私人语音助手 Fish Speech:实现声音克隆及文本转语音
进入模型后,我们可以在「Input Text」中输入我们想要转为语音的文字,比如在里面输入「走得最急的,都是最美的风景;平台会自动选择合适的算力资源和镜像版本,这里使用的是英伟达 RTX 4090 的算力和 PyTorch 的镜像,点击「审核并执行」。稍等片刻,待系统分配好资源,状态栏显示为「运行中」后,将鼠标悬停在 API 地址处,点击链接进入模型。如果选择「Reference Audic」,模
Fish Speech 是一个由 Fish Audio 于 2024 年开发的开源文本转语音(TTS)模型,它能够生成高质量、自然的语音。这个模型经过了大约 15 万小时的数据训练,能够熟练掌握中文、日语和英语,其语言处理能力接近人类水平,并且声音表现形式丰富多变。作为一个亿级参数的模型,Fish Speech 设计高效轻量,可以在个人设备上轻松运行和微调,成为用户的私人语音助手。
使用云平台:OpenBayes
http://openbayes.com/console/signup?r=sony_0m6v
登录到 OpenBayes 平台后,打开「公共教程」,找到「Fish Speech v1.4 声音克隆-文本转语音工具 Demo」的教程。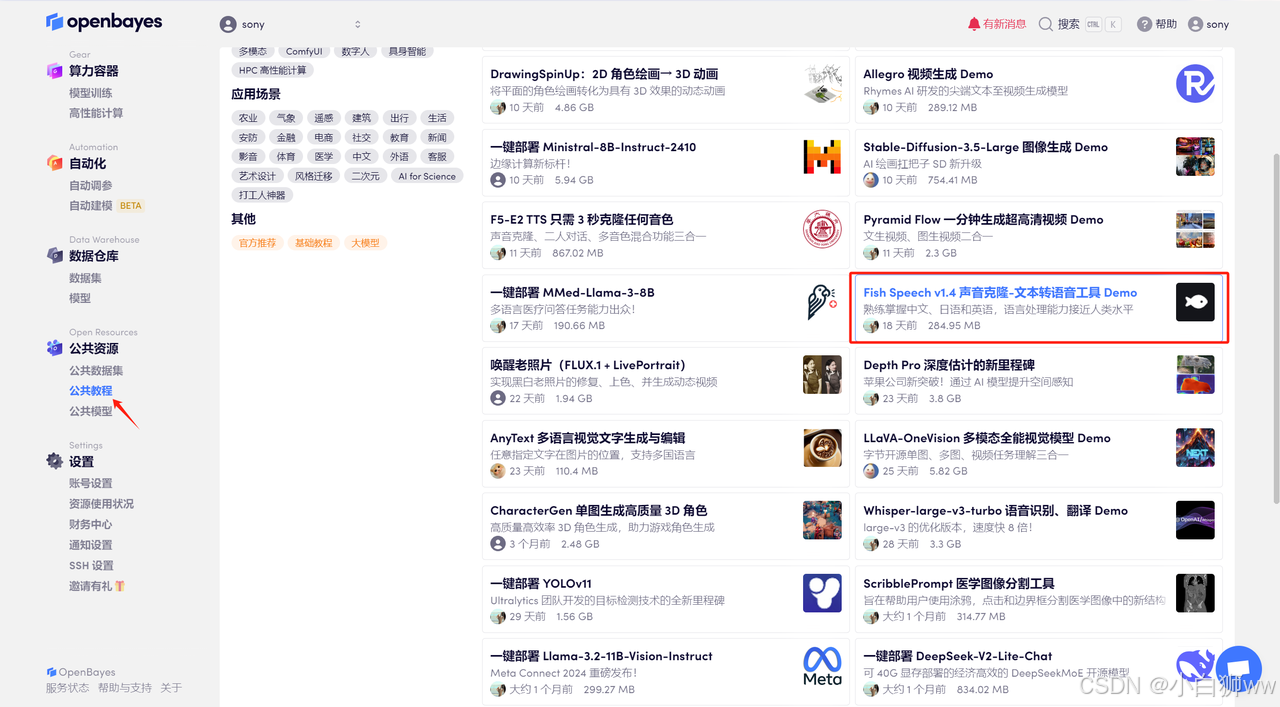
进入到教程界面后,点击右上角「克隆」。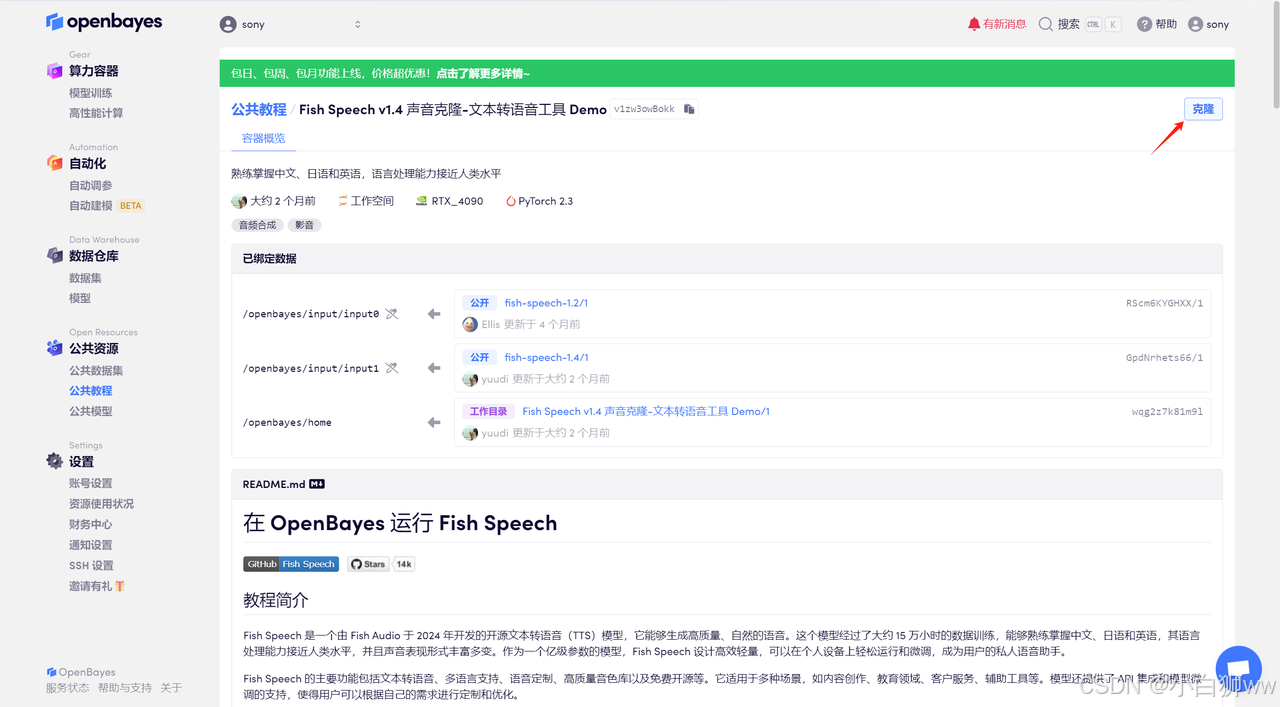
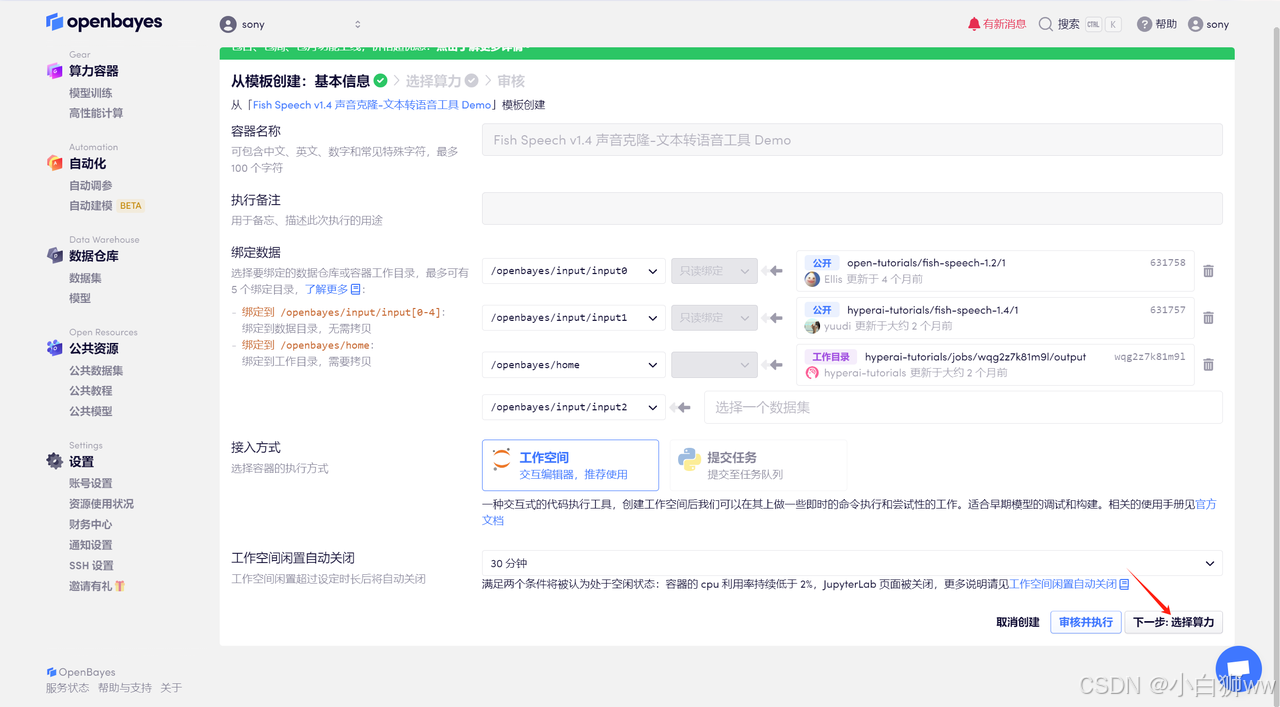
平台在克隆过程中以自动为我们配置好了模型文件,点击「下一步:选择算力」。
平台会自动选择合适的算力资源和镜像版本,这里使用的是英伟达 RTX 4090 的算力和 PyTorch 的镜像,点击「审核并执行」。可以使用文章开头的邀请链接,获得 RTX 4090 使用时长!
