哈工深发布多模态Reasoning大模型综述:感知、推理、思考和规划
就像人类遇到问题时会结合所见所闻,模型也需要跨模态推理能力,比如看到“乌云密布”联想到“带伞”,听到“玻璃碎裂”判断可能发生意外。:通过试错优化决策路径 典型案例是OpenAI的GPT-4o,能处理长达8分钟的复杂任务(如图像编辑多轮调整)。显示,现有评测基准(如OmniBench)中,顶尖模型准确率不足20%,说明技术仍处早期阶段。论文预言,这类模型将彻底打破现有架构,成为真正的“数字大脑”。:

论文:Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
链接:https://arxiv.org/pdf/2505.04921
如今的模型早已超越“看图说话”,论文开篇指出:真正的智能需要融合视觉、语言、听觉等多维度信息。就像人类遇到问题时会结合所见所闻,模型也需要跨模态推理能力,比如看到“乌云密布”联想到“带伞”,听到“玻璃碎裂”判断可能发生意外。 论文提出,多模态推理模型(LMRMs)是通向通用人工智能(AGI)的核心路径,但现有技术仍面临三大瓶颈:
-
模态割裂:文本、图像、视频各自为战
-
短视推理:只能处理简单问题,无法长链条思考
-
被动应答:缺乏主动规划和实时交互能力
技术进化四个阶段
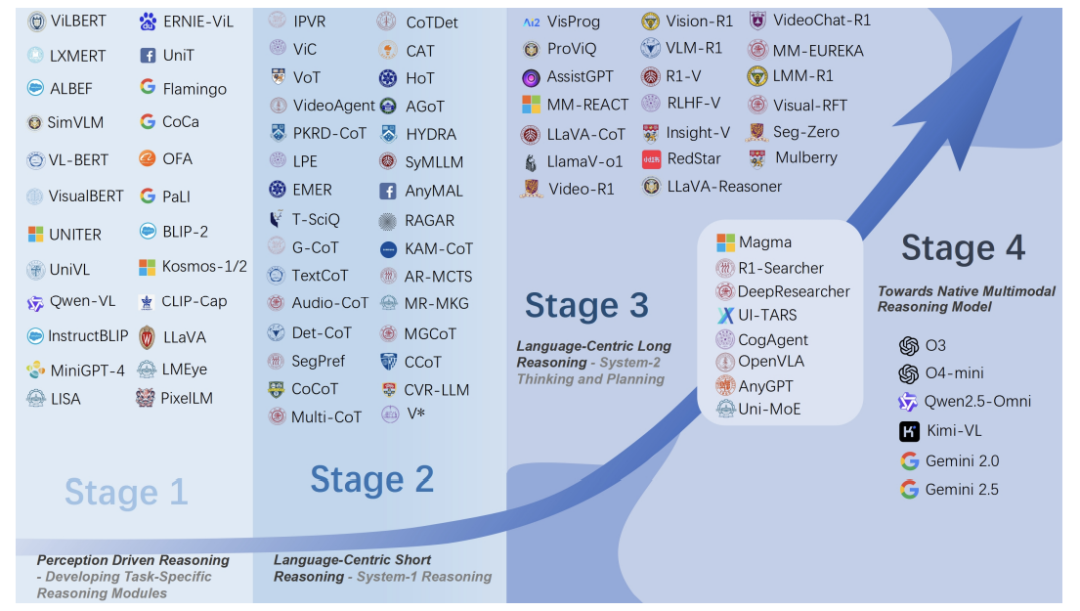 论文将技术发展分为四个阶段,如人类认知能力的升级过程:
论文将技术发展分为四个阶段,如人类认知能力的升级过程:
阶段1:模块化组装(2016-2019)
早期模型像“流水线工人”,不同模块各司其职:
-
视觉模块识别物体
-
语言模块生成描述
-
推理模块机械拼接结果
典型模型如ViLBERT、UNITER,但灵活性和泛化性差,换个任务就要重新训练。
阶段2:短链推理(2020-2022)
ChatGPT掀起“思维链(CoT)”革命后,多模态模型开始学会分步骤解释:
-
思维可视化:回答问题时展示推理过程(如“先定位物体,再分析关系”)
-
外部工具调用:用搜索引擎查资料,用画图工具辅助思考
代表技术如LLaVA、MiniGPT-4,但思考深度仅相当于人类“直觉反应”。
阶段3:长链推理(2023-2024)
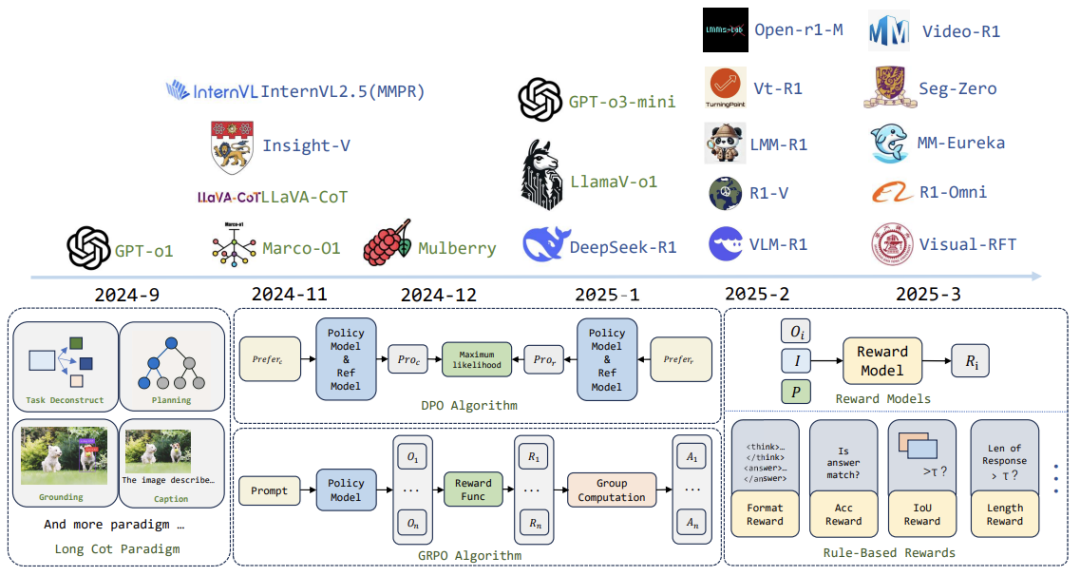 新一代模型引入“系统2思考”,像学霸解数学题般层层递进:
