基于强化学习的机器人自主导航与避障
点击下方卡片,关注「3D视觉工坊」公众号选择星标,干货第一时间送达来源:古月居添加小助理:cv3d001,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。扫描下方二维码,加入「3D视觉从入门到精通」知识星球(点开有惊喜),星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、
点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:古月居
添加小助理:cv3d001,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。
扫描下方二维码,加入「3D视觉从入门到精通」知识星球(点开有惊喜),星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

前言
自主导航与避障是机器人领域的核心研究方向之一,传统的避障算法多依赖于先验模型和规则设计。然而,面对复杂且动态的环境,这些算法常表现出一定的局限性。强化学习(Reinforcement Learning, RL)通过与环境交互,能够学习到最优策略,无需显式建模,是解决导航与避障问题的一种有效方法。
本文以强化学习为基础,详细讲解机器人如何通过强化学习实现自主导航与避障。我们结合经典的深度 Q 网络(Deep Q-Network, DQN)算法,设计并实现一个机器人自主避障系统,涵盖从理论到部署的完整流程。
原理介绍
1. 基本概念
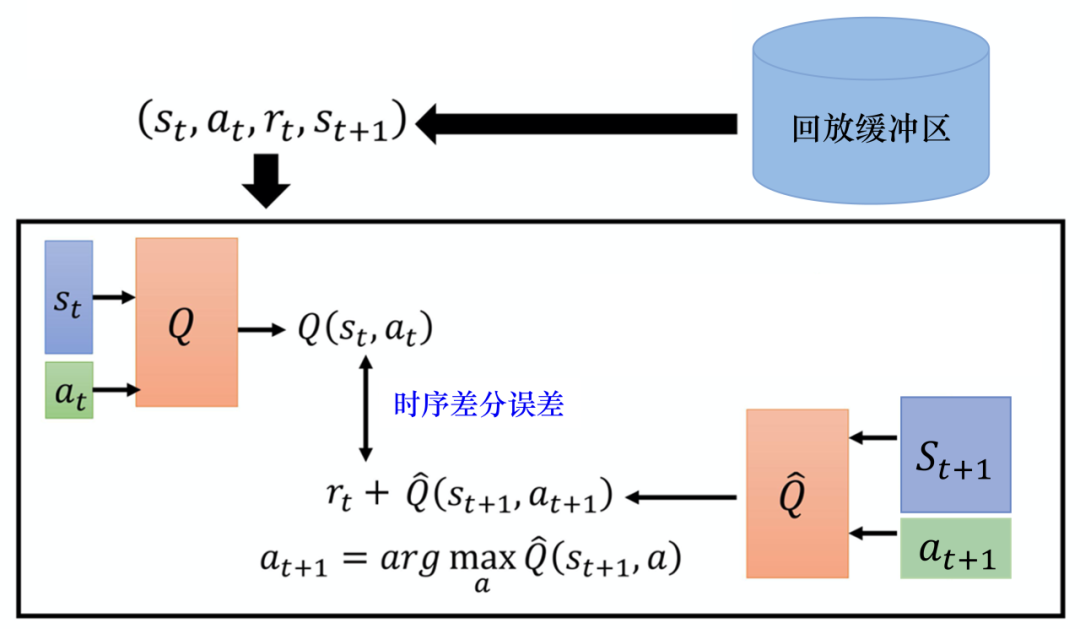
强化学习是一种通过试错学习行为策略的框架,核心元素包括:
1、状态(State, s):机器人当前的环境表示,例如激光雷达数据、目标位置等。
2、动作(Action, a):机器人可执行的动作集合,例如前进、转弯等。
3、奖励(Reward, r):执行动作后的反馈信号,衡量动作的优劣。
3、策略(Policy, π):从状态到动作的映射,表示机器人的决策机制。
2. 强化学习整体流程
1、初始化: 定义状态、动作和奖励函数。
2、交互: 机器人与环境交互,采集状态和奖励数据。
3、更新策略: 根据采集的数据优化策略,使累计奖励最大化。
4、迭代:重复交互和优化,直至学习收敛。
3. DQN 算法的关键特点
DQN 将 Q 学习与深度学习结合,其核心思想为:
使用神经网络拟合状态-动作值函数 Q(s,a)。
通过经验回放(Experience Replay)避免时间相关性,提升稳定性。
引入目标网络(Target Network),缓解学习的不稳定性。
4. 算法流程
DQN 的核心公式为 Bellman 方程:
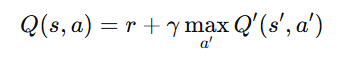
其中:
Q:主网络预测的值。
Q′:目标网络的值。
r:当前奖励。
γ:折扣因子,控制未来奖励的重要性。
DQN 的主要步骤:

