吴恩达Transformer2025版最新讲解(课程详细笔记)
在前面我们讨论了transformer如何进行模块的堆叠,在语言模型处理的最后阶段,会被转换为某种评分或标记概率的计算。所以语言模型头的结果是这种标记概率评分,表明在所有已知的token中每个token各自都多少概率会被输出,这些概率之和也就是百分之一百。贪婪解码(如选择最高概率的token)生成确定性结果,但可能陷入局部最优;Top-p(核采样)从累积概率阈值内的候选集中随机抽取,平衡多样性与合
Transformer学习(吴恩达2025最新课程笔记)
原视频地址 How Transformer LLMs Work - DeepLearning.AI
transformers QKV讲解网站:The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
一、词语言袋
近期AI语言模型的发展历程(了解)
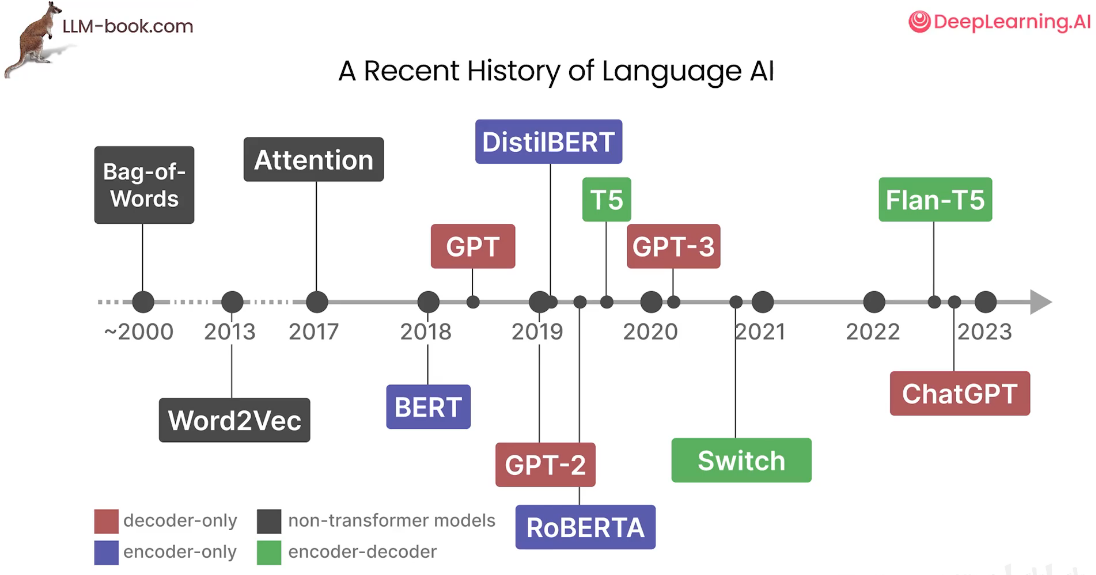
Non-Transformer Models(2017年前)
在Transformer出现之前,主流的语言模型主要基于循环神经网络(RNN)和卷积神经网络(CNN):
-
RNN/LSTM/GRU:通过循环结构处理序列数据,但存在长距离依赖问题(如梯度消失/爆炸),难以并行化训练
-
Word2Vec/GloVe:基于词嵌入的静态表示模型,无法捕捉上下文动态语义。
-
ELMo(2018):首次引入上下文感知的词向量,通过双向LSTM提取多层特征,但仍是RNN的变体
特点:模型规模较小,计算效率低,难以处理长文本
Transformer架构的诞生(2017)
关键论文:Vaswani等人提出《Attention Is All You Need》(2017),用自注意力机制(Self-Attention)替代循环结构
-
核心优势:并行化计算、长距离依赖建模、可扩展性强
基于Transformer的三大主流架构
(1) Encoder-Only Models(双向编码器)
-
特点:专注于理解上下文,适合分类、问答等任务
-
代表模型:
-
BERT(2018):通过掩码语言建模(MLM)和下一句预测(NSP)预训练,首次实现双向上下文编码
-
RoBERTa(2019):优化BERT的预训练策略(如移除NSP、增大数据量)
-
DeBERTa(2020):引入解耦注意力机制,提升细粒度语义建模能力
-
(2) Decoder-Only Models(自回归生成模型)
-
特点:单向生成文本,适合文本生成(如对话、续写)
-
代表模型:
-
GPT系列(2018-2023):从GPT-1到GPT-4,逐步扩大参数规模(175B到数万亿),采用自回归预训练
-
PaLM(2022):谷歌的540B参数模型,专注于Few-shot和Zero-shot学习
-
