RagFlow文档切块提升
最主要的分块方式就是通用分块、父子块分块、表格分块和Regulation分块,对于扫描件则要复杂的多,使用VL对文档内容转换成Markdown形式。
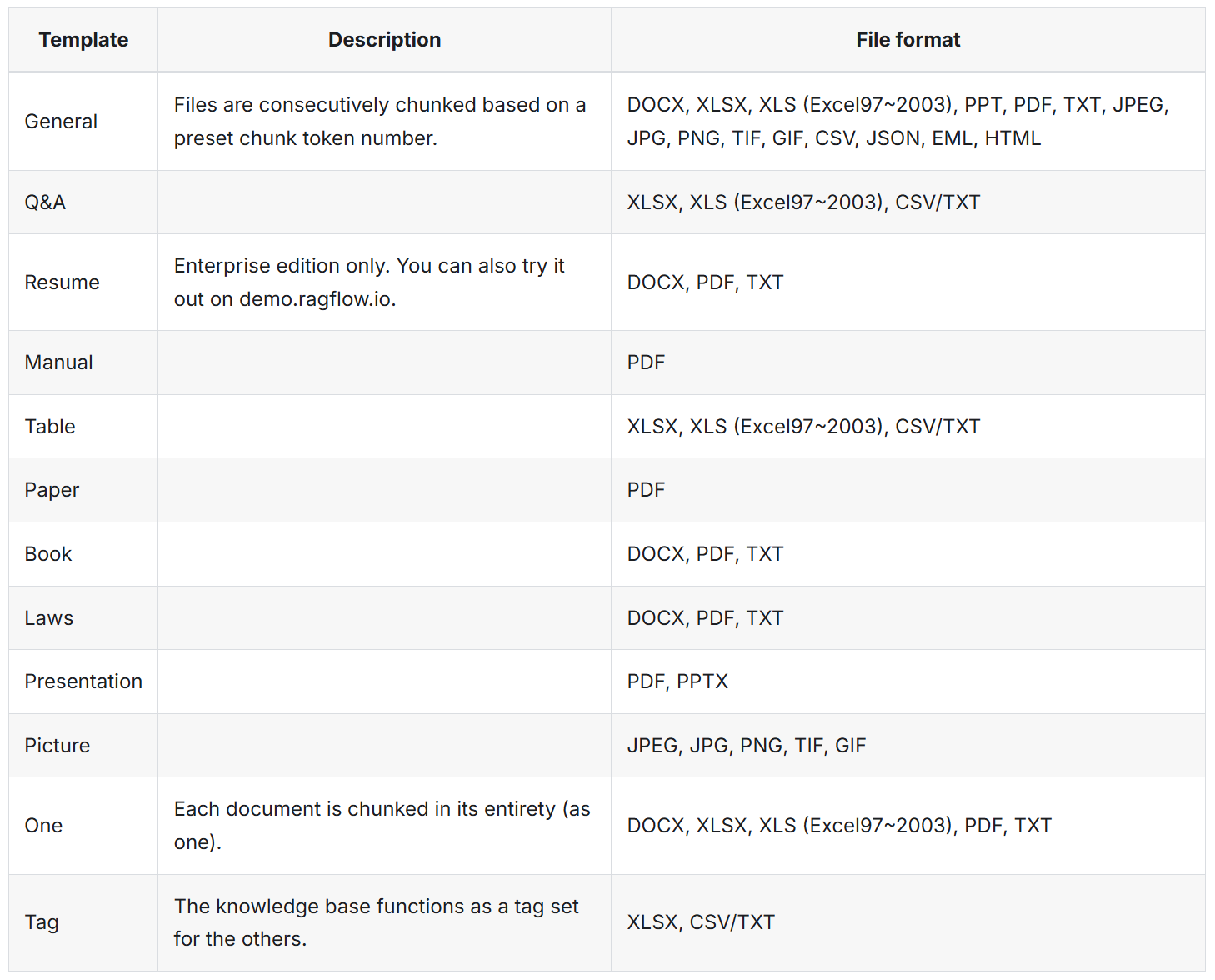
1.RagFlow切块介绍
2.复现优化
2.1 General 通用分块

def parser_text(self, txt, blockSize=512, overlapSize=0, delimiter="\n!?;。;!?"):
'''
文本分割
'''
sentences = self.split_text_by_period_qh(txt, delimiter, blockSize=blockSize)
result = []
lineNow = ''
for line in sentences:
if len(line) > blockSize:
if lineNow:
result.append(lineNow)
result.append(line)
lineNow = ''
elif len(line) + len(lineNow) > blockSize:
if lineNow:
result.append(lineNow)
lineNow = line
else:
lineNow += line
if lineNow:
result.append(lineNow)
# 处理重叠部分
overlapSize_ = int(overlapSize / 2)
if overlapSize_ != 0:
blockLen = len(result)
blocks = []
for i in range(len(result)):
block = result[i]
if i == 0 and blockLen > 1:
block = result[i] + result[i + 1][:overlapSize_]
elif i == blockLen - 1 and blockLen > 1:
block = result[i - 1][-overlapSize_:] + result[i]
elif blockLen > 2:
block = result[i - 1][-overlapSize_:] + result[i] + result[i + 1][:overlapSize_]
blocks.append(block)
result = blocks
result = [line.strip('\n \t ') for line in result]
return result
升级点:相对于RagFlow,添加了overlapSize块重叠长度入参,可以尽量的保留上下文。
2.2 通用父子分块
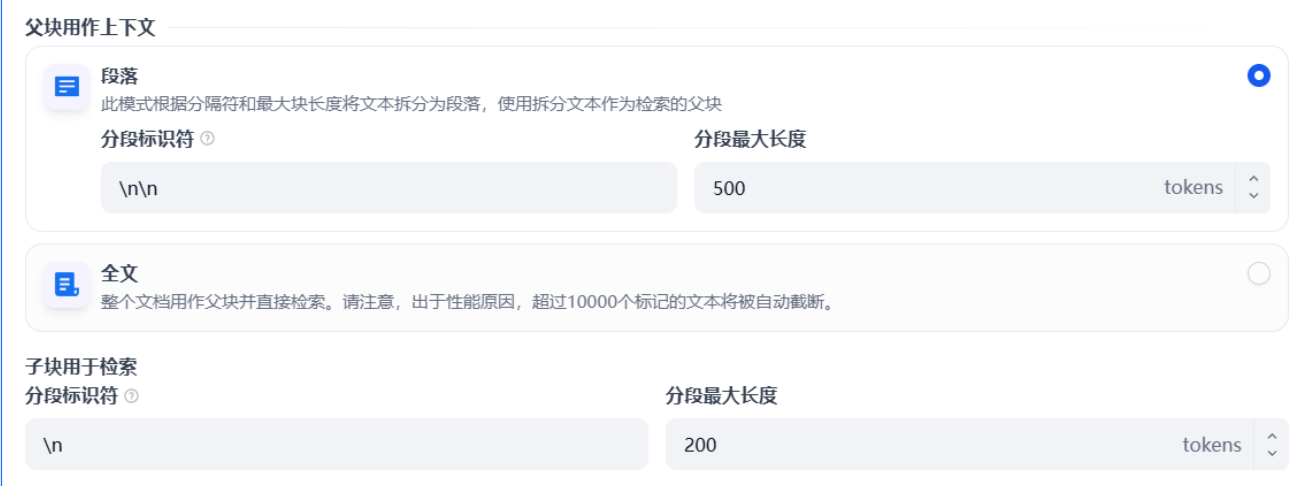
def ParentChildBlock(self, text, patternParent="\n!?;。;!?", blockSizeParent=myconfig.blockSize, patternChild="\n!?;。;!?",