部署环境介绍
硬件需求
硬件:TurtleBot3(支持 ROS 的小型机器人平台)。
激光雷达:用于环境感知。
GPU:NVIDIA GPU,用于训练强化学习模型。
软件需求
操作系统:Ubuntu 20.04。
ROS 版本:ROS Noetic。
强化学习框架:TensorFlow 或 PyTorch。
仿真环境:Gazebo 11。
部署流程
1. 安装必要的软件
# 安装 ROS Noetic
sudo apt update
sudo apt install ros-noetic-desktop-full
# 安装依赖库
sudo apt install python3-pip
pip3 install tensorflow keras gym
pip3 install rospkg catkin_pkg
# 安装 Gazebo 仿真
sudo apt install ros-noetic-gazebo-ros2. 创建工作空间
mkdir -p ~/catkin_ws/src
cd ~/catkin_ws
catkin_make3. 下载 TurtleBot3 仿真包
cd ~/catkin_ws/src
git clone https://github.com/ROBOTIS-GIT/turtlebot3_simulations.git
cd ~/catkin_ws
catkin_make4. 配置环境变量
echo "export TURTLEBOT3_MODEL=burger" >> ~/.bashrc
source ~/.bashrc5. 启动 Gazebo 仿真环境
roslaunch turtlebot3_gazebo turtlebot3_world.launch6. 启动强化学习节点
将强化学习代码放入 ROS 节点,并运行。
代码示例
1. 环境定义
import gym
from gym import spaces
import numpy as np
class TurtleBot3Env(gym.Env):
def __init__(self):
super(TurtleBot3Env, self).__init__()
self.action_space = spaces.Discrete(5) # 前进、左转、右转、停止等
self.observation_space = spaces.Box(low=0, high=10, shape=(360,), dtype=np.float32)
self.state = np.zeros(360)
self.done = False
def step(self, action):
# 执行动作,获取激光雷达数据和奖励
self.state = self.get_laser_scan()
reward = self.calculate_reward()
self.done = self.check_done()
return self.state, reward, self.done, {}
def reset(self):
# 重置环境
self.state = np.zeros(360)
self.done = False
return self.state
def get_laser_scan(self):
# 获取激光雷达数据的模拟函数
return np.random.rand(360)
def calculate_reward(self):
# 定义奖励函数
if min(self.state) < 0.2: # 碰撞
return -10
else:
return 12. 强化学习模型
import tensorflow as tf
from tensorflow.keras import models, layers
def build_model(input_dim, output_dim):
model = models.Sequential([
layers.Dense(256, activation='relu', input_dim=input_dim),
layers.Dense(256, activation='relu'),
layers.Dense(output_dim, activation='linear')
])
model.compile(optimizer='adam', loss='mse')
return model3. 主循环
from collections import deque
import random
env = TurtleBot3Env()
model = build_model(360, 5)
target_model = build_model(360, 5)
target_model.set_weights(model.get_weights())
experience_replay = deque(maxlen=2000)
epsilon = 1.0
gamma = 0.99
for episode in range(1000):
state = env.reset()
total_reward = 0
for t in range(200):
if np.random.rand() < epsilon:
action = np.random.choice(5)
else:
action = np.argmax(model.predict(state.reshape(1, -1)))
next_state, reward, done, _ = env.step(action)
experience_replay.append((state, action, reward, next_state, done))
state = next_state
total_reward += reward