LLaMA(2023):Meta开源的轻量级高效模型(7B-65B参数)
-
(3) Encoder-Decoder Models(序列到序列模型)
-
特点:结合编码器和解码器,适合需要双向理解和生成的任务(如翻译、摘要)
-
代表模型:
-
BART(2019):通过去噪自编码预训练,支持多种生成任务
-
T5(2020):统一所有NLP任务为“文本到文本”格式,使用多任务预训练
-
Flan-T5/Flan-UL2(2022):通过指令微调(Instruction Tuning)提升模型泛化能力
-
我们对一句话中的所有单词进行划分为单独的单词,这个操作就是分词,分词后输入的文本将转变为tokens。对所有的单词构建一个单词表,单词数量就是单词表的大小,这位我们后面的向量表示做准备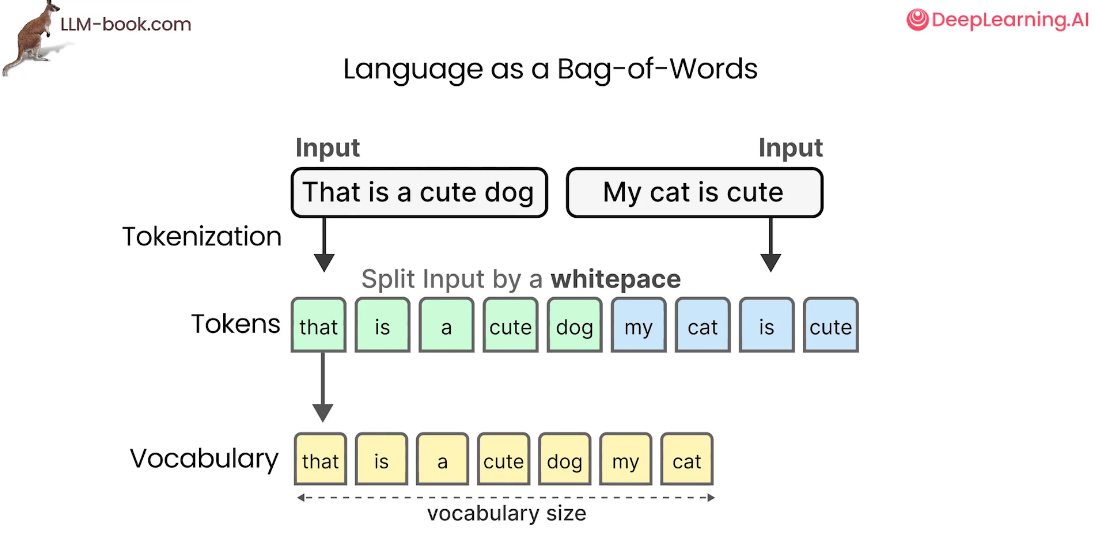
以 My cat is cute 为例,它的向量化表示就是对每个单词在前面定义的单词表中频率的一个统计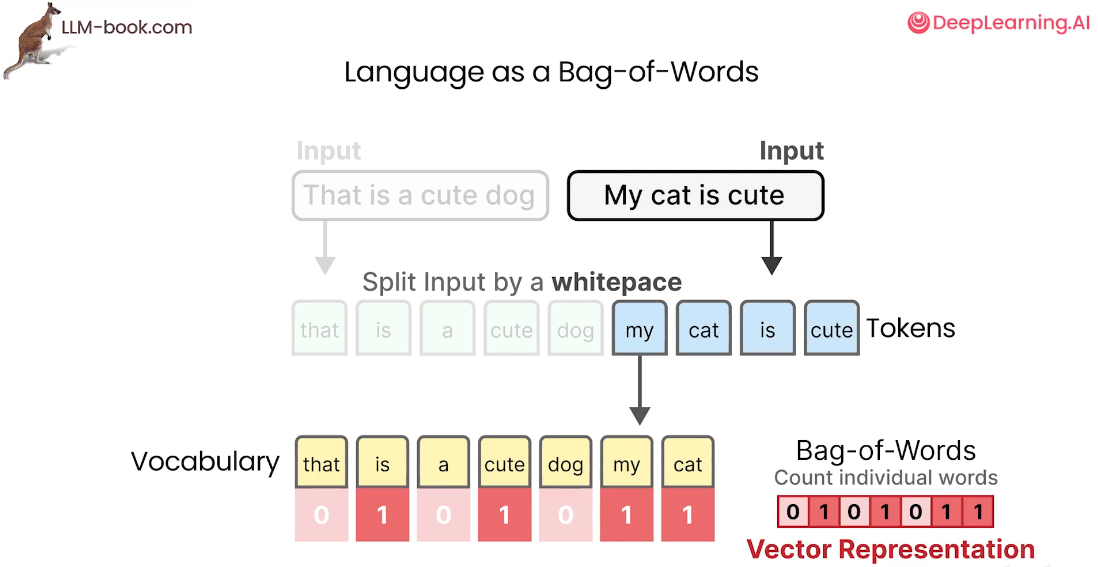
二、词嵌入
词袋模型有一个缺陷,它把文本简单看作“一堆单词的集合”,完全忽略单词之间的顺序、结构和上下文关系,导致无法真正理解语言的意义
Word2Vec是首次成功尝试捕捉文本意义的方法之一,它通过嵌入来实现这一点。Word2Vec通过在大量文本数据上进行训练来学习单词的语义表示,它利用神经网络可以得到每个单词的词嵌入表示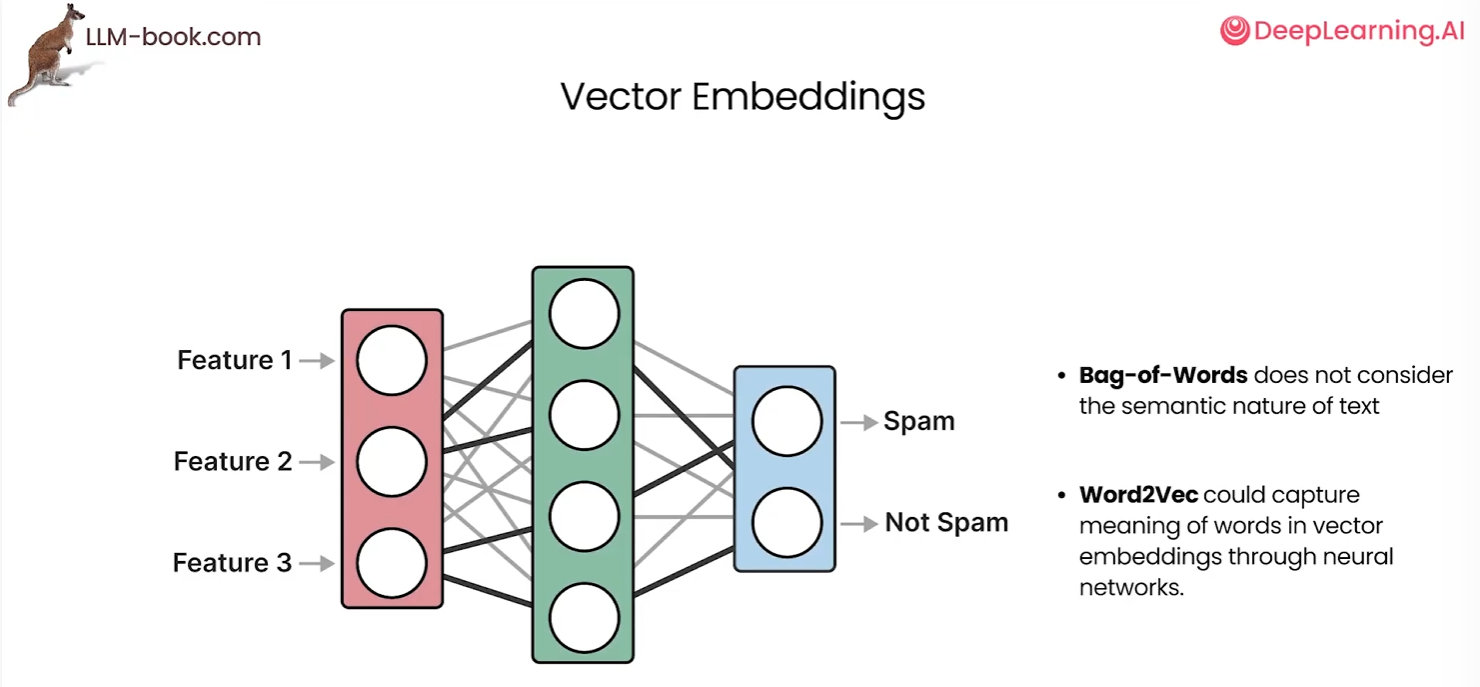
在一个给定句子中,首先要为你的词汇表里的每个单词分配一个向量嵌入,将设每个单词初始化五个值(可以随机生成),然后在每次训练过程中,从训练数据中取一对单词,模型尝试预测它们是否可能在一个句子中成为邻居。在这个过程中,Word2Vec学习单词之间的关系并提炼。如果两个单词倾向于优相同的邻居,他们会嵌入彼此更接近,反之亦然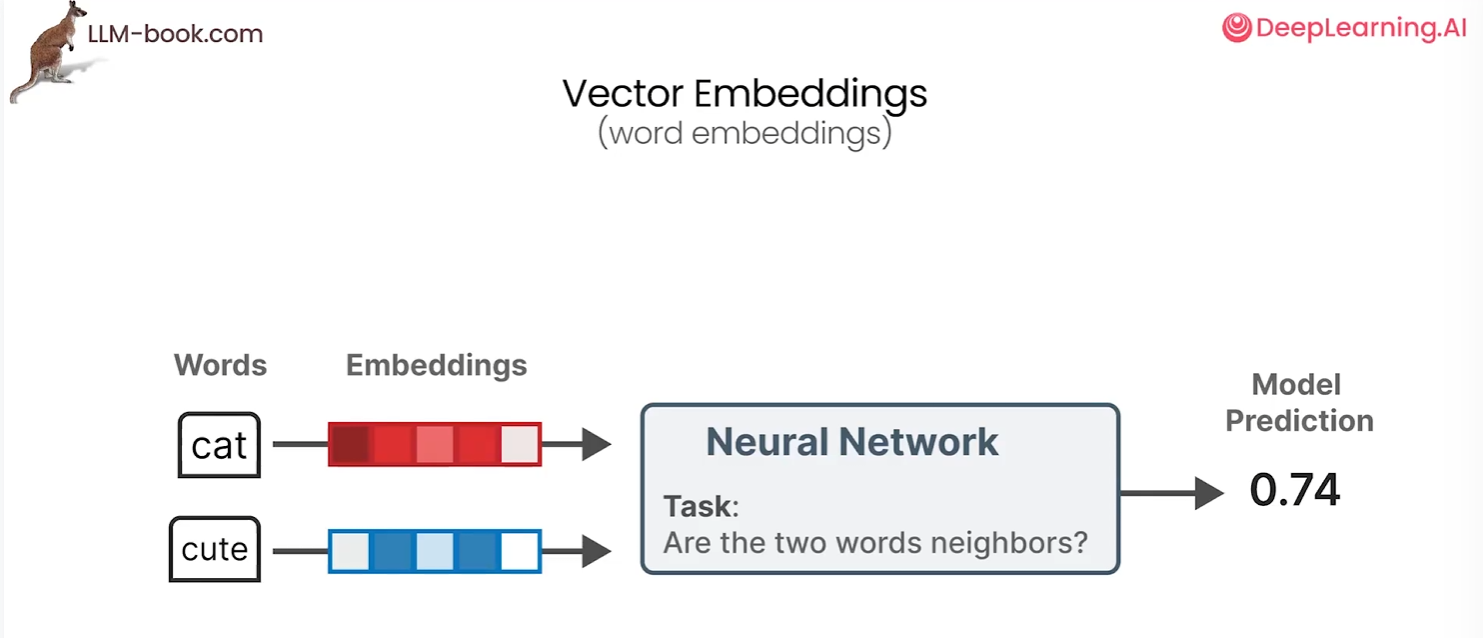
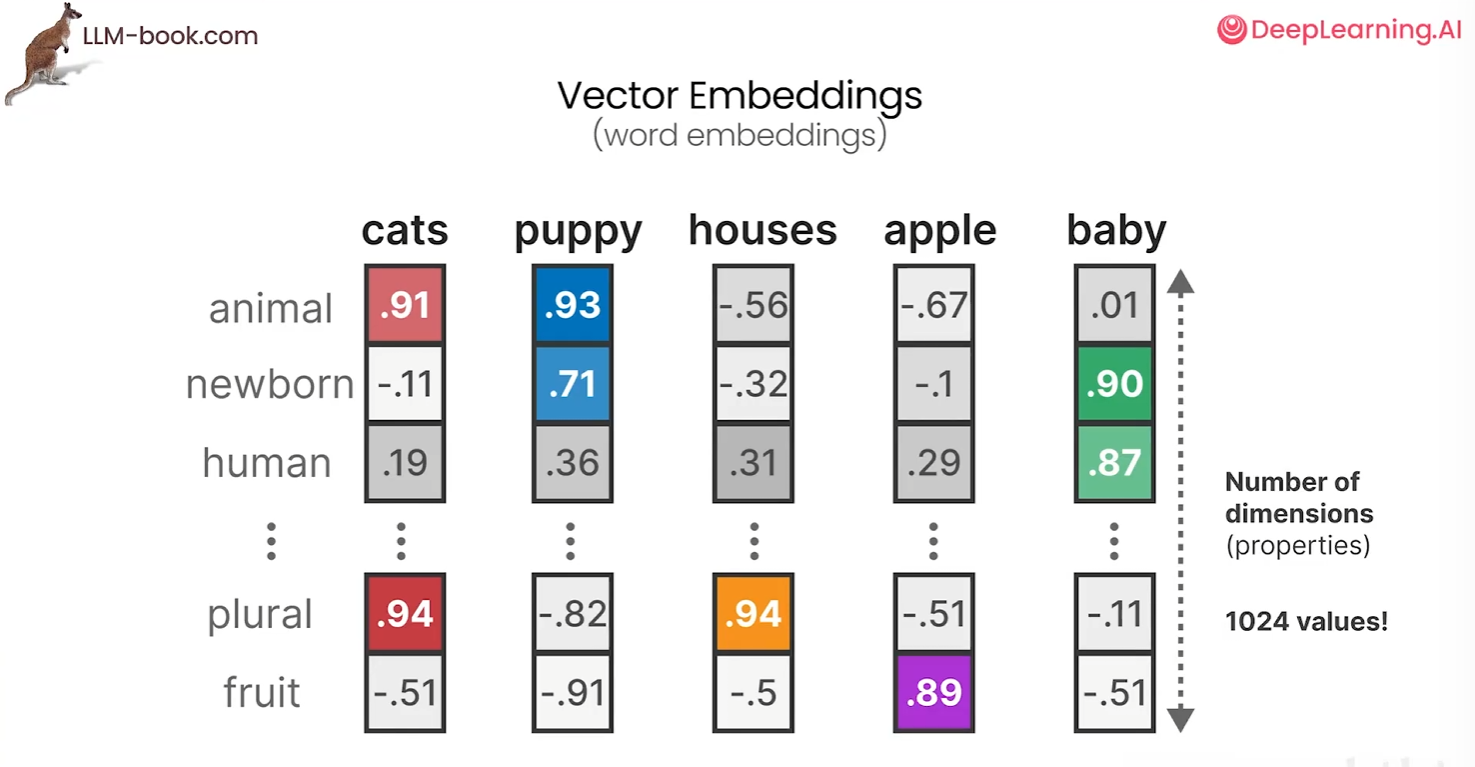
在实际操作中,我们并不知道这些属性具体代表什么,因为他们是通过复杂计算而得。这额属性允许你比较嵌入,因此具有相似含义的单词会被分组在一起,意义不同的单词则相距较远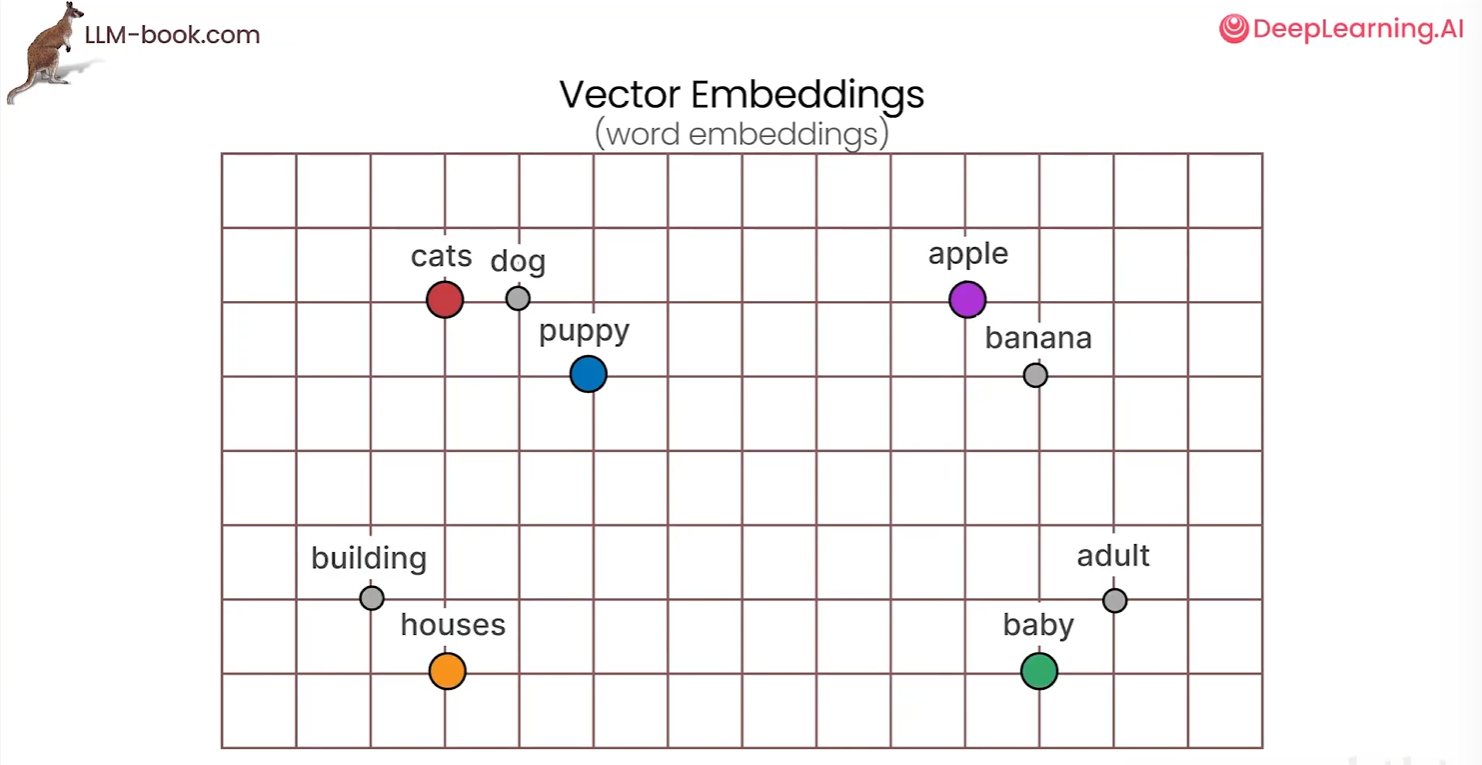
所以当得到了词嵌入后,我们可以利用这些词嵌入向量来创建句子嵌入,甚至更长的文档嵌入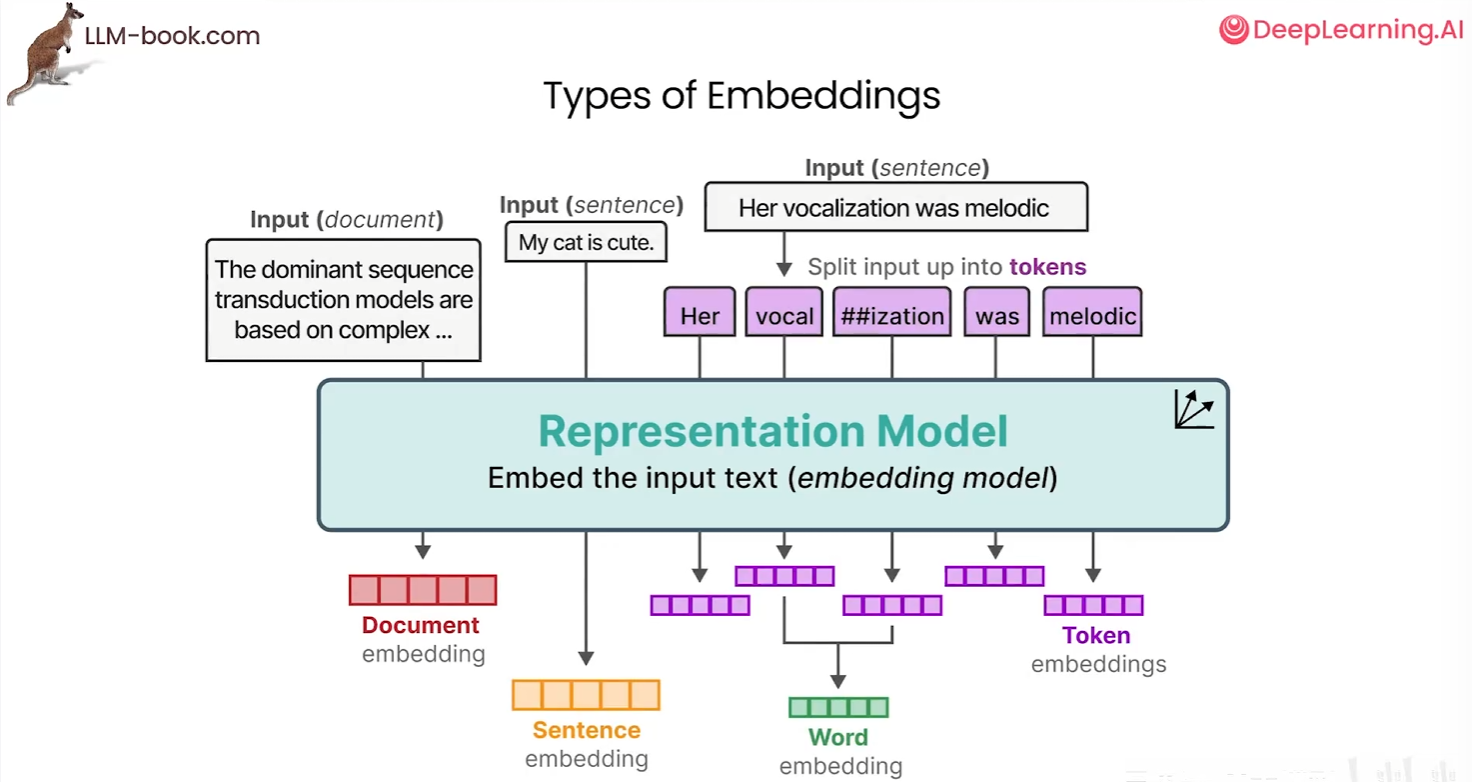
三、利用注意力机制对上下文进行编码和解码
单词到向量的静态嵌入,无论上下文如何,单词bank生成的词嵌入是相同的,但是bank既可以指银行,也可以指河畔,其意义应该和上下文而变化。捕捉文本上下文对于执行一些语言任务比如翻译任务很重要