blockSizeChild=int(myconfig.blockSize/5)):
# 父子块分割
result = []
text = self.text_format(text)
parentSentences = self.parser_text(text, blockSize=blockSizeParent, overlapSize=0, delimiter=patternParent)
for index, sentence in enumerate(parentSentences, start=1):
childSentences = self.parser_text(sentence, blockSize=blockSizeChild, overlapSize=0, delimiter=patternChild)
dic = {
'block_id': index,
'content': sentence,
'child': []
}
for child_id, child_content in enumerate(childSentences, start=1):
dic['child'].append({'child_id': child_id, 'child_content': child_content})
result.append(dic)
return result
升级点:RagFlow中没有这种方法。
2.3 QA问答对
(1)excel格式,必须包含两列,question和answer,一个QA一条;
(2)csv格式,必须包含两列,question和answer,一个QA一条;
(3)json格式,必须包含两个key值,question和answer,一个QA一条;
def excelQA(self, path):
excel_file = pd.ExcelFile(path)
sheet_names = excel_file.sheet_names
result = []
for sheet_name in sheet_names:
pdData = excel_file.parse(sheet_name, dtype=str, header=0)
pdData.fillna('', inplace=True)
datas = json.loads(pdData.to_json(orient='records'))
result.extend(datas)
data = self.findQA(result)
return data
def findQA(self, jaonData):
data1 = []
for item in jaonData:
try:
dic = {}
for k, v in item.items():
k_ = str(k).lower().replace(' ', '').replace('\t', '').replace('\n', '')
dic[k_] = v
data1.append(dic)
except:
print('QA 文件数据不规范!')
