Java中实现ONNX AI模型的可移植性
本文还有配套的精品资源,点击获取简介:ONNX(Open Neural Network Exchange)是促进AI模型互操作性的开放标准,允许在多个框架和平台上部署深度学习模型。Java开发人员可以通过ONNX Runtime库利用Java API加载、执行并集成ONNX格式的AI模型,实现模型的跨框架部署和运行,从而扩展Java应用的AI功能。本简介详细介绍了在Jav...

简介:ONNX(Open Neural Network Exchange)是促进AI模型互操作性的开放标准,允许在多个框架和平台上部署深度学习模型。Java开发人员可以通过ONNX Runtime库利用Java API加载、执行并集成ONNX格式的AI模型,实现模型的跨框架部署和运行,从而扩展Java应用的AI功能。本简介详细介绍了在Java中使用ONNX模型的步骤,包括安装运行时库、加载模型、准备输入数据、执行推理及获取输出结果等关键环节。 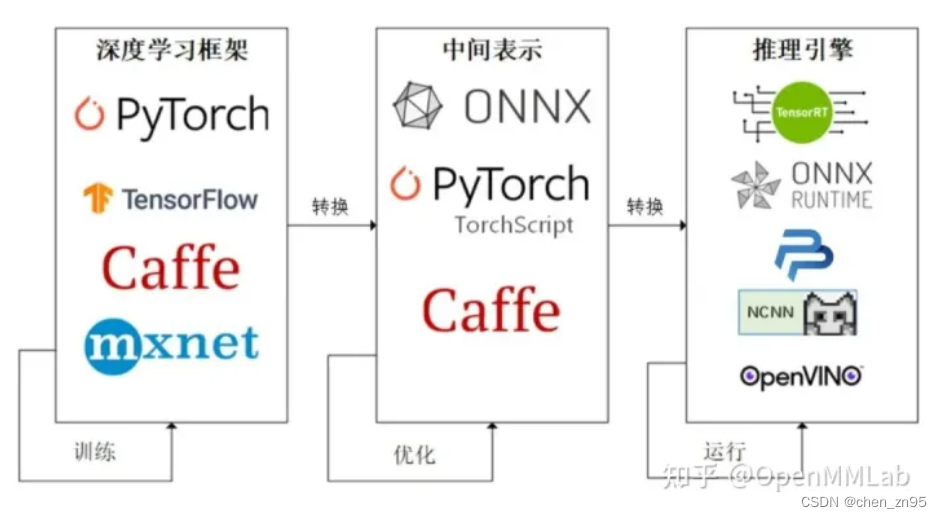
1. ONNX模型简介及互操作性
ONNX模型的起源和发展历程
ONNX(Open Neural Network Exchange)是为了解决不同深度学习框架之间的模型转换和互操作性问题而产生的开放标准。它由Facebook和Microsoft联合发起,并在2017年开源,旨在简化AI模型在不同平台和设备间的部署和迁移。ONNX支持多种深度学习框架,如PyTorch、TensorFlow和Caffe2等。
ONNX模型的格式和结构解析
ONNX模型由一个以 .onnx 为后缀的文件定义,包含了用于训练和推理的网络架构,以及模型的权重信息。模型结构以Protobuf格式存储,它是一种语言无关的序列化数据格式,易于人阅读和机器解析。ONNX模型结构的核心是图(Graph),它由节点(Node)和边(Edge)组成,节点代表运算操作,边代表数据流动。
ONNX模型的互操作性及其优势
互操作性是ONNX的核心优势之一,它允许数据科学家和工程师使用自己偏好的框架进行模型训练,然后将模型转换为ONNX格式,以便在不同的平台和设备上进行部署和推理。ONNX降低了深度学习框架之间的迁移成本,使得模型可以更加灵活地在不同的生产环境之间转移,从而加速了AI技术的落地和应用。
ONNX模型与其他AI框架的兼容性
ONNX广泛支持多个AI框架,这意味着模型可以在这些框架之间无缝迁移。例如,使用PyTorch训练的模型可以轻松转换为ONNX格式,并在TensorFlow或Caffe2中加载和推理。这种兼容性为AI研究和产品开发提供了极大的便利,有助于缩短开发周期和降低技术壁垒。
ONNX模型的应用场景和案例分析
ONNX模型在多个应用场景中得到了成功应用,包括图像识别、自然语言处理和推荐系统等。案例分析包括使用ONNX加速移动应用中的推理,以及在服务器端进行高性能计算。ONNX正成为AI模型互操作性的标准,推动了AI技术的普及和实践。
2. Java中ONNX模型的加载和运行
2.1 Java中加载ONNX模型的环境搭建
2.1.1 Java开发环境的配置
为了在Java环境中加载和运行ONNX模型,首先需要一个正确配置的Java开发环境。Java环境搭建的基本步骤包括安装Java Development Kit (JDK) 和配置环境变量。
- 下载并安装最新版本的JDK。访问[Oracle官网]( 或[OpenJDK]( 下载页面,根据你的操作系统选择合适的安装包进行下载和安装。
- 配置环境变量。在操作系统中,设置
JAVA_HOME环境变量,使其指向JDK安装目录,并将%JAVA_HOME%\bin(Windows系统)或$JAVA_HOME/bin(Unix/Linux/Mac系统)添加到系统路径中。
2.1.2 ONNX模型运行所需的库和工具安装
在Java环境中运行ONNX模型,需要安装ONNX Runtime Java库。ONNX Runtime是一个高性能的推理引擎,它支持ONNX格式的模型。
- 从[Maven Central Repository](***下载并添加
com.microsoft.onnxruntime:onnxruntime:1.7.0依赖到你的项目中。如果你使用Gradle构建系统,可以将以下依赖添加到你的build.gradle文件中:
dependencies {
implementation 'com.microsoft.onnxruntime:onnxruntime:1.7.0'
}
- 对于没有构建工具的简单测试环境,可以使用Maven命令行下载相应的jar包:
mvn dependency:get -DgroupId=com.microsoft.onnxruntime -DartifactId=onnxruntime -Dversion=1.7.0 -Dpackaging=jar
- 如果需要对ONNX Runtime进行更深入的定制或开发,可以访问[ONNX Runtime GitHub](***页面,按照提供的构建指南进行编译安装。
2.2 Java中加载ONNX模型的步骤和代码示例
2.2.1 从文件加载模型
加载ONNX模型的基本步骤涉及使用ONNX Runtime提供的API来加载和准备模型。以下是加载存储在本地文件系统中ONNX模型的示例代码。
import com.microsoft.onnxruntime.*;