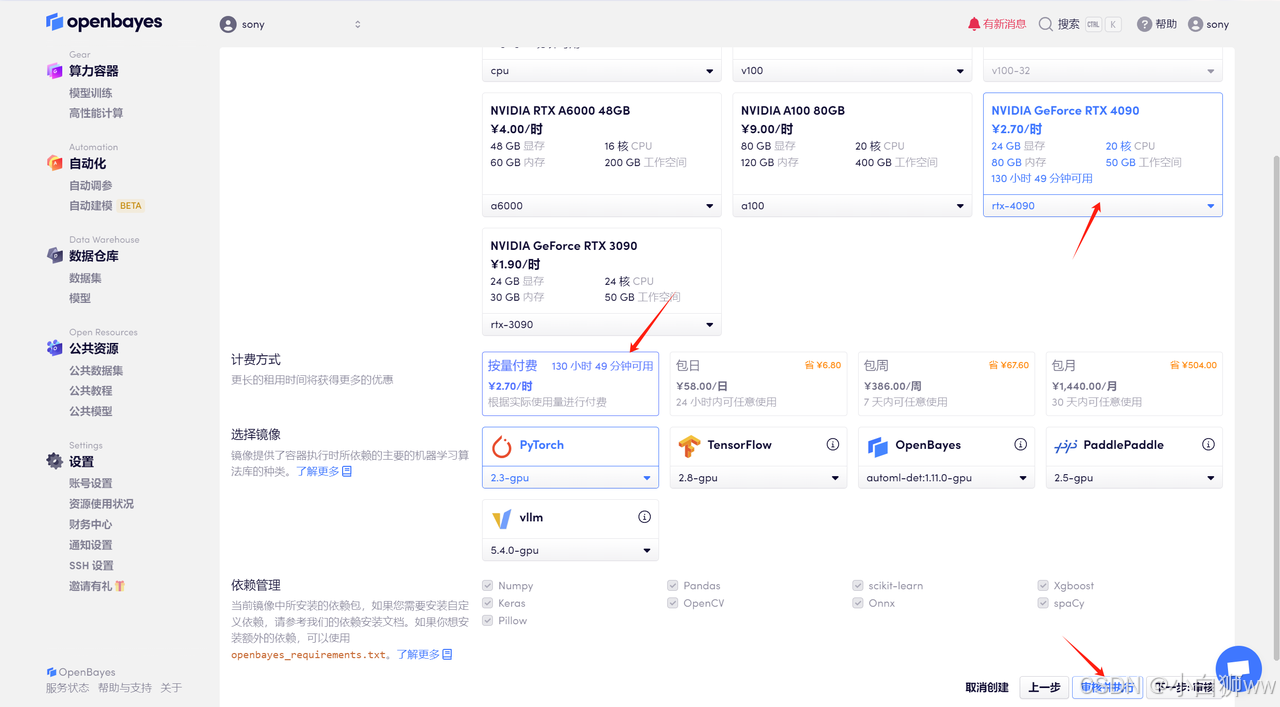
确认模型信息无误后,点击「继续执行」。
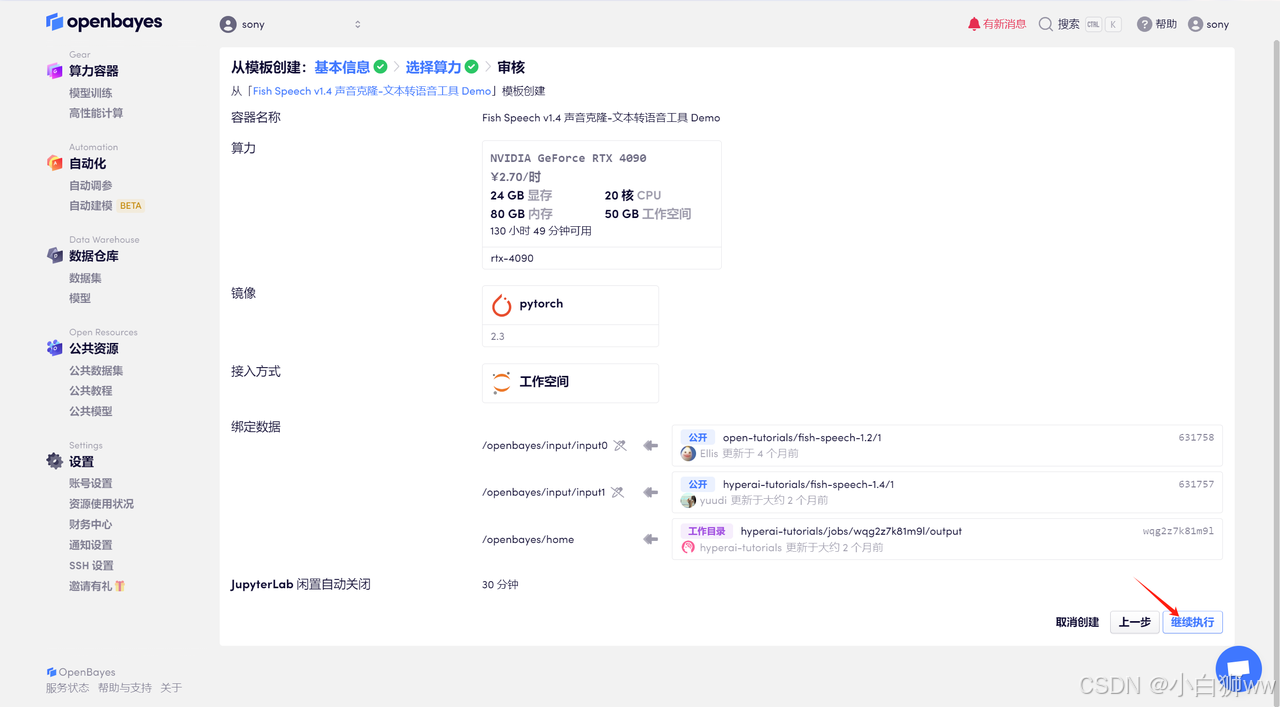
稍等片刻,待系统分配好资源,状态栏显示为「运行中」后,将鼠标悬停在 API 地址处,点击链接进入模型。