编码这一步可以通过循环神经网络来实现,这是神经网络的变体,可以使用额外输入来建模序列。这些RNN用于两个任务,编码或表示句子输入,解码或生成句子输出。例如下面ppt,将I love llamas 翻译成荷兰语。文本通过编码器传递,试图通过一个嵌入表示整个序列,解码器使用嵌入进而生成语言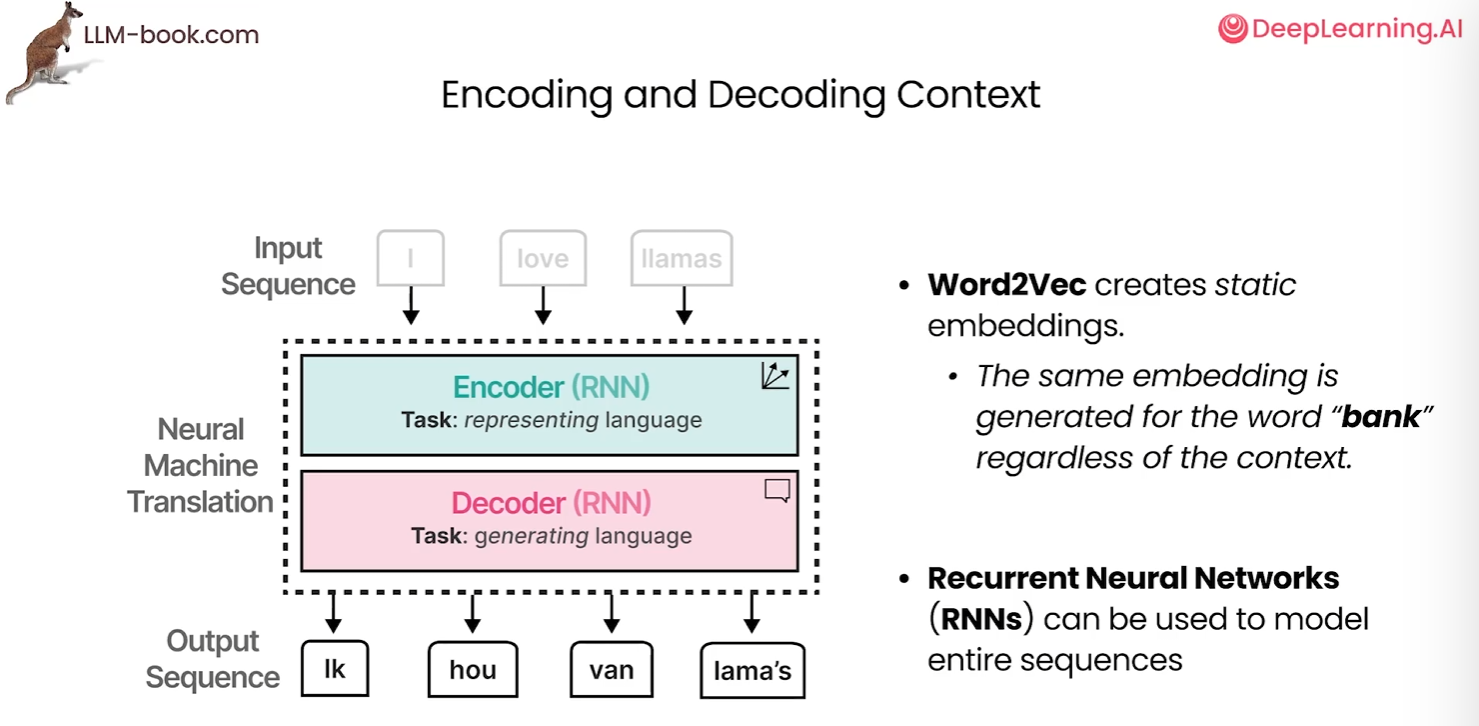
每一步在这个架构中都是自回归的,它会将某一次的输入和输出都作为下一次的输入,直到整个输出生成。大多数模型都是自回归的,因此在每次生成时都会生成一个标记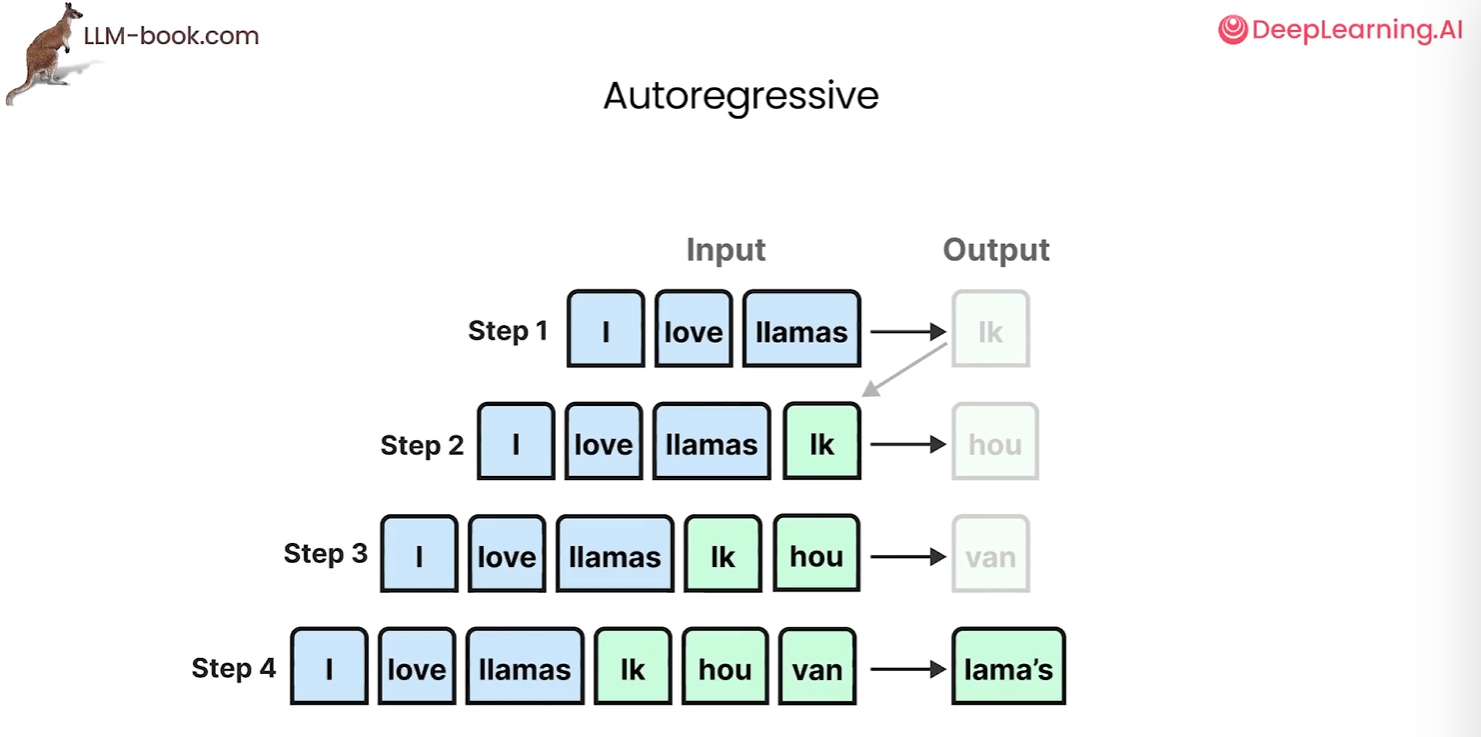
进一步探讨,我们首先将 I love llamas 芬妮此,使用单词到向量创建嵌入作为输入,编码器一次处理整个序列并考虑嵌入的上下文;解码器负责生成语言,通过利用之前生成的上下文嵌入(context embedding)来生成最终的输出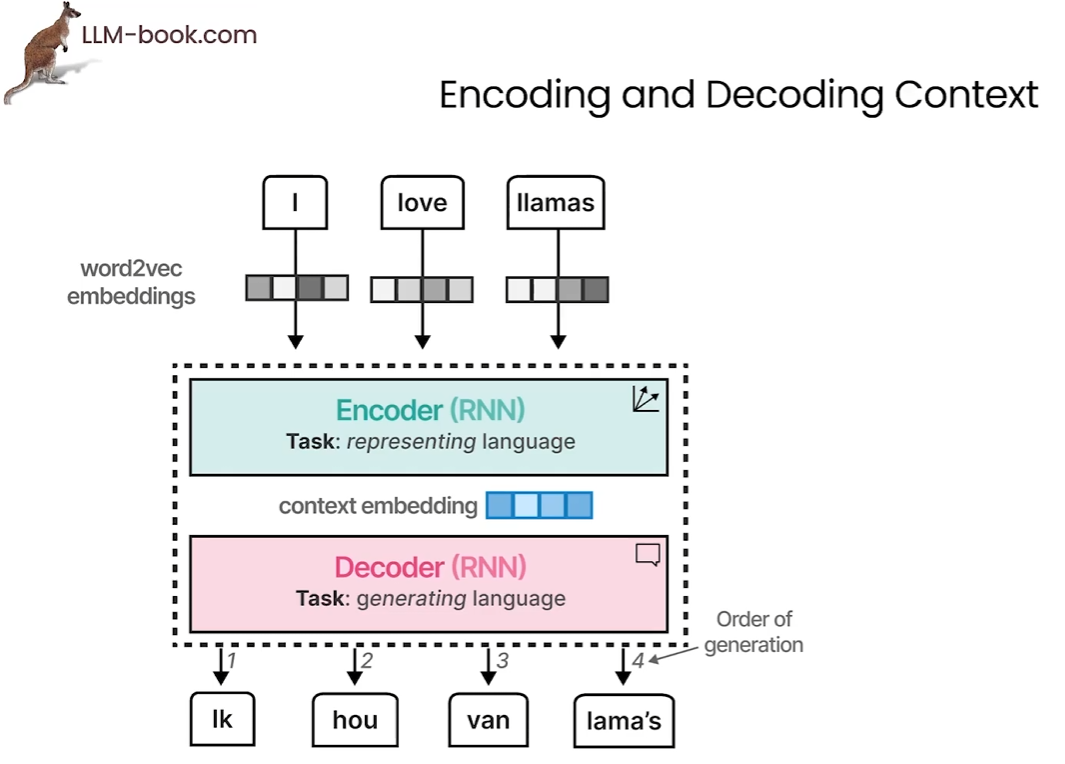
然而,因为一个上下文嵌入就代表了整个输入,这使得处理更长的句子变得困难,单一的嵌入可能无法捕捉到长而复杂序列的全部上下文。2014年,注意力的解决方案诞生,极大改进了原始架构。使用注意力能够关注输入序列中相关的部分,放大他们的信号,选择性的确定句子中那些单词最重要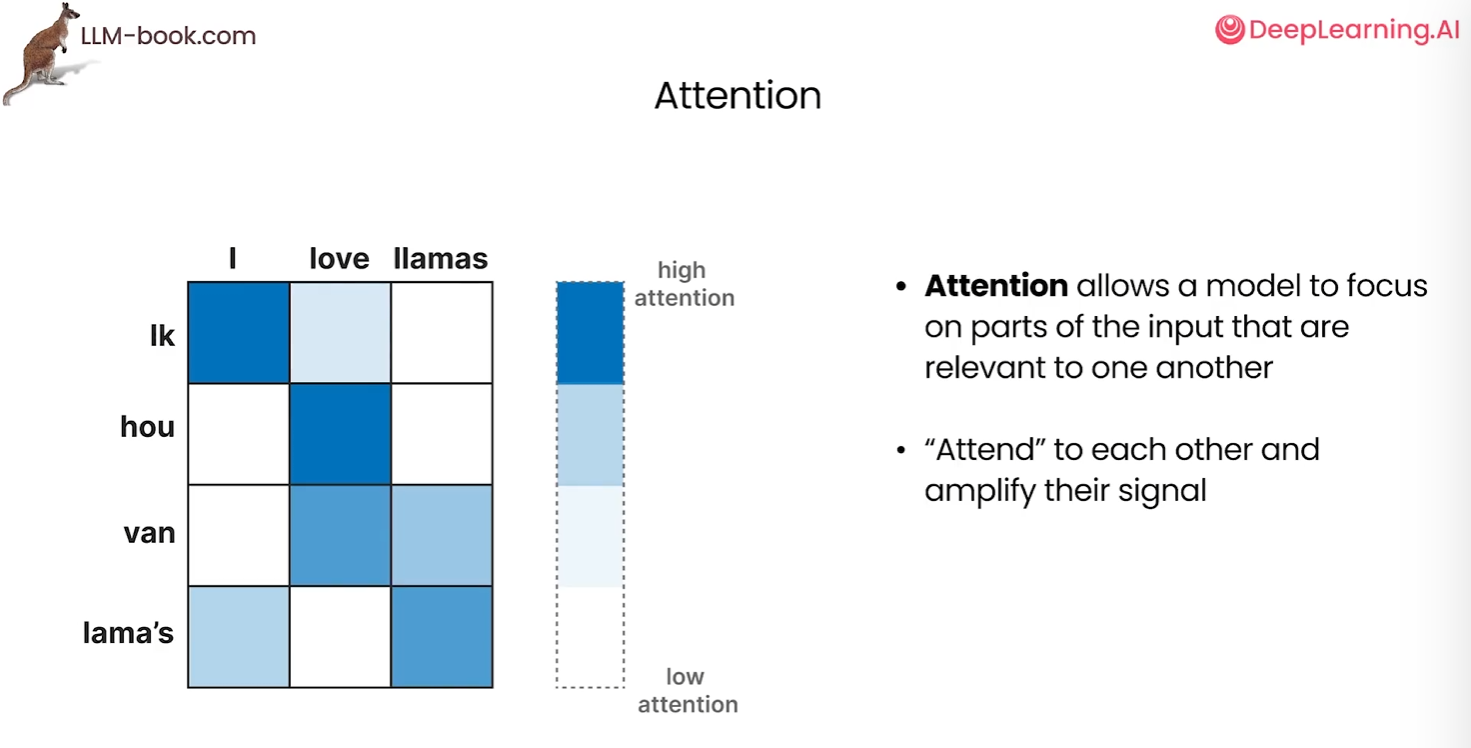
我们可以再次使用Word2Vec嵌入来表示输入,并将这些嵌入传给编码器,所有输入单词的隐藏状态都传递给解码器。某个单词的隐藏状态是一个内部因素,他是一个RNN隐藏层的状态,包含了关于先前单词的信息。解码器使用注意力机制生成了语言,输出往往会更好。因为现在使用了每个单词的嵌入查看整个序列而不是使用更小和更有限的上下文嵌入,所以在生成过程中模型会关注最相关的输入
四、Transformers
在《Attention is all you need》中,它创建了完全基于注意力机制,没有循环神经网络的架构,这使得允许模型进行并行计算,并且大大加快了计算速度
transformer 由堆叠的编码器和解码器块组成,这些块都包含之前说的相同的注意力机制,通过堆叠这些快可以增强编码器和解码器的强度。我们从单词随机向量表示开始,使用注意力机制,嵌入和更新它们,这些更新的嵌入向量由于注意力机制而包含更多的上下文信息。然后他们被传递给一个前馈神经网络,最终创建上下文化的单词嵌入
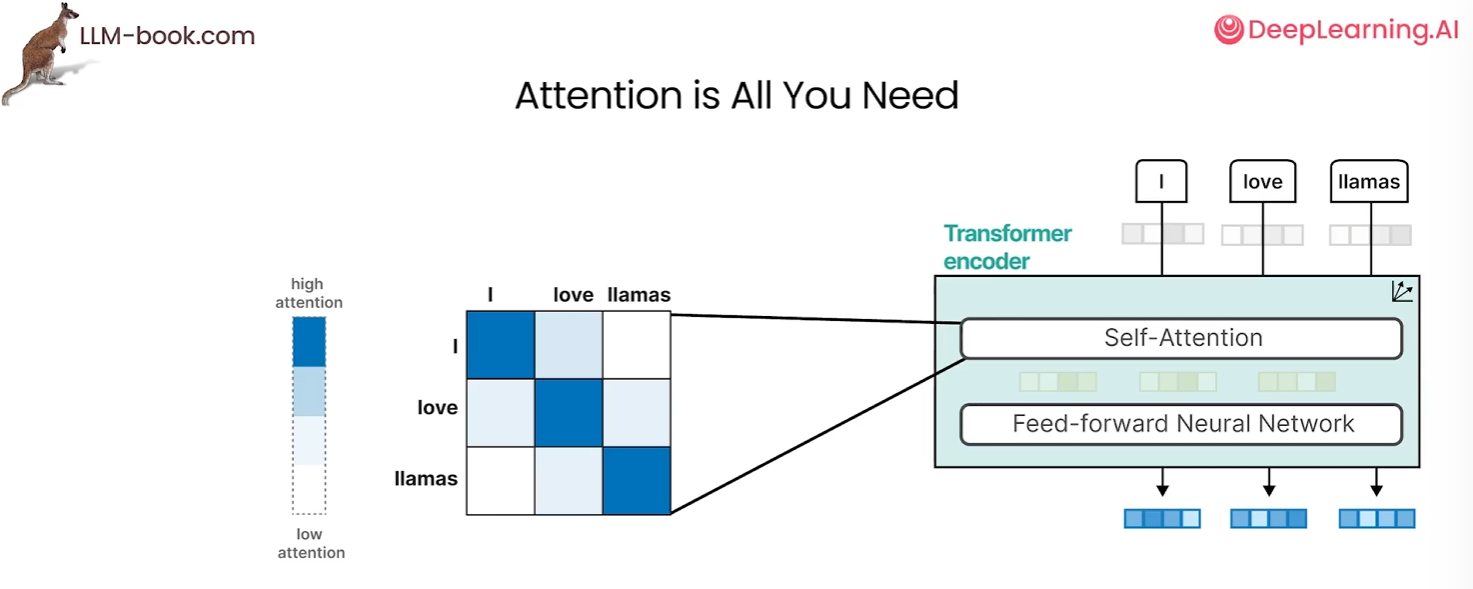
注意,编码器的作用是将文本转化为蕴含上下文信息的词嵌入,而自注意力机制通过分析同一序列内词语间的关联(例如“猫”与“垫子”的语义关系),帮助编码器捕捉这些语义,无需依赖其他外部序列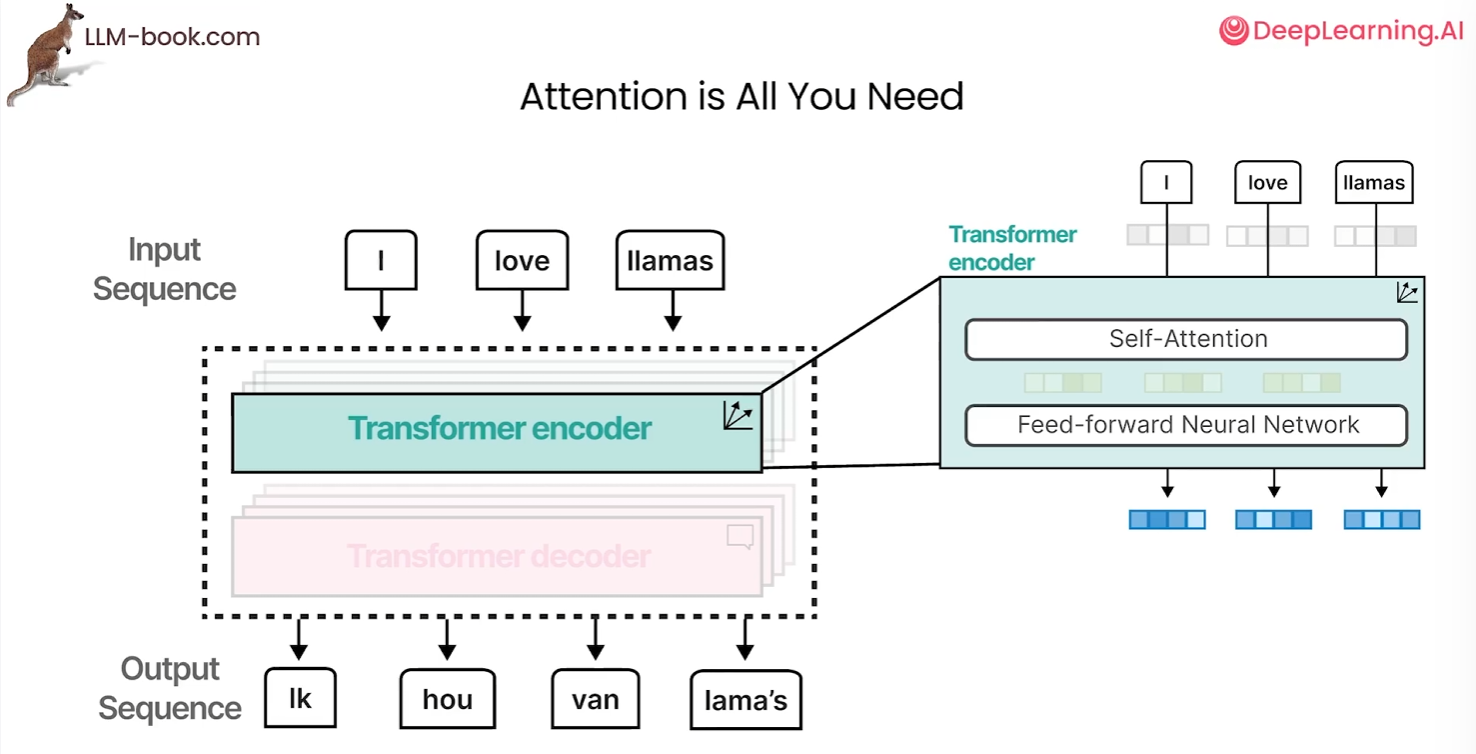
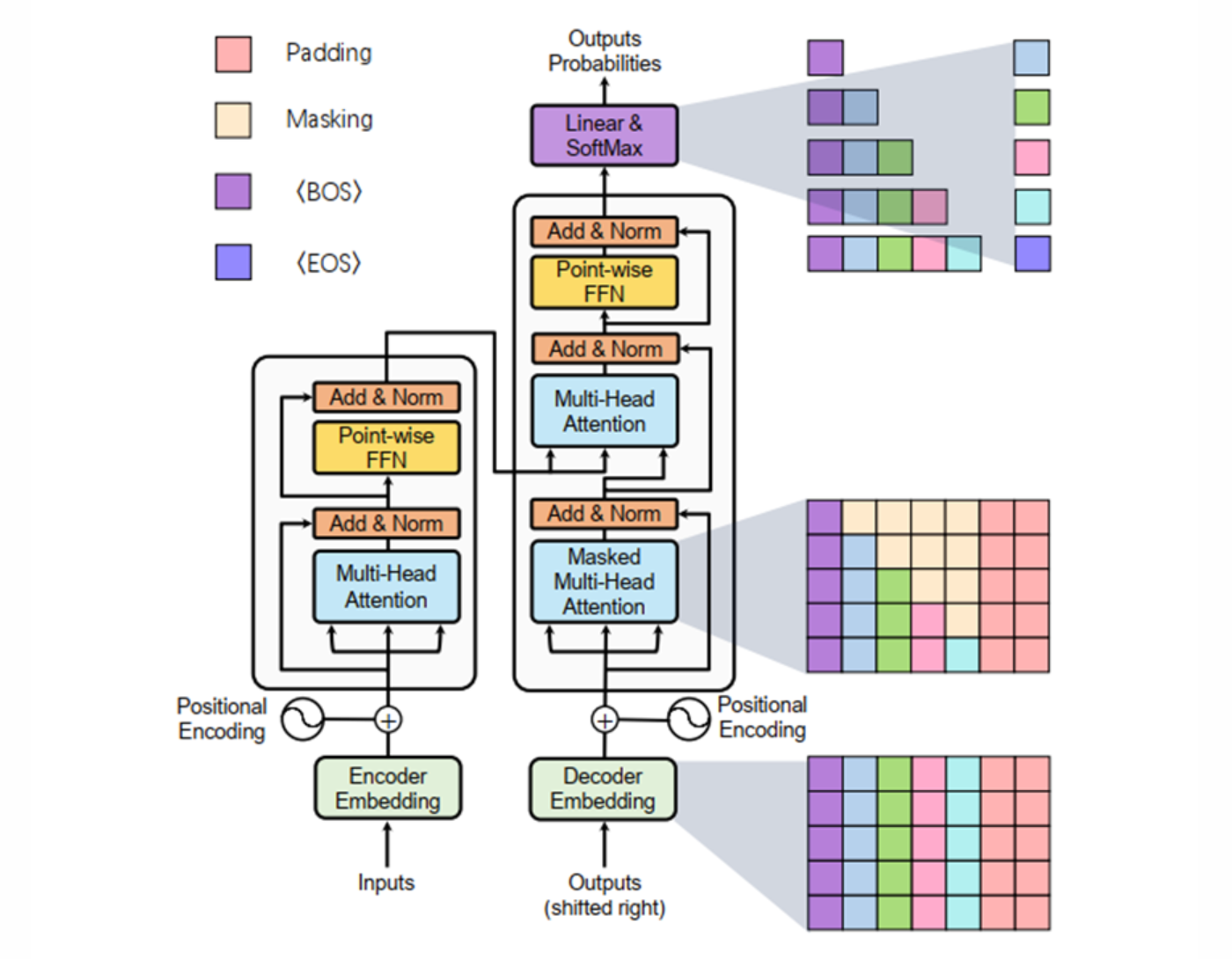