import java.nio.file.Paths;
import java.util.*;
public class OnnxModelLoader {
public static void main(String[] args) {
try (OrtEnvironment env = OrtEnvironment.getEnvironment();
OrtSession session = env.createSession("path/to/your/model.onnx")) {
// 这里可以添加更多的代码来执行模型
} catch (OrtException e) {
System.out.println(e.getMessage());
}
}
}
在上述代码中,我们首先创建了一个ONNX运行时环境 OrtEnvironment ,然后用模型文件的路径创建了一个 OrtSession 实例。 OrtSession 是模型的运行时实例,用于执行模型推理。
2.2.2 从网络加载模型
在某些场景下,可能需要从网络地址直接加载模型。ONNX Runtime也支持直接从URL加载模型。以下是相应的代码示例:
import com.microsoft.onnxruntime.*;
***.URL;
import java.nio.file.Paths;
public class OnnxModelLoader {
public static void main(String[] args) {
try (OrtEnvironment env = OrtEnvironment.getEnvironment();
// 假设模型通过HTTP协议提供,URL是模型的HTTP路径
OrtSession session = env.createSession(new URL("***").openStream())) {
// 这里可以添加更多的代码来执行模型
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
在这段代码中,我们用模型的网络地址和相应的输入流创建了 OrtSession 实例。这允许模型的直接下载和加载,无需先将模型保存到本地文件系统中。
2.3 Java中ONNX模型的运行和推理
2.3.1 模型的初始化和配置
一旦模型被加载到 OrtSession 中,就可以进行模型的初始化和配置,以便进行实际的推理。模型的配置可能包括设置输入和输出的名称,以及配置特定的运行时选项,例如并行执行或者GPU支持。
import com.microsoft.onnxruntime.*;
public class OnnxModelInference {
public static void main(String[] args) {
try (OrtEnvironment env = OrtEnvironment.getEnvironment();
OrtSession session = env.createSession("path/to/your/model.onnx")) {
// 获取模型的输入和输出信息
OrtSession.SessionOptions sessionOptions = session.getOptions();
OrtTensorTypeAndShapeInfo inputTypeInfo = session.getInputInfo("input_name");
long[] inputShape = inputTypeInfo.getShape();
OnnxTensor inputTensor = OrtTensor.createTensor(env, inputShape, YOUR_INPUT_DATA);
// 配置会话选项,例如并行执行
sessionOptions.setInterOpNumThreads(1);
sessionOptions.setIntraOpNumThreads(1);
// 创建推理的输入映射
Map<String, OnnxTensor> inputs = new HashMap<>();
inputs.put("input_name", inputTensor);
// 执行推理
OrtSession.Result result = session.run(inputs);
// ... 后续处理结果
} catch (OrtException e) {
System.out.println(e.getMessage());
}
}
}
在上面的代码中,我们首先获取了模型输入的类型和形状信息,并使用输入数据创建了 OnnxTensor 实例。然后,我们配置了会话选项,并创建了一个输入映射,用于传递给 session.run 方法执行推理。
2.3.2 推理执行的代码实现和调试
在推理执行过程中,需要确保数据的正确性,包括输入数据的维度和数据类型。以下是一个简化的例子,展示了如何使用ONNX Runtime Java API执行模型推理,并处理输出结果:
import com.microsoft.onnxruntime.*;
public class OnnxModelInference {
public static void main(String[] args) {
// ... 前面的代码省略 ...