进入 API 地址需要先进行实名认证~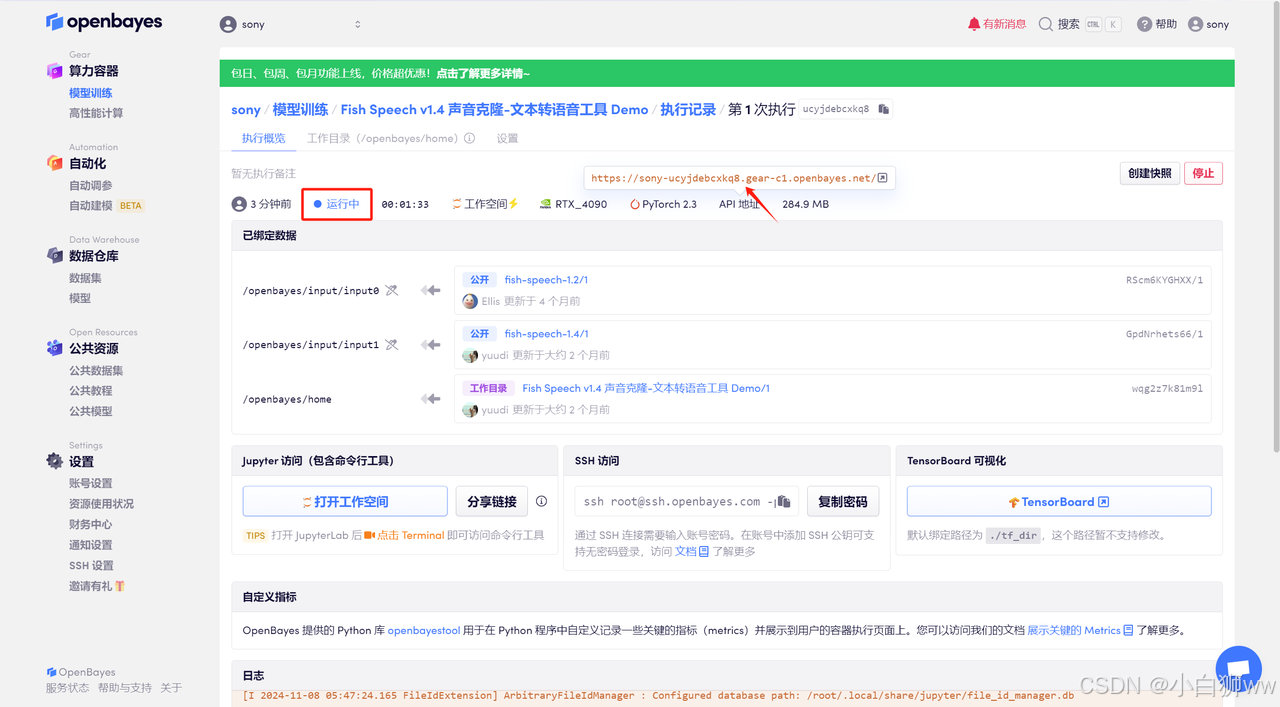

进入模型后,我们可以在「Input Text」中输入我们想要转为语音的文字,比如在里面输入「走得最急的,都是最美的风景;伤得最深的,也总是那些最真的感情。收拾起心情,继续向前走,就会发现:错过花,你将收获雨,错过雨,你会遇到彩虹。」