解码器可以接受任何之前生成的单词并将其传给掩蔽自注意力,类似于编码器来处理这些嵌入,生成中间嵌入并将其传递给另一个带有注意力的编码器,再将输出送入前馈神经网络,最终生成序列中的下一个单词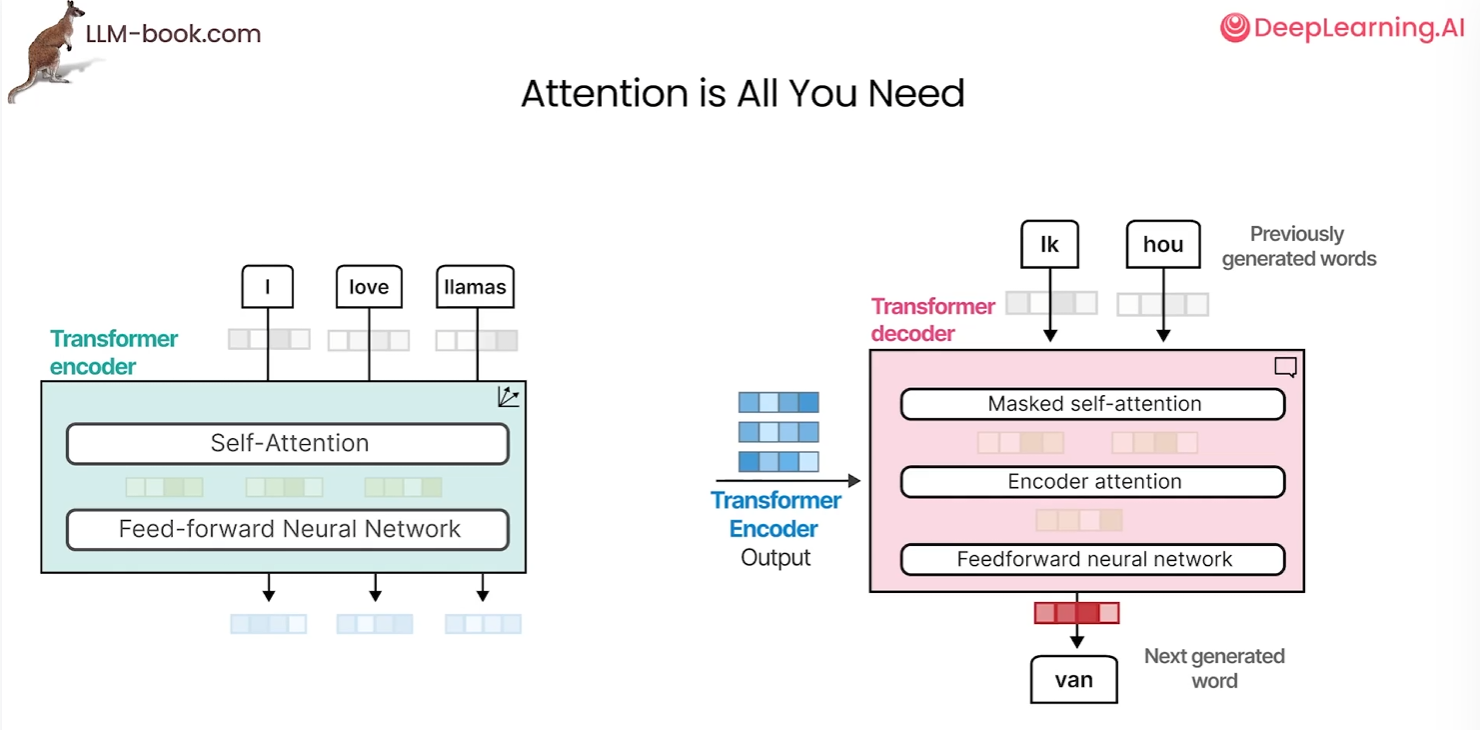
掩蔽自注意力和自注意力相比,它移除了所有上三角值,相当于掩蔽了未来的位置。因此,任何一个标记只能关注在它之前的标记,这有助于在生成输出时防止信息泄露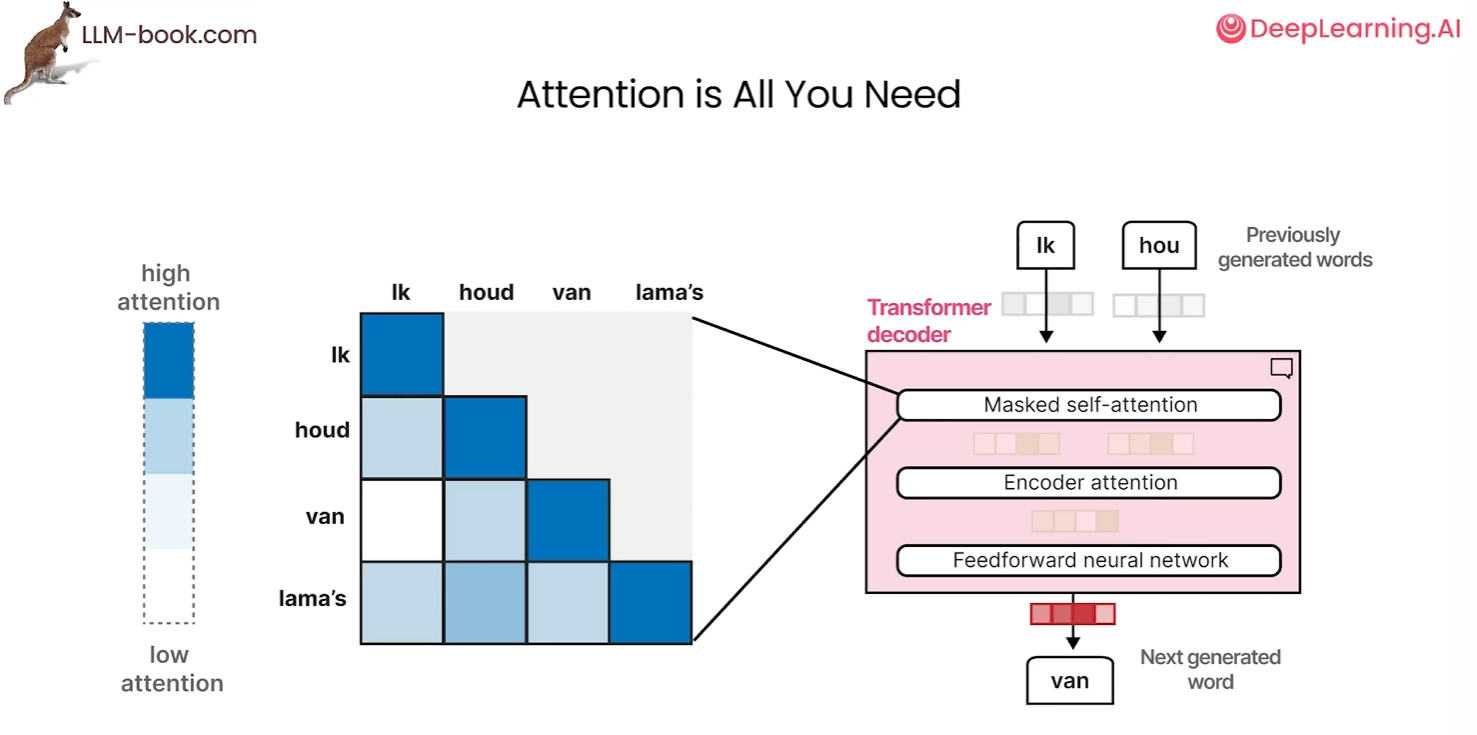
原始Transformer需处理完整编码器-解码器结构(如翻译任务),而文本分类仅需编码器提取语义特征,直接使用全架构会引入冗余计算。后续改进模型(如BERT)通过移除解码器、添加[CLS]标记和微调机制适配分类任务
Bert是一种仅编码的架构,他专注于表示语言并生成上下文化的词嵌入,这些编码块与前面的子注意力块相同。它的输入包含一个额外的分类标记,它被用作整个表示的输入。我们经常使用这个CLS token 作为微调的输入嵌入,在分类等特定任务上微调模型来训练一个bert模型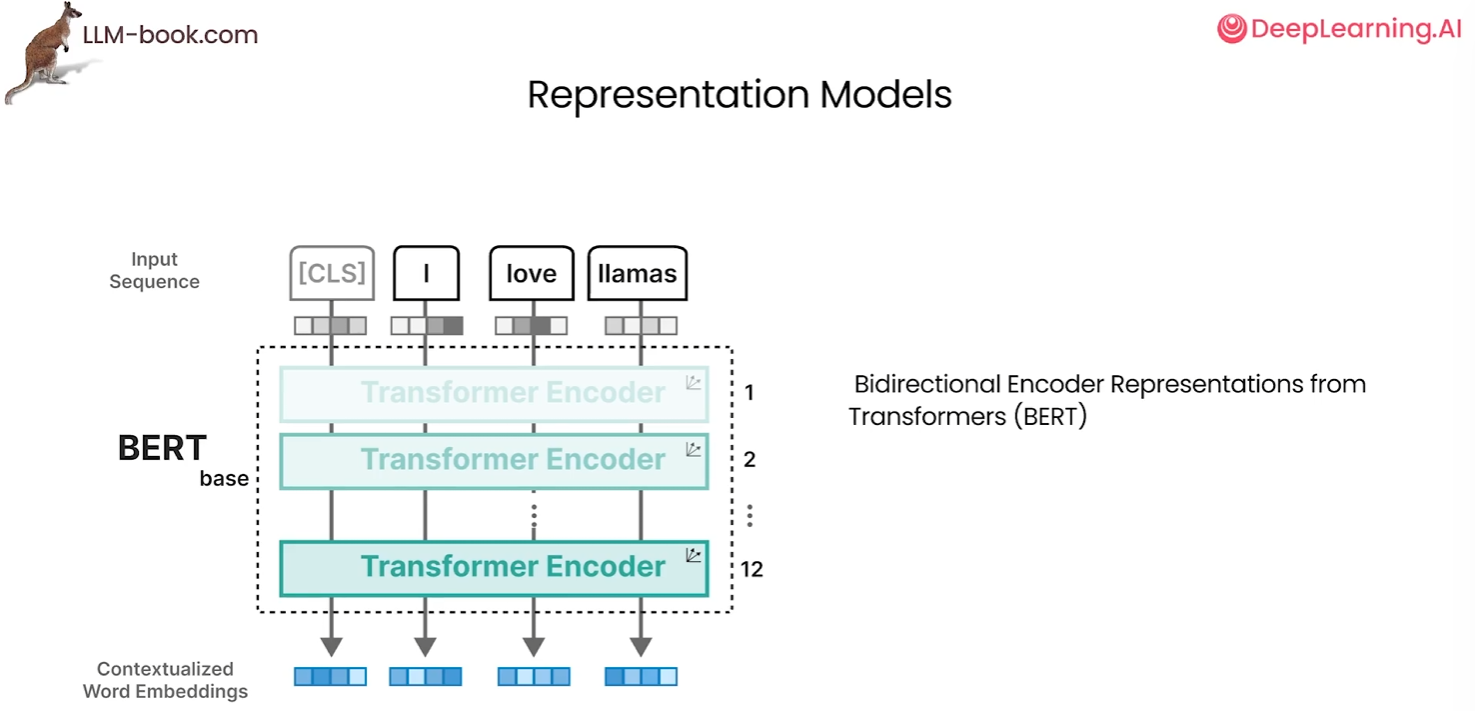
训练过程中,可以使用一种称为掩码语言模型的技术。掩码语言模型(MLM)通过随机遮盖输入文本中的部分词汇,迫使模型根据上下文预测被遮盖的词,以此学习双向语义关系。典型应用如BERT,遮盖15%的词并优化预测,使模型能同时捕捉左右语境,提升语义理解能力。
训练通常分为两步,首先在大量数据上应用掩码语言模型,这被称为预训练;然后对预训练模型进行微调,以适应多种下游任务
假设将另一个输入序列和随机初始化的嵌入只传递给解码器,进行不断堆叠,最终通过掩码技术和神经网络输出单词预测,这种实现方式就是我们熟知的GPT-1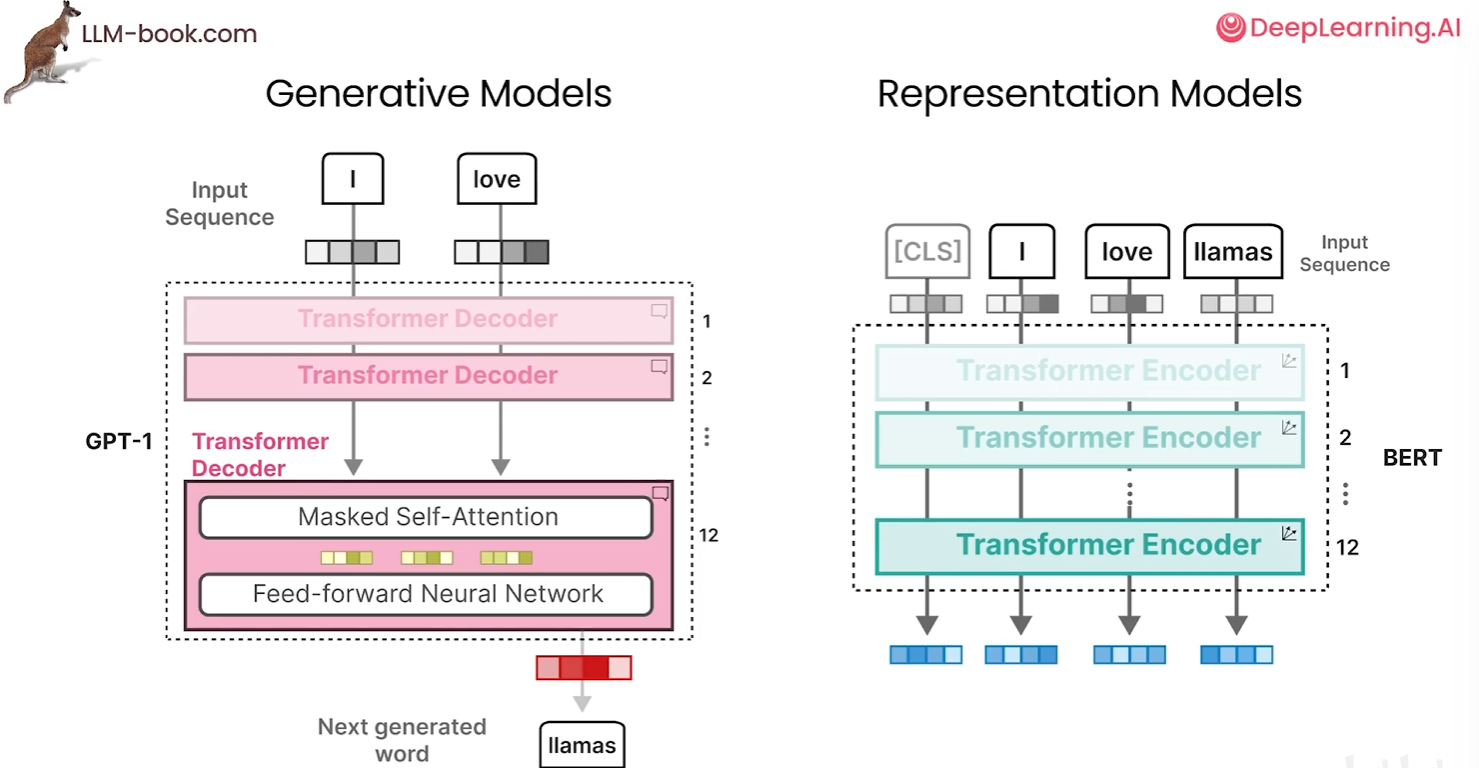
上述模型都有一个共同的特征--上下文长度。上下文长度指模型单次处理文本的最大范围(如GPT-4支持32k token)。长文本超出限制会被截断,影响连贯性;短则可能遗漏关键信息。模型通过注意力机制捕捉上下文关系,但过长会增加计算负担,需权衡效率与语义完整性。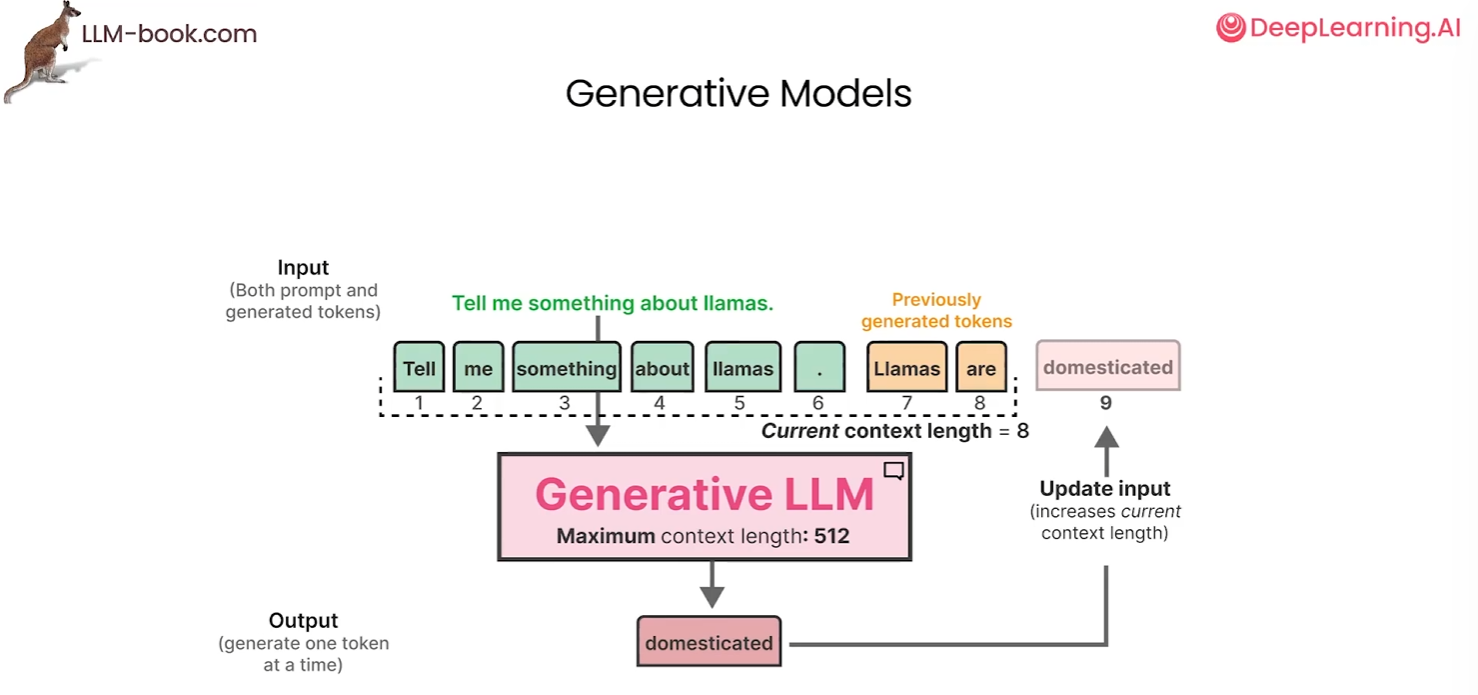
随着参数的增加,大模型的能力也随之提升,我们称2023年为生成式AI的一年
五、标记器(代码)
下面是通过使用hugging-face上的预训练分词器,来对文本进行分词的代码
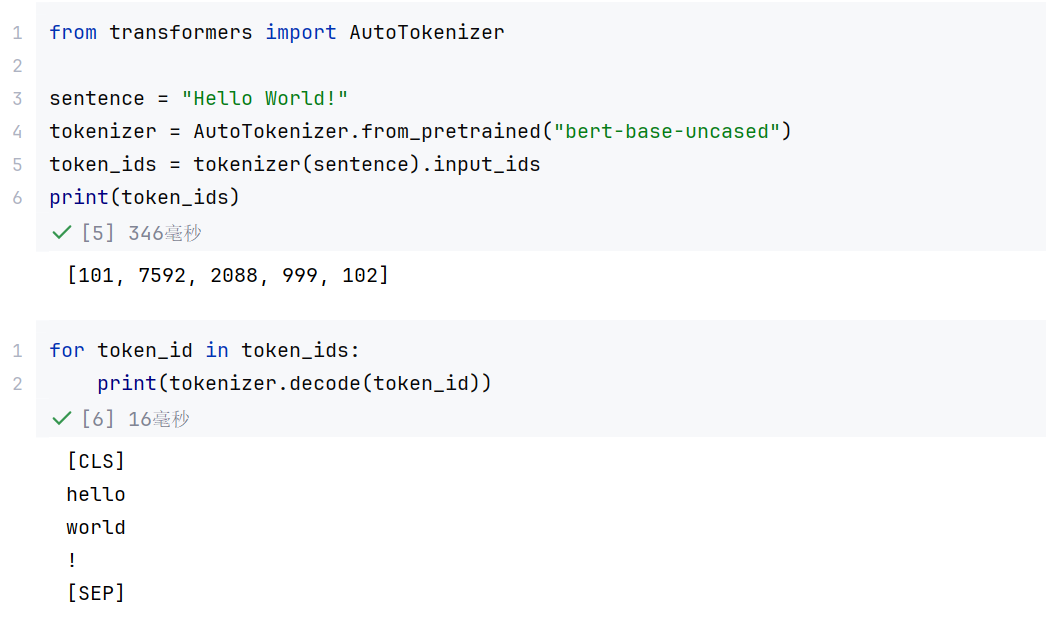
# 导入Hugging Face的自动分词器工具
from transformers import AutoTokenizer
# 待编码的原始文本
sentence = "Hello World!"