// 执行推理
OrtSession.Result result = session.run(inputs);
// 获取并处理输出数据
float[] outputArray = result.get(0).getValue().asFloatBuffer().array();
System.out.println("Output: " + Arrays.toString(outputArray));
// ... 后续处理和资源释放
}
}
在上述代码中, session.run 方法执行后会返回一个 OrtSession.Result 对象,它包含了所有的输出。通过调用 get 方法可以获取输出数据,并将其转换为Java中的数组格式。最后,我们打印出输出结果的数组形式。
请注意,本章节没有覆盖所有可能的场景和高级特性,为了深入理解ONNX Runtime的Java API,建议阅读官方文档和查看API的Javadoc。此外,异常处理(例如在捕获 OrtException 时添加日志和调试信息)对于实际开发中调试和确保模型正确执行至关重要。
3. ONNX Runtime安装和Java API应用
3.1 ONNX Runtime的安装和配置
3.1.1 ONNX Runtime的安装过程
ONNX Runtime是一个高性能的机器学习推理引擎,专为ONNX格式的模型设计。它可以支持多个平台和语言,包括Java。安装ONNX Runtime对于使用Java进行模型推理是至关重要的步骤。以下是安装ONNX Runtime的基本步骤:
-
检查系统要求 :确保你的系统满足运行ONNX Runtime的要求。这些要求可能包括操作系统的版本、处理器的架构以及是否需要特定的硬件加速功能。
-
下载ONNX Runtime安装包 :访问ONNX Runtime的官方发布页面,选择适合你系统的版本进行下载。对于Java环境,可能需要下载Java API的对应版本。
-
安装ONNX Runtime :根据下载的安装包类型(如.tar.gz或.zip文件),使用适当的解压工具将其解压到指定目录。如果是Windows系统,通常为安装向导步骤。
-
配置环境变量 :为了在Java中方便地调用ONNX Runtime,需要配置环境变量,使得Java能够找到ONNX Runtime的库文件。这通常涉及到设置
PATH环境变量,使其包含ONNX Runtime的二进制文件目录。
3.1.2 Java中ONNX Runtime的环境配置
在Java中使用ONNX Runtime,需要配置好Java开发环境并添加必要的依赖。以下是详细步骤:
-
配置Java开发环境 :确保你的Java开发环境(如JDK)已经正确安装。可以通过运行
java -version和javac -version命令来检查环境配置是否正确。 -
添加ONNX Runtime Java依赖 :在Java项目中,你需要添加ONNX Runtime的Java API依赖。这可以通过在项目的
pom.xml文件中添加相应的Maven依赖来完成,如下所示:
<dependency>
<groupId>com.microsoft.onnxruntime</groupId>
<artifactId>onnxruntime</artifactId>
<version>版本号</version>
</dependency>
请确保替换 版本号 为当前可用的最新版本。
- 配置项目构建路径 :确保构建路径中包含了ONNX Runtime的依赖jar包。在IDE中,这通常意味着需要将jar包添加到项目的类路径中。
完成这些配置后,Java就可以识别并使用ONNX Runtime API了。
3.2 Java中ONNX Runtime API的使用方法
3.2.1 API的初始化和加载模型
为了加载和运行ONNX模型,首先需要初始化ONNX Runtime的环境,并加载模型。以下是详细的步骤和示例代码:
import com.microsoft.onnxruntime.*;
import java.nio.file.Paths;
import java.util.Properties;
public class OnnxRuntimeExample {
public static void main(String[] args) {
// 初始化ONNX Runtime选项
Properties properties = new Properties();
properties.put("allowUnalignedBuffers", true);
// 创建一个会话选项对象
OrtSession.SessionOptions sessionOptions = new OrtSession.SessionOptions();
sessionOptions.addConfigEntry(properties);
// 加载ONNX模型文件
OrtEnvironment env = OrtEnvironment.getEnvironment();
OrtSession session = env.createSession("model.onnx", sessionOptions);
// 在这里可以进行模型的推理操作...
// session.run(inputTensor, ...)