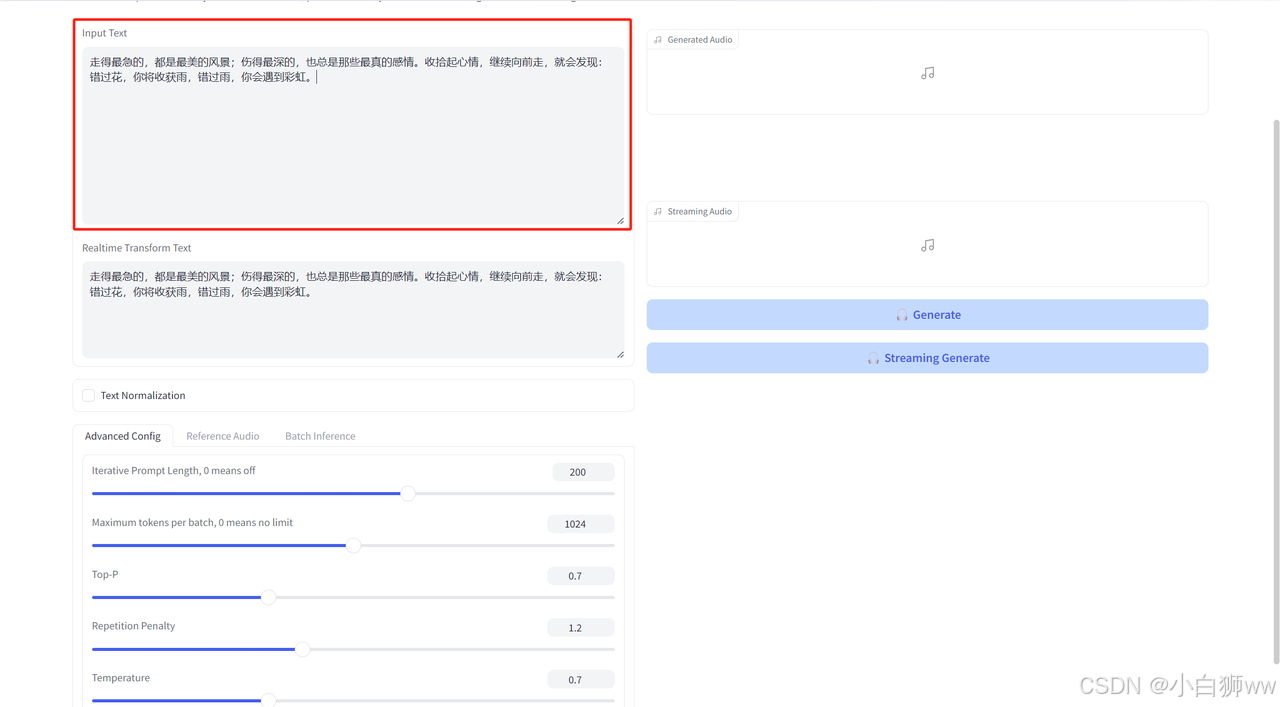
在「Advanced Config」处调整参数:
-
Iterative Prompt Length:迭代提示长度,指在生成文本时,模型将考虑的前文长度。
-
Maximum tokens per batch:批次最大标记数,限定了在每个批次中模型可以生成的最大标记(token)数。