新一代模型引入“系统2思考”,像学霸解数学题般层层递进:
-
跨模态关联:用视频片段佐证语音结论
-
强化学习训练:通过试错优化决策路径 典型案例是OpenAI的GPT-4o,能处理长达8分钟的复杂任务(如图像编辑多轮调整)。
阶段4:原生多模态(未来)
终极目标是打造“全感知模型”:
-
统一编码:将文字、图像、声音转化为同一套“思维语言”
-
主动交互:实时调整策略,像人类一样在动态环境中学习
论文预言,这类模型将彻底打破现有架构,成为真正的“数字大脑”。
当前最强模型的能力与短板
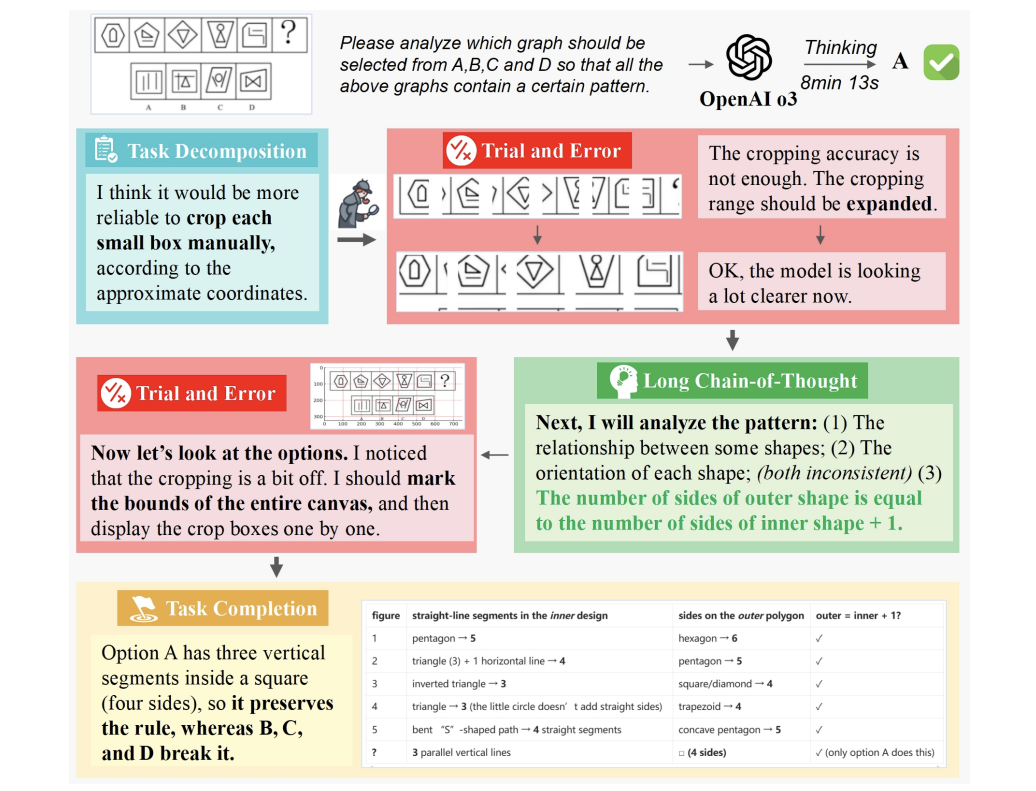

 以OpenAI的o3/o4-mini为例,论文揭露了现有顶尖模型的三大软肋:
以OpenAI的o3/o4-mini为例,论文揭露了现有顶尖模型的三大软肋:
-
感官干扰:看到“六根手指”仍坚持认为是“五根+拇指”(语言知识压倒视觉)
-
文件处理漏洞:解析PDF简历时电话号码错误,甚至编造项目经历
-
思考造假:为正确结论编造错误推理步骤(类似学生蒙对答案但过程错误)
这暴露了多模态对齐和因果推理的深层次难题。
未来模型雏形