}
}
在这段代码中,我们首先设置了ONNX Runtime的一些选项,并创建了一个会话选项对象。然后,我们创建了一个环境对象,并用它来创建一个会话,会话负责加载和执行模型。
3.2.2 API进行模型推理的方法和步骤
一旦模型被加载到会话中,我们就可以进行模型推理了。下面是进行模型推理的一些步骤和代码示例:
// 创建输入张量
float[] inputData = ... // 输入数据需要符合模型的输入要求
long[] inputShape = ... // 输入张量的形状,需要与模型定义一致
OrtTensorInfo inputTensorInfo = new OrtTensorInfo("float", inputShape);
OrtValue inputTensor = OrtValue.createTensorValue(inputTensorInfo, inputData);
// 创建输出张量
OrtValue[] output = new OrtValue[1];
long[] outputShape = ... // 输出张量的形状,通常由模型的输出层定义
// 执行模型推理
String[] inputNames = new String[] {"inputName"}; // 模型输入层的名称,需要根据实际情况填写
String[] outputNames = new String[] {"outputName"}; // 模型输出层的名称,需要根据实际情况填写
session.run(inputTensor, inputNames, outputNames, output);
在这段代码中,我们首先创建了输入张量,然后定义了输出张量的形状,并最终执行了模型的推理。输出张量可以用于后续的处理和结果解析。
3.2.3 API的高级功能和扩展使用
ONNX Runtime的Java API提供了许多高级功能,例如模型优化、会话选项配置、内存管理等。下面是一些高级功能的介绍:
// 会话配置示例:启用特定的执行提供者
Properties properties = new Properties();
properties.put("graph_optimization_level", "ORT_ENABLE_EXTENDED");
properties.put("execution_providers", new String[]{"CPUExecutionProvider", "GPUExecutionProvider"});
OrtSession.SessionOptions sessionOptions = new OrtSession.SessionOptions();
sessionOptions.addConfigEntry(properties);
// 使用会话选项创建新的会话
OrtSession session = env.createSession("model.onnx", sessionOptions);
在这个高级功能示例中,我们演示了如何设置会话选项来启用更高级的图形优化级别和指定执行提供者。
3.3 Java中ONNX Runtime API应用案例
3.3.1 应用案例:图像识别任务
在这个案例中,我们将使用ONNX Runtime执行一个图像识别任务。这需要加载一个预先训练好的模型,然后输入图像数据进行推理。
// 加载预训练的图像识别模型
OrtSession session = ... // 按照前面的步骤加载模型
// 图像数据预处理
BufferedImage image = ... // 加载图像
float[] preprocessedData = preprocessImage(image); // 图像预处理函数,例如缩放和归一化
// 创建输入张量
OrtTensorInfo inputTensorInfo = ... // 创建输入张量的描述信息
OrtValue inputTensor = OrtValue.createTensorValue(inputTensorInfo, preprocessedData);
// 推理和获取结果
String inputName = "input"; // 模型输入层名称
String outputName = "output"; // 模型输出层名称
OrtValue[] output = new OrtValue[1];
session.run(inputTensor, new String[] {inputName}, new String[] {outputName}, output);
// 解析推理结果
float[] result = ... // 从output张量中获取推理结果并进行解析
在这个案例中,我们演示了如何通过Java应用来加载一个图像识别模型,对输入图像进行预处理,执行推理,并解析结果。这个过程是典型的ONNX Runtime在Java中的应用场景,可以为机器学习和深度学习任务提供强大的支持。
3.4 ONNX Runtime与Java结合的优势
3.4.1 高性能推理
ONNX Runtime是专为高性能推理设计的,因此在Java中使用ONNX Runtime可以实现快速的模型执行和响应。这对于需要快速处理大量数据的应用尤其重要。
3.4.2 与Java生态的无缝集成
ONNX Runtime支持Java,意味着可以直接集成到现有的Java应用程序和微服务架构中。无需额外的学习成本,现有的Java开发者可以轻松地利用ONNX Runtime进行模型推理。
3.4.3 丰富的API和工具支持
ONNX Runtime提供了全面的API和工具支持,使得Java开发者可以方便地处理模型的加载、推理、以及结果的解析。这大大简化了在Java中进行机器学习任务的复杂性。