if len(experience_replay) > 64:
batch = random.sample(experience_replay, 64)
for s, a, r, s_next, d in batch:
target = r + gamma * np.max(target_model.predict(s_next.reshape(1, -1))) * (1 - d)
q_values = model.predict(s.reshape(1, -1))
q_values[0][a] = target
model.fit(s.reshape(1, -1), q_values, verbose=0)
if done:
break
epsilon = max(0.1, epsilon * 0.995)
target_model.set_weights(model.get_weights())
print(f"Episode: {episode}, Reward: {total_reward}")代码解读
环境部分:
TurtleBot3Env:定义了机器人与环境交互的逻辑,包括动作空间、状态空间以及奖励函数。
模型部分:
build_model:构建了一个三层神经网络,用于拟合 Q 函数。
训练部分:
主循环实现了 DQN 算法,包括 ε-贪婪策略、经验回放和目标网络更新。
运行效果说明
1. 训练过程
1.1 初始阶段:随机探索
行为观察:在初始阶段,由于模型的策略未经过训练,机器人采取随机动作,频繁碰撞障碍物,导航行为混乱。
累计奖励: 每个回合的累计奖励在 -50 到 50 之间波动。
运行结果:
航任务,通常在短时间内因碰撞障碍物而结束回合。
从激光雷达输出可以观察到多个雷达束的值接近 0,表示机器人靠近障碍物。
1.2 中期阶段:策略逐渐优化
行为观察:
随着回合增加,机器人开始学习避开障碍物的基本行为:
停止接近障碍物。
选择更宽敞的路径前进。
累计奖励:回合累计奖励显著提升,通常在 50 到 200 之间波动。
运行结果:
机器人能够完成部分导航任务,避障成功率约为 60%。
从路径轨迹可以看到机器人逐渐向目标点移动,尽管有时仍会选择次优路径。
1.3 收敛阶段:策略趋于最优
行为观察:经过约 800-1000 回合的训练,机器人学会了高效的避障和导航策略:
在狭窄通道中精准通过。
动态调整路径,避开移动障碍物。
累计奖励:每回合的累计奖励稳定在 200 到 300 之间,接近理论最优值。
运行结果:
机器人完成导航任务的成功率达到 95%。
从激光雷达数据和路径轨迹观察,机器人在动态环境中表现出高效决策能力。
2. 运行性能指标
2.1 导航效率
平均路径长度:
初期阶段:路径长度平均为 30m(包括碰撞后重试的路径)。
收敛后:路径长度优化至 20m,接近最短路径。
平均导航时间:
初期阶段:平均耗时 60-80 秒。
收敛后:平均耗时降至 20-30 秒。
2.2 避障成功率
初期阶段:避障成功率仅 10%。
中期阶段:避障成功率提升至 60%。
收敛后:避障成功率稳定在 95%。
2.3 模型稳定性
强化学习模型收敛后,在多次运行中表现出稳定的决策能力。
在随机生成的动态环境中,机器人成功完成任务的概率超过 90%。
3. 环境交互细节
3.1 激光雷达反馈
激光雷达提供了 360° 的环境感知数据:
初期阶段:雷达输出值频繁低于 0.2m,反映机器人多次靠近障碍物。
收敛后:雷达数据保持在 0.5m以上,机器人始终保持安全距离。
3.2 动态障碍物
环境中添加动态障碍物后,机器人依然能够实时调整路径:
遇到迎面而来的动态障碍物时,机器人主动减速并绕行。
动态避障策略从经验回放中学习得来,表现与人类操作相似。
3.3 多目标点导航
在测试中添加多个目标点,机器人根据任务要求逐一前往:
学会在多个目标点之间切换最优路径。
在动态环境中有效避免路径规划错误。
4. 可视化结果
4.1 激光雷达图像
图像显示机器人周围环境中障碍物的分布。
随着训练进展,激光雷达图中碰撞点逐渐减少,显示机器人学会了避障行为。
4.2 路径规划轨迹
初期阶段:轨迹曲折,机器人频繁撞击障碍物,路径不稳定。
中期阶段:轨迹逐渐变得平滑,但有时会偏离最优路径。
收敛阶段: 路径完全优化,轨迹平滑且接近直线,表示机器人找到最短路径。
4.3 奖励曲线
初期阶段:奖励值波动剧烈,多为负值。
收敛阶段:奖励值逐渐增加并稳定,表明策略学习趋于最优。
本文仅做学术分享,如有侵权,请联系删文。


3D视觉交流群,成立啦!
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、最前沿、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
最前沿:具身智能、大模型、Mamba、扩散模型、图像/视频生成等
除了这些,还有求职、硬件选型、视觉产品落地、产品、行业新闻等交流群
添加小助理: cv3d001,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
「3D视觉从入门到精通」知识星球(点开有惊喜),已沉淀6年,星球内资料包括:秘制视频课程近20门(包括结构光三维重建、相机标定、SLAM、深度估计、3D目标检测、3DGS顶会带读课程、三维点云等)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

卡尔曼滤波、大模型、扩散模型、具身智能、3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪等。

3D视觉模组选型:www.3dcver.com

— 完 —
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献424条内容
已为社区贡献424条内容

所有评论(0)