result = []
for item in data1:
q = self.keyQ(item.keys())
a = self.keyA(item.keys())
if q and a:
# result.append([item[q], item[a]])
result.append(json.dumps({'问题': str(item[q]).strip(' \n\t'), '答案': str(item[a]).strip(' \n\t')},
ensure_ascii=False))
return result
2.4 Table表格数据
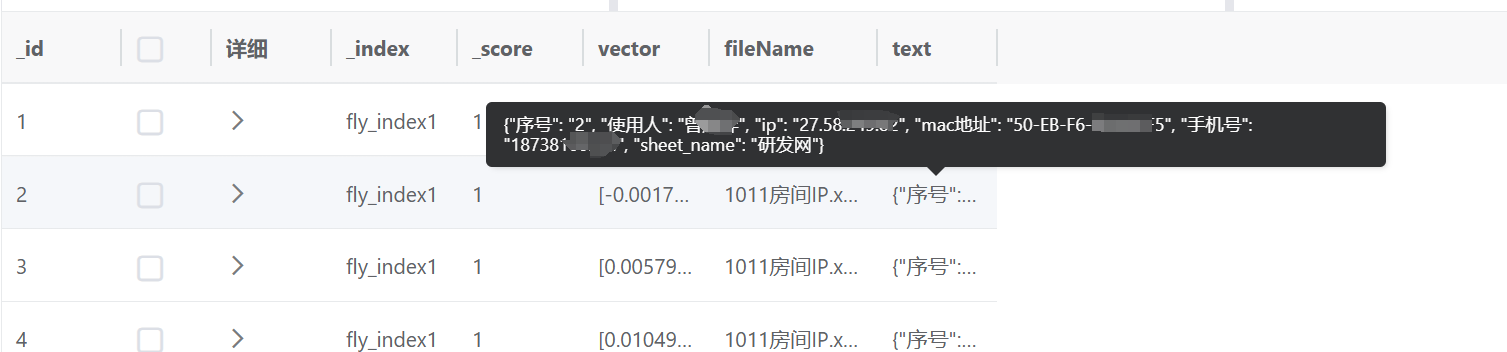
升级点:一行一条,加上sheet_name,每一块都是一个json格式的数据,并且进行了长度限制,超出长度则会保存多条。
def ExcleSplit(self, path):
'''
一块一行数据
'''
excel_file = pd.ExcelFile(path)
sheet_names = excel_file.sheet_names
result = []
for sheet_name in sheet_names:
pdData = excel_file.parse(sheet_name, dtype=str, header=0)
pdData.fillna('', inplace=True)
pdData['sheet_name'] = sheet_name
data = json.loads(pdData.to_json(orient='records'))
result.extend(data)
return result
def ExcleSplitSingle(self, path, blockSize=myconfig.excelSize):
'''
一块最多一行数据,当一行数据字数超出限制则也需要分成多块
'''
excel_file = pd.ExcelFile(path)
sheet_names = excel_file.sheet_names
result = []
for sheet_name in sheet_names:
pdData = excel_file.parse(sheet_name, dtype=str, header=0)
pdData.fillna('', inplace=True)
pdData['sheet_name'] = sheet_name
datas = json.loads(pdData.to_json(orient='records'))
for data in datas:
dataStr = json.dumps(data, ensure_ascii=False)
chunk_texts = txt_parser.parser_text(dataStr, blockSize=blockSize)
result.extend(chunk_texts)
return result
2.5 Book
支持的文件格式为DOCX、PDF、TXT。
细分到段落,每个段落一块,并且段落前需要拼接上当前段落所在的所有标题。
对于docx的文档,我们会先读取内部自带的格式,像一级标题/二级标题等,按照这种标题结构对文档进行切块;当不存在上述这种标题结构时,则使用规则的方法进行标题的读取,例如1.1,1.1.1等。
def readDocxStructure(path):
'''
使用 python-docx 解析工具抽取word文档,存在标题级别的情况下,最多读取5级标题
Args:
path: 文件路径
Returns:
titleMarkdown: markdown形式的标题结构