以上章节内容已经按照要求详细介绍了ONNX Runtime在Java中的安装、配置以及API的使用方法,并通过案例展示了如何将ONNX Runtime应用到实际的机器学习任务中。这些内容对于理解和掌握Java中的ONNX模型执行至关重要。
4. 模型输入数据准备
4.1 数据格式转换和处理
4.1.1 常见数据格式的转换方法
在机器学习和深度学习项目中,数据经常以不同的格式出现,比如CSV, JSON, 图像文件等。为了将这些数据用于ONNX模型的输入,我们通常需要进行一些格式转换。例如,Python中的Pandas库可以用来读取CSV文件,并将其转换为numpy数组,而图像文件通常需要经过OpenCV或Pillow等库处理后才能被模型接受。
Python代码示例:
import pandas as pd
import numpy as np
import cv2
# CSV转numpy数组
df = pd.read_csv('data.csv')
data_array = df.values
# 图像文件转换为模型输入格式
image = cv2.imread('image.jpg')
image_array = cv2.resize(image, (input_shape[1], input_shape[0])) # input_shape为模型输入尺寸
image_array = image_array.astype('float32') / 255.0 # 归一化
image_array = np.expand_dims(image_array, axis=0) # 增加一个批次维度
在这里,CSV数据通过Pandas库被读取并转换为numpy数组,而图像数据则通过OpenCV库读取、调整大小、归一化并增加批次维度。
4.1.2 数据预处理的步骤和技巧
数据预处理是机器学习中的一个关键步骤,它包括数据清洗、归一化、缩放等步骤。归一化是将数据缩放到[0,1]范围,有助于提高训练速度和模型稳定性。对于图像数据,通常还会包括尺寸调整和归一化处理,使得不同来源和格式的数据能够以统一的格式输入到模型中。
Python代码示例:
# 数据归一化处理
data_normalized = (data_array - np.min(data_array)) / (np.max(data_array) - np.min(data_array))
# 图像尺寸调整和归一化
image_resized = cv2.resize(image, (224, 224)) # 以224x224为例,适用于许多预训练模型
image_normalized = image_resized / 255.0 # 归一化
在这个例子中,数据被归一化处理,而图像数据则被调整到模型所需的尺寸并进行归一化。
4.2 Java中模型输入数据的准备
4.2.1 输入数据的类型和结构
在Java环境中,我们需要确保模型输入数据的类型和结构与模型在训练时所使用的数据类型和结构保持一致。对于大多数深度学习模型来说,输入数据通常是多维数组,比如在图像识别任务中,输入数据可能是三维数组(高度,宽度,颜色通道)。在Java中,我们可以使用多维数组或者特殊库如ND4J来处理这些数据。
Java代码示例:
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.factory.Nd4j;
// 示例:创建一个3x224x224的三维数组,模拟图像数据
INDArray input = Nd4j.create(new float[]{3, 224, 224}, new int[]{1, 3, 224, 224});
// 填充数据,假设从文件或其他来源加载
// 以下代码仅为示例,具体实现取决于数据的来源和格式
// ...
4.2.2 数据的加载和转换代码示例
在Java中加载和转换数据的过程与Python中类似,但需要注意的是Java没有内置的深度学习库。我们通常会依赖外部库(如ND4J)来处理数据和模型。下面是一个将图像数据加载和转换为模型输入格式的示例:
Java代码示例:
import org.bytedeco.javacv.CanvasFrame;
import org.bytedeco.javacv.Frame;
import org.bytedeco.javacv.OpenCVFrameConverter;
// 使用JavaCV读取图像
OpenCVFrameConverter.ToMat converter = new OpenCVFrameConverter.ToMat();
CanvasFrame canvas = new CanvasFrame("Image");
Frame frame = canvas.waitKey(-1);
// 转换图像到OpenCV的Mat格式
Mat mat = converter.convert(frame);
// 调整图像大小和归一化处理
Mat resizedMat = new Mat();
Size size = new Size(224, 224);
resize(mat, resizedMat, size);
resizedMat.convertTo(resizedMat, CV_32FC3, 1.0 / 255.0); // 归一化到0-1
// 将Mat转换为ND4J的INDArray
INDArray inputNDArray = matNDArrayFromOpenCVMat(resizedMat);
// 在这里,matNDArrayFromOpenCVMat是一个假设存在的函数,需要实现从OpenCV的Mat到ND4J INDArray的转换
// ...