-
Top-P:核采样,一种文本生成策略,模型在生成每一个新词时只考虑累积概率大于 P 的最小集合的词。
-
Repetition Penalty:重复惩罚,用于减少生成文本中的重复内容。
-
Temperature:温度,控制生成文本的随机性。
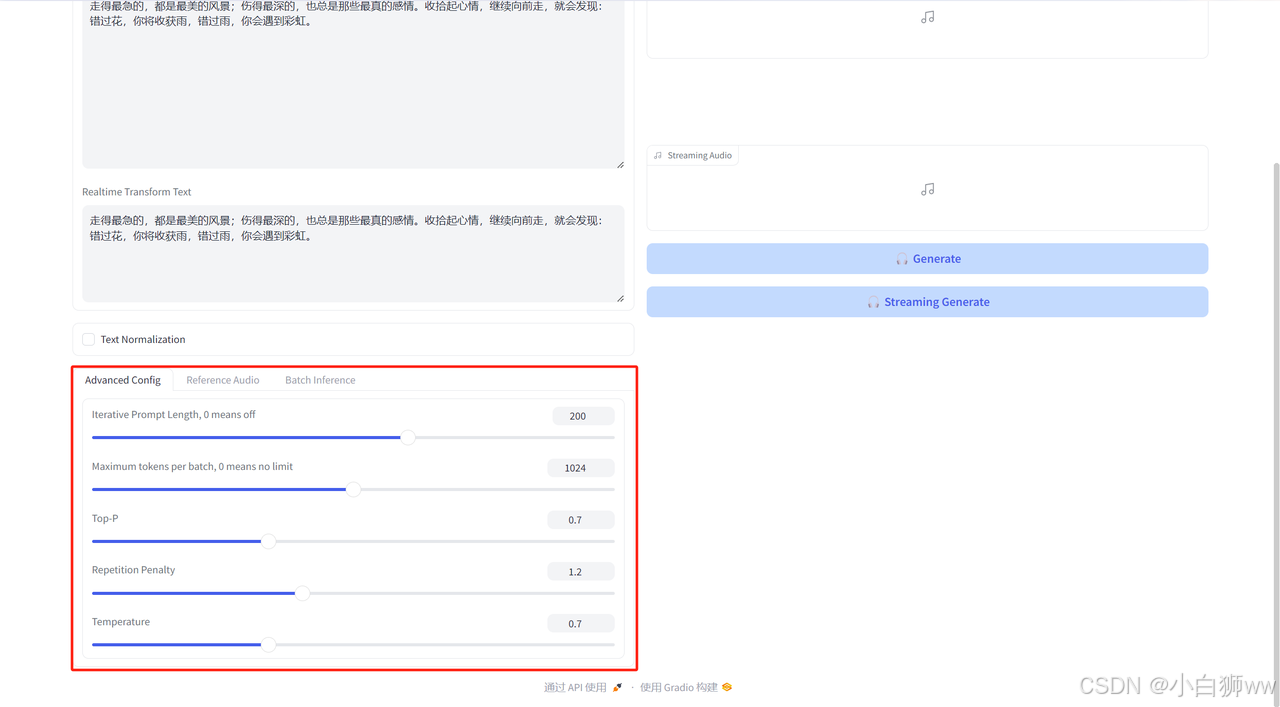