all_data: docx 最终的结构数据
'''
doc = docx.Document(path)
all_data = []
h1, h2, h3, h4, h5 = '', '', '', '', ''
titleMarkdown = ''
content = []
text_data_list = []
docxContentStr = ''
lastLevel = -1
for para in iter_block_items(doc):
if isinstance(para, Paragraph):
# p_xlm = para._element.xml # 读取xml
# content = save_picture(doc, p_xlm, content, '') # 图片处理
# 去除连续得到换行符,格式化
text = str(para.text)
text = re.sub('\n+', '\n', text)
text = str(text).strip(' ').replace("\"", "'")
docxContentStr += para.text + '\n'
if not text or text == '\n': # 数据无意义
continue
text_data_list.append(text)
# 判断标题
style_name = para.style.name.replace(" ", "")
style_id = para.style.style_id.replace(" ", "")
if style_name == 'Heading1' or style_name == 'Title' or style_name == '标题1' or style_id == 'Heading1':
if content or lastLevel == style_name:
# if content and h1:
all_data.append([h1, h2, h3, h4, h5, '\n'.join(content)])
h1 = text.replace(' ', '').replace("\"", "'")
h2 = ''
h3 = ''
h4 = ''
h5 = ''
titleMarkdown += '# %s\n' % h1
content = []
elif style_name == 'Heading2' or style_name == 'Subtitle' or style_name == '标题2' or style_id == 'Heading2':
if content or lastLevel == style_name:
all_data.append([h1, h2, h3, h4, h5, '\n'.join(content)])
h2 = text.replace(' ', '').replace("\"", "'")
h3 = ''
h4 = ''
h5 = ''
titleMarkdown += '## %s\n' % h2
content = []
elif style_name == 'Heading3' or style_name == '标题3' or style_id == 'Heading3':
if content or lastLevel == style_name:
all_data.append([h1, h2, h3, h4, h5, '\n'.join(content)])
h3 = text.replace(' ', '').replace("\"", "'")
h4 = ''
h5 = ''