在这个Java代码示例中,使用JavaCV库来读取图像,并将其转换为OpenCV的Mat格式。然后对Mat进行尺寸调整和归一化处理,最后将其转换为适合模型输入的ND4J INDArray格式。这个过程涉及到多种库的使用,每一步都需要精心处理以确保数据的正确性和类型一致性。
5. 推理执行和输出结果处理
5.1 ONNX模型的推理执行过程
5.1.1 推理执行的步骤和代码实现
推理执行是将训练好的模型应用于实际数据,从而获取预测结果的过程。在ONNX模型的推理执行过程中,我们通常需要以下几个步骤:
- 初始化ONNX Runtime会话。
- 准备输入数据,符合模型的输入要求。
- 使用ONNX Runtime会话执行推理。
- 获取并处理模型的输出数据。
以下是使用Java代码实现ONNX模型推理过程的示例:
import ai.onnxruntime.OrtEnvironment;
import ai.onnxruntime.OrtException;
import ai.onnxruntime.OrtSession;
import ai.onnxruntime.OrtSession.SessionOptions;
import ai.onnxruntime.Session;
// 创建环境
OrtEnvironment env = OrtEnvironment.getEnvironment();
// 创建会话选项并设置优化模式
SessionOptions sessionOptions = new SessionOptions();
sessionOptions.setOptimizationLevel(SessionOptions.OptLevel Rapids);
// 加载模型
Session session = env.createSession(modelPath, sessionOptions);
// 准备输入数据
float[] inputData = ...; // 模型输入数据
long[] inputShape = ...; // 模型输入形状
long[] outputShape = ...; // 模型输出形状
float[] outputData = new float[(int) outputShape[1]]; // 为输出数据创建缓冲区
// 执行推理
try (OrtSession.Runner runner = session.createRunner()) {
runner.addInput("input_name", inputData, inputShape)
.run(outputData); // 运行模型
}
// 关闭会话和环境
session.close();
env.close();
5.1.2 推理结果的获取和初步处理
在推理完成后,我们得到的是模型的输出数据,这通常需要根据具体任务进行进一步的处理。例如,在图像分类任务中,输出可能是一个概率分布数组,需要将其转换为类别标签,并找到概率最高的那个类别作为最终的预测结果。
// 将输出数据转换为可读的格式
for (int i = 0; i < outputData.length; i++) {
System.out.println("Class " + i + " probability: " + outputData[i]);
}
// 选择概率最高的类别作为预测结果
int bestClass = getMaxIndex(outputData);
System.out.println("Predicted class: " + bestClass);
5.1.3 推理结果的验证和应用示例
验证推理结果的准确性是机器学习模型部署中不可或缺的一环。我们可以通过与真实数据标签的对比来计算模型的准确度。在实际应用中,推理结果可以用于自动化决策过程,或者作为其他系统或服务的输入数据。
// 验证函数示例
public static double calculateAccuracy(float[] predictedLabels, float[] actualLabels) {
int correctPredictions = 0;
for (int i = 0; i < predictedLabels.length; i++) {
if ((int) predictedLabels[i] == (int) actualLabels[i]) {
correctPredictions++;
}
}
return (double) correctPredictions / predictedLabels.length;
}
// 使用推理结果进行验证
float[] actualLabels = ...; // 真实标签数据
double accuracy = calculateAccuracy(outputData, actualLabels);
System.out.println("Accuracy: " + accuracy);
5.2 推理结果的后处理和应用
5.2.1 结果解析和格式化
在获得初步推理结果之后,通常需要进行进一步的解析和格式化以满足后续处理的需要。例如,我们可以将概率分布转换为百分比,或者将数字标签映射到实际的类别名称。
5.2.2 结果的验证和应用示例
推理结果的验证是确保模型可靠性的关键步骤。验证过程一般涉及到比较模型输出与真实值的差异,并计算一些性能指标,如准确率、召回率、F1分数等。
5.2.3 应用示例
推理结果的应用非常广泛,可以用于实时推荐系统、自动化决策支持、图像或视频分析、语音识别等多个领域。例如,在自动驾驶汽车中,使用模型对车辆周围的环境进行实时分析,从而做出驾驶决策。
6. 数据预处理、模型优化、错误处理等高级特性
在前几章中,我们学习了ONNX模型的基础知识,如何在Java中加载和运行ONNX模型,以及如何安装和使用ONNX Runtime。现在,我们将深入探讨一些高级特性,这些特性将帮助您更有效地利用ONNX模型。本章将重点介绍数据预处理的高级技巧、模型优化的方法以及错误处理和调试技巧。
6.1 数据预处理的高级技巧
数据预处理是机器学习和深度学习中不可或缺的步骤。对于ONNX模型而言,正确的数据预处理可以显著提高模型的性能和准确性。
