hat{g}(x_k) g^(xk),并仍在每步进行近端运算。
- 更新公式与之前类似,只是把 ∇ f ( x k ) \nabla f(x_k) ∇f(xk) 换成 g ^ ( x k ) \hat{g}(x_k) g^(xk)。
- 确保期望意义上或大样本情形下也能收敛到最优解。
- 在机器学习中非常常见(如稀疏深度学习、在线学习等)。
坐标近端梯度 (Coordinate Proximal Methods)
高维情形下,可能一次更新全部坐标很昂贵。坐标近端梯度法在某个坐标或一小块坐标上做近端运算,其余坐标保持不变。
- 典型公式:选取坐标 i k i_k ik,做
x k + 1 , i k = p r o x α g i k ( x k , i k − α ∇ i k f ( x k ) ) , x_{k+1, i_k} = \mathrm{prox}_{\alpha g_{i_k}}\Bigl(x_{k, i_k} - \alpha \nabla_{i_k} f(x_k)\Bigr), xk+1,ik=proxαgik(xk,ik−α∇ikf(xk)),
其余维度不变或做类似操作。 - 收敛性需要一定的随机化或循环策略,但在实际大规模问题中常表现良好。
Proximal-ADMM 的联系
ADMM(交替方向乘子法)可视为在分块可分问题上,每次针对一个变量做近端(或子问题最小化)操作,并更新乘子。
- 若问题能写成
min x , z f ( x ) + g ( z ) , subject to A x + B z = c , \min_{x,z}\; f(x) + g(z), \quad \text{subject to } Ax + Bz = c, x,zminf(x)+g(z),subject to Ax+Bz=c,
ADMM 每个子步就像做一个带约束的近端更新。 - 在实际工程里,Proximal Gradient 与 ADMM 是两种常见“大杀器”,常能相互启发,也可在分布式或并行化时结合使用。
应用场景示例
-
LASSO 回归
min x 1 2 ∥ y − A x ∥ 2 2 + λ ∥ x ∥ 1 , \min_{x} \frac12 \|y - Ax\|_2^2 + \lambda \|x\|_1, xmin21∥y−Ax∥22+λ∥x∥1,
用近端梯度法,梯度部分对应 ∇ f ( x ) = A T ( A x − y ) \nabla f(x)= A^T(Ax - y) ∇f(x)=AT(Ax−y),近端算子对应软阈值操作。迭代开销低,适合大规模回归。 -
Logistic 回归 + L 1 L_1 L1 正则
min w ∑ i = 1 N log ( 1 + exp ( − b i w T x i ) ) + λ ∥ w ∥ 1 , \min_{w} \;\sum_{i=1}^N \log(1 + \exp(-b_i w^T x_i)) + \lambda \|w\|_1, wmini=1∑Nlog(1+exp(−biwTxi))+λ∥w∥1,
用随机近端梯度可在大数据集上高效求解稀疏分类模型。 -
矩阵补全 (Matrix Completion)
min X 1 2 ∥ P Ω ( X − M ) ∥ F 2 + λ ∥ X ∥ ∗ , \min_{X} \;\tfrac12\|P_\Omega(X - M)\|_F^2 + \lambda \|X\|_*, Xmin21∥PΩ(X−M)∥F2+λ∥X∥∗,
其中 ∥ X ∥ ∗ \|X\|_* ∥X∥∗ 为核范数 (trace norm)。近端算子是对奇异值做软阈值 (SVT);在推荐系统、图像修复中广泛应用。 -
多项约束 + 简单集合的投影
如果 g g g 是多个指示函数之和或附加多种正则项,只要能写成可分形式并能分别计算近端,都可运用近端梯度迭代。
总结
近端梯度法可视为“梯度下降 + 不可微项近端处理”的强大结合,让大量本来因不可微正则或约束而棘手的凸问题,得以轻松、高效、稳定地求解。其主要特点包括:
- 算法易实现:核心更新公式
x k + 1 = p r o x α k g ( x k − α k ∇ f ( x k ) ) x_{k+1} = \mathrm{prox}_{\alpha_k g}\Bigl(x_k - \alpha_k \nabla f(x_k)\Bigr) xk+1=proxαkg(xk−αk∇f(xk))
非常简洁;只要能有效计算近端算子,迭代计算量就不大。 - 收敛性强:在凸设置下保证全局收敛;能结合线搜索或加速技巧进一步提高效率。
- 可扩展性:可与随机梯度、坐标下降、ADMM、并行化/分布式方法等灵活结合,处理大规模或复杂结构问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)