titleMarkdown += '### %s\n' % h3
content = []
elif style_name == 'Heading4' or style_name == '标题4' or style_id == 'Heading4':
if content or lastLevel == style_name:
all_data.append([h1, h2, h3, h4, h5, '\n'.join(content)])
h4 = text.replace(' ', '').replace("\"", "'")
h5 = ''
titleMarkdown += '#### %s\n' % h4
content = []
elif style_name == 'Heading5' or style_name == '标题5' or style_id == 'Heading5':
if content or lastLevel == style_name:
all_data.append([h1, h2, h3, h4, h5, '\n'.join(content)])
h5 = text.replace(' ', '').replace("\"", "'")
titleMarkdown += '##### %s\n' % h5
content = []
else:
content.append(text.replace("\"", "'"))
lastLevel = style_name
elif isinstance(para, Table):
all_cell = []
table_str = ''
for i, row in enumerate(para.table.rows):
cell_lixt = []
for index, cell in enumerate(row.cells):
if cell not in all_cell:
all_cell.append(cell)
cell_lixt.append(cell.text.replace('\n', ' '))
table_str = table_str + '| %s |' % ' | '.join(cell_lixt) + '\n'
if i == 0:
table_str = table_str + '| --- ' * len(cell_lixt) + '|\n'
if table_str:
docxContentStr += table_str + '\n'
text_data_list.append(table_str)
if content:
all_data.append([h1, h2, h3, h4, h5, '\n'.join(content)])
content = []
all_data.append([h1, h2, h3, h4, h5, table_str])
if content:
all_data.append([h1, h2, h3, h4, h5, '\n'.join(content)])
return titleMarkdown, all_data, text_data_list, docxContentStr

2.6 Laws法律条款
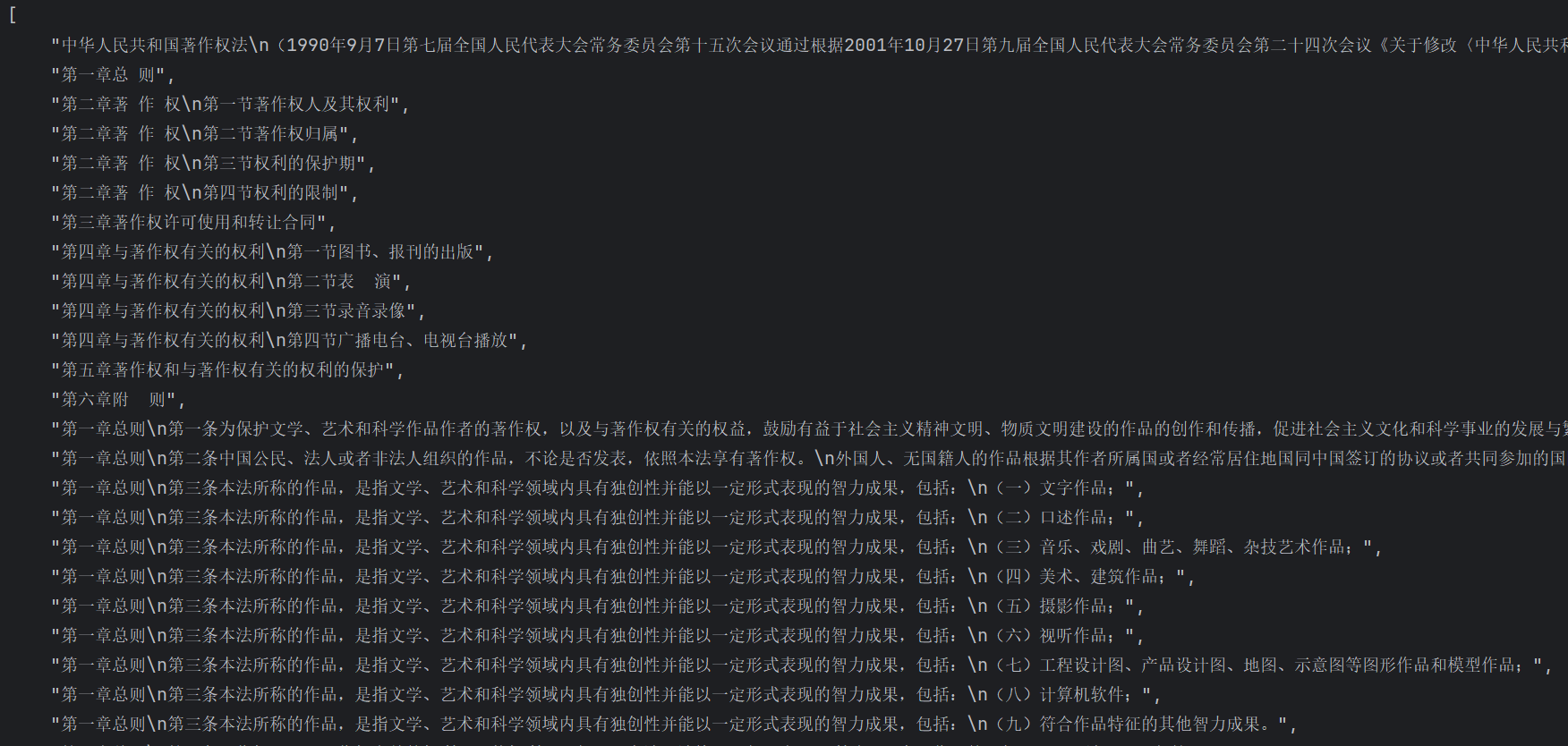
就是一个规则库,匹配最符合的编写逻辑,进行切分。
def parser_text(self, text, blockSize=myconfig.blockSize):
text = self.format_handle(text)