# 加载BERT基础版(不区分大小写)的分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# 将文本转换为包含特殊标记的token ID列表(例如[CLS], [SEP])
token_ids = tokenizer(sentence).input_ids
# 输出token ID列表:[101, 7592, 2088, 102]
print(token_ids)
# 逐个解码token ID(注意:单独解码可能产生子词符号,如##) for token_id in token_ids: print(tokenizer.decode(token_id)) # 例如:101→[CLS],7592→"hello",2088→"world",102→[SEP]
下面写了一个可视化分词的代码,用来对比不同分词器的分词效果
from transformers import AutoTokenizer
def show_tokens(text, model_name):
try:
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokens = tokenizer.tokenize(text)
encoded = tokenizer(text)
print(f"[Vocab Length] {tokenizer.vocab_size}")
print(f"[Tokenization] {' | '.join(f'[{tok}]' for tok in tokens)}")
print(f"[Token IDs] {encoded.input_ids}")
except OSError:
print(f"Error: Model '{model_name}' not found or network issue")
# 使用示例
print("bert 分词结果:")
show_tokens("Hello World! 😊", "bert-base-uncased")
print("gpt-2 分词结果:")
show_tokens("你好,世界!", "gpt2")
结果:
七、架构概述(语言模型头部)
在前面我们讨论了transformer如何进行模块的堆叠,在语言模型处理的最后阶段,会被转换为某种评分或标记概率的计算。所以语言模型头的结果是这种标记概率评分,表明在所有已知的token中每个token各自都多少概率会被输出,这些概率之和也就是百分之一百。
贪婪解码(如选择最高概率的token)生成确定性结果,但可能陷入局部最优;Top-p(核采样)从累积概率阈值内的候选集中随机抽取,平衡多样性与合理性,因此相同提示会产生不同输出。这是解码策略差异导致的生成结果波动。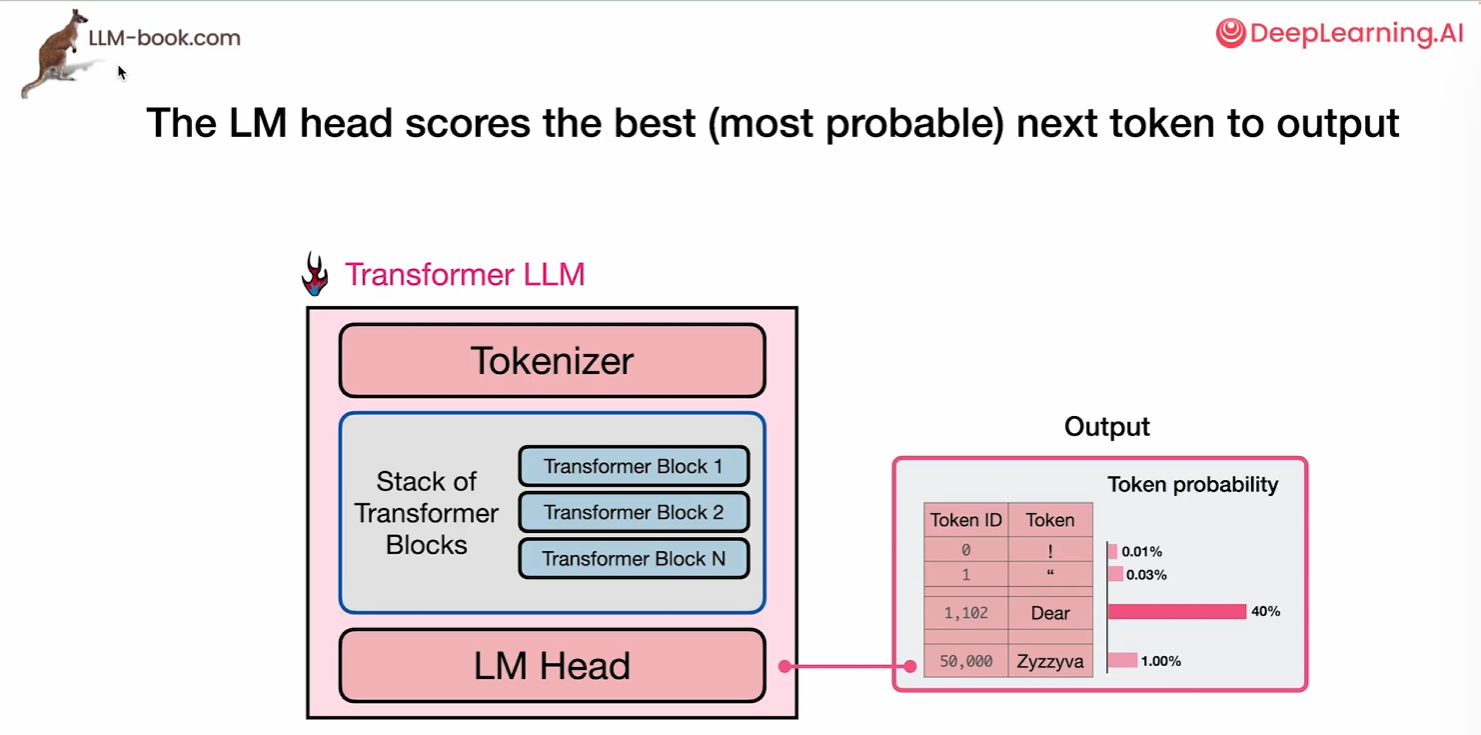