如果选择「Reference Audic」,模型将会提供一个语音模板,用户上传一段音频,模型就会根据音频的音色来生成特定的语音。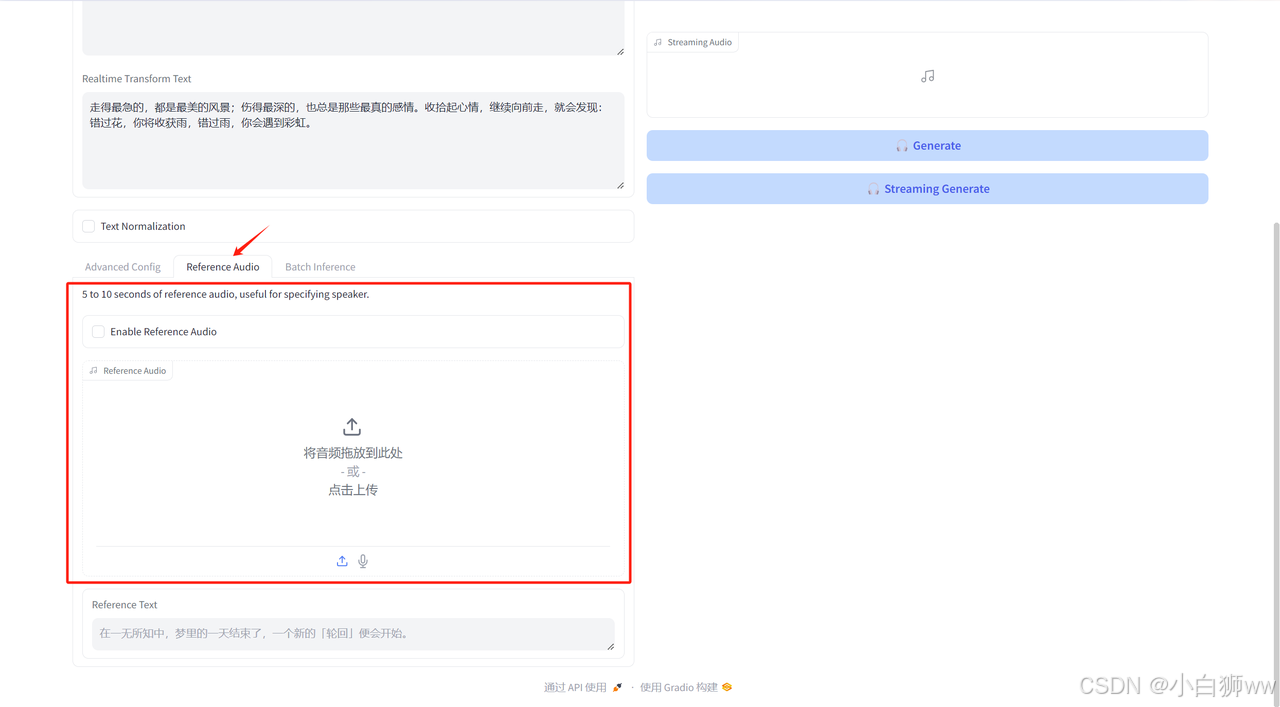
「Batch Inference」则表示生成语音的个数,默认值为「1」。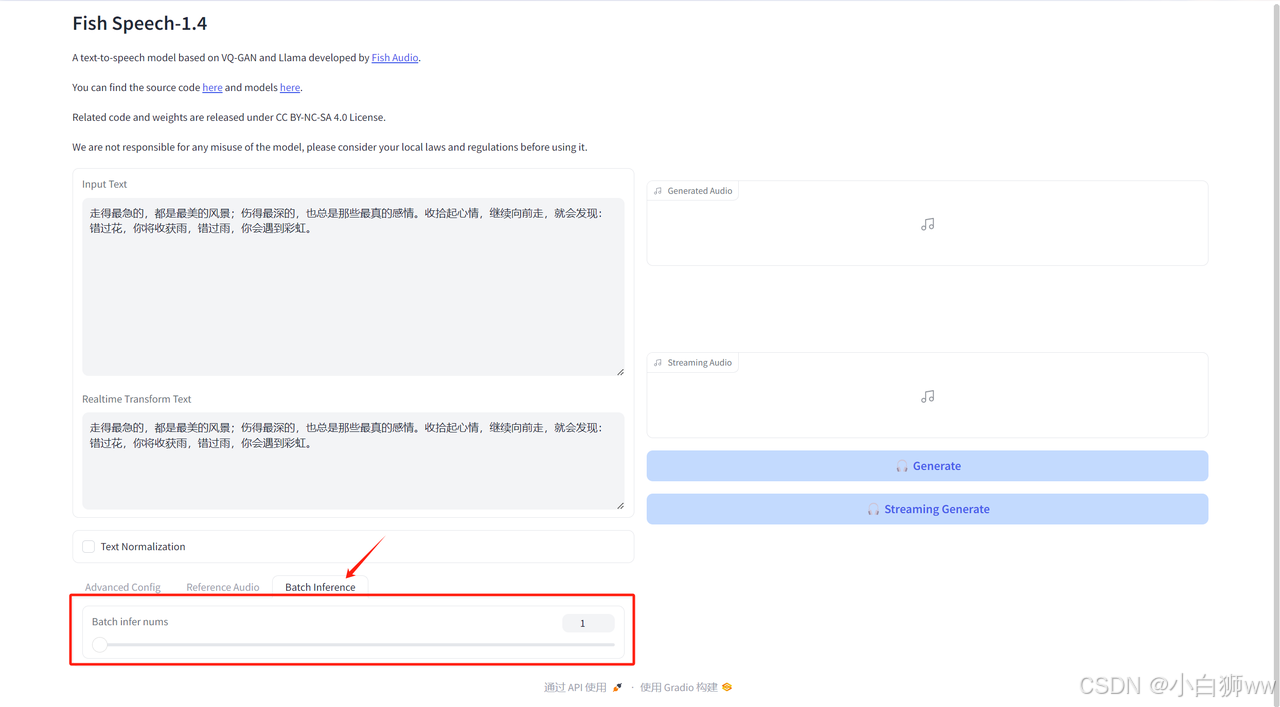