# print([text])
FormatTypeSelect = self.getFormatType(text, FormatTypes)
print(FormatTypeSelect)
datas = []
row = [''] * (len(FormatTypeSelect) + 1)
lastLevel = -1
for line in str(text).split('\n'):
if not line or line == '\n':
continue
level = self.text2titleLevel(FormatTypeSelect, line)
if level == -1:
row[-1] += line + '\n'
else:
if row[-1] or lastLevel == level or level < lastLevel:
datas.append(row)
row = row[:level] + [line] + [''] * (len(FormatTypeSelect) - level)
lastLevel = level
if row[-1]:
datas.append(row)
chunks = self.chunks2list(datas, blockSize)
# print(json.dumps(datas, ensure_ascii=False, indent=4))
return chunks
2.7 Regulation规则库分块
将Laws分块进行优化升级,形成Regulation分块方法,可以自动匹配哪一种逻辑,也可以知道某一种逻辑,规则库如下:
[
[
r"^第[\d零一二三四五六七八九十百]+章",
r"^第[\d零一二三四五六七八九十百]+条",
],
[
r"^第[\d零一二三四五六七八九十百]+章",
r"^第[\d零一二三四五六七八九十百]+条",
r"^[\((][零一二三四五六七八九十百]+[\))]"
],
[
r"^第[零一二三四五六七八九十百0-9]+章",
r"^第[零一二三四五六七八九十百0-9]+节",
r"^[零一二三四五六七八九十百]+[ 、]",
r"^[\((][零一二三四五六七八九十百]+[\))]",
],
[
r"^第[零一二三四五六七八九十百0-9]+(分?编|部分)",
r"^第[零一二三四五六七八九十百0-9]+章",
r"^第[零一二三四五六七八九十百0-9]+节",
r"^第[零一二三四五六七八九十百0-9]+条",
r"^[\((][零一二三四五六七八九十百]+[\))]",
],
[
r"^第[\d零一二三四五六七八九十百]+章",
r"^\d{1,2}[.、\.]?[^\d.、\.年日月号世天]",
r"^\d{1,2}[.、\.]\d{1,2}[.、\.]?[^\d.、\.]",
r"^\d{1,2}[.、\.]\d{1,2}[.、\.]\d{1,2}[.、\.]?[^\d.、\.]",
r"^\d{1,2}[.、\.]\d{1,2}[.、\.]\d{1,2}[.、\.]\d{1,2}[.、\.]?[^\d.、\.]",
r"^\d{1,2}[.、\.]\d{1,2}[.、\.]\d{1,2}[.、\.]\d{1,2}[.、\.]\d{1,2}[.、\.]?[^\d.、\.]",
],
[
r"^PART (ONE|TWO|THREE|FOUR|FIVE|SIX|SEVEN|EIGHT|NINE|TEN)",
r"^Chapter (I+V?|VI*|XI|IX|X)",
r"^Section [0-9]+",
r"^Article [0-9]+"
]
]
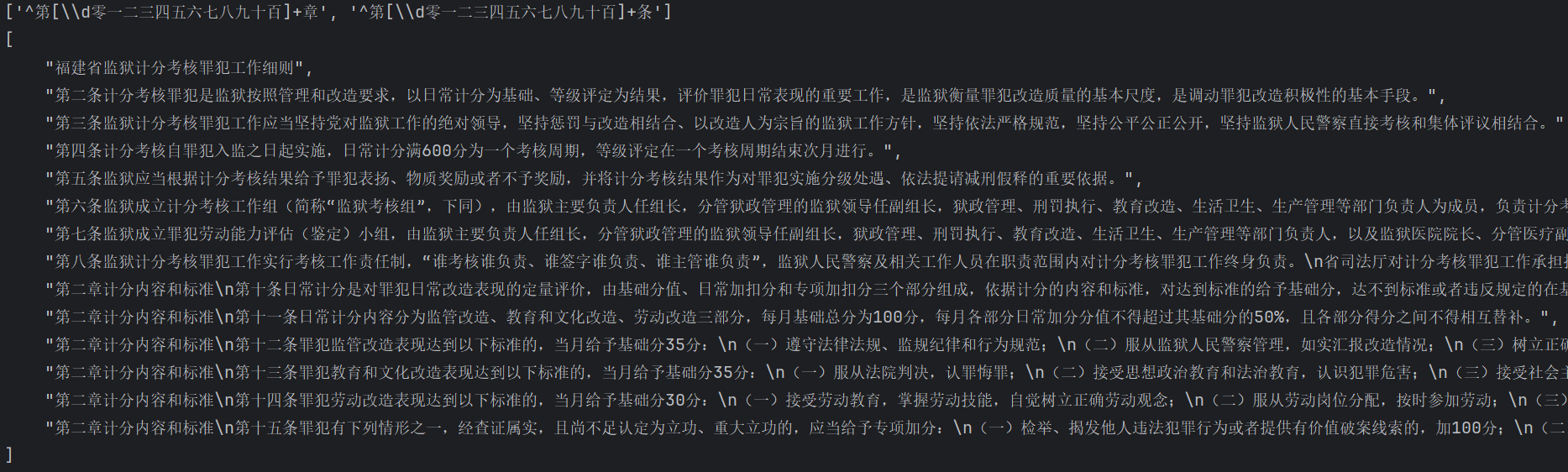
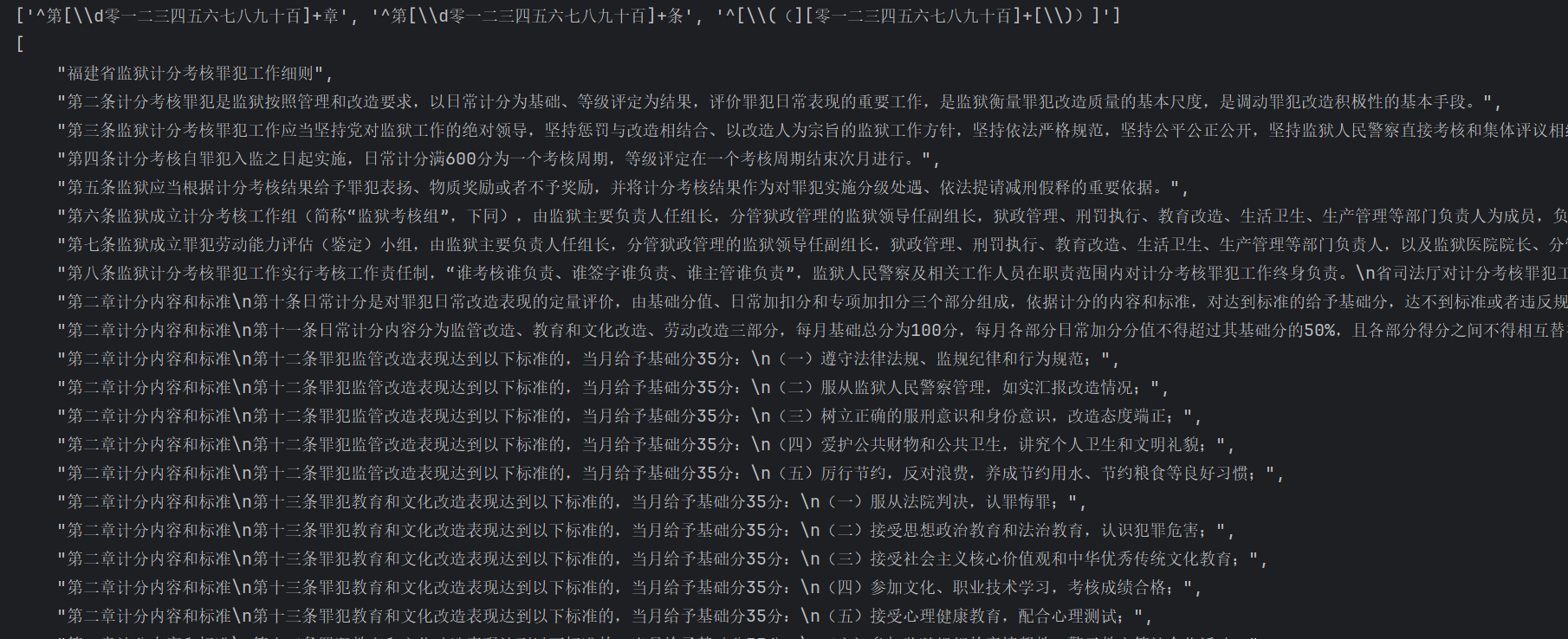