Transformer的并行计算能力(如同时处理所有位置的自注意力)显著提升了训练效率,尤其适合多GPU分布式计算。在自回归生成时(如GPT输出token),模型通过KV缓存存储历史token的键(Key)和值(Value),避免重复计算已生成部分的注意力矩阵,从而将复杂度从O(n²)降至O(n)。这种机制虽需逐token生成(类似循环),但因缓存复用而远快于RNN的序列依赖计算。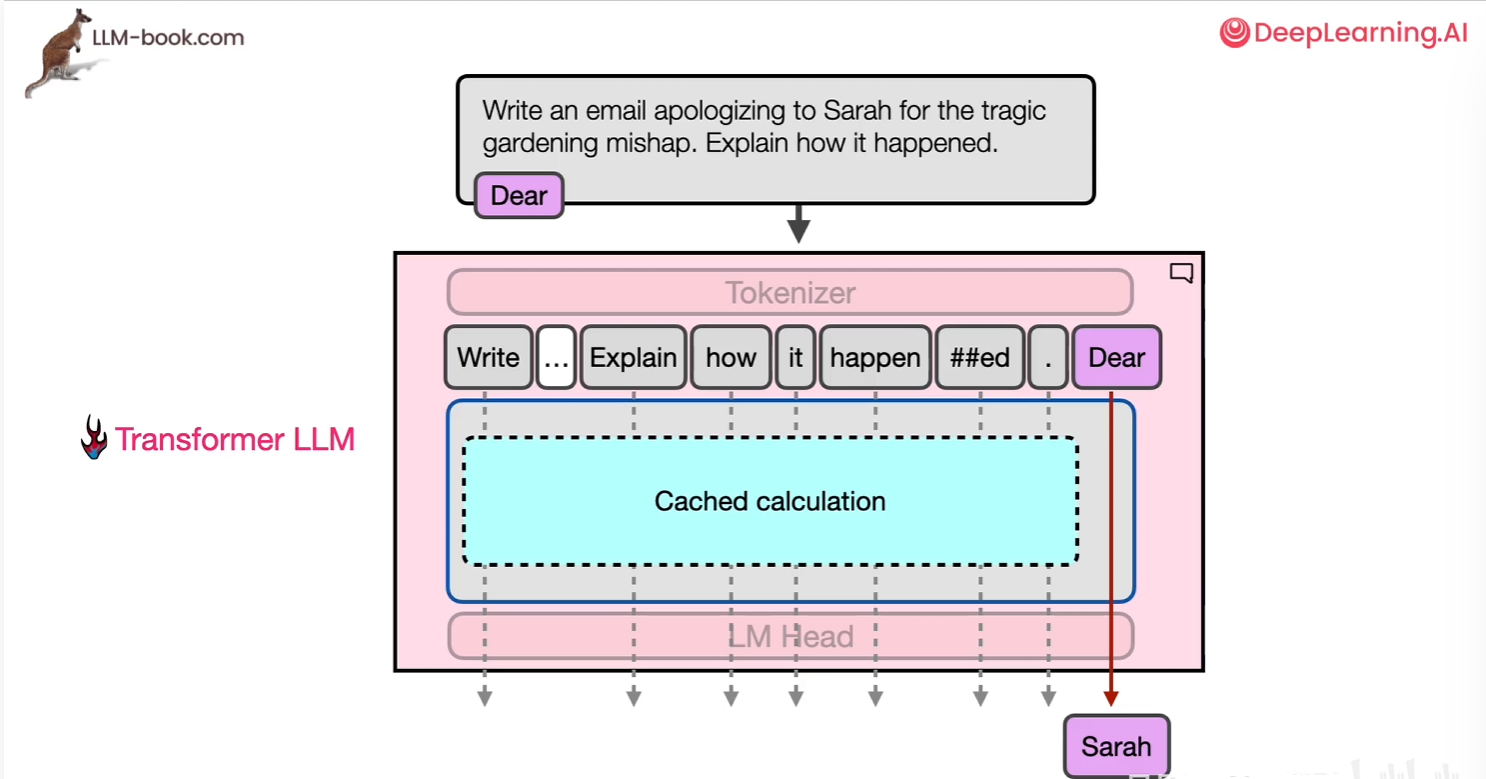
八、transformer模块
现在来考虑通过堆叠的transformer块流动的通道,Transformer模型中,数据流动始于分词器将输入文本拆分为标记(Token),随后通过向量嵌入将语言转化为数值表示。这些嵌入向量输入首个Transformer块进行处理,生成与输入同维度的输出向量,后续的每个Transformer块均以前一层的输出为输入,逐层并行计算,直至所有堆叠块处理完毕。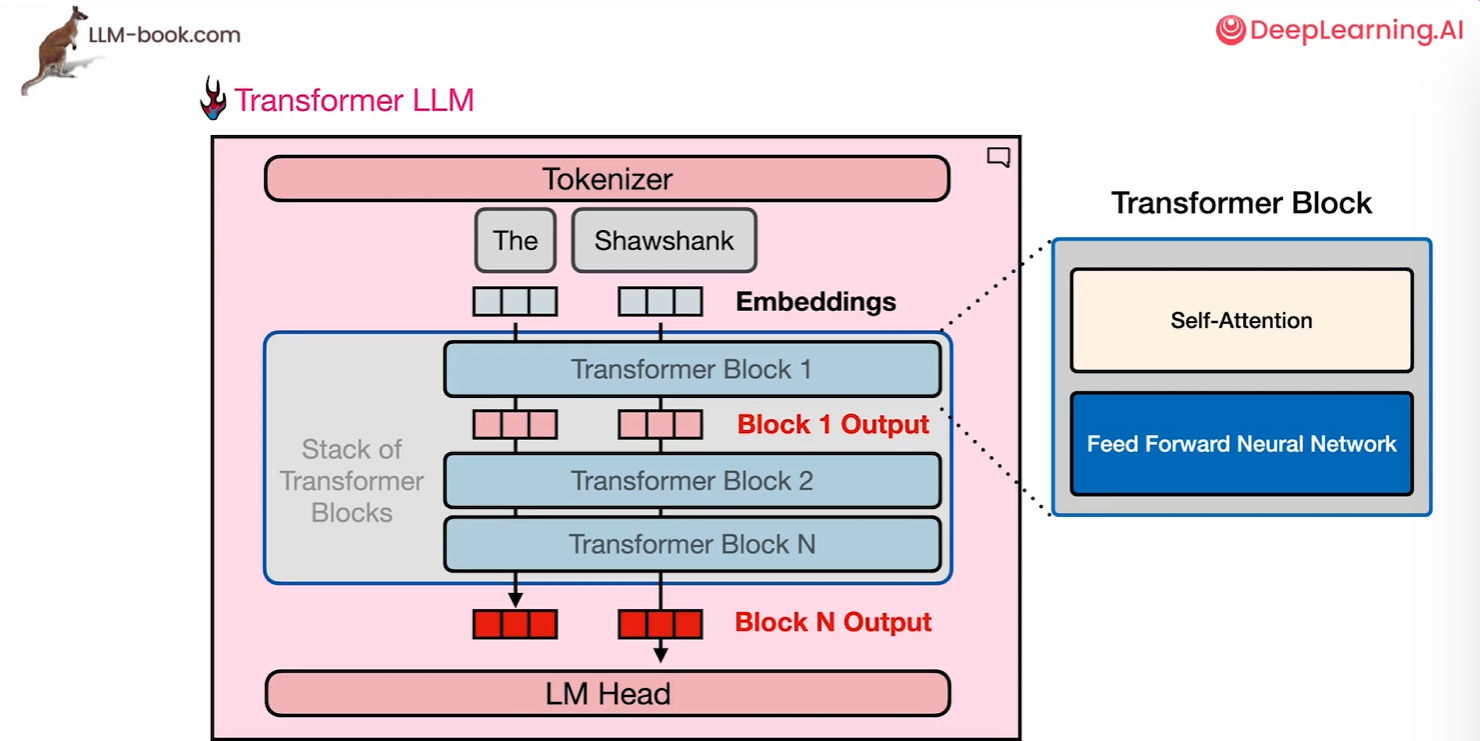
transformer块本身有两个主要部分,自注意力层和前馈神经网络层。其中前馈神经网络曾是对高层次的直觉,如果没有注意力而只有前馈神经网络,那么在输入shawshank(一个导演)后他大概率会输出“救赎”,因为救赎是他的一部电影,是在互联网上经过统计后最相关的词。在大多数情况下这就是前馈神经网络能够做到的事,所以我们把它看作是信息的存储和统计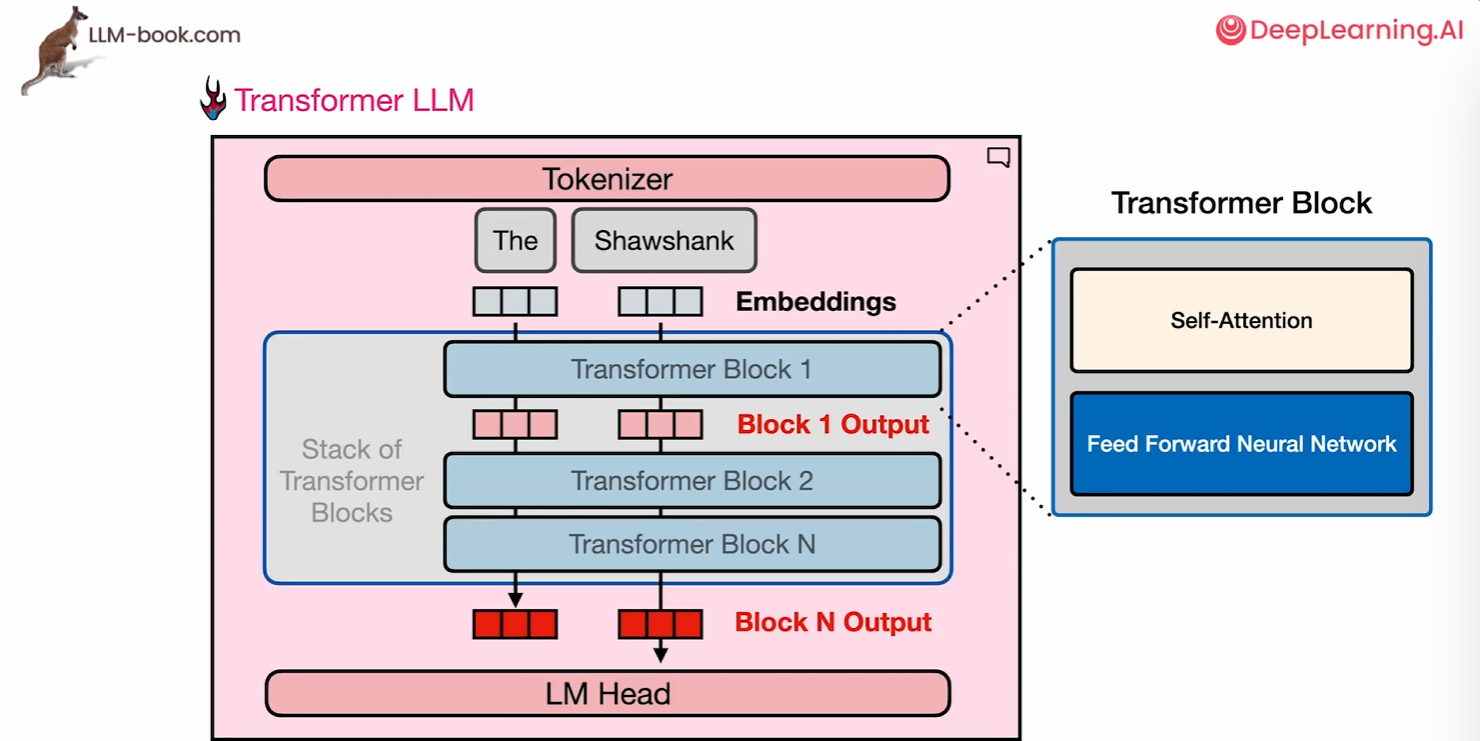
自注意力允许模型关注之前的标记并整合上下文在它对当前正在查看的token的解释中。举个例子,The dog chased the llama because it... 自注意力机制通过动态关联当前token(如“it”)与上下文中的相关标记(如“llama”或“dog”),将历史标记的语义信息整合到当前token的解释中。例如,处理句子“The dog chased the llama because it...”时,模型通过自注意力编码“llama”或“dog”的特征权重,确定“it”的具体指代对象,这种上下文依赖的语义解析能力称为共指消解(Coreference Resolution)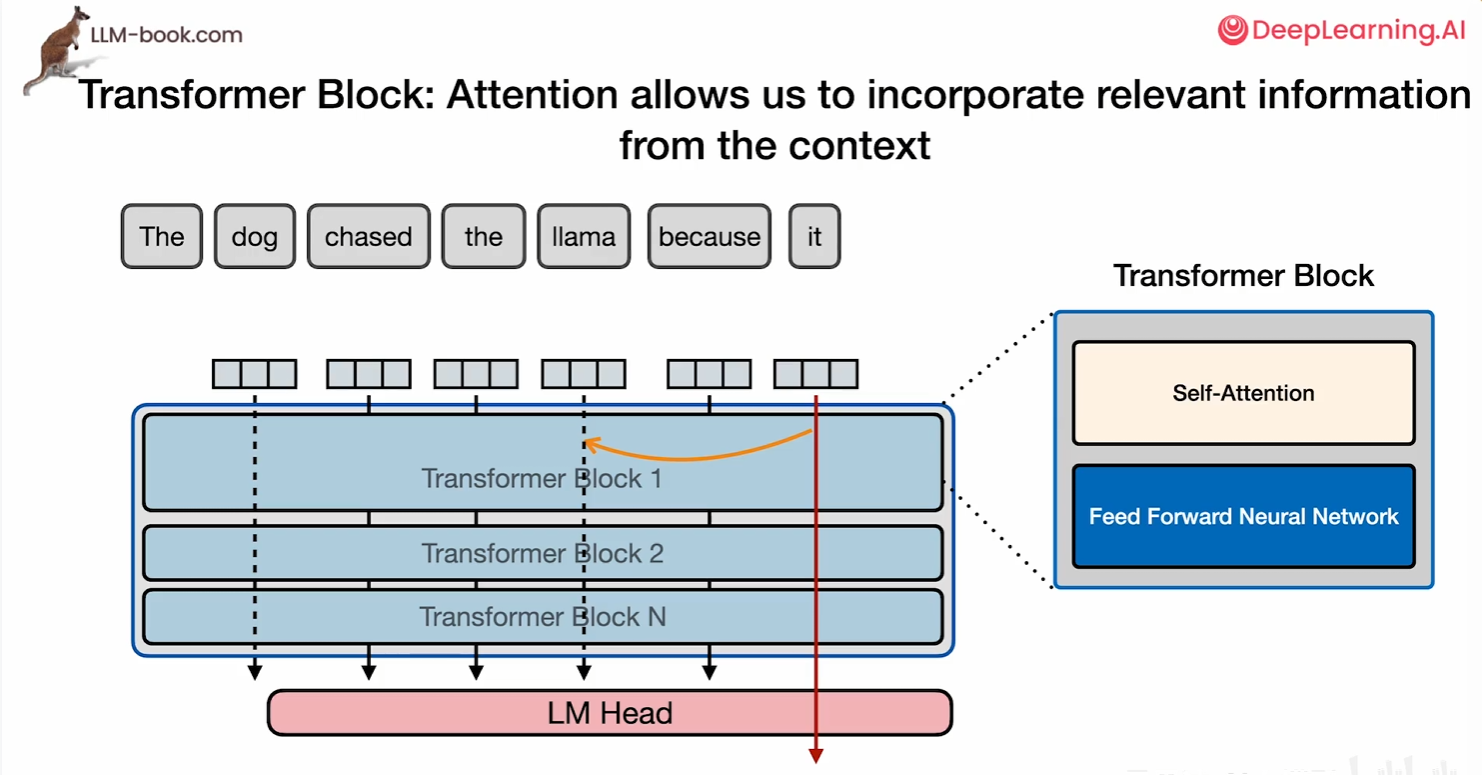
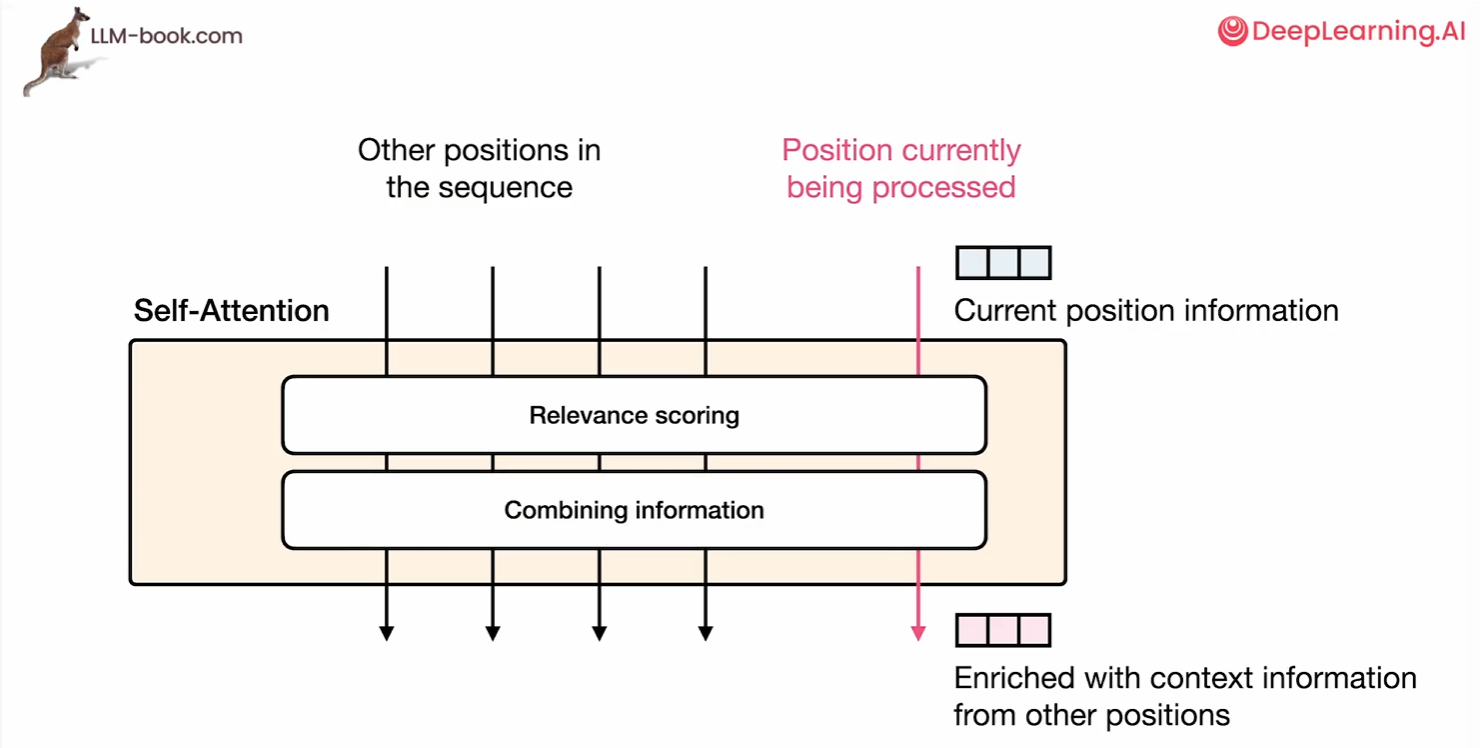
在高层次构件中,自注意力做了两件事。
-
第一件事是相关性评分。他为每个输入token分配一个评分,来表示和我们当前处理的标记的相关性。例如对当前处理的token(如“it”),计算其与序列中所有其他token(如“dog”“llama”)的关联权重,量化语义依赖强度。
-
第二件事是在相关性评分后,将相关的信息融合到表示中。基于评分权重,动态聚合相关token的语义特征(如将“llama”的特征高权重注入“it”的表示),使当前token的编码包含上下文解析能力(如明确指代对象)