6.1.1 数据增强和归一化
数据增强(Data Augmentation)是通过一系列变换来增加数据多样性的技术,这些变换包括旋转、缩放、裁剪、颜色变换等。数据增强不仅可以减少过拟合,还可以使模型在面对实际应用场景时更加鲁棒。
# 示例代码:Python中使用OpenCV进行图像数据增强
import cv2
import numpy as np
image = cv2.imread('image.jpg')
# 旋转
image_rotated = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
# 缩放
image_scaled = cv2.resize(image, None, fx=1.2, fy=1.2, interpolation=cv2.INTER_LINEAR)
# 裁剪
image_cropped = image[y:y+h, x:x+w]
# 颜色变换(例如改变亮度)
image_lighter = cv2.convertScaleAbs(image, alpha=1.1)
归一化(Normalization)是将数据按比例缩放,使之落入一个小的特定区间的过程。常见的归一化方法有最小-最大归一化、z-score标准化等。
6.1.2 特征提取和降维技术
在处理数据时,我们可能面临高维数据集,这可能会导致计算资源的浪费和过拟合的风险。特征提取和降维技术可以有效减少特征的数量,同时尽可能保留数据的重要信息。
# 示例代码:Python中使用PCA进行降维
from sklearn.decomposition import PCA
# 假设X是一个高维数据集
pca = PCA(n_components=0.95) # 保留95%的方差
X_reduced = pca.fit_transform(X)
在上例中,PCA(主成分分析)是一种常用的降维技术,它通过选择数据中最重要的主成分来降低维度。在调整 n_components 参数时,可以根据实际需要选择保留的信息百分比。
6.2 模型优化的方法和实践
模型优化是一个持续的过程,目标是提高模型的性能,同时减少资源消耗。下面介绍模型剪枝和量化,以及模型转换和加速器的使用。
6.2.1 模型剪枝和量化
模型剪枝(Pruning)是一种减少模型复杂度的方法,通过移除一些冗余的参数或层来简化模型。剪枝可以降低模型的存储需求,加快模型的推理速度,但需要注意剪枝可能会影响模型的准确性。
# 示例代码:Python中使用TensorFlow进行模型剪枝
import tensorflow as tf
import tensorflow_model_optimization as tfmot
# 假设model是一个已经训练好的模型
prune_low_magnitude = tfmot.sparsity.keras.prune_low_magnitude
model_for_pruning = prune_low_magnitude(model)
# 训练和评估剪枝后的模型
model_for_pruning.fit(train_data, epochs=1)
model_for_pruning.evaluate(test_data)
量化(Quantization)是一种减少模型权重和激活表示精度的方法,通过使用低精度的数据类型(如int8或float16)来降低模型大小和计算需求。虽然量化可能会降低模型精度,但它可以大幅提升推理速度和能效。
6.2.2 模型转换和加速器使用
模型转换是将模型从一种框架转换为另一种框架的过程,例如将模型转换为ONNX格式,从而可以利用ONNX Runtime提供的优化和加速功能。加速器是指使用硬件加速技术,如GPU、TPU、FPGA等,来提高模型的推理速度。
# 示例代码:使用ONNX模型转换器将PyTorch模型转换为ONNX格式
import torch
import onnx
# 加载PyTorch模型
model = torch.load('model.pth')
model.eval()
# 准备模型输入
dummy_input = torch.randn(1, 3, 224, 224)
# 导出ONNX模型
torch.onnx.export(model, dummy_input, "model.onnx")
在本例中,使用PyTorch的 torch.onnx.export 函数将一个预训练好的模型导出为ONNX格式。接下来,可以使用ONNX Runtime来运行导出的模型,享受加速器带来的性能提升。
6.3 错误处理和调试技巧
在模型开发和部署过程中,错误处理和调试是不可或缺的。有效的错误处理和调试可以加快问题解决的进程,提高开发效率。
6.3.1 常见错误的诊断和处理
在使用ONNX模型时,可能会遇到各种错误,如输入输出不匹配、数据类型错误等。通过精心设计的错误处理和日志记录机制,可以快速定位和解决问题。
# 示例代码:错误处理的一个简单示例
try:
# 假设model是ONNX模型的实例,input是模型输入
output = model.run(input)
except Exception as e:
# 打印错误信息和堆栈跟踪
print("Error: ", e)
print("Stack trace: ", traceback.print_exc())
6.3.2 性能瓶颈的分析和优化
性能瓶颈是阻碍模型优化和提高的重要因素。分析性能瓶颈需要对模型的计算图、内存使用、硬件资源等进行深入分析。
graph TD;
A[开始性能分析] --> B[检查数据加载时间]
B --> C[检查模型推理时间]
C --> D[检查CPU/GPU利用率]
D --> E{瓶颈定位}
E --> |数据加载| F[优化数据读取流程]
E --> |推理计算| G[优化模型结构]
E --> |硬件利用| H[使用更高效的硬件资源]
在上图中,展示了性能分析的一个基本流程,通过逐步检查可以定位到瓶颈所在的环节,并采取相应的优化措施。
通过本章的学习,您应该能够掌握数据预处理、模型优化和错误处理的高级技巧。这些技巧将帮助您更高效地使用ONNX模型,解决实际应用中的各种问题。
7. ONNX Runtime的性能提升和内存优化技术