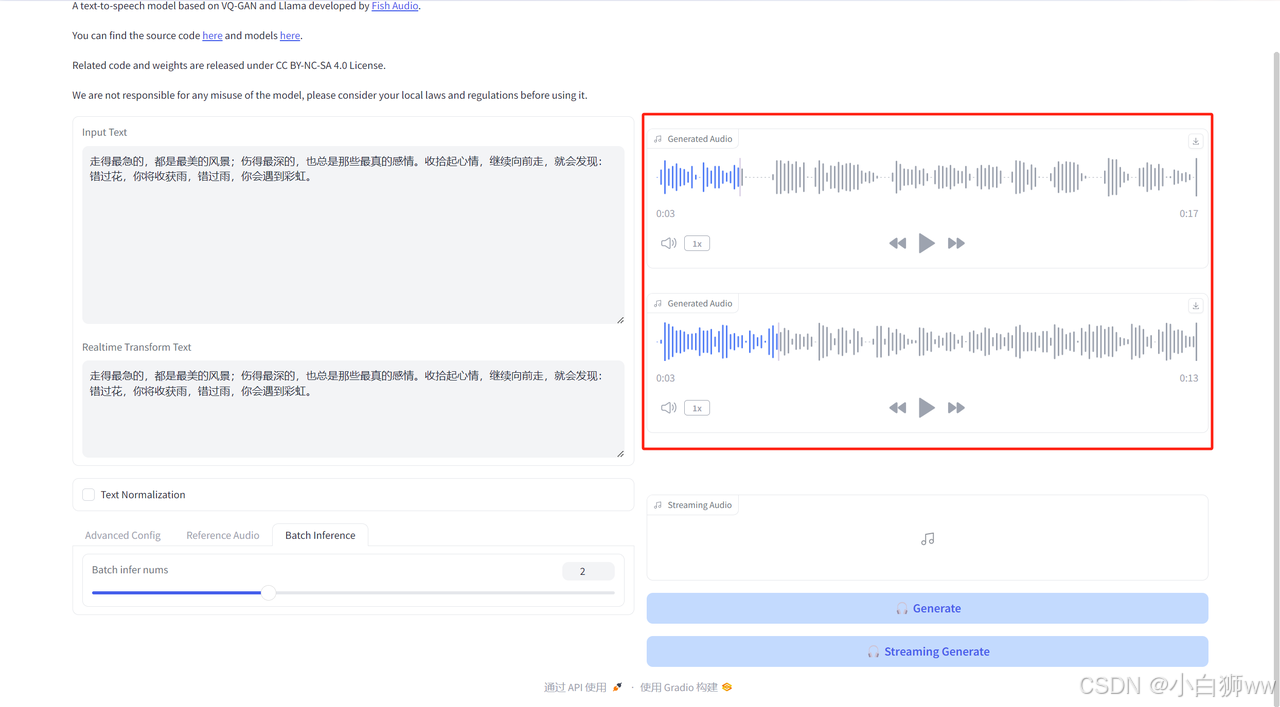
最后点击「Generate」生成。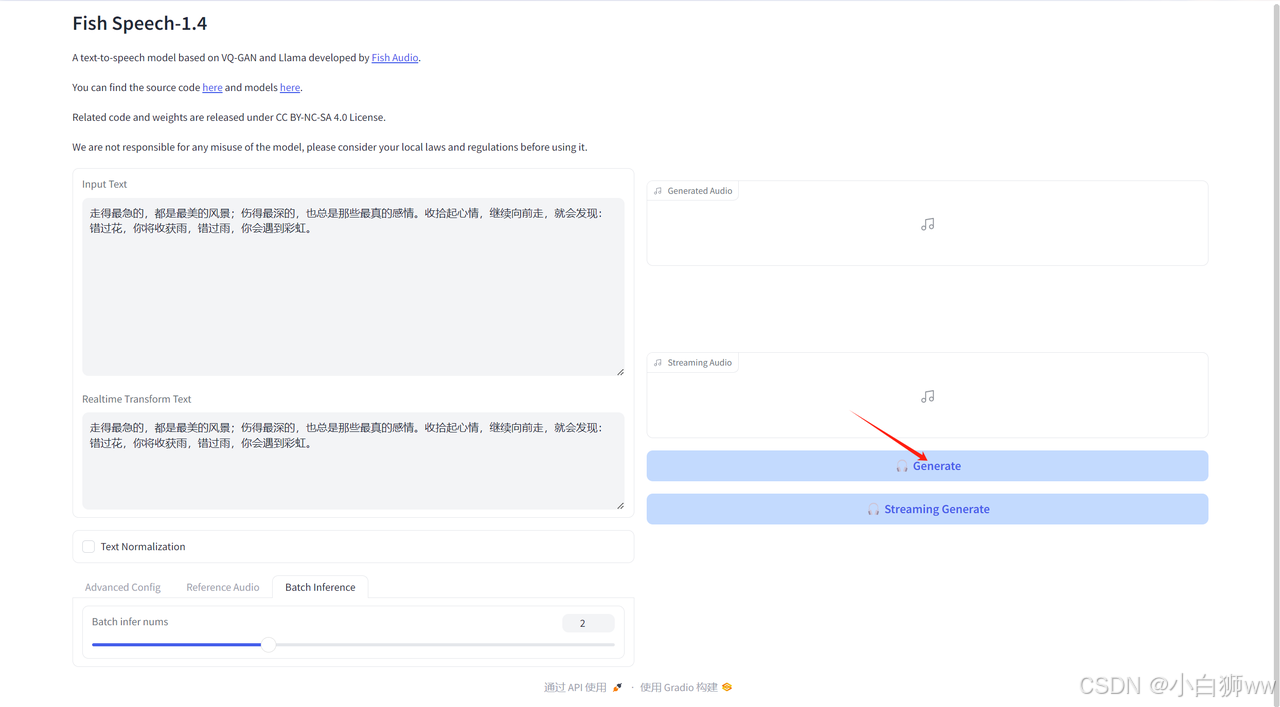

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)