对于以下文档内容进行分块的效果,文档内容:
福建省监狱计分考核罪犯工作细则\n第二条计分考核罪犯是监狱按照管理和改造要求,以日常计分为基础、等级评定为结果,评价罪犯日常表现的重要工作,是监狱衡量罪犯改造质量的基本尺度,是调动罪犯改造积极性的基本手段。\n第三条监狱计分考核罪犯工作应当坚持党对监狱工作的绝对领导,坚持惩罚与改造相结合、以改造人为宗旨的监狱工作方针,坚持依法严格规范,坚持公平公正公开,坚持监狱人民警察直接考核和集体评议相结合。\n第四条计分考核自罪犯入监之日起实施,日常计分满600分为一个考核周期,等级评定在一个考核周期结束次月进行。\n第五条监狱应当根据计分考核结果给予罪犯表扬、物质奖励或者不予奖励,并将计分考核结果作为对罪犯实施分级处遇、依法提请减刑假释的重要依据。\n第六条监狱成立计分考核工作组(简称“监狱考核组”,下同),由监狱主要负责人任组长,分管狱政管理的监狱领导任副组长,狱政管理、刑罚执行、教育改造、生活卫生、生产管理等部门负责人为成员,负责计分考核罪犯工作的组织领导和重大事项研究。监区、分监区分别成立计分考核工作小组(简称“监区考核组”“分监区考核组”,下同),监区考核组由监区负责人任组长,监区其他领导任副组长,分监区负责人为成员;分监区考核组由分监区负责人任组长,分监区全体民警为成员,负责罪犯日常计分考核工作的具体实施。\n监狱考核组办公室(简称“监狱考核办”,下同)设在狱政管理科,由分管狱政管理的监狱领导任主任,狱政管理、教育改造和生产管理等部门负责人担任副主任,狱政管理、教育改造和生产管理部门各指定1名以上的民警为成员。狱政管理部门负责罪犯监管改造部分加分、扣分、专项加分、专项扣分、月考核分、考核结果运用,以及处罚或者取消考核积分和奖励的审查;教育改造部门负责教育和文化改造部分加分、扣分、等级评定的审查;生产管理部门负责劳动改造部分加分、扣分、表扬兑换物质奖励的审查。\n第七条监狱成立罪犯劳动能力评估(鉴定)小组,由监狱主要负责人任组长,分管狱政管理的监狱领导任副组长,狱政管理、刑罚执行、教育改造、生活卫生、生产管理等部门负责人,以及监狱医院院长、分管医疗副院长为成员,负责对罪犯的劳动能力进行评估(鉴定)。罪犯劳动能力评估(鉴定),由分监区考核组提出评估申请,并填写《罪犯劳动能力评估(鉴定)表》,经监区考核组、监狱医院审核后,报监狱罪犯劳动能力评估(鉴定)小组研究决定。监狱也可以委托社会第三方机构对罪犯劳动能力进行评估(鉴定)。\n第八条监狱计分考核罪犯工作实行考核工作责任制,“谁考核谁负责、谁签字谁负责、谁主管谁负责”,监狱人民警察及相关工作人员在职责范围内对计分考核罪犯工作终身负责。\n省司法厅对计分考核罪犯工作承担指导责任,省监狱管理局承担监督管理责任。\n第九条监狱计分考核罪犯工作应当依法接受纪检监察机关、检察机关、社会团体和人民群众的监督。\n第二章 计分内容和标准\n第十条日常计分是对罪犯日常改造表现的定量评价,由基础分值、日常加扣分和专项加扣分三个部分组成,依据计分的内容和标准,对达到标准的给予基础分,达不到标准或者违反规定的在基础分基础上给予扣分,表现突出的给予加分,符合专项加分情形的给予专项加分,符合专项扣分情形的给予专项扣分,计分总和为罪犯当月考核分。\n第十一条日常计分内容分为监管改造、教育和文化改造、劳动改造三部分,每月基础总分为100分,每月各部分日常加分分值不得超过其基础分的50%,且各部分得分之间不得相互替补。\n第十二条罪犯监管改造表现达到以下标准的,当月给予基础分35分:\n(一)遵守法律法规、监规纪律和行为规范;\n(二)服从监狱人民警察管理,如实汇报改造情况;\n(三)树立正确的服刑意识和身份意识,改造态度端正;\n(四)爱护公共财物和公共卫生,讲究个人卫生和文明礼貌;\n(五)厉行节约,反对浪费,养成节约用水、节约粮食等良好习惯;\n(六)其他遵守监规纪律的情形。