九、自注意力机制
这里,吴恩达课程中关于QKV矩阵运算的讲解的比较粗造,我们参考 图解转换器 – Jay Alammar – 一次可视化一个概念的机器学习 这个网站来进行学习
计算自注意力的第一步是从编码器的每个输入向量(在本例中为每个单词的嵌入)创建三个向量。因此,对于每个单词,我们创建一个 Query 向量、一个 Key 向量和一个 Value 向量。这些向量是通过将嵌入向量乘以我们在训练过程中训练的三个矩阵来创建的
注意,这些新向量的维度小于嵌入向量。它们的维度为 64,而嵌入向量和编码器输入/输出向量的维度为 512。它们不必更小,这是一种架构选择,可以使多头注意力的计算(大部分)保持不变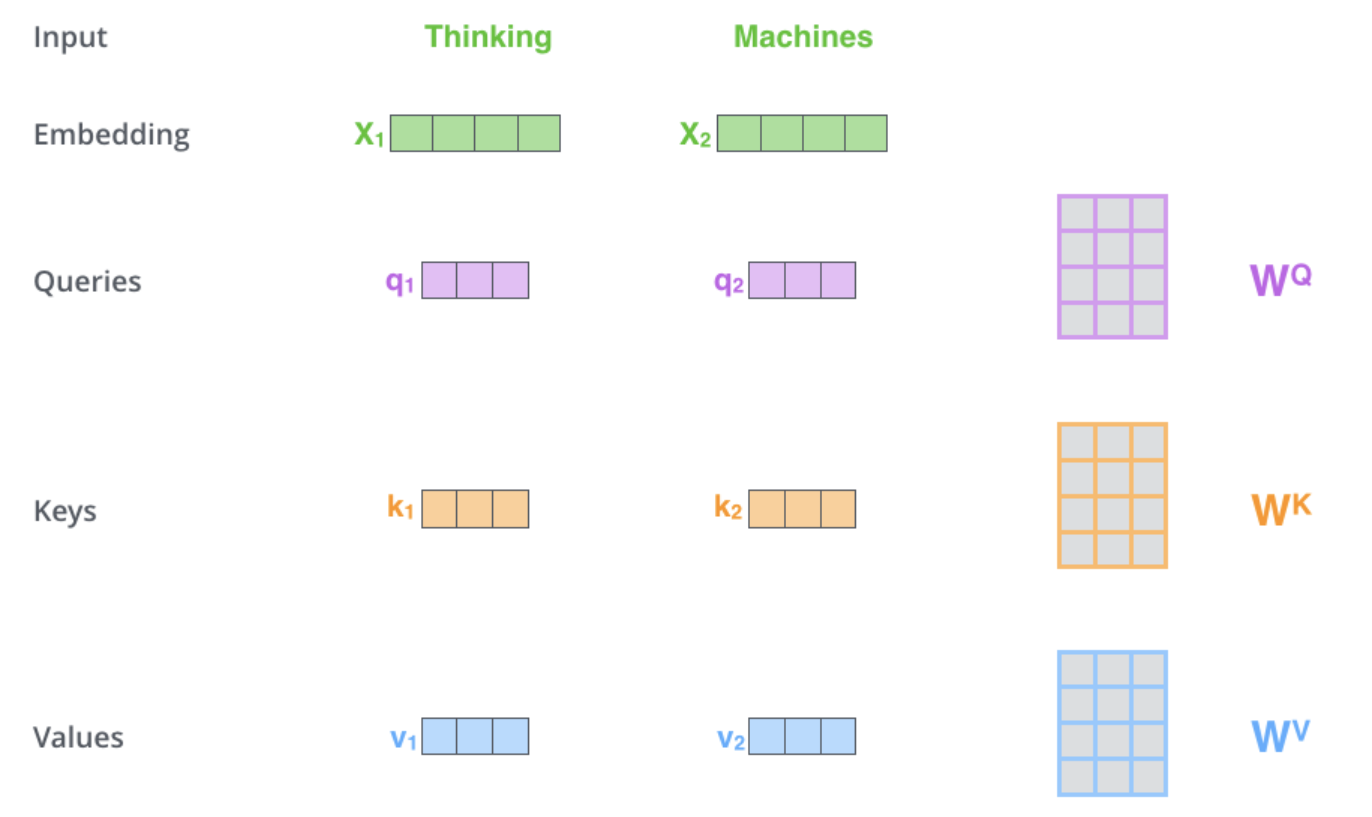
Q/K/V 的定义和作用
-
Query(Q):表示当前需要关注的词(或位置)的“提问”,用于与其他位置的键(Key)进行匹配。
-
Key(K):表示序列中每个词的“索引”,用于与 Query 计算相关性。
-
Value(V):表示序列中每个词的“实际内容”,最终根据注意力权重加权求和得到输出。
类比理解: 想象在搜索引擎中:
-
Query 是你的搜索关键词。
-
Key 是数据库中的文档标题或关键词。
-
Value 是文档的实际内容。 搜索引擎会用 Query 和 Key 计算匹配度,然后返回对应的 Value
计算自注意力的第二步是计算分数。假设我们正在计算此示例中第一个单词 “Thinking” 的自我关注。我们需要根据这个单词对输入句子的每个单词进行评分。分数决定了我们在某个位置对单词进行编码时,将多少注意力放在输入句子的其他部分上
分数的计算方法是将查询向量的点积与我们正在评分的相应单词的关键向量相提并论。因此,如果我们处理位置 #1 中的单词的自我注意,第一个分数将是 q1 和 k1 的点积。第二个分数将是 q1 和 k2 的点积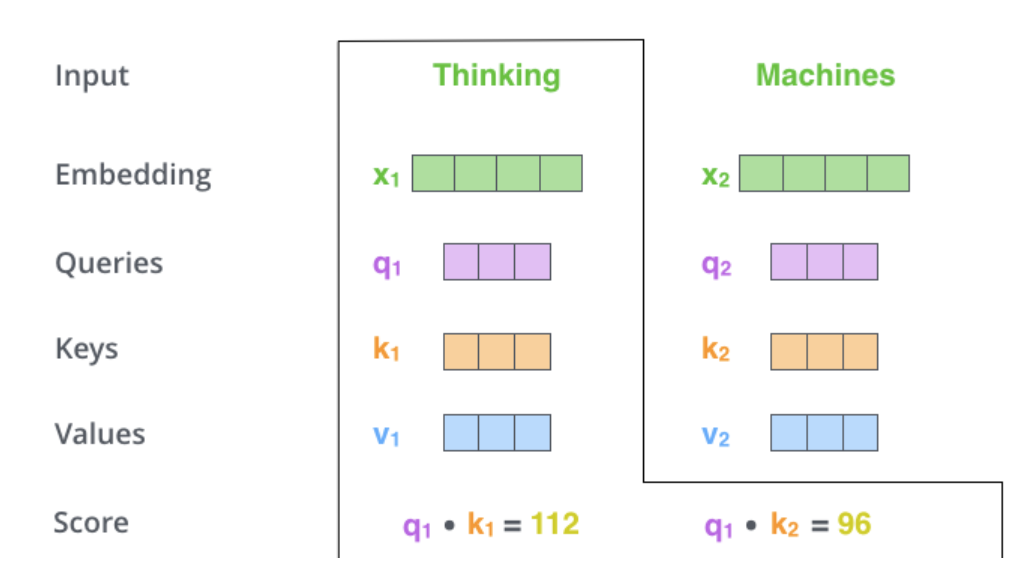
第三步和第四步是将分数除以 8(论文中使用的关键向量维度64的平方根。这会导致更稳定的梯度。这里可能还有其他可能的值,但这是默认值),然后通过 softmax作传递结果。Softmax 对分数进行标准化,使其全部为正数,总和为 1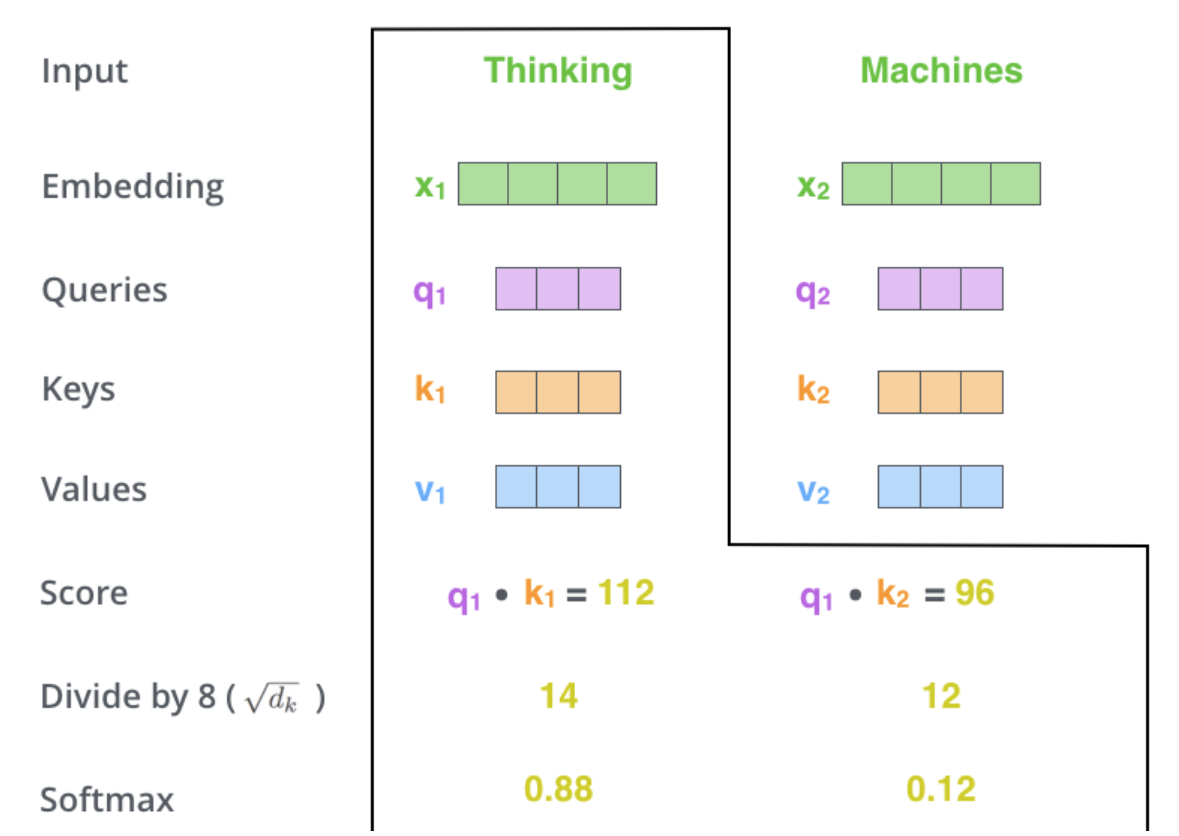
第五步是将每个值向量乘以 softmax 分数(准备对它们求和)。这里的直觉是保持我们想要关注的单词的值完整,并淹没不相关的单词(例如,将它们乘以 0.001 等小数字)
第六步是将加权值向量相加。这将在此位置(对于第一个单词)产生自注意层的输出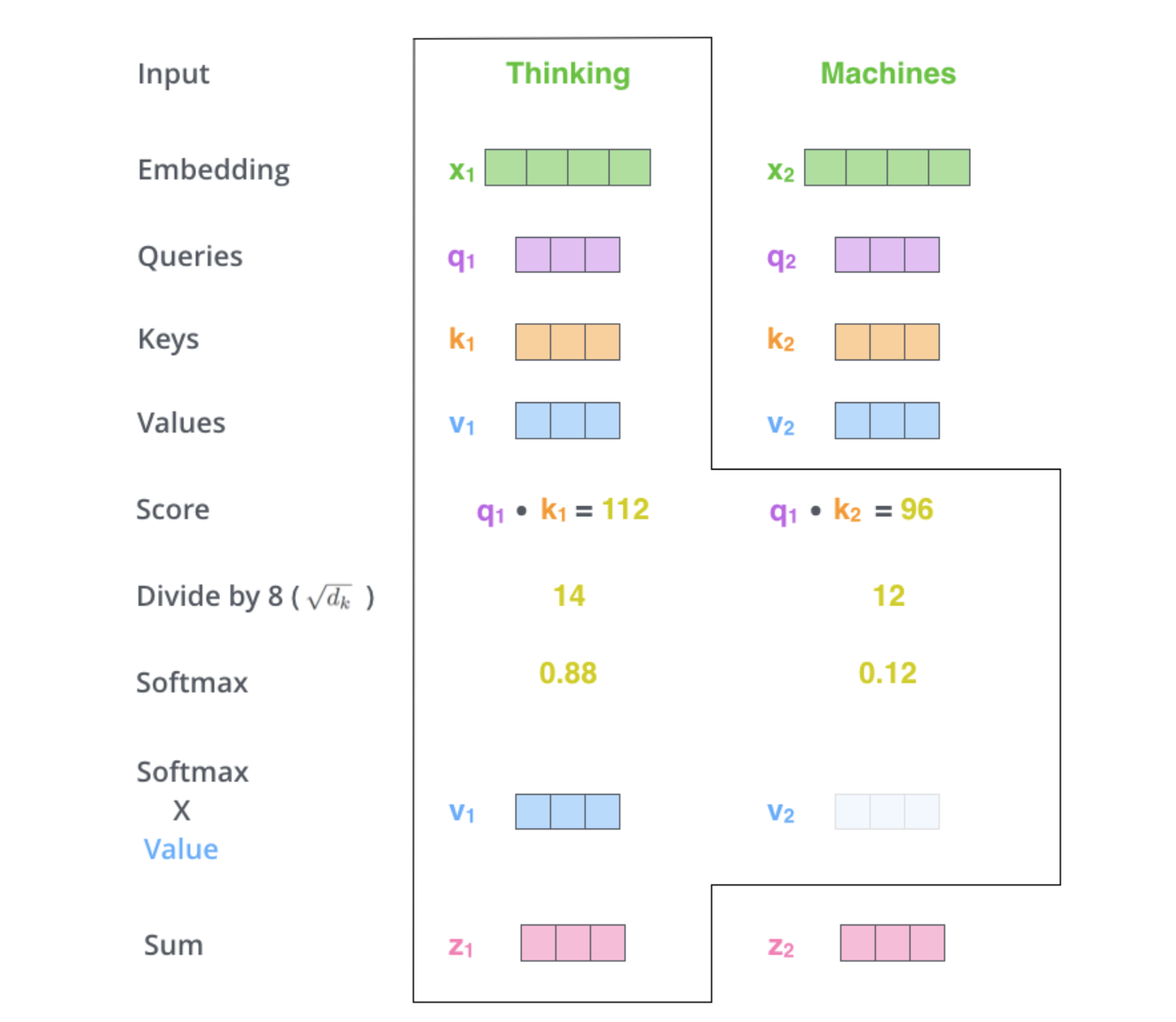
介绍了分数的计算办法,现在来计算QKV三个矩阵是怎么来的