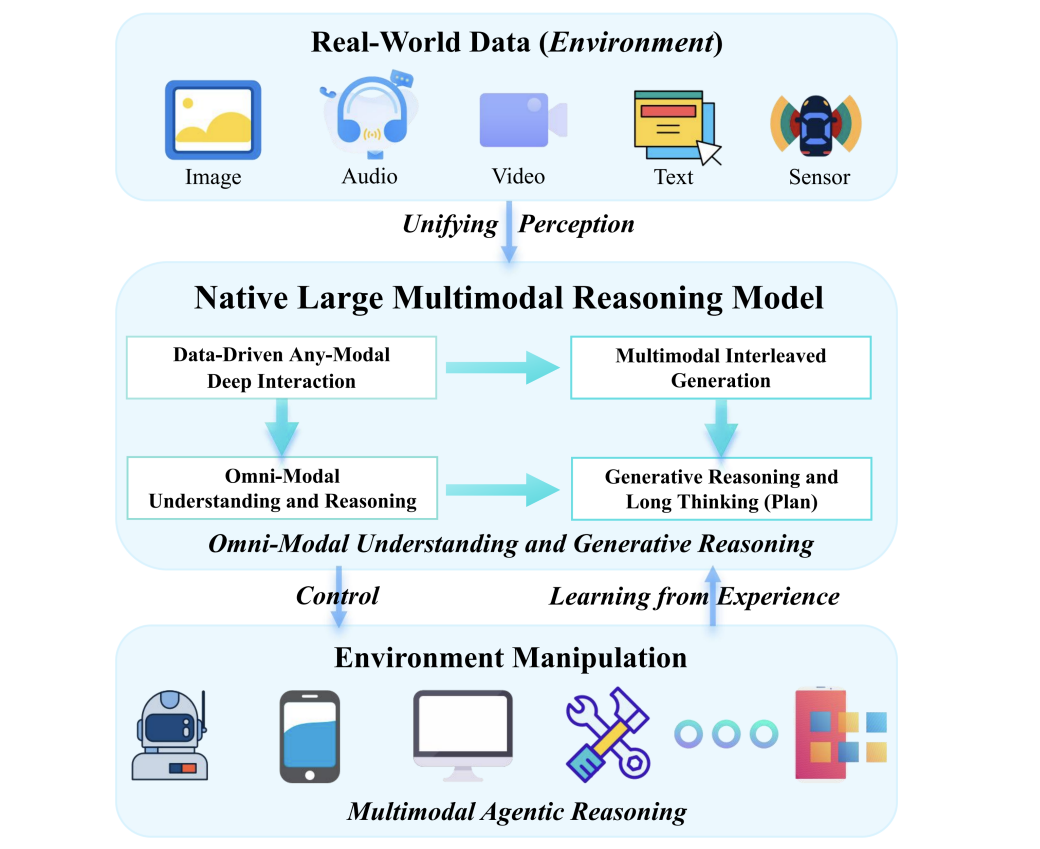 论文提出的原生多模态推理模型(N-LMRMs)具备两大颠覆性能力:
论文提出的原生多模态推理模型(N-LMRMs)具备两大颠覆性能力:
-
全能感知:同时处理文本、图像、音频、传感器数据
-
自主决策:在虚拟/现实环境中试错学习,如机器人自主规划抓取路径
关键技术突破包括:
-
MoE混合专家架构:不同模态由专用子模型处理
-
世界模型:通过模拟预测物理规律(如预测杯子掉落会破碎)
通往AGI的关键挑战
要实现上述愿景,论文指出三大攻坚点:
-
数据合成:需构建涵盖医疗、驾驶等场景的百万级多模态数据集
-
统一表示:开发跨模态的“通用编码语言”
-
实时交互:让模型在动态环境中像人类般快速响应
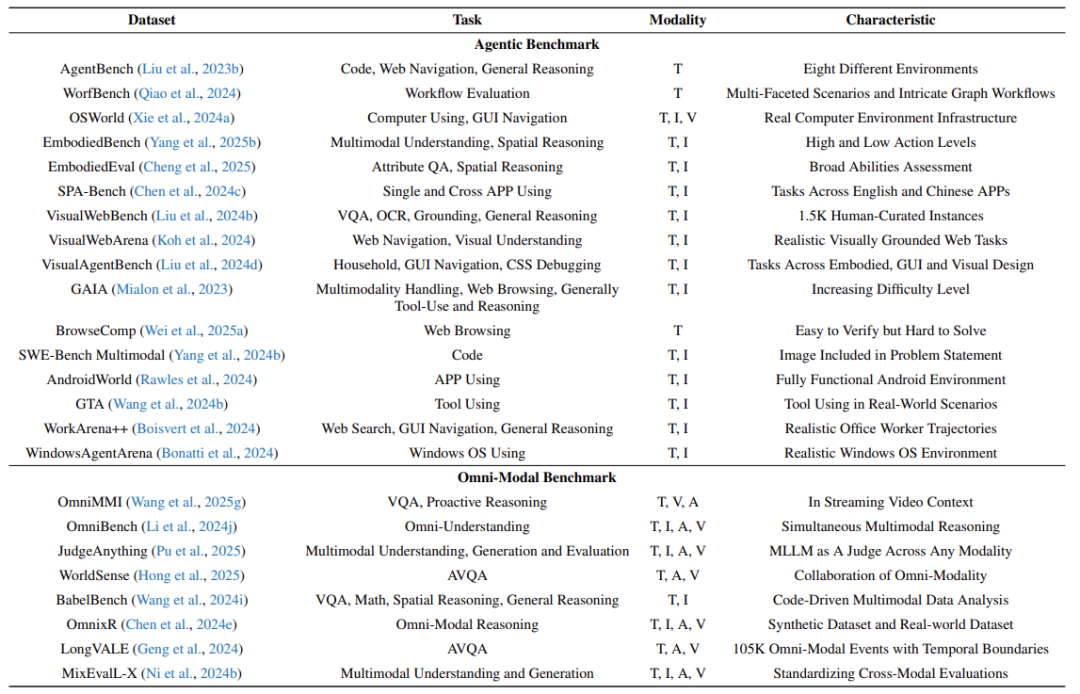
显示,现有评测基准(如OmniBench)中,顶尖模型准确率不足20%,说明技术仍处早期阶段。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 19
19 0
0- 0



 已为社区贡献123条内容
已为社区贡献123条内容

所有评论(0)