\n第十三条罪犯教育和文化改造表现达到以下标准的,当月给予基础分35分:\n(一)服从法院判决,认罪悔罪;\n(二)接受思想政治教育和法治教育,认识犯罪危害;\n(三)接受社会主义核心价值观和中华优秀传统文化教育;\n(四)参加文化、职业技术学习,考核成绩合格;\n(五)接受心理健康教育,配合心理测试;\n(六)参加监狱组织的亲情帮教、警示教育等社会化活动;\n(七)参加文体活动,树立积极改造心态;\n(八)其他积极接受教育和文化改造的情形。\n第十四条罪犯劳动改造表现达到以下标准的,当月给予基础分30分:\n(一)接受劳动教育,掌握劳动技能,自觉树立正确劳动观念;\n(二)服从劳动岗位分配,按时参加劳动;\n(三)认真履行劳动岗位职责,按时完成劳动任务,达到劳动质量要求;\n(四)遵守劳动纪律、操作规程和安全生产规定;\n(五)爱护劳动工具和产品,节约原材料;\n(六)其他积极接受劳动改造的情形。\n第十五条罪犯有下列情形之一,经查证属实,且尚不足认定为立功、重大立功的,应当给予专项加分:\n(一)检举、揭发他人违法犯罪行为或者提供有价值破案线索的,加100分;\n(二)及时报告或者当场制止罪犯实施违法犯罪行为的,加100分;\n(三)检举、揭发、制止罪犯自伤、自残、自杀或者预谋脱逃、行凶等行为的,加100分;\n(四)检举、揭发罪犯私自制作、藏匿、传递、使用违禁品的,加100分;违规品的,加50分;其它不能持有的物品或非监狱配发、购买、批准或允许销售的物品,加20分;\n(五)及时发现和报告重大安全隐患,避免安全事故的,加100分;\n(六)在抗御自然灾害或者处置安全事故中表现积极的,加100分;\n(七)进行技术革新或者传授劳动生产技术成绩突出的,加30分;\n(八)新入监罪犯根据看守所提供的羁押期间表现综合评定为优秀等次的加 50 分,良好等次的加30 分,一般等次的加10 分,差等次的不加分;\n(九)省监狱管理局认定其他具有突出改造行为的,加10-100分,每次加分按10的倍数加分。\n罪犯每年度专项加分总量原则上不得超过300分,有上述第一至五项情形的不受年度加分总量限制。
-
使用第一种分块方式效果:
-
使用第二种分块方式效果:
2.8 One
就是整体文档内容问一个块。
2.9 Resume简历
简历分块,需要使用到LLM,对文档内容进行json格式化,其中需要抽取的字段可以自己定义。
2.10 Picture图片
也是需要使用VL-LLM,对图片内容进行总结。
- Visual Type: [Type]
- Title: [Title text, if available]
- Axes / Legends / Labels: [Details, if available]
- Data Points: [Extracted data]
- Trends / Insights: [Analysis and interpretation]
- Captions / Annotations: [Text and relevance, if available]
2.11 Paper
(1)非扫描件PDF可以直接使用Regulation分块方法对文档进行切块,适当的添加不同的分布规则。
(2)扫描件则需要使用VL大模型对内容进行获取。
3. 总结
最主要的分块方式就是通用分块、父子块分块、表格分块和Regulation分块,对于扫描件则要复杂的多,使用VL对文档内容转换成Markdown形式。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)