如何计算 Query、Key 和 Value 矩阵?我们通过将嵌入向量打包到矩阵 X 中,并将其乘以我们训练的权重矩阵(WQ、WK、WV)来实现这一点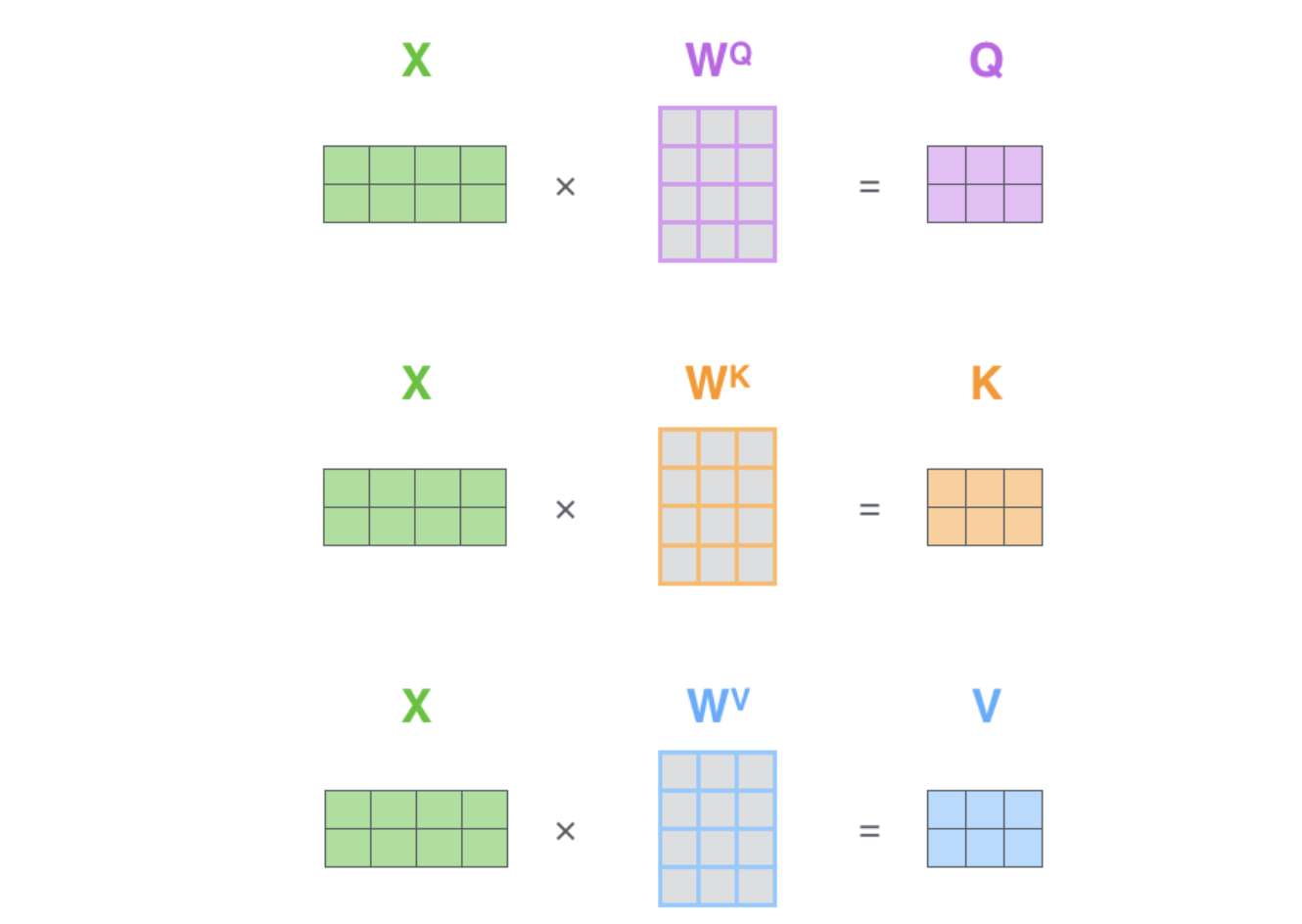
最后,由于我们正在处理矩阵,我们可以将步骤 2 到 6 压缩在一个公式中,以计算自我注意层的输出

在论文《Attention is all you need》中,它添加一种称为“多头”注意力的机制进一步完善了自注意层。这可以通过两种方式提高注意力层的性能:
-
它扩展了模型专注于不同位置的能力。
核心思想: 允许模型在不同的语义或位置组合上分配注意力权重,避免单一注意力头只能捕捉一种固定模式
具体机制:
-
多头并行计算:将 Q/K/V 矩阵分割为多个独立的子空间(头),每个头学习不同的注意力模式。
-
多样化关注:
例如,在处理句子时:
-
一个头可能关注局部语法关系(如形容词修饰名词);
-
另一个头可能捕捉长距离依赖(如主句和从句的关系);
-
第三个头可能关注特定词性(如动词与宾语的搭配)
-
-
它为注意力层提供了多个 “表示子空间”。
核心思想: 每个头的 Q/K/V 通过独立的线性变换映射到不同的子空间,增强模型的表征能力。
具体机制:
-
子空间投影: 每个头使用不同的权重矩阵 WiQ,WiK,WiV,将输入向量投影到不同的低维空间。 例如,若输入维度为 dmodel=512,分割为 h=8 个头,则每个头的维度为 dk=dv=64。每个头:Qi=XWiQ(∈Rn×64)
-
异构表示: 不同子空间中的 Q/K/V 会编码输入的不同特征(如语义、语法、位置等),形成互补的表示。
示例:
-
头1 的子空间:编码词义的相似性(如
cat和dog作为动物); -
头2 的子空间:编码句法结构(如主谓一致);
-
头3 的子空间:编码位置关系(如相邻词或远程词)。
优势:
-
信息解耦:不同子空间学习输入的不同侧面,避免特征混淆。
-
灵活组合:最终拼接所有头的输出,并通过 WO融合,实现多层次特征的交互
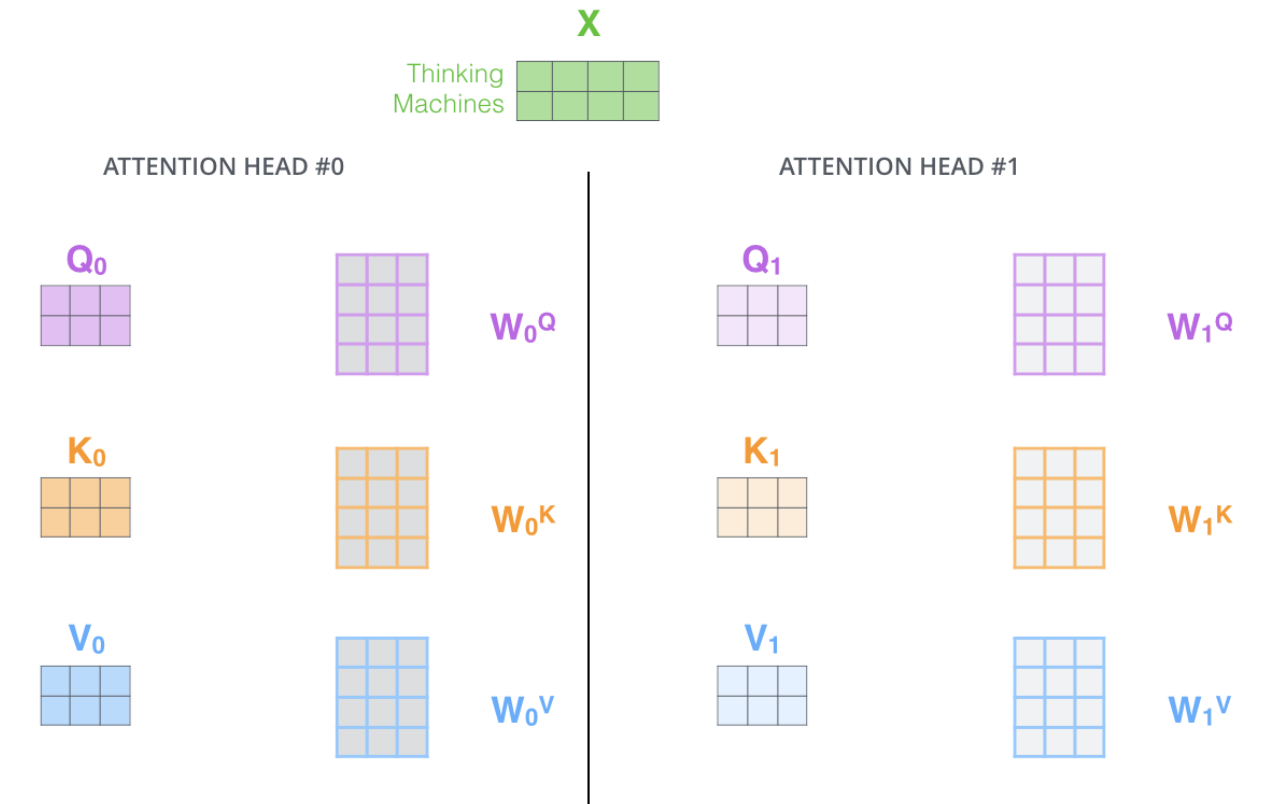 如果我们进行与上面概述的相同的自注意计算,只需 8 次不同的权重矩阵,我们最终会得到 8 个不同的 Z 矩阵
如果我们进行与上面概述的相同的自注意计算,只需 8 次不同的权重矩阵,我们最终会得到 8 个不同的 Z 矩阵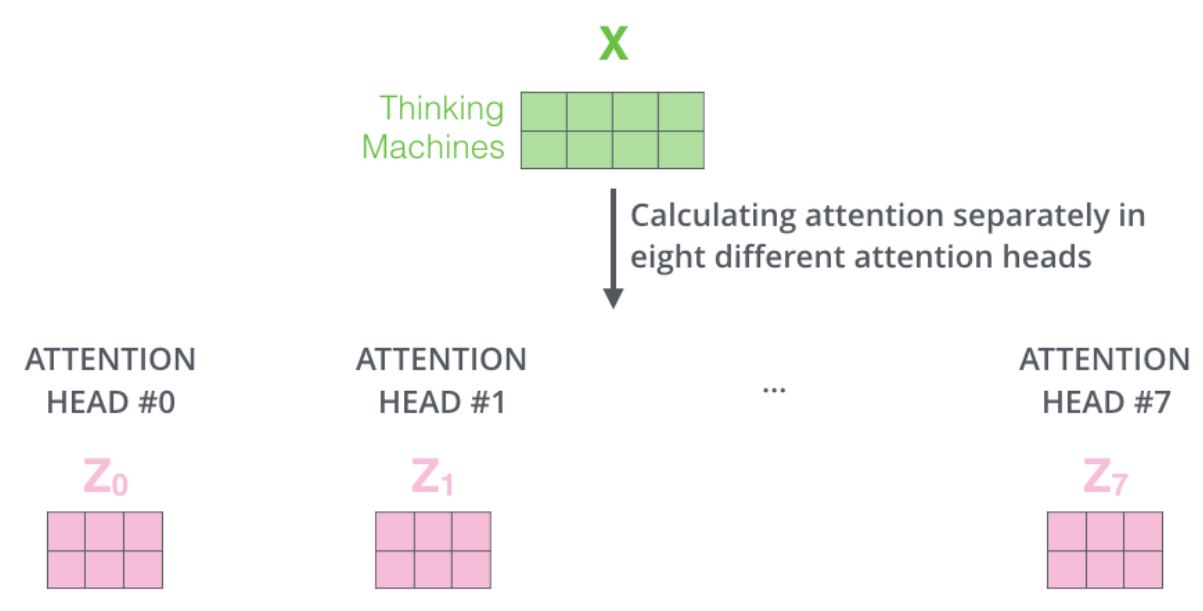
前馈层不需要八个矩阵 - 它需要一个矩阵(每个单词的向量)。所以我们需要一种方法将这 8 个矩阵浓缩成一个矩阵,这里我们采用连接矩阵,然后将它们乘以一个额外的权重矩阵 WO
总结所有计算过程如下:
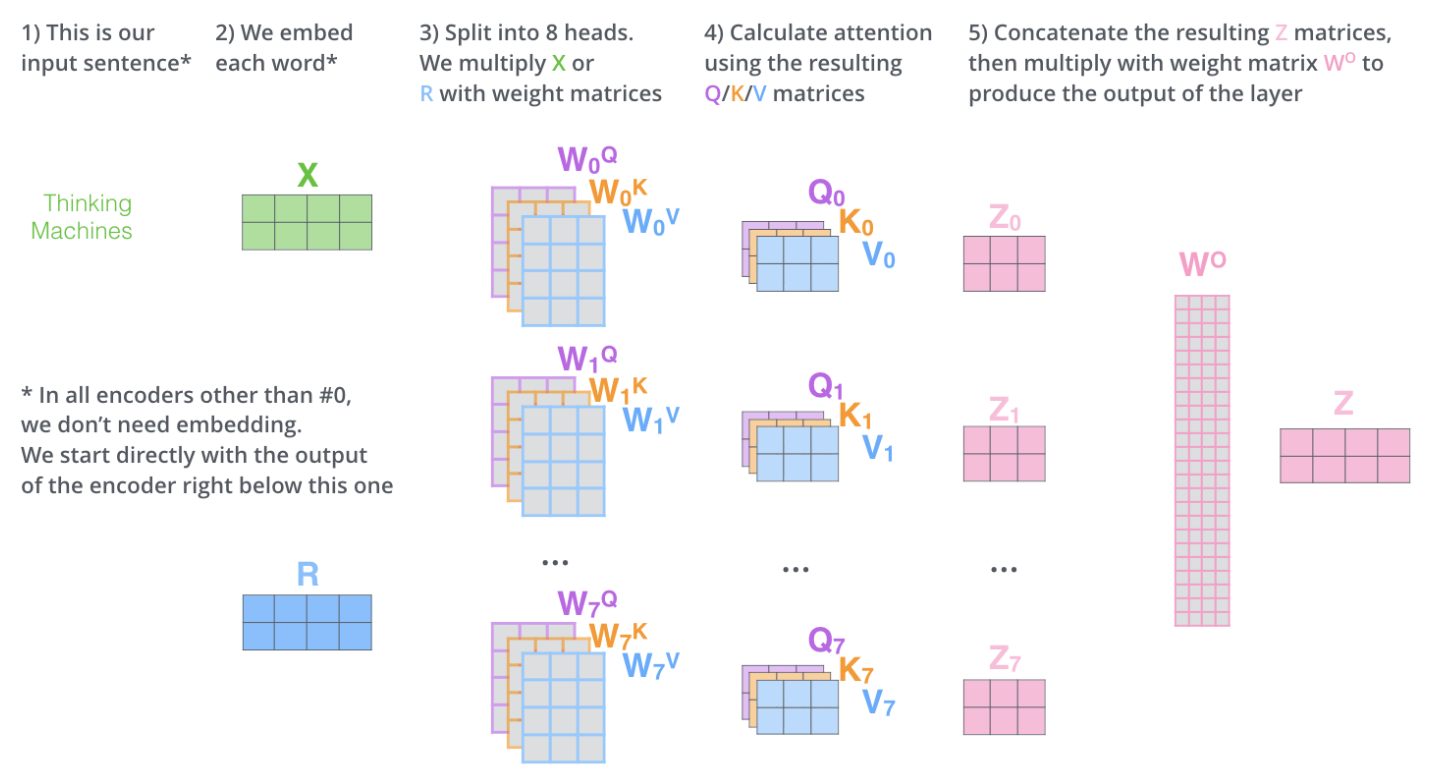

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)