7.1 ONNX Runtime性能提升的方法
在深入探讨如何提升ONNX Runtime性能之前,我们必须了解性能基准测试的重要性。性能基准测试可以量化模型执行的效率,并为后续优化提供数据支持。常用的基准测试工具有Netron、ONNX Runtime Profiler等。
7.1.1 性能基准测试和分析
进行性能基准测试,首先要确保测试环境的稳定性和测试过程的标准化。为了得到可靠的测试数据,通常要运行多次测试并计算平均值。测试中可以调整输入数据的批次大小、线程数等参数,观察它们对性能的影响。
代码示例:
import onnxruntime.*;
import java.util.Properties;
public class PerformanceTest {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty("sessionOptions", "intra_op_num_threads=1,inter_op_num_threads=1");
try (OrtEnvironment env = OrtEnvironment.getEnvironment(properties)) {
OrtSession.SessionOptions options = new OrtSession.SessionOptions();
options.addEnabledExecutionProvider("CPU");
OrtSession session = env.createSession("model.onnx", options);
// 创建一个输入tensor,填充模型需要的输入数据
float[] inputData = ...; // 模型输入数据
OrtTensorAccess inputTensor = OrtTensorAccess.create(inputData);
Ort Почем[] inputs = new Ort Почем[]{new Ort Почем("input_name", inputTensor)};
// 准备输出tensor
Ort Почем[] outputs = new Ort Почем[]{new Ort Почем("output_name", null)};
// 运行性能基准测试
long startTime = System.nanoTime();
for (int i = 0; i < 100; i++) {
session.run(inputs, outputs);
}
long endTime = System.nanoTime();
System.out.println("100次推理耗时:" + (endTime - startTime) / 1e6 + " ms");
}
}
}
7.1.2 性能优化策略和实践
基于基准测试的结果,可以实施针对性的优化策略。一些常见的策略包括: - 调整模型的批次大小以充分利用硬件并行性。 - 利用ONNX Runtime的多线程执行选项以优化计算资源的使用。 - 优化模型结构,例如模型剪枝或量化,减少计算量和内存占用。 - 使用模型加速器如GPUs进行计算,利用硬件优势提升性能。
7.2 ONNX Runtime内存优化技术
内存管理是模型部署和运行中的重要环节,特别是在需要处理大量数据或复杂模型的场景中。
7.2.1 内存消耗分析和诊断
内存消耗的分析可以从多个方面进行: - 利用JVM的内存监控工具,例如VisualVM,观察运行时的内存使用情况。 - ONNX Runtime提供了内存诊断工具,可以帮助识别内存消耗大户。 - 对模型的内存占用进行分析,这通常涉及到模型的结构和运行时的内存管理。
7.2.2 内存优化的技巧和应用
内存优化可以从模型和运行时环境两个方面入手: - 对于模型,可以使用压缩技术减少权重的存储量,例如权重剪枝或量化。 - 对于运行时环境,可以调整ONNX Runtime的执行选项,如启用内存优化模式或调整内存池的大小。
7.3 性能与内存优化的综合考量
在优化过程中,性能提升和内存优化往往需要综合考虑。过度优化可能带来性能损失,而忽视内存消耗则可能导致程序崩溃。
7.3.1 平衡性能与内存消耗的策略
实现平衡的一个有效方法是:使用适当的资源监控工具,了解在性能和内存使用之间的关系。根据具体需求进行调整,如在内存紧张时适当牺牲一些性能,而在性能关键的应用中放宽内存限制。
7.3.2 实际案例分析和优化经验分享
在实际应用中,很多优化经验来自于真实案例的分析。例如,在一个图像处理任务中,我们可能发现通过调整模型结构,比如减少卷积层的深度,虽然牺牲了一定的准确率,但是显著降低了内存消耗,并且由于模型简化后速度更快,整体的性能得到了提升。
下面是使用ONNX Runtime进行性能提升和内存优化的流程图:
graph TD
A[开始性能和内存优化] --> B[性能基准测试]
B --> C[内存消耗分析]
C --> D[确定优化目标]
D --> E[实施性能优化]
D --> F[实施内存优化]
E --> G[平衡性能与内存]
F --> G
G --> H[测试优化效果]
H --> |满意| I[结束优化流程]
H --> |不满意| J[重新分析与优化]
J --> B
在这一章节中,我们详细探讨了如何对ONNX Runtime进行性能提升和内存优化,并介绍了实际案例分析来分享优化经验。通过基准测试、性能分析、实际案例讨论等步骤,为IT专业人员提供了一套系统的方法来提升模型在Java环境中的运行效率。
简介:ONNX(Open Neural Network Exchange)是促进AI模型互操作性的开放标准,允许在多个框架和平台上部署深度学习模型。Java开发人员可以通过ONNX Runtime库利用Java API加载、执行并集成ONNX格式的AI模型,实现模型的跨框架部署和运行,从而扩展Java应用的AI功能。本简介详细介绍了在Java中使用ONNX模型的步骤,包括安装运行时库、加载模型、准备输入数据、执行推理及获取输出结果等关键环节。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)